R Code [zeigen / verbergen]
time_shoot_tbl <- read_excel("data/zerforschen_pseudo_time.xlsx") |>
mutate(date = as.factor(date),
trt = as_factor(trt))Letzte Änderung am 31. October 2025 um 19:39:44
“Life can only be understood backwards; but it must be lived forwards.” — Søren Kierkegaard.
Die Analyse von Zeitreihen kann sehr quälend sein, wenn dein Datumsformat nicht richtig ist. Bitte achte darauf, dass du in der Spalte mit dem Datum immer das gleiche Format vorliegen hast. Dann können wir das Format später richtig transformieren. Danach geht dann alles einfacher…
In diesem Kapitel wollen wir uns mit “pseudo” Zeitreihen beschäftigen. Wenn dich “echte” Zeitreihen interessieren, dann schaue bitte einmal in das nächste Kapitel Zeitreihen (eng. time series). Wenn dir jetzt unklar ist, was da der Unterschied zwischen einer pseudo und echten Zeitreihe sein soll, dann versuche ich dir gleich einmal die Sachlage zu erklären. Zuerst haben wir in beiden Fällen ganz einfach auf der \(x\)-Achse einer potenziellen Visualisierung die Zeit dargestellt. Wir wollen dann Auswerten, ob es über den zeitlichen Verlauf einen Trend gibt oder wir ein gutes Modell für den Verlauf der Beobachtungen anpassen können. Dabei haben wir dann aber meistens nicht einen super simplen Verlauf, sondern Spitzen oder Täler in den Daten, so dass wir hier die Daten entsprechend glätten (eng. to smooth) müssen. Soweit ist die Sachlage in beiden Fällen die gleiche.
Warum jetzt aber “pseudo” Zeitreihen? Da es bei der Analyse von Zeitreihen konkrete Anforderungen an die Daten gibt, damit es sich um eine “echte” Zeitreihe im statistischen Sinne handelt. Du kannst Daten haben, die einer Zeitreihe ähneln aber sich nicht mit den statistischen Verfahren einer Zeitreihenanalyse auswerten lassen. Meistens sind die Zeitreihen zu kurz und zeigen keinen zyklischen Verlauf. Daher hast du einfach zu wenig Datenpunkte um diese Zeitreihe als eine Zeitreihe zu analysieren. Wenn du nur die Temperatur im Frühjahr und Sommer misst, dann fehlt dir der Zyklus über Herbst und Winter plus du müsstest die Temperaturen über mehre Jahre messen. Um diese “pseudo” Zeitreihen mit dennoch sinnvollen Fragestellungen soll es in diesem Kapitel gehen. Deshalb schau dir einfach mal die Beispiele hier an. Du wirst dann sehen, ob die Daten eher zu den “pseudo” Zeitreihen passen oder aber zu der klassischen Zeitreihenanalyse im nächsten Kapitel.
Auf der anderen Seite reicht vielleicht auch eine aussagekräftige Visualisierung um “pseudo” Zeitreihen sinnvoll darzustellen. Daher schauen wir uns in diesem Kapitel dann auch verschiedene Möglichkeiten an eine pseudo Zeitreihe einmal zu visualisieren. Auch kann es Sinn machen das R Paket {plotly} zu nutzen um eine interaktive Grafik zu erschaffen, wenn sehr viele Zeitpunkte vorliegen. Durch {plotly} haben wir dann die Möglichkeit auch in einer Grafik Werte abzulesen und zwischen verschiedenen Verläufen zu vergleichen. Dementsprechend sehe die Visualisierung auch als eine Möglichkeit deine Zeitreihe auszuwerten und zu präsentieren, wenn die Zeitreihe eben nicht den klassischen Anforderungen genügt. Mehr findest du auch auf der Seite von R Coder - Evolution charts.
Wenn es um Zeitreihen geht, dann ist die Formatierung der Spalte mit dem Datum eigentlich so ziemlich das aufwendigste. In dem Kapitel Zeit und Datum findest du dann nochmal mehr Informationen dazu. Achte bitte darauf, dass du eine einheitlich formatierte Datumsspalte hast, die sich nicht im Laufe der Zeilen ändert. Wenn das der Fall ist, dann musst du meist händisch nochmal die Daten anpassen und das ist meistens sehr aufwendig.
In dem folgenden Zerforschenbeispiel wollen wir einmal einen zeitlichen verlauf nachbauen und dann die Auswertung etwas verbessern. Mit Verbessern meien ich, dass wir die Abbildung 71.1 zwar nachbauen, aber auch die korrekten \(x\)-Achsen setzen. Die Ergänzung von Bildern ist immer besser in PowerPoint oder anderen Programmen zu machen. Ja, es geht auch in {ggplot}, aber ich würde es eher lassen und wenn es sein muss, dann mache das einfach extern. Daher lasse ich es hier in meinem Beispiel.
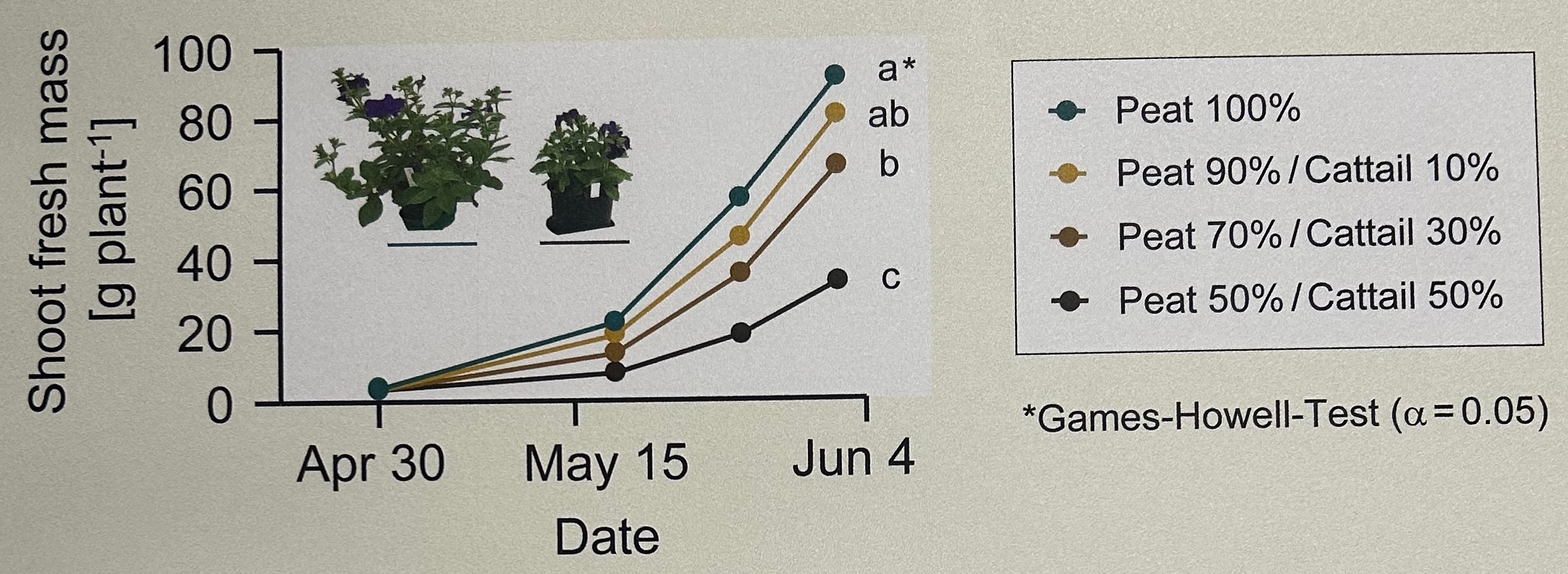
Du findest dann den Datensatz wie immer auf GitHub und hier lade ich einmal die Daten ein. Ich habe mir die Werte aus der Abbildung rausgesucht und dann nochmal jeweils zwei Beobachtungen ergänzt. Da wir bei dem letzten Termin einen Gruppenvergleich rechnen wollen, brauchen wir auch mehr als eine Beobachtung. Das ist auch so eine Sache, die hier fehlt. Es werden nämlich nur die Mittelwerte angegeben ohne die Standardabweichung. Ich wandle alle Zeitangaben in einen Faktor um, so dass die Abstände jetzt alle gleich lang sind. Das könnte man auch anders machen indem wir uns noch eine zusätzliche Spalte mit einer numerischen Zeitangabe bauen. Aber hier soll es so reichen.
time_shoot_tbl <- read_excel("data/zerforschen_pseudo_time.xlsx") |>
mutate(date = as.factor(date),
trt = as_factor(trt))Ich baue mir jetzt erstmal den zeitlichen Verlauf und ergeänze dann über das R Paket {patchwork} an der rechten Seite nochmal den Barplot für das letzte Datum. Den test rechne ich dann in {emmeans}, da das Paket einfach den anderen Tests überlegen ist. Der Games-Howell-Test nimmt Varianzheterogenität in den Daten an und das kann ich dann auch einfach in emmeans() durch die Option vcov. = sandwich::vcovHAC berücksichtigen. Das ist die bessere Option, da wir hier sehr viel flexibler sind als mit anderen statistischen Tests. Mehr dazu dann aber wie immer im Kapitel zu den multiplen Vergleichen.
Wir bauen uns jetzt einmal den zeitlichen Verlauf nach. Ich speichere dann auch den Plot einmal in dem Objekt p1 um ihn dann gleich wiederzuverwenden. Wichtig ist hierbei, dass wir zum einen eine Gerade durch die Mittelwerte zeichen und dann noch die Fehlerbalken ergänzen. Damit das alles nicht übereinander liegt, habe ich noch die Positionen angepasst. Die ursprünglichen Beobachtungen sind dann Kreuze. Ganz am Ende musste ich noch die \(y\)-Achse etwas expandieren, damit es gleich besser zusammen mit dem Barplot ausszieht. Aber wie immer, am meisten lernst du, wenn du einzelen Layer einfach mit # auskommentierst und schaust, was die so machen.
p1 <- time_shoot_tbl |>
ggplot(aes(date, freshmatter, color = trt, group = trt)) +
theme_minimal() +
geom_jitter(position=position_dodge(0.3), shape = 4, size = 2) +
stat_summary(fun.data="mean_sdl", fun.args = list(mult = 1),
geom="pointrange", position=position_dodge(0.3)) +
stat_summary(fun = "mean", fun.min = "min", fun.max = "max", geom = "line",
position=position_dodge(0.3)) +
labs(x = "Date", y = TeX(r"(Shoot fresh mass \[g plant$^{-1}$\])"),
color = "") +
theme(legend.position = "top") +
scale_x_discrete(labels = c("30. April", "17. Mai", "25. Mai", "03. Juni")) +
scale_y_continuous(expand = expand_scale(mult = c(0.09, 0.09))) +
scale_color_okabeito()
p1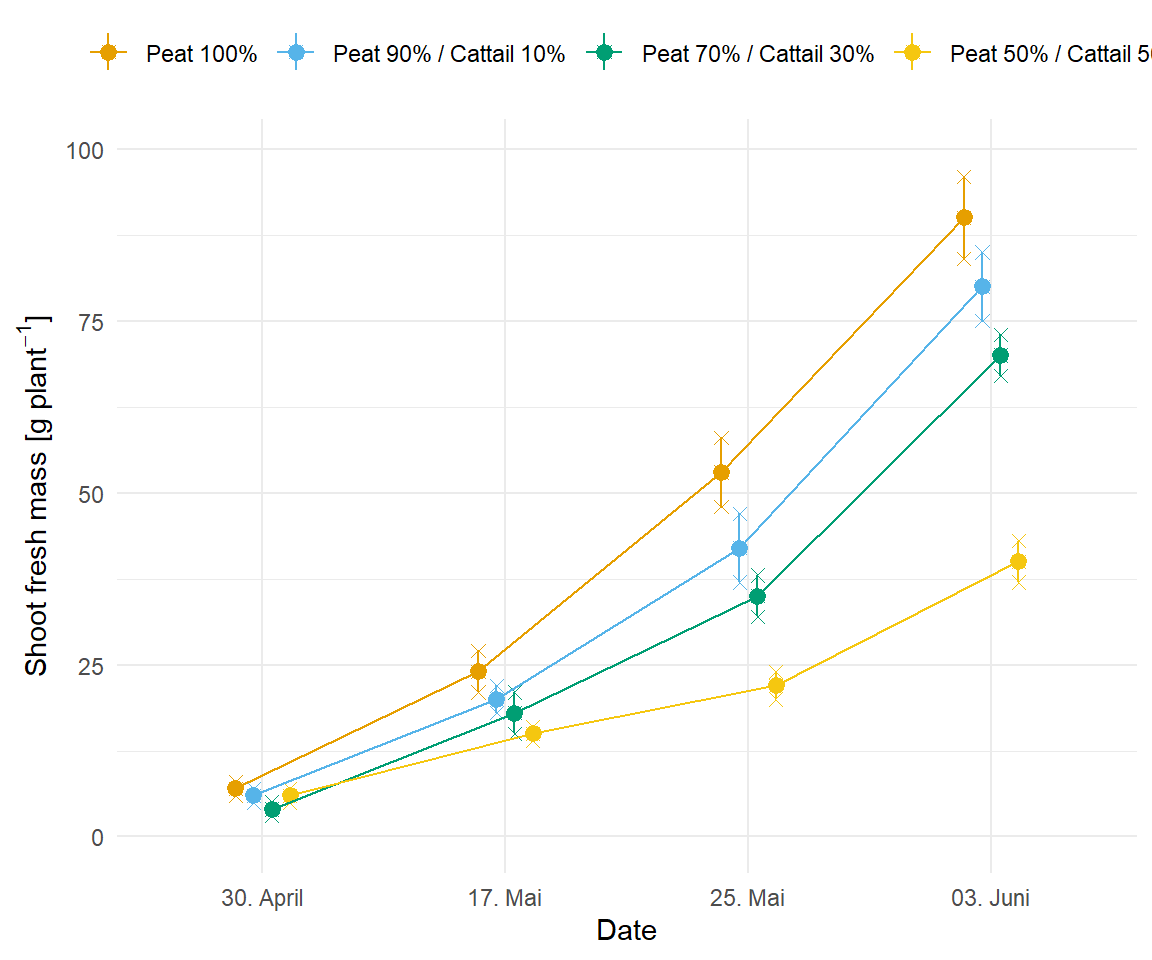
Dann möchte ich noch für den 3. Juni einmal gesondert die Barplots in einer Abbildung zeigen. Ich bin etwas faul und rechne einfach über alle Behandlungen getrennt nach dem Zeitpunkt einen multiplen Mittelwertesvergleich. Dann lasse ich mir das compact letter display wiedergeben. Ich entferne noch unnötige Leerzeichen und rechne den Standardfehler in die Standardabweichung zurück.
emmeans_tbl <- lm(freshmatter ~ trt + date + trt:date, data = time_shoot_tbl) |>
emmeans(~ trt | date, vcov. = sandwich::vcovHAC) |>
cld(Letters = letters, adjust = "none") |>
as_tibble() |>
mutate(.group = str_trim(.group),
sd = SE * sqrt(4)) In der Abbildung 71.3 wähle ich dann nur den 3. Juni aus und baue mir wie gewohnt einen Barplot aus dem Mittelwert und der berechneten Stanardabweichung. Ich räume dann noch den Plot etwas auf, da wir die Hauptinformationen in dem zeitlichen Verlauf drin haben.
p2 <- emmeans_tbl |>
filter(date == "2023-06-03") |>
ggplot(aes(x = trt, y = emmean, fill = trt)) +
theme_minimal() +
geom_bar(stat = "identity", position = position_dodge2(preserve = "single")) +
geom_errorbar(aes(ymin = emmean-sd, ymax = emmean+sd),
width = 0.5, position = position_dodge(0.9)) +
labs(x = "3. Juni", y = "") +
geom_text(aes(label = .group, y = emmean + sd + 3)) +
theme(legend.position = "none") +
theme(axis.text.x=element_blank(),
axis.ticks.x=element_blank()) +
scale_fill_okabeito()
p2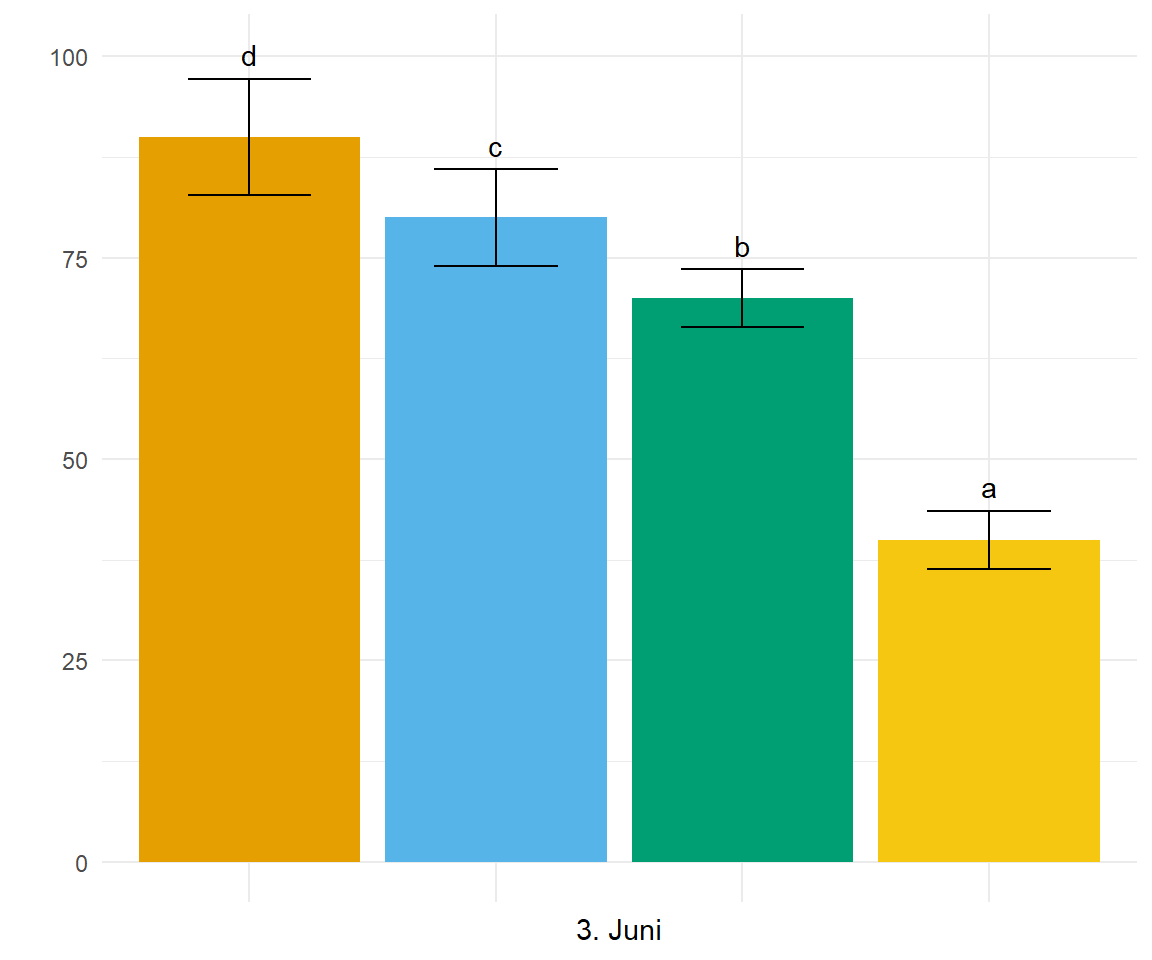
Am Ende nutze ich das R Paket {patchwork} um die beiden Abbidlungen in den Objekten p1 und p2 zusammenzubringen. Wie immer geht hier noch mehr, aber ich finde das wir hier eine schöne Übersicht über das Wachstum der Petunien über die Zeit haben. Ich habe jetzt auch die Buchstaben aus dem zeitlichen Verlauf rausgenommen, da man sonst denken könnte wir hätten den ganzen verlauf getestet und nicht nur den letzten Tag. Das macht einen gewaltigen Unterschied in der Interpretation.
