R Code [zeigen / verbergen]
pacman::p_load(tidyverse, magrittr, infer, conflicted, broom)
conflicts_prefer(dplyr::filter)Letzte Änderung am 26. June 2024 um 15:04:15
“Wer zu spät kommt, den bestraft das Leben.” — Gorbatschow zu Honecker beim Staatsbesuch in der DDR am 7. Oktober 1989
In diesem Kapitel wollen wir ein mächtiges Verfahren kennen lernen, welches zu den altvorderen Zeiten von Fisher und Co. nicht zu Verfügung stand: der Permutationstest oder aber das Bootstraping. Dabei war die Theorie schon bekannt, aber die technische Durchführung war unmöglich. Erst seit der Entwicklung von Computern, die hunderte bis tausende Rechenschritte in wenigen Sekunden durchführen können, sind Permutationstests erst denkbar. Damit erlauben uns die heutigen technischen Gegebenheiten mehr als es vor über hundert Jahren der Fall war, oder um es mit Fay & Gerow (2018) zu sagen:
“[…], if statistics were being invented today, bootstrapping, as well as related re-sampling methods, would be the standard go-to approach.” — Fay & Gerow (2018)
Was macht also Permutationstests oder allgemeiner gesprochen resampling Methoden so wirkmächtig? Permutationstests beruhen nicht auf Annahmen über die Verteilung unseres Outcomes \(y\), wie es bei einigen anderen Tests, wie zum Beispiel dem T-test, der Fall ist. Permutationstests funktionieren, indem die beobachteten Daten mehrmals neu gezogen werden, um einen \(p\)-Wert für den Test zu bestimmen. Wir haben es also mit einem iterativen Prozess zu tun. Oder anders gesagt, wir simulieren hier Daten und damit die Nullhypothese. Erinnern wir uns daran, dass der \(p\)-Wert als die Wahrscheinlichkeit definiert ist, Daten zu erhalten, die genauso extrem sind wie die beobachteten Daten, wenn die Nullhypothese wahr ist. Wenn die Daten gemäß der Nullhypothese mehrmals gemischt werden, kann die Anzahl der Fälle mit Daten, die genauso extrem sind wie die beobachteten Daten, gezählt und ein \(p\)-Wert berechnet werden.
Die Vorteile von Permutationstests, neben der relative Einfachheit bei Durchführung und Interpretation, sind:
Die Nachteile von Permutationstests sind:
In diesem Kapitel gebe ich eine kurze Übersicht über den Permutationstest und andere resampling Methoden. Es gibt wie immer die ein oder andere Literatur und auch Kritik sowie Diskussionen. Ich finde den Permutationstest als eine gute Lösung, wenn i) genug Fallzahl vorliegt und damit mehr als 10 Beobachtungen pro Gruppe sowie ii) es keinen passenden Test gibt. Warum muss es genug Beobachtungen in den Gruppen bzw. dann in dem Datensatz geben? Wir müssen ja genug zufällige Daten permutieren. Wenn wir zu wenig Beobachtungen haben, dann wiederholen sich unsere zufälligen Datensätze sehr schnell. Wir laufen dann in das gleiche Problem wie bei den nicht-parametrischen Tests, die auch eine Unterklasse von Permutationsverfahren mit einer geschlossenen mathematischen Formel sind.
Wir immer geht natürlich mehr als ich hier Vorstellen kann. Du findest im Folgenden Tutorien, die mich hier in dem Kapitel inspiriert haben. Ich habe mich ja in diesem Kapitel auf die Durchführbarkeit in R und die allgemeine Verständlichkeit konzentriert. Es geht aber natürlich wie immer auch mathematischer…
{infer} ist ein guter Startpunkt sich einmal klar zu machen, wie die Permutationstest funktionieren. Das Oaket hat ein sehr sauberes Framework und ich stelle hier auch noch ein Beispiel vor.{resample} liefert dann die aktuellste Form in R dann alle möglichen resampling Methoden durchzuführen. Ein Beispiel werde ich dann wieder vorstellen, aber es lohnt sich die Seite einmal zu besuchen.Wir wollen folgende R Pakete in diesem Kapitel nutzen.
pacman::p_load(tidyverse, magrittr, infer, conflicted, broom)
conflicts_prefer(dplyr::filter)An der Seite des Kapitels findest du den Link Quellcode anzeigen, über den du Zugang zum gesamten R-Code dieses Kapitels erhältst.
