```{r echo = FALSE}
#| message: false
#| warning: false
pacman::p_load(tidyverse, readxl, knitr, kableExtra, Hmisc, performance, parameters,
latex2exp, see, patchwork, mfp, multcomp, emmeans, janitor, effectsize,
broom, ggmosaic, ggrepel,
conflicted)
conflicts_prefer(dplyr::select)
conflicts_prefer(dplyr::filter)
cb_pal <- c("#000000", "#E69F00", "#56B4E9",
"#009E73", "#F0E442", "#F5C710",
"#0072B2", "#D55E00", "#CC79A7")
cbbPalette <- cb_pal
theme_modeling <- function() {
theme_minimal() +
theme(panel.grid.minor = element_blank(),
plot.background = element_rect(fill = "white", color = NA),
plot.title = element_text(size = 16, face = "bold"),
plot.subtitle = element_text(size = 12, face = "italic"),
plot.caption = element_text(face = "italic"),
axis.title = element_text(size = 12, face = "bold"),
axis.text = element_text(size = 12),
legend.title = element_text(face = "bold"),
strip.text = element_text(face = "bold"),
strip.background = element_rect(fill = "grey80", color = NA))
}
```
# Spielecke {#sec-spielecke}
*Letzte Änderung am `r format(fs::file_info("app-spielecke.qmd")$modification_time, '%d. %B %Y um %H:%M:%S')`*
> *"Denn, um es endlich auf einmal herauszusagen, der Mensch spielt nur, wo er in voller Bedeutung des Worts Mensch ist, und er ist nur da ganz Mensch, wo er spielt." --- Friedrich Schiller*
{fig-align="center" width="100%"}
Dieses Kapitel ist meine Spielecke, wo ich Ideen und sonst so Zeug sammele, was mir über den Weg läuft und ich noch nicht so richtig weiter im Skript eingeordnet habe. Deshalb hat das hier auch keine Struktur, da mir die Gedanken eben auch noch wirr durch den Kopf geistern.
## Mixed data {.unnumbered}
```{r}
o2_tbl <- read_excel("data/sauerstoffmangel.xlsx") |>
pivot_longer(cols = t0_height:last_col(),
values_to = "height",
names_to = c("time", "outcome"),