p1 + p2 +
plot_layout(widths = c(7, 1))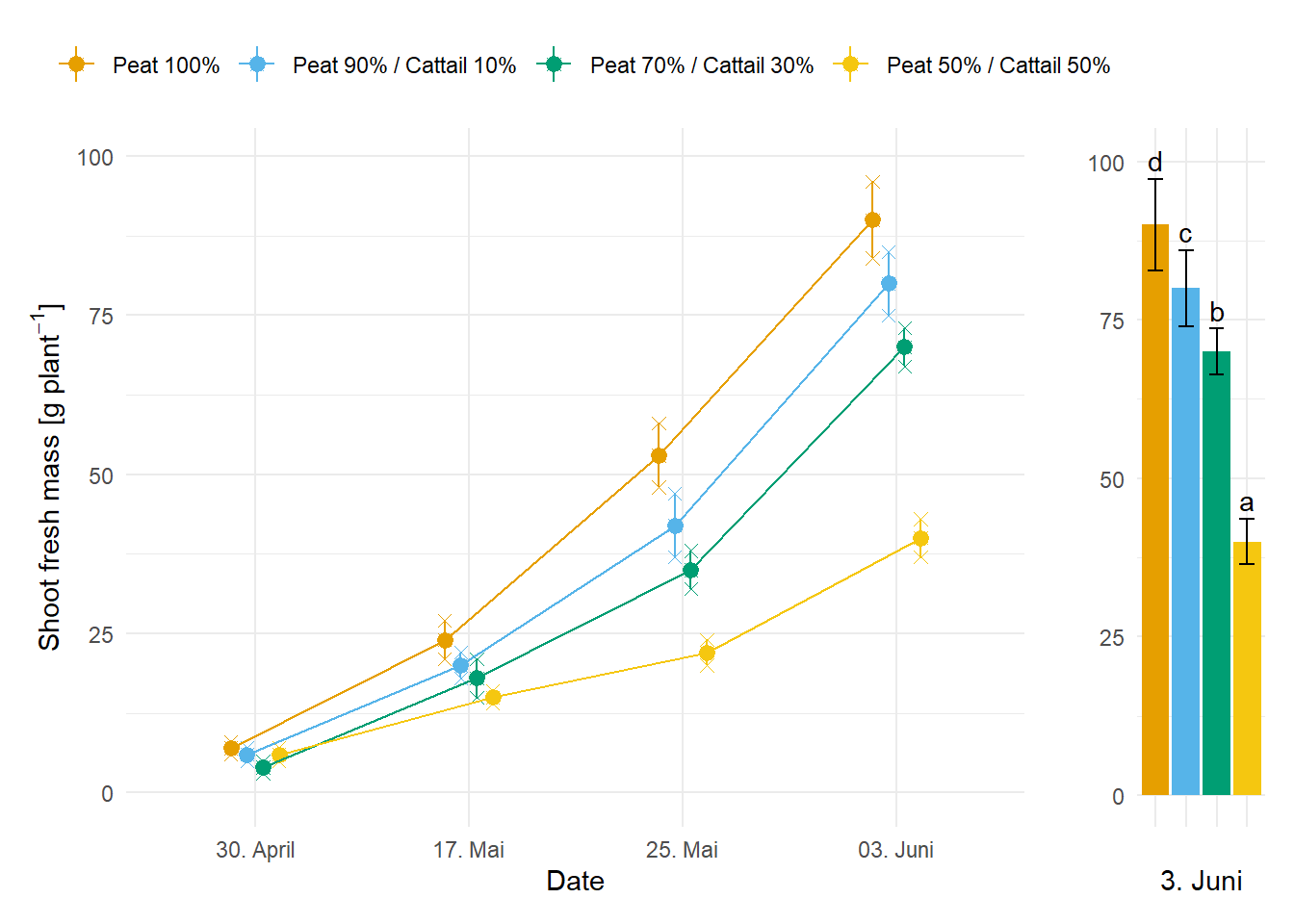
Dieses Anwendungsbeispiel zum Zerforschen ist mir mehr oder minder zufällig über den Weg gelaufen. Und wie immer es so ist, manchmal habe ich dann Lust noch was Neues auszuprobieren. In diesem Fall war es dann das R Paket {gganimate} was mich sehr gereizt hat mal auszuprobieren. Und für zeitliche Verläufe bietet sich das R Paket sehr gut an. Worum geht es also heute? Wir wollen uns die Geschichte anschauen, warum die NASA das Ozonloch nicht entdeckte, obwohl die Daten alle da waren. Hierzu wie immer auch noch mehr Informationen auf der Seite How NASA didn’t discover the hole in the ozone layer und natürlich auf der Homepage der NASA selbst mit History of the Ozone Hole. Von dort habe ich auch die ursprüngliche Abbildung 71.5, die wir hier einmal zerforschen wollen.
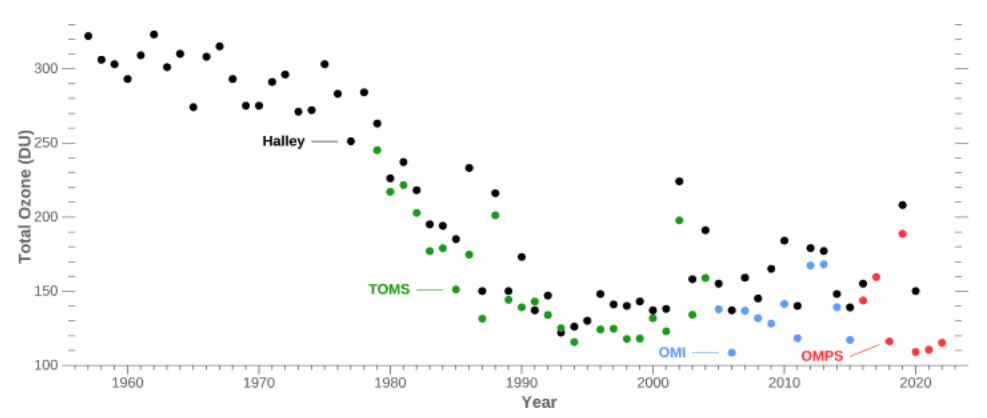
Was mich dann dazu gebracht hat, mir die Sachlage einmal mehr anzuschauen, war folgendes Zitat von Rob J Hyndman. Denn eigentlich meint man ja nicht sofort etwas in den Daten zu sehen.
Always plot the data. In this case, a graph such as Figure 71.5 would have revealed the problem in the late 1970s, but it seems no-one was producing plots like this. — How NASA didn’t discover the hole in the ozone layer
In den frühen 80zigern war es anscheinend noch nicht so gängig sich Daten auch wirklich mal anzuschauen. Das wollen wir hier einmal umgehen und laden uns einmal die Daten. Vorab brauche ich noch einige zusätzliche R Pakete um die Darstelung besser hinzukriegen.
pacman::p_load(ggh4x, gganimate)Die Daten habe ich aus der ursprünglichen Abbildung 71.5 abgelesen. Ich hatte erst überlegt mir die Daten runterzuladen, aber es war mir dann zu mühselig alles nochmal reinzulesen und nachzubauen. So reicht es auch vollkommen. Es dauerte etwas aber am Ende hatte ich fast die gleichen Daten wie oben in der Abbildung.
nasa_tbl <- read_excel("data/zerforschen_nasa_ozone.xlsx") |>
mutate(method = as_factor(method))Ich wolle mir dann einmal die Regression für die Daten vor 1980 einmal anschauen und dann als Regressionspfeil mit in die Abbildung plotten. Dafür filtere ich einmal die Daten und rechne mir eine lineare Regression aus.
nasa_tbl |>
filter(year <= 1980) |>
lm(total_ozone ~ year, data = _) |>
coef()(Intercept) year
6110.636404 -2.958568 Mit den Informationen zu der Steigung und dem Intercept kann ich mir auch gleich einmal die Regressionsgleichung bauen. Wie wir sehen, geht der Anteil an Ozon mit ca. 3 DU-Einheiten pro Jahr schon vor 1980 zurück. Das ist nicht wenig.
\[ total\_ozone = 6111 - 2.96 \cdot year \]
Dann ergänze ich noch den ursprünglichen Datensatz um eine Spalte mit der Vorhersage. Ich muss das machen, da ich in {gganimate} immer nur auf einen Datensatz zugreifen kann. Den Datensatz kann ich zwar filtern, aber es ist super schwer, wenn du mit mehreren Datensätzen arbeiten willst. Daher mache ich es mir hier einfacher.
nasa_pred_tbl <- nasa_tbl |>
mutate(pred_ozone = 6111 - 2.96 * year) Wenn du mehr wissen willst, dann kan ich dir das Animate ggplots with gganimate::CHEAT SHEET empfehlen. Wir animieren jetzt den Plot über die \(x\)-Achse und damit über year. Das ist eigentlich nur die letzte Zeile mit transition_reveal(year), die uns dann den Plot animierfähig macht. Ich speichere die Abbildung dann in dem Objekt p damit ich gleich die Geschwindigkeit modifizieren kann. Das R Paket {ggh4x} erlaubt mir dann noch die Ergänzung von zusätzlichen Strichen auf den Achsen. Der Rest ist eigentlich fast selbsterklärend. Der Pfeil war dann vermutlich die komplizierteste Ergänzung.
p <- nasa_pred_tbl |>
ggplot(aes(year, total_ozone, color = method, shape = method)) +
theme_minimal() +
geom_point(aes(group = seq_along(year)), size = 2) +
geom_line(data = filter(nasa_pred_tbl, year < 1979), aes(year, pred_ozone),
color = "gray", arrow = arrow(length=unit(0.30,"cm"), type = "closed"),
linewidth = 1.25) +
ylim(100, NA) +
theme(legend.position = "top") +
scale_x_continuous(minor_breaks = seq(1957, 2022, by = 1),
breaks = seq(1960, 2020, by = 10), limits = c(1957, 2022),
guide = "axis_minor",
sec.axis = sec_axis(trans=~.*1, name="",
breaks = seq(1960, 2020, by = 10))) +
scale_y_continuous(breaks = c(100, 150, 180, 200, 250, 300, 330),
sec.axis = sec_axis(trans=~.*1, name="",
breaks = c(100, 150, 180, 200, 250, 300, 330))) +
scale_color_okabeito(order = c(9, 3, 2, 6)) +
labs(x = "Year", y = "Total Ozone (DU)", color = "", shape = "") +
geom_hline(yintercept = 180, color = "gray") +
transition_reveal(year) In der Abbildung 71.6 siehst du dann einmal die animierte Abbildung. Ich habe dann noch mit der Option fps = 5 die Geschwindigkeit etwas angepasst. Wir sehen sehr schön wie stark der Ozongehalt schon vor 1980 beginnt zu fallen. Das können wir mit der Regressionsgeraden gut nachvollziehen. Es dauert aber noch ein paar Jahre, bis die Ozonwerte unter den damaligen kritischen Grenzwert der NASA von 180 DU fällt. Wir hätten den Trend schon viel früher sehen müssen, wenn wir die Daten visualisiert hätten.
animate(p, fps = 5)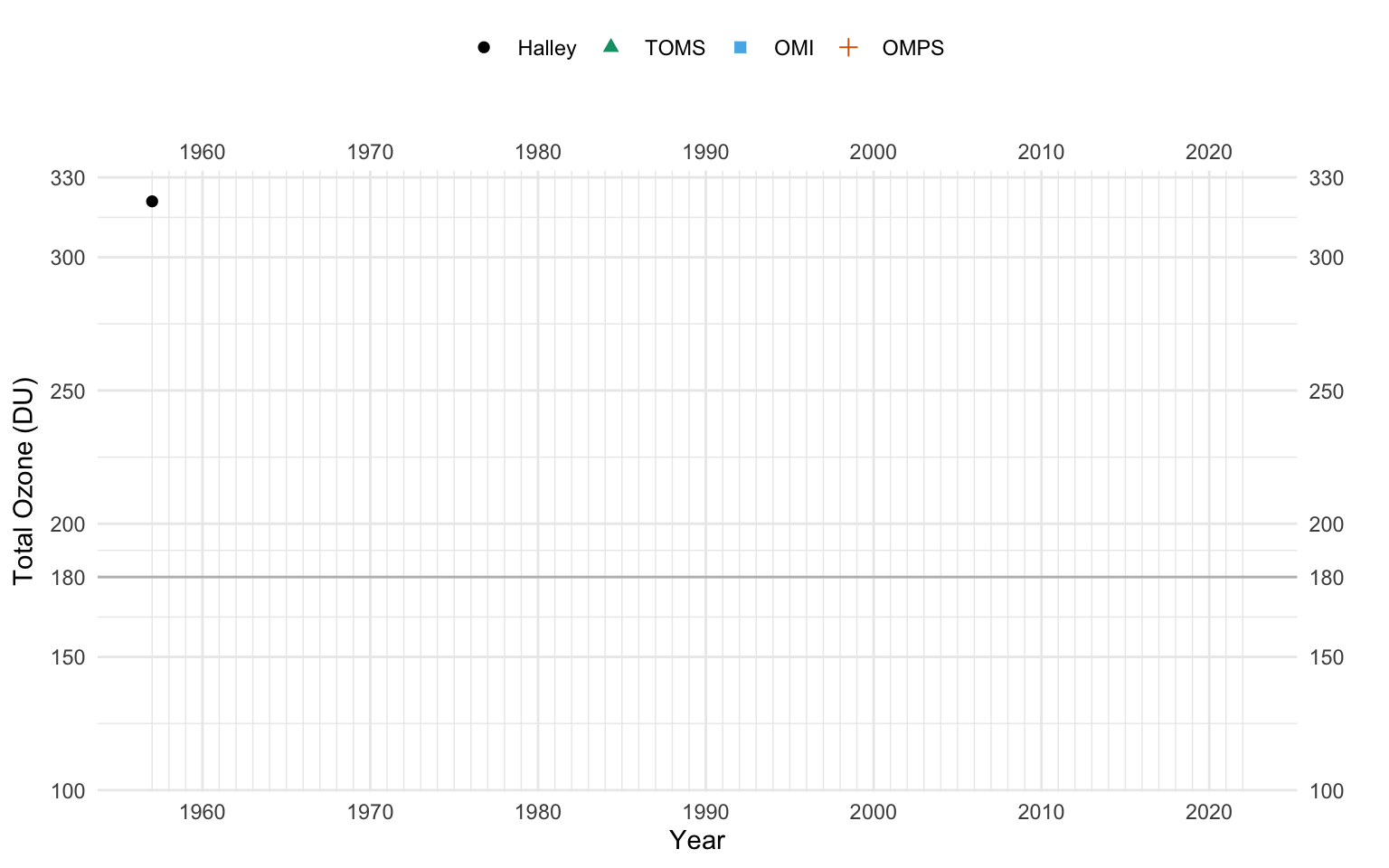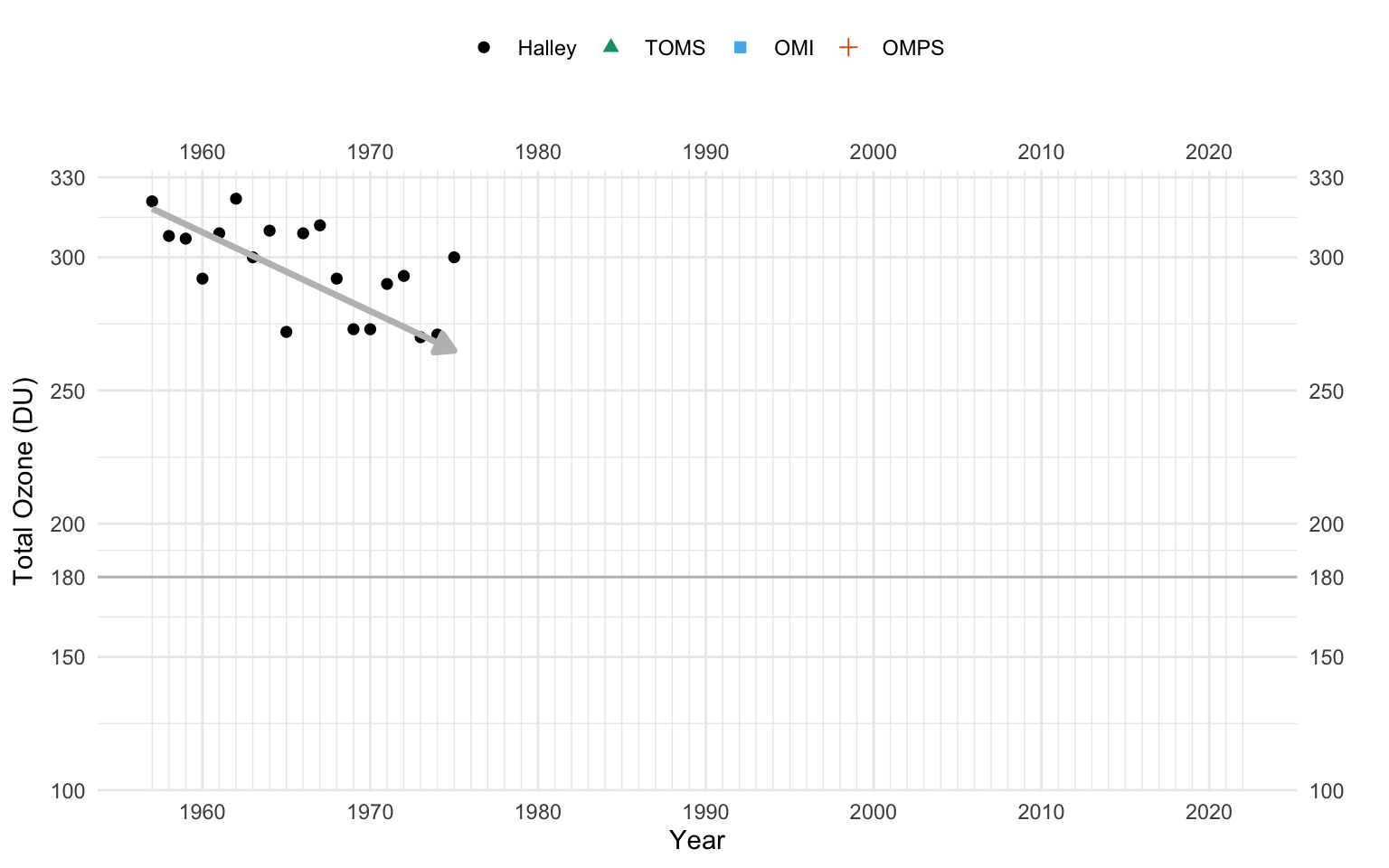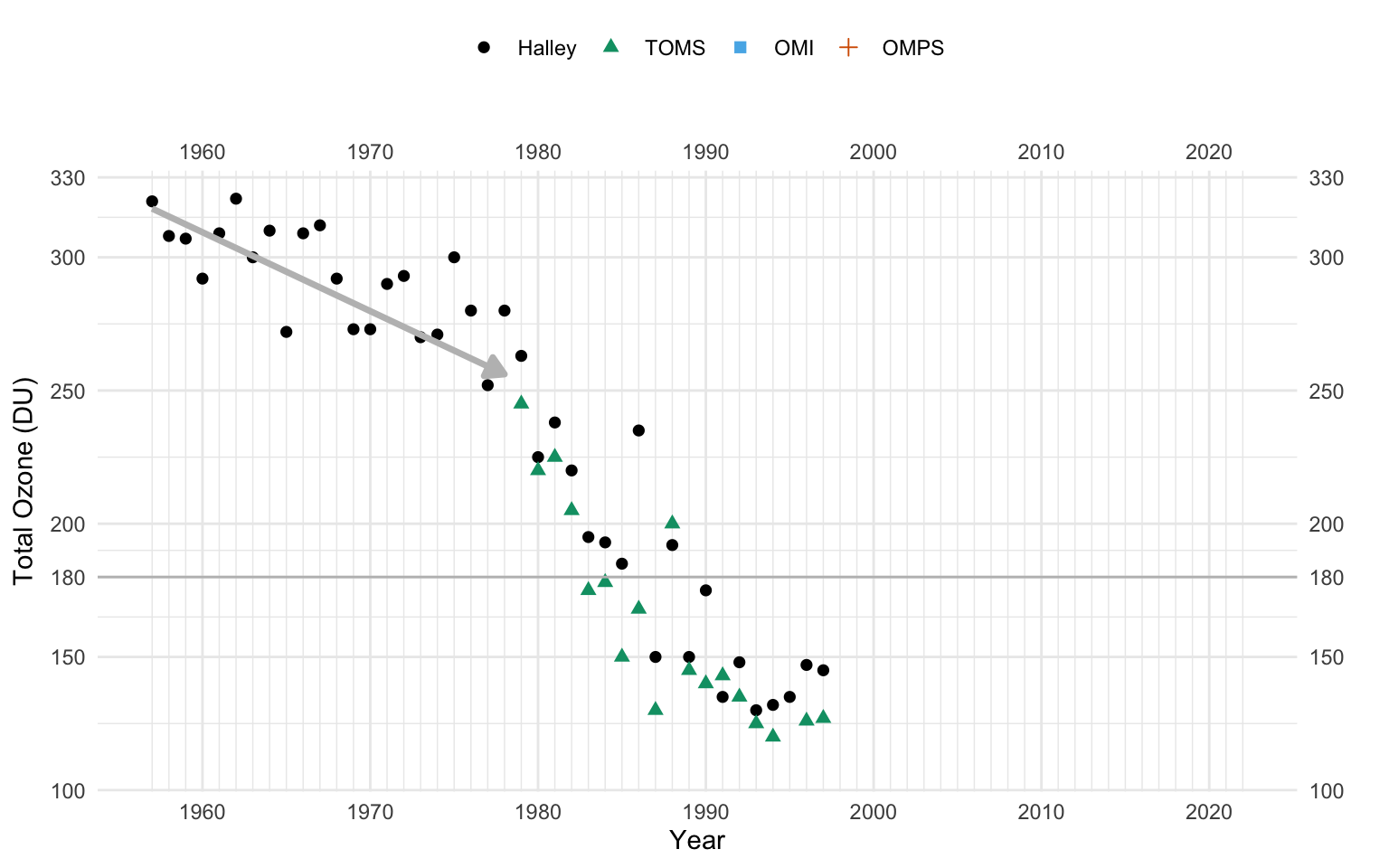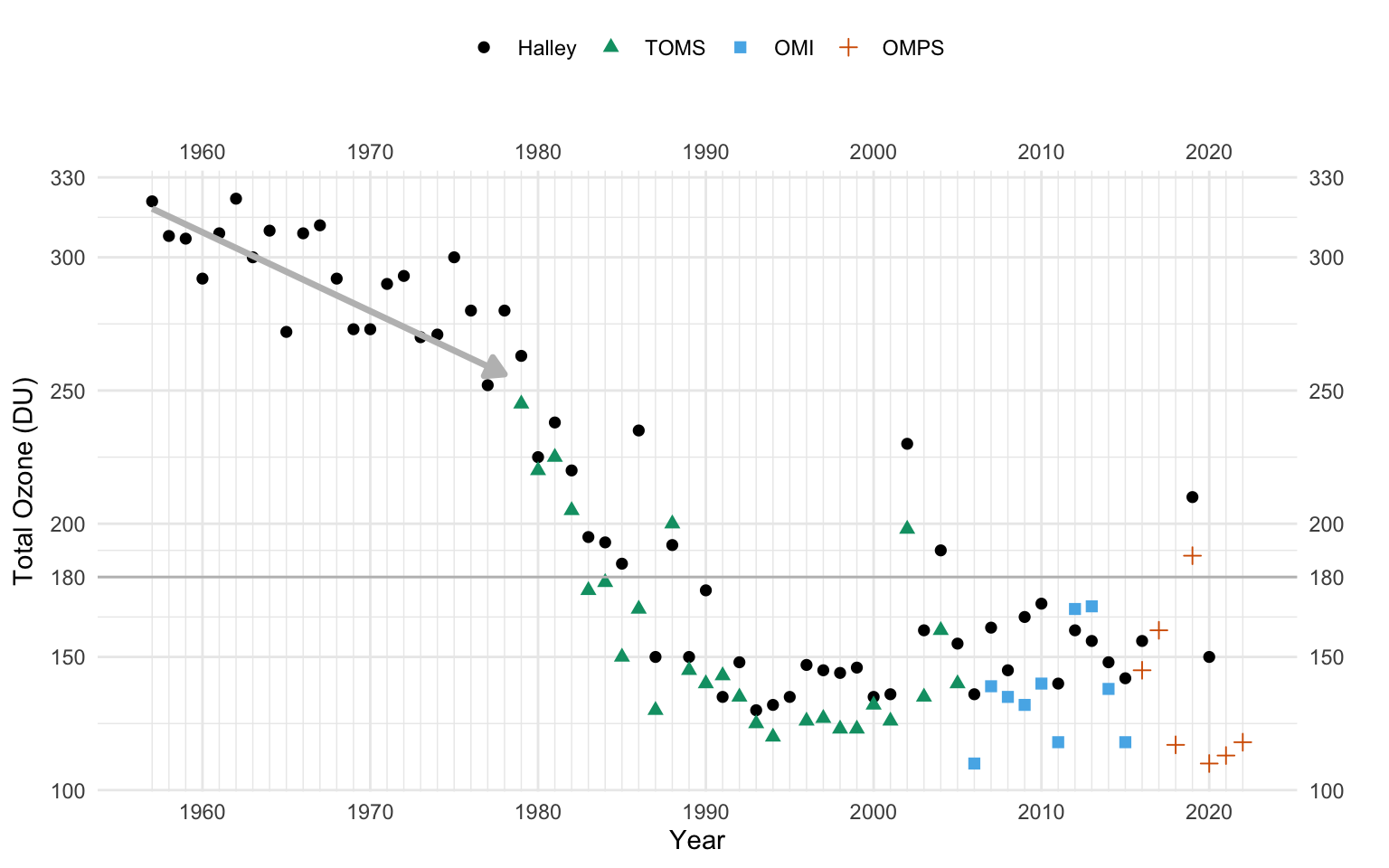
Wir wollen folgende R Pakete in diesem Kapitel nutzen.
pacman::p_load(tidyverse, magrittr, janitor, see, readxl,
lubridate, plotly, zoo, timetk, conflicted)
conflicts_prefer(dplyr::filter)
conflicts_prefer(magrittr::set_names)
conflicts_prefer(dplyr::slice)An der Seite des Kapitels findest du den Link Quellcode anzeigen, über den du Zugang zum gesamten R-Code dieses Kapitels erhältst.
