R Code [zeigen / verbergen]
pacman::p_load(tidyverse, tidymodels, magrittr,
janitor, vip, rpart.plot, see,
xgboost, Ckmeans.1d.dp, conflicted)
##
set.seed(2025429)Letzte Änderung am 20. May 2024 um 07:24:10
In diesem Kapitel wollen wir uns mit Entscheidungsbäumen (eng. decision trees) beschäftigen. Wie oft gibt es auch bei der Anwendung von Entscheidungsbäumen eine Menge Varianten. Wir wollen uns in diesem Kapitel eine erste Übersicht geben und du kannst dann ja schauen, welche Varianten es noch von den Entscheidungsbäumen gibt. Wichtig ist zu wissen, unsere Bäume spalten sich immer nur in zwei Äste auf.

Wir werden uns hier mit der Anwendung beschäftigen. Wie immer lassen wir daher tiefere mathematische Überlegungen weg.
Alle drei Algorithmen gehen wir jetzt einmal durch. Dabei können wir bei einem Entscheidunsgbaum noch recht gut nachvollziehen, was dort eigentlich passiert. Bei mehreren Bäumen zusammen, können wir nur noch schematisch nachvollziehen was die einzelnen Schritte in der Modellbildung sind.
Wir wollen folgende R Pakete in diesem Kapitel nutzen.
pacman::p_load(tidyverse, tidymodels, magrittr,
janitor, vip, rpart.plot, see,
xgboost, Ckmeans.1d.dp, conflicted)
##
set.seed(2025429)An der Seite des Kapitels findest du den Link Quellcode anzeigen, über den du Zugang zum gesamten R-Code dieses Kapitels erhältst.
Bei dem vorherigen Beispielen haben wir immer unseren Datensatz zu den infizierten Ferkeln genutzt. In diesem Kapitel wolle wir uns aber mal auf einen echten Datensatz anschauen. Wir nutzen daher einmal den Gummibärchendatensatz. Als unser Label und daher als unser Outcome nehmen wir das Geschlecht gender. Dabei wollen wir dann die weiblichen Studierenden vorhersagen. Im Weiteren nehmen wir nur die Spalte Geschlecht sowie als Prädiktoren die Spalten most_liked, age, semester, und height.
gummi_tbl <- read_excel("data/gummibears.xlsx") |>
mutate(gender = as_factor(gender),
most_liked = as_factor(most_liked)) |>
select(gender, most_liked, age, semester, height) |>
drop_na(gender)Wir dürfen keine fehlenden Werte in den Daten haben. Wir können für die Prädiktoren später die fehlenden Werte imputieren. Aber wir können keine Labels imputieren. Daher entfernen wir alle Beobachtungen, die ein NA in der Variable gender haben. Wir haben dann insgesamt \(n = 878\) Beobachtungen vorliegen. In Tabelle 79.1 sehen wir nochmal die Auswahl des Datensatzes in gekürzter Form.
| gender | most_liked | age | semester | height |
|---|---|---|---|---|
| m | lightred | 35 | 10 | 193 |
| w | yellow | 21 | 6 | 159 |
| w | white | 21 | 6 | 159 |
| w | white | 36 | 10 | 180 |
| m | white | 22 | 3 | 180 |
| m | green | 22 | 3 | 180 |
| … | … | … | … | … |
| w | green | 27 | 17 | 163 |
| m | none | 27 | 2 | 178 |
| m | none | 28 | 5 | 177 |
| w | green | 26 | 2 | 177 |
| w | darkred | 28 | 6 | 174 |
| m | yellow | 36 | NA | 165 |
Unsere Fragestellung ist damit, können wir anhand unserer Prädiktoren männliche von weiblichen Studierenden unterscheiden und damit auch klassifizieren? Um die Klassifikation mit Entscheidungsbäumen rechnen zu können brauchen wir wie bei allen anderen Algorithmen auch einen Trainings- und Testdatensatz. Wir splitten dafür unsere Daten in einer 3 zu 4 Verhältnis in einen Traingsdatensatz sowie einen Testdatensatz auf. Der Traingsdatensatz ist dabei immer der größere Datensatz. Da wir aktuell nicht so viele Beobachtungen in dem Gummibärchendatensatz haben, möchte ich mindestens 100 Beobachtungen in den Testdaten. Deshalb kommt mir der 3:4 Split sehr entgegen.
gummi_data_split <- initial_split(gummi_tbl, prop = 3/4)Wir speichern uns jetzt den Trainings- und Testdatensatz jeweils separat ab. Die weiteren Modellschritte laufen alle auf dem Traingsdatensatz, wie nutzen dann erst ganz zum Schluss einmal den Testdatensatz um zu schauen, wie gut unsere trainiertes Modell auf den neuen Testdaten funktioniert.
gummi_train_data <- training(gummi_data_split)
gummi_test_data <- testing(gummi_data_split)Nachdem wir die Daten vorbereitet haben, müssen wir noch das Rezept mit den Vorverabreitungsschritten definieren. Wir schreiben, dass wir das Geschlecht gender als unser Label haben wollen. Daneben nehmen wir alle anderen Spalten als Prädiktoren mit in unser Modell, das machen wir dann mit dem . Symbol. Da wir noch fehlende Werte in unseren Prädiktoren haben, imputieren wir noch die numerischen Variablen mit der Mittelwertsimputation und die nominalen fehlenden Werte mit Entscheidungsbäumen. Es gibt wie immer noch andere Imputationsmöglichkeiten, ich habe mich jetzt aus praktischen Gründen für dies beiden Verfahren entschieden. Ich überspringe hier auch die Diagnose der Imputation, also ob das jetzt eine gute und sinnvolle Imputation der fehlenden Werte war oder nicht. Die Diagnoseschritte müsstest du im Anwendungsfall nochmal im Kapitel zur Imputation nachlesen und anwenden. Dann müssen wir noch alle numerischen Variablen normalisieren und alle nominalen Variablen dummykodieren. Am Ende werde ich nochmal alle Variablen entfernen, sollte die Varianz in einer Variable nahe der Null sein.
gummi_rec <- recipe(gender ~ ., data = gummi_train_data) |>
step_impute_mean(all_numeric_predictors()) |>
step_impute_bag(all_nominal_predictors()) |>
step_range(all_numeric_predictors(), min = 0, max = 1) |>
step_dummy(all_nominal_predictors()) |>
step_nzv(all_predictors())
gummi_rec── Recipe ──────────────────────────────────────────────────────────────────────── Inputs Number of variables by roleoutcome: 1
predictor: 4── Operations • Mean imputation for: all_numeric_predictors()• Bagged tree imputation for: all_nominal_predictors()• Range scaling to [0,1] for: all_numeric_predictors()• Dummy variables from: all_nominal_predictors()• Sparse, unbalanced variable filter on: all_predictors()Alles in allem haben wir ein sehr kleines Modell. Wir haben ja nur ein Outcome und vier Prädiktoren. Trotzdem sollte dieser Datensatz reichen um zu erklären wie Entscheidungsbäume funktionieren.
Wie funktioniert nun ein Entscheidungsbaum? Ein Entscheidungsbaum besteht aus Knoten (eng. nodes) und Ästen (eng. edge). Dabei hat immer ein Knoten zwei Äste. Die Beobachtungen in einem Knoten fallen nach einer Entscheidungsregel anhand eines Prädiktors in entlang zweier Äste in zwei separate Knoten. So können wir unsere \(n = 878\) zum Beispiel anhand des Alters in zwei Gruppen aufteilen. Wir legen willkürlich die Altersgrenze bei 22 fest.
gummi_tbl |>
mutate(grp = if_else(age >= 22, 1, 0)) |>
pull(grp) |>
tabyl() pull(mutate(gummi_tbl, grp = if_else(age >= 22, 1, 0)), grp) n percent
0 370 0.421412301
1 504 0.574031891
NA 4 0.004555809
valid_percent
0.423341
0.576659
NAWir erhalten mit diesem Split zwei Gruppen mit je \(n_0 = 207\) und \(n_1 = 259\) Beobachtungen. Wir haben jetzt diesen Split willkürlich gewählt. In dem Algorithmus für die Entscheidungsbäume wird dieser Schritt intern optimiert, so dass wir den besten Wert für den Alterssplit finden, der uns möglichst reine Knoten im Bezug auf das Label liefert. Wir wollen ja am Ende einen Algorithmus trainieren, der uns die Geschlechter bestmöglich auftrennt, so dass wir eine neue Beobachtung bestmöglich vorhersagen können. Wenn keine Aufteilungen in einem Knoten mehr möglich sind, dann nennen wir diesen Knoten einen Terminalknoten.
In Abbildung 79.5 sehen wir ein Beispiel für zwei numerische Prädiktoren \(X_1\) und \(X_2\). Auf der linken Seite ist das Koordinatensystem mit dreizehn Beobachtungen dargestellt. Von den dreizehn Beobachtungen sind zehn Fälle (eng. cases) und drei Kontrollen (eng. control). Wir wollen uns jetzt an dem Koordinatensystem die Idee der Splits für ein Baumwachstum veranschaulichen. Auf der rechten Seite sehen wir nämlich den ersten Knoten des Entscheidungsbaums (eng. root node) in dem sich alle Beobachtungen befinden. Wir wollen jetzt die Beobachtungen anhand der Prädiktoren \(X_1\) und \(X_2\) so aufspalten, dass für möglichst reine Knoten erhalten. Wir stoppen auch im Splitting wenn wir weniger oder gleich vier Beobachtungen nach einem Split in einem Knoten erhalten.
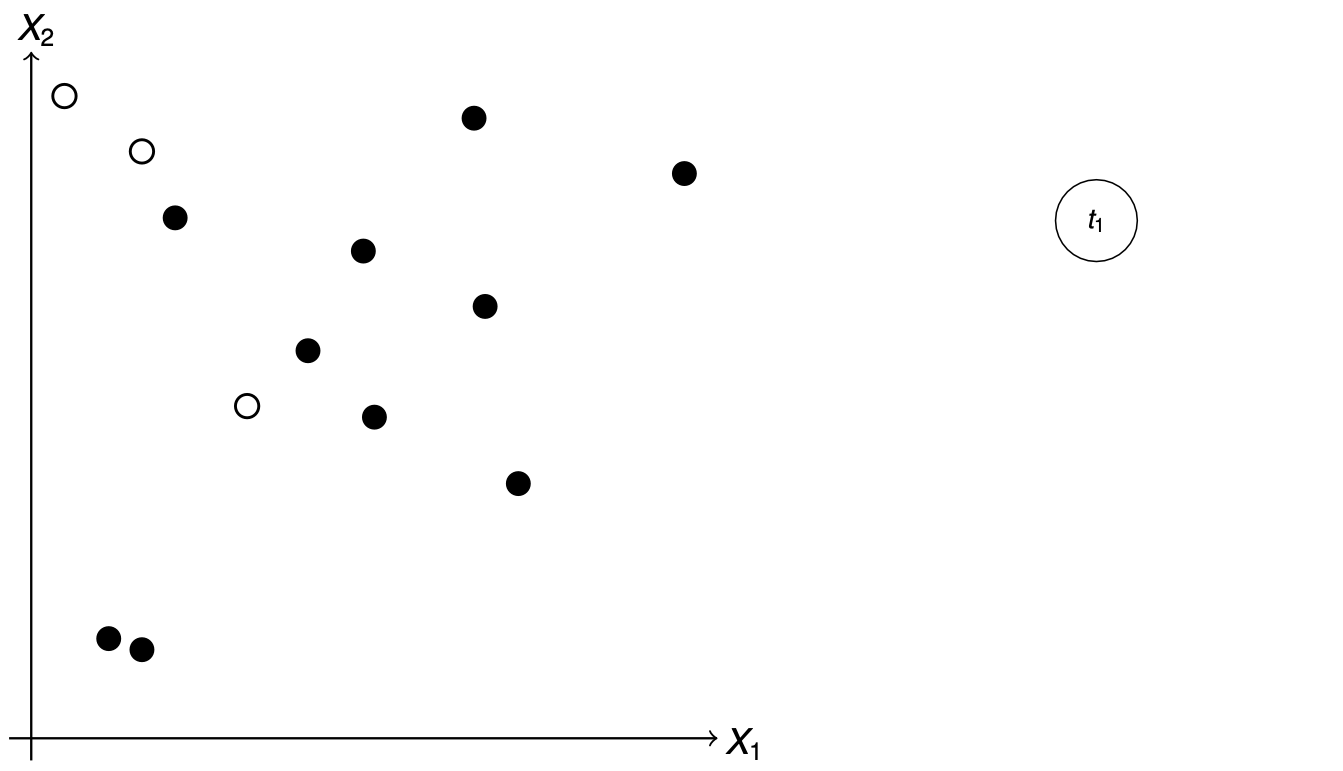
In Abbildung 79.6 sehen wir den ersten Split des Prädiktors \(X_1\) anhand des Wertes \(c_1\). Wir erhalten nach dem Split die zwei neuen Knoten \(t_2\) und \(t_3\). Wir haben den Split so gewählt, dass wir einen reinen Knoten \(t_3\) erhalten. Da der Knoten \(t_3\) jetzt nur noch Fälle enthaält, wird dieser Knoten zu einem Terminalknoten und es finden keine weiteren Aufspaltungen mehr statt. Wir machen jetzt also mit dem Knoten \(t_2\) weiter.
