R Code [zeigen / verbergen]
pacman::p_load(tidyverse, readxl, magrittr,
janitor, lubridate, glue, ggtext,
conflicted)
conflicts_prefer(magrittr::extract)Letzte Änderung am 02. April 2025 um 20:14:19
“Some people, when confronted with a problem, think ‘I know, I will use regular expressions!’ Now they have two problems.” — Jamie Zawinski
Hier kommen wir jetzt zu einem speziellen Fall von Zeichen nämlich den Buchstaben oder character sowie den Wörtern oder string. Wörter kommen in R dann meist ja doppelt vor. Zum einen als Namen für Objekte oder aber als Bezeichnungen von Faktoren. Wir haben aber auch Spaltennamen oder aber unvollständige Einträge in Spalten. Am Ende gibt es noch das Datum oder die Zeit als Eingabe, die wollen wir uns dann auch nochmal am Ende anschauen. So häufig wirst du nicht mit Strings und Co. arbeiten, denn meist sind die Datensätze klein genug, dass du dir deine Daten dann sauber in Excel zusammenbauen kannst. Wenn die Daten aber großer werden, dann müssen wir mit besseren Tools ran. Und eins dieser Tools sind dann reguläre Ausdrück (eng. regular expression, abk. RegExp oder Regex). Ich nutze vieles von diesen Funktionen in dem Kapitel dann in der Anwendung. Deshalb ist dieses Kapitel auch so ein wenig für mich um meine Funktionen, die ich immer wieder nutze, parat zu haben.
Wir brauchen nicht viele R Pakete in diesem Kapitel, aber ein paar sind es schon. Der Großteil der Funktionen steckt dann im R Paket {stingr} und das verbirgt sich dann in {tidyverse}.
pacman::p_load(tidyverse, readxl, magrittr,
janitor, lubridate, glue, ggtext,
conflicted)
conflicts_prefer(magrittr::extract)In diesem Kapitel nutzen wir den Datensatz zu den Hunde-, Katzen- und Fuchsflöhen. Wir wollen uns aber auf die Spaltennamen konzentrieren, deshalb brauchen wir nur die ersten drei Zeilen des Datensatzes. Sonst bauen wir uns die Daten oder Vektoren einfach selber, denn hier geht es ja nur um das schnelle Zeigen und nicht um die direkte sinnvolle Anwendung.
data_tbl <- read_excel("data/flea_dog_cat_fox.xlsx") |>
extract(1:3,)Wir nehmen jetzt diesen Datensatz und schauen uns das R Paket {stringr} näher an. Danach werden wir dann die Sache nochmal von der Seite der regulären Ausdrück betrachten.
{stringr}Das R Paket {stringr} und das Cheat Sheet zu {stringr} geben eine große Übersicht über die Möglichkeiten ein character zu bearbeiten. Im Folgenden schauen wir uns einmal einen simplen Datensatz an. Wir wollen auf dem Datensatz ein paar Funktionen aus dem R Paket {stringr} anwenden.
regex_tbl <- tibble(animal = c("cat", "cat", "dog", "bird"),
site = c("village", "village", "town", "cities"),
time = c("t1_1", "t2_2", "t3_3", "t3_5"))Die einfachste und am meisten genutzte Funktion ist str_c(). Die Funktion str_c() klebt verschiedene Vektoren zusammen. Wir können auch Zeichen wählen, wie das -, um die Vektoren zu verbinden. Wir bauen uns also eine neue Spalte animal_site in dem wir die Spalten animal und site mit einem - verbinden. Wir können statt dem - auch ein beliebiges anderes Zeichen oder auch Wort nehmen.
regex_tbl |>
mutate(animal_site = str_c(animal, "-", site))# A tibble: 4 × 4
animal site time animal_site
<chr> <chr> <chr> <chr>
1 cat village t1_1 cat-village
2 cat village t2_2 cat-village
3 dog town t3_3 dog-town
4 bird cities t3_5 bird-citiesHäufig brauchen wir auch eine ID Variable, die exakt \(n\) Zeichen lang ist. Hier können wir die Funktion str_pad() nutzen um Worte auf die Zeichenlänge width = zu verlängern. Wir können auch das Zeichen wählen, was angeklebt wird und die Seite des Wortes wählen an die wir kleben wollen. Wir verlängern also links die Spalte site auf ein Wort mit acht Zeichen und als Füllzeichen nehmen wir die Null.