Den ersten Datensatz, den wir uns anschauen wollen, ist in einer CSH-Datei abgespeichert, die ich schon in Excel exportiert habe. Eine CSH-Datei ist ein Datenformat aus Adobe Photoshop und eigentlich nichts anders als eine Information über eine Bilddatei. Wir haben aber hier nicht Pixel oder aber ein Foto vorliegen, sondern das Bild wurde schon in einen numerischen Wert pro Bild weiter verarbeitet. Das hier so ausgedachte Experiment war ein Dronenüberflug über eine Wiese und einem Feld in Uelzen. Dabei wurden Fotos gemacht und es sollten verschiedene Grünlandwerte aus den Fotos berechnet werden. Wir haben aber den Überflug nicht an einem einzigen Tag gemacht, sondern gleich an mehreren über das Jahr verteilt. Das ist jetzt auch dann gleich unsere Zeitreihe. Jetzt können wir uns Fragen, ob es einen Unterschied zwischen den Messwerten der beiden Dronenüberflüge gibt. Wir lesen wie immer erstmal die Daten ein.
csh_tbl <- read_excel("data/csh_data.xlsx") |>
clean_names() |>
mutate_if(is.numeric, round, 2) |>
mutate(day_num = as.numeric(as.factor(day)))In der Tabelle 71.1 siehst du einen Ausschnitt aus den 926 Überflügen. Hier wurden die Daten natürlich schon zusammengefasst. Aus jedem Bild wurde dann ein Wert für zum Beispiel kg_tm_ha berechnet. Hier interessiert uns aber nicht die Berechnungsart. Wir wollen jetzt gleich mit den Daten weiterarbeiten. Wie immer ist das Beispiel so semi logisch, hier geht es aber auch eher um die Anwendung der Methoden.
| parzelle | day | g_tm_plot | kg_tm_ha | netto_csh_cm | tm_gehlt | day_num |
|---|---|---|---|---|---|---|
| Wiese | 428 | 15.2 | 1148.47 | 7.8 | 0.22 | 1 |
| Wiese | 428 | 11.4 | 813.57 | 8 | 0.21 | 1 |
| Wiese | 428 | 24.7 | 1771.79 | 9.3 | 0.21 | 1 |
| Wiese | 428 | 20.9 | 1520.52 | 8 | 0.23 | 1 |
| … | … | … | … | … | … | … |
| Uelzen | 920 | 42.7 | 3104.49 | 3.6 | 0.2 | 30 |
| Uelzen | 920 | 31.9 | 2455.84 | 1.8 | 0.26 | 30 |
| Uelzen | 920 | 47 | 3396.17 | 3.4 | 0.24 | 30 |
| Uelzen | 920 | 30.2 | 2201.32 | 2.5 | 0.27 | 30 |
Im nächsten Datensatz schauen wir uns einmal die Daten von vier Loggern an. Hier haben wir mehr oder minder einfach jeweils einen Temperaturlogger an den jeweiligen Seiten unseres Folientunnels geworfen und dann nochmal einen Logger einfach so auf das Feld gelegt. In den Folientunneln haben wir dann Salat hochgezogen. Wir betrachten jetzt hier nur das Freiland, sonst wird es einfach zu viel an Daten.
salad_tbl <- read_excel("data/temperatur_salad.xlsx") |>
clean_names() |>
mutate_if(is.numeric, round, 2) |>
select(datum, uhrzeit, matches("freiland"))In der Tabelle 71.2 siehst du einmal die 2447 automatisch erfassten Messungen der Temperatur pro Tag und dann Stunde. Hier müssen wir dann einmal schauen, wie wir die Daten dann sinnvoll zusammenfassen. Es sind wirklich viele Datenpunkte. Aber gut wir schauen uns die Daten erstmal an und entscheiden dann später weiter. Wir sehen aber schon, dass wir die Daten nochmal bearbeiten müssen, denn irgendwas stimmt mit der Uhrzeitspalte und dem Datum nicht. Dazu dann aber gleich mehr im Abschnitt zum Datumsformat.
| datum | uhrzeit | freiland_messw | freiland_min | freiland_max |
|---|---|---|---|---|
| 2023-04-11 | 1899-12-31 13:30:00 | 21.9 | 21.9 | 21.9 |
| 2023-04-11 | 1899-12-31 14:00:00 | 18.8 | 18.8 | 22.5 |
| 2023-04-11 | 1899-12-31 14:30:00 | 14.6 | 13.8 | 18.8 |
| 2023-04-11 | 1899-12-31 15:00:00 | 13.2 | 13.2 | 15.6 |
| … | … | … | … | … |
| 2023-06-01 | 1899-12-31 11:00:00 | NA | NA | NA |
| 2023-06-01 | 1899-12-31 11:30:00 | NA | NA | NA |
| 2023-06-01 | 1899-12-31 12:00:00 | NA | NA | NA |
| 2023-06-01 | 1899-12-31 12:30:00 | NA | NA | NA |
Am Ende wollen wir uns dann nochmal Daten einer Wetterstation in Hagebüchen an. Auch hier haben wir wieder sehr viele Daten vorliegen und wir müssen uns überlegen, welche der Daten wir nutzen wollen. Aus Gründen der Machbarkeit wähle ich die Spalte temp_boden_durch und solar_mv aus, die wir uns dann später anschauen wollen. Sonst wird mir das zu groß und unübersichtlich.
station_tbl <- read_excel("data/Wetterstation_Hagebuechen.xlsx") |>
clean_names() |>
select(datum_uhrzeit, temp_boden_durch, solar_mv) |>
mutate_if(is.numeric, round, 2)Auch hier haben wir in der Tabelle 71.3 gut 4163 einzelne Messungen vorliegen. Das ist dann auch unserer größter Datensatz von Klimadaten. Wir werden die Daten dann aber sehr anschaulich einmal in einer Übersicht darstellen.
| datum_uhrzeit | temp_boden_durch | solar_mv |
|---|---|---|
| 2022-09-21 18:00:00 | 12.9 | 6978 |
| 2022-09-21 17:00:00 | 15.2 | 10223 |
| 2022-09-21 16:00:00 | 15.6 | 10343 |
| 2022-09-21 15:00:00 | 15.7 | 10348 |
| … | … | … |
| 2022-04-01 11:00:00 | -1.3 | 9854 |
| 2022-04-01 10:00:00 | -1.1 | 9892 |
| 2022-04-01 09:00:00 | -1.3 | 6983 |
| 2022-04-01 08:00:00 | -1.3 | 4083 |
Damit hätten wir uns eine Reihe von landwirtschaftlichen Datensätzen angeschaut. Sicherlich gibt es noch mehr, aber diese Auswahl erlaubt es uns gleich einmal die häufigsten Fragen rund um Zeitreihen in den Agrarwissenschaften einmal anzuschauen. Bitte beachte, dass es natürlich noch andere Formen von Zeitreihen und damit Datensätzen gibt. Deshalb gleich noch ein Datensatz, der künstlich ist und damit eine eher perfekte Zeitreihe repräsentiert. In dem folgenden Kasten findest du darüber hinaus nochmal eine Anregung zu Klimadaten aus deiner Region.
Du kannst gerne die entgeltfreien Informationen auf der DWD-Website nutzen um mehr Informationen zu dem Klima und deiner Region zu erhalten. Wir finden dort auf der Seite die Klimadaten für Deutschland und natürlich auch die Daten für Münster/Osnabrück. Sie dazu auch Isoplethendiagramm für Münster & Osnabrück im Skript zu beispielhaften Anwendung. Ich habe mir dort flux die Tageswerte runtergeladen und noch ein wenig den Header der txt-Datei angepasst. Du findest die Datei day_values_osnabrueck.txt wie immer auf meiner GitHub Seite. Du musst dir für andere Orte die Daten nur entsprechend zusammenbauen. Am Ende brauchen wir noch die Informationen zu den Tages- und Monatswerten damit wir auch verstehen, was wir uns da von der DWD runtergeladen haben.
Wenn wir von Zeitreihen sprechen dann sprechen wir auch von dem Datumsformat. Eine Zeitreihe ohne eine richtig formatierte Datumsspalte macht ja auch überhaupt keinen Sinn. Es ist eigentlich immer einer ewige Qual Daten in das richtige Zeitformat zu kriegen. Deshalb hier vorab einmal die folgende Abbildung, die nochmal die Wirrnisse des Datumsformat gut aufzeigt.

