R Code [zeigen / verbergen]
pacman::p_load(tidyverse, magrittr, broom, PMCMRplus,
readxl, rstatix, conover.test,
conflicted)
conflicts_prefer(dplyr::select)
conflicts_prefer(dplyr::filter)Letzte Änderung am 11. June 2025 um 13:29:49
“If your experiment needs a statistician, you need a better experiment.” — Ernest Rutherford
Brauchen wir den Kruskal-Wallis-Test heutzutage noch? Ich persönlich weiß es nicht. Aber der Kruskal-Wallis-Test wird immer wieder verwendet und tauscht auch mal gern ein wissenschaftlichen Publikationen und Abbildungen auf. Eigentlich hat der Kruskal-Wallis-Test sich überlebt, aber als Referenz ist dieses Kapitel dann doch wichtig. Manchmal wollen wir dann aber doch den U-Test rechnen und vorher eine Art ANOVA rechnen. Dann ist der Kruskal-Wallis-Test dann doch die richtige Wahl. Am Ende musst du wieder entscheiden, ob der Kruskal-Wallis-Test zu deiner wissenschaftlichen Fragestellung passt.
Der U-Test in dem vorherigen Kapitel vergleicht nur zwei Gruppen miteinander. Wir haben zwar einen Faktor vorliegen, aber der Faktor hat nur zwei Level oder Gruppen. Wir vergleichen also die Sprungweite für Hunde- und Katzenflöhe. Wenn wir jetzt aber noch die Fuchsflöhe hinzunehmen, dann müssen wir den Kruskal-Wallis-Test nutzen. Faktisch ist der Kruskal-Wallis-Test das gleiche wie die einfaktorielle ANOVA. Den der Kruskal-Wallis-Test kann nur mit einem Faktor arbeiten. Wenn du mehr über die Hintergründe und weitere Informationen zu dem nichtparametrischen Testen brauchst, dann schaue auch einmal im Kapitel zum U-Test rein. Hier werde ich dann die Hintergründe sehr kurz halten.
In der folgenden Abbildung habe ich dir aus der wissenschaftlichen Publikation The fading impact of lockdowns: A data analysis of the effectiveness of Covid-19 travel restrictions during different pandemic phases von Smyth (2022) mitgebracht. Wenn wir die beiden oberen Abbildungen anschauen, sehen wir dort die Mediane des Restriction Levels als Barplot und in den unteren beiden Abbildungen die Mittelwerte des Mobility drops als Barplots. Leider alle Abbildungen ohne Fehlerbalken. Wir konzentrieren und hier auf die Titel der beiden obigen Abbildungen wo wir die p-Werte eines Kruskal-Wallis-Test finden. Ohne die Fehlerbalken lässt sich der p-Wert schlecht mit den Barplots in Einklang bringen. Ja, die Mediane sind unterschiedlich, da die Säulen unterschiedlich sind.
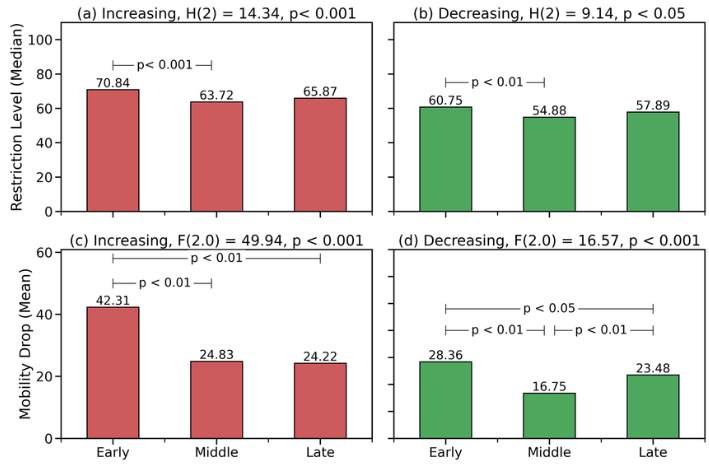
Anscheinend ist nach Smyth (2022) der Messwert Restriction Levels nicht normalverteilt und wird deshalb mit nichtparametrischen Methoden bearbeitet. Das heißt, der Kruskal-Wallis-Test ist im Prinzip die einfaktorielle ANOVA für nicht-normalverteilte Daten. Was ist jetzt der Unterschied zwischen einem Kruskal-Wallis-Test und einer einfaktoriellen ANOVA? Die ANOVA vergleicht die Mittelwerte mehrerer Normalverteilungen, also zum Beispiel die Verteilung der Sprungweiten der Hundeflöhe gegen die Verteilung der Sprungweiten der Katzenflöhe sowie gegen die Verteilung der Sprungweiten von Fuchsflöhen. Dazu nutzt die ANOVA die Abweichungsquadrate von den Mittelwerten. Damit nutze die ANOVA Parameter einer Verteilung und somit ist der ANOVA ein parametrischer Test. Wie wir hier sehen, ist der Unterschied manchmal sehr subtil.