regex_tbl |>
mutate(village_pad = str_pad(site, pad = "0",
width = 8, side = "left"))# A tibble: 4 × 4
animal site time village_pad
<chr> <chr> <chr> <chr>
1 cat village t1_1 0village
2 cat village t2_2 0village
3 dog town t3_3 0000town
4 bird cities t3_5 00cities Abschließend können wir auch eine Spalte in zwei Spalten aufteilen. Dafür müssen wir den Separator wählen nachdem die Spalte aufgetrennt werden soll. Wir können eine Spalte auch in mehrere Spalten aufteilen, wenn der Separator eben an zwei oder mehr Stellen steht. Wir haben die Spalte time und trennen die Spalte time an der Stelle _ in zwei Spalten auf.
regex_tbl |>
separate(time, into = c("time", "rep"),
sep = "_", convert = TRUE)# A tibble: 4 × 4
animal site time rep
<chr> <chr> <chr> <int>
1 cat village t1 1
2 cat village t2 2
3 dog town t3 3
4 bird cities t3 5Es gibt noch sehr viel mehr Möglichkeiten einen character Vektor zu bearbeiten. Teilweise nutze ich stringr bei der Auswertung von den Beispielen im Anhang. Schau dir da mal um, dort wirst du immer mal wieder die Funktionen aus dem Paket finden.
{glue}Das R Paket {glue} erlaubt es einfach Strings nach Regeln über geschweifte Klammern zusammenzukleben. Hier einmal ein Beispiel aus der Hilfeseite.
name <- "Fred"
age <- 50
anniversary <- as.Date("1991-10-12")
glue('My name is {name},',
' my age next year is {age + 1},',
' my anniversary is {format(anniversary, "%A, %B %d, %Y")}.')My name is Fred, my age next year is 51, my anniversary is Saturday, October 12, 1991.Hier dann erstmal nur der kurze Teil. mehr dann, wenn ich die Anwendungen dann in den Kapiteln nutze. Hier nochmal ein weiteres Beispiel zur Annotierung von Abbildungen von Andrew Heiss und seinem Blogpost Marginalia. Die Idee ist eben hier, dass wir auch Befehle aus Markdown für fett ** oder aber den Zeilenumbruch <br> in unsere Annotation schreiben können.
a_line <- function(x) (2 * x) - 1
slope_annotations <- tibble(x = c(-0.25, 1.2, 2.4)) |>
mutate(y = a_line(x)) |>
mutate(nice_y = y + 1) |>
mutate(nice_label = glue("x: {x}; y: {y}<br>",
"Slope (dy/dx): **{2}**"))Zusammen mit dem R Paket {ggtext} können wir dann schön eine Abbildung annotieren. Das ist hier natürlich sehr viel auf einmal und du findest dann auch nochmal im Kapitel zur Visualisierung von Daten mehr Informationen zu {ggplot}.