Wichtig ist, dass wir das richtige Datumsformat haben. Siehe bitte dazu auch das Kapitel Zeit und Datum. Das einzig richtige Datumsformat ist und bleibt eben Jahr-Monat-Tag. Häufig ist eben dann doch anders, so dass wir uns etwas strecken müssen um unser Format in das richtige Format zu überführen. Bitte beachte aber, dass du auf jeden Fall einheitlich dein Datum einträgst. Am besten auch immer zusammen mit dem Jahr, dass macht vieles einfacher. Wie immer gibt es auch noch das Tutorium zu Date Formats in R und natürlich das R Paket {lubridate} mit dem Einstieg Do more with dates and times in R.
Wir werden uns jetzt einmal am Beispiel die Transformation der Datumsformate in den jeweiligen Daten anschauen. Je nach Datensatz müssen wir da mehr oder weniger machen. Auch hier, wenn du weniger Arbeit möchtest, dann achte auf eine einheitliche Form der Datumsangabe
Das R Paket {timetk} liefert dankenswerterweise Funktionen für die Konvertierung von verschiedenen Zeitformaten in R. Deshalb schaue einmal in die Hilfeseite Time Series Class Conversion – Between ts, xts, zoo, and tbl und dann dort speziell der Abschnitt Conversion Methods. Leider ist Zeit in R wirklich relativ.
Das Datum in den CSH-Daten leidet unter zwei Besonderheiten. Zum einen fehlt das Jahr und zum anderen die Null vor der Zahl. Wir haben nämlich für den 28. April die Datumsangabe 428 in der Spalte day. Das hat zur Folge, dass Excel die Spalte als Zahl erkennt und keine vorangestellten Nullen erlaubt. Wir brauchen aber einen String und den Monat als zweistellig mit 04 für den Monat April. Deshalb nutzen wir die Funktion str_pad() um eine 0 an die linke Seite zu kleben, wenn der Wert in der Spalte kleiner als vier Zeichen lang ist. Somit würde der 1. Oktober mit 1001 so bleiben, aber der 1. September mit 901 zu 0901. Dann nutzen wir die Funktion as.Date() um aus unserem Sting dann ein Datum zu machen. Das Format ist hier dann %m%d und somit Monat und Tag ohne ein Trennzeichen.
csh_tbl <- csh_tbl |>
mutate(day = as.Date(str_pad(day, 4, pad = "0", side = "left"), format = "%m%d"))Und dann erhalten wir auch schon folgenden Datensatz mit dem korrekten Datumsformat mit dem wir dann weiterarbeiten werden.
csh_tbl |>
head(4)# A tibble: 4 × 7
parzelle day g_tm_plot kg_tm_ha netto_csh_cm tm_gehlt day_num
<chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Wiese 2025-04-28 15.2 1148. 7.8 0.22 1
2 Wiese 2025-04-28 11.4 814. 8 0.21 1
3 Wiese 2025-04-28 24.7 1772. 9.3 0.21 1
4 Wiese 2025-04-28 20.9 1521. 8 0.23 1Wie du siehst, wird dann automatisch das aktuelle Jahr gesetzt. Das heißt, da ich dieses Text hier im Jahr 2025 schreibe, erscheint natürlich auch eine 2025 vor dem Monat und Tag. Hier musst du dann schauen, ob das Jahr wirklich von Interesse ist oder du es dann später nochmal anpasst. Wir lassen jetzt erstmal alles so stehen. Es ist immer einfacher das Datum dann sauber in Excel zu setzen, als sich dann hier nochmal einen Abzubrechen, denn du bist ja keine Informatiker der eine generelle Lösung sucht sondern hast ja nur einen Datensatz vorliegen. Das wäre jedenfalls mein Tipp um es schneller hinzukriegen.
Bei den Salatdaten haben wir ein anderes Problem vorliegen. Wir haben einmal eine Datumsspalte und dann noch eine Spalte mit der Uhrzeit. Da wir aber keine reine Uhrzeitspalte haben können, wurde noch das Datum 1899-12-31 als default ergänzt. Das macht natürlich so überhaupt keinen Sinn. Deshalb müssen wir dann einmal die Uhrzeit als korrektes Uhrzeit-Format umwandeln und dann die Spalte datum in ein Datum-Format. Dann können wir die beiden Spalten addieren und schon haben wir eine Datumsspalte mit der entsprechenden Uhrzeit.
salad_datetime_tbl <- salad_tbl |>
mutate(uhrzeit = format(uhrzeit, format = "%H:%M:%S"),
datum = format(datum, format = "%Y-%m-%d"),
datum = ymd(datum) + hms(uhrzeit)) |>
select(-uhrzeit) Im Folgenden siehst du einmal das Ergebnis unserer Umfaormung. Wir haben jetzt eine Spalte mit dem Datum und der Uhrzeit vorliegen, so wir das auch wollen und dann auch abbilden können.
salad_datetime_tbl |>
head(4)# A tibble: 4 × 4
datum freiland_messw freiland_min freiland_max
<dttm> <dbl> <dbl> <dbl>
1 2023-04-11 13:30:00 21.9 21.9 21.9
2 2023-04-11 14:00:00 18.8 18.8 22.5
3 2023-04-11 14:30:00 14.6 13.8 18.8
4 2023-04-11 15:00:00 13.2 13.2 15.6Da wir später noch für die Visualisierung die einzelnen Spalten freiland_messw bis freiland_max einmal darstellen wollen, bauen wir uns nochmal mit pivot_longer() einen entsprechenden Datensatz, der uns diese Art der Visualiserung dann auch möglich macht.
salad_long_tbl <- salad_datetime_tbl |>
pivot_longer(freiland_messw:last_col(),
names_sep = "_",
names_to = c("location", "type"),
values_to = "temp") Wie du nun siehst, haben wir nur noch eine Spalte temp mit unseren Messwerten der Temperatur. Der Rest an Informationen ist dann alles in anderen Spalten untergebracht. Mit diesem Datensatz können wir dann auch in {ggplot} gut arbeiten.
salad_long_tbl |>
head(4)# A tibble: 4 × 4
datum location type temp
<dttm> <chr> <chr> <dbl>
1 2023-04-11 13:30:00 freiland messw 21.9
2 2023-04-11 13:30:00 freiland min 21.9
3 2023-04-11 13:30:00 freiland max 21.9
4 2023-04-11 14:00:00 freiland messw 18.8Wie du aber auch schon hier siehst sind die Werte für den Messwert, den Minimalwert und den Maximalwert faktisch identisch. Diese geringe Abweichung werden wir dann auch nur schwerlich schön in einer Abbildung zeigen können. Ich würde dann die Min/Max-Werte rausschmeißen und mich nur auf die Messwerte in diesem Fall konzentrieren.
Zu guter Letzt noch die Daten zu der Wetterstation. Hier haben wir das Problem, dass wir dann aus der Spalte mit den Informationen zu dem Datum und der Zeit noch einzelne Informationen extrahieren wollen. Wir wollen die Stunde oder den Tag haben. Dafür nutzen wir nun Funktionen wie day() oder month() aus dem R Paket {lubridate} um uns diese Informationen zu extrahieren. Wir können uns so auch die Uhrzeit wieder zusammenbauen, indem wir die Stunde, Minute und dann die Sekunden herausziehen.
station_tbl <- station_tbl |>
mutate(datum_uhrzeit = as_datetime(datum_uhrzeit),
month = month(datum_uhrzeit),
day = day(datum_uhrzeit),
hour = hour(datum_uhrzeit),
minute = minute(datum_uhrzeit),
second = second(datum_uhrzeit),
format_hour = paste(hour, minute, second, sep = ":"))Damit haben wir auch den letzten Datensatz so umgebaut, dass wir eine Spalte haben in der das Datum sauber kodiert ist. Sonst macht ja eine Zeitreihe keinen Sinn, wenn die Zeit nicht stimmt. Damit können wir uns dann auch der Visualisierung der Wetterstationsdaten zuwenden.
Wie auch bei anderen Analysen ist die Visualisierung von Zeitreihen das Wichtigste. Da wir im Besonderen bei Zeitreihen eben meistens keine Verläufe nur in den reinen Daten sehen können. Wir haben einfach zu viele Datenpunkte vorliegen. Meistens hilft uns dann auch eine Darstellung aller Datenpunkte auch nicht weiter, so dass wir uns entscheiden eine Glättung (eng. smoother) durchzuführen, damit wir überhaupt etwas sehen. Daher gehen wir hier einmal verschiedene Probleme an den Datensätzen durch. Vorab stelle ich dann aber nochmal das R Paket {plotly} vor, was es ermöglicht semi-interaktive Abbildungen zu erstellen. Wir haben mit {plotly} die Möglichkeit direkt Werte für die Punkte abzulesen. Das können wir mit einer fixen Abbildung in {ggplot} nicht. Mehr findest du auch auf der Seite von R Coder - Evolution charts.
{plotly}Das R Paket {plotly} erlaubt interaktive Abbildungen zu erstellen. Zwar ist die Interaktivität nicht so ausgeprägt wie bei einer R Shiny App, aber wir haben hier auf jeden Fall die Möglichkeit in die Abbildung hineinzuzoomen oder aber Werte direkt aus der Abbildung abzulesen. Die beiden Möglichkeiten sind insbesondere bei sehr langen Zeitreihen oder aber bei vielen verschiedenen Zeitreihen in einer Abbildung super hilfreich. Wie bauen wir uns nun eine Abbildung in {plotly}? Ich nutze dafür die Funktion ggplotly(), die aus einer {ggplot} Abbildung dann ganz einfach eine {plotly} Abbildung baut. Du musst natürlich schauen, dass die {ggplot} Abbildung nicht zu komplex wird. Nicht alles was in {ggplot} möglich ist, lässt sich dann Eins zu Eins dann in {plotly} reproduzieren. Auf jeden Fall hilft wie immer die Hilfeseite {plotly} R Open Source Graphing Library sowie im besonderen dann die Seite Getting Started with {plotly} in {ggplot2}. Im Folgenden werde ich einzelne Abbildungen in {plotly} umwandeln und dann einmal erklären, was du so machen kannst. Aber eigentlich ist eine {plotly} Abbildung selbsterklärend, klicke einfach mal auf der Abbildung 71.9 zu dem Salat herum.
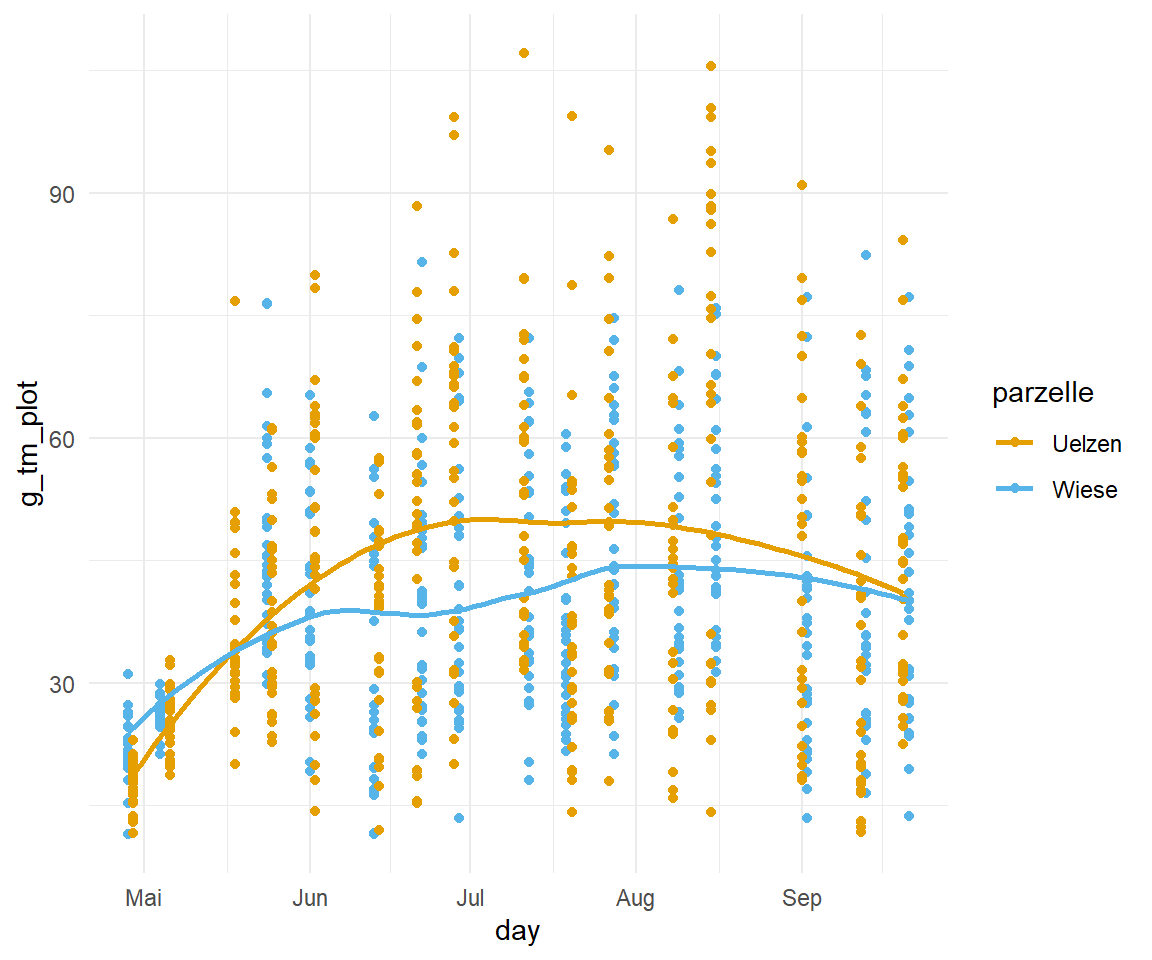
Die CSH-Daten stellen ja die Messung eines Dronenüberflugs von zwei Parzellen einmal in Uelzen und einer Kontrollparzelle dar. In der Abbildung 71.7 (a) siehst du einmal die beobachteten g_tm_plot-Werte für jeden der Messtage getrennt nach Parzelle aufgetragen. Hier sieht man auf den ersten Blick keine Unterschied. Deshalb hilft es immer einmal eine geglättete Funktion durch die Punkte zu legen. Wir nutzen dazu die Funktion geom_smooth() und erhalten die Abbildung 71.7 (b). Hier sehen wir schon, dass es einen Unterschied zwischen den beiden Parzellen gibt. Wir sind also nicht an den einzelnen Punkten interessiert sondern eigentlich an der Differenz zwischen den beiden Geraden. Wir wollen also die Fläche zwischen den beiden Linien berechnen und so feststellen wie groß der Unterschied zwischen den Messungen an den beiden Parzellen ist.
csh_tbl |>
ggplot(aes(day, g_tm_plot, color = parzelle)) +
theme_minimal() +
geom_point() +
scale_color_okabeito()
csh_tbl |>
ggplot(aes(day, g_tm_plot, color = parzelle)) +
theme_minimal() +
geom_point() +
stat_smooth(se = FALSE) +
scale_color_okabeito() 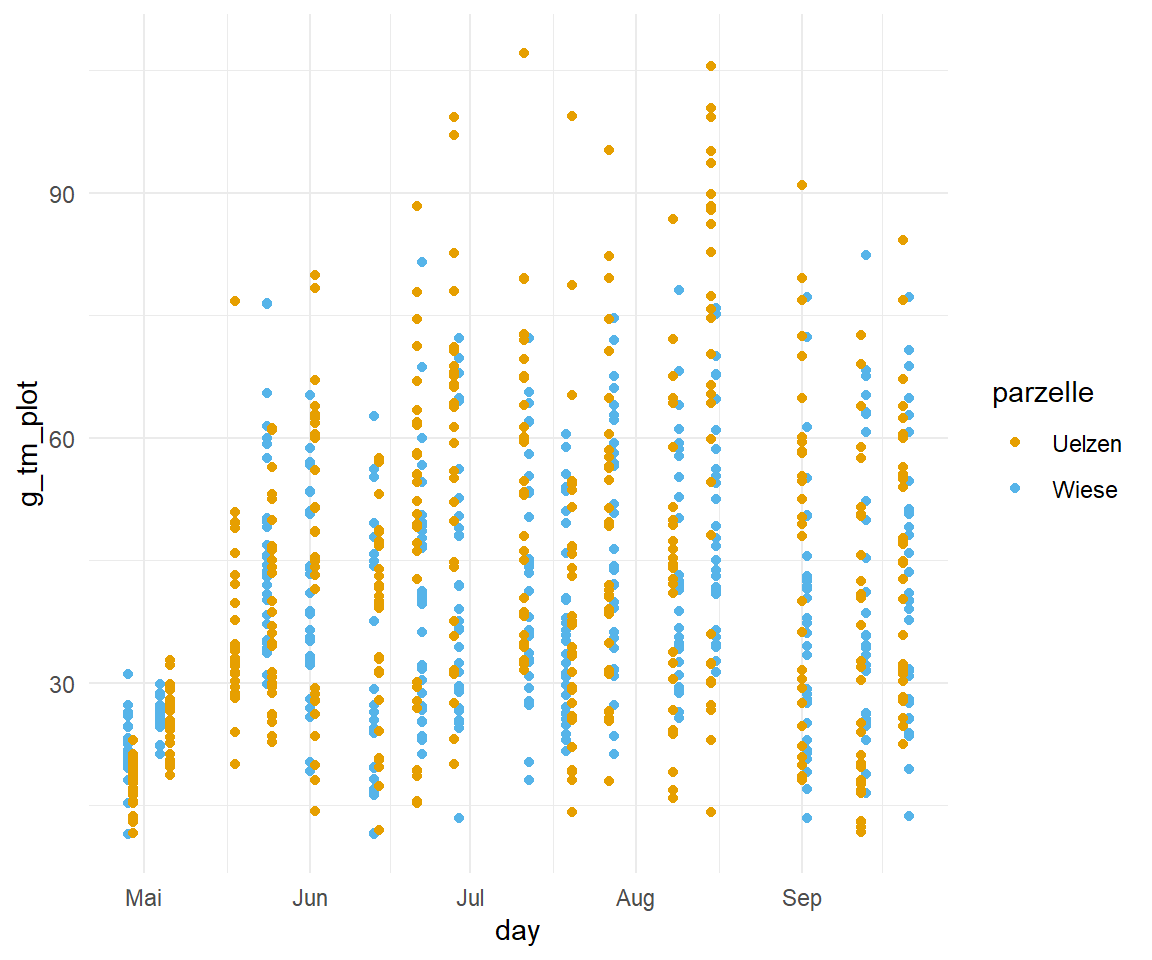
stat_smooth-Funktion
g_tm_plot-Werte in Abhängigkeit von dem Tag der Messung für die beiden Parzellen einmal in Uelzen und der Kontrollwiese. Ein Unterschied lsäät sich nur durch die Anpassung der beiden Linien durch die Punkte erkennen.
