R Code [zeigen / verbergen]
green_tea_tbl <- read_excel("data/zerforschen_green_tea_effect.xlsx") |>
mutate(trt = as_factor(trt),
time_fct = as_factor(time),
fat_ox_r_g_min = round(fat_ox_r_kj_min/37, 2))Letzte Änderung am 25. June 2025 um 12:39:39
“Alles, was wir hören, ist eine Meinung, keine Tatsache. Alles, was wir sehen, ist eine Perspektive, nicht die Wahrheit.” — Marcus Aurelius, Meditationen
Der Effektschätzer. Ein seltsames Kapitel, denn ich tue mich sehr schwer, dieses Kapitel irgendwo in die Linearität dieses Buches hier einzuordnen. Deshalb ist dieses Kapitel eigentlich immer an der falschen Stelle. Entweder hast du schon die statistischen Tests gelesen und du wüsstest gerne was die Effektschätzer sind oder du suchst hier nochmal die Beschreibung der Effektschätzer zum Beispiel aus der multiple Regression heraus. Also steht jetzt dieses Kapitel hier im Raum und du musst schauen, was du wirklich brauchst. Oder ob du dieses Kapitel erst überspringst und dann später nochmal hier liest. Eine wunderbare Übersicht über den Begriff Effektschätzer liefert das englische Buch Doing Meta-Analysis with R: A Hands-On Guide. Der Effektschätzer wird dabei auch gerne Theta \(\boldsymbol{\theta}\) genannt. Da wir dann aber später noch mit anderen Konzepten in die Quere kommen, nutze ich das etwas intuitivere Delta \(\boldsymbol{\Delta}\).
In diesem Zerforschenbeispiel wollen wir uns nicht direkt mit einem Poster beschäftigen sondern haben uns eine etwas andere Quelle herausgesucht. Ich hatte den Podcast Wie Jasper Caven ABNEHM-LÜGEN verbreitet | Podcast #49 (02/23) | Quarks Science Cops und mir dazu die Quellen auf der Webseite Der Fall Jasper Caven: Abnehmen mit Stoffwechsel-Pillen? angeschaut. Im Podcast geht es recht früh um die Publikation von Venables et al. (2008) mit dem Titel Green tea extract ingestion, fat oxidation, and glucose tolerance in healthy humans. Kurz, die Arbeit verkündet, dass mit grünen Teeextrakt (eng. green tea extract, abk. GTE) im Vergleich zu einem Placebo (abk. PLA) die Fettverbrennung um 17% ansteigt. Das ist natürlich eine steile These. Warum das jetzt nicht so gut ist, wie es klingt, wollen wir dann mal in der wissenschaftlichen Veröffentlichung zerforschen. Zuerst aber einmal in der Abbildung 24.1 ein Auszug aus dem Zusammenfassung (eng. abstract) aus der Arbeit von Venables et al. (2008) in der nochmal auf den Unterschied und dem Anstieg von 17% eingegangen wird. Und es stimmt ja auch, der Unterschied als Quotient zwischen den absoluten Zahlen \(0.41\) und \(0.35\) ist auch \(1.17\) und damit ist grüner Teeextrakt um 17% größer in der Fettverbrennung. Aber Achtung, so einfach ist es dann auch wieder nicht.

Schauen wir dazu einmal in den Ergebnisteil der Studie. Wir sehen auch hier, dass wir eine Fettverbrennungssteigerung haben. Es sind die gleichen Zahlen wie auch in der Zusammenfassung plus, dass wir einmal auf die Abbildung 24.3 verwiesen werden. Spannenderweise haben die Unterschiede zwischen der Energiebereitstellung (energy expenditure (EE)) von Kohlenhydraten zu Fett die gleichen prozentualen Steigerungen von Placebo zu grünen Teeextrakt.

Im Folgenden einmal die zentrale Abbildung zu der Fettverbrennung unter Placebo und grünem Teeextrakt. Hier haben wir leider dann ein Problem mit den Einheiten. In der Abbildung haben wir auf der \(y\)-Achse die Rate der Fettverbrennung in \(kJ/min\). Der Text spricht aber in den Einheiten \(g/min\) von der Fettverbrennung. Und damit wird es jetzt schwierig. Wir wissen zwar, dass fats and ethanol have the greatest amount of food energy per unit mass, 37 and 29 kJ/g (9 and 7 kcal/g), respectively, aber das hilft hier auch nur begrenzt weiter. Wir müssten für die Umrechnung von \(kJ/min\) zu \(g/min\) die Werte durch 37 teilen, aber irgendwie passt es dann immer noch nicht, wie wir gleich sehen werden.
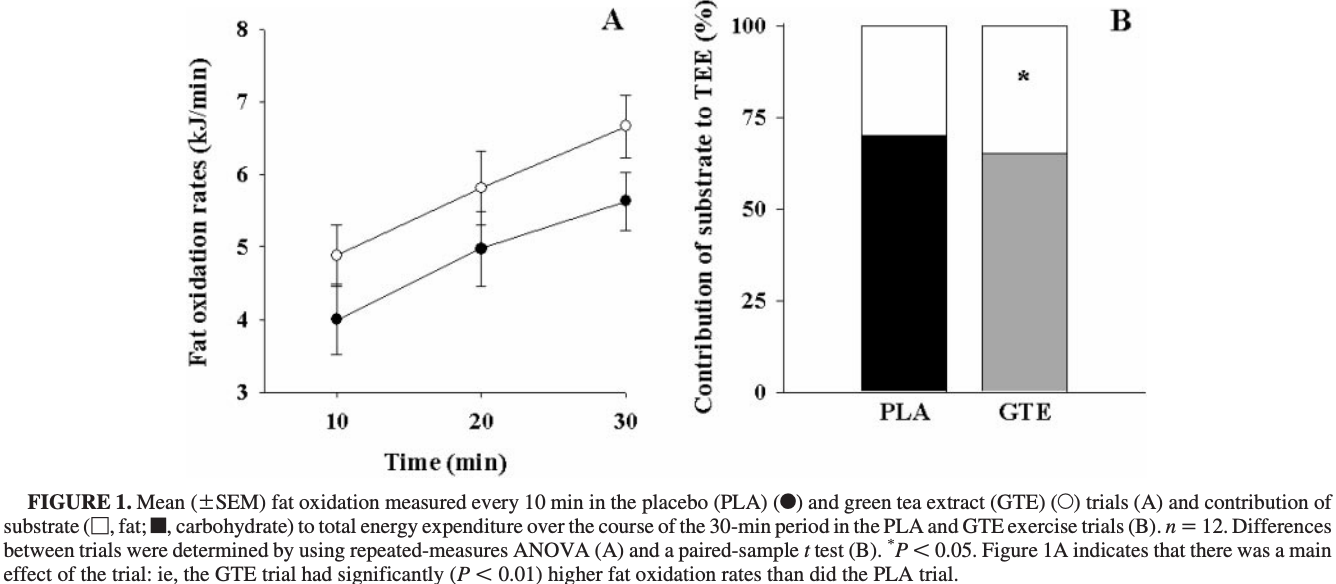
Dann wollen wir also die Abbildung 1.A einmal zerforschen. Ich habe den Datensatz etwas anders gebaut, damit ich die Standardabweichung nutzen kann und nicht den Standardfehler. Das macht es mir etwas einfacher. Da ich sowieso nur drei Beobachtungen genommen habe, kommt es dann auf diesen Unterschied auch nicht mehr direkt an. Der Standardfehler wurde aber in der ursprünglichen Arbeit von Venables et al. (2008) benutzt und ist auch ein besseres Maß, wenn es um die Abschätzung der statistischen Signifikanz geht.
green_tea_tbl <- read_excel("data/zerforschen_green_tea_effect.xlsx") |>
mutate(trt = as_factor(trt),
time_fct = as_factor(time),
fat_ox_r_g_min = round(fat_ox_r_kj_min/37, 2))In den beiden folgenden Tabs baue ich dir einmal den Verlauf nach und dann einmal die Werte mit \(0.41\pm 0.03\) und \(0.35\pm 0.03\) aus dem Text als Barplot.
Hier einmal als Nachbau die Abbildung des Verlaufs. Ich speichere mit die Abbildung einmal in dem Objekt p1 damit ich gleich das R Paket {patchwork} nutzen kann um die Abbildungen zusammenzubauen. Als Besonderheit ergänze ich an der rechten Seite die Fettverbrennung in der Einheit \(g/min\).
p1 <- green_tea_tbl |>
ggplot(aes(time, fat_ox_r_kj_min, color = trt)) +
theme_minimal() +
geom_jitter(position=position_dodge(0.4), shape = 4, size = 2) +
stat_summary(fun.data="mean_sdl", fun.args = list(mult = 1),
geom="pointrange", position=position_dodge(0.4)) +
stat_summary(fun = "mean", fun.min = "min", fun.max = "max", geom = "line",
position=position_dodge(0.4)) +
labs(x = "Time (min)", y = "Fat oxidation rates (kJ/min)", color = "") +
scale_y_continuous(sec.axis = sec_axis(~ ./37, breaks = c(4:7/37),
labels = round(c(4:7/37), 2),
name = "Fat oxidation rates (g/min)")) +
theme(legend.position = "none") +
scale_color_okabeito()Mich hat dann einmal interessiert wie die Werte aus dem Text mit \(0.41\pm 0.03\) und \(0.35\pm 0.03\) denn als Barplot aussehen würden. Deshalb hier einmal die Werte in einem tibble() um diese dann als einen Barplot abbilden zu können.
stat_tbl <- tibble(trt = as_factor(c("PLA", "GTE")),
mean = c(0.35, 0.41),
sem = c(0.03, 0.03))Auch hier speichere ich einmal die Abbildung in dem Objekt p2 um gleich eine schönere Abbildung mit dem R Paket {patchwork} zu bauen.
p2 <- stat_tbl |>
ggplot(aes(x = trt, y = mean, fill = trt)) +
theme_minimal() +
geom_bar(stat = "identity") +
geom_errorbar(aes(ymin = mean-sem, ymax = mean+sem),
width = 0.5) +
theme(legend.position = "none") +
labs(x = "", y = "Fat oxidation rates (g/min)", color = "") +
scale_fill_okabeito()In der Abbildung 24.4 siehst du einmal die beiden Abbildungen p1 und p2 in einem Plot visualisiert. Es war etwas aufwendiger um die Abbildung zu bauen, aber dann hatte ich die Werte auch ungefähr zusammen. Auch hier passen zwar die Werte für die Einheit \(kJ/min\) der Fettverbrennung aber nicht für die Einheit in \(g/min\). Da bin ich in der Umrechnung gescheitert. Was wir aber gleich mal machen werden, ist die Fläche unter der Kurve zu berechnen in der Hoffnung, dass wir eventuell hier den Quotienten von ca. \(17\%\) finden.
p1 + p2 +
plot_layout(widths = c(6, 1)) +
plot_annotation(tag_levels = 'A')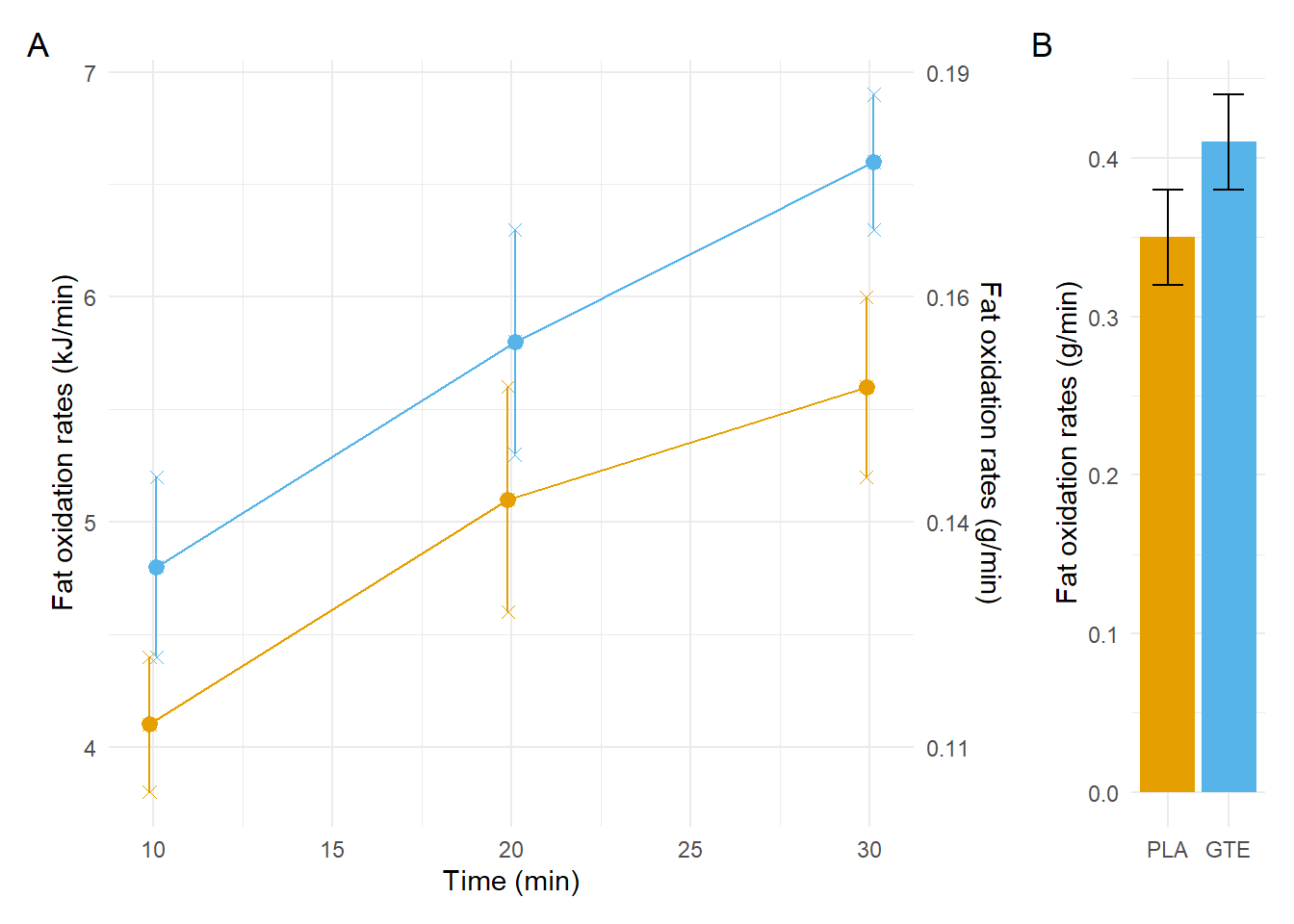
In den folgenden beiden Tabs habe ich einmal die Fläche unter den beiden Kurven berechnet. Ich habe die Hoffnung, dass der Quotient von den beiden Flächen sich dann um 17% unterscheidet. Das müsste ja ungefähr so hinkommen, wenn schon die Einheiten nicht funktionieren.
