“Make use of time, let not advantage slip.” — William Shakespeare
In diesem Kapitel wollen wir uns den linearen Trendtest einmal genauer anschauen. Wir wollen uns Fragen, ober über eine Variable sich zwei oder mehr Faktoren unterscheiden. Konkret wollen wir wissen, ob sich die Sorten von Gurken über die Zeit unterschiedlich gegeben des Längenwachstums verhalten. Damit ist der Trendtest so ein wenig zwischen den Stühlen. Wenn wir eine zeitliche Kovariable betrachten, dann sind wir fast schon bei Pseudo-Zeitreihen. Wenn es dann aber nur darum gehen soll, ob wir einen Einfluss von der Kovariablen haben, dann mag es sich eher nach einer ANCOVA anfühlen. Am Ende könnten wir dann auch daran interessiert sein, ob es über die Kovariable einen Punkt gibt, wo sich das Outcome verändert. Dann wären wir eher in einer changepoint detection (deu. Änderungspunktanalyse, nicht gebräuchlich). Ich bleibe hier also erstmal bei einem Beispiel und arbeite dieses Beispiel anhand des R Paketes {emmeans} einmal ab.
Neben dem linearen Trendtest, den wir uns hier in der Anwendung in {emmeans} einmal anschauen, gibt es auch das große Feld der changepoint detection. Sharma et al. (2016) beschreibt in der Arbeit Trend analysis and change point techniques: a survey einmal einen guten Überblick über das Was und Wie. Auch helfen da die verlinkten Tutorien in dem folgenden Kasten weiter. Bis auf weiteren wird es also hier keine change point analyse geben. Eigentlich passt die change point analyse auch eher zu dem Kapitel der Zeitreihen. Wenn es hier dann Bedarf aus der Beratung gibt, kann ich dann an passender Stelle ergänzen.
TippWeitere Tutorien für den Trendtest
Wie immer gibt es auch für die Frage nach dem Tutorium für den Trendtest oder eher der change point analyse verschiedene Quellen. Ich kann noch folgende Informationen und Hilfen empfehlen.
An der Seite des Kapitels findest du den Link Quellcode anzeigen, über den du Zugang zum gesamten R-Code dieses Kapitels erhältst.
42.2 Daten
Unser zweiter Datensatz ist ein Anwendungsdatensatz aus dem Gemüsebau. Wir schauen uns das Wachstum von drei Gurkensorten über siebzehn Wochen an. Die Gurkensorten sind hier unsere Versuchsgruppen. Da wir es hier mit echten Daten zu tun haben, müssen wir uns etwas strecken damit die Daten dann auch passen. Wir wollen das Wachstum der drei Gurkensorten über die Zeit betrachten - also faktisch den Verlauf des Wachstums.
In der Tabelle 64.2 sehen wir einmal die rohen Daten dargestellt.
Tabelle 42.1— Datensatz zu dem Längen- und Dickenwachstum von Gurken.
versuchsgruppe
t1
t2
t3
t4
t5
t6
t7
t8
t9
t10
t11
t12
t13
t14
t15
t16
t17
Proloog L
5.5
6.1
7.4
8.9
9.9
12
14.4
17
19.8
21.2
23.2
24
29.7
32.8
NA
NA
NA
Proloog L
4.6
5.1
6.4
5.7
5.5
5.2
5
5
4.5
0
0
0
0
0
NA
NA
NA
Proloog L
5.3
5.8
6.8
8.3
9
10
12.3
14.6
17.6
19.3
23.1
23.8
31.7
32.3
NA
NA
NA
Proloog L
5.4
5.7
6.9
8.2
8.6
10
12.1
14.5
16.2
17.1
19.3
21.6
28.5
30
NA
NA
NA
Proloog L
5
5.5
6.3
7.5
8.3
10
12.2
14.4
16.5
19.9
21
22.9
30.4
31
NA
NA
NA
Proloog L
4.2
4.6
5.4
5.5
5.2
5.3
6.1
6.5
8
9.3
11
12.5
22.3
24.2
NA
NA
NA
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
…
Katrina D
0.62
0.64
0.65
0.65
0.74
0.9
1.07
1.09
1.18
1.09
1.13
1.14
1.3
1.48
1.75
2.02
2.97
Katrina D
0.55
0.59
0.64
0.62
0.64
0.7
0.68
0.66
0.66
0.7
0.6
0.6
0.57
0
NA
NA
NA
Katrina D
0.64
0.73
0.77
0.8
0.86
1.2
1.25
1.42
1.75
1.92
2.24
2.52
4.02
3.9
NA
NA
NA
Katrina D
0.86
0.87
0.9
1.1
1.12
1.4
1.7
2.1
2.35
2.4
2.51
2.57
4.07
4.3
NA
NA
NA
Katrina D
0.62
0.67
0.7
0.71
0.78
0.95
1.1
1.24
1.41
1.66
2.02
2.25
3.85
4.07
NA
NA
NA
Tageslänge
13.98
14.05
14.12
14.18
14.25
14.3
14.37
14.43
14.5
14.57
14.62
14.68
14.75
14.8
15.1
15.15
15.32
Wir haben zwei Typen von Daten für das Gurkenwachstum. Einmal messen wir den Durchmesser für jede Sorte (D im Namen der Versuchsgruppe) oder aber die Länge (L im Namen der Versuchsgruppe). Wir betrachten hier nur das Längenwachstum und deshalb filtern wir erstmal nach allen Versuchsgruppen mit einem L im Namen. Dann müssen wir die Daten noch in Long-Format bringen. Da wir dann auch noch auf zwei Arten die Daten über die Zeit darstellen wollen, brauchen wir einmal die Zeit als Faktor time_fct und einmal als numerisch time_num. Leider haben wir auch Gurken mit einer Länge von 0 cm. Diese Gurken schmeißen wir am Ende mal raus. Auch haben wir ab Woche 14 keine Messungen mehr in der Versuchsgruppe Prolong, also nehmen wir auch nur die Daten bis zur vierzehnten Woche.
