R Code [zeigen / verbergen]
pacman::p_load(tidyverse, tidymodels, magrittr, conflicted)Letzte Änderung am 23. March 2024 um 21:44:07
Dieses Kapitel dient als Einführung in die Klassifikation mit maschinellen Lernmethoden. Leider müssen wir wieder einiges an Worten lernen, damit wir überhaupt mit den Methoden anfangen können. Vieles dreht sich um die Aufbereitung der Daten, damit wir dann auch mit den Modellen anfangen können zu arbeiten. Ja ich meine wirklich Arbeiten, denn wir werden eher einen Prozess durchführen. Selten rechnet man einmal ein Modell und ist zufrieden. Meistens müssen wir noch die Modelle tunen um mehr aus den Modellen rauszuholen. Wir wollen bessere Vorhersagen mit einem kleineren Fehler erreichen. Das ganze können wir dann aber nicht in einem Schritt machen, sondern brauchen viele Schritte nacheinander. Damit müssen wir auch mir R umgehen können sonst ist der Prozess nicht mehr abzubilden.
Wir wollen folgende R Pakete in diesem Kapitel nutzen.
pacman::p_load(tidyverse, tidymodels, magrittr, conflicted)An der Seite des Kapitels findest du den Link Quellcode anzeigen, über den du Zugang zum gesamten R-Code dieses Kapitels erhältst.
In dieser Einführung nehmen wir die infizierten Ferkel als Beispiel um einmal die verschiedenen Verfahren zu demonstrieren. Ich füge hier noch die ID mit ein, die nichts anderes ist, als die Zeilennummer. Dann habe ich noch die ID an den Anfang gestellt. Wir wählen auch nur ein kleines Subset aus den Daten aus, da wir in diesem Kapitel nur Funktion demonstrieren und nicht die Ergebnisse interpretieren.
pig_tbl <- read_excel("data/infected_pigs.xlsx") |>
mutate(pig_id = 1:n(),
infected = as_factor(infected)) |>
select(pig_id, infected, age:crp) |>
select(pig_id, infected, everything()) In Tabelle 78.1 siehst du nochmal einen Auschnitt aus den Daten. Wir haben noch die ID mit eingefügt, damit wir einzelne Beobachtungen nachvollziehen können.
| pig_id | infected | age | sex | location | activity | crp |
|---|---|---|---|---|---|---|
| 1 | 1 | 61 | male | northeast | 15.31 | 22.38 |
| 2 | 1 | 53 | male | northwest | 13.01 | 18.64 |
| 3 | 0 | 66 | female | northeast | 11.31 | 18.76 |
| 4 | 1 | 59 | female | north | 13.33 | 19.37 |
| 5 | 1 | 63 | male | northwest | 14.71 | 21.57 |
| 6 | 1 | 55 | male | northwest | 15.81 | 21.45 |
| … | … | … | … | … | … | … |
| 407 | 1 | 54 | female | north | 11.82 | 21.5 |
| 408 | 0 | 56 | male | west | 13.91 | 20.8 |
| 409 | 1 | 57 | male | northwest | 12.49 | 21.95 |
| 410 | 1 | 61 | male | northwest | 15.26 | 23.1 |
| 411 | 0 | 59 | female | north | 13.13 | 20.23 |
| 412 | 1 | 63 | female | north | 10.01 | 19.89 |
Gehen wir jetzt mal die Wörter und Begrifflichkeiten, die wir für das maschinelle Lernen später brauchen einmal durch.
In diesem Teil des Skriptes werden wir wieder mit einer Menge neuer Begriffe konfrontiert. Deshalb steht hier auch eine Menge an neuen Worten drin. Leider ist es aber auch so, dass wir bekanntes neu bezeichnen. Wir tauchen jetzt ab in die Community der Klassifizierer und die haben dann eben die ein oder andere Sache neu benannt.
Kurze Referenz zu What he says?