ggplot() +
theme_minimal() +
geom_vline(xintercept = 0, linewidth = 0.5, color = "grey50") +
geom_hline(yintercept = 0, linewidth = 0.5, color = "grey50") +
geom_function(fun = a_line, linewidth = 1, color = "#CC79A7") +
geom_point(data = slope_annotations, aes(x = x, y = y)) +
geom_richtext(data = slope_annotations,
aes(x = x, y = y, label = nice_label),
nudge_y = 0.5) +
scale_x_continuous(breaks = -2:5, limits = c(-1, 3)) +
scale_y_continuous(breaks = -3:9) +
labs(x = "x", y = "y") 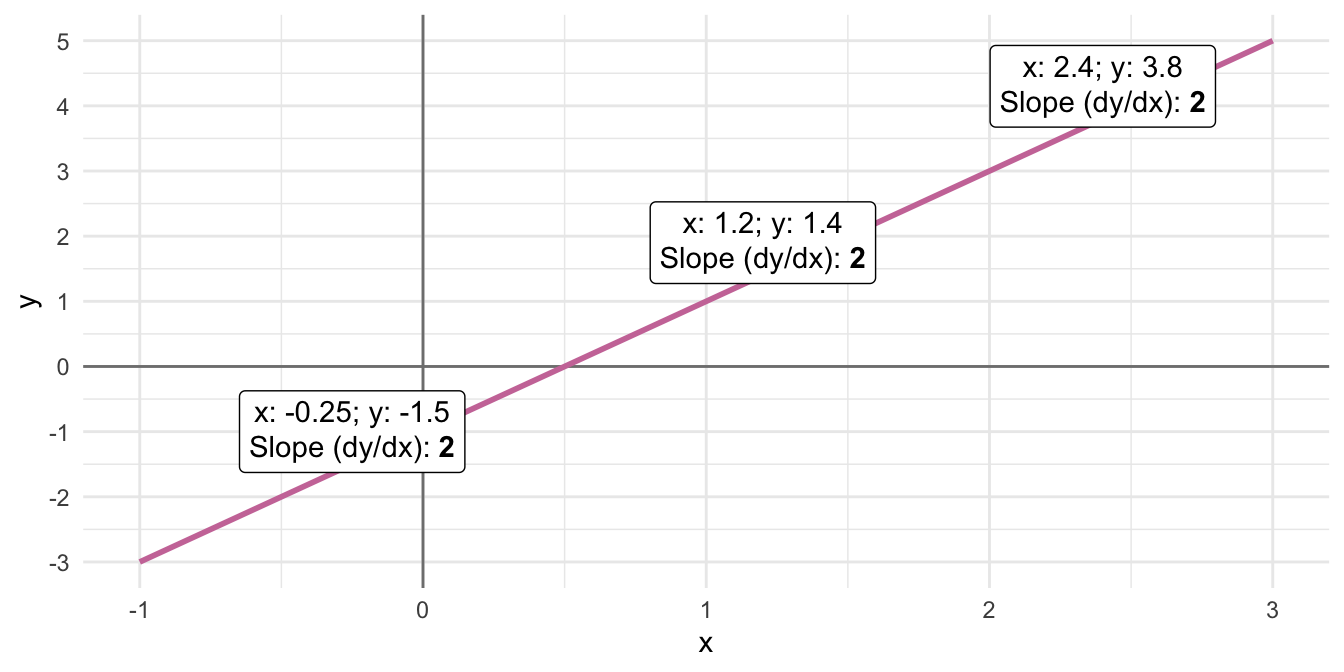
{glue} und dem R Paket {ggtext}.*
Ein regulärer Ausdruck (eng. regular expression, abk. RegExp oder Regex) ist eine verworrene Zeichenkette, die einer Maschine ein Muster übersetzt. Dieses Muster soll dann auch alle Wörter angewendet werden. Das klingt kryptisch und ist es auch. Reguläre Ausdrücke sind das Nerdthema schlechthin in der Programmierung. Also tauchen wir mal ab in die Welt der seht nützlichen und mächtigen regulären Ausdrücke.
Wir immer gibt es schöne Tutorials. Einmal Regular expressions in stingr und dann von Hadley Wickham ein Kapitel zu Regular expressions.
Fangen wir mit der grundsätzlichen Idee an. Reguläre Ausdrücke finden bestimmte Zeichen in Wörtern. Ich habe dir hier einmal eine winzige Auswahl an regulären Ausdrücken mitgebracht. Du kannst auch reguläre Ausdrück miteinander verknüpfen. Daher kommt die eigentlich Macht eines regulären Ausdruck. Aber später mehr dazu.
\d: entspricht einer beliebigen Ziffer. Wir finden also eine Ziffer oder Zahl in einem Wort.\s: entspricht einem beliebigen Leerzeichen (z. B. Leerzeichen, Tabulator, Zeilenumbruch). Wir finden also ein Leerzeichen in einem String.[abc]: passt auf a, b oder c. Das ist jetzt wörtlich gemeint. Wir finden die Buchstaben a, b oder c.[^abc]: passt auf alles außer a, b oder c. Das ist jetzt ebenfalls wörtlich gemeint.Denk daran, dass du, um einen regulären Ausdruck zu erstellen, der \d oder \s enthält, das \ für die Zeichenkette ausschließen musst, also gib \\d oder \\s ein. Das ist eien Besonderheit in R. Wir müssen in R immer ein doppeltes \\ schreiben.