In dem nächsten Abschnitt wollen wir dann einmal die Fläche zwischen den Linien bestimmen und schauen, ob wir hier wirklich einen Unterschied vorliegen haben. Wenn du mehr Linien oder Gruppen hast, dann musst du dann immer die Fläche zwischen zwei Linien berechnen bist du alle Kombinationen durch hast.
Die Salatdaten schauen wir uns jetzt einmal in der Abbildung 71.8 als statische Abbildungen in {ggplot} an. Besonders in der Abbildung 71.8 (a) siehtst du dann wegen den geringen Unterschieden der Temperaturen fast nichts auf der Abbildung. Dafür hilft es dann auch in der Abbildung 71.8 (b) einmal die Temperaturen aufzuteilen. Jetzt haben wir alle Temperaturen einmal als Vergleich vorliegen. Aber auch hier können wir schlecht die Werte an einem Datum ablesen und direkt vergleichen. Hier hilft dann gleich {plotly} weiter.
p_loc <- salad_long_tbl |>
ggplot(aes(datum, temp, color = type)) +
theme_minimal() +
scale_color_okabeito() +
geom_line() +
facet_wrap(~ location) +
theme(legend.position = "none")
p_loc
p_type <- salad_long_tbl |>
ggplot(aes(datum, temp, color = type)) +
theme_minimal() +
scale_color_okabeito() +
geom_line() +
facet_wrap(~ type, ncol = 1) +
theme(legend.position = "none")
p_type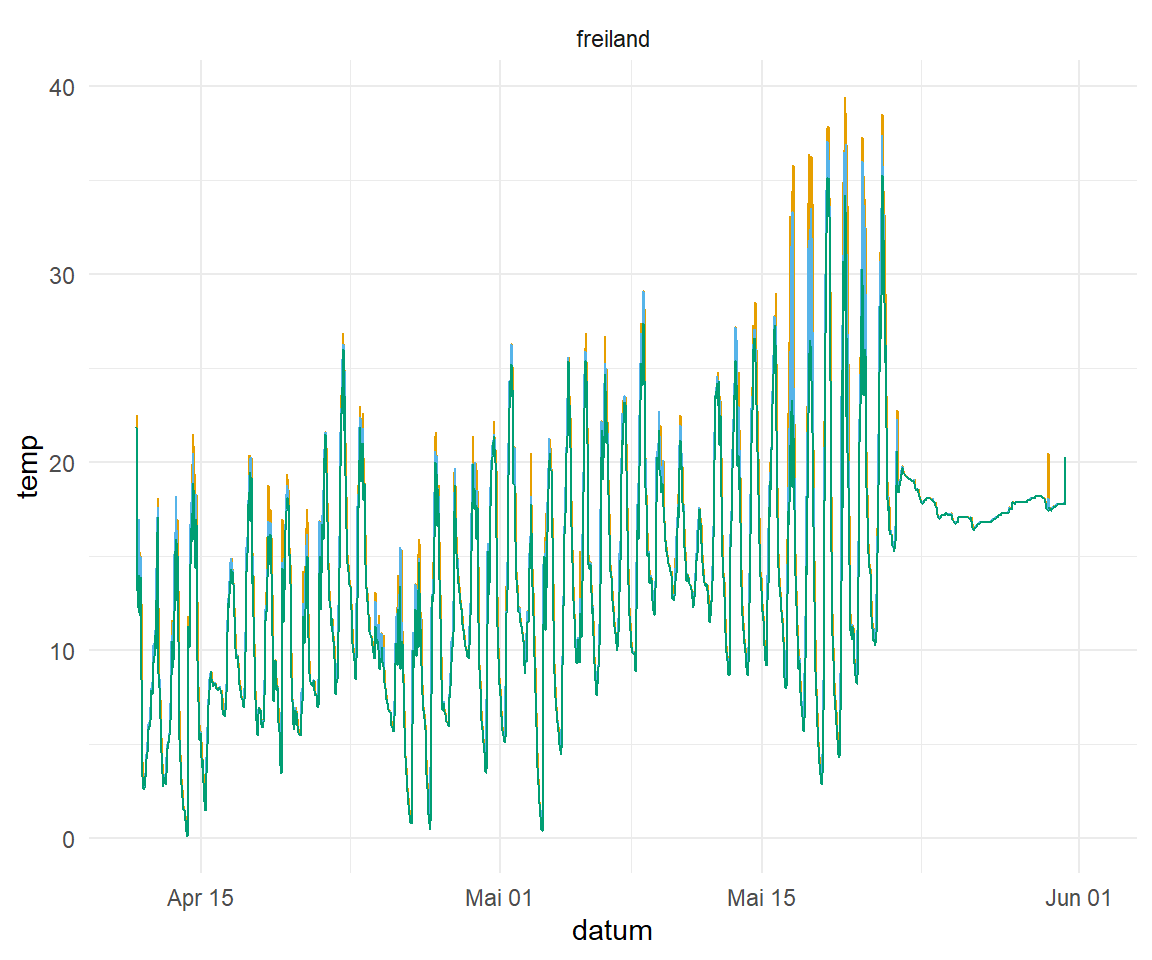
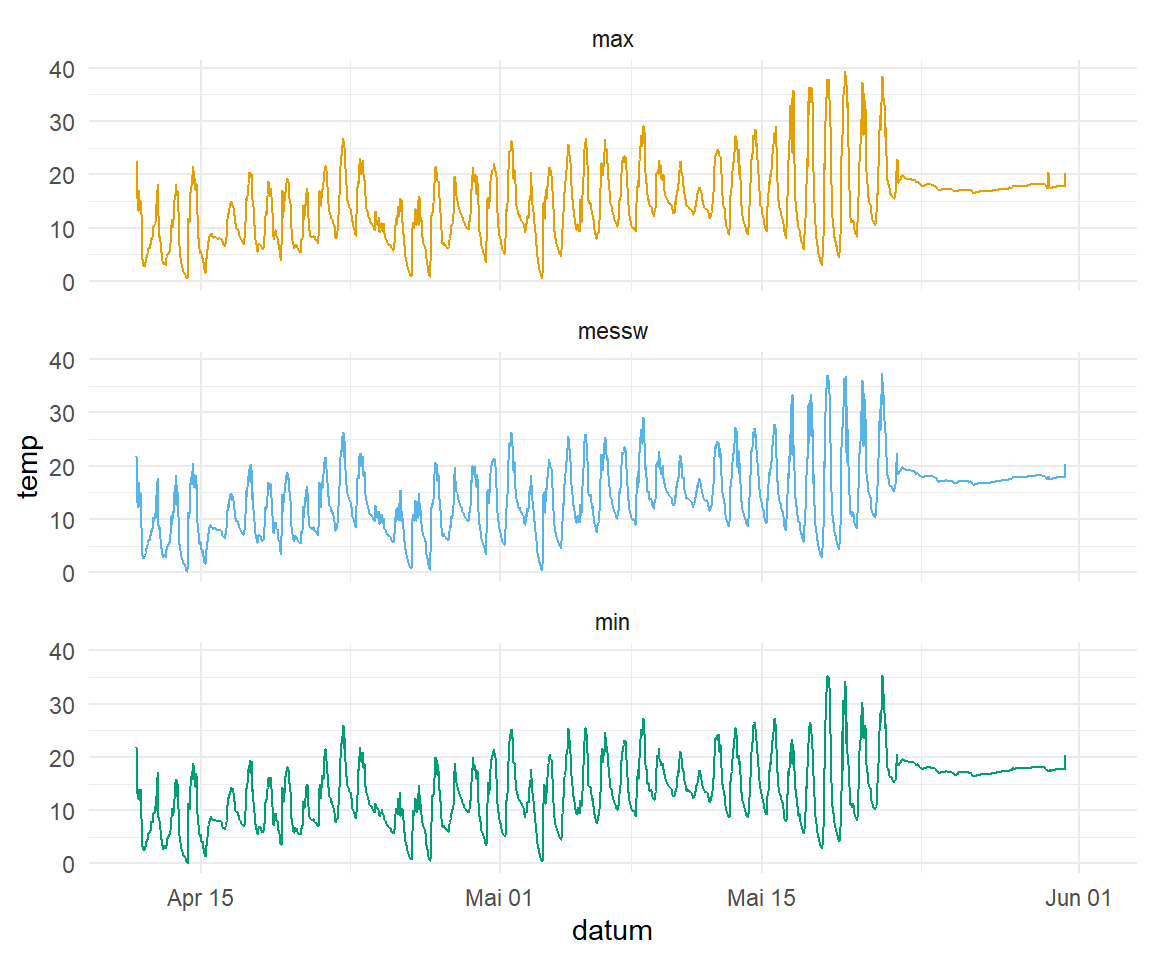
{ggplot} sehr schwer ist.
In der Abbildung 71.9 siehst du einmal die Version der ersten Abbildung in {plotly} dargestellt. Auf den ersten Blick ist alles gleich und auch wenn du die Abbildung ausdruckst oder in Word einfügst, wirst du nichts großartig anders machen können. Als Webseite oder im RStudio geht dann mehr. Du kannst jetzt mit der Maus über die Abbildung gleiten und dann werden dir die Werte an dem jeweiligen Punkt angezeigt. Das tolle ist, dass wir mit der Funktion ggplotly() viele Abbildungen aus {ggplot} direkt als {plotly} Abbildung wiedergeben lassen können. Wie immer gilt auch hier, dass die Hilfeseite Getting Started with {plotly} in ggplot2 einem enorm weiterhilft.
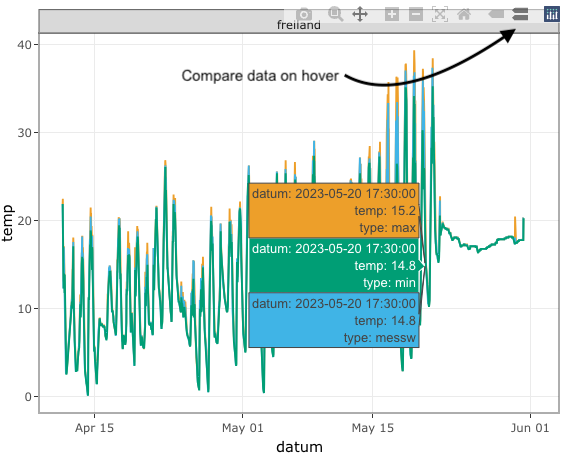
ggplotly(p_loc){plotly}. Einzelne Werte können jetzt angezeigt werden und somit auch verglichen werden. Besonders der Button Compare data on hover ist hier sehr nützlich.
In der Abbildung 71.10 siehst du nochmal den Button Compare data on hover in Aktion. Du kannst dann direkt die drei Punkte miteinander vergleichen auch wenn die Punkte in der Abbildung schlecht auseinander zu halten sind. Wir können uns dann damit die Werte auf der \(y\)-Achse für jeden Zeitpunkt anzeigen lassen. Das “Hovern” über die Werte macht die visuelle Auswertung sehr viel einfacher als eine statische Abbildung.
Die Wetterstationsdaten können wir uns natürlich aucb so anschauen wie die Daten aus den Loggern bei den Salatdaten. Das habe ich dann auch einmal in der Abbildung 71.11 gemacht. Wir sehen in der Abbildung den Temperaturverlauf von April bis Ende Oktober. Das Problem ist auch wieder hier, dass wir einzelne Werte für ein Datum sehr schlecht ablesen können. Auch hier hilft dann {plotly} weiter, da können wir dann schön die Werte ablesen. Das Ziel ist es hier aber nicht eine einfache Scatterabbildung zu bauen sondern gleich nochmal ein 2D Konturplot. Aber fangen wir erstmal mit der Übersicht an.
p <- station_tbl |>
ggplot(aes(datum_uhrzeit, temp_boden_durch)) +
theme_minimal() +
geom_line()
p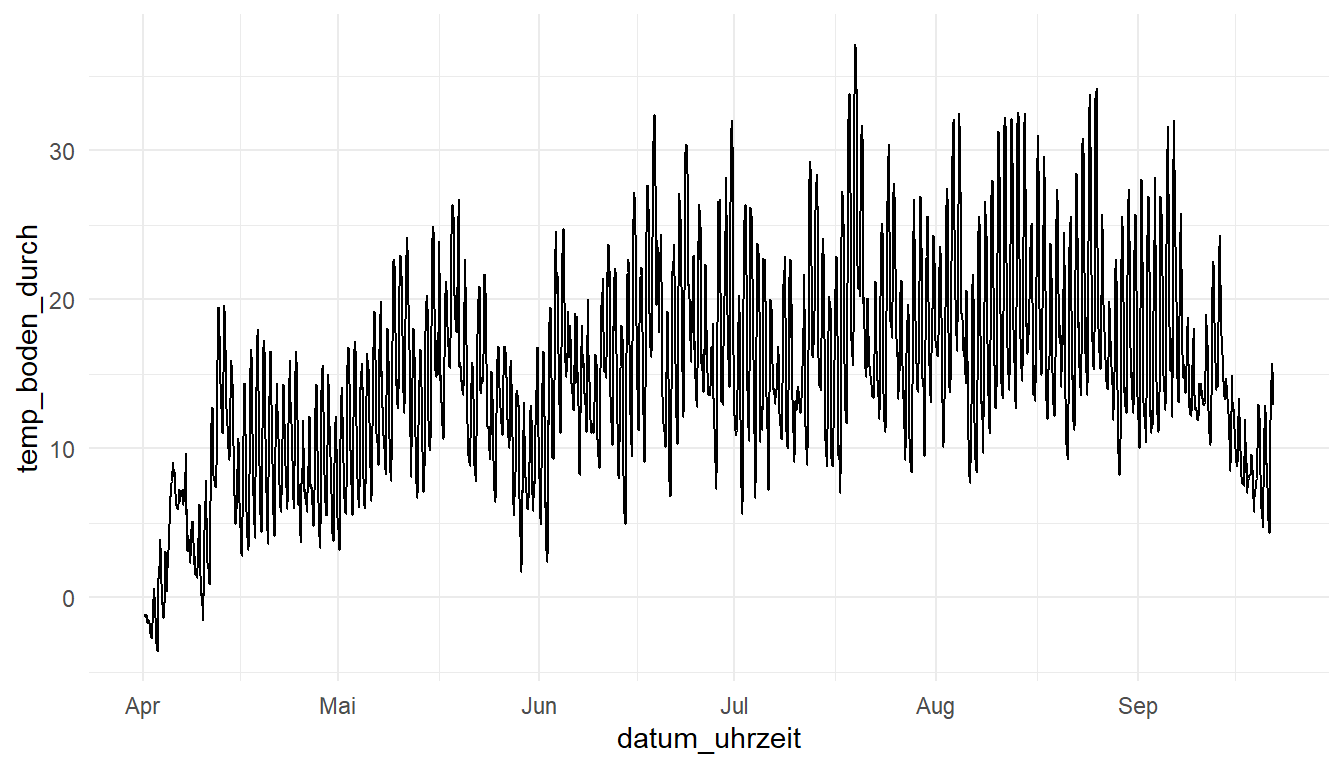
Dann können wir natürlich auch wieder unsere statische Abbildung einmal in {plotly} umwandeln und uns die einzelnen Werte anschauen. Wir haben hier aber eher weniger Informationen, da der lineare Ablauf doch recht schwer über die Monate zu vergleichen ist. Viel besser wären da die Tage für jeden Monat nebeneinander. Oder aber wir schauen uns einmal die Temperatur für jeden Tag an. Wir haben ja auch die Uhrzeiten vorliegen.
ggplotly(p){plotly}. Einzelne Werte können jetzt angezeigt werden und somit auch verglichen werden.