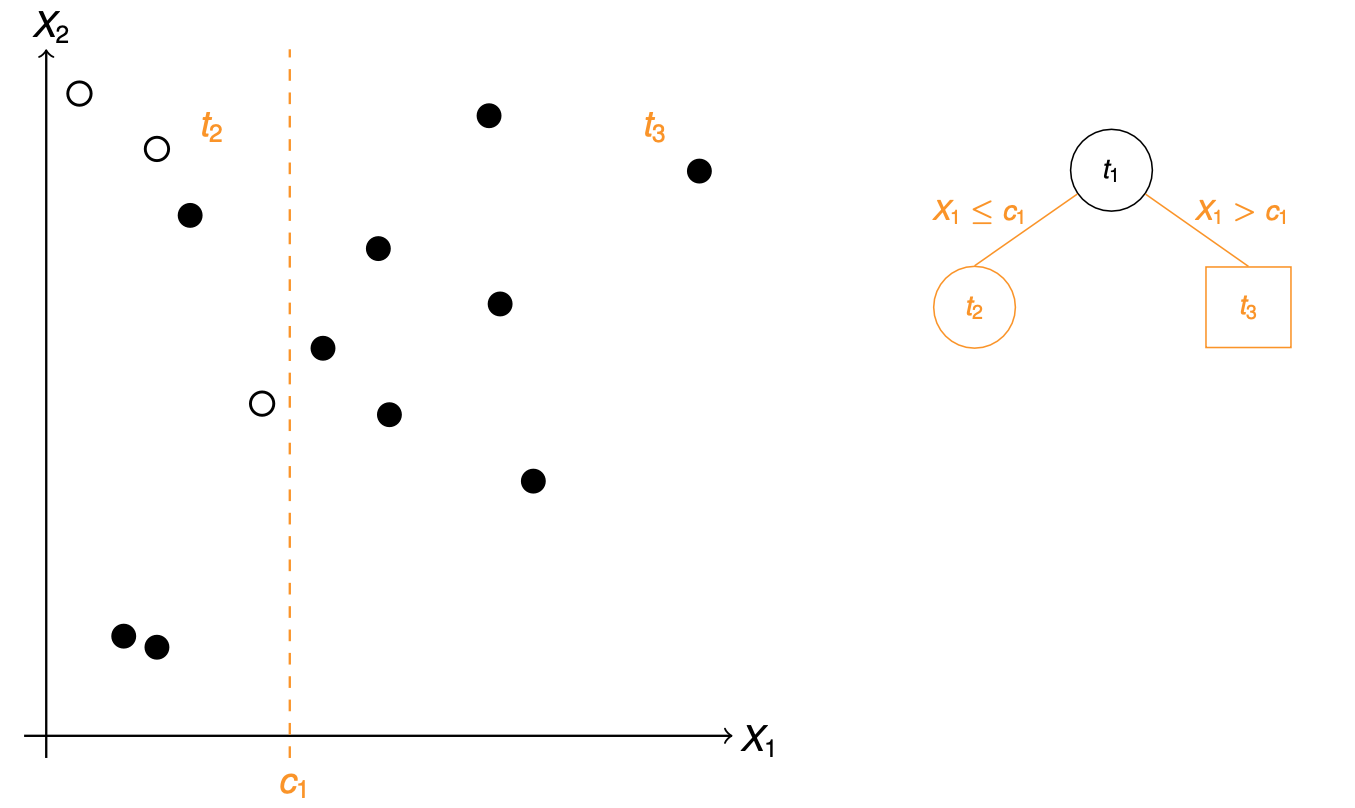
In Abbildung 79.8 sehen wir den Split durch den Prädiktor \(X_2\) nach dem Wert \(c_2\). Wir erhalten wieder zwei neue Knotenn \(t_4\) und \(t_5\). Der Knoten \(t_4\) wird nach unseren Regeln wieder zu einem Terminalknoten. Wir haben nur Fälle in dem Knoten \(t_4\) vorliegen. Wir stoppen auch bei dem Knoten \(t_5\) unsere weitere Aufteilung, da wir hier vier oder weniger Beobachtungen vorliegen haben. Damit sind wir mit dem Split zu einem Ende gekommen.
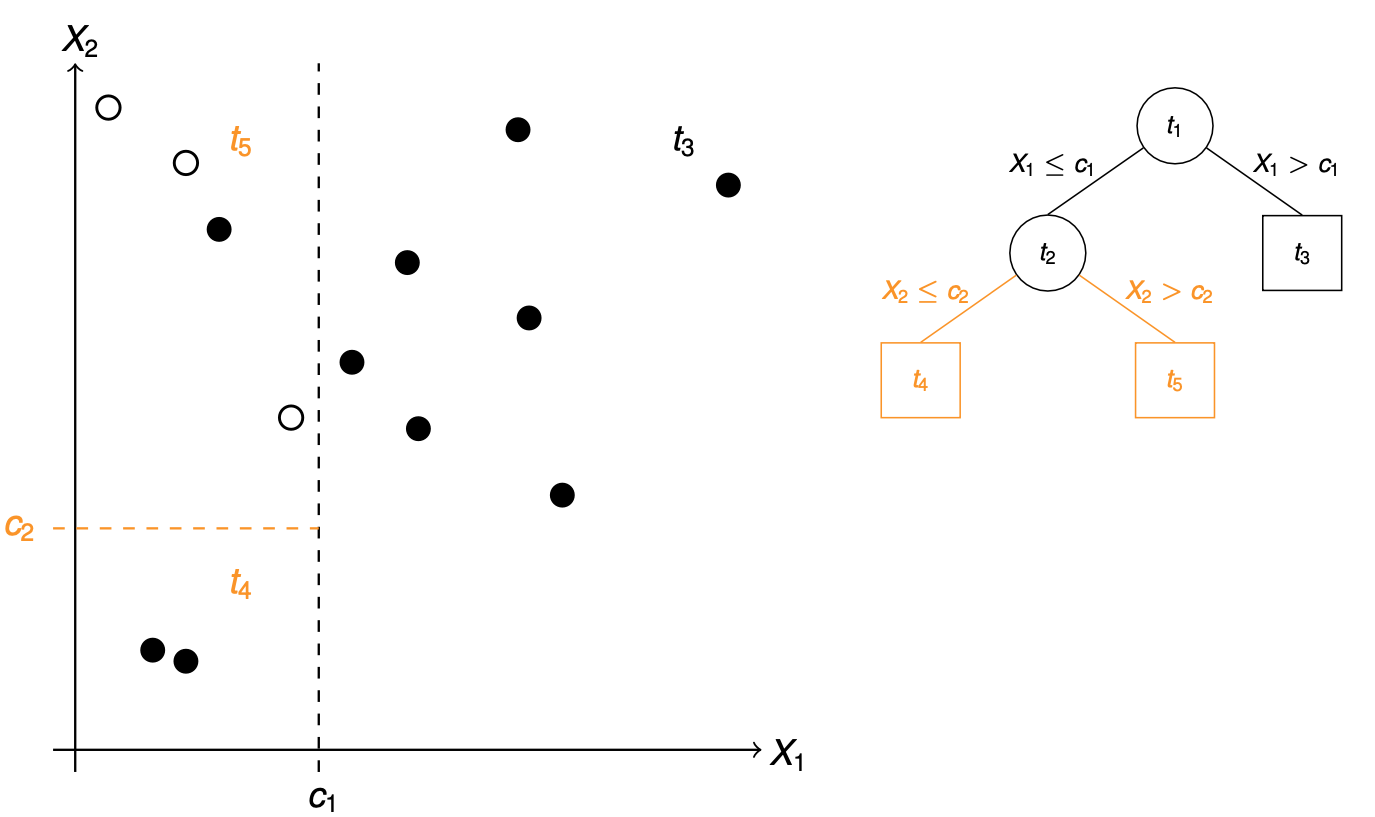
In Abbildung 79.12 sehen wir jetzt eine neue Beobachtung ? die mit gegebenen Werten für \(X_1\) und \(X_2\) in den terminalen Knoten \(t_5\) fällt. Wir zählen dort die Fälle und erhalten eine Klassenzugehörigkeitswahrscheinlichkeit von 25%. Daher würden wir sagen, dass die neue Beobchtung eine Kontrolle ist. Es handelt sich damit um eine weiße Beoabchtung.
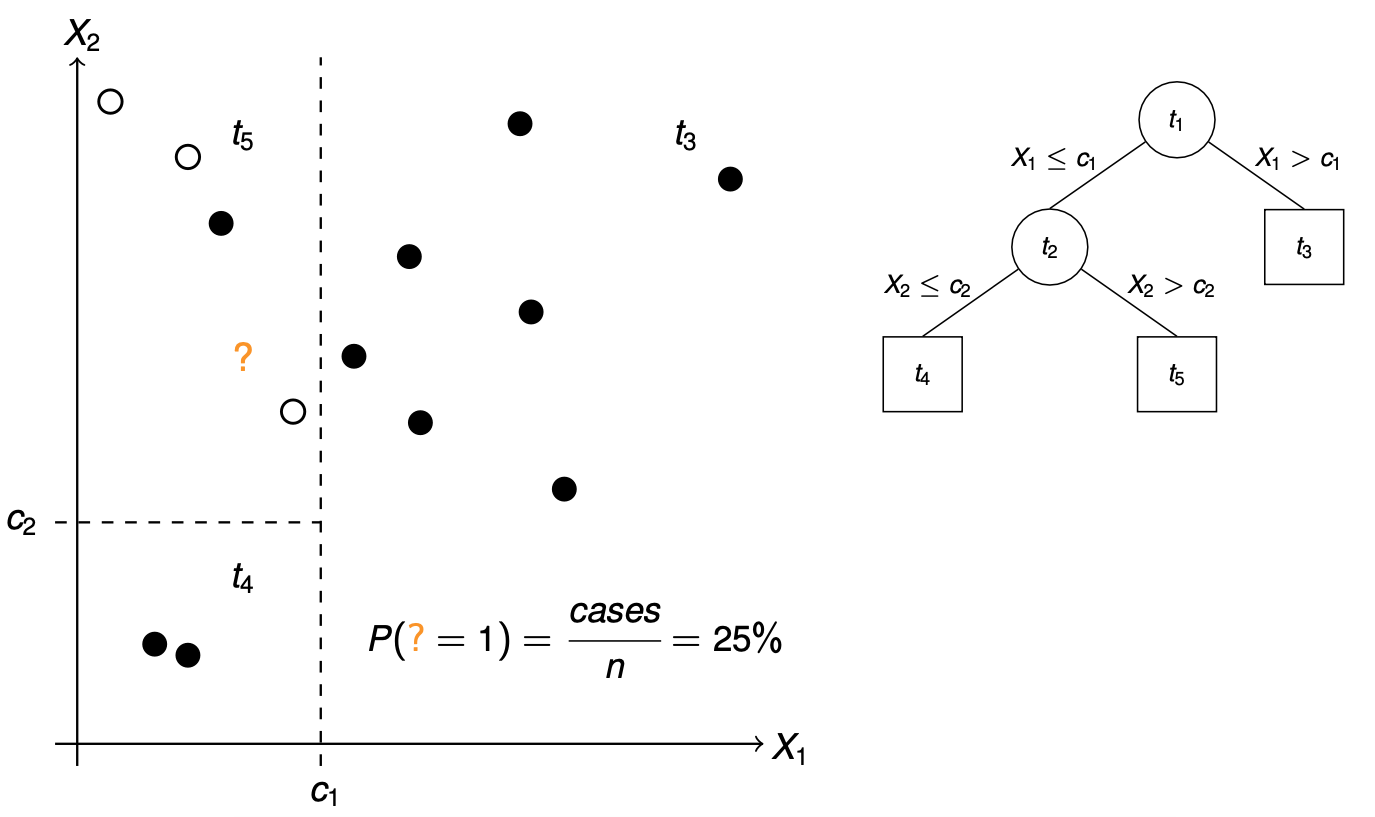
? fällt in den Terminalknoten \(t_5\). Dort zählen wir die schwarzen Kreise. Wir stellen fest, dass die neue Beobachtung mit 25% Wahrscheinlichkeit ein Fall und damit schwarz ist. Daher ist die neue Beobachtung weiß.