names_sep = "_") |>
mutate(light = as_factor(light),
water_level = as_factor(water_level),
time_fct = as_factor(time),
time_num = as.numeric(time_fct) - 1) |>
select(id, light, water_level, time_fct, time_num, height)
```
```{r}
#| echo: true
#| message: false
#| warning: false
#| label: fig-anwendung-o2-01
#| fig-align: center
#| fig-height: 5.5
#| fig-width: 11
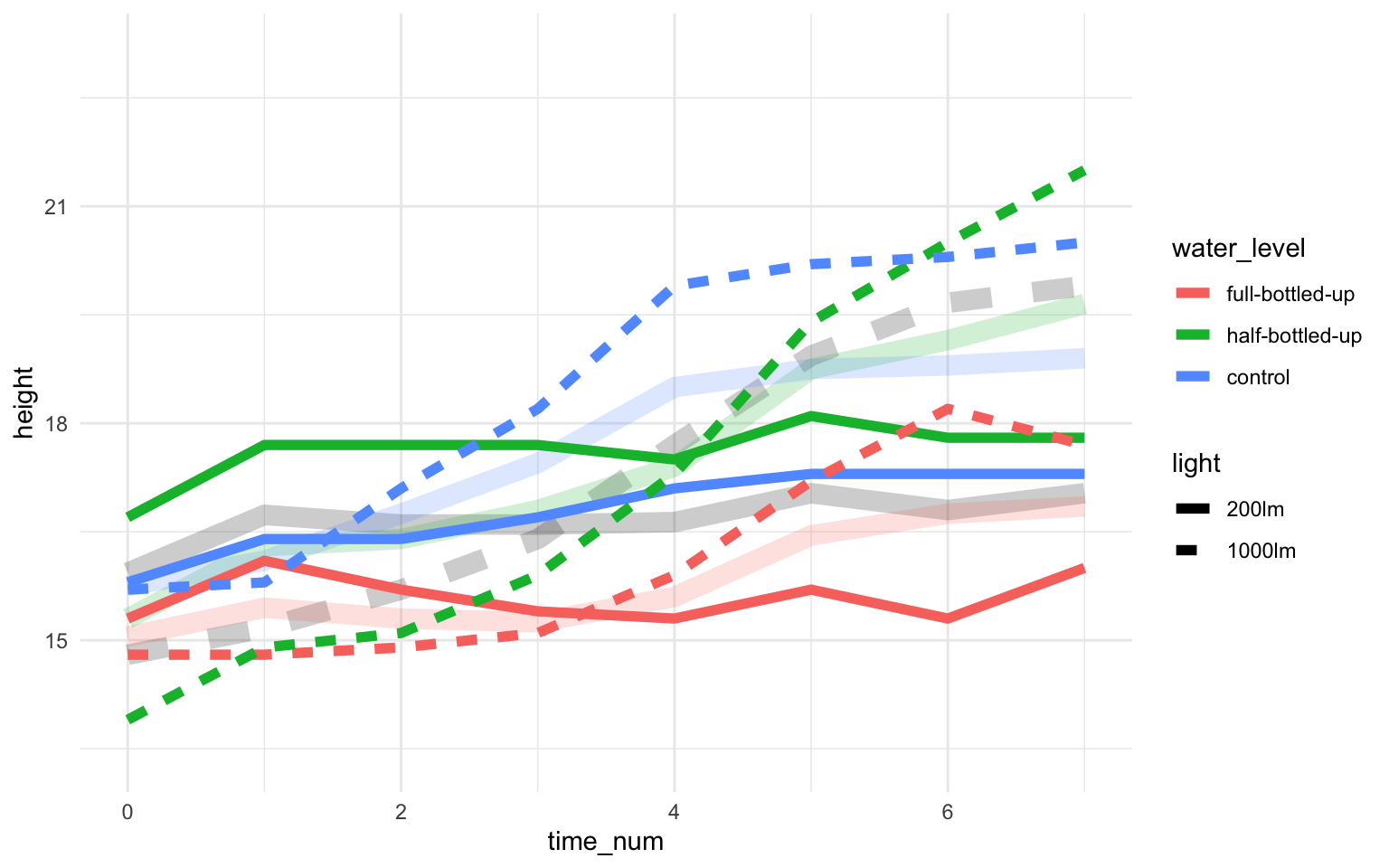
#| fig-cap: "Boxplot des Fruchtwachstums von fünfzehn Tomatensorten über zehn Wochen unter Trockenstress. **(A)** **(B)** *[Zum Vergrößern anklicken]*"
p1 <- ggplot(o2_tbl, aes(time_num, height, linetype = light, color = water_level)) +
theme_modeling() +
stat_summary(func = "mean", geom = "line", linewidth = 1) +
scale_color_okabeito() +
theme(legend.position = "top") +
guides(color=guide_legend(nrow=2,byrow=TRUE),
linetype = guide_legend(nrow=2,byrow=TRUE)) +
labs(color = "Wasser", linetype = "Licht",
x = "Zeit der Messung [Woche]", y = "Höhe der Tomatenplanze [cm]",
title = "Mittelwerte der Faktorkombinationen")
p2 <- ggplot(o2_tbl, aes(time_num, height, linetype = light, color = water_level)) +
theme_modeling() +
stat_summary(aes(group = light), func = "mean", geom = "line",
size = 1, show.legend = TRUE) +
stat_summary(aes(group = water_level), func = "mean", geom = "line",
size = 1, show.legend = TRUE) +
scale_color_okabeito() +
theme(legend.position = "top") +
guides(color=guide_legend(nrow=2,byrow=TRUE),
linetype = guide_legend(nrow=2,byrow=TRUE)) +
labs(color = "Wasser", linetype = "Licht",
x = "Zeit der Messung [Woche]", y = "Höhe der Tomatenplanze [cm]",
title = "Mittelwerte der Faktorlevel")
p1 + p2 +
plot_layout(ncol = 2) +
plot_annotation(tag_levels = 'A', tag_prefix = '(', tag_suffix = ')') &
theme(plot.tag = element_text(size = 16, face = "bold"))
```
## R Pakete {.unnumbered}
| Nr. | Link | Beschreibung |