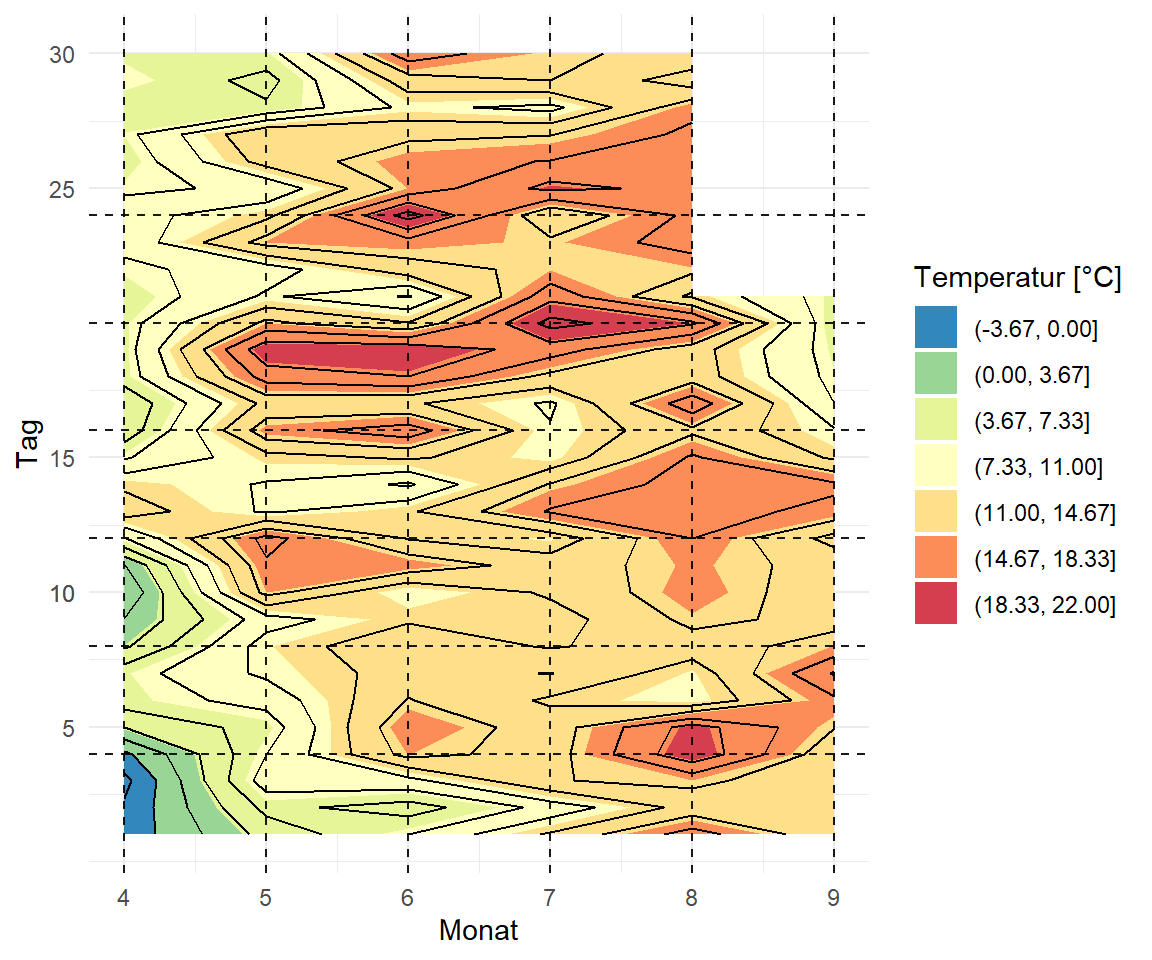
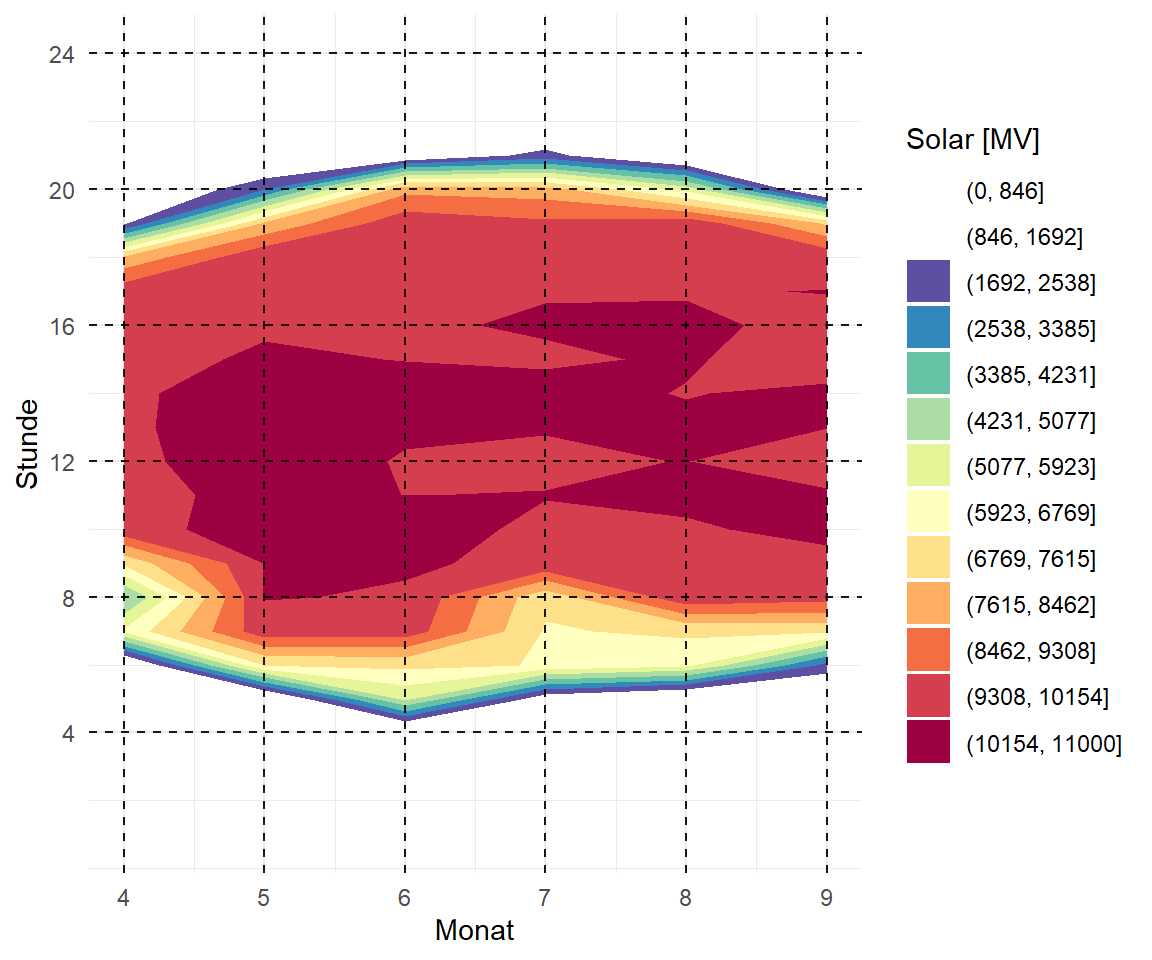
Wir können uns jetzt in Abbildung 71.13 die drei Konturplots ansehen. Wichtig ist natürlich hier, dass wir vorher die Tage und den Monat aus dem Datum extrahiert haben. Jetzt geht es aber los mit dem Bauen der Konturplots. Wir mussten noch das Spektrum der Farben einmal drehen, damit es auch mit den Temperaturfarben passt und wir haben noch ein paar Hilfslinien mit eingezeichnet. Sie dazu auch meine Auswertung zum Isoplethendiagramm für Münster & Osnabrück im Skript zu beispielhaften Anwendung als ein anderes Beispiel mit DWD Daten. Wenn du die Daten aus deiner Region runterlädst, kannst du dir auch ähnliche Abbildungen bauen.
Im Folgenden spiele ich mit den Funktionen geom_contour_filled() und geom_contour() rum um zum einen die Flächen und dann die Ränder des Isoplethendiagramms zu erhalten. Die Färbung ergibt sich dann aus der Funktion scale_fill_brewer(). Da wir hier exakt dreizehn Farben zu Verfügung haben, habe ich dann auch entschieden dreizehn Konturen zu zeichnen. Sonst musst du mehr Farben definieren, damit du auch mehr Flächen einfärben kannst. Teilweise musst du hier etwas mit den Optionen spielen, bis du bei deinen Daten dann eine gute Einteilung der Farben gefunden hast. Hier helfen dir dann die Optionen binwidth und bins weiter. Darüber hinaus habe ich mich auch entschieden hier mit einem Template in {ggplot} zu arbeiten, damit ich nicht so viel Code produziere. Ich baue mir im Prinzip einmal einen leeren Plot ohne die Funktion aes(). Die Definition was auf die \(x\)-Achse kommt und was auf die \(y\)-Achse mache ich dann später.
p <- ggplot(station_tbl) +
theme_minimal() +
geom_contour_filled(bins = 13) +
scale_fill_brewer(palette = "Spectral", direction = -1) +
scale_x_continuous(breaks = 1:12) +
geom_vline(xintercept = 4:9, alpha = 0.9, linetype = 2) +
geom_hline(yintercept = c(4, 8, 12, 16, 20, 24),
alpha = 0.9, linetype = 2) +
labs(x = "Monat", y = "Stunde", fill = "Temperatur [°C]")Wir können mit dem Operator %+% zu einem bestehenden {ggplot} neue Daten hinzufügen. Dann können wir auch wie gewohnt neue Optionen anpassen. Deshalb dann einmal das Template zusammen mit der Temperatur als Kontur aufgeteilt nach Monat und Stunde sowie Monat und Tag. Dann habe ich mir noch die Leistung der Sonne über den Monat und der Stunde anzeigen lassen. Je nach Fragestellung kommt es dann eben auf die Abbildung drauf an. Bei Zeitreihen haben wir mit dem Konturplot noch eine weitere Möglichkeit Daten spannend und aufschlussreich darzustellen.
p %+%
aes(month, hour, z = temp_boden_durch) +
geom_contour(binwidth = 2, color = "black") +
scale_y_continuous(limits = c(1, 24), breaks = c(4, 8, 12, 16, 20, 24)) +
labs(x = "Monat", y = "Stunde", fill = "Temperatur [°C]")
p %+%
aes(month, day, z = temp_boden_durch) +
geom_contour(binwidth = 2, color = "black") +
scale_y_continuous(limits = c(1, 30), breaks = c(5, 10, 15, 10, 25, 30)) +
labs(x = "Monat", y = "Tag", fill = "Temperatur [°C]")
p %+%
aes(month, hour, z = solar_mv) +
scale_y_continuous(limits = c(1, 24), breaks = c(4, 8, 12, 16, 20, 24)) +
labs(x = "Monat", y = "Stunde", fill = "Solar [MV]")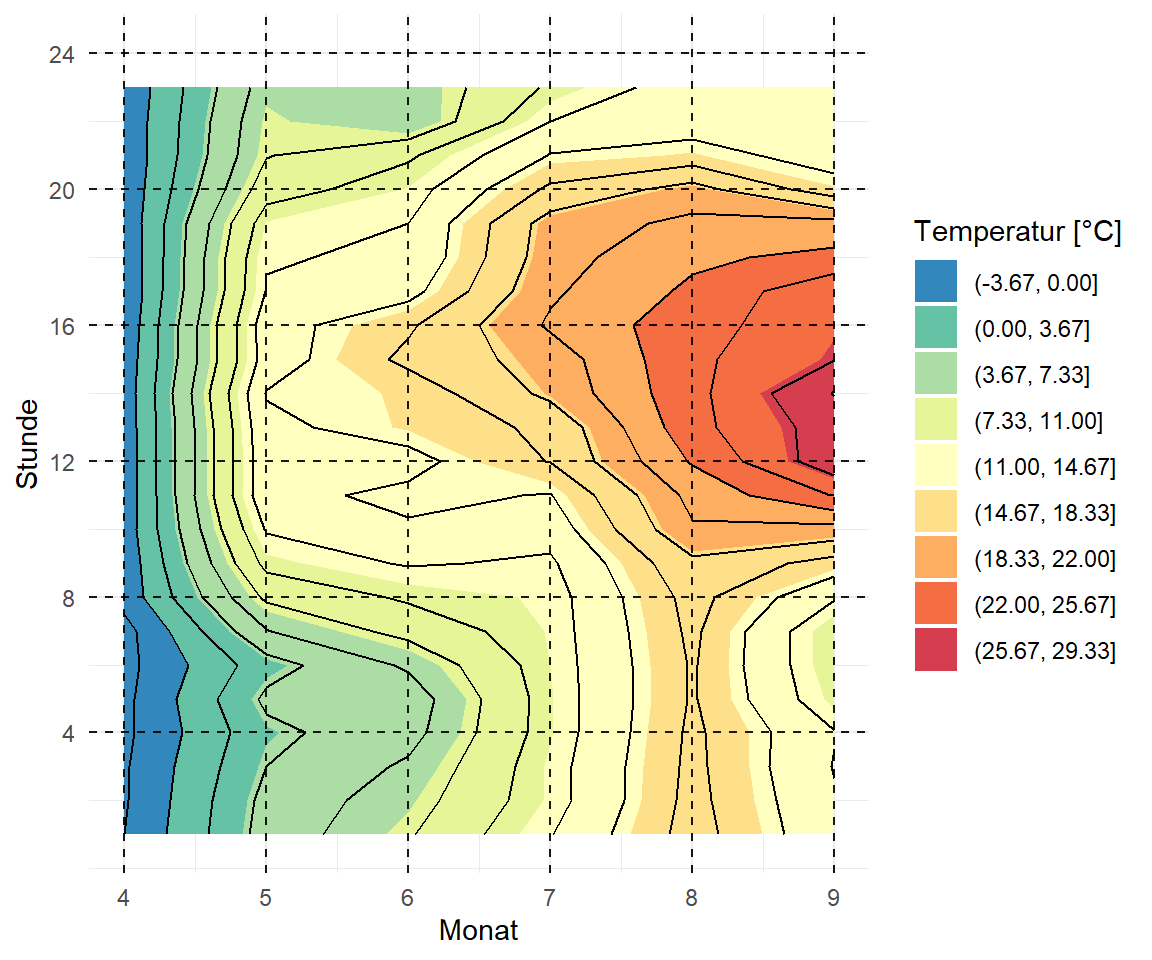
Bis jetzt haben wir uns die Visualisierung von Zeitreihen angeschaut. Häufig reicht die Visualisierung auch aus, wenn es um die Darstellung von Temperaturverläufen in einer Abschlussarbeit geht. Darüber hinaus wollen wir dann aber doch irgendwie eine statistische Analyse auf der Zeitreihe rechnen. Deshalb habe ich hier mal angefangen Beispiele zu Auswertungen von “pseudo” Zeitreihen zu sammeln und vorzustellen. Hauptsächlich nehme ich natürlich die drei Datensätze von weiter oben im Kapitel. Da die drei Datensätze zwar echte Daten aus dem agrarwissenschaftlichen Kontext repräsentieren, genügen die Datensätze dann doch nicht immer einer klassischen Zeitreihenanalyse.
Fangen wir also einmal mit eine einfachen Glättung an. Wir schauen uns hier als erstes die Standardvariante in R an. Ich zeige dir verschiedene Beispiele für die Glättung von Zeitreihen durch Mittelwert, Median oder aber auch der Summe. Du könntest auch stat_smooth() aus {ggplot} verwenden, aber hier zeige ich dir noch ein paar differenzierte Möglichkeiten. Das heißt, wir nehmen hier die einfachen Funktionen, die in R implementiert sind und rechnen damit eine Zeitreihenanalyse. Damit haben wir dann einige Nachteile, da wir uns die Funktionen dann eventuell nochmal aus Paketen zusammensuchen müssen. Dafür ist es aber schön kleinteilig und du kannst die Analysen Schritt für Schritt durchführen. Wenn dir das zu kleinteilig oder aber veraltet ist, dann schaue gleich weiter unten in den Abschnitten zu den R Paketen {tktime} und {modeltime} nach. Beide Pakete sind die Antwort auf eine Analyse von Zeitreihen im {tidyverse}.
Das R Paket {timetk} liefert dankenswerterweise Funktionen für die Konvertierung von verschiedenen Zeitformaten in R. Deshalb schaue einmal in die Hilfeseite Time Series Class Conversion – Between ts, xts, zoo, and tbl und dann dort speziell der Abschnitt Conversion Methods. Leider ist Zeit in R wirklich relativ.
Leider ist das Zeitformat ts etwas quälend. Dennoch basieren viele Tutorien auf diesem Format, deshalb hier auch einmal die Erklärung dafür. Es ist aber auch verständlich, denn das Format ist sozusagen der eingebaute Standard in R. Standard heißt hier aber nicht toll, sondern eher veraltet aus den 90zigern. Dann gibt es mit dem R Paket {zoo} noch ein Palette an nützlichen Funktionen, wenn du nicht so viel machen willst. Mit so viel meine ich, dass du eher an einem rollenden Mittelwert oder aber der rollenden Summe interessiert bist. Dann macht das R Paket {zoo} sehr viel Sinn. Einen Überblick liefert hier auch das Tutorium Reading Time Series Data.
Wenn wir viele Datenpunkte über die Zeit messen, dann hilft es manchmal die Spitzen und Täler aus den Daten durch eine rollende statistische Maßzahl zusammenzufassen. Das R Paket {zoo} hat die Funktion rollmean() sowie rollmax() und rollsum(). Es gibt aber noch eine Reihe weiterer Funktionen. Du musst hier einfach mal die Hilfeseite ?rollmean() für mehr Informationen aufrufen. Mit den Funktionen können wir für ein Zeitintervall \(k\) den Mittelwert bzw. der anderen Maßzahlen berechnen. In unserem Fall habe ich einmal das rollende Monatsintervall genommen. Du kannst aber auch andere Zeiten für \(k\) einsetzen und überlegen welcher Wert besser zu deinen Daten passt. Hier einmal die Berechnung für das rollende Mittel, das rollende Maximum und die rollende Summe. In allen drei Fällen nutzen wir die Funktion split() und map() um effizient unseren Code auszuführen.
roll_mean_tbl <- salad_long_tbl |>
split(~type) |>
map(~zoo(.x$temp, .x$datum)) |>
map(~rollmean(.x, k = 29)) |>
map(tk_tbl) |>
bind_rows(.id = "type")roll_max_tbl <- salad_long_tbl |>
split(~type) |>
map(~zoo(.x$temp, .x$datum)) |>
map(~rollmax(.x, k = 29)) |>
map(tk_tbl) |>
bind_rows(.id = "type")roll_sum_tbl <- salad_long_tbl |>
split(~type) |>
map(~zoo(.x$temp, .x$datum)) |>
map(~rollsum(.x, k = 29)) |>
map(tk_tbl) |>
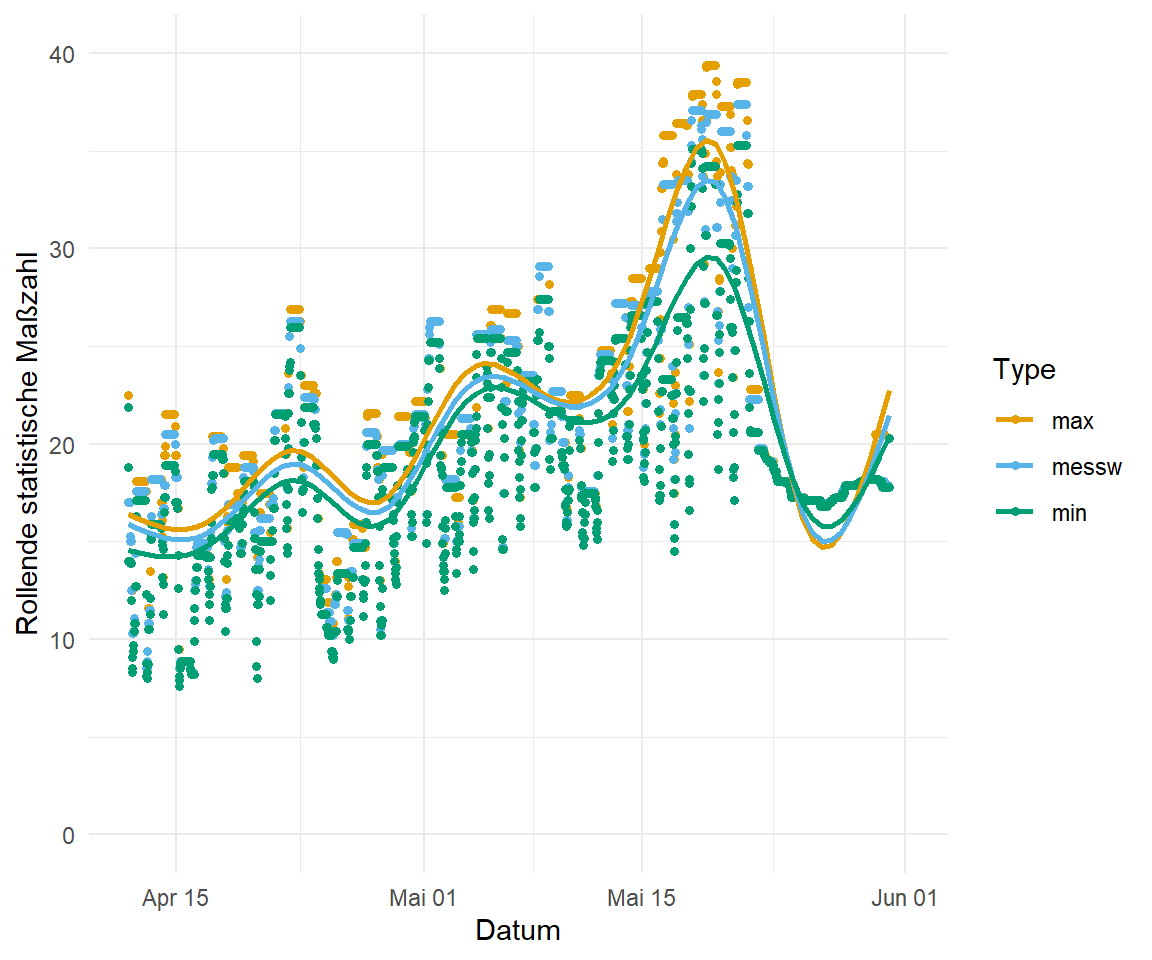
bind_rows(.id = "type")In der Abbildung 71.14 siehst du einmal das Ergebnis der drei rollenden Maßzahlen. Im Folgenden habe ich zuerst das Template p_temp erstellt und dann über den Operator %+% die Datensätze zum rollenden Mittelwert, zu dem rollenden Maximum und der rollenden Summe ersetzt. Die rollende Summe habe ich noch auf der \(\log\)-transformierten \(y\)-Achse dargestellt.