Wir berechnen einmal die Fläche unter der Kurve für unsere Placebodaten.
pla_fit <- green_tea_tbl |>
filter(trt == "PLA") |>
lm(fat_ox_r_kj_min ~ time, data = _)
f_pla <- \(x) predict(pla_fit, newdata = tibble(time = x))
integrate(f_pla, 10, 30)98.66667 with absolute error < 1.1e-12Damit haben wir dann \(98.6\; kJ/30min\) über die Zeit mit Placebo verbrannt. Jetzt können wir das noch einfach in \(g/min\) und dann \(g/h\) umrechnen.
\[ \cfrac{98.6\; kJ/30min}{37\; kJ/g} = 2.66 \; g/30min = 1.33 \; g/h \]
Wir berechnen einmal die Fläche unter der Kurve für unsere grünen Teeextraktdaten.
gte_fit <- green_tea_tbl |>
filter(trt == "GTE") |>
lm(fat_ox_r_kj_min ~ time, data = _)
f_gte <- \(x) predict(gte_fit, newdata = tibble(time = x))
integrate(f_gte, 10, 30)114.6667 with absolute error < 1.3e-12Damit haben wir dann \(114.67\; kJ/30min\) über die Zeit mit grünen Teeextrakt verbrannt. Jetzt können wir das noch einfach in \(g/min\) und dann \(g/h\) umrechnen.
\[ \cfrac{114.67\; kJ/30min}{37\; kJ/g} = 3.10 \; g/30min = 1.55 \; g/h \]
Und tatsächlich, wenn wir diese Werte dann in Relation setzen, kommen wir dann tatsächlich auf die prozentuale Steigerung von 17%, wie sie auch in der Veröffentlichung angegeben wird.
\[ \cfrac{1.55g/h}{1.33g/h} \approx 1.17\; (\uparrow 17\%) \]
Auch wenn sich die Steigerung von 17% viel anhört, ist doch der absolute Verbrauch an Fett wirklich zu vernachlässigen. Immer beachten, wir haben es hier mit Bewegung der Teilnehmer zu tun. Wir verbrennen also das Fett unter Bewegung und nicht einfach so im Sitzen. Dafür ist dann die Steigerung aus der Abbildung 24.4 wirklich zu vernachlässigen. Auch mit den Werten aus der Veröffentlichung von \(0.41g/min\) würden wir in einer Trainingseinheit von 30 Minuten \(12.3g\) Fett verbrennen. Das Placebo würde dann \(10.5g\) verbrennen. Somit würden wir mit fünfmal Training in der Woche nur \((12.3g - 10.8g) \cdot 5 = 9g\) mehr Fett verbrennen. Das sind alles winzige Zahlen, die nur durch den relativen Anstieg aufgeblasen werden.
Wenn wir einen der vielen Effektschätzer berechnen wollen, dann nutzen wir dafür die Effektschätzer aus dem R Paket {effectsize}. Das R Paket {effectsize} liefert Effektschätzer für fast alle statistischen Gelegenheiten. Wir werden hier wie immer nur den groben Überblick abdecken. Vermutlich wird das Kapitel dann noch Anwachsen. Streng genommen gehört das Kapitel 41 zu den diagnostischen Tests auf einer 2x2 Kreuztabelle auch irgendwie zu Effektschätzern. Wenn du Spezifität und Sensitivität suchst bist du in dem Kapitel zu diagnostischen Tests richtig.
Wir unterscheiden hier erstmal grob in vier Arten von Effektschätzern:
Daneben gibt es wie noch die Korrelation wie in Kapitel 48 beschrieben. Die Korrelation wollen wir aber in diesem Kapitel nicht vorgreifen bzw. wiederholen.
Am Ende muss du immer den Effekt im Kontext der Fragestellung bzw. des Outcomes \(y\) bewerten. Der numerische Unterschied von \(0.1\) cm kann in einem Kontext viel sein. Das Wachstum von Bakterienkolonien kann ein Unterschied von \(0.1\) cm viel sein. Oder aber sehr wenig, wenn wir uns das Wachstum von Bambus pro Tag anschauen. Hier bist du gefragt, den Effekt in den Kontext richtig einzuordnen. Ebenso stellt sich die Frage, ob ein Unterschied von 6% viel oder wenig ist.
Wenn wir uns einen Unterschied eines Mittelwerts anschauen, dann haben wir keinen Effekt vorliegen, wenn der Mittlwertsunterschied \(\Delta\) zwischen der Gruppe \(A\) und der Gruppe \(B\) gleich 0 ist. Die Nullhypothese gilt. Beide Gruppen \(A\) und \(B\) haben den gleichen Mittelwert.
\[ \Delta_{A-B} = A - B = 0 \]
Wenn wir uns einen Unterschied eines Anteils anschauen, dann haben wir keinen Effekt vorliegen, wenn der Anteilsunterschied \(\Delta\) zwischen der Gruppe \(A\) und der Gruppe \(B\) gleich 1 ist. Die Nullhypothese gilt. Beide Gruppen \(A\) und \(B\) haben den gleichen Anteil.
\[ \Delta_{A/B} = \cfrac{A}{B} = 1 \]
Dieses Wissen brauchen wir um die Signifikanzschwelle bei einem 95% Konfidenzintervall richtig zu setzen und interpretieren zu können. Siehe dazu auch nochmal das Kapitel 22.2.5.
Wir wollen folgende R Pakete in diesem Kapitel nutzen.
pacman::p_load(tidyverse, magrittr, see, scales,
effectsize, parameters, broom, readxl,
emmeans, vcd, irr, conflicted)
conflicts_prefer(dplyr::filter)
conflicts_prefer(effectsize::oddsratio)
conflicts_prefer(magrittr::set_names)An der Seite des Kapitels findest du den Link Quellcode anzeigen, über den du Zugang zum gesamten R-Code dieses Kapitels erhältst.
Wir berechnen zwei Mittelwerte \(\bar{y}_1\) und \(\bar{y}_2\). Wenn wir wissen wollen wie groß der Effekt zwischen den beiden Mittelwerten ist, dann bilden wir die Differenz. Wir berechnen das \(\Delta_{y_1-y_2}\) für \(y_1\) und \(y_2\) indem wir die beiden Mittelwerte voneinander abziehen.
\[ \Delta_{y_1-y_2} = \bar{y}_1 - \bar{y}_2 \]
Wenn es keinen Unterschied zwischen den beiden Mittelwerten \(\bar{y}_1\) und \(\bar{y}_2\) gibt, dann ist die Differenz \(\Delta_{y_1-y_2} = \bar{y}_1 - \bar{y}_2\) gleich 0. Wir sagen, die Nullhypothese vermutlich gilt, wenn die Differenz klein ist. Warum schreiben wir hier vermutlich? Ein statistischer Test ist eine Funktion von \(\Delta\), \(s\) und \(n\). Wir können auch mit kleinem \(\Delta\) die Nullhypothese ablehnen, wenn \(s\) und \(n\) eine passende Teststatistik generieren. Siehe dazu auch das Kapitel 22.3. Was wir besser annehmen können ist, dass die Relevanz klein ist. Effekt mit einem geringen Mittelwertsunterschied sind meistens nicht relevant. Aber diese Einschätzung hängt stark von der Fragestellung ab.
\[ H_0: \Delta_{y_1-y_2} = \bar{y}_1 - \bar{y}_2 = 0 \]
In Tabelle 24.1 ist nochmal ein sehr simples Datenbeispiel gegeben an dem wir den Zusammenhang nochmal nachvollziehen wollen.
| animal | jump_length |
|---|---|
| cat | 8.0 |
| cat | 7.9 |
| cat | 8.3 |
| cat | 9.1 |
| dog | 8.0 |
| dog | 7.8 |
| dog | 9.2 |
| dog | 7.7 |
Nehmen wir an, wir berechnen für die Sprungweite [cm] der Hundeflöhe einen Mittelwert von \(\bar{y}_{dog} = 8.2\) und für die Sprungweite [cm] der Katzenflöhe einen Mittelwert von \(\bar{y}_{cat} =8.3\). Wie große ist nun der Effekt? Oder anders gesprochen, welchen Unterschied in der Sprungweite macht es aus ein Hund oder eine Katze zu sein? Was ist also der Effekt von animal? Wir rechnen \(\bar{y}_{dog} - \bar{y}_{cat} = 8.2 - 8.3 = -0.1\). Zum einen wissen wir jetzt “die Richtung”. Da wir ein Minus vor dem Mittelwertsunterschied haben, müssen die Katzenflöhe weiter springen als die Hundeflöhe, nämlich 0.1 cm. Dennoch ist der Effekt sehr klein.
Da der Mittlwertsunterschied alleine nnur eine eingeschränkte Aussage über den Effekt erlaubt, gibt es noch Effektschätzer, die den Mittelwertsunterschied \(\Delta_{y_1-y_2}\) mit der Streuung \(s^2\) sowie der Fallzahl zusammenbringt. Der bekannteste Effektschätzer für einen Mittelwertsunterschied bei großer Fallzahl mit mehr als 20 Beobachtungen ist Cohen’s d. Wir können Cohen’s d wie folgt berechnen.
\[ |d| = \cfrac{\bar{y}_1-\bar{y}_2}{\sqrt{\cfrac{s_1^2+s_2^2}{2}}} \]
Wenn wir die berechneten Mittelwerte und die Varianz der beiden Gruppen in die Formel einsetzten ergibt sich ein absolutes Cohen’s d von 0.24 für den Gruppenvergleich.
\[ |d| = \cfrac{8.2 - 8.3}{\sqrt{(0.5^2+0.3^2) /2}} = \cfrac{-0.1}{0.41} = \lvert-0.24\rvert \]
Was denn nun Cohen’s d exakt aussagt, kann niemand sagen. Aber wir haben einen Wust an möglichen Grenzen. Hier soll die Grenzen von Cohen (1988) einmal angegeben werden. Cohen (1988) hat in seiner Arbeit folgende Grenzen in Tabelle 24.2 für die Interpretation von \(d\) vorgeschlagen. Mehr Informationen zu Cohen’s d gibt es auf der Hilfeseite von effectsize: Interpret standardized differences.
| Cohen’s d | Interpretation des Effekts |
|---|---|
| \(d < 0.2\) | Sehr klein |
| \(0.2 \leq d < 0.5\) | Klein |
| \(0.5 \leq d < 0.8\) | Mittel |
| \(d \geq 0.8\) | Stark |
Wir können auch über die Funktion cohens_d() Cohen’s d einfach in R berechnen. Die Funktion cohens_d() akzeptiert die Formelschreibweise. Die 95% Konfidenzintervalle sind mit Vorsicht zu interpretieren. Denn die Nullhypothese ist hier nicht so klar formuliert. Wir lassen also die 95% Konfidenzintervalle erstmal hier so stehen.
cohens_d(jump_length ~ animal, data = data_tbl, pooled_sd = TRUE)Cohen's d | 95% CI
-------------------------
0.24 | [-1.16, 1.62]
- Estimated using pooled SD.Dankenswerterweise gibt es noch die Funktion interpret_cohens_d, die es uns erlaubt auszusuchen nach welche Literturquelle wir den Wert von Cohen’s d interpretieren wollen. Ob dieser Effekt relevant zur Fragestellung ist musst du selber entscheiden.
interpret_cohens_d(0.24, rules = "cohen1988")[1] "small"
(Rules: cohen1988)Soweit haben wir uns mit sehr großen Fallzahlen beschäftigt. Cohen’s d ist dafür auch sehr gut geeigent und wenn wir mehr als 20 Beobachtungen haben, können wir Cohen’s d auch gut anwenden. Wenn wir weniger Fallzahl vorliegen haben, dann können wir Hedges’ g nutzen. Hedges’ g bietet eine Verzerrungskorrektur für kleine Stichprobengrößen (\(N < 20\)) sowie die Möglichkeit auch für unbalanzierte Gruppengrößen einen Effektschätzeer zu berechnen. Die Formel sieht mit dem Korrekturterm recht mächtig aus.
\[ g = \cfrac{\bar{y}_1 - \bar{y}_2}{s^*} \cdot \left(\cfrac{N-3}{N-2.25}\right) \cdot \sqrt{\cfrac{N-2}{N}} \]
mit
\[ s^* = \sqrt{\cfrac{(n_1-1)s_1^2 + (n_2-1)s_2^2}{n_1+n_2-2}} \]
Wir können aber einfach die Mittelwerte und die Varianzen aus unserem beispiel einsetzen. Da unsere beiden Gruppen gleich groß sind \(n_1 = n_2\) und damit ein balanziertes Design vorliegt, sind Cohen’s d und Hedges’ g numerisch gleich. Wir können dann noch für die geringe Fallzahl korrigieren und erhalten ein händisches \(g = 0.18\).
\[ g = \cfrac{8.2 - 8.3}{0.41} \cdot \left(\cfrac{8-3}{8-2.25}\right) \cdot \sqrt{\cfrac{8-2}{8}} = \lvert-0.24\rvert \cdot 0.87 \cdot 0.87 \approx 0.18 \]
mit
\[ s^* = \sqrt{\cfrac{(4-1)\cdot0.5^2 + (4-1)\cdot0.3^2}{4+4-2}} = \sqrt{\cfrac{0.75 + 0.27}{6}} = 0.41 \]
In R gibt es die Funktion hedges_g() die uns erlaubt in der Formelschreibweise direkt Hedges’ g zu berechnen. Wir sehen hier eine Abweichung von unserer händischen Rechnung. Das ist aber in soweit nicht ungewöhnlich, da es noch eine Menge Varianten der Anpassung für die geringe Fallzahl gibt. In der Anwendung nutzen wir die Funktion aus dem Paket {effectsize} wie hier durchgeführt.