Die asymptotische Effizienz des Kruskal-Wallis-Tests liegt im Vergleich zur einfaktoriellen ANOVA bei \(0.955\). Das heißt, dass der Kruskal-Wallis-Test \(4.5\%\) mehr Fallzahl benötigt um die gleiche Effizienz zu haben wie eine einfaktorielle ANOVA, deren Annahmen an die Normalverteilung und Varianzhomogenität erfüllt werden. Daher sind die beiden Tests in der Effizienz fast gleich. Der van-der-Waerden Test erreicht bei der Verletzung der Annahmen an eine einfaktorielle ANOVA sogar eine höhere Effizienz und ist daher vorzuziehen. Der Begriff der Effizienz ist hier natürlich etwas wage, aber du kannst den Begriff für dich auch vereinfacht als gleiche statistische Eigenschaften was die Signifikanz angeht lesen.
Der Kruskal-Wallis-Test ist die nicht-parametrische Variante der einfaktoriellen ANOVA in dem wir die Zahlen in Ränge umwandeln, also sortieren, und mit den Rängen der Zahlen rechnen. Die deskriptiven Maßzahlen wären dann Median, Quantile und Quartile. Das heißt wir vergleichen mit dem Kruskal-Wallis-Test die Mediane mehrer Gruppen miteinander. Wir wollen also wissen, ob sich die Mediane zwischen den Sprungweiten von Hunde-, Katzen- und Fuchsflöhen unterscheiden. Wie wir gleich noch sehen werden ist die Hypothese etwas komplexer, aber für dieses Kapitel kann es auch reichen zu wissen, dass wir als Lageparameter die Mediane vergleichen.
Es gibt eine Vielzahl von Methoden, die sich mit der nichtparametrischen Varianzanalyse beschäftigen. Alleine das R Paket {PMCMRplus} hat dutzende Methoden implementiert. Hier muss und will ich dann auch stoppen, da es dann wirklich das Kapitel sprengt. Ich habe versucht dir die besten Methoden rauszusuchen. Wenn ich was besseres finde, dann ergänze ich die Methoden zukünftig.
Wenn du mehr Lesen willst dann gibt es nur die Referenz schlechthin von Heiko Lübsen, die ich dir hier gerne einmal mit angebe. Hier wurde dann einmal in epischer BReite alles einmal durchgkaut, was es so an Literatur gibt.
Wir wollen folgende R Pakete in diesem Kapitel nutzen.
pacman::p_load(tidyverse, magrittr, broom, PMCMRplus,
readxl, rstatix, conover.test,
conflicted)
conflicts_prefer(dplyr::select)
conflicts_prefer(dplyr::filter)An der Seite des Kapitels findest du den Link Quellcode anzeigen, über den du Zugang zum gesamten R-Code dieses Kapitels erhältst.