Damit haben wir einmal den simplen Fall mit zwei numerischen Prädiktoren durchgespielt. Auch haben wir wenige Beobachtungen und sind schnell zu reinen Knoten gekommen. Wenn wir jetzt natürlich sehr viel mehr Beobachtungen haben oder sehr viele Prädiktoren dann wird die Sache sehr schnell sehr rechenintensiv. Dafür haben wir dann eben R.
Wenn wir in R einen Entscheidungsbaum rechnen wollen, dann nutzen wir die Funktion decision_tree() wir wollen nur eine maximale Tiefe von 5 Knoten haben und/oder mindestens 10 Beobachtungen in einem Knoten. Je nachdem welche Bedingung wir eher erreichen. Ebenfalls können wir das Wachstum mit dem Parameter cost_complexity kontrollieren. Sollte sich das Modell nicht um mindestens 0.001 verbessern, dann werden wir den nächsten Knoten nicht anlegen. Wir wählen als Engine den Algorithmus rpart, da wir uns diese Art von Algorithmus gut mit dem R Paket {rpart.plot} visualisieren können.
rpart_mod <- decision_tree(tree_depth = 5, min_n = 10, cost_complexity = 0.001) |>
set_engine("rpart") |>
set_mode("classification")Jetzt kommt wieder das Modell zusammen mit dem Rezept. Wir speichern wieder beides in einen Workflow.
rpart_wflow <- workflow() |>
add_model(rpart_mod) |>
add_recipe(gummi_rec)Den Workflow können wir dann mit dem Traingsdatensatz einmal durchlaufen lassen und uns das gefittete Modell wiedergeben lassen.
rpart_fit <- rpart_wflow |>
parsnip::fit(gummi_train_data)Nachdem wir das trainierte Modell vorliegen haben, nutzen wir die Funktion augment() um das Modell auf die Testdaten anzuwenden.
rpart_aug <- augment(rpart_fit, gummi_test_data ) Jetzt geht es los und wir schauen uns einmal an, wie gut die Klassifizierung mit dem Modell funktioniert hat. Als erstes bauen wir uns einmal die Konfusionsmatrix um zu sehen wie gut die beiden Geschlechter in dem Testdatensatz vorhergesagt wurden.
rpart_cm <- rpart_aug |>
conf_mat(gender, .pred_class)
rpart_cm Truth
Prediction m w
m 92 24
w 12 92Das freut einen doch. Das sieht ziemlich gut aus. Wir haben auf der Diagonalen fast alle Beoabchtungen und nur sehr wenige falsche Vorhersagen auf der Nichtdiagonalen. Jetzt können wir uns noch eine ganze Reihe an anderen Gütekriterien für den Vergleich von Modellen ausgeben lassen.
rpart_cm |> summary()# A tibble: 13 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 accuracy binary 0.836
2 kap binary 0.674
3 sens binary 0.885
4 spec binary 0.793
5 ppv binary 0.793
6 npv binary 0.885
7 mcc binary 0.678
8 j_index binary 0.678
9 bal_accuracy binary 0.839
10 detection_prevalence binary 0.527
11 precision binary 0.793
12 recall binary 0.885
13 f_meas binary 0.836Wir besprechen hier nicht alle, du kannst dann gerne nochmal in dem Kapitel über die Modellvergleiche nachlesen, was die ganze Gütekriterien alles bedeuten. Wenn wir uns auf die Accuarcy konzentrieren, erhalten wir einen guten Wert von 83% richtig klassifizierter Geschlechter. Das ist für echte Daten ohne Tuning und Kreuzvaldierung schon ein echt guter Wert.
Nun schauen wir uns noch schnell die ROC Kurve an und sehen, dass die Kurve schon weit von der Diagonalen entfernt ist. Wir sehen eine gute ROC Kurve. Die AUC sollte auch recht groß sein.
rpart_aug |>
roc_curve(gender, .pred_w, event_level = "second") |>
autoplot()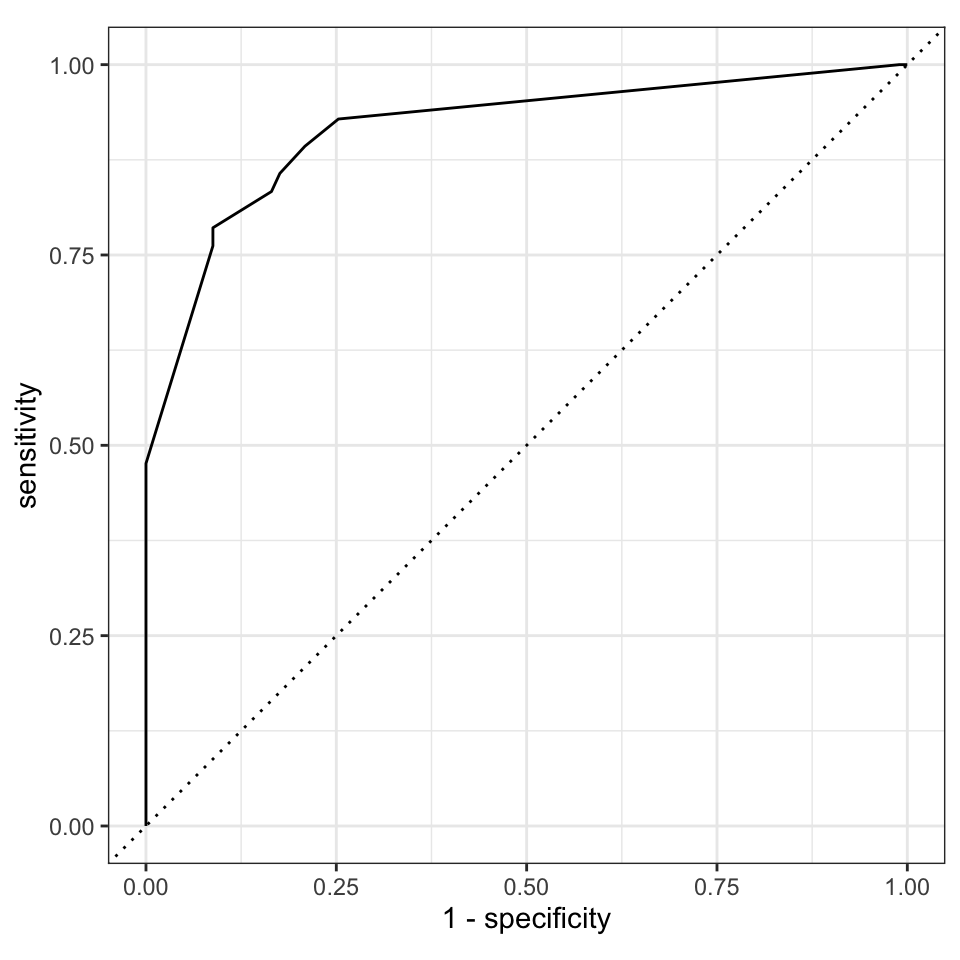
rpart Algorithmus.
Es gibt viele Möglichkeiten sich einen Entscheidungsbaum anzuschauen. Wir nutzen hier das R Paket {rpart.plot} und die gleichnamige Funktion rpart.plot(). Die vielen Möglichkeiten der Darstellung und der Optionen findest in der Vignette Plotting rpart trees with the rpart.plot package.. Wir gehen hier einmal auf die Variante extra = 101 ein. Es gibt insgesamt elf verschiedene Arten plus eben noch die Möglichkeit 100 zu einer der elf genannten Varianten hinzufügen, um auch den Prozentsatz der Beobachtungen im Knoten anzuzeigen. Zum Beispiel zeigt extra = 101 die Anzahl und den Prozentsatz der Beobachtungen in dem Knoten an.
rpart_fit |>
extract_fit_engine() |>
rpart.plot(roundint = FALSE, extra = 101)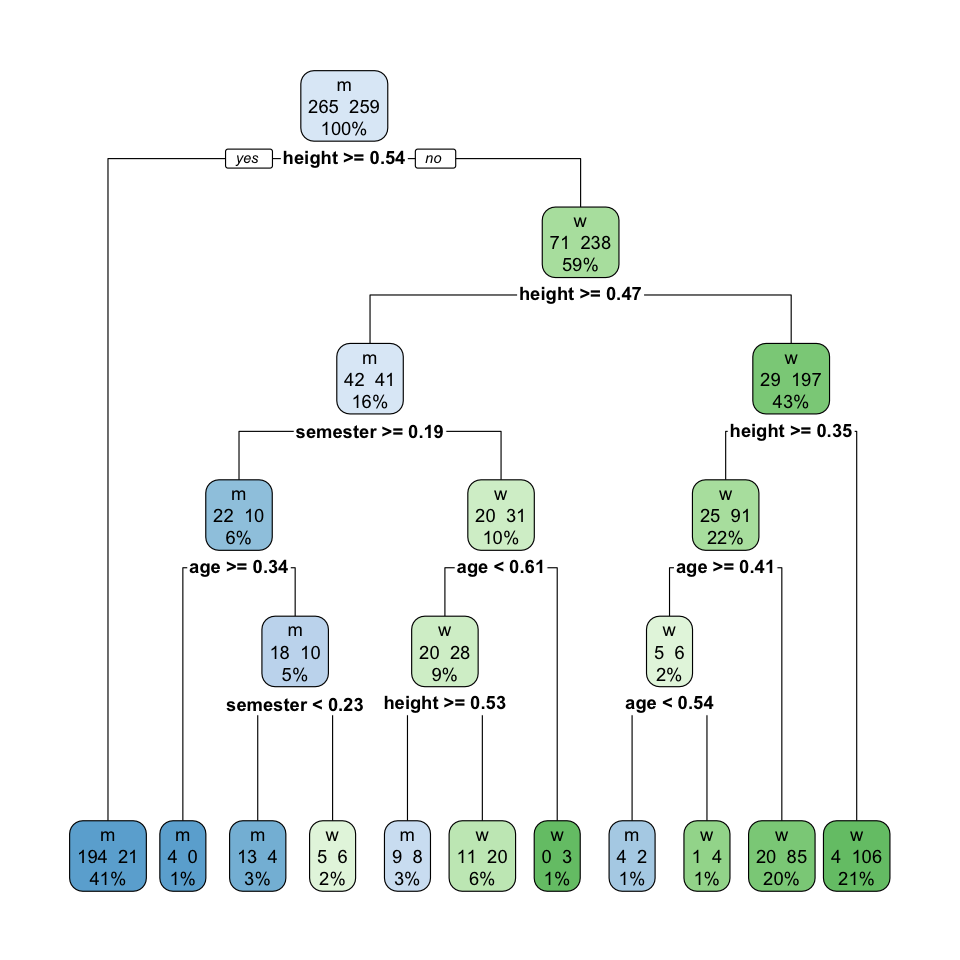
rpart Entscheidungsbaums.