Es gibt eine große Auswahl an möglichen regulären Ausdrücken. Ich nutze meist dann noch ein Cheat Sheet um den Überblick zu bewahren. Aber wie schon oben geschrieben, reguläre Ausdrücke braucht man meist erst, wenn die Daten so große werden, dass wir die Daten nicht mehr händisch bearbeiten können.
Ich selber nutze immer das Regular Expressions Cheat Sheet by DaveChild um den Überblick zu bewahren. Es ist dann auch einfach zu viel zu merken.
Wir können wieder das R Paket {stringr} nutzen um die regulären Ausdrück in R anzuwenden. Beginnen wir erstmal mit den einfachen Funktionen und arbeiten uns dann vor. Bitte beachte auch, dass du in der Funktion select() auch Helferfunktionen nutzen kannst, die dir das Leben wirklich einfacher machen. Auf diese Helferfunktionen gehen wir später nochmal ein.
str_detect() gibt TRUE/FALSE wieder, wenn das Wort eine Zeichenkette enthält.str_subset() gibt die Werte wieder in denen die Zeichenkette erkannt wird.str_replace() ersetzt das erste Auftreten der Zeichenkette durch eine andere Zeichenkette. Die Funktion str_replace_all() ersetzt dann jedes Auftreten der Zeichenkette.Fangen wir simple an, wir wollen Wörter finden, die eine Zeichenkette enthalten. Dafür nutzen wir die Funktion str_detect().
c("dog", "small-dog", "doggy", "cat", "kitty") |>
str_detect("dog")[1] TRUE TRUE TRUE FALSE FALSEOkay, das hat ja schon mal gut funktioniert. Wenn wir die Worte wiederhaben wollen, dann können wir auch die Funktion str_subset() nutzen. Wir wollen jetzt aber nur die Einträge, die mit der Zeichenkette dog anfangen. Deshalb schreiben wir ein ^ vor die Zeichenkette. Wenn wir nur die Einträge gewollt hätten, die mit dog enden, dann hätten wir dog$ geschrieben. Das $ schaut dann von hinten in die Wörter.
c("dog", "small-dog", "doggy", "cat", "kitty") |>
str_subset("^dog")[1] "dog" "doggy"Nun haben wir uns verschrieben und wollen das small entfernen und mit large ersetzen. Statt large hätten wir auch nichts "" hinschreiben können. Dafür können wir die Funktion str_replace() nutzen. Die Funktion entfernt das erste Auftreten einer Zeichenkette. Wenn du alle Zeichenketten entfernen willst, dann musst du die Funktion str_replace_all() verwenden.
c("dog", "small-dog", "doggy", "cat", "kitty") |>
str_replace("small", "large")[1] "dog" "large-dog" "doggy" "cat" "kitty" Damit haben wir die wichtigsten drei Funktionen einmal erklärt. Wir werden dann diese Funktionen immer mal wieder anwenden und dann kannst du sehen, wie die regulären Ausdrücke in den Funktionen funktionieren. Auf der Hilfeseite von stringr gibt es nochmal ein Tutorium zu Regular expressions, wenn du hier mehr erfahren möchtest.
Viel häufiger nutzen wir die Helferfunktionen in select(). Wir haben hier eine große Auswahl, die uns das selektieren von Spalten sehr erleichtert. Im Folgenden einmal die Liste alle möglichen Funktionen. Beachte auch dabei folgende weitere Funktionen im Overview of selection features.