|----|----|----|
| 1\. | [R Paket `{innsight}`](https://github.com/bips-hb/innsight) | |
| 2\. | [R Paket `{snakecase}`](https://tazinho.github.io/snakecase/) | |
| 3\. | [R Paket `{visdat}`](https://docs.ropensci.org/visdat/) | |
| 4\. | [R Paket `{vroom}`](https://vroom.r-lib.org/) | |
| 5\. | [R Paket `{gt}`](https://github.com/rstudio/gt) | |
: {tbl-colwidths="\[5,35,60\]"}
## Links {.unnumbered}
[Math in R](https://cran.r-project.org/view=NumericalMathematics)
[Large language models, explained with a minimum of math and jargon](https://www.understandingai.org/p/large-language-models-explained-with)
[Mixed](https://stats.stackexchange.com/questions/95054/how-to-get-an-overall-p-value-and-effect-size-for-a-categorical-factor-in-a-mi)
[Mixed II](https://bbolker.github.io/mixedmodels-misc/glmmFAQ.html)
[Marginal and conditional effects for GLMMs with {marginaleffects} \| Andrew Heiss – Andrew Heiss](https://www.andrewheiss.com/blog/2022/11/29/conditional-marginal-marginaleffects/)
[Lists are my secret weapon for reporting stats with knitr - Higher Order Functions](https://tjmahr.github.io/lists-knitr-secret-weapon/)
[Visualizing {dplyr}’s mutate(), summarize(), group_by(), and ungroup() with animations \| Andrew Heiss – Andrew Heiss](https://www.andrewheiss.com/blog/2024/04/04/group_by-summarize-ungroup-animations/)
Real World Data @liu2022real
Warum **Data** Science @hariri2019uncertainty
[A Refresher on A/B Testing](https://hbr.org/2017/06/a-refresher-on-ab-testing) [A/B Testing Simplified: Steps to Data-Driven Decisions](https://www.statsig.com/blog/ab-testing-101)
[Statistische Funktionen (Referenz) in Excel](https://support.microsoft.com/de-de/office/statistische-funktionen-referenz-624dac86-a375-4435-bc25-76d659719ffd)
[Cancer Paradox](https://youtu.be/1AElONvi9WQ)
