```{r echo = FALSE}
pacman::p_load(tidyverse, readxl, knitr, kableExtra, openxlsx)
```
# Überlebenszeitanalysen {#sec-survival}
*Letzte Änderung am `r format(fs::file_info("stat-modeling-survival.qmd")$modification_time, '%d. %B %Y um %H:%M:%S')`*
::: {.callout-caution appearance="minimal"}
## Dieses Kapitel ist archiviert
{fig-align="center" width="100%"}
Ich benötige die Thematik aktuell nicht in meiner Lehre oder der statistischen Beratung. Mir ist es als Nachschlagewerk aber immer noch wichtig zu behalten. Archivierte Kapitel werden nicht von mir weiter gepflegt oder ergänzt. Auftretende Fehler werden aber natürlich beseitigt, wenn die Fehler mir auffallen oder gemeldet werden.
:::
In diesem Kapitel wollen wir uns nochmal mit der Zeit beschäftigen. Wir haben hier aber keine zeitlichen Messwiederholungen an dem gleichen Subjekt, Tier oder Pflanze vorliegen sondern wir schauen uns an, wie lange es dauert bis ein Ereignis eintritt. Deshalb nennen wir diese Analysen algemein Ereigniszeitanalysen. Häufig schauen wir uns aber die zeit an, die es braucht, bis das Ereignis "tot" für eine Beobachtung eintritt. Daher heißt das Kapitel auch Überlebenszeitanalysen (eng. *survival analysis*).
Überlebenszeitanalysen sind in den Humanwissenschaften und inbesondere in der Onkologie *das* Thema schlechthin. Wir beantworten hier die Fragen nach *3 Monatsmortalität* und wollen wissen, wie viele patienten nach einer Behandlung mit einem Krebsmedikament nach drei Monaten noch leben. Du kanst dir vorstellen, dass es hier eine Menge an Annahmen und Modellen gibt. Wir wollen uns hier in dem Kapitel die Grundlagen anschauen. Da vieles in der Wissenschaft meist in englischer Sprache abläuft, kann ich hier sehr den das Buch von @david2012survival empfehlen. Insbesondere die Einführungskapitel sind sehr gut geschrieben. Diese Detailtiefe wie bei @david2012survival werde ich in diesem Abschnitt nicht erreichen. In den Agrarwissenschaften ist alles ein wenig anders als in den Humanwissenschaften.
Wie bereits erwähnt, konzentriert sich die Überlebensanalyse auf die erwartete Zeitdauer bis zum Auftreten eines Ereignisses von Interesse. Das Ereignis von Interesse ist dann meist ein Rückfall (eng. *relapse*) oder eben tot (eng. *death*). Es kann jedoch sein, dass das Ereignis bei einigen Personen innerhalb des Untersuchungszeitraums nicht beobachtet wird, was zu sogenannten zensierten Beobachtungen führt. Die Zensierung kann auf folgende Weise erfolgen:
- Ein Patient hat das interessierende Ereignis, wie Rückfall oder Tod, innerhalb des Studienzeitraums (noch) nicht erlebt;
- ein Patient wird während des Studienzeitraums nicht weiter beobachtet;
- bei einem Patienten tritt ein anderes Ereignis ein, das eine weitere Beobachtung unmöglich macht.
Diese Art der Zensierung, die als rechte Zensierung (eng. *right censoring*) bezeichnet wird, wird in der Überlebensanalyse in diesem Kapitel behandelt.
Am Ende muss ich dann nochmal auf die *proportional hazards assumption* hinweisen. Wir gehen davon aus, dass die Risiken im Zeitverlauf proportional sind, was bedeutet, dass die Wirkung eines Risikofaktors im Zeitverlauf konstant ist. Das ist jetzt etwas umständlich ausgedrückt, aber wir sagen, dass die Wahrscheinlichkeit zu Sterben über die ganze Studie immer konstant ist. Männer fangen also nicht nach $t$ Tagen an zügiger zu Versterben als Frauen. Wenn wir eine Verletzung der *proportional hazards assumption* vorliegen haben, dann müssen wir nochmal tiefer in das Thema einsteigen.
::: callout-tip
## Weitere Tutorien für die Analyse von Ereigniszeiten
Wir immer gibt es eine gute Auswahl an aktuellen Tutorien [Survival Analysis Basics](http://www.sthda.com/english/wiki/survival-analysis-basics), die hier auch aufgegrifen werden. Ein umfangreicheres Tutorium in R findet sich unter [Survival Analysis in R](https://www.emilyzabor.com/tutorials/survival_analysis_in_r_tutorial.html).
:::
## Genutzte R Pakete
Wir wollen folgende R Pakete in diesem Kapitel nutzen.
```{r echo = TRUE}
#| message: false
pacman::p_load(tidyverse, magrittr, conflicted, broom,
survminer, survival, parameters,
gtsummary, janitor, ranger)
conflicts_prefer(dplyr::filter)
cbbPalette <- c("#000000", "#E69F00", "#56B4E9", "#009E73",
"#F0E442", "#0072B2", "#D55E00", "#CC79A7")
```
An der Seite des Kapitels findest du den Link *Quellcode anzeigen*, über den du Zugang zum gesamten R-Code dieses Kapitels erhältst.
## Daten
Insgesamt schauen wir uns in diesem Kapitel dann drei Datensätze an. Einmal einen Datensatz der sehr simple ist und nochmal erklärt wie die Datenstruktur in R aussehen muss. Dafür nutzen wir das Überleben von Dodos. Dann einen Datensatz, der etwas komplizierter ist. Wir betrachten hier das Überleben von Fruchtfliegen. Den Abschluss bildet ein Datensatz zu einer klinischen Studie von Lungenkrebs. Der Datensatz wird viel in Beispielen genutzt, so dass ich den Datensatz auch hier nochmal vorstellen möchte.
### Überleben von Dodos
Wir schauen uns hier das Überleben von Dodos mit oder ohne Schnabelstutzen an. Wir schauen dann an jedem Lebenstag, wie viele Dodos verstorben sind. Da wir es hier mit sehr schnell wachsenden Dodos zu tun haben, ist der Datensatz nicht so lang was die Zeit angeht. Wir beobachten nur die ersten 55 Lebenstage (eng. *days of life*, abk. *dol*) bevor die Dodos dann geschlachtet werden. In der @tbl-surv-dodo-1 sehen wir die rohen Daten, die wir in der Form nicht analysieren können. Wir müssen uns hier etwas strecken, damit das Format der Daten für die Überlebenszeitanalyse passt.
```{r}
#| message: false
#| echo: false
n_dodo <- 250
set.seed(20220929)
dodo_raw_tbl <- bind_rows(tibble(dol = 1:55,
death = c(rep(0, 5), rpois(50, 3.5)),
count = cumsum(c(n_dodo, -1*death[-1])),
trt = "none"),
tibble(dol = 1:55,
death = c(rep(0, 5), rpois(50, 1.75)),
count = cumsum(c(n_dodo, -1*death[-1])),
trt = "clipped")) |>
select(trt, dol, count, death)
write.xlsx(dodo_raw_tbl, "data/dodo_raw.xlsx", rowNames = FALSE)
```
```{r}
#| message: false
#| echo: false
#| tbl-cap: Rohe Datentabelle mit den jeweiligen Lebenstagen (abk. *dol*) und der Anzahl an lebenden sowie toten Dodos an den entsprechenden Tagen.