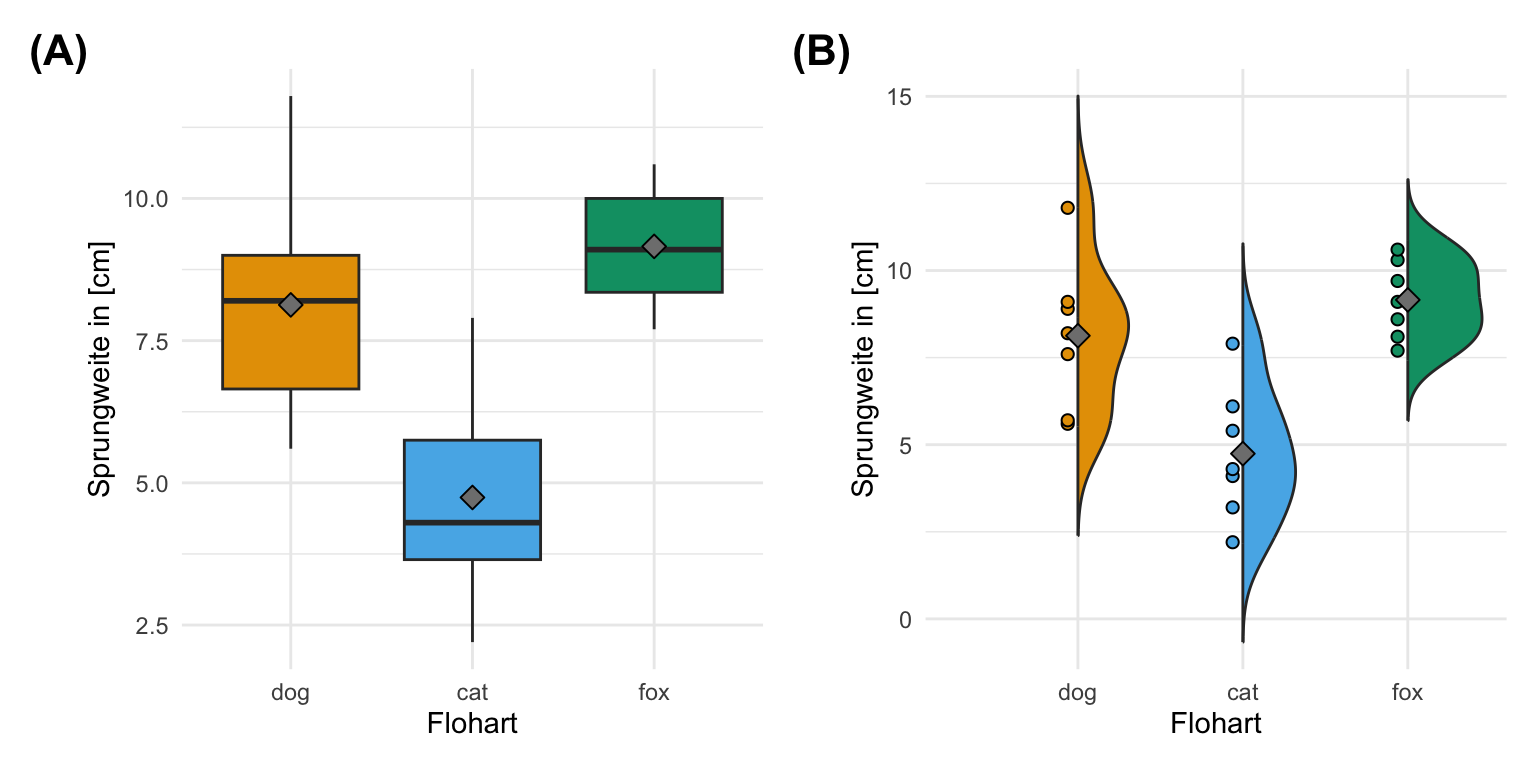
In den folgenden Abschnitten zur Anwendung des Kruskal-Wallis-Test brauchen wir dann einen Datensatz. Der Datensatz den wir verwenden wollen beschreibt Hunde-, Katzen- und Fuchsflöhe, die springen und deren Sprungweite dann gemessen wurde. Wir haben hier verschiedene Flöhe vorliegen, die nur einmal springen. Wir haben hier die Sprungweite in [cm] von Hunde-, Katzen- und Fuchsflöhe für jeweils sieben Flöhe gemessen. Unser Faktor ist hierbei also die Flohart animal in den Daten. Entweder ein Hundefloh oder eben ein Katzenfloh oder ein Fuchsfloh. Wir wollen jetzt wissen, ob sich die Floharten hinsichtlich ihrer Sprungweite jump_length unterscheiden.