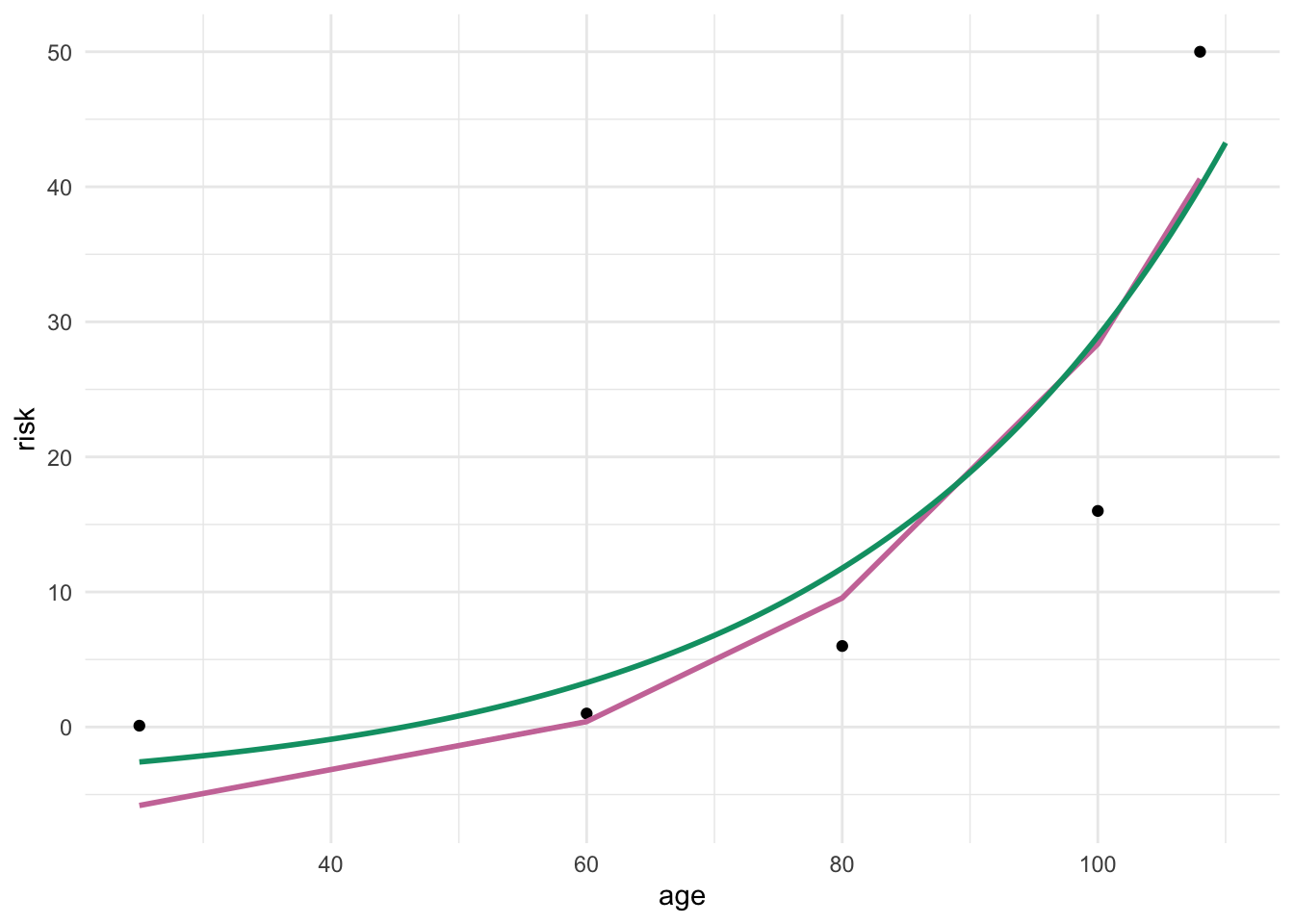
```{r}
#| warning: false
#| message: false
die_risk_tbl <- tibble(age = c(25, 60, 80, 100, 108),
risk = c(0.1, 1, 6, 16, 50))
fit_nls <- nls(risk ~ b0 + I(b1^(age)), data = die_risk_tbl,
start = c(b0 = 1, b1 = 1))
hand_func <- \(x) {-5 + 1.037^(x * 0.97)}
ggplot(die_risk_tbl, aes(age, risk)) +
theme_minimal() +
geom_point() +
geom_line(aes(y = predict(fit_nls)), size = 1, color = "#CC79A7") +
geom_function(fun = hand_func, color = "#009E73", size = 1,
xlim = c(25, 110))
```
Area under the curve larger than 1?
Why We Die: And How We Live: The New Science of Ageing and Longevity
[Here's Waldo: Computing the optimal search strategy for finding Waldo](https://randalolson.com/2015/02/03/heres-waldo-computing-the-optimal-search-strategy-for-finding-waldo/)
[Waldbrände und Dürren: Wie Korkeichen in Portugal den Klimawandel stoppen sollen](https://www.spiegel.de/ausland/waldbraende-und-duerren-wie-korkeichen-in-portugal-den-klimawandel-stoppen-sollen-a-db859f6d-2300-4b43-874c-ae239b76bd43)
[Stock assessment models overstate sustainability of the world’s fisheries](https://www.science.org/doi/10.1126/science.adl6282) and [Modelling seasonal data with GAMs](https://fromthebottomoftheheap.net/2014/05/09/modelling-seasonal-data-with-gam/)
[Ein Kind meiner Zeit](https://www.republik.ch/2024/06/19/ein-kind-meiner-zeit)
[Galenus von Pergamon - Leben und Werk](https://robl.de/galen/galen.htm)
[I Will Fucking Piledrive You If You Mention AI Again](https://ludic.mataroa.blog/blog/i-will-fucking-piledrive-you-if-you-mention-ai-again/)
> Amoc sind riesige Wasserzirkulationen im Ozean, zu denen auch der Golfstrom gehört. Sie sorgen dafür, dass wir in Europa mildes Klima haben. Wenn dieses System zusammenbricht, würde es in den Niederlanden oder Deutschland etwa zehn bis zwanzig Grad kälter werden.