Die gute nachticht zuerst, wir haben ein relativ festes Vokabular. Das heißt, wir springen nicht so sehr zwischen den Begrifflichkeiten wie wir es in den anderen Teilen des Skriptes gemacht haben. Du kennst die Modellbezeichnungen wie folgt.
\[ y \sim x \]
mit
Das bauen wir jetzt um. Wir nennen in dem Bereich des maschinellen Lernen jetzt das \(y\) und das \(x\) wie folgt.
Im folgenden Text werde ich also immer vom Label schreiben und dann damit das \(y\) links von dem ~ in der Modellgleichung meinen. Wenn ich dann von den Features schreibe, meine ich alle \(x\)-Variablen rechts von dem ~ in der Modellgleichung. Ja, daran muss du dich dann gewöhnen. Es ist wieder ein anderer sprachlicher Akzent in einem anderen Gebiet der Statistik.
Wenn mich etwas aus der Bahn geworfen hat, dann waren es die Terme classification und regression im Kontext des maschinellen Lernens. Wenn ich von classification schreibe, dann wollen wir ein kategoriales Label vorhersagen. Das bedeutet wir haben ein \(y\) vorliegen, was nur aus Klassen bzw. Kategorien besteht. Im Zweifel haben wir dann ein Label mit \(0/1\) einträgen. Wenn mehr Klassen vorliegen, wird auch gerne von multiclass Klassifikation gesprochen.
Dazu steht im Kontrast der Term regression. In dem Kontext vom maschinellen Lernen meint regression die Vorhersage eines numerischen Labels. Das heißt, wir wollen die Körpergröße der Studierenden vorhersagen und nutzen dazu einen regression Klassifikator. Das ist am Anfang immer etwas verwirrend. Wir unterschieden hier nur die Typen der Label, sonst nichts. Wir fassen also wie folgt zusammen.
infected sind die Ferkel infiziert \((1)\) oder nicht-infiziert daher gesund \((0)\). Du wählst dann den Modus set_mode("classification").weight. Du wählst dann den Modus set_mode("regression").Wir brauchen die Begriffe, da wir später in den Algorithmen spezifizieren müssen, welcher Typ die Klassifikation sein soll.
Wir werden uns in diesen und den folgenden Kapiteln hauptsächlich mit der Klassifikation beschäftigen. Wenn du eine Regression rechnen willst, also ein kontinuierliches Label vorliegen hast, dann musst du bei dem Modellvergleich andere Maßzahlen nehmen und auch eine ROC Kurve passt dann nicht mehr. Du findest dann hier bei den Metric types unter dem Abschnitt numeric Maßzahlen für die Güte der Regression in der Prädiktion.
Der Unterschied zwischen einer suprvised Lernmethode oder Algorithmus ist, dass das Label bekannt ist. Das heißt, dass wir in unseren Daten eine \(y\) Spalte haben an der wir unser Modell dann trainieren können. Das Modell weiß also an was es sich optimieren soll. In Tabelle 74.2 sehen wir einen kleinen Datensatz in einem supervised Setting. Wir haben ein \(y\) in den Daten und können an diesem Label unser Modell optimieren. Oft sagen wir auch, dass wir gelabelte Daten vorliegen haben. Daher haben wir eine Spalte, die unser LAbel mit \(0/1\) enthält.
| \(y\) | \(x_1\) | \(x_2\) | \(x_3\) |
|---|---|---|---|
| 1 | 0.2 | 1.3 | 1.2 |
| 0 | 0.1 | 0.8 | 0.6 |
| 1 | 0.3 | 2.3 | 0.9 |
| 1 | 0.2 | 9.1 | 1.1 |
In der Tabelle 74.3 sehen wir als Beispiel einen Datensatz ohne eine Spalte, die wir als Label nutzen können. Nazürlich haben wir in echt dann keine freie Spalte. Ich habe das einmal so gebaut, damit du den Unterschied besser erkennen kannst. Beim unsuoervised Lernen muss der Algorithmus sich das Label selber bauen. Wir müssen meist vorgeben, wie viele Gruppen wir im Label erwarten würden. Dann können wir den Algorithmus starten.