In Abbildung 79.6 sehen wir den finalen Entscheidungsbaum. Wir sehen, dass wir nicht weiter als fünf Splits nach unten gewandert sind. Das hatten wir ja auch mit dem Parameter tree_depth so eingestellt. Jetzt sehen wir aber auch, dass wir mit dem Preprocessing auch eine Grube graben können. Wir haben in unserem ersten Knoten 189 Männer und 165 Frauen. Daher hat der Knoten nach Mehrheitsentscheidung den Status m. Jetzt spalten wir den Knoten nach der Körpergröße von \(0.48\) in zwei Gruppen. Was soll jetzt \(0.48\) heißen? Keine Ahnung. Wir haben die Daten normalisiert. Wenn du hier die Werte für die Splits interpretieren willst, dann musst du auf den Orginaldaten rechnen. Nach dem Split sehen wir zwei Knoten, in denen zum einen die Männer domiern und zum anderen die Frauen. Wir splitten wieder nach der Körpergröße und erhalten immer reinere Knoten in den fast nur noch Männer oder Frauen sind.
Schaue dir auch die anderen Arten der Visualisierung in rpart.plot an und entscheide, ob dir die anderen Varianten bessere Informationen liefern, die zu deiner wissenschaftlichen Fragestellung passen.
An der Stelle trifft dann immer die Klassifikation auf die Interpretation. Du kannst nicht das Modell im Nachgang wieder entnormalisieren. Das geht nicht. Wenn du auf den Orginaldaten rechnest, dann wirst du ein anderes Modell erhalten. Das Modell mag besser oder schlechter sein, auf jeden Fall anders. Wie so oft hängt es von der wissenschaftlichen Fragestellung ab.
Bis jetzt haben wir einen Entscheidungsbaum wachsen lassen. Was wäre, wenn wir statt einen Baum mehrere Bäume wachsen lassen. Wir lassen einen ganzen Wald (eng. forest) entstehen. Nun macht es wenig Sinn, immer den gleichen Baum auf immer den selben Daten wachsen zu lassen. Daher wählen wir zufällig eine Anzahl an Zeilen und Spalten aus bevor wir einen Baum in unserem Wald wachsen lassen. Dabei bringen wir zwei den Zufall in die Generierung eines Baums mit ein.
Im maschinellen Lernen nennen wir diese Methode Bagging. Das Wort Bagging steht für bootstrap aggregating und ist eine Methode, um Vorhersagen aus verschiedenen Modellen zu kombinieren. In unserem Fall sind es die verschiedenen Entscheidungsböume. Dabei müssen alle Modelle mit dem gleichen Algorithmus laufen, können aber auf verschiedenen Datensätzen oder aber Variablensätzen zugreifen. Häufig haben die Modelle eine hohe Varianz in der Vorhersage und wir nutzen dann Bagging um die Modelle miteinander zu kombinieren und dadurch die Varianz zu verringern. Die Ergebnisse der Modelle werden dann im einfachsten Fall gemittelt. Das Ergebnis jeder Modellvorhersage geht mit gleichem Gewicht in die Vorhersage ein. Wir haben auch noch andere Möglichkeiten, aber du kannst dir Vorstellen wir rechnen verschiedene Modelle \(j\)-mal und bilden dann ein finales Modell in dem wir alle \(j\)-Modelle zusammenfassen. Wie wir die Zusammenfassung rechnen, ist dann immer wieder von Fall zu Fall unterschiedlich. Wir erhalten am Ende einen Ensemble Klassifizierer, da ja ein Ensemble von Modellen zusammengefasst wird. In dem Fall von den Entscheidungsbäumen ist das Ensemble ein Wald an Bäumen.
Wenn wir wirklich viele Bäume wachsen lassen wollen, dann bietet sich die parallele Berechnung an. Das können wir über das R Paket {parallel} realisieren. Wir detektieren erstmal wie viele Kerne wir auf dem Rechner zu Verfügung haben.
cores <- parallel::detectCores()
cores[1] 8Wenn wir das gemacht haben, dann können wir in set_engine("ranger", num.threads = cores) auswählen, dass die Berechnung parallel verlaufen soll. Besonders auf Großrechnern macht die parallele Berechnung am meisten Sinn.
Auch hier ist es so, dass es verschiedene Algorithmen für den Random Forest gibt. Wir nehmen hier dann den ranger Algorithmus. Du kannst wie immer schauen, welche Algorithmen es noch gibt und auch wiederum verschiedene Algorithmen ausprobieren. In jedem Baum sollen drei Prädiktoren (mtry = 3) und einer Anzahl von mindestens zehn Beobachtungen je Knoten (min_n = 10) und wir wollen insgesamt eintausend Bäume wachsen lassen (trees = 1000). Darüber hinaus wollen wir uns auch die Variable Importance wiedergeben lassen. Die Variable Importance beschreibt, wie gut ein Prädiktor über alle Bäume des Waldes, in der Lage war Splits in möglichst reine Knoten durchzuführen. Ein Prädiktor mit einer hohen Variable Importance, ist also besonders geeignet für gute Splits mit hoher Reinheit.
ranger_mod <- rand_forest(mtry = 3, min_n = 10, trees = 1000) |>
set_engine("ranger", importance = "impurity") |>
set_mode("classification")Nun bauen wir uns wieder unseren Workflow indem wir das Modell mit dem Rezept für die Gummidatensatz verbinden. Das tolle ist jetzt, dass wir hier wieder des Rezept vom Anfang verwenden können. Wir müssen also nicht das Rezept neu definieren. Wir bauen uns also einfach nur einen neuen Workflow.
ranger_wflow <- workflow() |>
add_model(ranger_mod) |>
add_recipe(gummi_rec)Wenn wir den Workflow haben, dann können wir wieder mit der Funktion fit() unser Modell anpassen.
ranger_fit <- ranger_wflow |>
parsnip::fit(gummi_train_data)In der Abbildung 79.7 sehen wir dann die Variable Importance sortiert für alle Prädiktoren. Ganz wichtig, die Variable Importance ist nicht numerisch zu interpretieren und auch nicht über verschiedene Datensäze hinweg. Wir können nur die Variable Importance von einem Datensatz anschauen und dort sehen welche Variablen den meisten Einfluss haben. Wir sehen also, dass die Körpergröße eine sehr große Wichtigkeit hat um die Männer von den Frauen in den Gummibärchendaten zu trennen. Das macht auch Sinn. Frauen und Männer sind nun mal unterschiedlich groß. Nicht mehr so wichtig ist das Alter und das Semester. Beide Prädiktoren haben einen ehr geringeren Einfluss auf die Aufteilung der beiden Geschlechter. Der Lieblingsgeschmack tut bei der Einteilung in Männer und Frauen nichts zur Sache.
ranger_fit |>
extract_fit_parsnip() |>
vip(num_features = 20) +
theme_minimal()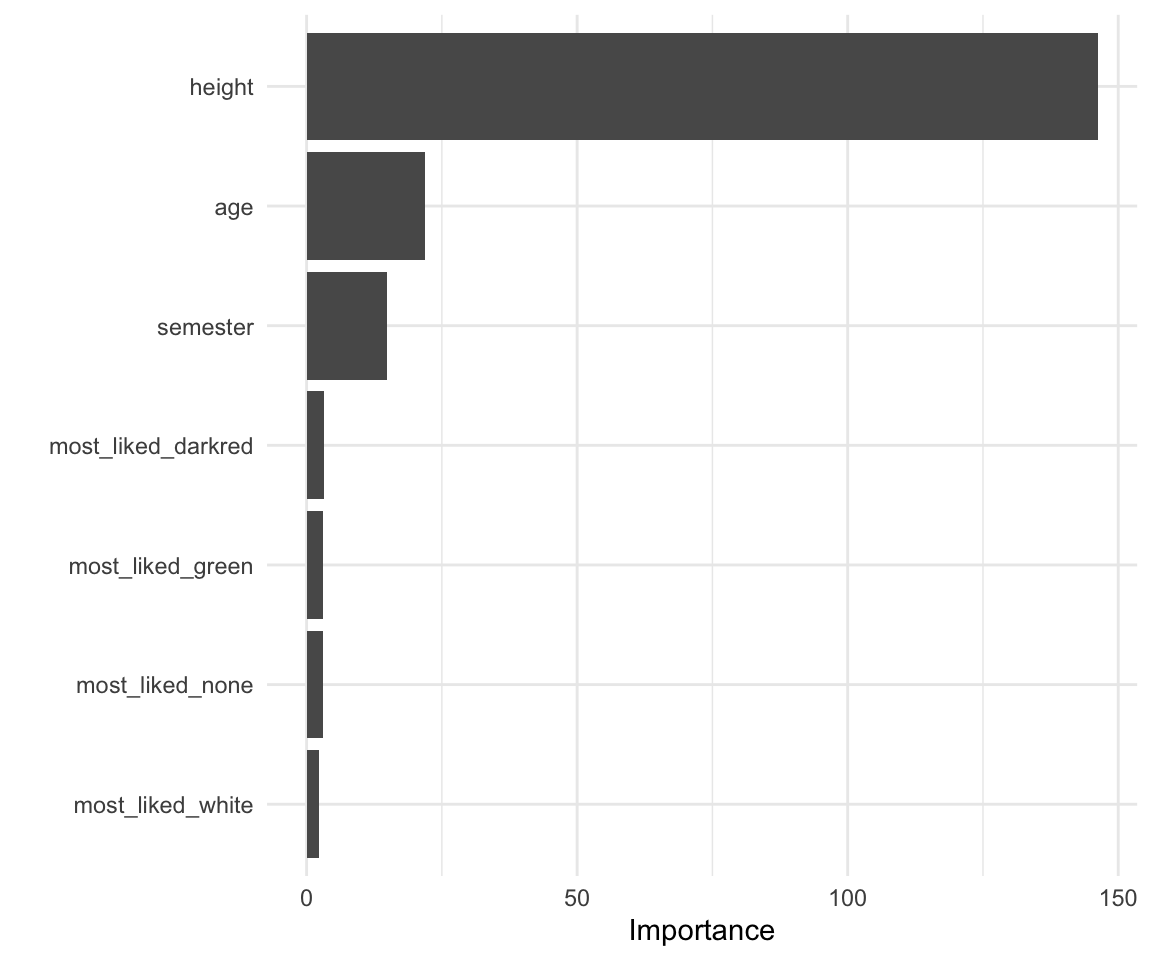
ranger Algorithmus.
Nach unserem kleinen Ausflug zu der Variable Importance können wir jetzt wieder unser Modell auf den Testdatensatz anwenden und schauen, wie gut der Random Forest unsere Geschlechter vorhersagen kann.
ranger_aug <- augment(ranger_fit, gummi_test_data ) Nun schauen wir uns an wie gut die Klassifizierung mit dem ranger Modell funktioniert hat. Als erstes bauen wir uns einmal die Konfusionsmatrix um zu sehen wie gut die beiden Geschlechter in dem Testdatensatz vorhergesagt wurden.
ranger_cm <- ranger_aug |>
conf_mat(gender, .pred_class)
ranger_cm Truth
Prediction m w
m 86 16
w 18 100Ja, das sieht ähnlich gut aus wie der rpart Algorithmus. Wir haben eine gute Aufspaltung nach dem Geschlechtern. Viele der Beobachtungen liegen auf der Diagonalen und nur wenige Beobachtungen wurden falsch klassifiziert. Jetzt können wir uns noch eine ganze Reihe an anderen Gütekriterien für den Vergleich von Modellen ausgeben lassen.
ranger_cm |> summary()# A tibble: 13 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 accuracy binary 0.845
2 kap binary 0.690
3 sens binary 0.827
4 spec binary 0.862
5 ppv binary 0.843
6 npv binary 0.847
7 mcc binary 0.690
8 j_index binary 0.689
9 bal_accuracy binary 0.844
10 detection_prevalence binary 0.464
11 precision binary 0.843
12 recall binary 0.827
13 f_meas binary 0.835Wir besprechen wie beim rpart Algorithmus nicht alle Kriterien, du kannst dann gerne nochmal in dem Kapitel über die Modellvergleiche nachlesen, was die ganze Gütekriterien alles bedeuten. Wenn wir uns auf die Accuarcy konzentrieren, erhalten wir einen guten Wert von 84% richtig klassifizierter Geschlechter. Das ist für echte Daten ohne Tuning und Kreuzvaldierung schon ein echt guter Wert.