[Atmospheric Response to a Collapse of the North Atlantic](https://gmao.gsfc.nasa.gov/gmaoftp/corbe/AMOC/orbe245_revision1.pdf)
[Atlantic meridional overturning circulation](https://en.wikipedia.org/wiki/Atlantic_meridional_overturning_circulation)
[The 2,500-Year-Old History of Adults Blaming the Younger Generation](https://historyhustle.com/2500-years-of-people-complaining-about-the-younger-generation/)
[Goals Gone Wild: The Systematic Side Effects of Over-Prescribing Goal Setting](https://www.hbs.edu/ris/Publication%20Files/09-083.pdf)
## Paper Ideen {.unnumbered}
### Tierpaper {.unnumbered .unlisted}
- [Arginine Nutrition in Neonatal Pigs](https://www.sciencedirect.com/science/article/pii/S0022316623031279)
- [Fiber effects in nutrition and gut health in pigs](https://link.springer.com/article/10.1186/2049-1891-5-15)
- [Phosphorus nutrition of growing pigs](https://www.sciencedirect.com/science/article/pii/S2405654522000373)
- [Implications of sorghum in broiler chicken nutrition](https://www.sciencedirect.com/science/article/pii/S0377840110000209)
- [Proposed bursa of fabricius weight to body weight ratio standard in commercial broilers](https://www.sciencedirect.com/science/article/pii/S0032579119322448)
- [Growth, efficiency, and yield of commercial broilers from 1957, 1978, and 2005](https://www.sciencedirect.com/science/article/pii/S0032579119385505)
- [Factors Involved in the Ejection of Milk](https://www.sciencedirect.com/science/article/pii/S0022030241954061) von @ely1941factors mit der Katze auf dem Rücken der Kuh
### Pflanzenpaper {.unnumbered .unlisted}
- [Hoverfly pollination enhances yield and fruit quality in mango under protected cultivation](https://www.sciencedirect.com/science/article/pii/S0304423822004411)
- [Plant Growth, Yield, and Fruit Size Improvements in ‘Alicia’ Papaya Multiplied by Grafting](https://www.mdpi.com/2223-7747/12/5/1189)
- [Growth, yield, plant quality and nutrition of basil (Ocimum basilicum L.) under soilless agricultural systems](https://www.sciencedirect.com/science/article/pii/S0570178316300288)
- [Growing Hardier Crops for Better Health: Salinity Tolerance and the Nutritional Value of Broccoli](https://pubs.acs.org/doi/full/10.1021/jf802994p)
- [Influence of Light Intensity and Spectrum on Duckweed Growth and Proteins in a Small-Scale, Re-Circulating Indoor Vertical Farm](https://www.mdpi.com/2223-7747/11/8/1010)
## Zitate {.unnumbered}
> *"" ---*
------------------------------------------------------------------------
> *"The whole world is a very narrow bridge and the main thing is to have no fear at all." --- [Kol Ha'Olam Kulo](https://jwa.org/media/lyrics-to-kol-haolam-kulo)*
> *"Am Ende wird alles gut. Und wenn es noch nicht gut ist, dann ist es noch nicht das Ende." --- Fernando Sabino*
> *"Mein Bleistift und ich sind klüger als ich." --- Albert Einstein nach Karl Popper*
> *"Das Leben ist, im Detail betrachtet, eine Tragödie, aber eine Komödie in der Gesamtperspektive." --- Charlie Chaplin*
> *"We must all suffer one of two things: the pain of discipline or the pain of regret. Discipline weighs ounces, but regret weighs tons. Every day, you are choosing which one you will carry" --- Jim Rohn*
> *"The days can be easy if the years are consistent. You can write a book or get in shape or code a piece of software in 30 minutes per day. But the key is you can't miss a bunch of days." --- James Clear*
> *"Find what you love and let it kill you." --- Charles Bukowski*
> *"In einer Klasse lernt der Lehrer am meisten..." --- anonym*
> *"My God, it's full of stars." --- 2001, A Space Odessey*
> *"Der Sinn des Lebens besteht darin, deine Gabe zu finden. Der Zweck des Lebens ist, sie zu verschenken." --- Pablo Picasso*
> *"If you are allowed one wish for your child, seriously consider wishing him or her optimism. Optimists are normally cheerful and happy, and therefore popular; they are resilient in adapting to failures and hardships, their chances of clinical depression are reduced, their immune system is stronger, they take better care of their health, they feel healthier than others and are in fact likely to live longer. Optimistic individuals play a disproportionate role in shaping our lives. Their decisions make a difference; they are the inventors, the entrepreneurs, the political and military leaders – not average people. They got to where they are by seeking challenges and taking risks. They are talented and they have been lucky, almost certainly luckier than they acknowledge... the people who have the greatest influence on the lives of others are likely to be optimistic and overconfident, and to take more risks than they realize." --- Daniel Kahneman, Thinking, Fast and Slow*