| \(x_1\) | \(x_2\) | \(x_3\) | |
|---|---|---|---|
| \(\phantom{0}\) | 0.2 | 1.3 | 1.2 |
| 0.1 | 0.8 | 0.6 | |
| 0.3 | 2.3 | 0.9 | |
| 0.2 | 9.1 | 1.1 |
Dann gibt es natürlich auch den Fall, dass wir ein paar Beobachtungen mit einem Eintrag haben und wiederum andere Beobachtungen ohne eine Eintragung. Dann sprechen wir von einem semi-supervised learning. Im Prinzip ist es ein Mischmasch aus supervised learning und dem unsupervised learning. Es gibt hier aber keine genaue Grenze wie viele gelabelete Beobachtungen zu ungelabelten Beobachtungen da sein müssen.
Wir haben sehr oft eine superised Setting in unseren Daten vorliegen. Aber wie immer, du wirst vielleicht auch Cluster bilden wollen und dann ist das unsupervised Lernen eine Methode, die du gut nutzen kannst. Am Ende müssen jeder Beobachtung ein Label zugeordnet werden. Wer das dann macht, ist wiederum die Frage.
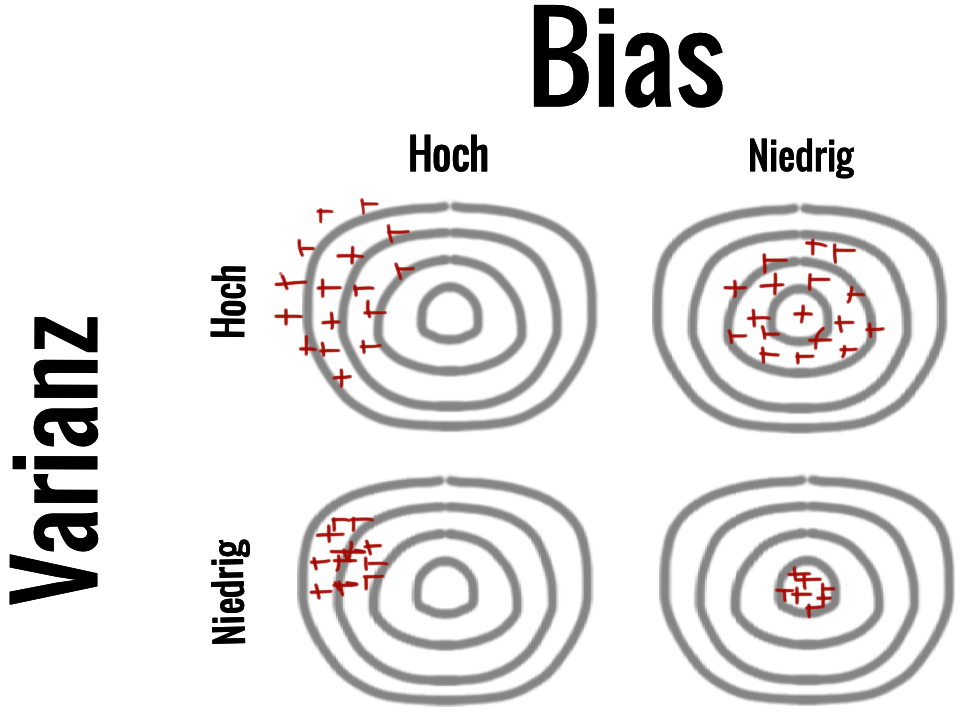
Im Bereich des maschinellen Lernens sprechen wir oft von einem Bias/Varianz Trade-off. Das heißt, wir haben zum einen eine Verzerrung (eng. Bias) in unserem Auswahlprozess des anzuwendenden Algorithmus. Zum anderen ist unser Algorithmus nur bedingt genau, das heißt wir haben auch eine Varianz die durch den Algorithmus hervorgerufen wird. Hierbei musst du dich etwas von dem Begriff Varianz im Sinne der deskriptiven Statistik lösen. Die Varianz beschreibt hier die Variabilität in der Vorhersage. Wir meinen hier schon eine Art Abweichung, aber das Wort Varianz mag hier etwas verwirrend sein. In Abbildung 74.1 sehen wir nochmal den Zusammenhang zwischen dem Bias und der Varianz.