Wir ignorieren wie auch bei Cohen’s d das 95% Konfidenzintervall, da die Interpretation ohne die Nullhypothese nicht möglich ist. Die Nullhypothese ist in diesem Fall komplexer. Wir lassen daher das 95% Konfidenzintervall erstmal einfach hier so stehen.
hedges_g(jump_length ~ animal, data = data_tbl, pooled_sd = TRUE)Hedges' g | 95% CI
-------------------------
0.21 | [-1.01, 1.41]
- Estimated using pooled SD.Auch für Hedges’ g gibt es die Möglichkeit sich über die Funktion interpret_hedges_g() den Wert von \(g=0.21\) interpretieren zu lassen. Nach Sawilowsky (2009) haben wir hier einen kleinen Effekt vorliegen. Ob dieser Effekt relevant zur Fragestellung ist musst du selber entscheiden.
interpret_hedges_g(0.21, rules = "sawilowsky2009")[1] "small"
(Rules: sawilowsky2009)Die Hilfeseite zu dem Paket effectsize bietet eine Liste an möglichen Referenzen für die Wahl der Interpretation der Effektstärke. Du musst dann im Zweifel schauen, welche der Quellen und damit Grenzen du nutzen willst.
Neben den Unterschied zweier Mittelwerte ist auch häufig das Interesse an dem Unterschied zwischen zwei Anteilen. Nun unterscheiden wir zwischen Wahrscheinlichkeiten und Chancen. Beide Maßzahlen, die Wahrscheinlichkeit wie auch die Chance, beschreiben einen Anteil. Hier tritt häufig Verwirrung auf, daher hier zuerst ein Beispiel.
Wir behandelt \(n = 65\) Hunde mit dem Antiflohmittel FleaEx. Um die Wirkung von FleaEx auch bestimmen zu können haben wir uns zwei Gruppen von Hunden ausgesucht. Wir haben Hunde, die mit Flöhe infiziert sind und Hunde, die nicht mit Flöhen infiziert sind. Wir schauen nun in wie weit FleaEx gegen Flöhe hilft im Vergleich zu einer Kontrolle.
| Infected | |||
| Yes (1) | No (0) | ||
| Group | FleaEx | \(18_{\;\Large a}\) | \(23_{\;\Large b}\) |
| Control | \(14_{\;\Large c}\) | \(10_{\;\Large d}\) |
Aus der Tabelle 24.3 können wir entnehmen, dass 18 behandelte Hunde mit Flöhen infiziert sind und 14 Hunde keine Infektion aufweisen. Bei den Hunden aus der Kontrolle haben wir 23 infizierte und 10 gesunde Tiere beobachtet.
Wir können nun zwei Arten von Anteilen berechnen um zu beschreiben, wie sich der Anteil an infizierten Hunden verhält. Das bekanntere ist die Frequenz oder Wahrscheinlichkeit oder Risk Ratio (\(RR\)). Das andere ist das Chancenverhältnis oder Odds Ratio (\(OR\)). Beide kommen in der Statistik vor und sind unterschiedlich zu interpretieren. Es gibt verschiedene Typen von klinischen Studien, also Untersuchungen an Menschen. Einige Studien liefern nur \(OR\) wieder andere Studientypen liefern \(RR\). George et al. (2020) liefert eine gute Übersicht über What’s the risk: differentiating risk ratios, odds ratios, and hazard ratios?
Um die die Odds Ratio und die Risk Ratios auch in R berechnen zu können müssen wir einmal die 2x2 Kreuzabelle in R nachbauen. Wir nutzen dafür die Funktion matrix() und müssen schauen, dass die Zahlen in der 2x2 Kreuztabelle in R dann auch so sind, wie in der Datentabelle. Das ist jetzt ein schöner Codeblock, ist aber dafür da um sicherzustellen, dass wir die Zahlen richtig eintragen.
cross_mat <- matrix(c(18, 23, 14, 10),
nrow = 2, byrow = TRUE,
dimnames = list(
Group = c("FleaEx", "Control"),
Infected = c("Yes", "No")
)
)
cross_mat Infected
Group Yes No
FleaEx 18 23
Control 14 10Später werden wir das \(OR\) und \(RR\) wieder treffen. Das \(OR\) kommt in der logistsichen Regression als Effektschätzer vor. Wir nutzen das \(RR\) als Effektschätzer in der Poissonregression.
Wir berechnen wir nun das Wahrscheinlichkeitsverhältnis oder Risk Ratio (RR)? Das Risk Ratio ist das Verhältnis von den infizierten Hunden in der Behandlung (\(a\)) zu allen infizierten Hunden (\(a+c\)) zu dem Verhältnis der gesunden Hunde in der Behandlung (\(b\)) zu allen gesunden Hunden (\(b+d\)). Das klingt jetzt etwas wirr, deshalb helfen manchmal wirklich Formeln, den Zusammenhang besser zu verstehen. Damit ist \(Pr(\mbox{FleaEx}|\mbox{infected})\) die Wahrscheinlichkeit infiziert zu sein, wenn der Hund mit FleaEx behandelt wurde.
\[ Pr(\mbox{FleaEx}|\mbox{infected}) = \cfrac{a}{a+c} = \cfrac{18}{18+14} \approx 0.56 \]
Die Wahrscheinlichkeit \(Pr(\mbox{Control}|\mbox{infected})\) ist dann die Wahrscheinlichkeit infiziert zu sein, wenn der Hund mit in der Kontrolle war.]{.aside}
\[ Pr(\mbox{Control}|\mbox{infected}) = \cfrac{b}{b+d} = \cfrac{23}{23 + 10} \approx 0.70 \]
Das Risk Ratio ist mehr oder minder das Verhältnis von der beiden Spalten der Tabelle 24.3 für die Behandlung. Wir erhalten also ein \(RR\) von \(0.76\). Damit mindert die Gabe von FleaEx die Wahrscheinlichkeit sich mit Flöhen zu infizieren.
\[ \Delta_{y_1/y_2} = RR = \cfrac{Pr(\mbox{FleaEx}|\mbox{infected})}{Pr(\mbox{Control}|\mbox{infected})} = \cfrac{0.56}{0.70} \approx 0.80 \]
Wir überprüfen kurz mit der Funktion riskratio() ob wir richtig gerechnet haben. Das 95% Konfidenzintervall können wir interpretieren, dafür brauchen wir aber noch einmal eine Idee was “kein Effekt” bei einem Risk Ratio heist.
riskratio(cross_mat)Risk ratio | 95% CI
-------------------------
0.81 | [0.55, 1.18]Wann liegt nun kein Effekt bei einem Anteil wie dem RR vor? Wenn der Anteil in der einen Gruppe genauso groß ist wie der Anteil der anderen Gruppe.
\[ H_0: RR = \cfrac{Pr(\mbox{dog}|\mbox{infected})}{Pr(\mbox{cat}|\mbox{infected})} = 1 \]
Wir interpretieren das \(RR\) nun wie folgt. Unter der Annahme, dass ein kausaler Effekt zwischen der Behandlung und dem Outcome besteht, können die Werte des relativen Risikos auf folgende Art und Weise interpretiert werden:
Das heist in unserem Fall, dass wir mit einem RR von \(0.80\) eine protektive Behandlung vorliegen haben. Die Gabe von FleaEx reduziert das Risiko mit Flöhen infiziert zu werden. Durch das 95% Konfidenzintervall wissen wir auch, dass das \(RR\) nicht signifikant ist, da die 1 im 95% Konfidenzintervall enthalten ist.
Neben dem Risk Ratio gibt es noch das Odds Ratio. Das Odds Ratio ist ein Chancenverhältnis. Wenn der Mensch an sich schon Probleme hat für sich Wahrscheinlichkeiten richtig einzuordnen, scheitert man allgemein an der Chance vollkommen. Dennoch ist das Odds Ratio eine gute Maßzahl um abzuschätzen wie die Chancen stehen, einen infizierten Hund vorzufinden, wenn der Hund behandelt wurde.
Schauen wir uns einmal die Formeln an. Im Gegensatz zum Risk Ratio, welches die Spalten miteinander vergleicht, vergleicht das Odds Ratio die Zeilen. Als erstes berechnen wir die Chance unter der Gabe von FleaEx infiziert zu sein wie folgt.
\[ Odds(\mbox{FleaEx}|\mbox{infected}) = a:b = 18:23 = \cfrac{18}{23} = 0.78 \]
Dann berechnen wir die Chance in der Kontrollgruppe infiziert zu sein wie folgt.
\[ Odds(\mbox{Control}|\mbox{infected}) = c:d = 14:10 = \cfrac{14}{10} \approx 1.40 \]
Abschließend bilden wir das Chancenverhältnis der Chance unter der Gabe von FleaEx infiziert zu sein zu der Chance in der Kontrollgruppe infiziert zu sein. Es ergbit sich das Odds Ratio wie folgt.
\[ \Delta_{y_1/y_2} = OR = \cfrac{Odds(\mbox{Flea}|\mbox{infected})}{Odds(\mbox{Control}|\mbox{infected})} = \cfrac{a \cdot d}{b \cdot c} = \cfrac{0.78}{1.40} \approx 0.56 \]
Wir überprüfen kurz mit der Funktion oddsratio() ob wir richtig gerechnet haben. Das 95% Konfidenzintervall können wir interpretieren, dafür brauchen wir aber noch einmal eine Idee was “kein Effekt” bei einem Odds Ratio heist.
oddsratio(cross_mat)Odds ratio | 95% CI
-------------------------
0.56 | [0.20, 1.55]Wann liegt nun kein Effekt bei einem Anteil wie dem OR vor? Wenn der Anteil in der einen Gruppe genauso groß ist wie der Anteil der anderen Gruppe.
\[ H_0: OR = \cfrac{Odds(\mbox{dog}|\mbox{infected})}{Odds(\mbox{cat}|\mbox{infected})} = 1 \]
Wir interpretieren das \(OR\) nun wie folgt. Unter der Annahme, dass ein kausaler Effekt zwischen der Behandlung und dem Outcome besteht, können die Werte des Odds Ratio auf folgende Art und Weise interpretiert werden:
Das heist in unserem Fall, dass wir mit einem OR von \(0.56\) eine protektive Behandlung vorliegen haben. Die Gabe von FleaEx reduziert die Chance mit Flöhen infiziert zu werden. Durch das 95% Konfidenzintervall wissen wir auch, dass das \(OR\) nicht signifikant ist, da die 1 im 95% Konfidenzintervall enthalten ist.
Wenn wir das OR berechnet haben, wollen wir eventuell das \(OR\) in dem Sinne eines Riskoverhältnisses berichten. Leider ist es nun so, dass wir das nicht einfach mit einem \(OR\) machen können. Ein \(OR\) von 3.5 ist ein großes Chancenverhältnis. Aber ist es auch 3.5-mal so wahrscheinlich? Nein so einfach können wir das OR nicht interpretieren. Wir können aber das \(OR\) in das \(RR\) umrechnen. Dafür brauchen wir aber das \(p_0\). Dabei ist das \(p_0\) das Basisrisiko also die Wahrscheinlichkeit des Ereignisses ohne die Intervention. Wenn wir nichts tun würden, wie wahrscheinlich wäre dann das Auftreten des Ereignisses? Es ergibt sich dann die folgende Formel für die Umrechnung des \(OR\) in das \(RR\). Grant (2014) gibt nochmal eine wissenschaftliche Diskussion des Themas zur Konvertierung von OR zu RR.
\[ RR = \cfrac{OR}{(1 - p_0 + (p_0 \cdot OR))} \]
Schauen wir uns das einmal in einem Beispiel an. Wir nutzen für die Umrechnung die Funktion oddsratio_to_riskratio() aus dem R Paket {effectsize}. Wenn wir ein \(OR\) von 3.5 haben, so hängt das \(RR\) von dem Basisriskio ab. Wenn das Basisirisko für die Erkrankung ohne die Behandlung sehr hoch ist mit \(p_0 = 0.85\), dann ist das \(RR\) sehr klein.