Für unsere Demonstration des Permutationstest nutzen wir den Datensatz flea_dog_cat_length_weight.xlsx. Zum einen wollen wir einen Gruppenvergleich zwischen den Sprungweiten der Hunde- und Katzenflöhe rechnen. Also einen klassischen t-Test für einen Gruppenvergleich. Nur eben hier als einen Permutationstest. Als zweites wollen wir einen \(p\)-Wert für das Bestimmtheitsmaß \(R^2\) abschätzen. Per se gibt es keinen \(p\)-Wert für das Bestimmtheitsmaß \(R^2\), aber der Permutationstest liefert hier eine Lösung für das Problem. Daher schauen wir uns in einer simplen linearen Regression den Zusammenhang zwischen einem \(y\) und einem \(x_1\) an. Daher wählen wir aus dem Datensatz die beiden Spalten jump_length und weight. Wir wollen nun feststellen, ob es einen Zusammenhang zwischen der Sprungweite in [cm] und dem Flohgewicht in [mg] gibt. In dem Datensatz finden wir 400 Flöhe wir wählen aber nur zufällig 20 Tiere aus.
model_tbl <- read_csv2("data/flea_dog_cat_length_weight.csv") |>
select(animal, jump_length, weight) |>
filter(animal %in% c("dog", "cat")) |>
slice_sample(n = 20)Neben dem einfachen Datensatz zu den Hunde- und Katzenflöhen haben wir noch Daten zu dem Wachstum von Wasserlinsen. Wir haben einmal händisch die Dichte bestimmt duckweeds_density und einmal mit einem Sensor gemessen. Dabei sind die Einheiten der Sensorwerte erstmal egal, wir wollen aber später eben nur mit einem Sensor messen und dann auf den Wasserlinsengehalt zurückschließen. Wir haben hier eher eine Sätigungskurve vorliegen, denn die Dichte der Wasserlinsen ist ja von der Oberfläche begrenzt. Auch können sich die Wasserlinsen nicht beliebig teilen, es gibt ja nur eine begrenzte Anzahl an Ressourcen.
duckweeds_tbl <- read_excel("data/duckweeds_density.xlsx")In der Tabelle 63.2 siehst du dann einmal einen Auszug aus den Daten zu den Wasserlinsen. Es ist ein sehr einfacher Datensatz mit nur zwei Spalten. Wie du siehst, scheint sich hierbei um eine nicht lineare Regression zu handeln. Einen linearen Zusammenhang würde ich hier nicht annehmen.
| duckweeds_density | sensor |
|---|---|
| 4.8 | 0.4303 |
| 4.8 | 0.4763 |
| 4.8 | 0.4954 |
| … | … |
| 53.2 | 2.1187 |
| 53.2 | 2.1296 |
| 53.2 | 2.1246 |
Auch die Wasserlinsendaten wollen wir uns erstmal in einer Abbildung anschauen und dann sehen, ob wir eine Kurve durch die Punkte gelegt kriegen. Für die Visualisierung der Wasserlinsendaten in der Abbildung 63.10 verzichte ich einmal auf die logarithmische Darstellung. Auffällig ist erstmal, dass wir sehr viel weniger Beobachtungen und auch Dichtemesspunkte auf der \(x\)-Achse haben. Wir haben dann zu den jeweiligen Wasserlinsendichten dann drei Sensormessungen. Das könnte noch etwas herausfordernd bei der Modellierung werden.