Wir können daher wie folgt den Bias und die Varianz beschreiben. Wichtig ist hier nochmal, dass wir uns hier die Worte etwas anders benutzen, als wir es in der klassischen Statistik tun würden.
In Abbildung 74.2 shen wir den Zusammenhang zwischen Bias und Varianz an einer Dartscheibe dargestellt. Wenn wir eine hohe Varianz und einen hohen Bias haben, dann treffen wir großflächig daneben. Wenn sich der Bias verringert, dann treffen wir mit einer großen Streuung in die Mitte. Eine geringe Varianz und ein hoher Bias lässt uns präsize in daneben treffen. Erst mit einem niedrigen Bias und einer niedrigen Varianz treffen wir in die Mitte der Dartscheibe.
Der gesamte Fehler unseres Modells setzt sich dann wie folgt aus dem Bias und der Varianz zusammen. Wir können den Bias kontrollieren in dem wir verschiedene Algorithmen auf unsere Daten testen und überlegen, welcher Algorithmus am besten passt. Die Varianz können wir dadurch verringern, dass wir unsere Modelle tunen und daher mit verschiedenen Parametern laufen lassen. Am Ende haben wir aber immer einen Restfehler \(\epsilon\), den wir nicht reduzieren können. Unser Modell wird niemals perfekt zu generalisieren sein. Wenn \(\epsilon\) gegen Null laufen sollte, spricht es eher für ein Auswendiglernen des Modells als für eine gute Generalisierung.
\[ error = variance + bias + \epsilon \]
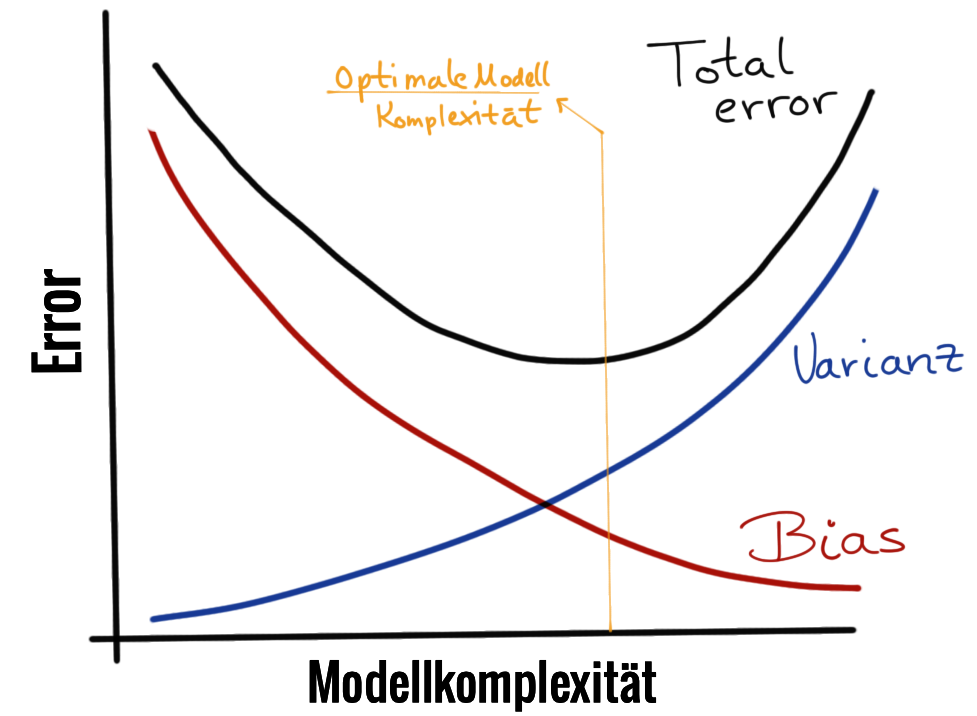
In der Abbildung 74.3 sehen wir den Zusammenhang zwischen Bias und Varianz nochmal in einer Abbildung im Zusammenhang mit der Modellkomplxität gezeigt. Je größer die Modellkomplexität wird, desto geringer wird der Bias. Dafür wird das Modell aber überangepasst und die Varianz des Modells steigt. Daher gibt es ein Optimum des total errors bei dem der Bias und Varianz jeweils Minimal sind.