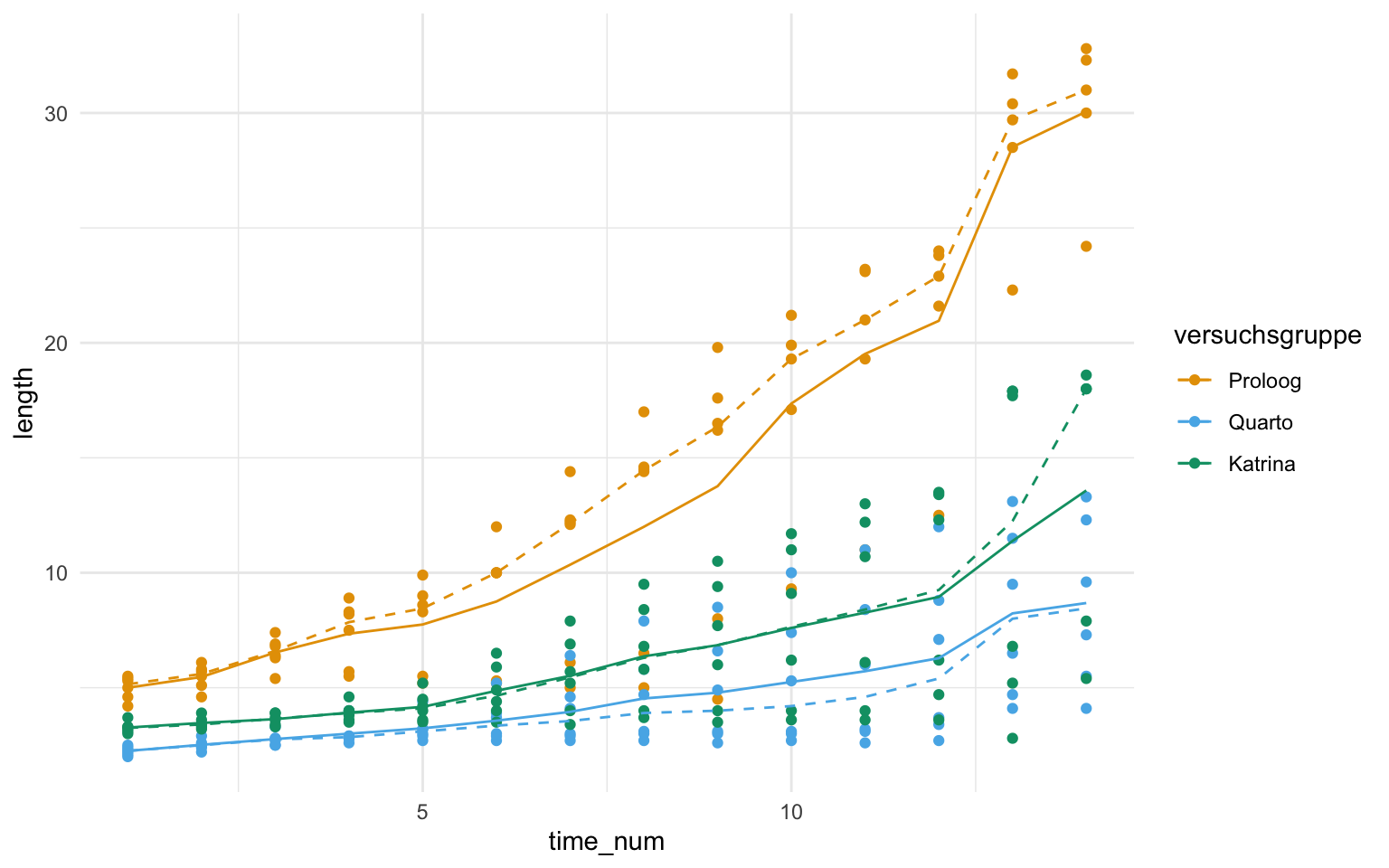
Im Folgenden schauen wir uns dann die Auswertung der Gurkendaten einmal genauer an. Für mehr Informationen zu dem Paket {emmeans} und den entsprechenden Funktionen dann bitte einmal in das Kapitel Kapitel 44 schauen. In der Abbildung 42.1 sehen wir die Daten einmal als Scatterplot. Die durchgezogene Gerade stellt den Verlauf der Mittelwerte über die Versuchsgruppen dar. Die gestrichelte Linie zeigt den Median über die Gruppen. Wir wollen jetzt der Frage nachgehen, ob es einen Unterschied zwischen den Gurkensorten versuchsgruppen über den zeitlichen Verlauf der vierzehn Wochen gibt.
Abbildung 42.1— Scatterplot des Längenwachstums der drei Gurkensorten über vierzehn Wochen. Die gestrichtelten Linien stellen den Median und die durchgezogene Line den Mittelwert der Gruppen dar.
Unser erstes Modell was wir uns anschauen wollen ist nochmal eine klassische zweifaktorielle ANOVA mit einem Interaktionsterm. Wir wollen raus finden ob die Länge von den Gurken von den Sorten (\(f_1\)), dem zeitlichen Verlauf (\(f_2\)) und der Interaktion zwischen der Sorten und der Zeit abhängt (\(f_1:f_2\)). Wir stellen nun folgendes lineares Modell für die zweifaktorielle ANOVA auf.