ggplot(duckweeds_tbl, aes(duckweeds_density, sensor)) +
geom_point() +
theme_minimal() +
labs(x = "Gemessene Dichte der Wasserlinsen", y = "Sensorwert")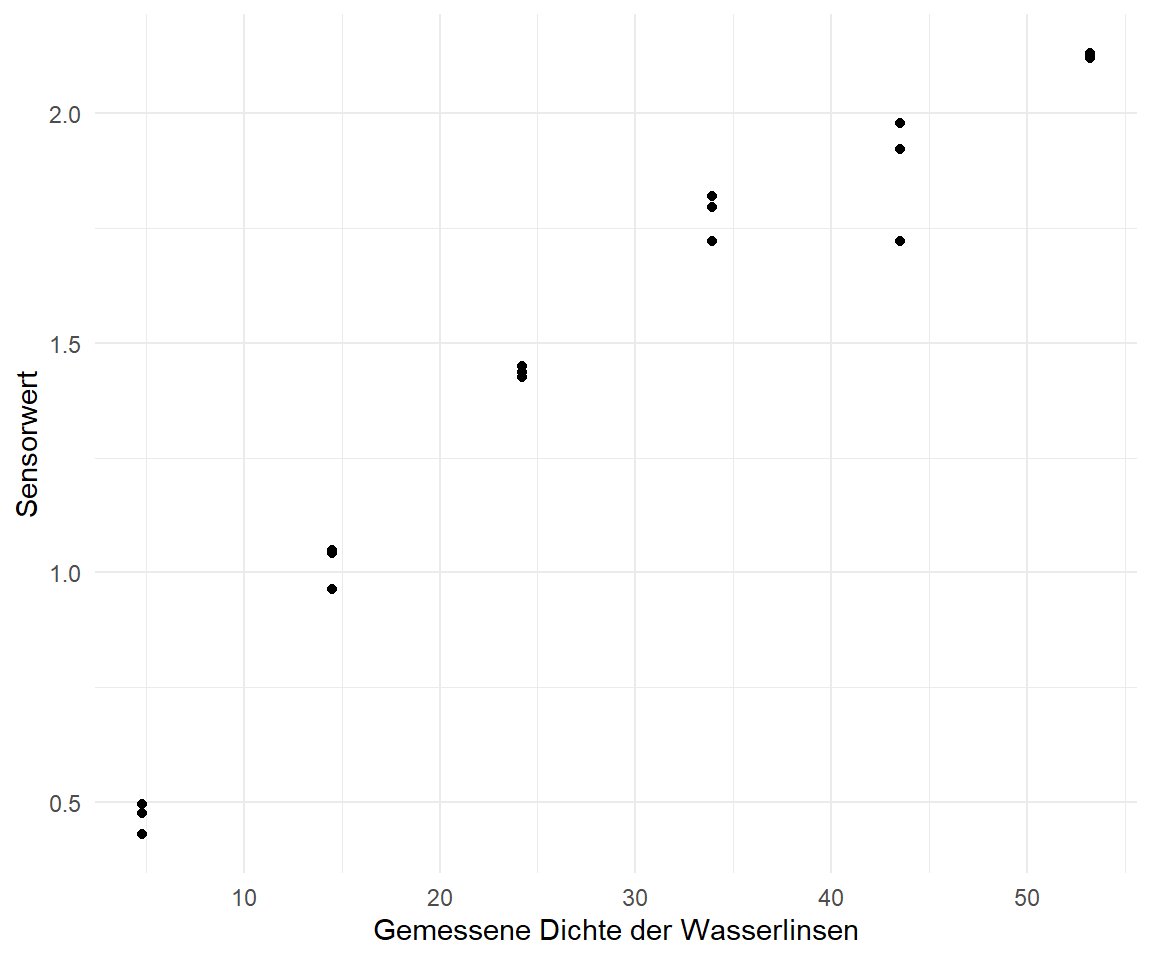
Jetzt wollen wir uns den Permutationstest einmal ganz einfach anschauen. Wir wollen einen t-Test für den Mittelwertsvergleich einmal händisch mit der Funktion sample() nachbauen. Dann schauen wir uns die Sachlage einmal in dem R Paket {infer} an.
sample()Wir wollen zuerst einmal mit einem einfachen Mittelwertsvergleich anfangen. Im Prinzip bauen wir hier kompliziert einen t-Test nach. Der t-Test testet, ob es einen signifikanten Mittelwertsunterschied gibt. Anstatt jetzt den t-Test zu rechnen, berechnen wir erstmal das \(\Delta\) und damit den Mittelwertsunterschied der Sprungweiten der Hunde- und Katzenflöhe.
model_tbl |>
group_by(animal) |>
summarise(mean_jump = mean(jump_length)) |>
pull(mean_jump) |>
diff()[1] 3.376154Wir sehen, dass die Hunde- und Katzenflöhe im Mittel einen Unterschied in der Sprungweite von \(3.38cm\) haben. Das ist der Mittelwertsunterschied in unseren beobachteten Daten.