matches(), wählt alle Spalten die eine Zeichenkette enthalten. Hier können wir reguläre Ausdrücke verwenden.all_of(), ist für die strenge Auswahl. Wenn eine der Variablen im Zeichenvektor fehlt, wird ein Fehler ausgegeben.any_of(), prüft nicht auf fehlende Variablen. Dies ist besonders nützlich bei der negativen Selektionen, wenn du sicherstellen möchtest, dass eine Variable entfernt wird.contains(), wählt alle Spalten die eine Zeichenkette enthalten. Funktioniert nicht mit regulären Ausdrücken.starts_with(), wählt alle Spalten die mit einer Zeichenkette beginnt. Funktioniert nicht mit regulären Ausdrücken.ends_with(), wählt alle Spalten die mit einer Zeichenkette endet. Funktioniert nicht mit regulären Ausdrücken.everything(), sortiert die restlichen Spalten hinten an. Wir können uns also die wichtigen Spalten namentlich nach vorne holen und dann den Rest mit everything() hinten an kleben.last_col(), wählt die letzte Spalte aus. Besonders wichtig, wenn wir von einer Spalte bis zur letzten Spalte auswählen wollen.num_range(), können wir nutzen, wenn wir über eine Zahl eine Spalte wählen wollen. Das heißt, unsere Spalten haben Zahlen in den Namen und wir könne darüber dann die Spalten wählen.Hier einmal das Beispiel mit matches() wo wir alle Spalten nehmen in denen ein _ als Unterstrich vorkommt.
data_tbl |>
select(matches("_"))# A tibble: 3 × 2
jump_length flea_count
<dbl> <dbl>
1 5.7 18
2 8.9 22
3 11.8 17Wir können auch über einen Vektor die Spalten auswählen. Das ist meistens nötig, wenn wir die Namen der Spalten zum Beispiel aus einer anderen Funktion erhalten. Dafür können wir dann die Funktion one_of() nutzen.
data_tbl |>
select(one_of("animal", "grade"))# A tibble: 3 × 2
animal grade
<chr> <dbl>
1 dog 8
2 dog 8
3 dog 6Es gibt noch eine Menge anderer Tools zum Nutzen von Regulären Ausdrücken. Aber hier soll es erstmal reichen. Wir gehen dann später in der Anwendung immer mal wieder auf die Funktionen hier ein.
Die Arbeit mit Datumsdaten in R kann frustrierend sein. Die R Befehle für Datumszeiten sind im Allgemeinen nicht intuitiv und ändern sich je nach Art des verwendeten Datumsobjekts. Hier gibt es aber eine Lösung mit dem R Paket {lubridate}, die uns die Arbeit etwas erleichtert.

Der beste Tipp ist eigentlich immer, das Datum in ein Format zu bringen und dann dieses Format weiterzuverarbeiten.
character Spalte mit as.character() um. Ein Datum besteht immer aus dem Tag, dem Monat und dem Jahr. Dabei ist wichtig, dass der Monat und der Tag immer zweistellig sind. Manchmal muss man dann über str_split() und str_pad() erstmal echt sich einen Wolf splitten und kleben, bis dann das Format so passt. Dann geht es meistens wie folgt weiter.as_date() eine Datumspalte zu erschaffen. Häufig erkennt die Funktion die Spalte richtig und schneidet das Datum korrekt in Jahr/Monat/Tag. Manchmal klappt das aber auch nicht. Dann müssen wir uns weiter strecken.as_date() nicht klappt, musst du nochmal über parse_date_time() gehen und angeben, wie dein Datum formatiert ist.Auf der Hilfeseite der Funktion parse_date_time() erfährst du dann mehr über User friendly date-time parsing functions
Schauen wir uns einmal ein Beispiel für Daten an. Ich habe hier die Daten von Deutschen Wetterdienst runtergeladen und möchte die Spalte jjjjmmdd in ein Datum in R umwandeln.
time_tbl <- read_table("data/day_values_osnabrueck.txt") |>
clean_names() |>
select(jjjjmmdd) |>
print(n = 3)# A tibble: 501 × 1
jjjjmmdd
<dbl>
1 20221030
2 20221029
3 20221028
# ℹ 498 more rowsWir nehmen die Datumsspalte, die eine Zahl ist und transformieren die Spalte in einen character. Danach können wir dann die Funktion as_date() nutzen um uns ein Datum wiedergeben zu lassen.
time_tbl |>
mutate(jjjjmmdd = as.character(jjjjmmdd),
jjjjmmdd = as_date(jjjjmmdd)) |>
print(n = 3)# A tibble: 501 × 1
jjjjmmdd
<date>
1 2022-10-30
2 2022-10-29
3 2022-10-28
# ℹ 498 more rowsWie wir sehen passt die Umwandlung in diesem Fall hervorragend. Die Funktion as_date() erkennt das Jahr, den Monat und den Tag und baut uns dann die Datumsspalte zusammen. Meistens passt es auch, dann können wir hier enden.