Nun wollen wir auch überprüfen, ob es eine Interaktion zwischen den Versuchsgruppen und dem zeitlichen Verlauf gibt. Das ganze schauen wir uns neben einer ANOVA auch einmal graphisch mit der Funktion emmip() an. Wenn wir keine signifikante Interaktion erwarten würden, dann müssten die drei Versuchgruppe über den zeitlichen Verlauf gleichmäßig ansteigen. Wir sehen in der Abbildung 42.2, dass dies nicht der Fall ist. Wir nehmen daher eine Interaktion zwischen den Versuchsgruppen und dem zeitlichen Verlauf an.
Wir haben eben einmal die Zeit als Faktor mit ins Modell genommen, da wir so für jeden Zeitpunkt einen Mittelwert schätzen können. Wenn wir eine einfaktorielle ANCOVA rechnen, dann geht die Zeit als numerische Kovariate (\(c_1\)) linear in das Modell ein. Wir haben also von jedem Zeitpunkt zum nächsten den gleichen Anstieg. Wir modellieren ja auch einen linearen Zusammenhang. Hier einmal das Modell für die ANCOVA.
Auch hier einmal die Überprüfung auf eine Interaktion mit der ANCOVA. Wir sehen, dass wir eine signifikante Interaktion zwischen den Versuchsgruppen und dem zeitlichen verlauf vorliegen haben.
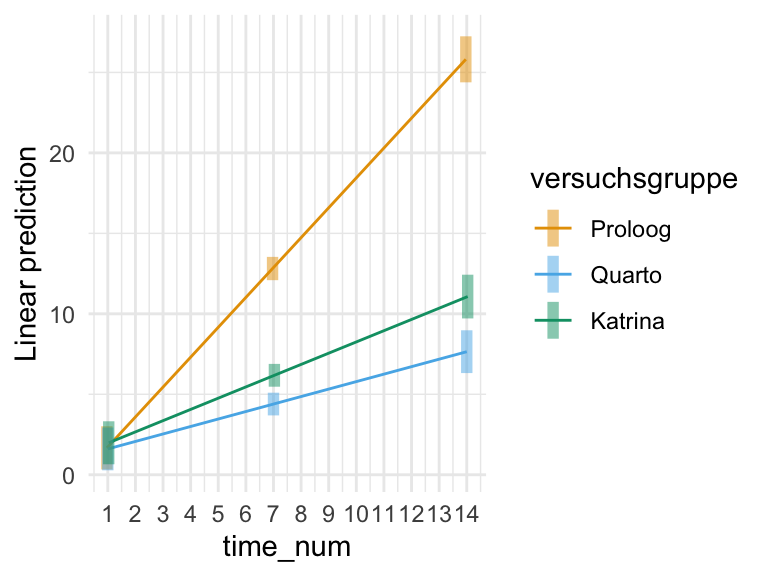
In der Abbildung 42.3 sehen wir dann nochmal das Modell im Interaktionsplot. In beiden Abbildungen sehe wir den linearen Zusammenhang. Die Interaktion drückt sich in der unterschiedlichen Steigung der Versuchsgruppen über den zeitlichen Verlauf aus. Wir können durch die Option at = entscheiden für welche Zeitpunkte wir uns die 95% Konfidenzintervalle anzeigen lassen wollen, wie in der linken Abbildung exemplarisch für die Zeitpunkte 1 Woche, 7 Wochen und 14 Wochen. Oder aber wir lassen uns alle durch die Option cov.reduce = FALSE anzeigen, wie in der rechten Abbildung gezeigt.
Abbildung 42.3— Interaktionsplot über den zeitlichen Verlauf für alle drei Sorten.
Jetzt kommt eigentlich der spannende Teil, wir wollen jetzt über den zeitlichen Verlauf einen statistischen Test rechnen, ob wir einen Trend in den verschiedenen Versuchsgruppen haben. Wir rechnen also einen Trendtest über die Kovariate \(c_1\) für die drei Gruppen getrennt. Das können wir mit der Funktion emtrends() durchführen. Hier musst du angeben welche deine Kovariate var ist. In unserem Fall ist die Kovariate natürlich time_num.
R Code [zeigen / verbergen]
emtrends(time_num_fit, ~ versuchsgruppe, var ="time_num", infer =TRUE)
Die Spalte time_num.trend zeigt uns jetzt den linearen Anstieg über die Zeit für die jeweilige Versuchsgruppe. Das heißt jede Woche wächst die Sorte Proloog um \(1.857cm\) an Länge. In der gleichen Art können wir auch die anderen Werte in der Spalte interpretieren. Jetzt stellt sich natürlich die Frage, ob dieses Längenwachstum untereinander unterschiedlich ist. Dafür könne wir dann leicht den Code abändern und setzen das Wort pairwise vor die Tilde. Dann testet die Funktion auch alle paarweisen Vergleiche. Wir nutzen jetzt noch die Funktion model_parameters() um eine schönere Ausgabe zu erhalten.
R Code [zeigen / verbergen]
emtrends(time_num_fit, pairwise ~ versuchsgruppe, var ="time_num", infer =TRUE) |>model_parameters()
Wir sehen wieder erst die Trends, die kennen wir schon. Dann sehen wir die Kontraste oder auch paarweisen Vergleiche. Das kannst du schnelle nachrechnen, der Unterschied von Proloog zu Quarto ist \(1.48 - 0.45 = 1.03\). Damit können wir dann auch über den gesamten zeitlichen Verlauf testen, ob ein Unterschied zwischen den Sorten vorliegt.
Wir sind jetzt schon sehr weit gekommen, aber wir könnten auch einen nicht-linearen Zusammenhang zwsichen der Zeit und dem Längenwachstum von Gurken annehmen. Das würde auch biologisch etwas mehr Sinn ergeben. Deshalb modellieren wir den Einfluss der Zeit time_num durch einen Exponenten hoch drei. Daher schreiben wir mathematisch \((time\_num)^3\).
Den Exponenten schreiben wir dann entsprechend in R mit poly(time_num, 3) in die Formel. Die Funktion poly() nutzen wir innerhalb von Formelaufrufen um einen Exponenten einzufügen.