Jetzt wollen wir einmal einen Permutationstest rechnen. Die wichtigste Funktion hierfür ist die Funktion sample(). Die Funktion sample() durchmischt zufällig einen Vektor. Einmal ein Beispiel für die Zahlen 1 bis 10, die wir in die Funktion sample() pipen.
c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) |>
sample() [1] 4 5 8 1 3 9 2 7 6 10Das gleiche Durchmischen findet auch in der Funktion mutate() statt. Wir durchwirblen einmal die Zuordnung der Level des Faktors animal zu den jeweiligen Speungweiten. Dann berechnen wir die Mittelwertsdifferenz für diesen neuen Datensatz. Das machen wir dann \(n\_sim\) gleich 1000 Mal.
n_sim <- 1000
mean_perm_tbl <- map_dfr(1:n_sim, \(x) {
mean_diff <- model_tbl |>
## Permutation Start
mutate(animal = sample(animal)) |>
## Permutation Ende
group_by(animal) |>
summarise(mean_jump = mean(jump_length)) |>
pull(mean_jump) |>
diff()
return(tibble(mean_diff))
})In der Abbildung 43.2 sehen wir die Verteilung aller Mittelwertsdifferenzen, die aus unserem permutierten Datensätzen herausgekommem sind.
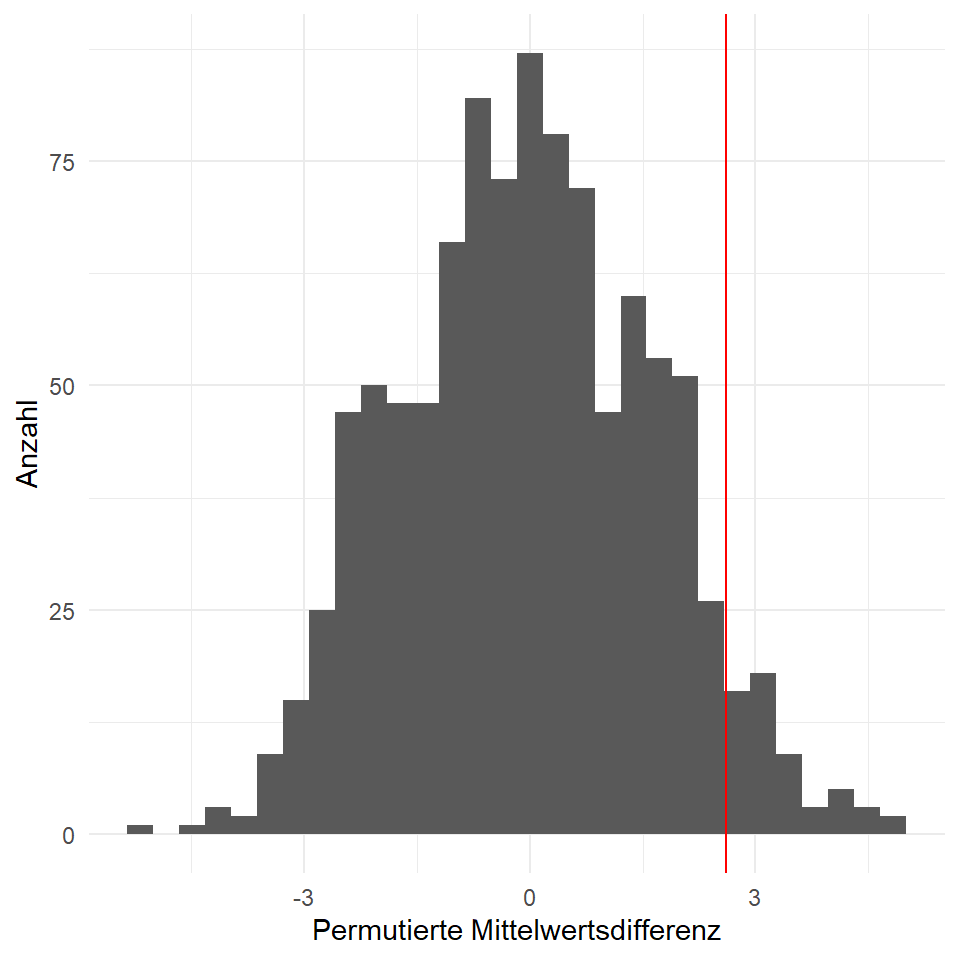
sum(mean_perm_tbl$mean_diff >= 2.6119)/n_sim[1] 0.054Ist das Gleiche als wenn wir dann den Mittelwert berechnen.
mean(mean_perm_tbl$mean_diff >= 2.6119) [1] 0.054Teilweise wird diskutiert, ob der \(p\)-Wert hier noch mal 2 genommen werden muss, da wir ja eigentlich zweiseitig Testen wollen, aber da gehen die Meinungen auseinander. Ich belasse es so wie hier.