Jetzt wollen wir uns den Zusammenhang zwischen Bias und Varianz nochmal an der Bilderkennung veranschaulichen. Wir nutzen dafür die Bilderkennung um Meerschweinchen und Schafe auf Bildern zu erkennen. In der Abbildung 74.4 sehen wir mich in einem Krokodilkostüm. Unser erstes Modell 1 klassifiziert mich als Meerschweinchen. Wir haben also ein sehr hohes Bias vorliegen. Ich bin kein Meerschweinchen.

In der Abbildung 74.5 (a) sehen wir ein durch Model 2 korrekt klassifiziertes Meerschweinchen. Nun hat dieses Modell 2 aber eine zu hohe Varianz. Die hohe Varianz in dem Modell 2 sehen wir in der Abbildung 74.5 (b). Das Meerschweinchen wird nicht als Meerschweinchen von Modell 2 erkannt, da es keine krausen Haare und eine andere Fellfarbe hat. Wir sind also auch mit diesem Modell 2 nicht zufrieden. Nur exakt die gleichen Meerschweinchen zu klassifizieren ist uns nicht genug.


In der Abbildung 74.5 (b) sehen wir nun unser Modell 3 mit einem niedrigen Bias und einer niedrigen Varianz. Das Modell 3 kann Schafe in einer Herde als Schafe klassifizieren. Aber auch hier sehen wir gewisse Grenzen. Das Schaf welches den Kopf senkt, wird nicht von dem Modell 3 als ein Schaf erkannt. Das kann vorkommen, wenn in dem Traingsdaten so ein Schaf nicht als Bild vorlag. Häufig brauchen wir sehr viele gute Daten. Mit guten Daten, meine ich nicht immer die gleichen Beobachtungen oder Bilder sondern eine gute Bandbreite aller möglichen Gegebenheiten.

Wir sehen also, das Thema Bias und Varianz beschäftigt uns bei der Auswahl des richtigen Modells und bei der Festlegung der Modellkomplexität. Du kannst dir merken, dass ein komplexeres Modell auf den Trainingsdaten meistens bessere Ergebnisse liefert und dann auf den Testdaten schlechtere. Ein komplexes Modell ist meist überangepasst (eng. overfitted).
In dem Kapitel 76 erfährst du, wie du mit den fehlenden Werten im maschinellen Lernen umgehst. Wir werden dort aber nicht alle Details wiederholen. In dem Kapitel 51 erfährst du dann mehr über die Hintergründe und die Verfahren zum Imputieren von fehlenden Werten.
Ein wichtiger Punkt ist bei der Nutzung von maschinellen Lernen, dass wir keine fehlenden Beobachtungen in den Daten haben dürfen. Es darf kein einzelner Wert fehlen. Dann funktionieren die Algorithmen nicht und wir erhalten eine Fehlermeldung. Deshalb ist es die erste Statistikerpflicht darauf zu achten, dass wir nicht so viele fehlenden Werte in den Daten haben. Das ist natürlich nur begrenzt möglich. Wenn wir auf die Gummibärchendaten schauen, dann wurden die Daten ja von mir mit Erhoben. Dennoch haben wir viele fehlende Daten mit drin, da natürlich Studierende immer was eingetragen haben. Wenn du wissen willst, wie du mit fehlenden Werten umgehst, dann schaue einmal dazu das Kapitel 51 an. Wir gehen hier nicht nochmal auf alle Verfahren ein, werden aber die Verfahren zur Imputation von fehlenden Werten dann am Beispiel der Gummibärchendaten anwenden. Müssen wir ja auch, sonst könnten wir auch die Daten nicht für maschinelle Lernverfahren nutzen.