OR <- 3.5
baserate <- 0.85
oddsratio_to_riskratio(OR, baserate) %>% round(2)[1] 1.12Auf der anderen Seite nähert sich das \(OR\) dem \(RR\) an, wenn das Basisriskio für die Erkrankung mit \(p_0 = 0.04\) sehr klein ist.
OR <- 3.5
baserate <- 0.04
oddsratio_to_riskratio(OR, baserate) %>% round(2)[1] 3.18Weil wir natürlich das Basisrisiko nur abschätzen können, verbleibt hier eine gewisse Unsicherheit, wie das \(RR\) zu einem gegebenen \(OR\) aussieht.
Der Foldchange (deu. Zunahmenänderung ungebräuchlich, abk. FC) ist ein statistisches Maß welches uns beschreibt, wie sehr sich eine Menge von einem Anfangs- zu einem Endwert verändert. Dabei ist es wichtig, dass wir es hier gleich mit einem Anteil zu tun haben. Beispielsweise entspricht ein Anfangswert von 30 und ein Endwert von 60 einer 2-fachen Änderung oder eben eines two-fold change. Wir wollen dabei natürlich wissen, wie sich der Wert von Ende zu Beginn geändert hat.
\[ FC = \cfrac{Endwert}{Anfangswert} = \cfrac{60}{30} = 2 \]
Eine Verringerung von 80 auf 20 wäre ein Foldchange von -0.75, während eine Veränderung von 20 auf 80 ein Foldchange von 3 wäre. Damit sind wir natürlich sehr unsymmetrisch um die 1.
\[ FC = \cfrac{Endwert}{Anfangswert} = \cfrac{20}{80} = 0.75 \]
Alle Foldchanges mit einer Verringerung pressen sich in den Zahlenraum \([0,1]\) während alle Erhöhungen sich im Zahlenraum \([1, \infty]\) bewegen. Um dies zu umgehen, verwenden wir \(log2\) für den Ausdruck der Log Foldchange. Damit du das besser verstehst, dann die Sachlage einmal als ein Beispiel. Wenn du einen FC von 2 vorliegen hast und dann \(log_2(2)\) berechnest, dann erhälst du einen \(log_2FC\) von 1.
FC <- c(0.1, 0.5, 0.75, 1, 2, 3, 4)
log2(FC) |>
round(2) |>
set_names(FC) 0.1 0.5 0.75 1 2 3 4
-3.32 -1.00 -0.42 0.00 1.00 1.58 2.00 Wenn du einen log2-transformierten FC-Wert wieder zurück haben willst, dann nutze einfach die 2-er Potenz mit \(2^{logFC}\). Auch hier einmal das schnelle Beispiel.
2^log2(FC)[1] 0.10 0.50 0.75 1.00 2.00 3.00 4.00Wenn dir also einmal ein Foldchange über den Weg läuft, dann geht es eigentlich nur darum eine Veränderung gleichmäßig um die Eins darstellen zu können.
Neben den klassischen Effektmaßzahlen, die sich aus einem Mittelwert oder einem Anteil direkt berechnen, gibt es noch andere Effektmaße. Einer dieser Effektmaße ist der Wirkungsgrad für zum Beispiel ein Pflanzenschutzmittel. Wir können hier aber auch weiter denken und uns überlegen in wie weit wir eine Population von Schaderregern durch eine Behandlung reduzieren können. Unabdingbar ist in diesem Fall eine positive Kontrolle in der nichts gemacht wird sondern nur der normale Befall gemessen wird. Merke also, ohne eine Kontrolle geht bei der Bestimmung des Wirkungsgrades gar nichts.
In der Tabelle 24.4 sehen wir nochmal eine Übersicht über vier mögliche Arten den Wirkungsgrad zu berechnen. Je nachdem was wir vorliegen haben, entweder einen Befall mit Zähldaten oder aber eine Sterblichkeit bzw. Mortalität, müssen wir eine andere Methode wählen. Auch müssen wir unterscheiden, ob wir eine homogene Population vorliegen haben oder eher eine heterogene Population. Ich kann hier aber schon mal etwas abkürzen, meistens können wir nur den Wirkungsgrad nach Abbott et al. (1925) berechnen, da unser experimentelles Design nicht mehr hergibt. Der Wirkungsgrad nach Abbott hat nämlich nur die räumliche Komponente und nicht die zeitliche. So lässt sich Abbott häufig einfacher durchführen und ausrechnen. Für eine zeitliche Komponente wie bei Henderson-Tilton müssten wir dann den Befall wiederholt messen.
| Homogene Population | Heterogene Population (Vorbefall differenziert) | |
| Befall oder lebende Individuen | Abbott [räumlicher Bezug] | Henderson-Tilton [zeitlich und räumlicher Bezug] |
| Sterblichkeit oder tote Individuen | Schneider-Orelli | Sun-Shepard |
Im Folgenden gehen wir einmal die vier Wirkungsgrade durch. Neben Abbott stelle ich dann hier nochmal den Wirkungsgrad nach Henderson & Tilton (1955) vor. Die anderen Wirkungsgrade nur als Formeln, da mir aktuell noch keine Anwendungen hier über den Weg gelaufen sind. Der Hauptfokus liegt dann aber am Ende auf den Wirkungsgrad nach Abbott. Den Wirkungsgrad brauchen wir eben dann doch am meisten, da wir nach Abbott nur den gezählten Befall nach der Behandlung bestimmen müssen. Der Wirkungsgrad nach Abbott entspricht meistens eher der experimentellen Wirklichkeit. Das soll dich natürlich nicht davon abschrecken auch die anderen Wirkunsggrade zu nutzen, aber dafür musst du meistens mehr Aufwand betreiben.
Der Wirkungsgrad nach Henderson-Tilton hate den großen Vorteil, dass wir auch eine zzeitliche Komponente mit berücksichtigen können. Wie verhält sich der BEfall der Kontrolle und der Behandlung über die Zeit des Versuches? Wir müssen dafür den Befall vor (eng. before, abk. b) und den Befall nach (eng. after, abk. a) der Applikation bestimmen. Dann erhalten wir folgende Formel, die die Anzahlen der Behandlung und Kontrolle räumlich wie zeitlich zusamenfasst. Nämlich einmal zu Beginn des Versuches und einmal zum Ende. Henderson-Tilton erlaubt es damit zusätzlich Unterschiede in der Populationsdynamik zu bewerten.
\[ WG_{HT} = \left(1 - \cfrac{T_a}{T_b}\cdot\cfrac{C_b}{C_a}\right) \]
mit
Hier nochmal ein kleines numerisches Beispiel mit \(T_b = 300\) sowie \(T_a = 30\) und \(C_b = 500\) sowie \(C_a = 1000\). Wir fangen also in einer Population mit einem Befall von \(500\) Trepsen in der Kontrolle an und haben am Ende des Versuches dann \(1000\) Trepsen in unserem Versuch vorliegen. In der Behandlung haben wir zu Beginn des Versuches \(300\) Trepsen im Feld gezählt und finden nach der Applikation unseres Pflanzenschutzmittels am Ende des Versuches noch \(30\) Trepsen wieder. Dann können wir einmal die Zahlen in die Formel einsetzen.
\[ WG_{HT} = \left(1 - \cfrac{T_a}{T_b}\cdot\cfrac{C_b}{C_a}\right) = \left(1 - \cfrac{30}{300}\cdot\cfrac{500}{1000}\right) = 1 - (0.1 \cdot 0.5) = 0.95 \]
Wir haben hier nun einen räumlichen und zeitlichen Bezug in unserem Wirkungsgrad abgebildet. Leider haben wir nicht immer einen Befall in unserem Bestand. Der Befall tritt erst während der Applikation auf. Dann müssen wir die Formel nach Abbott nutzen, die sich nur auf die Entwicklung des Befalls am Ende des Versuches konzentriert.
Im Folgenden wollen wir uns auf die Berechnung des Wirkungsgrad nach Abbott konzentrieren. Der Wirkungsgrad wird sehr häufig genutzt, so dass sich hier eine tiefere Betrachtung lohnt. Wir berechnen hier den Wirkungsgrad nach Abbott et al. (1925) erstmal sehr simpel an einem Beispiel. Dann nutzen wir R um die ganze Berechnung nochmal etwas komplexer durchzuführen. Abschließend schauen wir uns mit der Anpassung von Finner et al. (1989) noch eine Erweiterung des Wirkungsgrads nach Abbott an. Der Wirkungsgrad \(WG\) eines Schutzmittels im Vergleich zur Kontrolle berechnet sich wie folgt.
\[ WG_{Ab} = \left(\cfrac{C_a - T_a}{C_a}\right) = \left(1-\cfrac{T_a}{C_a}\right) \]
mit
Wir können auch nur den räumlichen Bezug mit dem Wirkungsgrad nach Abbott abbilden. Hier nochmal ein kleines numerisches Beispiel von oben mit \(T_b = 300\) sowie \(T_a = 30\) und \(C_b = 500\) sowie \(C_a = 1000\). Wir fangen also in einer Population mit einem Befall von \(500\) Trepsen in der Kontrolle an und haben am Ende des Versuches dann \(1000\) Trepsen in unserem Versuch vorliegen. In der Behandlung haben wir zu Beginn des Versuches \(300\) Trepsen im Feld gezählt und finden nach der Applikation unseres Pflanzenschutzmittels am Ende des Versuches noch \(30\) Trepsen wieder. Hier ist es wichtig, dass wir uns nicht den Zusammenhang über die Zeit anschauen können. Also entweder betrachten wir den Zusammenhang von nach unser Applikation oder aber den Vergleich von vorher und nachher von unserer Behandlung.
\[ WG_{Ab} = \left(1-\cfrac{T_a}{C_a}\right) = \left(1-\cfrac{30}{1000}\right) = 0.97 \]
Oder wir konzentrieren uns eben nur auf den zeitlichen Bezug in dem wir die Formel nach Abbott etwas modidifzieren und nur auf die Behandlung \(T\) schauen.
\[ WG_{Ab^*} = \left(1-\cfrac{T_a}{T_b}\right) = \left(1-\cfrac{30}{300}\right) = 0.90 \]
Natürlich ist die Formel wieder auf sehr einfachen Daten gut zu verstehen. Wir haben aber später dann in der Anwendung natürlich Datensätze, so dass wir uns hier einmal zwei Beispieldaten anschauen wollen. Zuerst schauen wir uns einen Datensatz zu dem Befall mit Trespe, einem Wildkraut, an. Wir haben also Parzellen in denen sich die Trespe ausbreitet und haben verschiedene Behandlungen durchgeführt. Wichtig hierbei, wir haben auch Parzellen wo wir nichts gemacht haben, das ist dann unsere positive Kontrolle (ctrl).
| variante | block_1 | block_2 | block_3 | block_4 |
|---|---|---|---|---|
| crtl | 16.0 | 16.0 | 4.8 | 11.2 |
| 2 | 4.8 | 4.0 | 0.0 | 2.4 |
| 3 | 10.4 | 2.4 | 0.0 | 0.0 |
| 4 | 8.0 | 8.8 | 7.2 | 4.0 |
In der Tabelle 24.6 haben wir dann einmal den Wirkungsgrad nach Abbott wg_abbott aus dem mittleren Befall über die vier Blöcke berechnet. Wir lassen hier mal weg, dass wir in einigen Parzellen mehr Befall hatten und deshab negative Wirkunsggrade. Hier hilft dann der Mittelwert.
wg_abbott berechnet aus dem mittleren Befall über die Blöcke.
| variante | block_1 | block_2 | block_3 | block_4 | mean | wg_abbott |
|---|---|---|---|---|---|---|
| crtl | 16.0 | 16.0 | 4.8 | 11.2 | 12.0 | 0.00 |
| 2 | 4.8 | 4.0 | 0.0 | 2.4 | 2.8 | 0.77 |
| 3 | 10.4 | 2.4 | 0.0 | 0.0 | 3.2 | 0.73 |
| 4 | 8.0 | 8.8 | 7.2 | 4.0 | 7.0 | 0.42 |
Dann das Ganze auch nochmal händisch aufbereitet und berechnet. Wir erhalten die gleichen Werte wie auch oben in der Tabelle.
\[ \begin{align} WG_2 &= \left(1 - \cfrac{2.8}{12}\right) = 0.77 \\ WG_3 &= \left(1 - \cfrac{3.2}{12}\right) = 0.73 \\ WG_4 &= \left(1 - \cfrac{7.0}{12}\right) = 0.42 \end{align} \]
Jetzt wollen wir etwas tiefer in die Thematik einsteigen und müssen daher einmal die Daten umwandeln, da unsere Daten nicht im Long-Format vorliegen. Wir müssen die Daten erst noch anpassen und dann die Spalte block in einen Faktor umwandeln. Laden wir einmal den Datensatz in R und verwandeln das Wide-Format in das Long-Format. Dann natürlich wie immer alle Faktoren als Faktoren mutieren.