Dann das ganze nochmal mit einem Student t-Test verglichen und wir sehen, dass wir dem \(p\)-Wert aus einem Student t-Test sehr nahe kommen. Wenn du jetzt noch die Anzahl an Simulationen erhöhen würdest, dann würde sich der \(p_{perm}\) dem \(p_{t-Test}\) immer weiter annähern.
t.test(jump_length ~ animal, data = model_tbl) |>
pluck("p.value") |>
round(3)[1] 0.049Am Ende bleibt dann die Frage, wie viele Permutationen sollen es denn sein? Auch hier sehen wir dann, dass der t-Test signifikant ist, aber der Permutationstest noch nicht. Vielleicht helfen da mehr Permutationen? Oder aber der Effekt ist dann doch zu gering. Hier musst du dann immer überlegen, ob du nicht zu sehr an dem Signifikanzniveau von 5% klebst. Am Ende muss dann der permutierte \(p\)-Wert zudammen mit dem Effekt im Kontext der Fragestellung diskutiert werden.
{infer}In dem Kapitel Testen in R nutzen wir das R Paket {infer} als eine Möglichkeit statistische Tests zu rechnen. Sonst machen wir das ja alles in diesem Teil mit den R Funktionen, die schon in {base} implementiert sind. Eine Alternative ist eben {infer}, welches auch einen Permutationstest rechnet, aber etwas sortierter, als wenn du dir alles selber bauen musst. Die Idee ist aber ähnlich wie oben. Zuerst berechnen wir uns die Teststatistik \(t_d\) nutzen dazu dann aber Funktionen und müssen diese uns nicht selber schreiben. Wir haben hier eine Menge an möglichen Teststatistiken zur Auswahl, aber ich nutze hier auch mal den Mittelwertsvergleich mit dem nachgebauten t-Test als Permutaionstest. Du könntest als statistische Maßzahl auch die Mittelwertsdifferenz wählen.
t_d <- model_tbl |>
specify(jump_length ~ animal) |>
hypothesize(null = "independence") |>
calculate(stat = "t", order = c("dog", "cat"))Nachdem wir dann die Teststatistik aus unseren Daten berechnet haben müssen wir diese Teststatistik noch zu einer Verteilung der Nullhypothese vergleichen. Dafür berechnen wir uns mit der Funktion generate() dann eintausend Teststatistiken aus einer Permutation.
null_dist_data <- model_tbl |>
specify(jump_length ~ animal) |>
hypothesize(null = "independence") |>
generate(reps = 1000, type = "permute") |>