In dem Kapitel 76 erfährst du, wie du die Normalisierung von Daten im maschinellen Lernen anwendest. In dem Kapitel 20 kannst du dann mehr über die Hintergründe und die Verfahren zur Normalisierung nachlesen. Wir wenden in hier nur die Verfahren an, gehen aber nicht auf die Details weiter ein.
Unter Normalisierung der Daten fassen wir eigentlich ein preprocessing der Daten zusammen. Wir haben ja unsere Daten in einer ursprünglichen Form vorliegen. Häufig ist diese Form nicht geeignet um einen maschinellen Lernalgorithmus auf diese ursprüngliche Form der Daten anzuwenden. Deshalb müssen wir die Daten vorher einmal anpassen und in eine geleiche Form über alle Variablen bringen. Was meine ich so kryptisch damit? Schauen wir uns einmal in der Tabelle 74.4 ein Beispiel für zu normalisierende Daten an.
| \(y\) | \(x_1\) | \(x_2\) | \(x_3\) |
|---|---|---|---|
| 1 | 0.2 | 1430 | 23.54 |
| 0 | 0.1 | 1096 | 18.78 |
| 1 | 0.4 | 2903 | 16.89 |
| 1 | 0.2 | 7861 | 12.98 |
Warum müssen diese Daten normalisiert werden? Wir haben mit \(x_1\) eine Variable vorliegen, die im Iterval \([0;1]\) liegt. Die Variable \(x_2\) liegt in einem zehntausendfach größeren Wertebereich. Die Werte der Variable \(x_3\) ist auch im Vergleich immer noch hundertfach im Wertebereich unterschiedlich. Dieser großen Unterschiede im Wertebereich führen zu Fehlern bei Modellieren. Wir können hierzu das Kapitel 20 betrachten. Dort werden gängige Transformationen einmal erklärt. Wir gehen hier nicht nochmal auf alle Verfahren ein, sondern konzentrieren uns auf die häufigsten Anwendungen.
recipe()Wenn wir jetzt in den folgenden Kapiteln mit den maschinellen Lernverfahren arbeiten werden, nutzen wir das R Paket {recipes} um uns mit der Funktion recipe() ein Rezept der Klassifikation zu erstellen. Warum brauchen wir das? Wir werden sehen, dass wir auf verschiedene Datensätze immer wieder die gleichen Algorithmen anwenden. Auch wollen wir eine Reihe von Vorverarbeitungsschritten (eng. preprocessing steps) auf unsere Daten anwenden. Dann ist es einfacher, wenn wir alles an einem Ort abgelegt haben. Am Ende haben wir auch verschiedene Spalten in unseren Daten. Meistens eine Spalte mit dem Label und dann sehr viele Spalten für unsere Features oder Prediktoren. Vielleicht noch eine Spalte für die ID der Beobachtungen. Das macht alles sehr unübersichtlich. Deshalb nutzen wir recipes um mehr Ordnung in unsere Klassifikation zu bekommen.
Du findest hier die Introduction to recipes und dann eine Idee wie recipes funktionieren mit Preprocess your data with recipes.
Wir gehen nun folgende vier Schritte für die Erstellung eines Modellfits mit dem R Paket {recipe} einmal durch. Am Ende haben wir dann unsere Klassifikation durchgeführt. Vorher haben wir aber unseren Algorithmus und damit unser Modell definiert und auch festgelegt, was in den Daten noch angepasst und transformiert werden soll. Alles zusammen bringen wir dann in ein workflow Objekt in dem alles, was wir mit den Daten machen wollen, gespeichert ist.
logreg_mod),pig_tbl erstellen (pig_rec),pig_wflow), undfit() trainieren.Es geht los in dem wir als erstes unser Modell definieren. Wir wollen hier aus einfachen Gründen eine logistische Regression rechnen. Dafür nutzen wir die Funktion logistic_reg() um eben eine logistische Regression zu rechnen. Es gibt aber eine große Anzahl an möglichen Implementierungen bzw. engine in R. Wir wählen hier die Implementierung des glm mit der Funktion set_engine("glm"). Faktisch haben wir hier also die Funktion glm(..., family = binomial) definiert. Nur ohne die Daten und die Formel.