Als eine Alternative haben wir auch die Möglichkeit die Funktion as.Date() zu nutzen. Hier können wir das Datumformat in einer etwas kryptischen Form angeben. Schauen wir uns erst die Funktion in Arbeit an und dann was wir hier gemacht haben.
time_tbl |>
mutate(jjjjmmdd = as.character(jjjjmmdd),
jjjjmmdd = as.Date(jjjjmmdd, "%Y%m%d")) |>
print(n = 3)# A tibble: 501 × 1
jjjjmmdd
<date>
1 2022-10-30
2 2022-10-29
3 2022-10-28
# ℹ 498 more rowsWir können der Funktion das Datumsformat mitgeben. Im Folgenden einmal eine Auswahl an Möglichkeiten. Die jeweiligen Prozent/Buchstaben-Kombinationen stehen dann immer für ein Jahr oder eben ein Monat.
%Y: 4-Zeichen Jahr (1982)%y: 2-Zeichen Jahr (82)%m: 2-Zeichen Monat (01)%d: 2-Zeichen Tag des Monats (13)%A: Wochentag (Wednesday)%a: Abgekürzter Wochentag (Wed)%B: Monat (January)%b: Abgekürzter Monat (Jan)Nehmen wir einmal an, wir haben das Datum in folgender Form 2012-11-02 vorliegen. Dann können wir dafür als Format %Y-%m-%d schreiben und das Datum wird erkennt. Hier ist es besonders hilfreich, dass wir die Trennzeichen mit angeben können. Sonst müssen wir die Trennzeichen dann über str_replace_all() entfernen und könten dann schauen, ob es über die Funktion as_date() geht.
Als ein weiteres Beispiel nochmal das Einlesen von einer Datei mit dem Datum und der Uhrzeit in zwei Spalten. Wir wollen die beiden Spalten zusammenführen, so dass wir nur noch eine Spalte mit datetime haben.
date_time_tbl <- read_excel("data/date_time_data.xlsx") |>
clean_names()
date_time_tbl# A tibble: 7 × 5
datum uhrzeit messw min max
<dttm> <dttm> <dbl> <dbl> <dbl>
1 2023-04-11 00:00:00 1899-12-31 13:30:00 22 22 22
2 2023-04-11 00:00:00 1899-12-31 14:00:00 19.5 19.5 22.6
3 2023-04-11 00:00:00 1899-12-31 14:30:00 23.4 19.5 25.8
4 2023-04-11 00:00:00 1899-12-31 15:00:00 19.2 18.3 28.1
5 2023-04-11 00:00:00 1899-12-31 15:30:00 17.1 17.1 23.3
6 2023-04-11 00:00:00 1899-12-31 16:00:00 19.2 15.3 21.9
7 2023-04-11 00:00:00 1899-12-31 16:30:00 29.2 18.3 31 Dazu nutzen wir die Funktion format() die es uns erlaubt die Spalten einmal als Datum ohne Uhrzeit zu formatieren und einmal erlaubt die Uhrzeit ohne das Datum zu bauen. Dann nehmen wir beide Spalten und packen das Datum und die Uhrzeit wieder zusammen.
date_time_tbl |>
mutate(uhrzeit = format(uhrzeit, format = "%H:%M:%S"),
datum = format(datum, format = "%Y-%m-%d"),
datum = ymd(datum) + hms(uhrzeit))# A tibble: 7 × 5
datum uhrzeit messw min max
<dttm> <chr> <dbl> <dbl> <dbl>
1 2023-04-11 13:30:00 13:30:00 22 22 22
2 2023-04-11 14:00:00 14:00:00 19.5 19.5 22.6
3 2023-04-11 14:30:00 14:30:00 23.4 19.5 25.8
4 2023-04-11 15:00:00 15:00:00 19.2 18.3 28.1
5 2023-04-11 15:30:00 15:30:00 17.1 17.1 23.3
6 2023-04-11 16:00:00 16:00:00 19.2 15.3 21.9
7 2023-04-11 16:30:00 16:30:00 29.2 18.3 31 Im Weiteren hilft das Tutorium zum R Paket {lubridate} - Make Dealing with Dates a Little Easier und natürlich das weitere Tutorium Dates and times.