calculate(stat = "t", order = c("dog", "cat"))In der Abbildung 43.3 siehst du dann einmal die Nullhypothese mit unserer berechneten Teststatistik. Die rote Fläche ist dann der \(p\)-Wert.
visualize(null_dist_data) +
shade_p_value(obs_stat = t_d, direction = "two-sided") +
theme_minimal() +
labs(x = "Statistik", y = "Absolute Häufigkeit")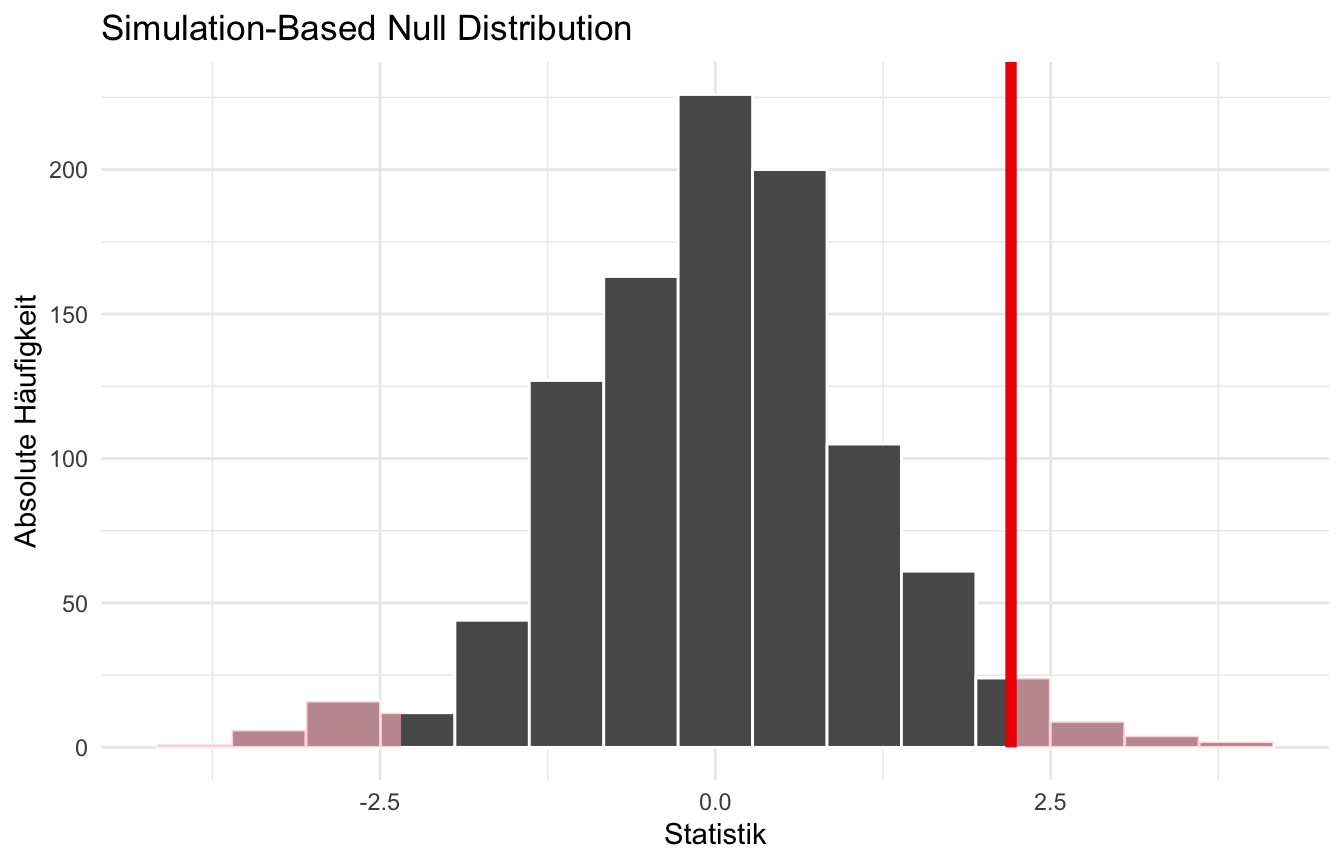
In der Abbildung können wir zwar schön die eingefärbten Flächen als die \(p\)-Werte identifizieren, aber leider wollen wir nicht nur die Werte sehen sondern auch die numerischen Werte der Flächen haben. Dafür nutzen wir dann die Funktion get_p_value(), die uns dann erlaubt aus einer Verteilung der Nullhypothese die Fläche neben der beobachteten Teststatistik \(T_D\) zu berechnen.
null_dist_data %>%
get_p_value(obs_stat = t_d, direction = "two-sided")# A tibble: 1 × 1
p_value
<dbl>
1 0.048Und am Ende kommen wir fast auf die gleichen Werte raus. Die leichte Abweichung kommt eben dann zum einen durch den Zufall und zum anderen, dass wir einmal die Mittelwertsdifferenz permutiert haben und hier dann die Teststatistik eines t-Tests.
Das vorherige Beispiel mit dem Mittelwertsvergleich war im Prinzip nur eine Fingerübung für den Ablauf. Wir können auch einfach einen t-Test rechnen und dann ist gut. Anders sieht es aus, wenn wir keinen \(p\)-Wert geliefert bekommen und auch keinen \(H_0\) Testverteilung bekannt ist um einen \(p\)-Wert zu bestimmen. Das ist der Fall bei dem Bestimmtheitsmaß \(R^2\). Wir haben hier keine Teststatistik und dadurch einen \(p\)-Wert vorliegen. Dagegen können wir dann mit einem Permutationstest was tun. Bei dem 95% Konfidenzintervall wird es dann schwieriger, hier müssen wir dann etwas anders permutieren. Wir nutzen dann die Bootstrap Konfidenzintervalle im nächsten Abschnitt.
model_tbl %$%
lm(jump_length ~ weight) |>
glance() |>
pull(r.squared)[1] 0.3000498Damit haben wir erstmal das Bestimmtheitsmaß aus unseren Daten berechnet. Jetzt stellt sich natürlich die Frage, wie wahrscheinlich ist es den dieses Bestimmtheitsmaß von 0.30 zu beobachten? Dafür lassen wir jetzt einen Permutationstest laufen in dem wir die Daten einmal durchmischen.