#| label: tbl-surv-dodo-1
rbind(head(dodo_raw_tbl, n = 6),
rep("...", times = ncol(dodo_raw_tbl)),
tail(dodo_raw_tbl, n = 6)) |>
kable(align = "c", "pipe")
```
Unsere Daten zu den Dodos beinhalten die folgenden Spalten mit den entsprechenden Bedeutungen.
- **trt**, die Behandlung der Schnäbel mit `none` und `clipped`
- **dol**, der *day of life* also der Lebenstag der Dodos
- **count**, die Anzahl an lebenden Dodos an dem entprechenden *day of life*
- **death**, die Anzahl an tot aufgefundenen Dodos an dem entpsrechenden *day of life*
Wir haben somit $n = `r 2*n_dodo`$ beobachtete Dodos mit jeweils `r n_dodo` für jede der beiden Schnabelbehandlungen. Jetzt brauchen wir aber wie immer einen Datansatz in dem jede Zeile einen beobachteten Dodo entspricht. In der @tbl-surv-dodo-2-example sehen wir welche Art von Tabelle wir bauen müssen.
| dodo_id | trt | dol | death |
|---------|---------|-----|-------|
| 1 | none | 6 | 1 |
| 2 | none | 6 | 1 |
| 3 | none | 7 | 1 |
| ... | ... | ... | ... |
| 249 | none | 55 | 0 |
| 250 | none | 55 | 0 |
| 251 | clipped | 6 | 1 |
| ... | ... | ... | ... |
| 500 | clipped | 55 | 0 |
: Beispielhafte Datentabelle für die Analyse der Dododaten. Jede Zeile entspricht einem beobachteten Dodo und dem entsprechenden Informationen zur Lebensdauer und Schnabelbehandlung. {#tbl-surv-dodo-2-example}
Fangen wir also mit der Information an, die wir haben. Wir wissen wie viele Dodos jeweils zu einem bestimmten Lebenstag gestorben sind. Daher können wir anhand der Spalte `death` die Anzahl an Zeilen entsprechend vervielfältigen. Sind an einem Lebenstag drei Dodos gestorben, dann brauchen wir dreimal eine Zeile mit der Information des Lebenstages und dass an diesem Tag ein Dodo gestorben ist. Wir nutzen dazu die Funktion `uncount()`. Dann erschaffen wir noch eine Spalte `death` in der einfach immer eine `1` steht, da ja an diesem Lebenstag ein Dodo verstorben ist.
```{r}
death_tbl <- dodo_raw_tbl |>
uncount(death) |>
mutate(death = 1)
```
Im nächsten Schritt müssen wir die lebenden Dodos *separat für jede Behandlung* ergänzen. Daher spalten wir uns die Daten in eine Liste auf und ergänzen dann die Informationen zu den fehlenden, lebenden Dodos. Alle lebenden Dodos haben die maximale Lebenszeit, sind nicht gestorben und damit bleibt die Anzahl auch konstant.
```{r}
alive_tbl <- death_tbl |>
split(~trt) |>
map(~tibble(dol = max(.x$dol),
death = rep(0, last(.x$count)),
count = last(.x$count))) |>
bind_rows(.id = "trt")
```
Wenn wir die Informationen zu toten und den noch lebenden Dodos gebaut haben, können wir uns dann einen finalen Datensatz zusammenkleben.
```{r}
dodo_tbl <- bind_rows(death_tbl, alive_tbl)
```
In der @tbl-surv-dodo-2 sehen wir den finalen Dododatensatz, den wir uns aus den Informationen zusammengebaut haben. Wir haben hier einmal die Struktur eines Überlebenszeitdatensatzes gelernt und das wir manchmal uns ganz schön strecken müssen um die Daten dann auch gut umzubauen. Wir werden am Ende nur die Informationen in der Spalte `dol`, `death` und `trt` nutzen.
```{r}
#| message: false
#| echo: false
#| tbl-cap: Finaler Dododatensatz für die Überlebenszeitanalysen.
#| label: tbl-surv-dodo-2
rbind(head(dodo_tbl, n = 6),
rep("...", times = ncol(dodo_tbl)),
tail(dodo_tbl, n = 6)) |>
kable(align = "c", "pipe")
```
### Überleben von Fruchtfliegen
Im folgenden Beispiel in @tbl-surv-2 beobachten wir Fruchtfliegen bis fast alle Insekten verstorben sind. Das ist natürlich das andere Extrem zu den Dododatensatz. Wir testen hier ein Insektizid und am Ende haben wir dann keine lebenden Fruchtfliegen mehr. Das würdest du mit Dodos oder Schweinen nicht machen, denn so lange möchtest du die Tiere ja auch nicht beobachten, bis alle gestorben sind. Bei Fruchtfliegen dauert es eben nicht so lange bis alle Fliegen verstorben sind.
```{r}
#| message: false
#| echo: false
set.seed(20220929)
fruitfly_tbl <- tibble(times_raw = round(c(rpois(50, 10), rpois(50, 14))),
status = rbinom(100, 1, 0.8),
trt = factor(gl(2, 50), labels = c("fruitflyEx", "control")),
sex = sample(factor(gl(2, 50), labels = c("male", "female"))),
time = ifelse(sex == "male", times_raw - 2, times_raw + 5),
weight = round(c(rnorm(50, 11, 3), rnorm(50, 19, 3)), 2),
weight_bin = ifelse(weight <= 15, "low", "high")) |>
select(-times_raw) |>
select(trt, time, status, everything()) |>
arrange(trt, time)
write.xlsx(fruitfly_tbl, "data/fruitfly.xlsx", rowNames = FALSE)
```
Wir laden die Daten der Fruchtfliegen aus der Datei `fruitfly.xlsx`.
```{r}
fruitfly_tbl <- read_excel("data/fruitfly.xlsx")
```
Damit arbeiten wir dann im Folgenden weiter.
```{r}
#| message: false
#| echo: false
#| tbl-cap: Fruchtfliegendatensatz mit verschiedenen Covariaten zu der Behandlung, der Zeit und dem Status der Fruchtfliegen.
#| label: tbl-surv-2
fruitfly_raw_tbl <- fruitfly_tbl |>
mutate(trt = as.character(trt),
sex = as.character(sex))
rbind(head(fruitfly_raw_tbl, n = 4),
rep("...", times = ncol(fruitfly_raw_tbl)),
tail(fruitfly_raw_tbl, n = 4)) |>
kable(align = "c", "pipe")
```
Unsere Daten zu den Fruchtfliegen beinhalten die folgenden Spalten mit den entsprechenden Bedeutungen.
- **trt**, als die Behandlung mit den beiden Leveln `fruitflyEx` und `control`
- **time**, den Zeitpunkt des Todes der entsprechenden Fruchfliege
- **status**, den Status der Fruchtfliege zu dem Zeitpunkt `time`. Hier meist `1` und damit tot, aber ein paar Fruchtfliegen sind bei der Überprüfung entkommen und haben dann eine `0`.