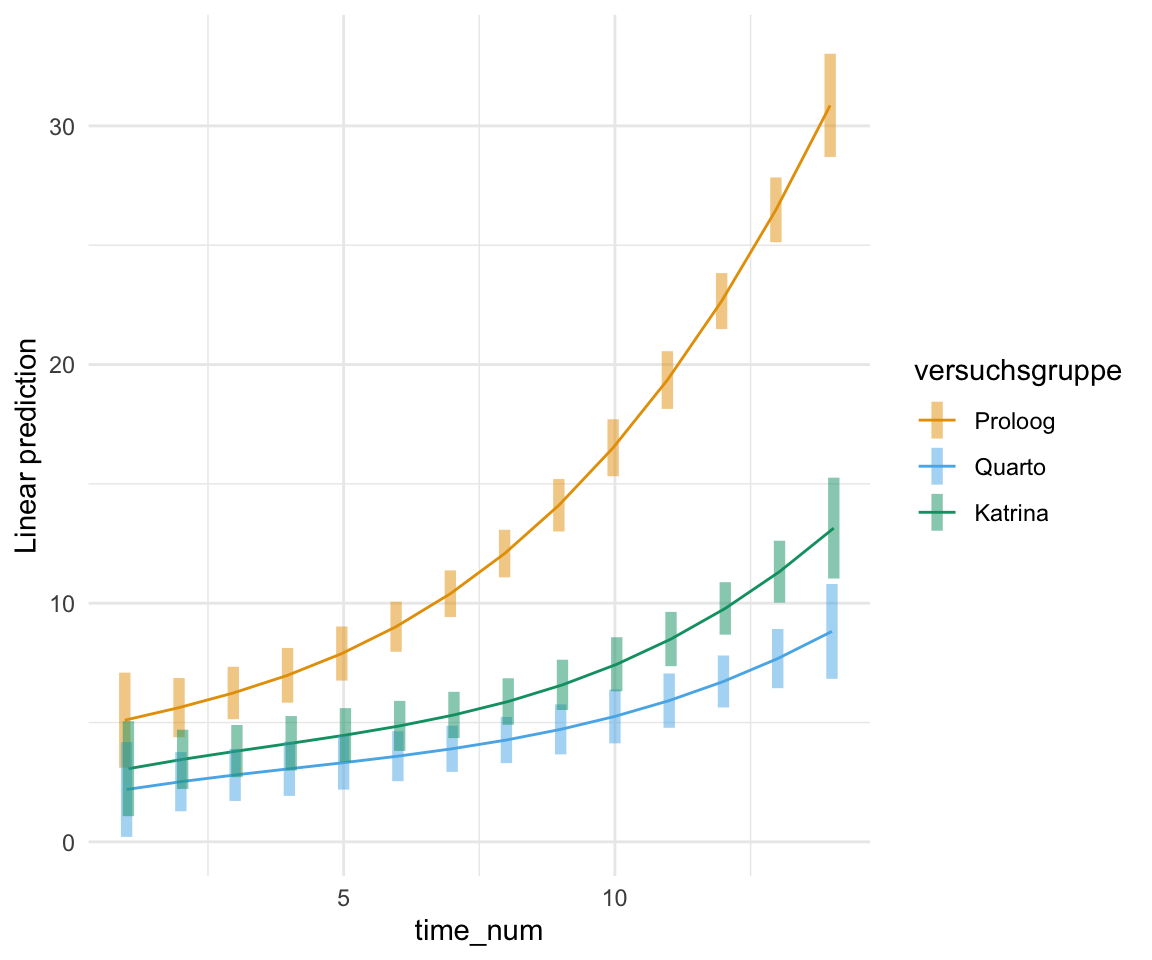
In der Abbildung 42.4 sehen wir dann nochmal die Anpassung des Modells und wir sehen, dass unser Modell besser zu den Daten passt. Das sieht schon sehr viel sauberer aus, als der brutale lineare Zusammenhang, den wir vorher hatten. Du musst hier etwas mit den Exponenten spielen und ausprobieren, welcher da am besten passt.
Abbildung 42.4— Interaktionsplot über den zeitlichen Verlauf für alle drei Sorten mit einer kubischen Anpassung der Regression.
Jetzt wollen wir die Analyse nochmal auf die Spitze treiben. Wir schauen uns jetzt an den Zeitpunkten 1 Woche, 7 Wochen und 14 Wochen den Unterschied zwischen den Sorten einmal an. Das machen wir indem wir zu der Funktion emmeans() die Optione at = list(time_num = c(1, 7, 14)) ergänzen. Am Ende lassen wir uns noch das compact letter display wiedergeben.
time_num = 1:
versuchsgruppe emmean SE df lower.CL upper.CL .group
Quarto 2.20 1.010 234 0.209 4.18 a
Katrina 3.07 1.010 234 1.077 5.05 a
Proloog 5.10 1.010 234 3.106 7.09 a
time_num = 7:
versuchsgruppe emmean SE df lower.CL upper.CL .group
Quarto 3.90 0.492 234 2.932 4.87 a
Katrina 5.32 0.492 234 4.348 6.29 a
Proloog 10.40 0.496 234 9.421 11.38 b
time_num = 14:
versuchsgruppe emmean SE df lower.CL upper.CL .group
Quarto 8.82 1.010 234 6.832 10.80 a
Katrina 13.15 1.070 234 11.033 15.26 b
Proloog 30.86 1.100 234 28.698 33.02 c
Confidence level used: 0.95
P value adjustment: tukey method for comparing a family of 3 estimates
significance level used: alpha = 0.05
NOTE: If two or more means share the same grouping symbol,
then we cannot show them to be different.
But we also did not show them to be the same.