n_sim <- 1000
r2_perm_tbl <- map_dfr(1:n_sim, \(x) {
r2 <- model_tbl |>
## Permutation Start
mutate(weight = sample(weight)) %$%
## Permutation Ende
lm(jump_length ~ weight) |>
glance() |>
pull(r.squared)
return(tibble(r2))
})In der Abbildung 43.4 sehen wir die Verteilung aller Bestimmtheitsmaße \(R^2\), die aus unserem permutierten Datensätzen herausgekommem sind. Wir erkennen sofort, dass es wenig zufällig bessere Datensätze gibt, die ein höheres Bestimmtheitsmaße \(R^2\) erzeugen.
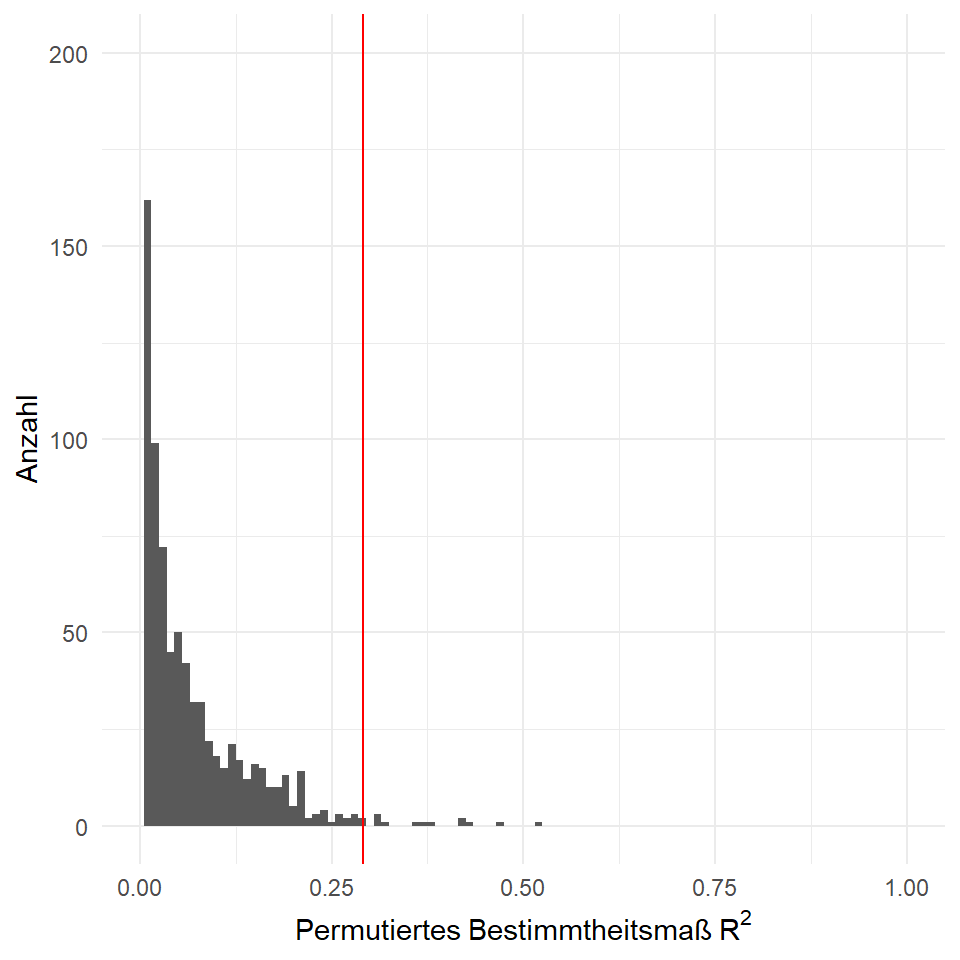
Jetzt wollen wir einmal bestimmen wie viele Bestimmtheitsmaße \(R^2\) größer sind als unser Bestimmtheitsmaß \(R^2 = 0.29\) aus den Daten.
sum(r2_perm_tbl$r2 >= 0.291164)/n_sim [1] 0.011Die Berechnung ist das Gleiche, als wenn wir den Mittelwert aus der logischen Abfrage berechnen würden.
mean(r2_perm_tbl$r2 >= 0.291164) [1] 0.011Teilweise wird diskutiert, ob der \(p\)-Wert hier noch mal 2 genommen werden muss, da wir ja eigentlich zweiseitig Testen wollen, aber da gehen die Meinungen auseinander. Ich belasse es so wie hier. Damit haben wir unseren \(p\)-Wert für das Bestimmtheitsmaß \(R^2\) mit \(0.013\). Das ist was wir wollten und somit können wir dann auch sagen, dass wir einen signifikantes Bestimmtheitsmaß \(R^2\) vorliegen haben. Was noch fehlt ist das 95% Konfidenzintervall, was wir Mithilfe des Bootstrapverfahrens berechnen wollen.