- **sex**, das Geschlecht der entsprechenden Fruchtfliege
- **weight**, das Gewicht der entsprechenden Fruchtfliege in $\mu g$.
- **weight_bin** das Gewicht der entsprechenden Fruchtfliege aufgeteilt in zwei Gruppen nach dem Cutpoint von $15 \mu g$.
### Überleben von Lungenkrebs
Zum Abschluss möchte ich noch den Datensatz `lung` in der @tbl-surv-3 aus dem R Paket `{survival}` vorstellen. Das hat vor allem den Grund, dass es sich hier um einen klassischen Datensatz zur Überlebenszeitanalyse handelt und ich auch dieses Teilgebiet einmal mit abdecken möchte. Wie schon weiter oben gesagt, Überlebenszeitanalysen kommen eher in dem Humanbereich vor. Darüber hinaus bedienen sich fast alle anderen Tutorien im Internet diesem Datensatz, so dass du dann einfacher die englischen Texte nachvollziehen kannst.
```{r}
#| message: false
#| echo: false
#| tbl-cap: "Der Datensatz `lung` über eine Beobachtungsstudiue Studie zu Lungenkrebs."
#| label: tbl-surv-3
rbind(head(as_tibble(lung), n = 4),
rep("...", times = ncol(lung)),
tail(as_tibble(lung), n = 4)) |>
kable(align = "c", "pipe")
```
- **inst** Institution code
- **time** Survival time in days
- **status** censoring status 1=censored, 2=dead
- **age** Age in years
- **sex** Male=1 Female=2
- **ph.ecog** ECOG performance score (0=good 5=dead)
- **ph.karno** Karnofsky performance score (bad=0-good=100) rated by physician
- **pat.karno** Karnofsky performance score as rated by patient
- **meal.cal** Calories consumed at meals
- **wt.loss** Weight loss in last six months
Trotz seiner Prominenz hat der Datensatz einen Fehler. Wir wollen den Status nicht auf 1/2 kodiert haben sondern auf 0/1. Ebenso wollen wir die Spalte `inst` nicht, da wir die Informationen nicht brauchen. Dann sind noch die Namen der Spalten hässlich, so dass wir da die Funktion `clean_names()` nutzen um einmal aufzuräumen.
```{r}
lung_tbl <- lung |>
as_tibble() |>
mutate(status = recode(status, `1` = 0, `2` = 1)) |>
clean_names() |>
select(-inst)
```
## Die `Surv()` Funktion
Als *die* Besonderheit bei der Bearbeitung von Überlebenszeitanalysen ist die Andersartigkeit von unserem $y$. Wir haben ja *zwei* Spalten, die das Outcome beschreiben. Zum einen die Dauer oder Zeit bis zum Ereignis und dann die Spalte, die beschreibt, ob das Ereignis überhaupt eingetreten ist. In R lösen wir dieses Problem in dem wir zwei Spalten in dem Objekt `Surv()` zusammenführen. Alle Analysen in R gehen nur mit dem `Surv()` Objekt.
```{r}
#| echo: true
#| message: false
#| warning: false
#| eval: false
Surv(time, death)
```
In dem Objekt `Surv()` haben wir erst die Spalte für die Zeit und dann die Spalte für das Ereignis. Für den Dododatensatz haben wir dann folgende Zusammenhänge.
- `dol` in den Daten `dodo_tbl` ist gleich `time` in dem `Surv()` Objekt
- `death` in den Daten `dodo_tbl` ist gleich `death` in dem `Surv()` Objekt
Bei dem Fruchfliegendatensatz sieht die Sachlage dann so aus.
- `time` in den Daten `fruitfly_tbl` ist gleich `time` in dem `Surv()` Objekt
- `status` in den Daten `fruitfly_tbl` ist gleich `death` in dem `Surv()` Objekt
Für den Lungenkrebsdatensatz haben wir dann folgende Zuordnung.
- `time` in den Daten `lung_tbl` ist gleich `time` in dem `Surv()` Objekt
- `status` in den Daten `lung_tbl` ist gleich `death` in dem `Surv()` Objekt
Im Folgenden haben wir dann immer auf der linken Seite vom `~` ein `Surv()` Objekt stehen. Daran muss man sich immer etwas gewöhnen, sonst kommt sowas ja nicht in den Analysen vor.
## Visualisierung über Kaplan Meier Kurven
::: callout-caution
## Nur kategoriale Variablen in einer Kaplan Meier Kurve
Wir können nur kategoriale Variablen in einer Kaplan Meier Kurve darstellen. Das heißt, wir müssen alle unsere $x$, die kontinuierlich sind in eine kategoriale Variable umwandeln.
:::
Wir können nur kategoriale Variablen in einer Kaplan Meier Kurve darstellen. Das heißt, wir müssen alle unser $X$, die wir haben, in Variablen mit Kategorien umwandeln. Wenn du also in deinen Daten eine Spalte für das Gewicht in kg hast, dann musst du dir überlegen, wie du diese Werte in Kategorien änderst. Eine beliebte Variante ist, dass du zwei Gruppen bildest. Einmal die Patienten, die schwerer sind als der Median des Körpergewichts und einmal eine Gruppe für die Patienten, die leichter sind als der Median des Körpergewichts. Die Kategorisierung von Variablen ist faktisch ein eigenes Problem und lässt sich ohne den biologischen Hintergrund eigentlich nicht sauber durchführen. Daher werden in klinischen Studien oder Experimenten die Daten gleich in Kategorien erhoben. Daher gibt es vorab klare Kriterien in welcher Gewichtsklasse oder Altersklasse ein Patient landen wird. Das Gleiche gilt dann auch für andere kontinuierlichen Variablen.
Ein häufiger Fehler bei der Betrachtung der Kaplan Meier Kurve ist diese als die simple lineare Regression der Überlebenszeitanalyse anzusehen. Wir können zwar mit der Kaplan Meier Kurve immer nur *ein* $X$ betrachten aber der Algorithmus basiert auf dem $\mathcal{X}^2$-Test und hat nichts mit einer Regression zu tun. Daher *kann* es sein, dass du unterschiedliche Ergebnisse in der Visualisierung mit Kaplan Meier Kurven und dann der Analyse mit dem Cox Proportional-Hazards Modell erhälst.
In R nutzen wir das Paket `{survminer}` und die Funktion `ggsurvplot()` für die Visualisierung der Kaplan Meier Kurven.
### Dodos
Um eine Kaplan Meier Kurve zeichnen zu können, brauchen wie als erstes die Funktion `survfit()`. Mit der Funktion `survfit()` können wir zum einen das mediane Überleben berechnen und alle Informationen erhalten, die wir brauchen um die Kaplan Meier Kurve zu plotten.
```{r}
trt_fit <- survfit(Surv(dol, death) ~ trt, data = dodo_tbl)
```
Wir können einmal das Objekt `trt_fit` uns anschauen.