Was erkennen wir? Wir sehen, dass sich in der ersten Woche die Sorten noch nicht voneinander unterscheiden. Erst in der Woche sieben sehen wir einen Unterschied von Proloog zu dem Rest der Sorten. In der letzten Woche unterscheiden sich dann alle Sorten voneinander. Wie stark, kannst du aus der Spalte emmean entnehmen, dort steht der Mittelwert für die jeweilige Sorte zu dem jeweiligen Zeitpunkt.
Abschließend wollen wir nochmal schauen, wie sich der Trend in den verschiedenen Modellierungen der Exponenten zeigen würde. Wir müssen dafür bei der Funktion emtrends() angeben bis zu welchen maximalen Exponenten, bei uns hoch Drei, die Funktion rechnen soll. Deshalb setzen wir max.degree = 3. Dann noch pairwise vor die Tilde gesetzt, damit wir dann auch die paarweisen Vergleiche für die Sorten und Verläufe angezeigt kriegen. Achtung, jetzt kommt eine lange Ausgabe.
R Code [zeigen / verbergen]
emtrends(time_num_poly_fit, pairwise ~ versuchsgruppe, var ="time_num", infer =TRUE,max.degree =3)
Was sehen wir in diesem Fall? In der linearen Modellierung der Zeit haben wir sehr viele signifikante Ergebnisse. Leider entspricht der lineare verlauf über die Zeit nicht so den beobachteten Daten. Bei der kubischen Modellierung, also hoch Drei, haben wir dann in der Abbildung eine bessere Modellierung. Die Effekte reichen dann aber nicht aus um über den gesamten zeitlichen Verlauf, Betonung liegt auf dem gesamten zeitlichen Verlauf, einen Unterschied zeigen zu können.
Daher müsste man hier einmal überlegen, ob man nicht die frühen Wochen aus den Daten entfernt. Hier sind die Gurlen noch sehr ähnlich, so dass wir hier eigentlich auch keinen Unterschied erwarten. Sonst könntest du nochmal mit einer \(\log\)-Transformation der Länge spielen, dann verlierst du zwar die direkte biologische Interpretierbarkeit der Effektschätzer, aber dafür könnte der Verlauf über die Zeit besser aufgesplittet werden. Das Problem sind ja hier sehr kleine Werte zu Anfang und sehr große Werte zum Ende.
42.4 Change point detection
VorsichtStand des Abschnitts
Das Thema Change point detection ist erstmal auf Stand-By gesetzt, bis mir klar ist, wohin ich mit dem Abschnitt zum Ende hin will. Zentral fehlen mir aktuell die Beratungsfälle, die mir dann auch die Probleme aufzeigen, die ich lösen will. Das Thema ist einfach zu groß. Wenn du also hier reingestolpert bist, dann schreibe mir einfach eine Mail, dann geht es auch hier weiter. Vorerst bleibt es dann bei einem Stopp.
Referenzen
Sharma, S., Swayne, D. A., & Obimbo, C. (2016). Trend analysis and change point techniques: a survey. Energy, Ecology and Environment, 1, 123–130.
Quellcode
```{r echo = FALSE}pacman::p_load(tidyverse, readxl, knitr, kableExtra, Hmisc)```# Der Trendtest {#sec-trendtest}*Letzte Änderung am `r format(fs::file_info("stat-tests-trendtest.qmd")$modification_time, '%d. %B %Y um %H:%M:%S')`*> *"Make use of time, let not advantage slip." --- William Shakespeare*In diesem Kapitel wollen wir uns den linearen Trendtest einmal genauer anschauen. Wir wollen uns Fragen, ober über eine Variable sich zwei oder mehr Faktoren unterscheiden. Konkret wollen wir wissen, ob sich die Sorten von Gurken über die Zeit unterschiedlich gegeben des Längenwachstums verhalten. Damit ist der Trendtest so ein wenig zwischen den Stühlen. Wenn wir eine zeitliche Kovariable betrachten, dann sind wir fast schon bei [Pseudo-Zeitreihen](#sec-pseudo-time-series). Wenn es dann aber nur darum gehen soll, ob wir einen Einfluss von der Kovariablen haben, dann mag es sich eher nach einer [ANCOVA](#sec-ancova) anfühlen. Am Ende könnten wir dann auch daran interessiert sein, ob es über die Kovariable einen Punkt gibt, wo sich das Outcome verändert. Dann wären wir eher in einer *changepoint detection* (deu. *Änderungspunktanalyse*, nicht gebräuchlich). Ich bleibe hier also erstmal bei einem Beispiel und arbeite dieses Beispiel anhand des R Paketes `{emmeans}` einmal ab.Neben dem linearen Trendtest, den wir uns hier in der Anwendung in `{emmeans}` einmal anschauen, gibt es auch das große Feld der *changepoint detection*. @sharma2016trend beschreibt in der Arbeit [Trend analysis and change point techniques: a survey](https://link.springer.com/article/10.1007/s40974-016-0011-1) einmal einen guten Überblick über das Was und Wie. Auch helfen da die verlinkten Tutorien in dem folgenden Kasten weiter. Bis auf weiteren wird es also hier keine *change point analyse* geben. Eigentlich passt die *change point analyse* auch eher zu dem [Kapitel der Zeitreihen](#sec-time-series). Wenn es hier dann Bedarf aus der Beratung gibt, kann ich dann an passender Stelle ergänzen.::: callout-tip## Weitere Tutorien für den TrendtestWie immer gibt es auch für die Frage nach dem Tutorium für den Trendtest oder eher der *change point analyse* verschiedene Quellen. Ich kann noch folgende Informationen und Hilfen empfehlen.