Du findest auf Fitting and predicting with parsnip eine große Auswahl an implementierten Algorithmen.
logreg_mod <- logistic_reg() |>
set_engine("glm")Nachdem wir den Algorithmus für unser Modell definiert haben, wollen wir natürlich noch festlegen, was jetzt gerechnet werden soll. Unser Modell definieren wir in der Funktion recipe(). Hier haben wir definiert, was in das Modell soll. Links steht das Outcome und rechts nur ein .. Damit haben wir alle anderen Spalten als Einflussvariablen ausgewählt. Das stimmt aber nur halb. Den in dem Rezept können wir auch Rollen für unsere Variablen definieren. Mit der Funktion update_role() definieren wir die Variable pig_id als "ID". In der Klassifikation wird jetzt diese Variable nicht mehr berücksichtigt. Dann können wir noch Variablen transfomationen definieren. Wir wollen hier eine Dummykodierung für alle nominalen Prädiktoren, daher Faktoren, durchführen. Und wir wollen alle Variablen entfernen, in denen wir nur einen Eintrag haben oder eben eine Varianz von Null.
pig_rec <- recipe(infected ~ ., data = pig_tbl) |>
update_role(pig_id, new_role = "ID") |>
step_dummy(all_nominal_predictors()) |>
step_zv(all_predictors())
pig_rec── Recipe ──────────────────────────────────────────────────────────────────────── Inputs Number of variables by roleoutcome: 1
predictor: 5
ID: 1── Operations • Dummy variables from: all_nominal_predictors()• Zero variance filter on: all_predictors()Wir du siehst wird hier noch nichts gerechnet. Es gilt jetzt zu definieren was wir tun wollen. Damit wir das Rezept einfach immer wieder auf neue Daten anwenden können. Die Rollen der Variablen kannst du dir auch über die Funktion summary() wiedergeben lassen.
summary(pig_rec)# A tibble: 7 × 4
variable type role source
<chr> <list> <chr> <chr>
1 pig_id <chr [2]> ID original
2 age <chr [2]> predictor original
3 sex <chr [3]> predictor original
4 location <chr [3]> predictor original
5 activity <chr [2]> predictor original
6 crp <chr [2]> predictor original
7 infected <chr [3]> outcome originalDu siehst, dass die Variable pig_id eine ID ist und die Variable infected das Outcome darstellt. Der Rest sind die Prädiktoren mit ihren jeweiligen Typen. Wir können über die Hilfsfunktionen all_predictor() oder all_nominal_predictor() eben nur bestimmte Spalten für eine Transformation auswählen.
Im nächsten Schritt bringen wir das Modell logreg_mod und das Rezept pig_rec mit den Informationen über die Variablen und die notwendigen Transformationsschritte in einem workflow() zusammen. In diesem workflow() sind alle wichtigen Information drin und wir können den Workflow mit immer wieder neuen Subsets von unseren ursprünglichen Daten füttern.
pig_wflow <- workflow() |>
add_model(logreg_mod) |>
add_recipe(pig_rec)
pig_wflow══ Workflow ════════════════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: logistic_reg()
── Preprocessor ────────────────────────────────────────────────────────────────
2 Recipe Steps
• step_dummy()
• step_zv()
── Model ───────────────────────────────────────────────────────────────────────
Logistic Regression Model Specification (classification)
Computational engine: glm Nun heißt es noch den Wirkflow mit echten Daten zu füttern. Wir rechnen also erst jetzt mit echten Daten. Vorher aber wir nur gesagt, was wir machen wollen. Erst die Funktion fit() rechnet das Modell auf den Daten mit den Regeln in dem Rezept. Wir nehmen hier wieder unsere ursprünglichen Daten, aber du könntest hier auch den Traingsdatensatz nehmen.