```{r}
trt_fit
```
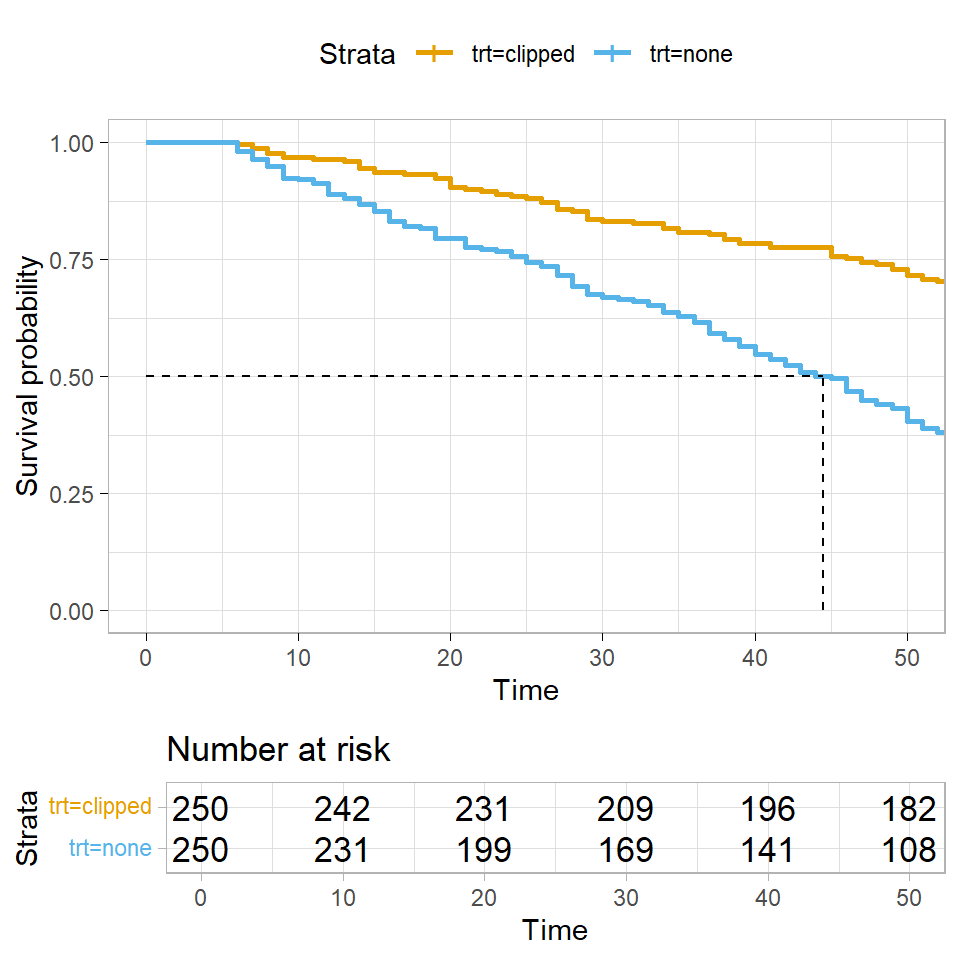
Zum einen fallen uns die `NA`'s in der Wiedergabe des Fits der Überlebenszeit auf. Wenn wir uns die @fig-surv-1 einmal anschauen, dann wird das Problem etwas klarer. Wir sehen nämlich, dass wir bei den geklippten Tieren gar nicht so weit runter kommen mit den toten Tieren, dass wir das mediane Überleben berechnen könnten. Nicht immer können wir auch alle statistischen Methoden auf alle Fragestellungen anwenden. Insbesondere wenn nicht genug Ereignisse wie in diesem Beispiel auftreten.
```{r}
#| echo: true
#| message: false
#| warning: false
#| label: fig-surv-1
#| fig-align: center
#| fig-height: 5
#| fig-width: 5
#| fig-cap: "Kaplan Meier Kurven für unsere geklippten Dodos. Wir sehen, dass die geklippten Tiere in der Zeit der Versuchsdurchführung garnicht zur Hälfte versterben."
ggsurvplot(trt_fit,
data = dodo_tbl,
risk.table = TRUE,
surv.median.line = "hv",
ggtheme = theme_light(),
palette = cbbPalette[2:8])
```
### Fruchtfliegen
Gehen wir einen Schritt weiter und schauen uns das Modell für die Fruchtfliegen an. Hier haben wir eine Behandlung mit zwei Leveln also Gruppen vorliegen. Wir nutzen wieder die Funktion `survfit()` um einaml unser Modell der Überlebenszeiten zu fitten.
```{r}
trt_fit <- survfit(Surv(time, status) ~ trt, data = fruitfly_tbl)
```
Wir erhalten dann folgende Ausgabe des Modells.
```{r}
trt_fit
```
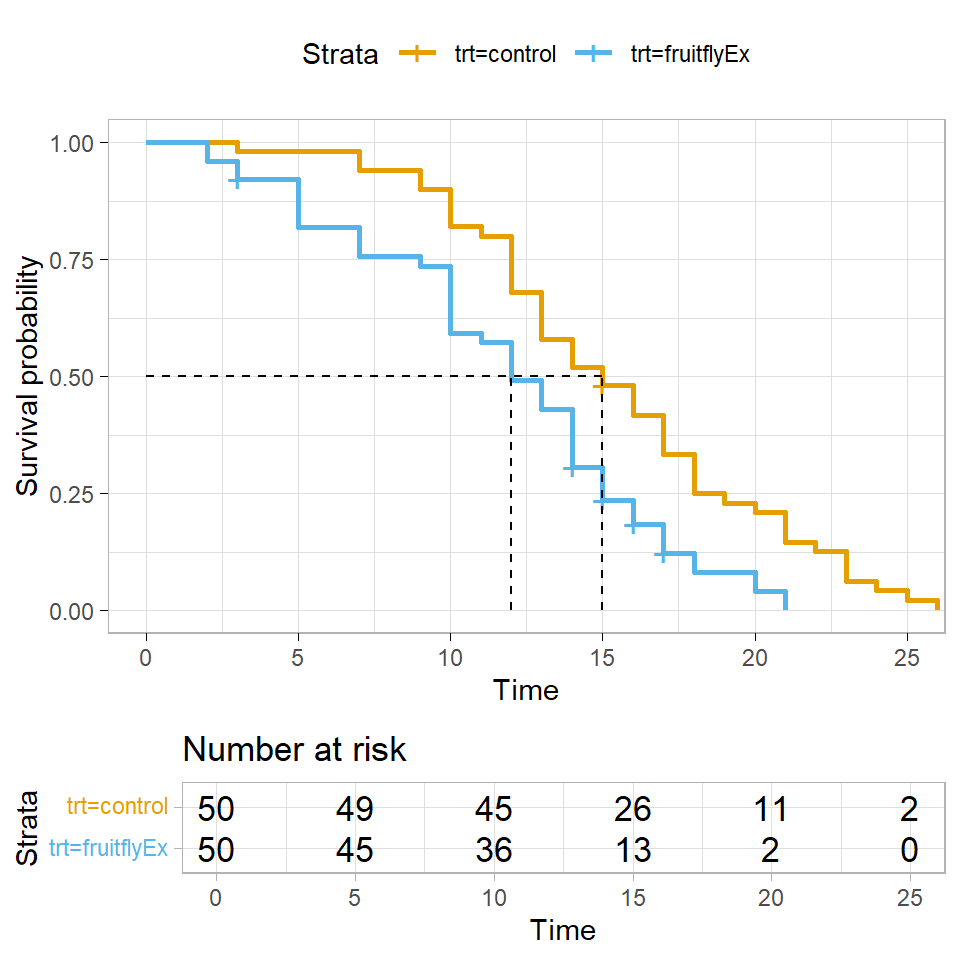
In der @fig-surv-2 sehen wir die Visualisierung des Modells als Kaplan Meier Kurve. In diesem Experiment sterben fast alle Fruchtfliegen im Laufe der Untersuchung. Wir können also einfach das mediane Überleben für beide Gruppen berechnen.