- [How to Perform a Mann-Kendall Trend Test in R](https://www.geeksforgeeks.org/how-to-perform-a-mann-kendall-trend-test-in-r/) beschreibt nochmal einen Test für einen linearen Trend in einer Zeitreihe.- [Test for Trend in Proportions](https://rpkgs.datanovia.com/rstatix/reference/prop_trend_test.html) testet, ob sich ein Trend in Wahrscheinlichkeiten bzw. Anteilen finden lässt.- [Das R Paket `{trend}`](https://cran.r-project.org/web/packages/trend/trend.pdf) liefert *die* Übersicht an Funktionen für eine *change point analyse*.:::## Genutzte R PaketeWir wollen folgende R Pakete in diesem Kapitel nutzen.```{r echo = TRUE}#| message: falsepacman::p_load(tidyverse, magrittr, broom, quantreg, see, performance, emmeans, multcomp, janitor, parameters, conflicted)conflicts_prefer(dplyr::select)conflicts_prefer(dplyr::filter)cbbPalette <-c("#000000", "#E69F00", "#56B4E9", "#009E73", "#F0E442", "#0072B2", "#D55E00", "#CC79A7")```An der Seite des Kapitels findest du den Link *Quellcode anzeigen*, über den du Zugang zum gesamten R-Code dieses Kapitels erhältst.## DatenUnser zweiter Datensatz ist ein Anwendungsdatensatz aus dem Gemüsebau. Wir schauen uns das Wachstum von drei Gurkensorten über siebzehn Wochen an. Die Gurkensorten sind hier unsere Versuchsgruppen. Da wir es hier mit echten Daten zu tun haben, müssen wir uns etwas strecken damit die Daten dann auch passen. Wir wollen das Wachstum der drei Gurkensorten *über* die Zeit betrachten - also faktisch den Verlauf des Wachstums.```{r}#| message: false#| warning: falsegurke_raw_tbl <-read_excel("data/wachstum_gurke.xlsx") |>clean_names() |>select(-pfl, -erntegewicht) |>mutate(versuchsgruppe =as_factor(versuchsgruppe)) ```In der @tbl-model-2 sehen wir einmal die rohen Daten dargestellt.```{r}#| message: false#| echo: false#| tbl-cap: "Datensatz zu dem Längen- und Dickenwachstum von Gurken."#| label: tbl-model-2ancova_raw_2_tbl <- gurke_raw_tbl |>mutate(versuchsgruppe =as.character(versuchsgruppe))rbind(head(ancova_raw_2_tbl),rep("...", times =ncol(ancova_raw_2_tbl)),tail(ancova_raw_2_tbl)) |>kable(align ="c", "pipe")```Wir haben zwei Typen von Daten für das Gurkenwachstum. Einmal messen wir den Durchmesser für jede Sorte (`D` im Namen der Versuchsgruppe) oder aber die Länge (`L` im Namen der Versuchsgruppe). Wir betrachten hier nur das Längenwachstum und deshalb filtern wir erstmal nach allen Versuchsgruppen mit einem `L` im Namen. Dann müssen wir die Daten noch in Long-Format bringen. Da wir dann auch noch auf zwei Arten die Daten über die Zeit darstellen wollen, brauchen wir einmal die Zeit als Faktor `time_fct` und einmal als numerisch `time_num`. Leider haben wir auch Gurken mit einer Länge von 0 cm. Diese Gurken schmeißen wir am Ende mal raus. Auch haben wir ab Woche 14 keine Messungen mehr in der Versuchsgruppe `Prolong`, also nehmen wir auch nur die Daten bis zur vierzehnten Woche.```{r}gurke_time_len_tbl <- gurke_raw_tbl |>filter(str_detect(versuchsgruppe, "L$")) |>mutate(versuchsgruppe =factor(versuchsgruppe, labels =c("Proloog", "Quarto", "Katrina"))) |>pivot_longer(cols = t1:t17,values_to ="length",names_to ="time") |>mutate(time_fct =as_factor(time),time_num =as.numeric(time_fct)) |>filter(length !=0) |>filter(time_num <=14)```## Der Trendtest in RIm Folgenden schauen wir uns dann die Auswertung der Gurkendaten einmal genauer an. Für mehr Informationen zu dem Paket `{emmeans}` und den entsprechenden Funktionen dann bitte einmal in das Kapitel @sec-posthoc schauen. In der @fig-ancova-gurke-03 sehen wir die Daten einmal als Scatterplot. Die durchgezogene Gerade stellt den Verlauf der Mittelwerte über die Versuchsgruppen dar. Die gestrichelte Linie zeigt den Median über die Gruppen. Wir wollen jetzt der Frage nachgehen, ob es einen Unterschied zwischen den Gurkensorten `versuchsgruppen` über den zeitlichen Verlauf der vierzehn Wochen gibt.```{r}#| echo: true#| message: false#| warning: false#| label: fig-ancova-gurke-03#| fig-align: center#| fig-height: 5#| fig-width: 8#| fig-cap: "Scatterplot des Längenwachstums der drei Gurkensorten über vierzehn Wochen. Die gestrichtelten Linien stellen den Median und die durchgezogene Line den Mittelwert der Gruppen dar."ggplot(gurke_time_len_tbl, aes(time_num, length, color = versuchsgruppe)) +theme_minimal() +geom_point() +stat_summary(fun ="mean", geom ="line") +stat_summary(fun ="median", geom ="line", linetype =2) +scale_color_okabeito()```Unser erstes Modell was wir uns anschauen wollen ist nochmal eine klassische zweifaktorielle ANOVA mit einem Interaktionsterm. Wir wollen raus finden ob die Länge von den Gurken von den Sorten ($f_1$), dem zeitlichen Verlauf ($f_2$) und der Interaktion zwischen der Sorten und der Zeit abhängt ($f_1:f_2$). Wir stellen nun folgendes lineares Modell für die zweifaktorielle ANOVA auf.