Nun schauen wir uns noch schnell die ROC Kurve an und sehen, dass die Kurve schon weit von der Diagonalen entfernt ist. Wir sehen eine gute ROC Kurve. Die AUC sollte auch recht groß sein. Damit sind wir mit dem Random Forest Algorithmus soweit durch und wir schauen uns jetzt einen etwas komplexeren xgboost Algorithmus an.
ranger_aug |>
roc_curve(gender, .pred_w, event_level = "second") |>
autoplot()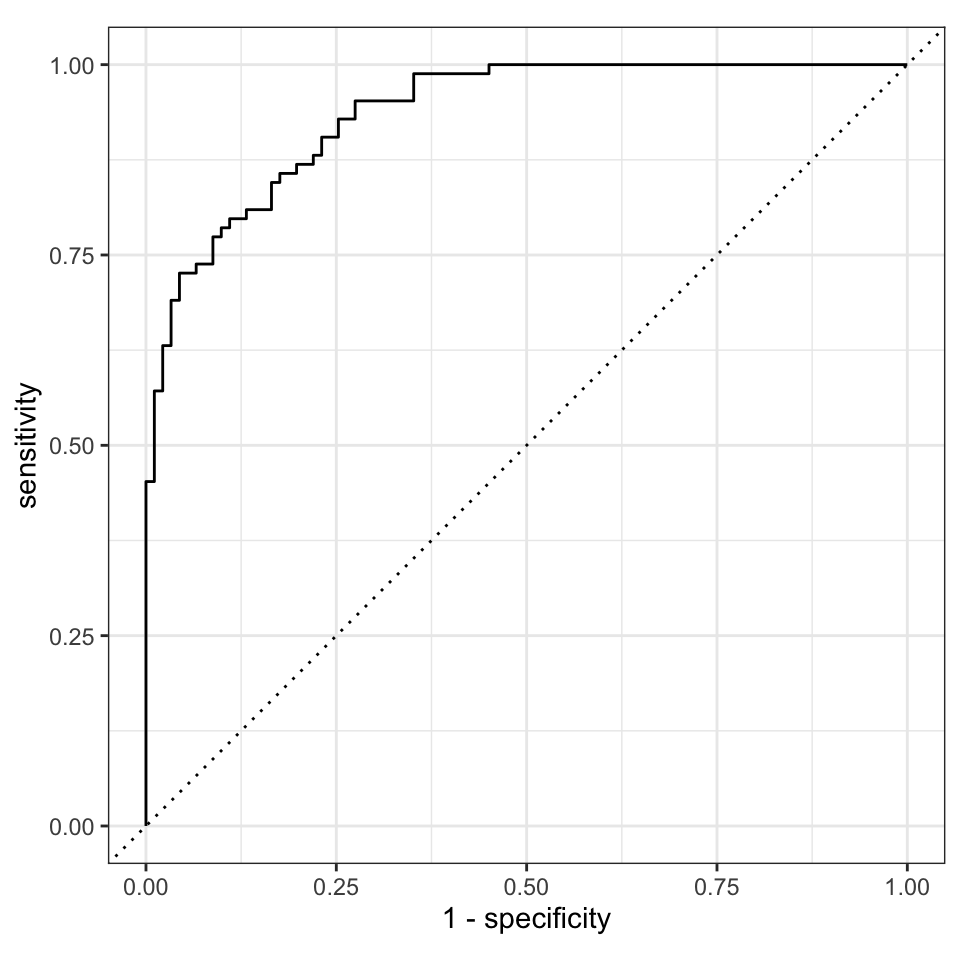
ranger Algorithmus.
Ja, kannst du. Wenn du nur eine Kreuzvalidierung durchführen willst, findest du alles im Kapitel 78 für den \(k\)-NN Algorithmus. Du musst dort nur den Workflow ändern und schon kannst du alles auch auf den Random Forest Algorithmus anwenden. Wir nutzen gleich die Kreuzvalidierung in Kombination mit dem Tuning vom xgboost Algorithmus.
Wenn du also den Random Forest Algorithmus auch tunen willst, dann schaue einfach weiter unten nochmal bei dem Tuning des xgboost Algorithmus rein. Es ändert sich kaum was für die Auwahl der Tuning Parameter vom Random Forest Algorithmus.
Als letztes Beispiel für Entscheidungsbäume schauen wir uns das Boosting an. Auch hier haben wir es wieder mit einem Wald an Entscheidungsbäumen zu tun, die wir auch wieder zusammenfassen wollen. Wir verlassen uns also nicht auf die Klassifikation von einem Baum, sondern nehmen die Informationen von vielen Bäumen zusammen. Was ist jetzt der Unterschied zu einem Random Forest? Bei einem Random Forest bauen wir uns im Prinzip hunderte einzelne Bäume und trainieren darauf den Algorithmus. Am Ende fassen wir dann alle Bäume für die Vorhersage zusammen. Beim Boosting nutzen wir die Information des ersten Baumes für das Wachstum des zweiten Baumes und so weiter. Das Boosting verkettet also die Informationen der einzelnen Bäume zu einem kontinuierlichen Lernen. Daher sind Bossting Algorithmen meist sehr gute Klassifizierer.
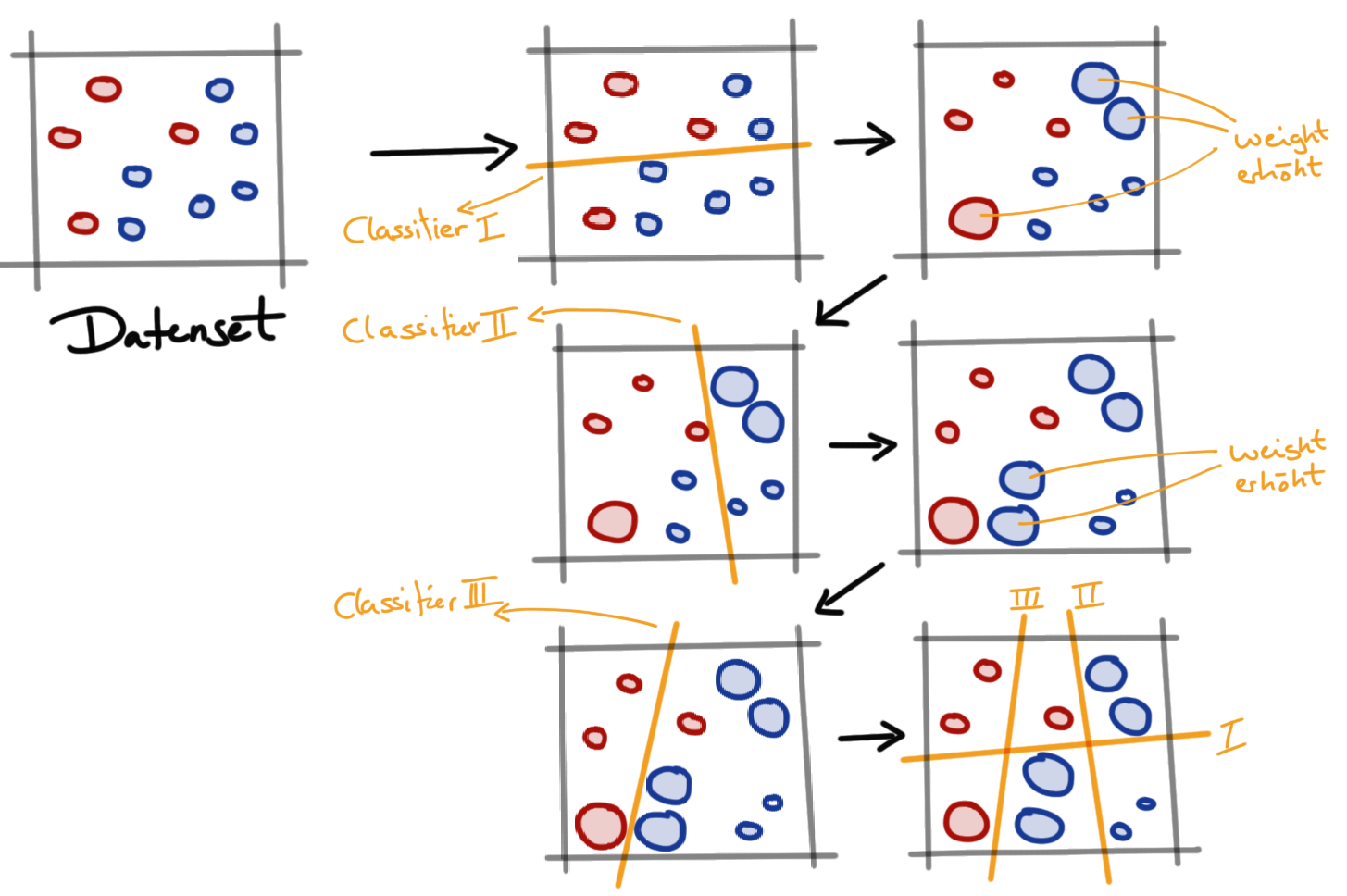
Wir unterscheiden beim Boosting grob in zwei Kategorien. Zum einen gibt es das adaptive Boosting und das gradient Boosting. Beim adaptiven Boosting erhalten die Beobachtungen über die verschiedenen Klassifizierungsschritte unterschiedliche Gewichte für ihre Bedeutung. In Abbildung 79.9 sehen wir ein Beispiel für den adaboost Algorithmus. Wir haben einen ursprünglichen Datensatz mit blauen und roten Beobachtungen. Wir wollen nun diese Beobachtungen voneinander trennen und damit einen Klassifizierer bauen. Wir fangen mit einem simplen Entscheidungsbaum an, der nur einen Split durchführt. Jetzt haben wir zwei falsch klassifizierte blaue Beobachtungen und eine falsche rote Beobachtung. Nun erhöhen wir das Gewicht dieser drei Beobachtungen. Der nächste Klassifizierer soll nun insbesondere auf diese drei Beobachtungen achten. Wir erhalten daher einen anderen Split und damit zwei blaue Beobachtungen die nicht richtig klassifiziert wurden. Wir erhöhen wieder das Gewicht der beiden falsch klassifizierten blauen Beobachtungen. Der dritte Klassifizierer schafft es jetzt die beiden blauen Beobachtungen gut von den roten Beobachtungen zu trennen. Wir stoppen jetzt hier und bringen alle Klassifiziererregeln, also wo der Split liegen soll, in einen Klassifizierer zusammen.