```{r}
#| echo: true
#| message: false
#| warning: false
#| label: fig-surv-2
#| fig-align: center
#| fig-height: 5
#| fig-width: 5
#| fig-cap: "Kaplan Meier Kurven für die Fruchtfliegen nach der Behandlung mit einem Pestizid und einer Kontrolle."
ggsurvplot(trt_fit,
data = fruitfly_tbl,
risk.table = TRUE,
surv.median.line = "hv",
ggtheme = theme_light(),
palette = cbbPalette[2:8])
```
Nachdem wir die Kaplan Meier Kurven einmal für die Behandlung durchgeführt haben, können wir uns auch anschauen, ob das Überleben der Fruchtfliegen etwas mit dem Gewicht der Fruchtfliegen zu tun hat. Hier können wir *nicht* auf das Gewicht in der Spalte `weight` zurückgreifen sondern müssen die Variable `weight_bin` mit zwei Klassen nehmen.
```{r}
weight_fit <- survfit(Surv(time, status) ~ weight_bin, data = fruitfly_tbl)
```
Wir erhalten dann die Kaplan Meier Kurven in der @fig-surv-3 zurück. Hier ist es wichtig sich nochmal klar zu machen, dass wir eben nur kategoriale Variablen in einer Kaplan Meier Kurve darstellen können.
```{r}
#| echo: true
#| message: false
#| warning: false
#| label: fig-surv-3
#| fig-align: center
#| fig-height: 5
#| fig-width: 5
#| fig-cap: "Kaplan Meier Kurven für die Fruchtfliegen nach der Behandlung mit einem Pestizid und einer Kontrolle."
ggsurvplot(weight_fit,
data = fruitfly_tbl,
risk.table = TRUE,
surv.median.line = "hv",
ggtheme = theme_light(),
palette = cbbPalette[2:8])
```
### Lungenkrebs
Als letztes Beispiel wollen wir uns nochmal den Datensatz `lung_tbl` anschauen. Zwar ist Lungenkrebs jetzt nichts was Tiere und Pflanzen als eine wichtige Erkrankung haben können, aber der Datensatz wird viel als Beispiel genutzt, so dass ich den Datensatz hier auch nochmal vorstellen möchte. Auch sind teilweise gewisse Schritte von Interesse, die eventuell auch in deiner Tier- oder Mäusestudie von Interesse sein könnten.
Beginnen wir einmal mit dem Nullmodell. Das heißt, wir schauen uns den Verlauf des gesamten Überlebens einmal an. Wir wollen wissen, wie das mediane Überleben in unseren Daten ausschaut ohne das wir uns irgendeien Variable anschauen.
```{r}
null_fit <- survfit(Surv(time, status) ~ 1, data = lung_tbl)
```
Im Folgenden einmal die Ausgabe des Fits.
```{r}
null_fit
```
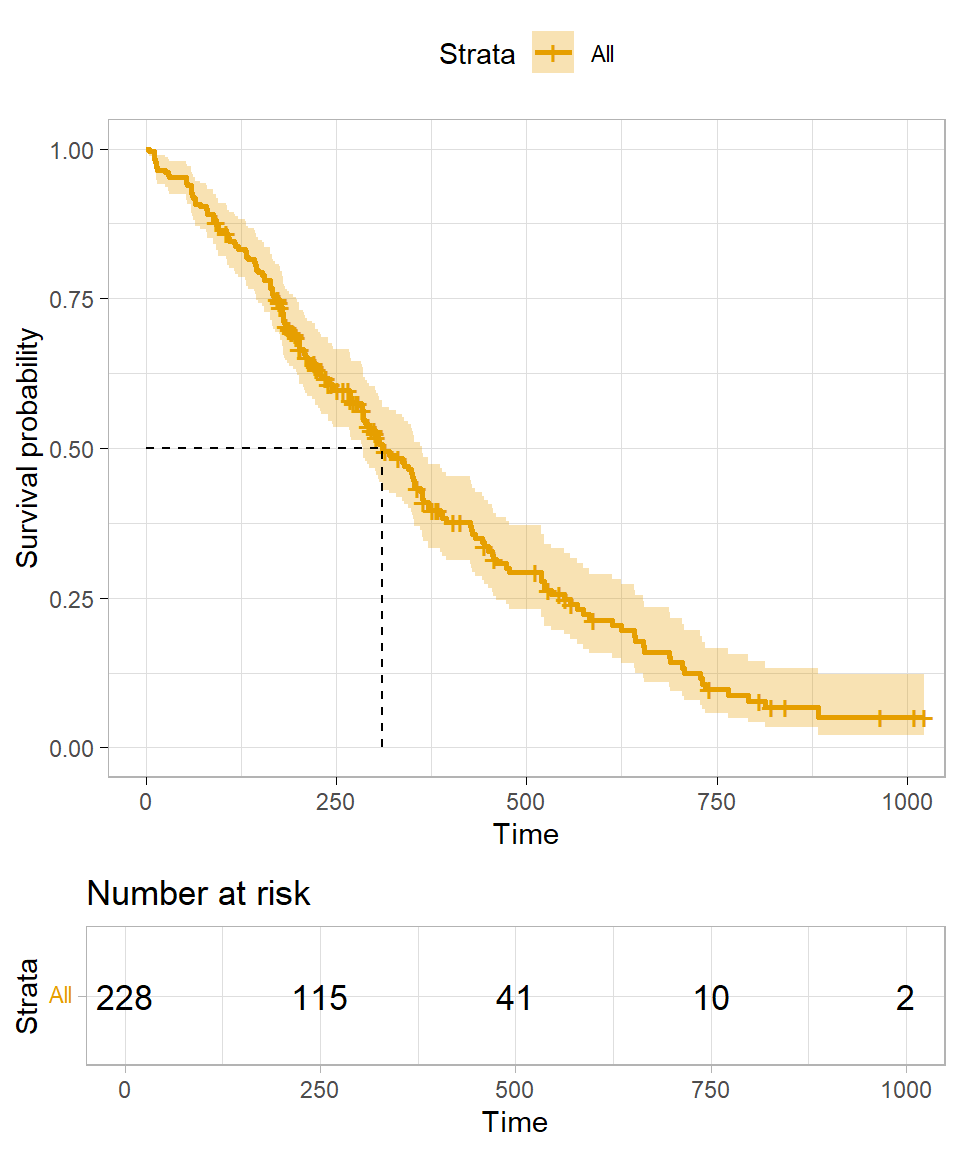
Wir sehen, dass wir ein medianes Überleben von $310$ Tagen haben. Es gibt insgesamt $165$ Ereignisse zu beobachten von insgesamt $228$ in die Studie eingeschlossenen Patienten. Wir können uns auch für bestimmte Zeitpunkte das Überleben wiedergeben lassen. Wir schauen uns hier einmal das Überleben nach einem Jahr bzw. $365.25$ Tagen an.