> *"Above all, do not lose your desire to walk: every day I walk myself into a state of well-being and walk away from every illness; I have walked myself into my best thoughts, and I know of no thought so burdensome that one cannot walk away from it. Even if one were to walk for one's health and it were constantly one station ahead—I would still say: Walk! Besides, it is also apparent that in walking one constantly gets as close to well-being as possible, even if one does not quite reach it—but by sitting still, and the more one sits still, the closer one comes to feeling ill. Health and salvation can be found only in motion... if one just keeps on walking, everything will be all right." --- [Soren Kierkegaard](https://www.die-inkognito-philosophin.de/kierkegaard)*
> *"Numerical quantities focus on expected values, graphical summaries on unexpected values." --- John Tukey*
> *"Nobody belongs anywhere, nobody exists on purpose, everybody's going to die." --- [Rick and Morty](https://www.youtube.com/watch?v=E_qvy82U4RE)*
> *"To celebrate the noun do the verb." --- [Ryan Holiyday](https://www.youtube.com/shorts/zvJozTZo18o)*
> *"The formulation of a problem is often more essential than its solution, which may be merely a matter of mathematical or experimental skill. To raise new questions, new possibilities, to regard old problems from a new angle requires creative imagination and marks real advances in science" --- Albert Einstein*
> *"The graveyard is full of 'irreplaceable' and important people." --- Charles De Gaulle [and others](https://quoteinvestigator.com/2011/11/21/graveyards-full/)*
> *"20 years from now, the only people who will remember that you worked late are your kids." --- David Clarke on [r/antiwork](https://www.reddit.com/r/antiwork/comments/12uz90c/psa_20_years_from_now_the_only_people_who_will/?rdt=47059)*
> *"You have to finish things — that's what you learn from, you learn by finishing things." --- Neil Gaiman in Advice to Aspiring Writers*
> *"Leben heißt leiden, überleben heißt, im Leiden einen Sinn finden." --- Friedrich Nietzsche*
> *"Wachstum ist nicht alles, das ist wahr. Aber ohne Wachstum ist alles nichts." --- Angela Merkel*
> *"Competition is for losers!" --- Peter Thiel*
> *"Das Pferd frisst keinen Gurkensalat" --- Philipp Reis erster 1981 telefonisch übertragende Satz*
> *"One glance at a book and you hear the voice of another person perhaps someone dead for thousands of years. Across the millennia the author is speaking clearly and silently inside your head, directly to YOU." --- Carl Sagan*
> *"If you feel safe in the area that you're working in, you're not working in the right area. Always go a little further into the water than you feel you're capable of being in. Go a little bit out of your depth, and when you don't feel that your feet are quite touching the bottom, you're just about in the right place to do something exciting." -- David Bowie*
> *"(1) Alles was es schon gab, als Du geboren wurdest, ist normal und gewöhnlich. Diese Dinge werden als natürlich wahrgenommen und halten die Welt am Laufen. (2) Alles was zwischen Deinem 16ten und 36ten Lebensjahr erfunden wird ist neu, aufregend und revoltionär. Und vermutlich kannst Du in dem Bereich sogar Karriere machen. (3) Alles was nach dem 36ten Lebensjahr erfunden wird ist gegen die natürliche Ordnung der Dinge." --- Douglas Adams, Per Anhalter durch die Galaxis*
> *"Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it." --- Brian Kernighan, professor at Princeton University.*
> *"The three stages of career development are: 1. I want to be in the meeting; 2. I want to run the meeting; 3. I want to avoid meetings." --- Jay Ferro*
> *"Freude ist ein Akt des Trotzes. Mit Freude gewinnen wir, auch wenn wir verlieren. Gut gelebt zu haben ist alles was uns bleibt, denn sterben müssen wir alle." --- Jaghatai Khan, The Lost and the Damned*
> *"Freude ist ein Akt des Trotzes. Durch sie gewinnen wir, auch wenn wir verlieren. Denn sterben müssen wir alle und ein schönes Leben ist alles was uns bleibt." --- Jaghatai Khan, The Lost and the Damned*
> *"\[Alice Munro\] habe sich, erzählte sie einmal, die Sätze ihrer Erzählungen jeweils beim Kartoffelschälen ausgedacht und diese, während die Kartoffeln kochten, zwischendurch im Wohnzimmer notiert." --- [Alice Munro & Die Kunst des Nebenbeischreibens](https://www.zeit.de/kultur/literatur/2024-05/alice-munro-schriftstellerin-nobelpreis-nachruf)*
> *"Gott würfelt nicht!" --- Albert Einstein*
## Referenzen {.unnumbered}