fac1_tbl <- read_xlsx("data/flea_dog_cat_fox.xlsx") |>
select(animal, jump_length) |>
mutate(animal = as_factor(animal))In der folgenden Tabelle siehst du dann einmal einen Auszug aus den Daten der Sprungweiten für die drei Floharten. Dabei ist dann die Spalte animal unser Faktor über den wir den Gruppenvergleich für die Sprungweiten jump_length als Messwert rechnen wollen.
| animal | jump_length |
|---|---|
| dog | 5.7 |
| dog | 8.9 |
| dog | 11.8 |
| ... | ... |
| fox | 10.6 |
| fox | 8.6 |
| fox | 10.3 |
Dann wollen wir uns auch einmal die Daten visualisieren. Ich nutze dazu dann einmal den Boxplot sowie den Violinplot. Die Daten sehen einigermaßen normalverteilt aus, so dass wir hier auch eine einfaktorielle ANOVA rechnen könnten. Wie immer geht es hier auch um die Demonstration der Algorithmen, also nutzen wir hier auch diese Daten für den Kruskal-Wallis-Test. Der Kruskal-Wallis-Test funktioniert auch super auf normalverteilten Daten.
Der Kruskal-Wallis-Test betrachtet die Gruppen und Ränge um einen Unterschied nachzuweisen. Daher haben wir in der Nullhypothese als Gleichheitshypothese folgende Prosahypothese. Mehr zu den Hintergründen der Hypothesen in einem nichtparametrischen Test findest du im Kapitel zum U-Test.
\(H_0:\) Die Gruppen werden aus Populationen mit identischen Verteilungen entnommen. Typisch ist, dass die Stichprobenpopulationen stochastische Gleichheit aufweisen. Daher sind häufig die Mediane gleich.
Die Alternative lautet, dass sich mindestens ein paarweiser Vergleich unterschiedet. Hierbei ist das mindestens ein Vergleich wichtig. Es können sich alle Gruppen unterschieden oder eben nur ein Paar. Wenn ein Kruskal-Wallis-Test die \(H_0\) ablehnt, also ein signifikantes Ergebnis liefert, dann wissen wir nicht, welche Gruppen sich unterscheiden und einen entsprechenden Post-hoc Test rechnen.
\(H_A:\) Die Gruppen werden aus Populationen mit unterschiedlichen Verteilungen entnommen. Typischerweise weist eine der untersuchten Populationen eine stochastische Dominanz auf. Die Mediane sind häufig verschieden.
Wir schauen uns jetzt einmal den Kruskal-Wallis-Test theoretisch an bevor wir uns mit der Anwendung des Kruskal-Wallis-Test in R beschäftigen.
Wir können den Kruskal-Wallis-Test natürlich auch händisch rechnen. Wir machen das händische Rechnen jetzt nur um uns nochmal klar werden zu lassen wie die Analyse durchläuft. Für die Anwendung des Kruskal-Wallis-Test ist es natürlich nicht notwendig händisch den Test rechnen zu können. Ich zeige dir die Anwendung einmal im Standardpaket {stats} sowie der Implementierung in {coin} und {rstatix}. Das letzte Paket {rstatix} ruft im Prinzip die Funktionen aus {coin} auf hat aber eine bessere Implementierung, die sich einfacher nutzen lässt. Immer häufiger ist der Kruskal-Wallis-Test nur als zusätzliche Funktion implementiert wie im R Paket {ggpubr} um dann einer Abbildung den p-Wert für den Kruskal-Wallis-Test zu ergänzen.