trespe_tbl <- read_excel("data/raubmilben_data.xlsx", sheet = "trespe") %>%
pivot_longer(block_1:block_4,
names_to = "block",
values_to = "count") %>%
mutate(block = factor(block, labels = 1:4),
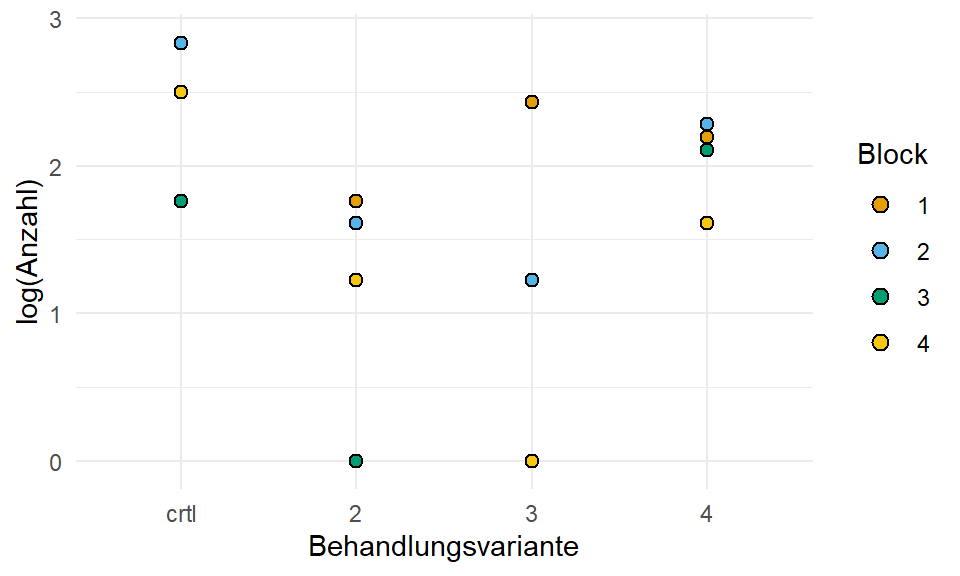
variante = as_factor(variante))In der Abbildung 24.5 sehen wir nochmal die orginalen, untransformierten Daten sowie die \(log\)-transformierten Daten. Wir nutzen die Funktion log1p() um die Anzahl künstlich um 1 zu erhöhen, damit wir Nullen in den Zähldaten zum Logarithmieren vermeiden.
ggplot(trespe_tbl, aes(variante, count, fill = block)) +
theme_minimal() +
geom_dotplot(binaxis = "y", stackdir = "center") +
labs(x = "Behandlungsvariante", y = "Anzahl", fill = "Block") +
scale_fill_okabeito()
ggplot(trespe_tbl, aes(variante, log1p(count), fill = block)) +
theme_minimal() +
geom_dotplot(binaxis = "y", stackdir = "center") +
labs(x = "Behandlungsvariante", y = "log(Anzahl)", fill = "Block") +
scale_fill_okabeito()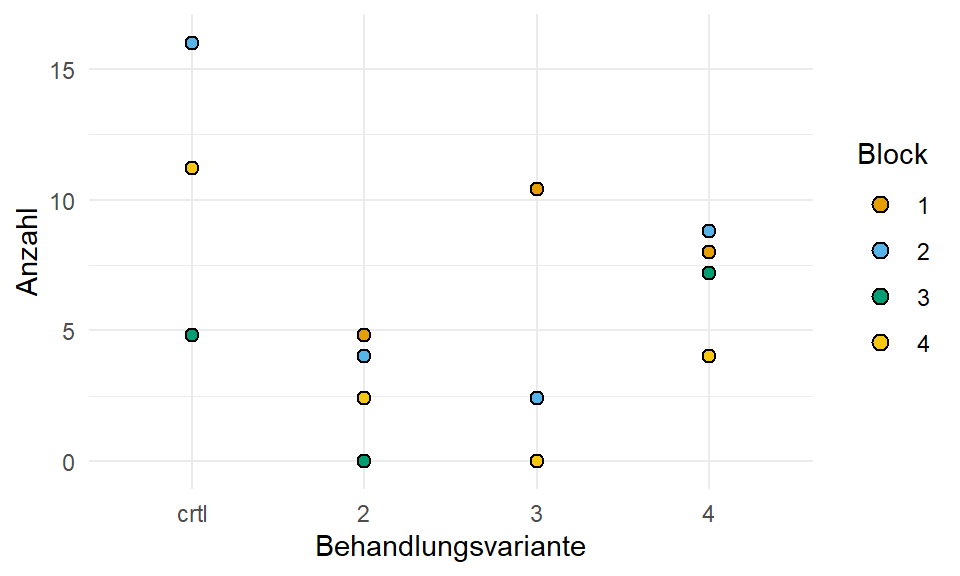
Nun geht es eigentlich ganz fix den Wirkungsgrad nach Abbott mit einer linearen Poisson Regression zu berechnen. Erstmal schätzen wir eine Poissonregression mit der Anzahl der Trespen als Outcome. Es ist wichtig in der Funktion glm() die Option family = poisson zu setzen. Sonst rechnen wir auch keine Poissonregression. Wir haben hier im Prinzip die effizientere Variante vorliegen, da wir durch die Modellierung auch noch andere Einflussfaktoren mit ins Modell nehemn können als nur den Block. Da wir hier aber nichts Weiteres gemessen haben, bleibt es bei dem einfachen Modell.
fit <- glm(count ~ variante + block, data = trespe_tbl, family = poisson)Wir nutzen die Schätzer aus dem Modell um mit der Funktion emmeans() die Raten in jeder Variante gemittelt über alle Blöcke zu berechnen. Dann müssen wir nur noch die Formel nach Abbott nutzen um jede Rate in das Verhältnis zur Rate der Kontrolle rate[1] zu setzen. Wir erhalten dann den Wirkungsgrad nach Abbott für unsere drei Varianten. Wie wir sehen, sind auch hier die Werte gleich.
res_trespe_tbl <- fit %>%
emmeans(~variante, type = "response") %>%
tidy() %>%
mutate(WG_abbott = (rate[1] - rate)/rate[1],
WG_abbott_per = percent(WG_abbott)) %>%
select(variante, rate, WG_abbott, WG_abbott_per)
res_trespe_tbl# A tibble: 4 × 4
variante rate WG_abbott WG_abbott_per
<chr> <dbl> <dbl> <chr>
1 crtl 10.8 0 0.0%
2 2 2.52 0.767 76.7%
3 3 2.89 0.733 73.3%
4 4 6.31 0.417 41.7% Damit haben wir den Wirkungsgard \(WG_{abbott}\) für unser Trepsenbeispiel einmal berechnet. Die Interpretation ist dann eigentlich sehr intuitiv. Wir haben zum Beispiel bei Variante 2 einen Wirkungsgrad von 76.7% der Kontrolle und somit auch eine Reduzierung von 76.7% der Trepsen auf unseren Parzellen im Vergleich zur Kontrolle.
Wir können auch einfach testen, ob sich die Kontrolle von den anderen Varianten sich unterscheidet. Wir nutzen dafür wieder die Funktion emmeans() und vergleichen alle Varianten zu der Kontrolle. Da die Kontrolle in der ersten Zeile steht bzw. das erste Level des Faktors variante ist, müssen wir noch die Referenz mit ref = 1 setzen.
fit %>%
emmeans(trt.vs.ctrlk ~ variante, type = "response", ref = 1) %>%
pluck("contrasts") contrast ratio SE df null z.ratio p.value
2 / crtl 0.233 0.0774 Inf 1 -4.385 <.0001
3 / crtl 0.267 0.0839 Inf 1 -4.202 0.0001
4 / crtl 0.583 0.1390 Inf 1 -2.267 0.0633
Results are averaged over the levels of: block
P value adjustment: dunnettx method for 3 tests
Tests are performed on the log scale Wir wir sehen, sind alle Varianten, bis auf die Variante 4, signifikant unterschiedlich zu der Kontrolle. Nun könnten wir uns auch Fragen in wie weit sich die Wirkungsgrade untereinander unterscheiden. Dafür müssen wir dann die Anteile mit der Funktion pairwise.prop.test() paarweise Vergleichen. Da wir natürlich auf die Kontrolle standardisieren hat der Vergleich mit der Kontrolle nur so halbwegs Sinn, mag aber von Interesse sein.
pairwise.prop.test(x = res_trespe_tbl$WG_abbott * 100,
n = c(100, 100, 100, 100),
p.adjust.method = "none")
Pairwise comparisons using Pairwise comparison of proportions
data: res_trespe_tbl$WG_abbott * 100 out of c(100, 100, 100, 100)
1 2 3
2 < 2e-16 - -
3 < 2e-16 0.7 -
4 1.4e-12 1.0e-06 1.2e-05
P value adjustment method: none Wir sehen, dass sich alle Varianten in ihrem Wirkungsgrad von der Kontrolle unterscheiden, die Kontrolle hat hier die ID 1. Die Variante 4 unterscheidet sich von allen anderen Varianten in ihrem Wirkungsgrad.
Im zweiten Beispiel wollen wir uns mit dem geometrischen Mittel \(WG_{geometric}\) als Schätzer für den Wirkungsgrad beschäftigen. Hier kochen wir dann einmal die Veröffentlichung von Finner et al. (1989) nach. Dafür brauchen wir einmal die Daten zu den Raubmilben, die ich schon als Exceldatei aufbereitet habe. Wie immer sind die Rohdaten im Wide-Format, wir müssen aber im Long-Format rechnen. Da bauen wir uns also einmal schnell die Daten um. Dann wollen wir noch die Anzahlen der Raubmilben logarithmieren, so dass wir jede Anzahl um 1 erhöhen um logarithmierte Nullen zu vermeiden. Das ganze machen wir dann in einem Rutsch mit der Funktion log1p().
mite_tbl <- read_excel("data/raubmilben_data.xlsx", sheet = "mite") %>%
pivot_longer(block_1:block_5,
names_to = "block",
values_to = "count") %>%
mutate(block = factor(block, labels = 1:5),
sorte = as_factor(sorte),
log_count = log1p(count))| sorte | block_1 | block_2 | block_3 | block_4 | block_5 |
|---|---|---|---|---|---|
| 1 | 0 | 2 | 2 | 21 | 0 |
| 2 | 302 | 108 | 64 | 23 | 49 |
| 3 | 59 | 51 | 59 | 1 | 26 |
| 4 | 64 | 154 | 41 | 27 | 41 |
| 5 | 45 | 141 | 51 | 70 | 37 |
| 6 | 58 | 240 | 140 | 27 | 11 |
| 7 | 1 | 2 | 3 | 8 | 16 |
| 8 | 4 | 1 | 0 | 0 | 1 |
| ctrl | 46 | 32 | 62 | 90 | 20 |
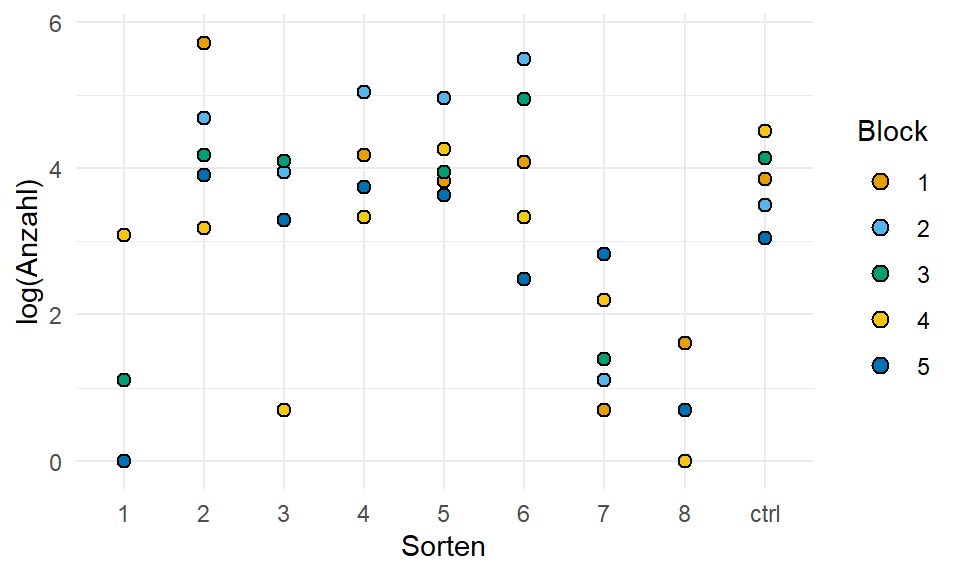
Schauen wir uns einmal die Daten in der Abbildung 24.6 an. Wichtig ist, dass wir usn merken, dass in unseren Daten jetzt die Kontrolle an der neuten Position ist. Das ist eben in diesen Daen so, ich hätte die Sortierung dann anders gemacht. Aber wir arbeiten hier mit dem was wir vorliegen haben.