Bootstrap oder Bootstraping ist eine mächtige Methode um Vertrauensbereiche zu bestimmen. Wir wollen mehr oder minder wissen, in welchen Bereich unsere Beobachtungen fallen könnten, wenn wir unser Experiment wiederholen. Wir haben ja meistens nur einen sehr kleinen Datensatz, der nur einen Ausschnitt repräsentiert. Durch Bootstrap können wir jetzt auch ohne eine geschlossene mathematische Formel für die Konfidenzintervalle oder Prädiktionsintervalle die jeweiligen Intervalle berechnen. Dennoch musst du beachten, dass wir ein paar Beobachtungen brauchen. Wenn du nur fünf Beobachtungen pro Gruppe hast, wird es meistens sehr schnell sehr eng mit dem Bootstrapverfahren.
Wir können die Methode des Bootstraping nutzen um uns die 95% Konfidenzintervalle über eine Simulation bzw. Permutation berechnen zu lassen. Haben wir in dem Permutatiosntest noch die Spalten permutiert so permutieren wir bei dem Bootstrap-Verfahren die Zeilen. Da wir aber keinen neuen Datensatz erhalten würden, wenn wir nur die Zeilen permutieren, ziehen wir einen kleineren Datensatz mit zurücklegen. Das heißt, dass wir auch Beobachtungen mehrfach in unseren gezogenen Bootstrapdatensatz haben können. Wir nutzen in R die Funktion slice_sample() in der wir dann auswählen, dass 80% der Beobachtungen mit zurücklegen gezogen werden sollen. Das Zurücklegen können wir mit der Option replace = TRUE einstellen. Wir führen das Bootstraping dann insgesamt 1000 mal durch.
n_boot <- 1000
r2_boot_tbl <- map_dfr(1:n_boot, \(x) {
r2 <- model_tbl |>
## Bootstrap Start
slice_sample(prop = 0.8, replace = TRUE) %$%
## Bootstrap Ende
lm(jump_length ~ weight) |>
glance() |>
pull(r.squared)
return(tibble(r2))
})Nachdem wir nun unser Bootstrap gerechnet haben und eintausend Bestimmtheitsmaße bestimmt haben, können wir einfach das \(2.5\%\) und \(97.5\%\) Quantile bestimmen um unser 95% Konfidenzintervall zu bestimmen. Zwischen \(2.5\%\) und \(97.5\%\) liegen ja auch 95% der Werte der eintausend Bestimmtheitsmaße.
r2_boot_tbl %$%
quantile(r2, probs = c(0.025, 0.975)) |>
round(3) 2.5% 97.5%
0.013 0.609 Wir hatten ein Bestimmtheitsmaß \(R^2\) von \(0.30\) berechnet und können dann die untere und obere 95% Konfidenzgrenze ergänzen. Wir erhaltend dann \(0.300\, [0.016; 0.620]\), somit liegt unser beobachtetes Bestimmtheitsmaß \(R^2\) mit 95% Sicherheit zwischen \(0.016\) und \(0.620\).

Das Thema Prädiktionsintervall ist erstmal auf Stand-By gesetzt, bis mir klar ist, wohin ich mit dem Abschnitt zum Ende hin will. Zentral fehlen mir aktuell die Beratungsfälle, die mir dann auch die Probleme aufzeigen, die ich lösen will. Das Thema ist einfach zu groß. Wenn du also hier reingestolpert bist, dann schreibe mir einfach eine Mail, dann geht es auch hier weiter. Vorerst bleibt es dann bei einem Stopp.
Idee vom Botstraping und Resample Working with resampling sets
Bootstrap confidence intervals für nicht-lineare Daten für unseren Datensatz Tabelle 63.2
Understanding Prediction Intervals
Simulating Prediction Intervals
Quantile Regression Forests for Prediction Intervals
P-values for prediction intervals machen keinen Sinn