$$length \sim \overbrace{versuchsgruppe}^{f_1} + \underbrace{time\_fct}_{f_2} + \overbrace{versuchsgruppe:time\_fct}^{f_1:f_2}$$Dieses Modell können wir dann auch in R einmal über die Funktion `lm()` abbilden.```{r}#| message: false#| warning: falsetime_fct_fit <-lm(length ~ versuchsgruppe + time_fct + versuchsgruppe:time_fct, gurke_time_len_tbl)```Nun wollen wir auch überprüfen, ob es eine Interaktion zwischen den Versuchsgruppen und dem zeitlichen Verlauf gibt. Das ganze schauen wir uns neben einer ANOVA auch einmal graphisch mit der Funktion `emmip()` an. Wenn wir keine signifikante Interaktion erwarten würden, dann müssten die drei Versuchgruppe über den zeitlichen Verlauf gleichmäßig ansteigen. Wir sehen in der @fig-stat-ancova-08, dass dies nicht der Fall ist. Wir nehmen daher eine Interaktion zwischen den Versuchsgruppen und dem zeitlichen Verlauf an.```{r}#| message: false#| echo: true#| warning: false#| fig-align: center#| fig-height: 5#| fig-width: 6#| fig-cap: Interaktionsplot über den zeitlichen Verlauf für alle drei Sorten.#| label: fig-stat-ancova-08emmip(time_fct_fit, versuchsgruppe ~ time_fct, CIs =TRUE) +theme_minimal() +scale_color_okabeito()```Nochmal kurz mit der ANOVA überprüft und wir sehen eine signifikante Interaktion.```{r}#| message: false#| warning: falsetime_fct_fit |>anova() |>model_parameters()```Wir haben eben einmal die Zeit als Faktor mit ins Modell genommen, da wir so für jeden Zeitpunkt einen Mittelwert schätzen können. Wenn wir eine einfaktorielle ANCOVA rechnen, dann geht die Zeit als numerische Kovariate ($c_1$) linear in das Modell ein. Wir haben also von jedem Zeitpunkt zum nächsten den gleichen Anstieg. Wir modellieren ja auch einen linearen Zusammenhang. Hier einmal das Modell für die ANCOVA.$$length \sim \overbrace{versuchsgruppe}^{f_1} + \underbrace{time\_num}_{c_1} + \overbrace{versuchsgruppe:time\_num}^{f_1:c_1}$$Wir fitten wieder das Modell in R mit der Funktion `lm()`.```{r}time_num_fit <-lm(length ~ versuchsgruppe + time_num + versuchsgruppe:time_num, gurke_time_len_tbl)```Auch hier einmal die Überprüfung auf eine Interaktion mit der ANCOVA. Wir sehen, dass wir eine signifikante Interaktion zwischen den Versuchsgruppen und dem zeitlichen verlauf vorliegen haben.```{r}time_num_fit |>anova() |>model_parameters()```In der @fig-stat-ancova-05 sehen wir dann nochmal das Modell im Interaktionsplot. In beiden Abbildungen sehe wir den linearen Zusammenhang. Die Interaktion drückt sich in der unterschiedlichen Steigung der Versuchsgruppen über den zeitlichen Verlauf aus. Wir können durch die Option `at =` entscheiden für welche Zeitpunkte wir uns die 95% Konfidenzintervalle anzeigen lassen wollen, wie in der linken Abbildung exemplarisch für die Zeitpunkte 1 Woche, 7 Wochen und 14 Wochen. Oder aber wir lassen uns alle durch die Option `cov.reduce = FALSE` anzeigen, wie in der rechten Abbildung gezeigt.```{r}#| message: false#| echo: true#| warning: false#| fig-align: center#| fig-height: 3#| fig-width: 4#| label: fig-stat-ancova-05#| fig-cap: "Interaktionsplot über den zeitlichen Verlauf für alle drei Sorten."#| fig-subcap: #| - "An drei Zeitpunkten."#| - "Über alle Zeitpunkte."#| layout-nrow: 1emmip(time_num_fit, versuchsgruppe ~ time_num, CIs =TRUE, at =list(time_num =c(1, 7, 14))) +theme_minimal() +scale_x_continuous(breaks =1:14) +scale_color_okabeito()emmip(time_num_fit, versuchsgruppe ~ time_num, CIs =TRUE, cov.reduce =FALSE) +theme_minimal() +scale_x_continuous(breaks =1:14) +scale_color_okabeito()```Jetzt kommt eigentlich der spannende Teil, wir wollen jetzt über den zeitlichen Verlauf einen statistischen Test rechnen, ob wir einen Trend in den verschiedenen Versuchsgruppen haben. Wir rechnen also einen Trendtest über die Kovariate $c_1$ für die drei Gruppen getrennt. Das können wir mit der Funktion `emtrends()` durchführen. Hier musst du angeben welche deine Kovariate `var` ist. In unserem Fall ist die Kovariate natürlich `time_num`.```{r}emtrends(time_num_fit, ~ versuchsgruppe, var ="time_num", infer =TRUE)```Die Spalte `time_num.trend` zeigt uns jetzt den linearen Anstieg über die Zeit für die jeweilige Versuchsgruppe. Das heißt jede Woche wächst die Sorte Proloog um $1.857cm$ an Länge. In der gleichen Art können wir auch die anderen Werte in der Spalte interpretieren. Jetzt stellt sich natürlich die Frage, ob dieses Längenwachstum *untereinander* unterschiedlich ist. Dafür könne wir dann leicht den Code abändern und setzen das Wort `pairwise` vor die Tilde. Dann testet die Funktion auch alle paarweisen Vergleiche. Wir nutzen jetzt noch die Funktion `model_parameters()` um eine schönere Ausgabe zu erhalten.