pig_fit <- pig_wflow |>
fit(data = pig_tbl)
pig_fit══ Workflow [trained] ══════════════════════════════════════════════════════════
Preprocessor: Recipe
Model: logistic_reg()
── Preprocessor ────────────────────────────────────────────────────────────────
2 Recipe Steps
• step_dummy()
• step_zv()
── Model ───────────────────────────────────────────────────────────────────────
Call: stats::glm(formula = ..y ~ ., family = stats::binomial, data = data)
Coefficients:
(Intercept) age activity crp
-19.46706 0.01100 0.06647 0.96804
sex_male location_northeast location_northwest location_west
-0.51320 0.01848 -0.51613 -0.26807
Degrees of Freedom: 411 Total (i.e. Null); 404 Residual
Null Deviance: 522.6
Residual Deviance: 402.3 AIC: 418.3Wir erhalten den klassischen Fit einer logististischen Regression wieder, wenn wir die Funktion extract_fit_parsnip() verwenden. Die Funktion gibt uns dann alle Informationen wieder. Dann können wir uns über die Funktion tidy() auch eine aufgeräumte Wiedergabe erstellen lassen.
pig_fit |>
extract_fit_parsnip() |>
tidy() |>
mutate(across(where(is.numeric), round, 2),
p.value = pvalue(p.value))Warning: There was 1 warning in `mutate()`.
ℹ In argument: `across(where(is.numeric), round, 2)`.
Caused by warning:
! The `...` argument of `across()` is deprecated as of dplyr 1.1.0.
Supply arguments directly to `.fns` through an anonymous function instead.
# Previously
across(a:b, mean, na.rm = TRUE)
# Now
across(a:b, \(x) mean(x, na.rm = TRUE))# A tibble: 8 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <chr>
1 (Intercept) -19.5 3.02 -6.45 <0.001
2 age 0.01 0.03 0.4 0.690
3 activity 0.07 0.09 0.72 0.470
4 crp 0.97 0.11 8.8 <0.001
5 sex_male -0.51 0.32 -1.61 0.110
6 location_northeast 0.02 0.36 0.05 0.960
7 location_northwest -0.52 0.32 -1.6 0.110
8 location_west -0.27 0.36 -0.75 0.460 Und was ist jetzt mit der Prädiktion? Dafür können wir entweder die Funktion predict() nutzen oder aber die Funktion augment(). Mir persönlich gefällt die Funktion augment() besser, da ich hier mehr Informationen zu den vorhergesagten Werten erhalte. Ich wähle mir dann die Spalte infected aus und alle Spalten, die ein .pred beinhalten. Dann runde ich noch auf die zweite Kommastelle.
augment(pig_fit, new_data = pig_tbl) |>
select(infected, matches(".pred")) |>
mutate(across(where(is.numeric), round, 2))# A tibble: 412 × 4
infected .pred_class .pred_0 .pred_1
<fct> <fct> <dbl> <dbl>
1 1 1 0.03 0.97
2 1 0 0.73 0.27
3 0 1 0.45 0.55
4 1 1 0.31 0.69
5 1 1 0.11 0.89
6 1 1 0.13 0.87
7 1 0 0.6 0.4
8 0 0 0.66 0.34
9 1 1 0.05 0.95
10 1 1 0.21 0.79
# ℹ 402 more rowsDamit hätten wir einmal das Prinzip des Rezeptes für die Klassifikation in R durchgeführt. Dir wird das Rezept in den nächsten Kapiteln wieder über den Weg laufen. Für die Anwendung gibt es eigentlich keine schönere Art die Klassifikation sauber durchzuführen. Wir erhalten gute Ergebnisse und wissen auch was wir getan haben.