```{r}
null_fit |>
summary(times = 365.25)
```
Hier sehen wir, dass $40.9\%$ das eine Jahr überlebt haben. Achtung, immer auf die Kodierung achten. Nur wenn du `death = 1` kodiert hast, kannst du hier die Ausgaben der Funktionen in diesem Sinne interpretieren. Gerne kannst du hier auch das 3 Monatsüberleben bestimmen. Das kommt ganz darauf an, was deine Fragestellung ist. In der @fig-surv-4 siehst du nochmal die Kaplan Meyer Kurve für das Nullmodell.
```{r}
#| echo: true
#| message: false
#| warning: false
#| label: fig-surv-4
#| fig-align: center
#| fig-height: 6
#| fig-width: 5
#| fig-cap: "Kaplan Meier Kurven für das Nullmodell des Lungenkrebsdatensatzes."
ggsurvplot(null_fit,
data = lung_tbl,
risk.table = TRUE,
surv.median.line = "hv",
ggtheme = theme_light(),
palette = cbbPalette[2])
```
Schauen wir uns auch einmal Kaplan Meier Kurven für die Variable `ph_ecog` an. Hier haben wir das Problem, dass die Kategorie `3` kaum mit Patienten belegt ist. Daher filtern wir die Kategorie `3` einmal aus unseren Daten raus.
```{r}
lung_tbl %<>%
filter(ph_ecog != 3)
```
Wir können dann das Modell der Überlebenszeit einmal fitten.
```{r}
lung_fit <- survfit(Surv(time, status) ~ ph_ecog, data = lung_tbl)
```
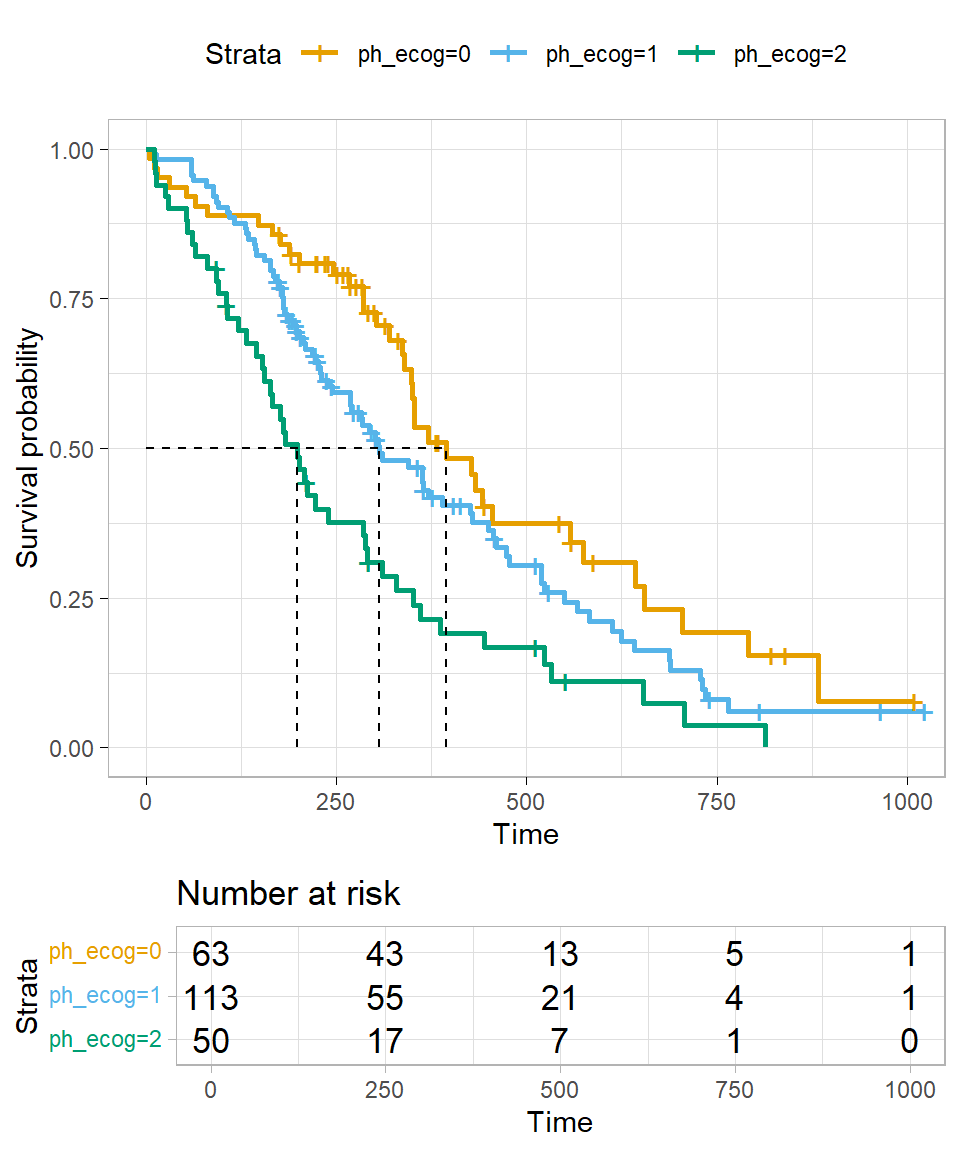
In der @fig-surv-5 sehen wir dann die Kaplan Meier Kurve für die Variable `ph_ecog`. Du kannst hier schön sehen, dass wenn wir mehrere Kategorien in der Variable haben auch mehrere Graphen erhalten. Wichtig hierbei ist nochmal, dass sich die Graphen nicht überschneiden oder aber in der Mitte kreuzen. Dann haben wir ein Problem und könnten die Daten nicht auswerten. Konkret geht es hier um die *proportional hazards assumption*, die besagt, dass Überlebenszeitkurven für verschiedene Gruppen Hazardfunktionen haben müssen, die über die Zeit $t$ proportional sind. Daher dürfen sich die Kurven nicht schneiden.
```{r}
#| echo: true
#| message: false
#| warning: false
#| label: fig-surv-5
#| fig-align: center
#| fig-height: 6
#| fig-width: 5
#| fig-cap: "Kaplan Meier Kurve für die Variable `ph_ecog` des Lungenkrebsdatensatzes."
ggsurvplot(lung_fit,
data = lung_tbl,
risk.table = TRUE,
surv.median.line = "hv",
ggtheme = theme_light(),
palette = cbbPalette[2:8])
```
Ganz zum Schluss dann noch die Frage, ob wir einen *signifikanten* Unterschied zwischen den beiden Kurven sehen. Dafür können wir dann die Funktion `survdiff()` nutzen. Die Funktion `survdiff()` gibt uns dann einen p-Wert wieder, ob sich die Kurven unterscheiden. Da es sich hier um einen globalen p-Wert handelt, erfahren wir nur, dass sich die Kurven unterscheiden, aber nicht welche. Dafür müssten wir dann die Kurven paarweise getrennt betrachten. Eigentlich ist nur der p-Wert von Interesse, die anderen Informationen haben eigentlich keinen biologischen Mehrwert.