Der Kruskal-Wallis-Test berechnet die H Teststatistik auf den Rängend der Daten. Es gibt genau so viele Ränge wie es Beobachtungen im Datensatz gibt. Wir haben \(n = 21\) Beobachtungen in unseren Daten zu der Sprungweite in [cm] von den Hunde-, Katzen- und Fuchsflöhen. Somit müssen wir auch einundzwanzig Ränge vergeben.
Die Tabelle 37.2 zeigt das Vorgehen der Rangvergabe. Wir sortieren als erstes das \(y\) aufsteigend. In unserem Fall ist das \(y\) die Sprunglänge. Dann vergeben wir die Ränge jweiles zugehörig zu der Position der Sprunglänge und der Tierart. Abschließend addieren wir die Rangsummmen für cat, dog und fox zu den Rangsummen \(R_{cat}\), \(R_{dog}\) und \(R_{fox}\).
cat, dog und fox haben jeweils die entsprechenden Ränge zugeordnet bekommen und die Rangsummen wurden berechnet
| Rank | animal | jump_length | Ränge cat |
Ränge dog |
Ränge fox |
|---|---|---|---|---|---|
| 1 | cat | 2.2 | 1 | ||
| 2 | cat | 3.2 | 2 | ||
| 3 | cat | 4.1 | 3 | ||
| 4 | cat | 4.3 | 4 | ||
| 5 | cat | 5.4 | 5 | ||
| 6 | dog | 5.6 | 6 | ||
| 7 | dog | 5.7 | 7 | ||
| 8 | cat | 6.1 | 8 | ||
| 9 | dog | 7.6 | 9 | ||
| 10 | fox | 7.7 | 10 | ||
| 11 | cat | 7.9 | 11 | ||
| 12 | fox | 8.1 | 12 | ||
| 13 | dog | 8.2 | 13 | ||
| 14 | fox | 8.6 | 14 | ||
| 15 | dog | 8.9 | 15 | ||
| 16 | dog | 9.1 | 16 | ||
| 17 | fox | 9.1 | 17 | ||
| 18 | fox | 9.7 | 18 | ||
| 19 | fox | 10.3 | 19 | ||
| 20 | fox | 10.6 | 20 | ||
| 21 | dog | 11.8 | 21 | ||
| Rangsummen | \(R_{cat} = 34\) | \(R_{dog} = 87\) | \(R_{fox} = 110\) | ||
| Gruppengröße | 7 | 7 | 7 |
Die Summe aller Ränge ist \(1+2+3+...+21 = 231\). Wir überprüfen nochmal die Summe der Rangsummen als Gegenprobe \(R_{cat} + R_{dog} + R_{fox} = 231\). Das ist identisch, wir haben keinen Fehler bei der Rangaufteilung und der Summierung gemacht.
Die Formel für die H Statistik sieht wie die U Statistik ein wenig wild aus, aber wir können eigentlich relativ einfach alle Zahlen einsetzen. Dann musst du dich etwas konzentrieren bei der Rechnung.
\[ H = \cfrac{12}{N(N+1)}\sum_{i=1}^k\cfrac{R_i^2}{n_i}-3(N+1) \]
mit
Wir setzen nun die Zahlen ein. Da wir ein balanciertes Design vorliegen haben sind die Fallzahlen \(n_1 = n_2 = n_3 = 7\) gleich.
\[ H_{D} = \cfrac{12}{21(21+1)}\left(\cfrac{34^2}{7}+\cfrac{87^2}{7}+\cfrac{110^2}{7}\right)-3(21+1) = 11.27 \]
Der kritische Wert für die H Statistik ist \(H_{\alpha = 5\%} = 5.99\). Bei der Entscheidung mit der berechneten Teststatistik \(H_{D}\) gilt, wenn \(H_{D} \geq U_{\alpha = 5\%}\) wird die Nullhypothese (H\(_0\)) abgelehnt. Da in unserem Fall das \(H_{D}\) mit \(11.27\) größer ist als das \(H_{\alpha = 5\%} = 5.99\) können wir die Nullhypothese ablehnen. Wir haben ein signifkianten Unterschied in den Medianen zwischen den beiden Tierarten im Bezug auf die Sprungweite in [cm] von Flöhen.