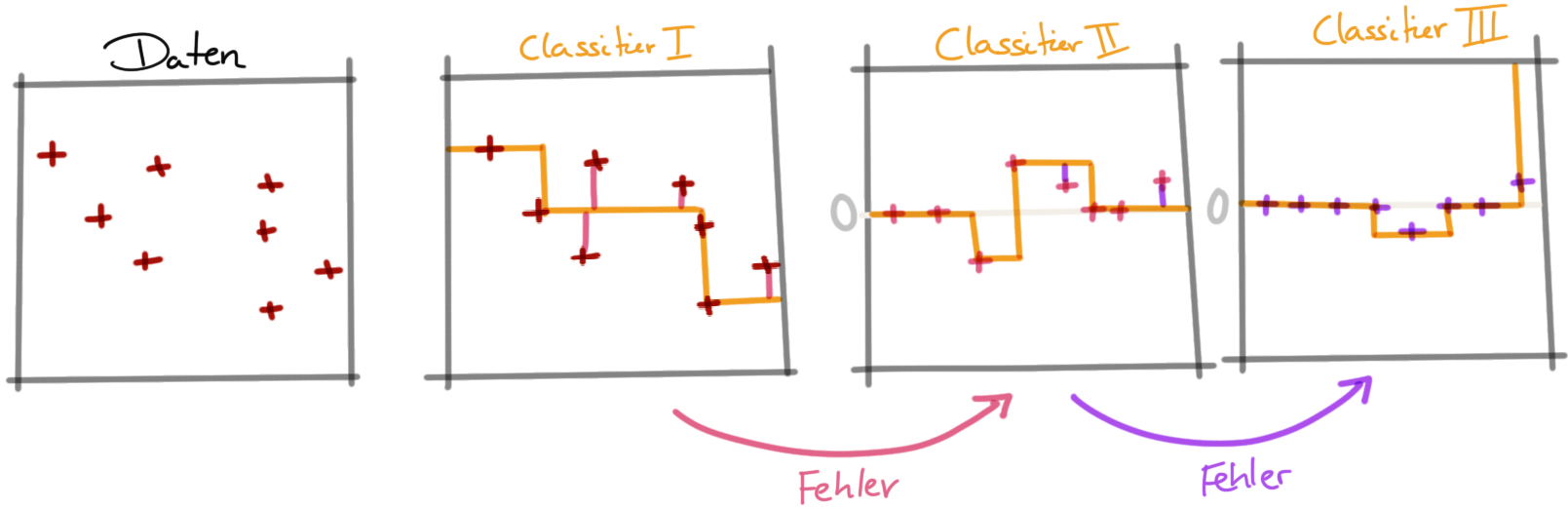
In der Abbildung 79.10 sehen wir die Idee des gradient Boosting einmal dargestellt. Die Idee ist recht simple. Wir wollen wieder nacheinander einen Klassifizierer auf schon klassifizierte Daten anwenden. Wir wollen also das unser zweiter Klassifizierer von dem ersten Klassifizier lernt. Wie machen wir das? Indem wir im ersten Schritt unsere Daten klassifizieren. Wir machen das mit einem Entscheidungsbaum, der mehrere Splits durchführt, die wir dann zu einer eckigen Graden zusammenfassen. Dann haben wir aber einen Fehler als Abstand zu den Splits oder eben zu der Graden. Diese Abstände übertragen wir dann in einen neuen Datensatz auf dem wir dann den nächsten Entscheidungsbaum wachsen lassen. Wir reduzieren also den Fehler des ersten Klassifizierers durch den zweiten Klassifizierer. Dann übertragen wir den Fehler des zweiten Klassifizierers in einen neuen Datensatz und lassen den dritten Klassifizierer den Fehler weiter reduzieren. Am Ende kombinieren wir alle drei Klassifizierer in ein Modell. Durch das gradient Boosting erhalten wir ziemlich gute Entscheidungsbäume, die in der Lage sind sehr schnell und effizient eine Vorhersage zu treffen.
Nach dieser theoretischen Einführung wollen wir uns einmal mit der Implementierung beschäftigen. Wir nutzen hier einmal die bekannten Parameter aus dem Random Forest Algorithmus um unseren xgboost Algorithmus zu trainieren. Wie wir gleich noch im Tuning sehen werden, hatr der xgboost Algorithmus noch mehr Parameter an denen du schrauben kannst. In jedem Baum sollen drei Prädiktoren (mtry = 3) und einer Anzahl von mindestens zehn Beobachtungen je Knoten (min_n = 10) und wir wollen insgesamt eintausend Bäume wachsen lassen (trees = 1000).
xgboost_mod <- boost_tree(mtry = 3, min_n = 10, trees = 1000) |>
set_engine("xgboost") |>
set_mode("classification")Nun bauen wir uns wieder unseren Workflow indem wir das Modell mit dem Rezept für die Gummidatensatz verbinden. Das tolle ist jetzt, dass wir hier wieder des Rezept vom Anfang verwenden können. Wir müssen also nicht das Rezept neu definieren. Wir bauen uns also einfach nur einen neuen Workflow.
xgboost_wflow <- workflow() |>
add_model(xgboost_mod) |>
add_recipe(gummi_rec)Wenn wir den Workflow haben, dann können wir wieder mit der Funktion fit() unser Modell anpassen. Es ist eine wahre Freude. Ich mache das ja jetzt auch schon hier eine Weile im Skript und es ist echt super, wie gut das funktioniert.
xgboost_fit <- xgboost_wflow |>
parsnip::fit(gummi_train_data)Wie auch beim Random Forest Algorithmus können wir uns beim xgboost Algorithmus die Variable Importance wiedergeben lassen. Die Wichtigkeit der Variablen wird in xgboost anhand von drei verschiedenen Wichtigkeiten für eine Variable berechnet. Hier unterscheidet sich dann der Algorithmus xgboost von dem Random Forest Algorithmen. Achtung, wir können nicht einfach die Variable Importance von einem Random Forest Algorithmus mit der eines xgboost Algorithmus vergleichen. Wir kriegen hier andere Werte zurück, die wir dann auch anders interpretieren können.
Schauen wir uns also einmal die Kriterien der Variable Importance für unsere Gummibärchendaten einmal an. Gehen wir mal die Parameter gain, cover und frequency einmal für unsere Körpergröße durch. Zuerst hat die Körpergröße den höchsten Wert in gain mit \(0.84\). Da wir das Gain auf 1 skaliert haben, macht die Körpergröße 84% des gesamten Gain in dem Modell aus. Daher wissen wir, dass die Körpergröße einen überaus bedeutenden Anteil an der Vorhersage des Geschlechts hat. Im Weiteren sehen wir an dem Parameter cover, dass in 34% der Beobachtungen ein Split mit der Körpergröße vorausgeht. Das heißt, 34% der Beobachtungen wurden anhand der Körpergröße aufgeteilt. Da wir nicht wissen wie viele Splits es ingesamt gab, muss man dieses Wert immer etwas vorsichtig bewerten. Die frequency teilt uns mit, dass in 33% der der Splits auch die Körpergröße vor kam. Wir sehen, die Körpergröße ist wichtig für die Vorhersage des Geschlechts. Wenn Variablen fehlen, dann haben diese keinen Einfluss auf die Klassifikation gehabt.
xg_imp <- xgboost_fit |>
extract_fit_parsnip() %$%
xgboost::xgb.importance(model = fit) |>
mutate(across(where(is.numeric), round, 2))
xg_imp Feature Gain Cover Frequency
<char> <num> <num> <num>
1: height 0.81 0.30 0.31
2: age 0.10 0.28 0.29
3: semester 0.06 0.22 0.21
4: most_liked_darkred 0.02 0.12 0.12
5: most_liked_green 0.01 0.08 0.07In der Abbildung 79.11 sehen wir dann die Variable Importance sortiert für alle Prädiktoren und eingeteilt in Cluster. Die Funktion xgb.ggplot.importance() versucht ähnlich bedeutende Prädiktoren in gleiche Cluster zuzuordnen.
xg_imp |>
xgb.ggplot.importance() +
theme_minimal() +
scale_fill_okabeito()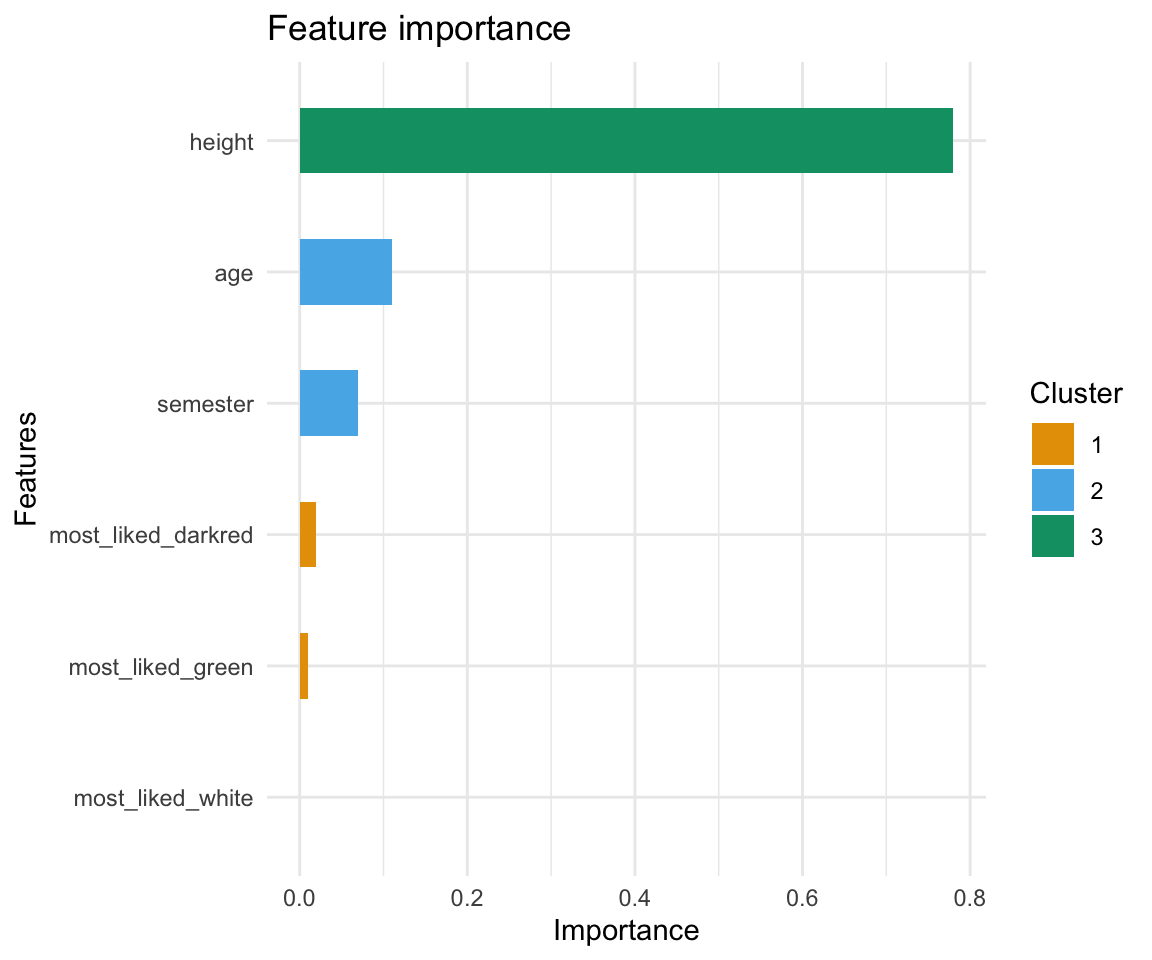
xgboost Algorithmus. Wir sehen, dass sich grob drei Gruppen für Bedeutung der Variablen für die Klassifikation gebildet haben.