ggplot(mite_tbl, aes(sorte, count, fill = block)) +
theme_minimal() +
geom_dotplot(binaxis = "y", stackdir = "center") +
labs(x = "Sorten", y = "Anzahl", fill = "Block") +
scale_fill_okabeito()
ggplot(mite_tbl, aes(sorte, log1p(count), fill = block)) +
theme_minimal() +
geom_dotplot(binaxis = "y", stackdir = "center") +
labs(x = "Sorten", y = "log(Anzahl)", fill = "Block") +
scale_fill_okabeito()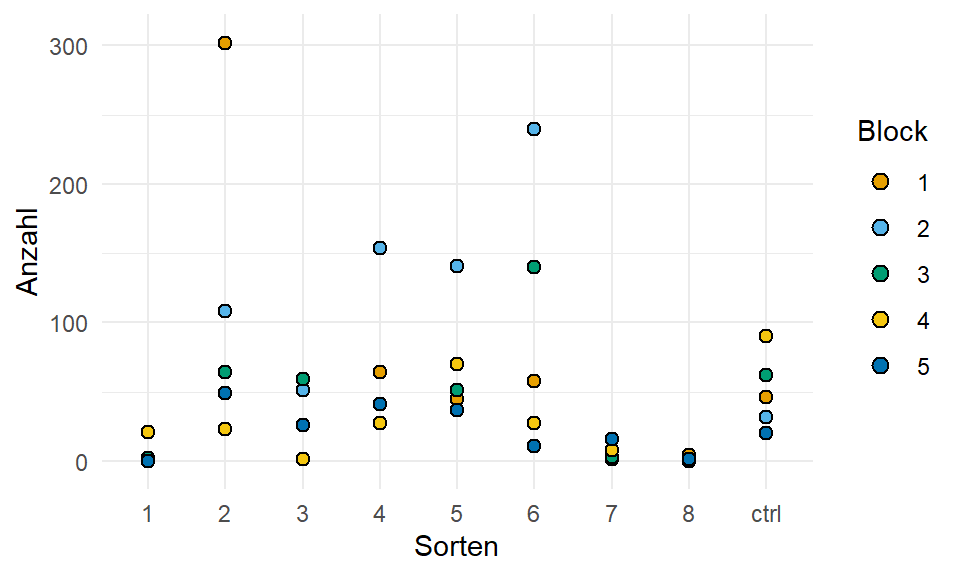
Wir brauchen jetzt eine Helferfunktion, die uns aus \(Pr\) die Gegenwahrscheinlichkeit \(1 - Pr\) berechnet. Auch wollen wir dann die Prozentangabe der Gegenwahrscheinlichkeit, also die Gegenwahrscheinlichkeit \(1 - Pr\) multipliziert mit Einhundert. Dann brauchen wir als Variable noch die Gruppengröße \(n_g\), die bei uns ja bei 5 liegt. Wir haben pro Sorte fünf Beobachtungen je Block.
get_q <- function(x){100 * (1 - x)}
n_group <- 5Wir nutezn jetzt das geometrisches Mittel um den Effekt der Behandlung bzw. Sorte im Verhältnis zur Kontrolle zu berechnen. Hierbei ist es wichtig sich zu erinnern, dass wir nicht alle paarweisen Vergleiche rechnen, sondern nur jede Sorte \(j\) zu der Kontrolle \(ctrl\) vergleichen. Dabei nutzen wir dann das Verhältnis der geometrisches Mittel um zu Beschreiben um wie viel weniger Befall mit Raubmilden wir in den Sorten \(y_j\) im Verhältnis zur Kontrolle \(y_{ctrl}\) vorliegen haben.
\[ \Delta_{geometric} = \left(\cfrac{\prod_{i=1}^n y_j}{\prod_{i=1}^n y_{ctrl}}\right)^{1/n_j} \mbox{ für Sorte } j \]
Berechnen wir also als erstes einmal das Produkt aller gezählten Raubmilden pro Sorte und speichern das Ergebnis in der Spalte prod.
mite_wg_gemetric_tbl <- mite_tbl %>%
mutate(count = count + 1) %>%
group_by(sorte) %>%
summarise(prod = prod(count))
mite_wg_gemetric_tbl# A tibble: 9 × 2
sorte prod
<fct> <dbl>
1 1 198
2 2 2576106000
3 3 10108800
4 4 497624400
5 5 916413472
6 6 673639344
7 7 3672
8 8 20
9 ctrl 186729543Jetzt können wir im nächsten Schritt einmal das \(\Delta_{geometric}\) berechnen und dann den Wirkungsgrad über die Gegenwahrscheinlichkeit. Wichtig ist hier, dass die Kontrolle in der neunten Zeile ist. Daher teilen wir immer durch das Produkt an neunter Position mit prod[9]. Wir sehen ganz klar, das wir ein Delta von 1 für die Kontrolle erhalten, da wir ja die Kontrolle ins Verhältnis zur Kontrolle setzen. Damit sollte der Rest auch geklappt haben. Den Wirkungsgrad der Sorten in Prozent gegen Raubmilbenbefall im Verhältnis zur Kontrolle können wir dann direkt ablesen. Die Funktion percent() berechnet uns aus den Gegenwahrscheinlichkeiten dann gleich die Prozent. Wir brauchen daher hier noch nicht unsere Funktion get_q().
mite_wg_gemetric_tbl %>%
mutate(delta_geometric = (prod/prod[9])^(1/n_group),
WG_geometric = percent(1 - delta_geometric))# A tibble: 9 × 4
sorte prod delta_geometric WG_geometric
<fct> <dbl> <dbl> <chr>
1 1 198 0.0638 93.6%
2 2 2576106000 1.69 -69.0%
3 3 10108800 0.558 44.2%
4 4 497624400 1.22 -21.7%
5 5 916413472 1.37 -37.5%
6 6 673639344 1.29 -29.3%
7 7 3672 0.114 88.6%
8 8 20 0.0404 96.0%
9 ctrl 186729543 1 0.0% Soweit haben wir erstmal nur eine andere Variante des Wirkungsgrades berechnet. Im Gegensatz zu der Berechnung nach Abbott et al. (1925) können wir aber bei den geometrischen Wirkungsgrad auch ein einseitiges 95% Konfidenzintervall \([-\infty; upper]\) angeben. Dafür müssen wir erstmal den Exponenten \(a\) berechnen und mit diesem dann die obere Konfidenzschranke \(upper\). Dafür brauchen wir dann doch ein paar statistische Maßzahlen.
\[ \begin{align} a &= \sqrt{2/n} \cdot s \cdot t_{\alpha=5\%} + \ln(1 - \Delta_{geometric})\\ upper &= 1 - e^a \end{align} \]
Wir brauchen zum einen die Freiheitsgrade der Residuen df.residual sowie den Standardfehler der Residuen sigma oder \(s\). Beides erhalten wir aus einem linearen Modell auf den logarithmierten Anzahlen der Raubmilben.
residual_tbl <- lm(log_count ~ sorte + block, data = mite_tbl) %>%
glance() %>%
select(df.residual, sigma)
residual_tbl# A tibble: 1 × 2
df.residual sigma
<int> <dbl>
1 32 0.962Mit den Freiheitsgraden der Residuen können wir jetzt den kritischen Wert \(t_{\alpha = 5\%}\) aus der \(t\)-Verteilung berechnen.
t_quantile <- qt(p = 0.05, df = residual_tbl$df.residual, lower.tail = FALSE)
t_quantile[1] 1.693889Wir können jetzt unseren Datensatz mite_wg_gemetric_tbl um die Spalte mit den Werten des Exponenten \(a\) ergänzen und aus diesem dann die obere Schranke des einseitigen 95% Konfidenzintervall berechnen. Die Werte für die Kontrolle ergeben keinen biologischen Sinn und sind ein mathematisches Artefakt. Wir kriegen halt immer irgendwelche Zahlen raus.
mite_res_tbl <- mite_wg_gemetric_tbl %>%
mutate(delta_geometric = (prod/prod[9])^(1/n_group),
WG_geometric = get_q(delta_geometric),
a = sqrt(2/n_group) * residual_tbl$sigma * t_quantile + log(delta_geometric),
upper = get_q(exp(a)))
mite_res_tbl# A tibble: 9 × 6
sorte prod delta_geometric WG_geometric a upper
<fct> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 198 0.0638 93.6 -1.72 82.1
2 2 2576106000 1.69 -69.0 1.56 -374.
3 3 10108800 0.558 44.2 0.447 -56.4
4 4 497624400 1.22 -21.7 1.23 -241.
5 5 916413472 1.37 -37.5 1.35 -285.
6 6 673639344 1.29 -29.3 1.29 -262.
7 7 3672 0.114 88.6 -1.14 67.9
8 8 20 0.0404 96.0 -2.18 88.7
9 ctrl 186729543 1 0 1.03 -180. Wir räumen nochmal die Ausgabe auf und konzentrieren uns auf die Spalten und runden einmal die Ergebnisse.
mite_res_tbl %>%
select(sorte, WG_geometric, upper) %>%
mutate(across(where(is.numeric), ~round(.x, 2))) # A tibble: 9 × 3
sorte WG_geometric upper
<fct> <dbl> <dbl>
1 1 93.6 82.1
2 2 -69.0 -374.
3 3 44.2 -56.4
4 4 -21.7 -241.
5 5 -37.5 -285.
6 6 -29.2 -262.
7 7 88.6 67.9
8 8 96.0 88.7
9 ctrl 0 -180. Wir können wir jetzt das einseitige 95% Konfidenzintervall interpretieren? In der Sorte 1 erhalten wir einen Wirkungsgrad von 93.6% und mit 95% Sicherheit mindestens einen Wirkungsgrad von 82.1%. Damit haben wir auch eine untere Schranke für unseren Wirkungsgradschätzer. Wir berichten für die Sorte 1 einen Wirkungsgrad von 93.6% [\(-\infty\); 82.1%].
Genauso können wir aber auch den Wirkungsgrad nach Abbott et al. (1925) nochmal auf den Daten berechnen. Dafür müssen wir nur eine Poissonregression auf der Anzahl der Raubmilben rechnen. Die angepassten Werte können wir dann verwenden um den \(WG_{abbott}\) zu schätzen.
fit <- glm(count ~ sorte + block, data = mite_tbl, family = poisson)Wir nutzen hier dann die Funktion emmeans() um die mittlere Anzahl an Raubmilben über alle Blöcke zu ermitteln. Dann können wir auch schon den \(WG_{abbott}\) berechnen. Wichtig ist hier, dass die Referenzkategorie mit der Kontrolle an der neunten Stelle bzw. Zeile steht. Deshalb müssen wir auch hier durch prod[9] teilen. Achtung, die \(p\)-Werte haben hier keine tiefere Bedeutung im Bezug auf den Wirkungsgrad und deshalb schauen wir uns diese Werte auch gar nicht tiefer an.
res_mite_tbl <- fit %>%
emmeans(~sorte, type = "response") %>%
tidy() %>%
mutate(WG_abbott = (rate[9] - rate)/rate[9],
WG_abbott_per = percent(WG_abbott)) %>%
select(sorte, WG_abbott, WG_abbott_per, rate)
res_mite_tbl# A tibble: 9 × 4
sorte WG_abbott WG_abbott_per rate
<chr> <dbl> <chr> <dbl>
1 1 0.900 90.0% 4.49
2 2 -1.18 -118.4% 98.0
3 3 0.216 21.6% 35.2
4 4 -0.308 -30.8% 58.7
5 5 -0.376 -37.6% 61.7
6 6 -0.904 -90.4% 85.4
7 7 0.880 88.0% 5.38
8 8 0.976 97.6% 1.08
9 ctrl 0 0.0% 44.9 Wenn du verwirrt bist über die negativen Wirkungsgrade, dann musst du dir klar werden, dass wir immer den Wirkungsgrad im Verhältnis zur Kontrolle berechnen. Wenn du also negative Wirkungsgrade siehst, dann sind die Anzahlen in den Sorten höher als in der Kontrolle. Je nach Fragestellung macht dieses Ergebnis mehr oder weniger Sinn.
Auch hier können wir noch schnell einen statistischen Test rechnen und die Sorten zu der Kontrolle ref = 9 vergleichen.
fit %>%
emmeans(trt.vs.ctrlk ~ sorte, type = "response", ref = 9) %>%
pluck("contrasts") contrast ratio SE df null z.ratio p.value
1 / ctrl 0.100 0.02100 Inf 1 -10.977 <.0001
2 / ctrl 2.184 0.16700 Inf 1 10.229 <.0001
3 / ctrl 0.784 0.07480 Inf 1 -2.551 0.0686
4 / ctrl 1.308 0.11000 Inf 1 3.196 0.0101
5 / ctrl 1.376 0.11400 Inf 1 3.841 0.0009
6 / ctrl 1.904 0.14900 Inf 1 8.244 <.0001
7 / ctrl 0.120 0.02320 Inf 1 -10.973 <.0001
8 / ctrl 0.024 0.00991 Inf 1 -9.028 <.0001
Results are averaged over the levels of: block
P value adjustment: dunnettx method for 8 tests
Tests are performed on the log scale Wir wir sehen, sind alle Varianten signifikant unterschiedlich zu der Kontrolle bis auf die Sorte 3.