```{r}
survdiff(Surv(time, status) ~ ph_ecog, data = lung_tbl)
```
## Cox Proportional-Hazards Modell
Wenn die Kaplan Meyer Kurven sowas wie die simple lineare Regression sind, dann ist das Cox Proportional-Hazards Modell die multiple Regression in den Ereigniszeitanalysen. Damit haben wir natürlich wieder einen statistischen Engel überfahren. Das Cox Proportional-Hazards Modell ist natürlich etwas anders und lässt sich so einfach auch nicht mit einer multiplen Regression vergleichen, aber die Anwendung ist ähnlich. Wo wir bei den Kaplan Meier Kurven nur ein $X$ in das Modell nehmen können, so können wir beim Cox Proportional-Hazards Modell beliebig viele $X$ mit ins Modell nehmen. Theoretisch müssen die Variablen in einem Cox Proportional-Hazards Modell auch nicht mehr kategorial sein. Da wir aber meist alles schon in Kategorien visualisiert haben, bleiben wir dann meist im Cox Proportional-Hazards Modell auch bei den Kategorien in den Variablen. Auch im Fall des Cox Proportional-Hazards Modells kann ich hier nur eine Übersicht geben. Es findet sich natürlich auch ein Tutorium zum [Cox Proportional-Hazards Model Tools](http://www.sthda.com/english/wiki/cox-proportional-hazards-model). Für das Überprüfen der Modellannahmen empfiehlt sich auch das Tutorium zu [Cox Model Assumptions](http://www.sthda.com/english/wiki/cox-model-assumptions).
In R nutzen wir die Funktion `coxph()` um ein Cox Proportional-Hazards Modell anzupassen. Die Anwendung ist eigentlich ziemlich einfach und lässt sich schnell durchführen.
```{r}
#| message: false
fit_1 <- coxph(Surv(time, status) ~ trt + sex + weight, data = fruitfly_tbl)
fit_1 |>
model_parameters(exponentiate = TRUE)
```
Als Koeffizienten erhalten wir das *Hazard ratio* (abk. *HR*) wieder. Wie schon bei der logistischen Regression müssen wir auch hier die Koeffizienten exponieren, damit wir die Link-scale verlassen. Wir können das HR wie ein Risk ratio (abk. *RR*) interpretieren. Es handelt sich also mehr um eine Sterbe*wahrscheinlichkeit*. Ganz richtig ist die Interpretation nicht, da wir hier noch eine Zeitkomponente mit drin haben, aber für den umgangssprachlichen Gebrauch reicht die Interpretation.
Wenn wir ein $HR > 1$ vorliegen haben, so steigert die Variable das Risiko zu sterben. Daher haben wir eine protektive Variable vorliegen, wenn dass $HR < 1$ ist. Häufig wollen wir ein $HR < 0.8$ oder $HR < 0.85$ haben, wenn wir von einem relevanten Effekt sprechen wollen. Sonst reicht uns die Risikoreduktion nicht, um wirklich diese Variable zukünftig zu berücksichtigen. Aber wie immer hängt die Schwelle sehr von deiner Fragestellung ab.
Ich habe nochmal als Vergleich die Variable `weight` in das Modell genommen und damit den `fit_1` angepasst sowie die Variable `weight` in zwei Gruppen zu `weight_bin` aufgeteilt. Hier siehst du sehr schön, dass der Effekt der Dichotomisierung nicht zu unterschätzen ist. Im `fit_1` ist die kontinuierliche Variable `weight` eine Risikovariable, daher wir erwarten mehr tote Fruchtfliegen mit einem steigenden Gewicht. In dem `fit_2` haben wir die dichotomisierte Variable `weight_bin` vorliegen und schon haben wir eine protektive Variable. Wenn das Gewicht steigt, dann sterben weniger Fruchtfliegen. Zwar ist in beiden Fällen die Variable nicht signifikant, aber du solltest eine Dichotomisierung immer überprüfen.
```{r}
#| message: false
fit_2 <- coxph(Surv(time, status) ~ trt + sex + weight_bin, data = fruitfly_tbl)
fit_2 |>
model_parameters(exponentiate = TRUE)
```
Nachdem wir ein Cox Proportional-Hazards Modell angepasst haben, wollen wir nochmal überprüfen, ob die Modellannahmen auch passen. Insbesondere müssen wir überprüfen, ob das Risiko über die ganze Laufzeit der Studie gleich bleibt oder sich ändert. Wir testen also die *proportional hazards assumption*. Dafür können wir in R die Funktion `cox.zph()` nutzen.
```{r}
test_ph <- cox.zph(fit_2)
test_ph
```
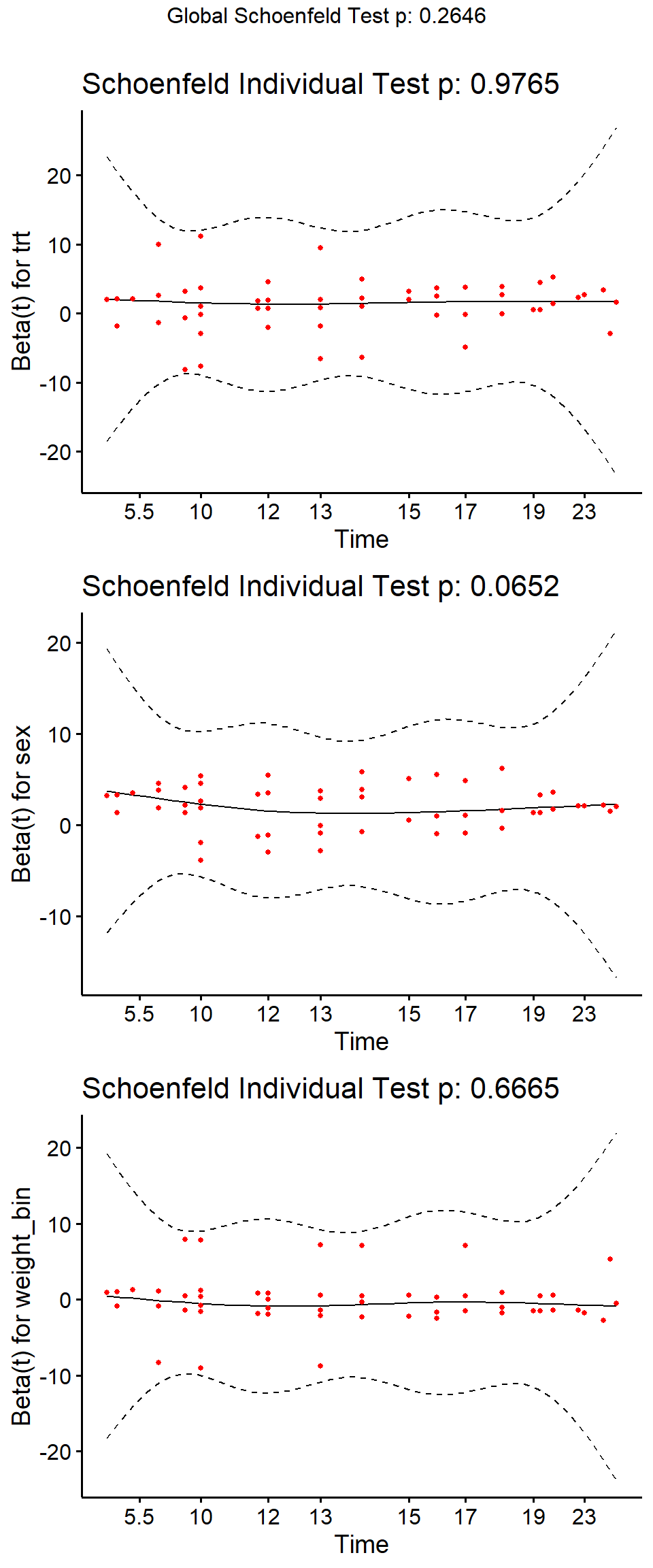
Wir lesen die Ausgabe von unten nach oben. Zuerst könne wir die *proportional hazards assumption* nicht ablehnen. Unser globaler p-Wert ist mit $0.265$ größer als das Signifikanzniveau $\alpha$ gleich $5\%$. Betrachten wir die einzelnen Variablen, dann können wir auch hier die *proportional hazards assumption* nicht ablehnen. In der @fig-surv-6 ist der Test auf die *proportional hazards assumption* nochmal visualisiert. Wenn die durchgezogene Linie innerhalb der gestrichelten Linien, als Bereich von $\pm 2$ Standardfehlern, bleibt, dann ist soweit alles in Orndung. Bei einem Verstoß gegen die *proportional hazards assumption* kannst du folgende Maßnahmen ausprobieren:
- Hinzufügen von einer Kovariate\*Zeit-Interaktion in das Cox Proportional-Hazards Modell
- Stratifizierung der Daten nach der Kovariaten, die der *proportional hazards assumption* nicht folgt
Auch hier musst du dann mal tiefer in die Materie einsteigen und einmal in den verlinkten Tutorien schauen, ob da was passendes für dein spezifisches Problem vorliegt.
```{r}
#| echo: true
#| message: false
#| warning: false
#| label: fig-surv-6
#| fig-align: center
#| fig-height: 12
#| fig-width: 5
#| fig-cap: "Visualisierung der Überprüfung der Proportional-Hazards-Annahme."
ggcoxzph(test_ph)
```
## Logistische Regression
Was schon wieder die logistische Regression? Ja, schon wieder die logistische Regression. Wenn du dich nicht mit der Ereigniszeitanalyse rumschlagen willst oder denkst, dass die Ereigniszeitanalyse nicht passt, dann hast du immer noch die Möglichkeit eine logistische Regression zu rechnen. Dafür müssen wir dann nur ein wenig an den Daten rumbasteln. Wir müssen dann nämlich eine neue Variable erschaffen. Wir schauen einfach zu einem Zeitpunkt $t$, ob die Beobachtung noch lebt. Dadurch bauen wir uns dann eine Spalte mit $0/1$ Werten. Dann kann es auch schon losgehen mit der logistischen Regression.
Im ersten Schritt bauen wir uns eine neue Variable `died_3_m` für den Lingenkrebsdatensatz. Da in einer logistsichen Regression das *Schlechte* immer 1 ist, fragen wir, wer nach 90 Tagen verstorben ist. Also eine Lebenszeit unter 90 Tagen hatte. Diese Beobachtungen kriegen dann eine 1 und die anderen Beobachtungen eine 0.
```{r}
lung_logreg_tbl <- lung_tbl |>
mutate(died_3_m = ifelse(time < 90, 1, 0))
```
Nachdem wir uns recht schnell eine neue Variable gebaut haben, können wir dann einfach die logistische Regression rechnen. Bitte beachte, dass du die Effekte nur auf der log-Scale wiedergegeben kriegst, du musst dann die Ausgabe noch exponieren. Das machen wir hier in der Funktion `model_parameters()` gleich mit.
```{r}
#| message: false
glm(died_3_m ~ age + sex + ph_ecog, data = lung_logreg_tbl, family = binomial) |>
model_parameters(exponentiate = TRUE)
```
Was sind die Unterschiede? Eine logistische Regression liefert Odds Ratios, also ein Chancenverhältnis. Aus einer Ereigniszeitanalyse erhalten wir Hazard Ratios, was eher ein Risk Ratio ist und somit eine Wahrscheinlichkeit. Deshalb lassen sich die Ergebnisse an der Stelle nur bedingt vergleichen. Im Falle der logistischen Regression fallen auch Zensierungen weg. Wir betrachten eben nur *einen einzigen* Zeitpunkt. In der Ereigniszeitanalyse betrachten wir hingegen den gesamten Verlauf. Wir immer musst du überlegen, was ist deine Fragestellung und was möchtest du berichten. Wenn es dir wirklich nur um den Zeitpunkt $t$ geht und dir die Progression dahin oder danach egal ist, dann mag die logistische Regression auch eine Möglichkeit der Auswertung sein.
## Discrete Time Survival Analysis
::: callout-caution
## Stand des Abschnitts
{fig-align="center" width="50%"}
Das Thema *Discrete Time Survival Analysis* ist erstmal auf Stand-By gesetzt, bis mir klar ist, wohin ich mit dem Abschnitt zum Ende hin will. Zentral fehlen mir aktuell die Beratungsfälle, die mir dann auch die Probleme aufzeigen, die ich lösen will. Das Thema ist einfach zu groß, deshalb erstmal hier diese Link- und Buchsammlung, die schon mal ein Ansatz ist, wenn du dich tiefer mit dem Thema auseinandersetzen willst.
:::
Einmal kurz die Idee der *discrete time survival analysis* erläutert. Wir schauen uns nicht an, wie lange es dauert bis ein Ereignis eintritt, sondern ob ein Ereignis in einem bestimmten Intervall auftritt. Die Frage ist also, ist der Krebs im $i$-ten Jahr aufgetreten? Dafür brauchen wir dann auch eine spezielle Form der Datendarstellung, nämlich *person period data*, die wir uns dann aber meistens aus normalen Überlebenszeitdaten bauen können. Da gibt es dann eine Reihe von Funktion in R für die Umwandlung zu *person period data*.
Einmal bitte auch @suresh2022survival anschauen mit der Veröffentlichung [Survival prediction models: an introduction to discrete-time modeling](https://bmcmedresmethodol.biomedcentral.com/articles/10.1186/s12874-022-01679-6). Dann gibt es noch zwei Tutorien, die ich dann nochmal aufarbeiten muss.
- [Event History Analysis - Example 6 - Discrete Time Hazard Model](https://rpubs.com/corey_sparks/63112)
- [Intro to Discrete-Time Survival Analysis in R](https://www.rensvandeschoot.com/tutorials/discrete-time-survival/)
## Referenzen {.unnumbered}