Nach unserem kleinen Ausflug zu der Variable Importance können wir jetzt wieder unser xgboost Modell auf den Testdatensatz anwenden und schauen, wie gut das gradient Boosting unsere Geschlechter vorhersagen kann.
xgboost_aug <- augment(xgboost_fit, gummi_test_data ) Nun schauen wir uns an wie gut die Klassifizierung mit dem xgboost Modell funktioniert hat. Als erstes bauen wir uns einmal die Konfusionsmatrix um zu sehen wie gut die beiden Geschlechter in dem Testdatensatz vorhergesagt wurden.
xgboost_cm <- xgboost_aug |>
conf_mat(gender, .pred_class)
xgboost_cm Truth
Prediction m w
m 87 16
w 17 100Ja, das sieht ähnlich gut aus wie der Random Forest Algorithmus. Wir haben eine gute Aufspaltung nach dem Geschlechtern. Viele der Beobachtungen liegen auf der Diagonalen und nur wenige Beobachtungen wurden falsch klassifiziert. Jetzt können wir uns noch eine ganze Reihe an anderen Gütekriterien für den Vergleich von Modellen ausgeben lassen.
xgboost_cm |> summary()# A tibble: 13 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 accuracy binary 0.85
2 kap binary 0.699
3 sens binary 0.837
4 spec binary 0.862
5 ppv binary 0.845
6 npv binary 0.855
7 mcc binary 0.699
8 j_index binary 0.699
9 bal_accuracy binary 0.849
10 detection_prevalence binary 0.468
11 precision binary 0.845
12 recall binary 0.837
13 f_meas binary 0.841Wier vorher schon besprechen wir nicht alle Kriterien, du kannst dann gerne nochmal in dem Kapitel über die Modellvergleiche nachlesen, was die ganze Gütekriterien alles bedeuten. Wenn wir uns auf die Accuarcy konzentrieren, erhalten wir einen guten Wert von 86% richtig klassifizierter Geschlechter. Besonders die Sensitivität ist mit 92% sehr gut. Die Sensitivität gibt ja an, wie zuverlässig unser xgboost Algorithmus erkennt, ob man eine Frau ist. Die Spezifität ist etwas niedriger, also die Fähigkeit die Männer auch als Männer zu erkennen. Das ist für echte Daten ohne Tuning und Kreuzvaldierung schon ein echt sehr guter Wert. Da sind wir noch besser als beim Random Forest.
Nun schauen wir uns noch schnell die ROC Kurve an und sehen, dass die Kurve schon weit von der Diagonalen entfernt ist. Wir sehen eine gute ROC Kurve. Die AUC sollte auch recht groß sein. In den folgenden Schritten wollen wir einmal den xgboost Algorithmus tunen und schauen, ob wir noch bessere Ergebnisse für die Klassifikation mit anderen Parametern für den Algorithmus hin bekommen.
xgboost_aug |>
roc_curve(gender, .pred_w, event_level = "second") |>
autoplot()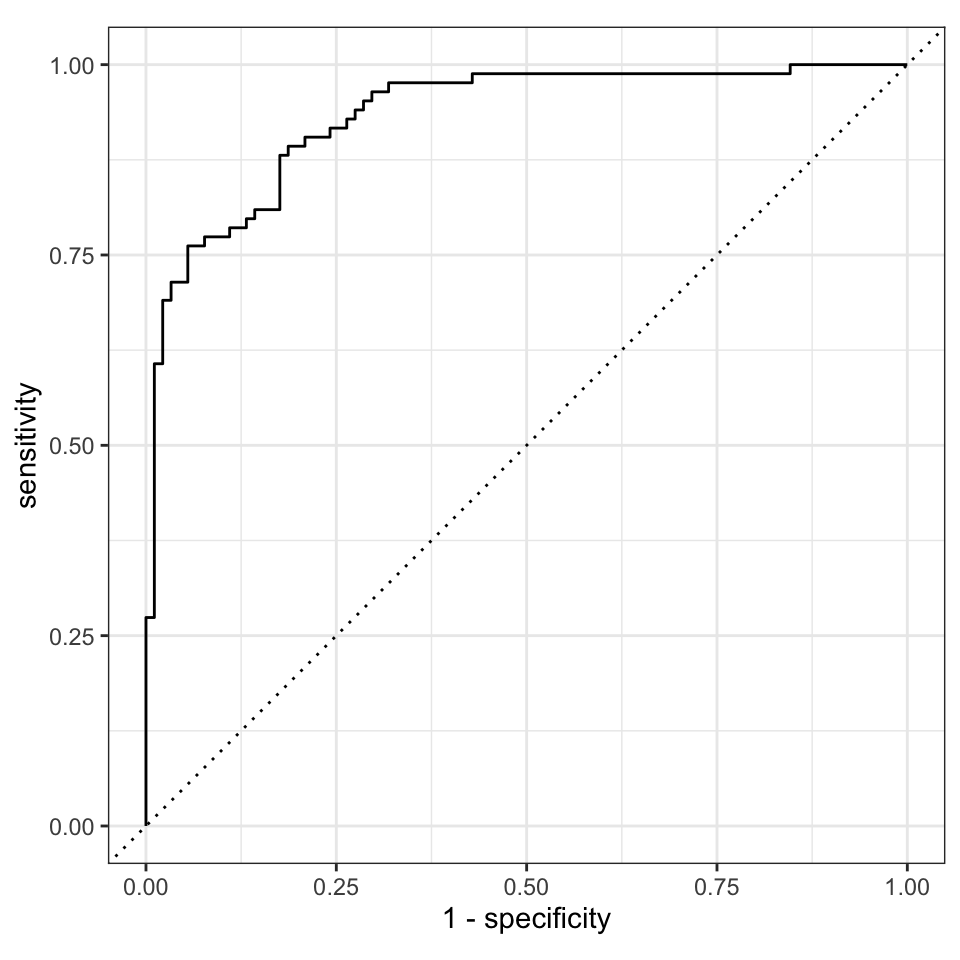
xgboost Algorithmus.
Ja, kannst du. Wenn du nur eine Kreuzvalidierung durchführen willst, findest du alles im Kapitel 78 für den \(k\)-NN Algorithmus. Du musst dort nur den Workflow ändern und schon kannst du alles auch auf den xgboost Algorithmus anwenden. Wir nutzen gleich die Kreuzvalidierung in Kombination mit dem Tuning vom xgboost Algorithmus.
Was heißt Tuning? Wie bei einem Auto können wir an verschiedenen Stellschrauben bei einem mathematischen Algorithmus schrauben. Welche Schrauben und Teile das sind, hängt dann wieder vom Algorithmus ab. Im Falle des xgboost Algorithmus können wir an folgenden Parametern drehen und jeweils schauen, was dann mit unserer Vorhersage passiert. Insgesamt hat der xgboost Algorithmus acht Tuningparameter, wir wählen jetzt für uns hier drei aus. Ich nehme hier auch nur drei Parameter, da sich dann drei Parameter noch sehr gut visuell darstellen lassen. In der Anwendung wäre dann natürlich besser alle Parameter zu tunen, aber das dauert dann auch lange.
mtry, zufällig ausgewählte Anzahl an Variablen für jeden Baum. Das heißt, für jeden Baum werden von unseren Variablen die Anzahl mtry zufällig ausgewählt und auf diesem kleineren Datensatz der Baum erstellt.min_n, kleinste Knotengröße, die noch akzeptiert wird. Wenn ein Knoten unter min_n fällt, dann endet hier das Wachstum des Baumes.trees, Anzahl der Bäume die in einem xgboost Algorithmus erstellt werden.Nun ist es so, dass wir natürlich nicht händisch alle möglichen Kombinationen von der Anzahl der ausgewählten Variablen pro Baum, der kleinsten Knotengröße und der Anzahl der Bäume berechnen wollen. Das sind ziemlich viele Kombinationen und wir kommen dann vermutlich schnell durcheinander. Deshalb gibt es die Funktion tune() aus dem R Paket {tune}, die uns einen Prozess anbietet, das Tuning automatisiert durchzuführen.
Als erstes müssen wir uns ein Objekt bauen, das aussieht wie ein ganz normales Modell in der Klassifikation. Aber wir ergänzen jetzt noch hinter jeder zu tunenden Option noch die Funktion tune(). Das sind die Parameter des Algorithmus, die wir später tunen wollen.
tune_spec <- boost_tree(mtry = tune(),
min_n = tune(),
trees = tune()) |>
set_engine("xgboost") |>
set_mode("classification")
tune_specBoosted Tree Model Specification (classification)
Main Arguments:
mtry = tune()
trees = tune()
min_n = tune()
Computational engine: xgboost Jetzt bauen wir uns den Workflow indem wir statt unserem Modell, die Tuninganweisung in den Workflow reinnehmen. Echt simpel und straightforward. Das Rezept bleibt ja das Gleiche.
gummi_tune_wflow <- workflow() |>
add_model(tune_spec) |>
add_recipe(gummi_rec)Jetzt müssen wir noch alle Kombinationen aus den drei Parametern mtry, min_n und trees ermitteln. Das macht die Funktion grid_regular(). Es gibt da noch andere Funktionen in dem R Paket {tune}, aber ich konzentriere mich hier auf die einfachste. Jetzt müssen wir noch die Anzahl an Kombinationen festlegen. Ich möchte für jeden Parameter fünf Werte tunen. Daher nutze ich hier die Option levels = 5 auch damit hier die Ausführung nicht so lange läuft. Fange am besten mit levels = 5 an und schaue, wie lange das zusammen mit der Kreuzvalidierung dann dauert. Dann kannst du die Levels noch hochschrauben. Beachte aber, dass mehr Level nur mehr Zwischenschritte bedeutet. Jede Option hat eine Spannweite range, die du dann anpassen musst, wenn du höhere Werte haben willst. Mehr Level würden nur mehr Zwischenschritte bedeuten. In unserem Fall weiß zum Beispiel die Funktion mtry() nicht, wie viele Variablen in dem Datensatz sind. Wir müssen also die range für die Anzahl an ausgewählten Variablen selber setzen. Ich wähle daher eine Variable bis vier Variablen.
gummi_grid <- grid_regular(mtry(range = c(1, 4)),
trees(),
min_n(),
levels = 5)Das Tuning nur auf dem Trainingsdatensatz durchzuführen ist nicht so eine gute Idee. Deshalb nutzen wir hier auch die Kreuzvalidierung. Eigentlich ist eine 10-fache Kreuzvalidierung mit \(v=10\) besser. Das dauert mir dann aber hier im Skript viel zu lange. Deshalb habe ich hier nur \(v=5\) gewählt. Wenn du das Tuning rechnest, nimmst du natürlich eine 10-fach Kreuzvalidierung.
gummi_folds <- vfold_cv(gummi_train_data, v = 5)Nun bringen wir den Workflow zusammen mit dem Tuninggrid und unseren Sets der Kreuzvaidierung. Daher pipen wir den Workflow in die Funktion tune_grid(). Als Optionen brauchen wir die Kreuzvaldierungsdatensätze und das Tuninggrid. Wenn du control_grid(verbose = TRUE) wählst, dann erhälst du eine Ausgabe wie weit das Tuning gerade ist. Achtung!, das Tuning dauert seine Zeit. Im Falle des xgboost Algorithmus dauert das Tuning zwar nicht so lange, aber immer noch ein paar Minuten. Wenn du dann alle acht Parameter des xgboost Algorithmustunen wollen würdest, dann würde die Berechnung sehr viel länger dauern. Du kannst das Ergebnis des simpleren Tunings auch in der Datei gummi_xgboost_tune_res.rds finden.
gummi_tune_res <- gummi_tune_wflow |>
tune_grid(resamples = gummi_folds,
grid = gummi_grid,
control = control_grid(verbose = FALSE))Damit du nicht das Tuning durchlaufen lassen musst, habe ich das Tuning in die Datei gummi_xgboost_tune_res.rds abgespeichert und du kannst dann über die Funktion read_rds() wieder einlesen. Dann kannst du den R Code hier wieder weiter ausführen.