Auch hier können wir die Wirkungsgrade miteinander vergleichen. Aber Achtung, wir können nur Wirkungsgrade zwischen 0 und 1 miteinander sinnvoll vergleichen. Deshalb fliegen bei uns einige an Sorten raus. Darüber hinaus musst du jetzt auch einmal schauen, welche Sorte sich hinter der numerischen ID aus dem pairwise.prop.test() verbirgt.
res_mite_tbl %>%
filter(WG_abbott < 1 & WG_abbott >= 0) %$%
pairwise.prop.test(x = WG_abbott * 100,
n = rep(100, 5),
p.adjust.method = "none")
Pairwise comparisons using Pairwise comparison of proportions
data: WG_abbott * 100 out of rep(100, 5)
1 2 3 4
2 < 2e-16 - - -
3 0.821 < 2e-16 - -
4 0.053 < 2e-16 0.019 -
5 < 2e-16 2.7e-06 < 2e-16 < 2e-16
P value adjustment method: none Das letzte Beispiel zeigt nochmal schön, dass wir uns immer überlegen müssen, was wir mit den Wirkungsgraden eigentlich zeigen wollen und welche Wirkungsgrade noch eine biologisch sinnvolle Bedeutung haben.
Der Wirkungsgrad nach Sun-Shepard bezieht sich auf die Mortalität [%] in unserem Versuch. Wir können müssen hier auch vor der Applikation und nach der Applikation in unserer Kontrolle die Mortalität bestimmen, sonst können wir nicht das \(C_{\Delta}\) in der Kontrolle berechnen. Auf der Webseite von Ehab Bakr, auf die sich irgendwie in einem Zirkelschluss alle meine gefundenen Quellen beziehen, steht dann zwar \(\pm\) aber ich denke, dass hier ausgesagt werden soll, dass \(C_{\Delta}\) negativ oder positiv sein kann. Dann können wir auch auch besser nur Plus schreiben und damit ist dann die Formel auch in sich konsistent. Das passt dann auch zu der Durchführung und dem Beispiel auf der Webseite.
\[ WG_{SS} = \left(\cfrac{T + C_{\Delta}}{1 + C_{\Delta}}\right) \]
und
\[ C_{\Delta} = \left(\cfrac{C_a - C_b}{C_b}\right) \]
mit
Der Wirkungsgrad nach Schneider-Orelli betrachtet nur die Mortalität nach dem Versuch und ist somit mit dem Wirkungsgrad nach Abbott zu vergleichen. Die Formel ist dabei sehr simpel
\[ WG_{SO} = \left(\cfrac{T_a - C_a}{1 - C_a}\right) \]
mit
Worum geht es jetzt in diesem Abschnitt? Wir wollen uns anschauen, ob verschiedene Bewerter auf die gleichen Noten oder Einschätzungen kommen. Das ist eher selten im Kontext einer Abschlussarbeit, aber kommt häufiger bei der Bonitur vor. Wir können uns dabei zwei Fälle vorstellen. Zum einen wollen wir wissen ob zwei oder mehr Bewerter auf die gleichen Noten kommen, wenn sie das gleiche Subjekt bewerten. Wir haben also eine Rasenfläche oder ein Schwein vor uns und drei Forschende sollen bestimmen wie krank der Rasen oder das Schwein auf einer Skala von 1 bis 9 ist. Vorher wurden natürlich alle drei auf der Notensakal trainiert. Das würden wir dann die Interrater Reliabilität nennen. Benoten zwei oder mehr Bewerter ein Subjekt nach einem gegebenen Notenschlüssen und Kriterien gleich. Wichtig ist hier, dass es ein Kriterienkatalog gibt. Wir machen machen hier also nicht auf Geratewohl los.
Die andere Möglichkeit ist, dass wir wissen wollen, ob ein Bewerter selber konstante Benotungen an dem gleichen Subjekt liefert. Das können wir durch Fotos und zufällige Zuordnung machen oder eben eine Stunde oder Zeit dazwischen lassen. Wir sprechen dann von Intrarater Reliabilität. Diese Art der Reliabilität ist etwas seltener und kann auch gleich gelöst werden wie der Vergleich von unterschiedlichen Bewertern. Meistens reicht es dann auch aus und wir müssen die Korrelation durch den gleichen Bewerter eigentlich nicht weiter beachten.
Unterscheiden sich die Bewertungen oder Benotungen an einer Beobachtung zwischen zwei oder mehr Bewertern?
Unterscheiden sich die Bewertungen oder Benotungen eines Bewerters an einer Beobachtung über die Zeit?
Reliabilität ist der Grad an Übereinstimmung einer Messung, wenn diese unter identischen Bedingungen jedoch von unterschiedlichen Bewertern wiederholt wird. Anhand der Interrater Reliabilität wird es somit möglich, den Grad zu ermitteln, in dem sich die erhaltenen Ergebnisse wiederholen lassen. Eine wunderbare Übersicht zur Interrater Reliabilität gibt auf Data Novia mit Introduction to R for Inter-Rater Reliability Analyses. Ebenso liefert das Tutorium Inter-rater-reliability and Intra-class-correlation einen guten Überblick über alle Methoden in R. Wir schauen uns jetzt einmal die häufigsten Maßzahlen für die Reliabilität an. Für das erste beschränken wir uns hier einmal auf Cohen’s Kappan.
Fangen wir mit dem simpelsten Fall an. Wir haben zwei Bewerter \(R_1\) und \(R_2\) und wir wollen schauen, ob diese beiden Bewerter ein Subjekt richtig in \(ja\) oder \(nein\) einordnen. So kann die Frage sein, hat die Sonnenblume Mehltau? Oder aber die Frage, ist das Schwein erkrankt? Wir haben hier keine Wahrheit vorliegen, sondern wollen einfach nur wissen, ob unsere beiden Bewerter zum gleichen Schluss kommen. Dafür können wir dann Cohen’s Kappa \(\kappa\) nutzen. Dabei ist die Verwendung von Cohen’s Kappa nicht unumstritten. Maclure & Willett (1987) diskutiert in seiner Arbeit Misinterpretation and misuse of the kappa statistic diesen Sachverhalt. Fangen wir einmal mit einem Beispiel an. Die Tabelle 24.8 zeigt einmal das Ergebnis von siebzig bewerteten Subjekten. Wir haben hier zwei Bewerter vorliegen, die jeweils mit \(ja\) oder \(nein\) bewerten sollten. In R kannst du dir später so eine Tabelle einfach mit der Funktion xtabs() bauen.
| Bewerter 1 | |||
| ja (1) | nein (0) | ||
| Bewerter 2 | ja (1) | \(25_{\;\Large a}\) | \(10_{\;\Large b}\) |
| nein (0) | \(15_{\;\Large c}\) | \(20_{\;\Large d}\) |
Als Faustregel für Cohen’s Kappa \(\kappa\) dient dabei, dass die Diagonale von links oben nach rechts unten die Übereinstimmungen zeigt. Die Diagonale von links unten nach rechts oben zeigt dann die Nichtübereinstimmung. Das ist natürlich nur eine grobe Abschätzung im Folgenden einmal die Formel mit der du dann Cohen’s Kappa \(\kappa\) berechnen kannst.
\[ \kappa = \cfrac{p_0 - p_e}{1 - p_e} \]
mit
Das ist jetzt natürlich wieder sehr theoretisch. Deshalb wollen wir einmal die beiden Teile \(p_0\) und \(p_e\) aus den obigen Daten berechnen. Wenn du jetzt denkst, dass dir das doch irgendwie bekannt vorkommt, ja der \(\mathcal{X}^2\)-Test sieht sehr ähnlich aus. Wir können \(p_0\) wie folgt aus der 2x2 Kreuztabelle berechnen. Wir schauen hier auf die Übereinstimmungen auf der Diagonalen von obeb links nach unten rechts.
\[ p_0 = \cfrac{a + d}{N} = \cfrac{25 + 20}{70} = 0.643 \]
Für den Wert von \(p_e\) brauchen wir zwei Werte, die wir dann aufaddieren. Einmal berechnen wir den Wert für \(p_e\) von \(ja\) und einmal den Wert von \(p_e\) für \(nein\). Das geht dann mit der Formel auch recht schnell. Wir schauen hier im Prinzip auf die Diagonale von unten links nach oben rechts.
\[ p_e^{ja} = \cfrac{a + b}{N} \cdot \cfrac{a + c}{N} = \cfrac{25+10}{70} \cdot \cfrac{25+15}{70} = 0.5 \cdot 0.57 = 0.285 \]
\[ p_e^{nein} = \cfrac{c + d}{N} \cdot \cfrac{b + d}{N} = \cfrac{15+20}{70} \cdot \cfrac{10+20}{70} = 0.5 \cdot 0.428 = 0.214 \]
Dann addieen wir die beiden Werte für \(p_e\) einmal auf.
\[ p_e = p_e^{ja} + p_e^{nein} = 0.285 + 0.214 = 0.499 \]
Dann können wir auch schon Cohen’s Kappa \(\kappa\) für eine 2x2 Kreuztabelle berechnen. Ehrlicherweise, machen wir das dann natürlich gleich in R.
\[ \kappa = \cfrac{0.643 - 0.499}{1 - 0.499} = 0.28 \]
Dabei interpretieren wir dann Cohen’s Kappa \(\kappa\) wie folgt. Beachte dabei immer, dass es sich natürlich erstmal nur um eine grobe Abschätzung handelt. Wie gut oder wie schlecht dann diese Zahl von Cohen’s Kappa \(\kappa\) in deinem Bereich ist, liegt dann auch daran wie genau du arbeiten möchtest.
Cohen’s Kappa kann von -1 (keine Übereinstimmung) bis +1 (perfekte Übereinstimmung) reichen. Wenn \(\kappa = 0\) ist, ist die Übereinstimmung nicht besser als das, was durch Zufall erreicht werden würde. Wenn \(\kappa\) negativ ist, ist die Übereinstimmung geringer als die zufällig erwartete Übereinstimmung. Wenn \(\kappa\) positiv ist, übersteigt die Übereinstimmung der Bewerter die zufällige Übereinstimmung.
Was sind jetzt die exakten grenzen für die Cohen’s Kappa Werte? Das kannst du dir fast wieder aussuchen wie du möchtest. Es gibt eine Reihe von Publikationen, die alle verschiedene Grenzwerte liefern. Gerne kannst du dir die Tabellen in dem Tutorium Cohen’s Kappa in R: For Two Categorical Variables einmal näher anschauen. Ich würde dann mal als Quintessenz folgende Regel von McHugh (2012) nehmen.
| Cohen’s Kappa | Level of agreement | % of data that are reliable |
|---|---|---|
| 0 - 0.20 | None | 0 - 4‰ |
| 0.21 - 0.39 | Minimal | 4 - 15% |
| 0.40 - 0.59 | Weak | 15 - 35% |
| 0.60 - 0.79 | Moderate | 35 - 63% |
| 0.80 - 0.90 | Strong | 64 - 81% |
| Above 0.90 | Almost Perfect | 82 - 100% |
Das R Paket {vcd} liefert nun die Funktion Kappa() mit der wir auf einer 2x2 Kreuztabelle zum Beispiel aus der Funktion xtabs() dann Cohen’s Kappa \(\kappa\) berechnen können. Die Funktion xtabs() hilft dir aus zwei oder mehr Spalten eine Kreuztabelle zu bauen.
xtab <- as.table(rbind(c(25, 10), c(15, 20)))Dann können wir auch schon Cohen’s Kappa \(\kappa\) in R berechnen.
kappa_res <- Kappa(xtab)
kappa_res value ASE z Pr(>|z|)
Unweighted 0.2857 0.1134 2.52 0.01173
Weighted 0.2857 0.1134 2.52 0.01173Die ungewichtete Version entspricht dem Cohen’s Kappa, mit dem wir uns in diesem Kapitel beschäftigen. Das gewichtete Kappa sollte nur für ordinale Variablen betrachtet werden und wird weitgehend hier ignoriert. Dann noch die Konfidenzintervalle und alles ist soweit da, was wir brauchen.
kappa_res |>
confint()
Kappa lwr upr
Unweighted 0.06352154 0.507907
Weighted 0.06352154 0.507907Das Ganze geht natürlich nicht nur für zwei Level (ja/nein) sondern dann in R auch für mehrere Level. Also wenn wir zum Beispiel dann Boniturnoten einmal bewerten und dann für zwei Bewerter vergleichen wollen.
Cohen’s Kappa für mehr als zwei Bewerter liefert das R Paket {irr} mit der Funktion kappam.light() oder kappam.fleiss(), wenn es dann auch noch mehr Kategorien als zwei in den Spalten gibt. Das R Paket ist schon ziemlich alt und hat auch sehr schlechte bis gar keine Hilfeseiten. Wenn man weiß, was man braucht und die Funktion bedeuten, dann kannst du das Paket gut nutzen.
Hier helfen dann auch die passenden Tutorien weiter. Ich habe hier nochmal die beiden anderen Fälle aufgelistet, wenn du eben Noten oder noch andere Kategorien in deinen Daten hast. Im Prinzip änderst du nur deine Funktion die du dann nutzt. Die Bewertung der einzelnen Ausgaben schwankt dann auch leicht. Aber eine Eins bedeutet immer eine perfekte Übereinstimmung.
Kappa() aus dem R Paket {vcd}. Wir nutzen dann die Weighted Zeile in der Ausgabe der Funktion.kappam.fleiss() aus dem R Paket {irr}.Damit wären wir hier soweit erstmal fertig. Im nächsten Abschnitt schauen wir uns dann einmal den Fall an, dass wir kontinuierliche Bewertungen haben. Wir haben nämlich gezählt, was ja auch eine Art der Bewertung ist. Nur eben nicht auf einer Notenskala sondern eben kontinuierlich.