p_temp <- ggplot() +
aes(index, value, color = type) +
theme_minimal() +
geom_point2() +
stat_smooth(se = FALSE) +
labs(x = "Datum", y = "Rollende statistische Maßzahl",
color = "Type") +
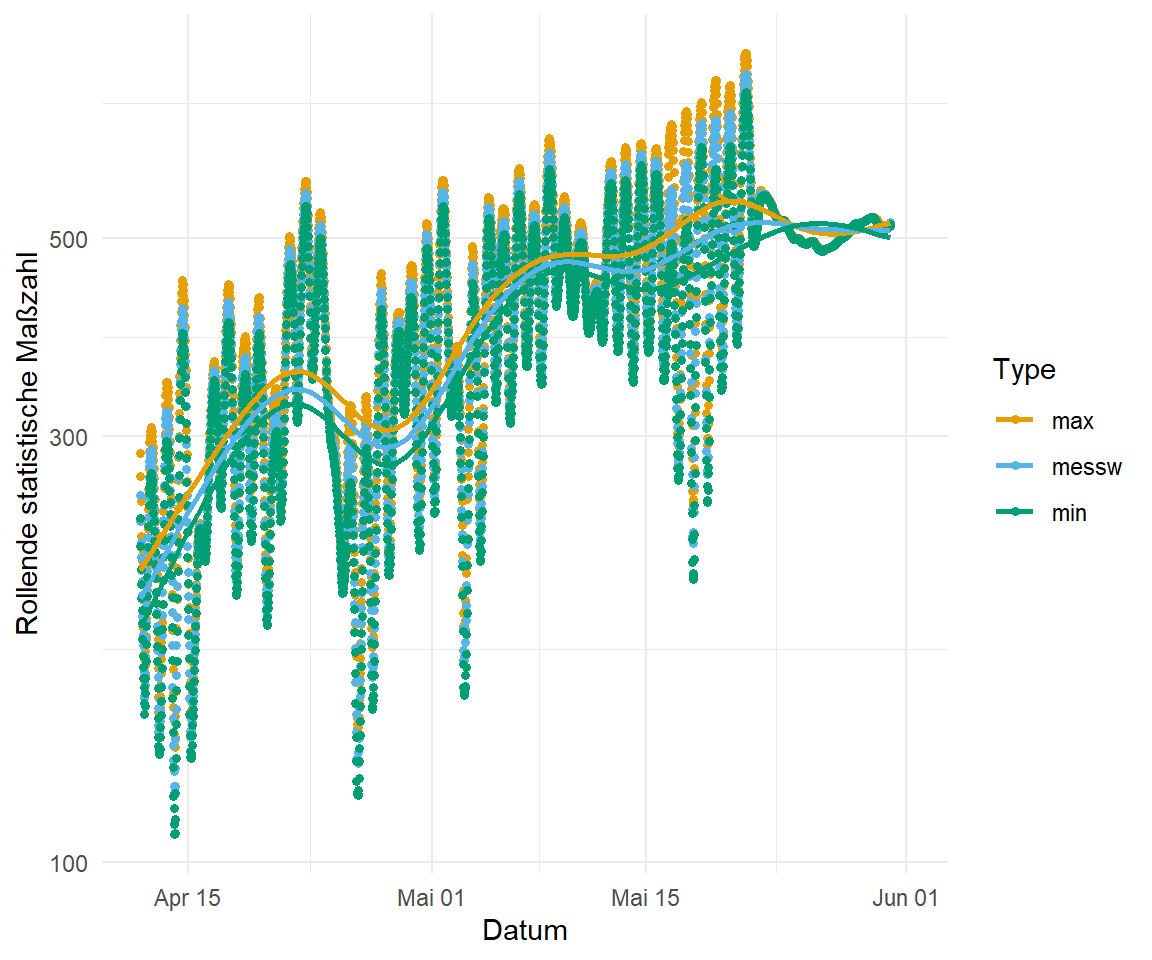
scale_color_okabeito() Wir sehen in der folgenden Abbildung, dass sich die Messtypen dann doch nicht so stark in durch die rollenden Maßzahlen unterscheiden. Wir haben ja schon in der Orginalabbildung das Problem gehabt, dass sich die Werte sehr stark ähneln. Das scheint auch über 29 Tage der Fall zu ein. Was man besser sieht, ist das wellenförmige Ansteigen der Temperatur über die gemessene Zeit. Wir hatten also immer mal wieder etwas kältere Phasen, die von wärmeren Phasen abgelöst wurden.
p_temp %+%
roll_mean_tbl +
ylim(0, 40)
p_temp %+%
roll_max_tbl +
ylim(0, 40)
p_temp %+%
roll_sum_tbl +
scale_y_log10()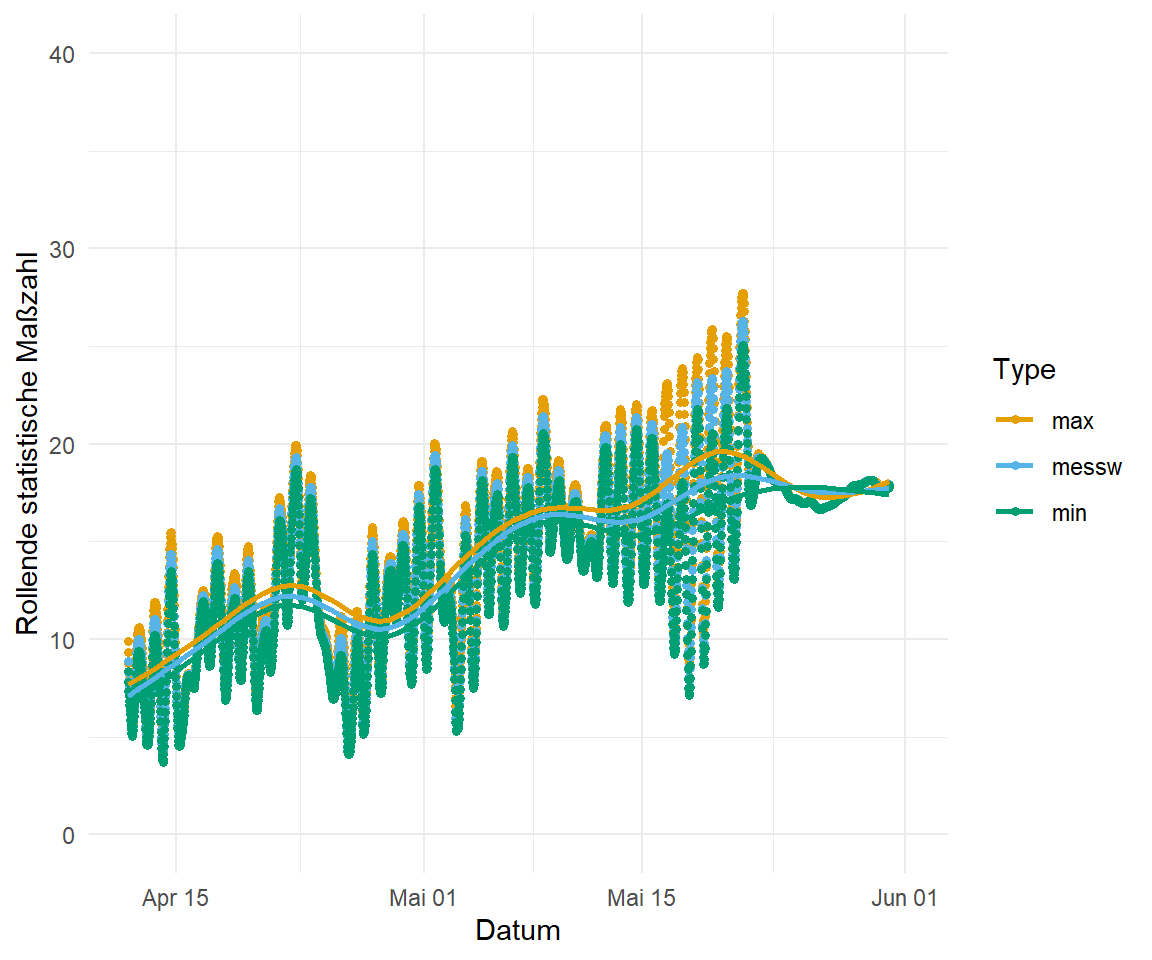
Unsere Dronenüberflugdaten sind etwas besondere Daten, wenn wir uns Zeitreihen anschauen. Wir haben zwar auch einen zeitlichen Verlauf auf der \(x\)-Achse, aber der Zeitrahmen ist mit unter einem Jahr zu klein um einen zyklischen Verlauf zu beobachten. Wir wollen hier auch etwas anderes erreichen. Uns interessieren die einzelnen Beobachtungen nicht, wir wollen die angepasste Graden durch die Punktewolken vergleichen. In der Abbildung 71.15 siehst du nochmal die angepassten Kurven ohne die einzelnen Messpunkte. Eigentlich rechnen wir hier einen Gruppenvergleich über die Zeit. Spannende Sache, die wollen wir uns dann mal genauer ansehen. Wir werden hier aber keinen statistischen Test rechnen, sondern nur ausrechnen in wie weit sich die beiden Parzellen numerisch im Ertrag unterscheiden.
csh_tbl |>
ggplot(aes(day, g_tm_plot, color = parzelle)) +
theme_minimal() +
geom_point(alpha = 0.4) +
stat_smooth(se = FALSE) +
scale_color_okabeito() 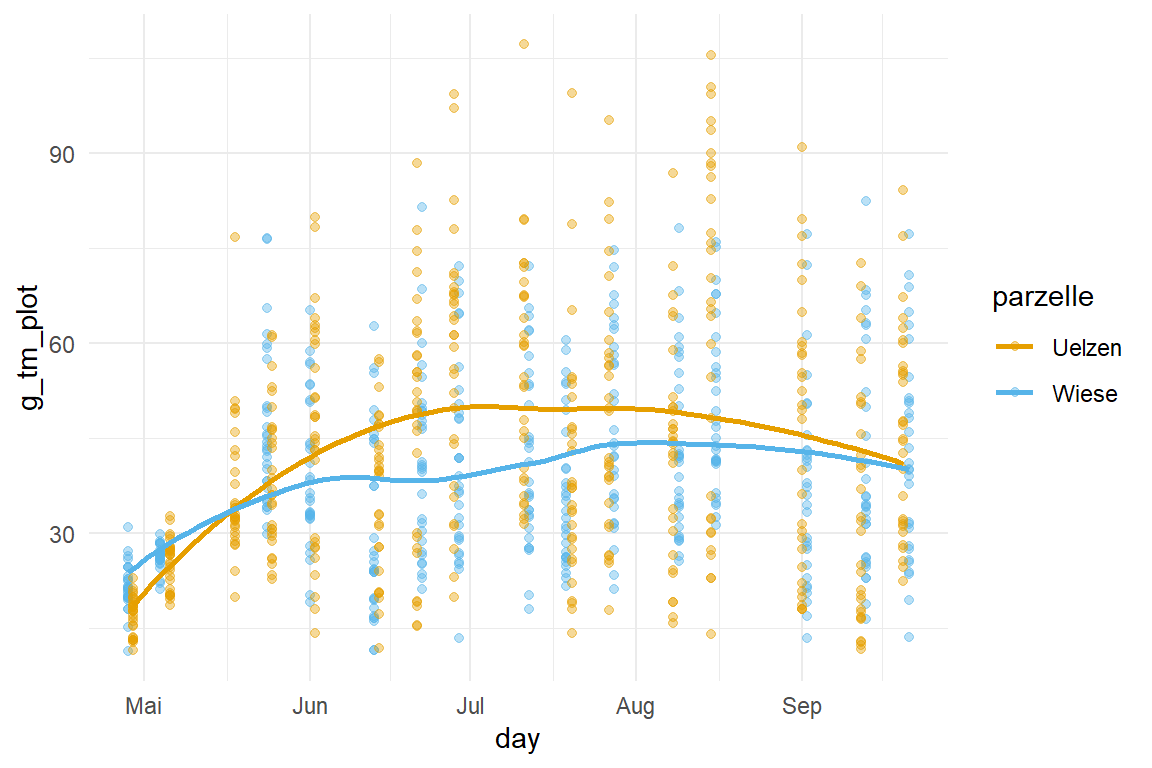
Gibt es also einen Unterschied zwischen den beiden Parzellen \(Uelzen\) und \(Wiese\) im Bezug auf den Ertrag? Dafür müssen wir die Differenz der Graden an jedem Punkt berechnen. Oder anders formuliert, wir wollen die Fläche zwischen den beiden Kurven berechnen. Um die Fläche zu berechnen, brauchen wir die Koordinaten, die die Kurven beschreiben. Wir machen uns es hier aber etwas einfacher und berechnen die Kurven nochmal separat mit der Funktion gam() aus dem R Paket {mgcv}. In beiden Tabs sehen wir dann jeweils die Modellanpassungen für die beiden Parzellen in Uelzen und auf der Wiese.
Wenn du ein GAM rechnest, dann musst du auf jeden Fall, die Variable, die auf der \(x\)-Achse ist nochmal in ein s() packen, damit hier auch ein Spline bzw. eine Glättung mit der Variable gerechnet wird.
gam_uelzen_fit <- csh_tbl |>
filter(parzelle == "Uelzen") |>
gam(g_tm_plot ~ s(day_num), data = _)
gam_uelzen_fit
Family: gaussian
Link function: identity
Formula:
g_tm_plot ~ s(day_num)
Estimated degrees of freedom:
8.56 total = 9.56
GCV score: 311.7048 Das Ergebnis ist relativ nichts sagend für uns, wir nutzen jetzt gleich den Fit um die Fläche unter der Kurve zu berechnen. Der GCV score ist in etwa ein AIC-Wert. Damit sind Modelle mit kleineren GCV-Werten zu bevorzugen.
Wenn du ein GAM rechnest, dann musst du auf jeden Fall, die Variable, die auf der \(x\)-Achse ist nochmal in ein s() packen, damit hier auch ein Spline bzw. eine Glättung mit der Variable gerechnet wird.
gam_wiese_fit <- csh_tbl |>
filter(parzelle == "Wiese") |>
gam(g_tm_plot ~ s(day_num), data = _)
gam_wiese_fit
Family: gaussian
Link function: identity
Formula:
g_tm_plot ~ s(day_num)
Estimated degrees of freedom:
8.61 total = 9.61
GCV score: 190.3596 Das Ergebnis ist relativ nichts sagend für uns, wir nutzen jetzt gleich den Fit um die Fläche unter der Kurve zu berechnen. Der GCV score ist in etwa ein AIC-Wert. Damit sind Modelle mit kleineren GCV-Werten zu bevorzugen.
Dann können wir schon über die Funktion integrate() die Fläche unter der Kurve (eng. area under the curve, abk. AUC) berechnen. Dafür brauchen wir dann einmal die Funktion der Kurve, die wir uns mit predict() generieren. Dann wollen wir noch den ersten bis zum letzten Zeitpunkt integrieren. Da wir dann einunddreißig Messzeitpunkte haben, integrieren wir von Eins bis Einunddreißig. Ich mache dann beides einmal in den folgenden Tabs. Hier musst du manchmal etwas frickeln, bist du die Anzahl deiner Messtage weißt. Ich muss ja immer schauen, denn ich habe das Experiment ja nicht gemacht.
f_uelzen_gam <- function(x) predict(gam_uelzen_fit, tibble(day_num = x))
integrate(f_uelzen_gam, 1, 31) 1297.45 with absolute error < 0.076f_wiese_gam <- function(x) predict(gam_wiese_fit, tibble(day_num = x))
integrate(f_wiese_gam, 1, 31) 1182.063 with absolute error < 0.11Am Ende haben wir dann die Fläche unter der Kurve für die Parzelle in Uelzen mit \(1297\) und die Fläche der Parzelle der Wiese mit \(1182\). Damit unterscheiden sich die beiden Parzellen um einen Ertrag von \(115\). Wir können eine einzelne Zahl nicht statistisch Testen, daher steht die Zahl so erstmal im Raum. Ob das jetzt viel oder wenig Ertrag ist, muss du selber entscheiden. Im folgenden Kasten zeige ich nochmal, wie du mit Messwiederholungen dann doch noch eine statistische Aussage über zwei Gruppen erhalten kannst.