Nachdem das Tuning durchgelaufen ist, können wir uns über die Funktion collect_metrics(), die Ergebnisse des Tunings für jede Kombination der drei Parameter mtry, min_n und trees wiedergeben lassen. Diese Ausgabe ist super unübersichtlich. Ich habe mich ja am Anfange des Abschnitts auch für drei Tuningparameter entschieden, da sich dann diese drei Parameter noch gut visualisieren lassen. Deshalb einmal die Abbildung der mittleren Accuarcy und der mittleren AUC-Werte über alle Kreuzvalidierungen.
gummi_tune_res |>
collect_metrics() |>
mutate(trees = as_factor(trees),
min_n = as_factor(min_n)) |>
ggplot(aes(mtry, mean, color = min_n, linetype = trees)) +
theme_minimal() +
geom_line(alpha = 0.6) +
geom_point() +
facet_wrap(~ .metric, scales = "free", nrow = 2) +
scale_x_log10(labels = scales::label_number()) +
scale_color_okabeito()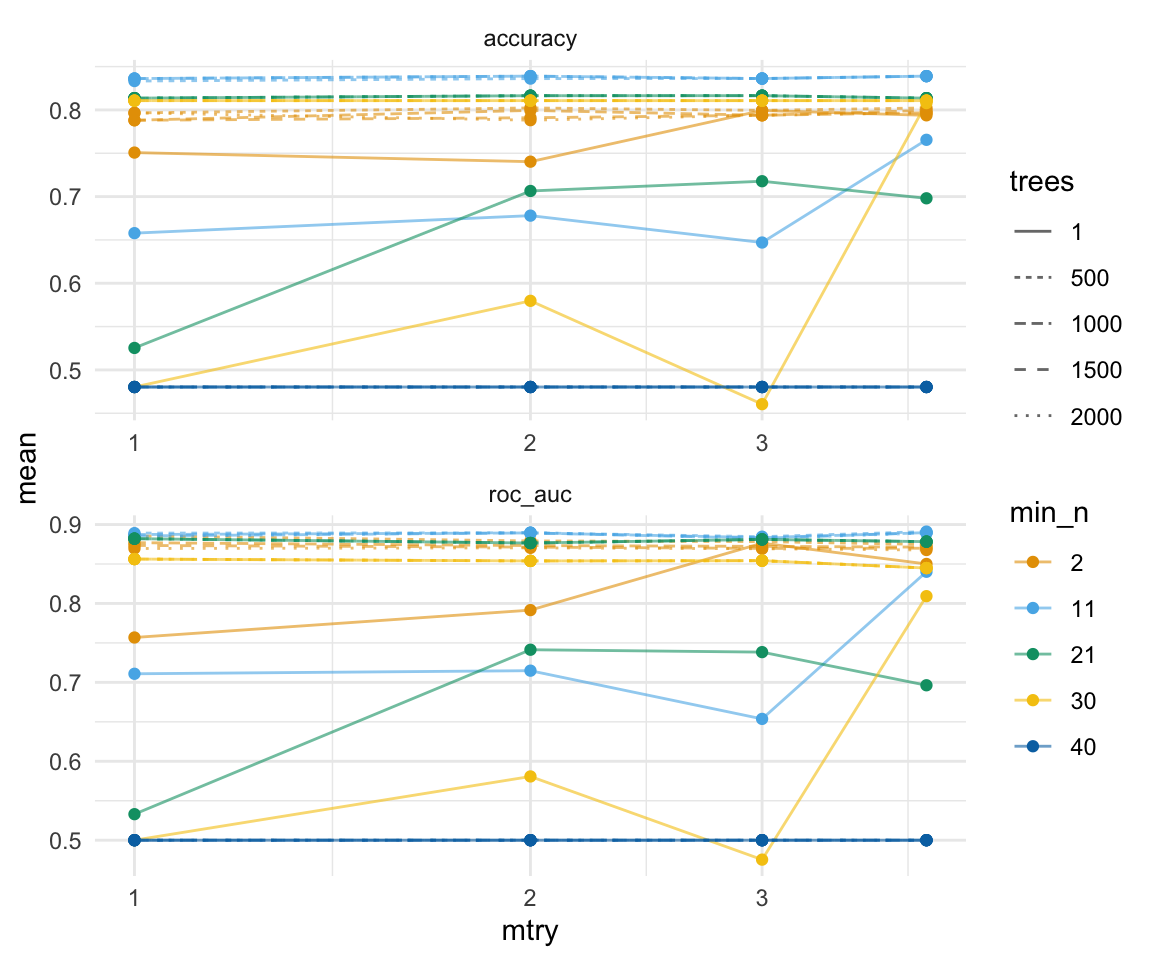
xgboost Algorithmus.
Damit wir nicht händisch uns die beste Kombination raussuchen müssen, können wir die Funktion show_best() nutzen.
gummi_tune_res |>
show_best()Warning in show_best(gummi_tune_res): No value of `metric` was given; "roc_auc"
will be used.# A tibble: 5 × 9
mtry trees min_n .metric .estimator mean n std_err .config
<int> <int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
1 4 500 11 roc_auc binary 0.891 5 0.00637 Preprocessor1_Model0…
2 2 2000 11 roc_auc binary 0.890 5 0.00963 Preprocessor1_Model0…
3 4 1500 11 roc_auc binary 0.890 5 0.00626 Preprocessor1_Model0…
4 4 1000 11 roc_auc binary 0.890 5 0.00631 Preprocessor1_Model0…
5 2 500 11 roc_auc binary 0.890 5 0.00912 Preprocessor1_Model0…Das war die Funktion show_best() aber wir können uns auch die gleich die besten Parameter nach der Accuracy raus ziehen. Das Rausziehen der besten Parameter macht für uns die Funktion select_best().
best_xgboost <- gummi_tune_res |>
select_best()Warning in select_best(gummi_tune_res): No value of `metric` was given;
"roc_auc" will be used.best_xgboost# A tibble: 1 × 4
mtry trees min_n .config
<int> <int> <int> <chr>
1 4 500 11 Preprocessor1_Model082Wir sehen, dass wir mtry = 3 wählen sollten. Dann müssen wir als Anzahl der Bäume trees = 1000 nutzen. Die minimale Anzahl an Beobachtungen pro Knoten ist dann 11. Müssen wir jetzt die Zahlen wieder in ein Modell eingeben? Nein, müssen wir nicht. Mit der Funktion finalize_workflow() können wir dann die besten Parameter aus unserem Tuning gleich mit dem Workflow kombinieren. Dann haben wir unseren finalen, getunten Workflow. Du siehst dann auch in der Ausgabe, dass die neuen Parameter in dem xgboost Algorithmus übernommen wurden.
final_gummi_wf <- gummi_tune_wflow |>
finalize_workflow(best_xgboost)
final_gummi_wf ══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: boost_tree()
── Preprocessor ────────────────────────────────────────────────────────────────
5 Recipe Steps
• step_impute_mean()
• step_impute_bag()
• step_range()
• step_dummy()
• step_nzv()
── Model ───────────────────────────────────────────────────────────────────────
Boosted Tree Model Specification (classification)
Main Arguments:
mtry = 4
trees = 500
min_n = 11
Computational engine: xgboost Jetzt bleibt uns nur noch der letzte Fit übrig. Wir wollen unseren finalen, getunten Workflow auf die Testdaten anwenden. Dafür gibt es dann auch die passende Funktion. Das macht für uns die Funktion last_fit(), die sich dann die Informationen für die Trainings- und Testdaten aus unserem Datensplit von ganz am Anfang extrahiert.
final_fit <- final_gummi_wf |>
last_fit(gummi_data_split) Da wir immer noch eine Kreuzvaldierung rechnen, müssen wir dann natürlich wieder alle Informationen über alle Kreuzvaldierungsdatensätze einsammeln. Dann erhalten wir unsere beiden Gütekriterien für die Klassifikation des Geschlechts unser Studierenden nach dem xgboost Algorithmus. Die Zahlen sind schon gut für echte Daten. Eine Accuracy von 84% bedeutet das wir über acht von zehn Studierenden richtig klassifizieren. Die AUC ist auch schon fast hervorragend, wir bringen kaum Label durcheinander.
final_fit |>
collect_metrics()# A tibble: 3 × 4
.metric .estimator .estimate .config
<chr> <chr> <dbl> <chr>
1 accuracy binary 0.841 Preprocessor1_Model1
2 roc_auc binary 0.921 Preprocessor1_Model1
3 brier_class binary 0.109 Preprocessor1_Model1Dann bleibt uns nur noch die ROC Kurve zu visualisieren. Da wir wieder etwas faul sind, nutzen wir die Funktion autoplot(). Als Alternative geht natürlich auch das R Paket {pROC}, was eine Menge mehr Funktionen und Möglichkeiten bietet.
final_fit |>
collect_predictions() |>
roc_curve(gender, .pred_w, event_level = "second") |>
autoplot()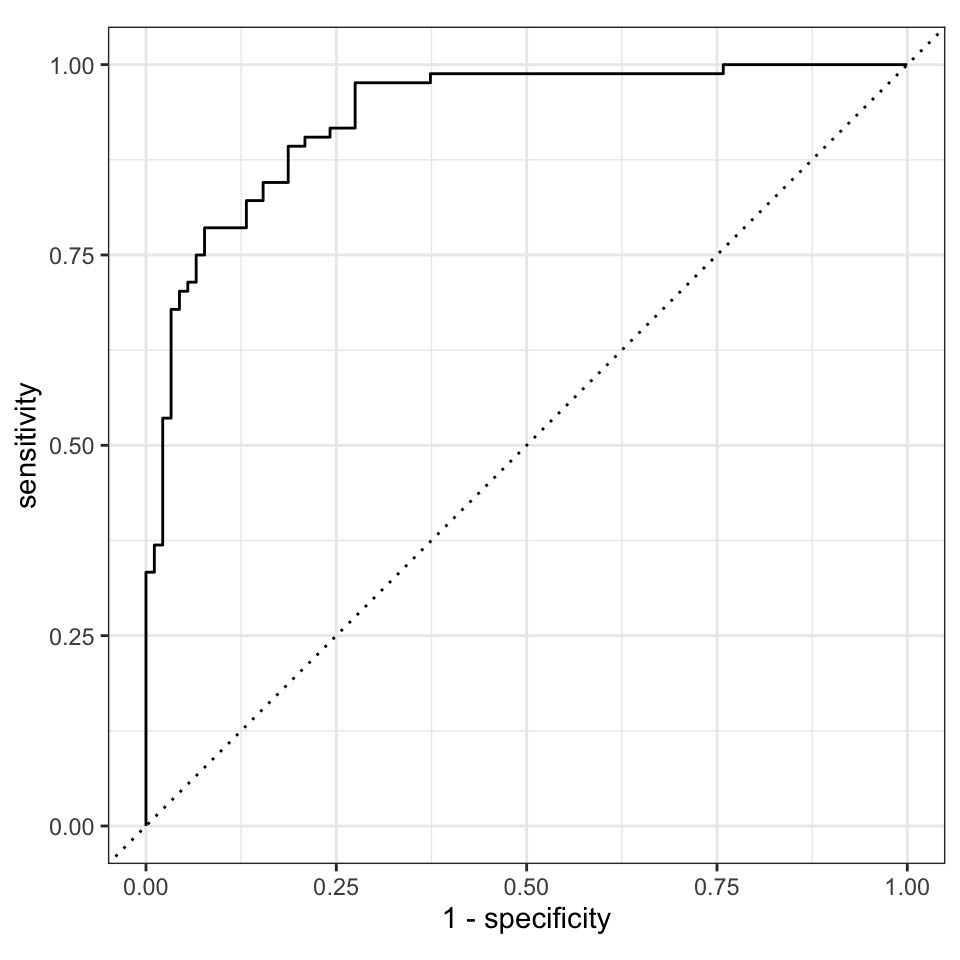
xgboost Algorithmus nach der Kreuvalidierung und dem Tuning.
Eine gute ROC Kurve würde senkrecht nach oben gehen und dann waagrecht nach rechts. Dann hätten wir eine AUC von 1 und eine perfekte Separation der beiden Label durch unseren Algorithmus. Unser Algorithmus würde jedem weiblichen Studierenden in dem Testdatensatz korrekt dem Geschlecht w zuweisen. Da wir eine ROC Kurve hier vorliegen haben, die sehr weit weg von der Diagonalen ist, haben wir sehr viele richtig vorhergesagte Studierende in unseren Testdaten. Unser Modell funktioniert um das Geschlecht von Studierenden anhand unserer Gummibärchendaten vorherzusagen.