Jetzt betrachten wir einen Datensatz indem Entenküken auf verschiedenen Bildern von Studierenden gezählt werden sollten. Insgesamt haben wir vier Studierende als Bewerter, die die Küken dann in zwei voneinander getrennten Sessions bewertet haben. Wir laden also einmal den Datensatz und schauen uns die Zähldaten einmal an.
duck_tbl <- read_excel("data/interrater_duck_count.xlsx")In der Tabelle 24.10 siehst du einmal einen Auszug aus den Entendaten. Dabei steht die id für ein Bild, die Spalte session beschreibt die beiden Termine, wo die Studierenden dann die Bilder ausgezählt haben.
| id | session | rater_1 | rater_2 | rater_3 | rater_4 |
|---|---|---|---|---|---|
| #385 | 1 | 106 | 115 | 100 | 82 |
| #387 | 1 | 77 | 94 | 103 | 77 |
| #374 | 1 | 120 | 131 | 213 | 133 |
| #381 | 1 | 115 | 127 | 208 | 135 |
| #871 | 1 | 104 | 165 | 97 | 165 |
| … | … | … | … | … | … |
| #874 | 2 | 43 | 39 | 33 | 43 |
| #826 | 2 | 110 | 122 | 114 | 117 |
| #832 | 2 | 104 | 99 | 89 | 106 |
| #836 | 2 | 101 | 100 | 107 | 103 |
| #821 | 2 | 92 | 106 | 108 | 94 |
Da so eine Datentabelle dann imer schwer zu lesen ist, dann hier einmal in der Abbildung 24.7 die Visualisierung der Daten. Wir sehen, dass die zweite Session schonmals ehr viel weniger Varianz zeigt und sich die Bewerter sehr viel ähnlicher sind als bei der ersten Session. Darüber hinaus ist der dritte Bewerter in der ersten Session am schlechtesten, da er die größte Varianz und Abweichung zu den anderen Bewertern zeigt.
duck_tbl |>
pivot_longer(cols = rater_1:rater_4,
values_to = "count",
names_to = "rater") |>
mutate(session = as_factor(session)) |>
ggplot(aes(x = rater, y = count, color = session, label = id)) +
theme_minimal() +
geom_text(position = position_dodge(0.5), show.legend = FALSE) +
scale_color_okabeito() +
labs(x = "Bewerter", y = "Gezählte Anzahl an Entenküken auf dem Bild")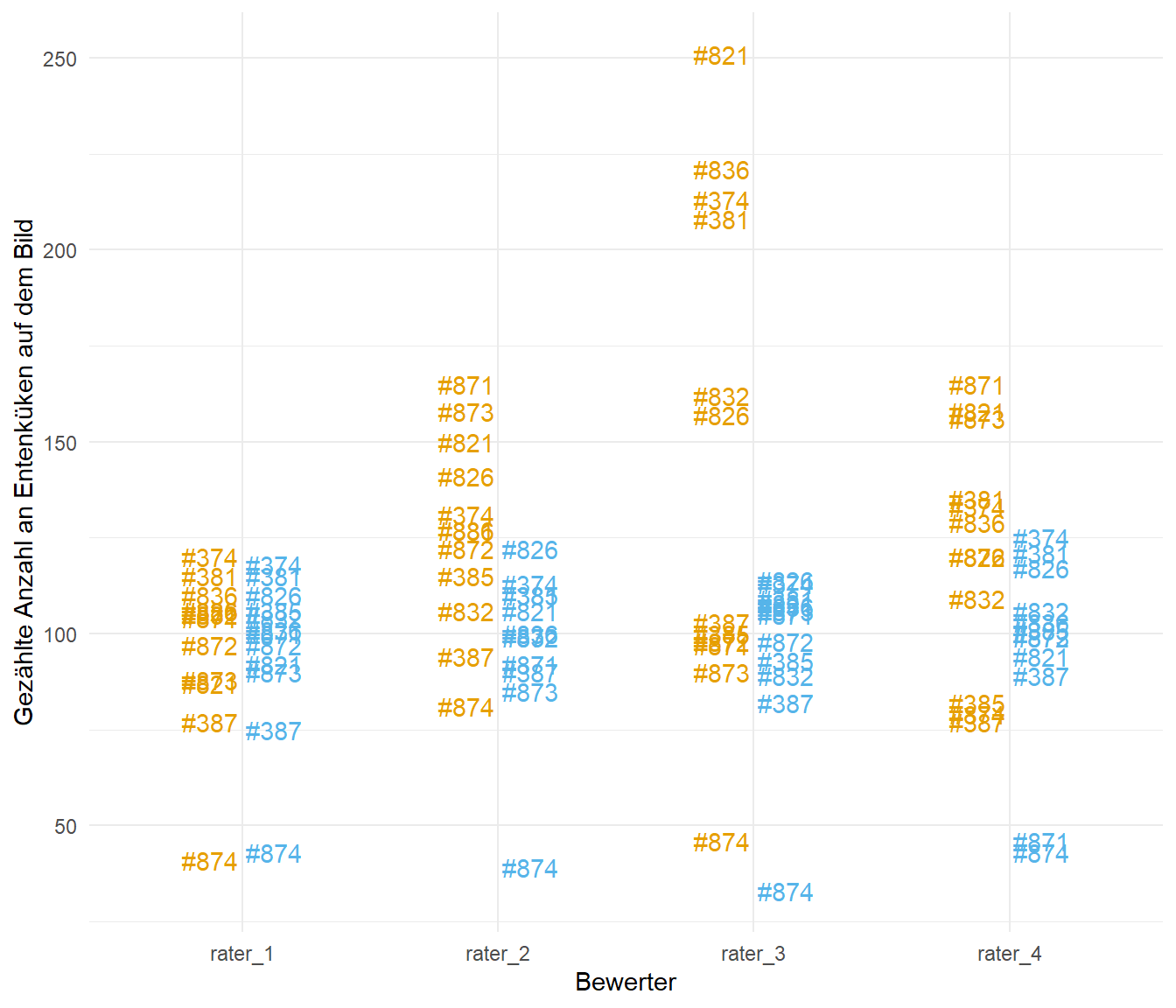
Was erwarten wir nun? Zum einen sollte die zweite Session bessere Übereinstimmungen liefern als die erste Session. Immerhin haben ja die Studierenden geübt. Wir nutzen jetzt hier den Intraclass Correlation Coefficient (ICC) in R um auf die Reliabilität von Bewertern zurückzuschließen. Das Tutorium liefert nochmal eine Reihe an mehr Informationen. Ich halte hier die Sachlage relativ kurz. Wir wollen hier mal prinzipiell schauen, wie unsere Bewerter so abschneiden. Als zweite Überlegung wollen wir dann noch wissen, ob unsere Bewerter dann auch konsistent sind. Daher die erste Session genauso wie die zweite Session bewertet haben. Aber auch hier Achtung, wir wissen nicht die Wahrheit. Wir schauen nur, ob die beiden Sessions gleich waren. Ein Bewerter, der in der ersten Session versagt und in der zweiten alles richtig zählt, würde hier also schlechter wegkommen, als ein Bewerter, der nichts gelernt hat und in beiden Fällen schlecht zählt. Wir würden dann nur sehen, dass die Bewerter untereinander nicht passen.
Betrachten wir also einmal in den beiden folgenden Tabs die beiden Sessions getrennt voneinander über alle Bewerter hinweg und berechnen den Intraclass Correlation Coefficient (ICC). Der ICC-Wert läuft von 0 bis 1, wobei 0 dann gar keine Übereinstimmung und 1 eine perfekte Übereinstimmung bedeutet. Wir würden sagen, dass ab 0.9 eine perfekte Übereinstimmung und unter 0.5 eine schlechte Übereinstimmung vorliegt. Wichtig ist hier, dass die Funktion icc() nur die Spalten mit den Bewertungen will und sonst rein gar nichts.
duck_tbl |>
filter(session == 1) |>
select(matches("rater")) |>
icc(model = "twoway", type = "agreement", unit = "single") Single Score Intraclass Correlation
Model: twoway
Type : agreement
Subjects = 12
Raters = 4
ICC(A,1) = 0.304
F-Test, H0: r0 = 0 ; H1: r0 > 0
F(11,29.2) = 3.32 , p = 0.00462
95%-Confidence Interval for ICC Population Values:
0.061 < ICC < 0.638Wir sehen, dass wir eine relativ schlechte Übereinstimmung haben. Der ICC-Wert ist mit 0.304 sehr nahe an der Null. Auch wenn der Test sagt, dasss wir einen signifkanten Unterschied von der Null haben, geht mir ein ICC-Wert von unter 0.8 nicht als Gleich durch. Das deckt sich auch mit unserer obigen Abbildung.
duck_tbl |>
filter(session == 2) |>
select(matches("rater")) |>
icc(model = "twoway", type = "agreement", unit = "single") Single Score Intraclass Correlation
Model: twoway
Type : agreement
Subjects = 12
Raters = 4
ICC(A,1) = 0.806
F-Test, H0: r0 = 0 ; H1: r0 > 0
F(11,33.4) = 16.3 , p = 2.2e-10
95%-Confidence Interval for ICC Population Values:
0.61 < ICC < 0.931Wir sehen, dass wir eine relativ gute Übereinstimmung haben! Der ICC-Wert ist mit 0.806 nahe an der Eins. Das deckt sich auch mit unserer obigen Abbildung, wo wir sehen, dass die Bewerter in der zweiten Session viel mehr auf einer Linie liegen. Zwar ist 0.8 noch nicht perfekt, aber schonmal eins sehr viel besserer Wert.
Jetzt möchte ich mir nochmal die Bewerter einzeln für die jeweiligen Sessions anschauen. Wie unterscheiden sich den die Bewerter, wenn sie ein Bild erneut sehen? Auch hier nochmal, wir haben keinen Goldstandard, wir schauen nur, ob die Bewerter in der zweiten Session genauso zählen wie in der ersten Session. Wir machen das jetzt im Folgenden auf zwei Arten. Einmal kannst du das händsich über select() machen. Du wählst einfach immer den Bewerter aus, den du möchtest und führst den Code aus. Du ersetzt also rater_1 dann durch rater_2 und dann so weiter. Die zweite Variante ist alles in einem Rutsch mit der Funktion map().
duck_tbl |>
select(id, session, rater_1) |>
pivot_wider(names_from = session, values_from = rater_1, names_prefix = "session_") |>
select(-id) |>
icc(model = "twoway", type = "agreement", unit = "single") Single Score Intraclass Correlation
Model: twoway
Type : agreement
Subjects = 12
Raters = 2
ICC(A,1) = 0.985
F-Test, H0: r0 = 0 ; H1: r0 > 0
F(11,11.3) = 124 , p = 4.35e-10
95%-Confidence Interval for ICC Population Values:
0.95 < ICC < 0.996Wir sehen, dass der erste Studierende extrem konsistent die zweite Session im Vergleich zu der ersten bewertet hat. Der ICC-Wert ist fast bei Eins und somit fast ein perfektes Ergebnis. Auf einer numerischen Skala ist auch kaum noch mehr Spielraum nach oben.
Jetzt spielen wir ein wenig. Zuerst bauen wir uns dann für jeden Bewerter einen Datensatz der nur aus den beiden Sessions besteht. Dafür nutzen wir die Funktion pivot_wider(). Dann entfernen wir noch die ID, da die Funktion icc() gleich die ID nicht mag. Wir nutzen die Funktion map() um für jeden Bewerter den Datensatz zu bauen und am Ende in einer Liste zu speichern.
rater_lst <- map(c("rater_1", "rater_2", "rater_3", "rater_4"), \(x) {
duck_tbl |>
select(id, session, all_of(x)) |>
pivot_wider(names_from = session,
values_from = x,
names_prefix = "session_") |>
select(-id)
})Da wir alles einer Liste gespeichert haben, können wir jetzt die Liste mit der Funktion map() iterativ bearbeiten. Wir rufen dann für jeden der Listeneinträge dann einmal die Funktion icc() auf und extrahieren uns durch die Funktion pluck() den berechneten ICC Wert. Wenn du die letzte Zeile weglässt, dann kriegst du eben vier mal die Ausgabe der Funktion icc(), das war mir dann hier zu viel Platz.
rater_lst |>
map(~icc(ratings = .x, model = "twoway", type = "agreement", unit = "single")) |>
map_dbl(pluck("value"))[1] 0.98511710 0.26459153 0.26335874 0.06509083Wir sehen hier einmal als Werte, was wir auch schon in der Abbildung 24.7 beobachten konnten. Je höher die Zahl, desto besser die Übereinstimmung zwischen der ersten und der zweiten Session. Die Reihenfolge ist die Reihenfolge der Bewerter.
Der erste Studierende ist der konsitenteste Bewerter und der vierte Studierende hat die geringste Übereinstimmung. Hier muss man aber vorsichtig sein, da wir ja sehen, dass die erste Session teilweise sehr mies war. Dann kann auch die Übereinstimmung zwischen der ersten und zweiten Session nur schelcht sein, wenn sich der Studierende sehr verbessert hat. Denn eins musst du immer wissen, die Lernleistung oder Verbesserung kannst du hier nicht abbilden. Ein sehr schelchter Bewerter, der aber zügig lernt, wird hier immer mit einer sehr schelchten Übereinstimmung rauskommen. Dagegen müsstest du dann sehr viele Sessions laufen lassen, denn je mehr Sessions er macht, desto weniger unterscheiden sich diese.