```{r}emtrends(time_num_fit, pairwise ~ versuchsgruppe, var ="time_num", infer =TRUE) |>model_parameters()```Wir sehen wieder erst die Trends, die kennen wir schon. Dann sehen wir die Kontraste oder auch paarweisen Vergleiche. Das kannst du schnelle nachrechnen, der Unterschied von Proloog zu Quarto ist $1.48 - 0.45 = 1.03$. Damit können wir dann auch über den *gesamten* zeitlichen Verlauf testen, ob ein Unterschied zwischen den Sorten vorliegt.Wir sind jetzt schon sehr weit gekommen, aber wir könnten auch einen nicht-linearen Zusammenhang zwsichen der Zeit und dem Längenwachstum von Gurken annehmen. Das würde auch biologisch etwas mehr Sinn ergeben. Deshalb modellieren wir den Einfluss der Zeit `time_num` durch einen Exponenten hoch drei. Daher schreiben wir mathematisch $(time\_num)^3$.$$length \sim \overbrace{versuchsgruppe}^{f_1} + \underbrace{(time\_num)^3}_{c_1} + \overbrace{versuchsgruppe:(time\_num)^3}^{f_1:c_1}$$Den Exponenten schreiben wir dann entsprechend in R mit `poly(time_num, 3)` in die Formel. Die Funktion `poly()` nutzen wir innerhalb von Formelaufrufen um einen Exponenten einzufügen.```{r}time_num_poly_fit <-lm(length ~ versuchsgruppe *poly(time_num, 3), gurke_time_len_tbl)```In der @fig-stat-ancova-06 sehen wir dann nochmal die Anpassung des Modells und wir sehen, dass unser Modell besser zu den Daten passt. Das sieht schon sehr viel sauberer aus, als der brutale lineare Zusammenhang, den wir vorher hatten. Du musst hier etwas mit den Exponenten spielen und ausprobieren, welcher da am besten passt.```{r}#| message: false#| echo: true#| warning: false#| fig-align: center#| fig-height: 5#| fig-width: 6#| fig-cap: Interaktionsplot über den zeitlichen Verlauf für alle drei Sorten mit einer kubischen Anpassung der Regression.#| label: fig-stat-ancova-06emmip(time_num_poly_fit, versuchsgruppe ~ time_num, CIs =TRUE, cov.reduce =FALSE) +theme_minimal() +scale_color_okabeito()```Jetzt wollen wir die Analyse nochmal auf die Spitze treiben. Wir schauen uns jetzt an den Zeitpunkten 1 Woche, 7 Wochen und 14 Wochen den Unterschied zwischen den Sorten einmal an. Das machen wir indem wir zu der Funktion `emmeans()` die Optione `at = list(time_num = c(1, 7, 14))` ergänzen. Am Ende lassen wir uns noch das *compact letter display* wiedergeben.```{r}emmeans(time_num_poly_fit, pairwise ~ versuchsgruppe | time_num, at =list(time_num =c(1, 7, 14))) |>cld(Letters = letters) ```Was erkennen wir? Wir sehen, dass sich in der ersten Woche die Sorten noch nicht voneinander unterscheiden. Erst in der Woche sieben sehen wir einen Unterschied von Proloog zu dem Rest der Sorten. In der letzten Woche unterscheiden sich dann alle Sorten voneinander. Wie stark, kannst du aus der Spalte `emmean` entnehmen, dort steht der Mittelwert für die jeweilige Sorte zu dem jeweiligen Zeitpunkt.Abschließend wollen wir nochmal schauen, wie sich der Trend in den verschiedenen Modellierungen der Exponenten zeigen würde. Wir müssen dafür bei der Funktion `emtrends()` angeben bis zu welchen maximalen Exponenten, bei uns hoch Drei, die Funktion rechnen soll. Deshalb setzen wir `max.degree = 3`. Dann noch `pairwise` vor die Tilde gesetzt, damit wir dann auch die paarweisen Vergleiche für die Sorten und Verläufe angezeigt kriegen. Achtung, jetzt kommt eine lange Ausgabe.```{r}emtrends(time_num_poly_fit, pairwise ~ versuchsgruppe, var ="time_num", infer =TRUE,max.degree =3) ```Was sehen wir in diesem Fall? In der linearen Modellierung der Zeit haben wir sehr viele signifikante Ergebnisse. Leider entspricht der lineare verlauf über die Zeit nicht so den beobachteten Daten. Bei der kubischen Modellierung, also hoch Drei, haben wir dann in der Abbildung eine bessere Modellierung. Die Effekte reichen dann aber nicht aus um über den gesamten zeitlichen Verlauf, Betonung liegt auf dem gesamten zeitlichen Verlauf, einen Unterschied zeigen zu können.Daher müsste man hier einmal überlegen, ob man nicht die frühen Wochen aus den Daten entfernt. Hier sind die Gurlen noch sehr ähnlich, so dass wir hier eigentlich auch keinen Unterschied erwarten. Sonst könntest du nochmal mit einer $\log$-Transformation der Länge spielen, dann verlierst du zwar die direkte biologische Interpretierbarkeit der Effektschätzer, aber dafür könnte der Verlauf über die Zeit *besser* aufgesplittet werden. Das Problem sind ja hier sehr kleine Werte zu Anfang und sehr große Werte zum Ende.## Change point detection::: callout-caution## Stand des Abschnitts{fig-align="center" width="50%"}Das Thema *Change point detection* ist erstmal auf Stand-By gesetzt, bis mir klar ist, wohin ich mit dem Abschnitt zum Ende hin will. Zentral fehlen mir aktuell die Beratungsfälle, die mir dann auch die Probleme aufzeigen, die ich lösen will. Das Thema ist einfach zu groß. Wenn du also hier reingestolpert bist, dann schreibe mir einfach eine Mail, dann geht es auch hier weiter. Vorerst bleibt es dann bei einem Stopp.:::## Referenzen {.unnumbered}