Wir hatten uns eben gerade zwar ein Beispiel für den Vergleich zweier Zeitreihen angeschaut, aber hatten wir dort keine Wiederholungen, die wir zuordnen konnten. Wenn wir mit Pflanzen arbeiten, dann können wir das Wachstum über die Zeit bei jeder einzelnen Pflanze messen. Dann können wir aber auch den Verlauf des Wachstums für jede Pflanze darstellen. Damit haben wir dann auch noch eine andere Möglichkeit die Daten zu analysieren. Dazu nutzen wir jetzt ein Beispiel mit Baumwolle. Wir haben zwei Typen von Baumwole vorliegen. Einmal die Standardsorte ctrl sowie eine neue genetisch veränderte Sorte genetic. Wir haben das Wachstum an zwölf Pflanzen P1 bis P12 an insgesamt achtzehn Terminen gemessen. Wir haben die Daten in einem Wide-Format vorliegen und bauen uns deshalb mit der Funktion pivot_longer() einen Long-Format. Vorher müssen wir noch das Datum in Messtage umwandeln, damit wir besser mit den Werten rechnen können. Für die Darstellung nutzen wir dann die ursprünglcihe Datumsspalte.
cotton_time_tbl <- read_excel("data/timeseries_cotton.xlsx", sheet = "diameter") |>
group_by(trt) |>
mutate(day_measured = 1:n()) |>
pivot_longer(cols = P1:P12,
names_to = "plant_id",
names_pattern = ".(\\d+)",
names_transform = as.numeric,
values_to = "height") |>
ungroup()In der Abbildung 71.16 siehst du einmal die Daten der Wuchshöhe der zwölf Baumwollpflanzen pro Sorte über die achtzehn Messtermine visualisiert. Die beiden Baumwolllinien sind jeweils farbig markiert, die einzelnen Linien entsprechen den jeweils zwölf Pflanzen pro Linie. Wir müssen hier etwas mit der Funktion new_scale_color() arbeiten, damit wir dann wieder einen neuen Farbgradienten einführen können. Die Linien sind mit der loess()-Funktion durch die Punkte geschätzt. Wir speichern die Abbildung auch einmal in dem Objekt p1, da wir gleich noch die Abbildung mit der Auswertung der Flächen unter den Kurven zusammenbringen wollen.
p1 <- ggplot() +
aes(date, height, group = plant_id) +
theme_minimal() +
geom_smooth(data = filter(cotton_time_tbl, trt == "ctrl"),
aes(color = plant_id),
method = "loess", se = FALSE) +
scale_color_gradientn(colors = c('#99000d', '#fee5d9'), guide="none") +
new_scale_color() +
geom_smooth(data = filter(cotton_time_tbl, trt == "genetic"),
aes(color = plant_id),
method = "loess", se = FALSE) +
scale_color_gradientn(colors = c('#084594', '#4292c6'), guide="none") +
new_scale_color() +
geom_point(data = cotton_time_tbl, aes(color = trt)) +
scale_color_manual(values = c('#99000d', '#084594')) +
theme(legend.position = "top") +
labs(color = "Baumwolllinie", x = "", y = "Wuchshöhe in [cm]")
p1 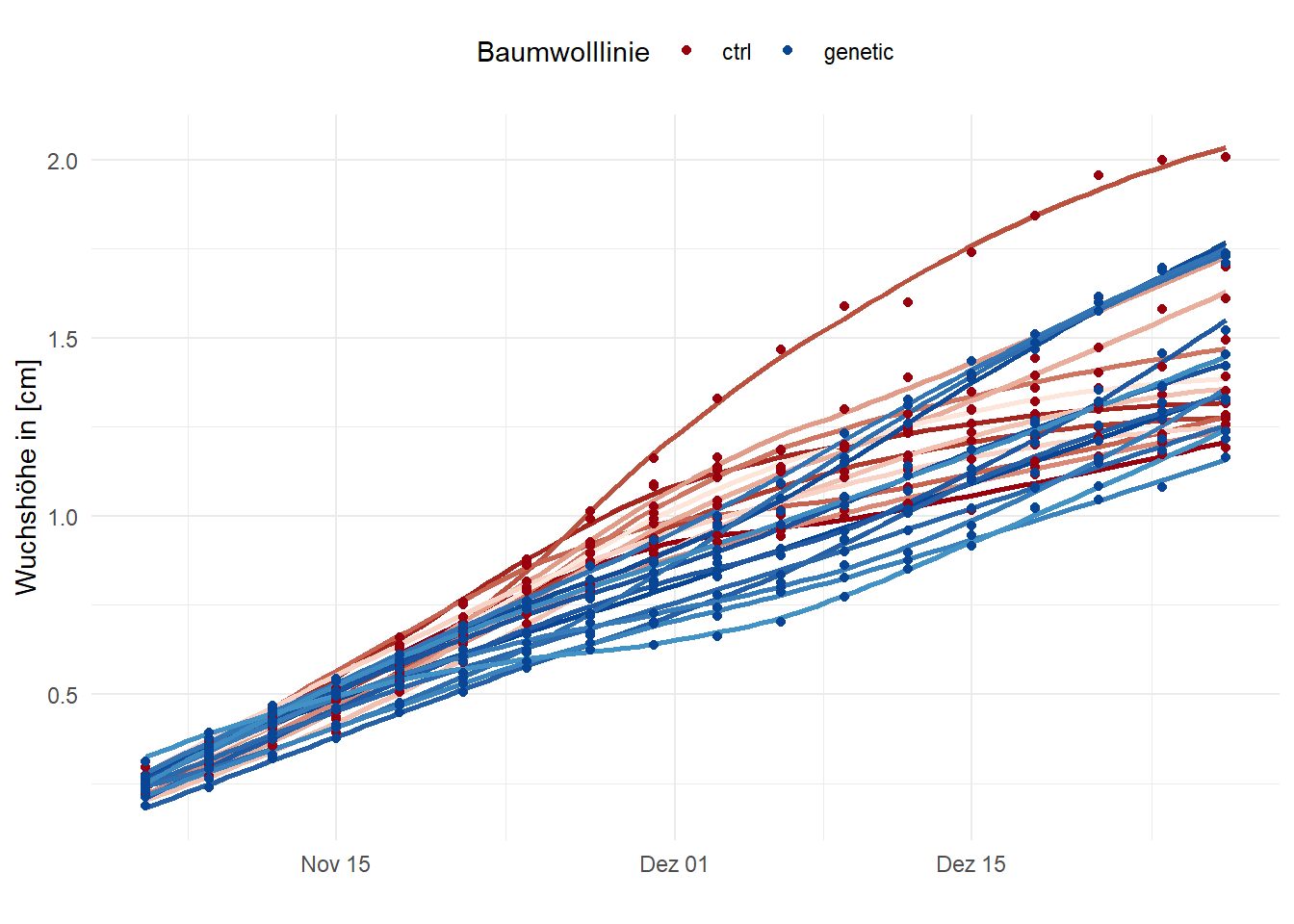
Jetzt stellt sich die Frage, ob sich das Wachstum über die Zeit in den beiden Linien unterscheidet. Dafür müssen wir die Fläche unter der Kurve für jede Pflanze berechnen. Dann können wir die Flächen vergleichen. Wenn das Wachstum gleich wäre, dann wären auch die Flächen gleich. Ich habe mir dafür die Funktion get_area() gebaut, die intern die Funktion loess() angepasst für diesen Datensatz aufruft. Dann brauche die noch die Funktion die integriert werden soll, die brauche ich mir mit der Funktion predict(). Abschließend muss ich noch der Funktion integrate() mitteilen von welchem \(x\)-Wert ich integrieren will. Ich entscheide mich hier von der ersten Messung bis zur letzten Messung am achtzehnten Tag zu integrieren.
get_area <- function(tbl) {
fit <- loess(height ~ day_measured, tbl)
f <- function(x) predict(fit, newdata = x)
integrate(f, 1, 18)$value
}Statt mit der Funktion loess() lassen sich die Kurven auch mit der Funktion gam() aus dem R Paket {mgcv} bauen. Ich nutze hier loess(), da die Funktion einfach zu nutzen ist und für die Genauigkeit hier ausreicht. Wenn du die Funktion gam() nutzt, dann musst die Funktion predict() anpassen, da bei gam() nur Datensätze als newdata akzeptiert werden.
Nachdem ich mir die nun Funktion gebaut habe, kann ich dann für jede Kombination aus Linie und Pflanze einmal die Fläche unter der Kurve auc (eng. area under the curve) berechnen. Ich nutze dazu die Funktionen nest() und map() um mir die Sache einfacher zu machen. Ich könnte auch mit filter() mir alle Subgruppen rausfiltern und am Ende zusammenbauen. Aber so geht es eben schneller.
auc_cotton_tbl <- cotton_time_tbl |>
group_by(trt, plant_id) |>
nest() |>
mutate(auc = map(data, ~get_area(.x))) |>
unnest(auc) Dann kann ich auch schon einen t-Test für den Vergleich der zwölf Flächen unter der Kurve für die Kontrolllinie und der neuen genetischen Linie rechnen. Prinzipiell ginge hier auch ein nicht-parametrischer Test, aber die Daten sehen einigermaßen normalverteilt aus, wie du gleich in den Boxplots in der Abbildung 71.17 sehen wirst.
t.test(auc ~ trt, data = auc_cotton_tbl)
Welch Two Sample t-test
data: auc by trt
t = 2.5392, df = 21.985, p-value = 0.0187
alternative hypothesis: true difference in means between group ctrl and group genetic is not equal to 0
95 percent confidence interval:
0.3128222 3.1016126
sample estimates:
mean in group ctrl mean in group genetic
15.91998 14.21277 Wir haben also einen signifikanten \(p\)-Wert für den Verglich der Flächen unter der Kurve für die beiden Linien. Ich baue mir jetzt einmal den Boxplot in Abbildung 71.17 und speichere mir den Plot auch gleich in ein Objekt p2. Ich werde dann die beiden Abbildungen p1 und p2 gleich einmal zusammenbringen. Vieles von dem Code dient nur die Abbildung schöner zu machen.
p2 <- auc_cotton_tbl |>
ggplot(aes(trt, auc, fill = trt)) +
theme_minimal() +
geom_boxplot(alpha = 0.8) +
scale_fill_manual(values = c('#99000d', '#084594')) +
theme(legend.position = "none") +
labs(y = "Fläche unter der Kurve", x = "") +
annotate("text", x = 1.5, y = 19, label = "p = 0.019") +
scale_y_continuous(position = "right")
p2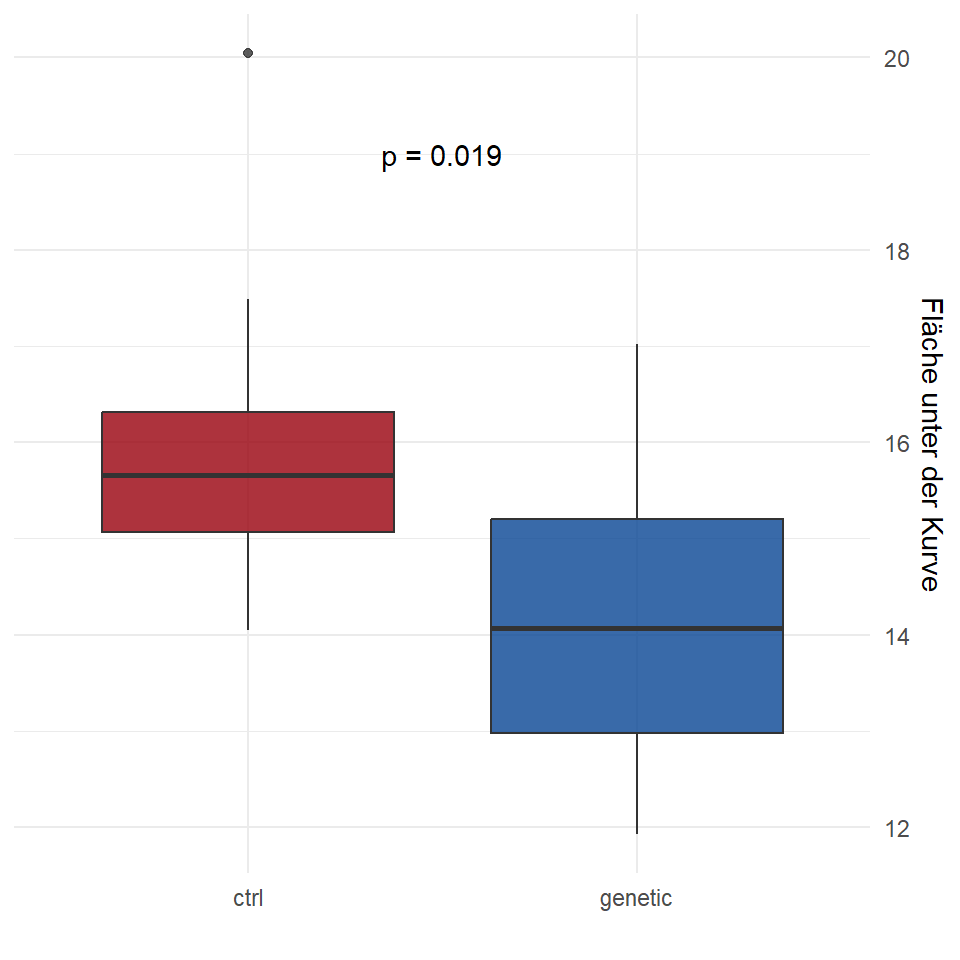
Dann können wir auch die beiden Abbildungen p1 und p2 mit dem R Paket {patchwork} zusammenbringen und eine Annotation mit den Buchstaben A und B ergänzen. Dann mache ich den Boxplot noch über die Funktion plot_layout() sehr viel schmaler, als den zeitlichen Verlauf. Eigentlich brauchen wir dann nur die Abbildung 71.18 veröffentlichen, die Abbildung bringt ja alles zusammen. Anscheinend gibt es einen Unterschied zwischen den beiden Linien. Überraschenderweise ist unsere neue genetische Linie signifikant kleiner. Oder andersherum, die Linie ist kleiner, ob das gewollt ist war oder nicht, kann ich dir nicht beantworten.
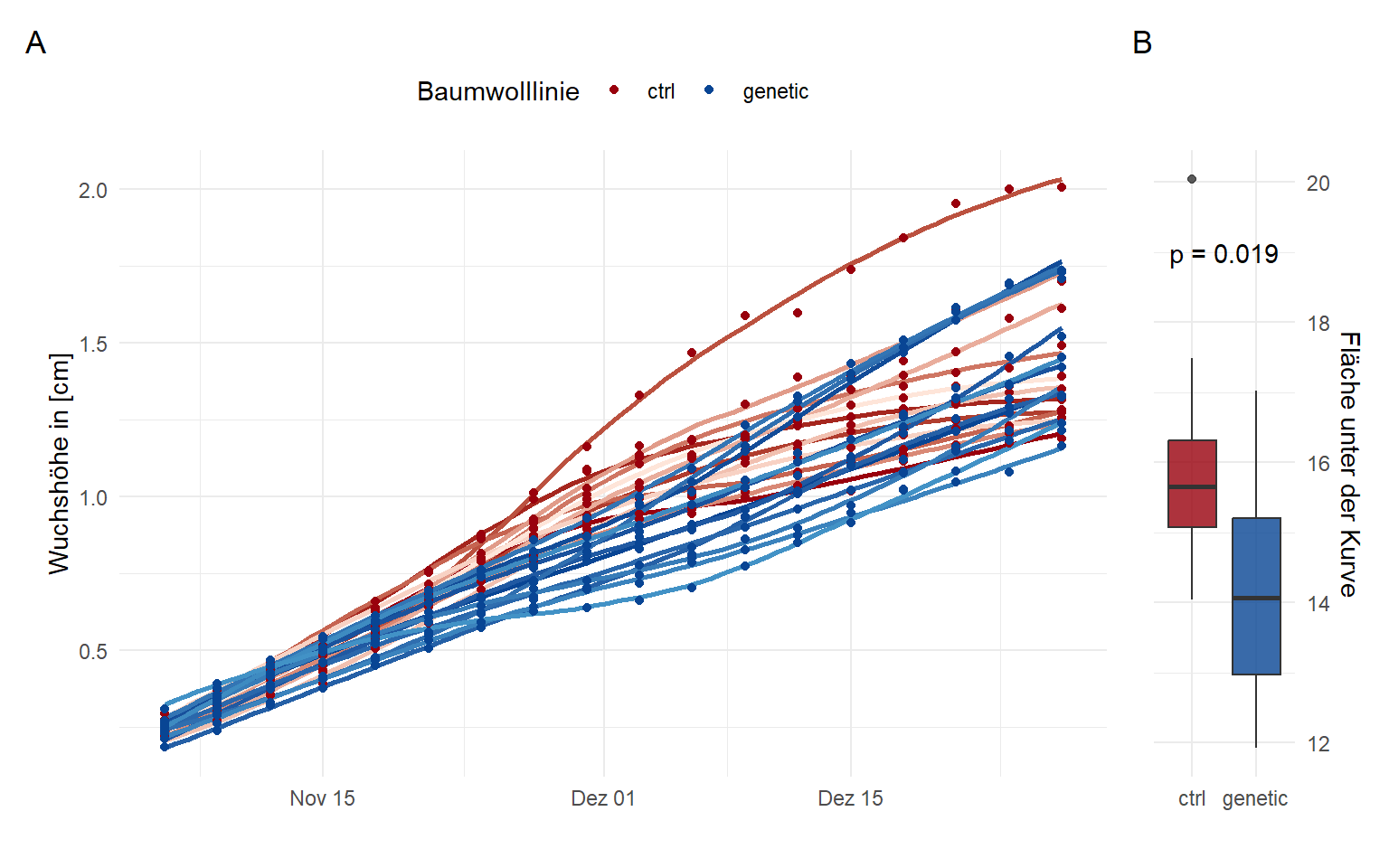
loess-Funktion geschätzt. (B) Boxplot der Fläche unter der Kurve für die beiden Baumwolllinien. Der \(p\)-Wert stammt aus einem Welch t-Test.
Und wie jetzt weiter? Was ist wenn du eine Vorhersage machen willst? Ja in dem Fall können wir dann im nächsten Kapitel einmal schauen, wie wir eine klassische Zeitreihenanalyse rechnen. Wir brauchen aber auf jeden Fall eine lange Beobachtungsdauer mit vielen Zeitpunkten. Aber das schaue dir am besten einmal im nächsten Kapitel an.