Die Nutzung des Kruskal-Wallis-Test in R ist relativ einfach mit der Funktion kruskal.test(). Wir nutzen die Formelschreibweise um das Modell zu definieren und können dann schon die Funktion nutzen.
kruskal.test(jump_length ~ animal, data = fac1_tbl)
Kruskal-Wallis rank sum test
data: jump_length by animal
Kruskal-Wallis chi-squared = 11.197, df = 2, p-value = 0.003704Mit einem p-Wert von \(0.0037\) können wir die Nullhypothese ablehnen, da der p-Wert kleiner ist als das Signifikanzniveau \(\alpha\) von 5%. Wir haben mindestens einen medianen Unterschied zwischen den Sprungweiten der Hunde-, Katzen- und Fuchsflöhen.
In dem R Paket {coin} können wir die Funktion kruskal_test() nutzen. Da der Funktionsname gleich der Funktion in {rstatix} ist, muss ich hier nochmal extra mit :: sagen, welches Paket genutzt werden soll. Ansonsten ist das Ergebnis das gleiche Ergebnis wie vorher.
coin::kruskal_test(jump_length ~ animal, data = fac1_tbl)
Asymptotic Kruskal-Wallis Test
data: jump_length by animal (dog, cat, fox)
chi-squared = 11.197, df = 2, p-value = 0.003704Mit einem p-Wert von \(0.0037\) können wir die Nullhypothese ablehnen, da der p-Wert kleiner ist als das Signifikanzniveau \(\alpha\) von 5%. Wir haben mindestens einen medianen Unterschied zwischen den Sprungweiten der Hunde-, Katzen- und Fuchsflöhen.
In dem R Paket {rstatix} können wir die Funktion kruskal_test() nutzen. Da der Funktionsname gleich der Funktion in {coin} ist, muss ich hier nochmal extra mit :: sagen, welches Paket genutzt werden soll. Der Vorteil der Funktion aus {ratatix} ist, dass wir hier auch den Pipe-Operator nutzen können.
rstatix::kruskal_test(jump_length ~ animal, data = fac1_tbl)# A tibble: 1 × 6
.y. n statistic df p method
* <chr> <int> <dbl> <int> <dbl> <chr>
1 jump_length 21 11.2 2 0.0037 Kruskal-WallisMit einem p-Wert von \(0.0037\) können wir die Nullhypothese ablehnen, da der p-Wert kleiner ist als das Signifikanzniveau \(\alpha\) von 5%. Wir haben mindestens einen medianen Unterschied zwischen den Sprungweiten der Hunde-, Katzen- und Fuchsflöhen.
Soweit so gut. Im Prinzip produzieren alle drei Funktionen und Implementierungen den gleichen p-Wert. Daher kannst du dir hier aussuchen was du verwenden willst. Ich nehme dann immer häufiger {rstatix} oder aber die Implementierung direkt in {ggpubr}. Es kommt hier dann imm darauf an was du zeigen möchtest. Am Ende ist es vermutlich nicht ganz so wichtig, ob deine Abbildung einen p-Wert für den Kruskal-Wallis-Test hat oder nicht.
Für die Betrachtung der Effektgröße in einem Kruskal-Wallis-Test nutzen wir das R Paket {rstatix} und die darin enthaltende Funktion kruskal_effsize(). Wir berechnen hierbei analog zu einfaktoriellen ANOVA den \(\eta^2\) Wert.
fac1_tbl |> kruskal_effsize(jump_length ~ animal)# A tibble: 1 × 5
.y. n effsize method magnitude
* <chr> <int> <dbl> <chr> <ord>
1 jump_length 21 0.511 eta2[H] large Das \(\eta^2\) nimmt Werte von 0 bis 1 an und gibt, multipliziert mit 100, den Prozentsatz der Varianz der durch die \(x\) Variable erklärt wird. In unserem Beispiel wird 51.1% der Varianz in de Daten durch den Faktor animal erklärt. Das R Paket {effectsize} liefert mit der Funktion kendalls_w() eine weitere Möglichkeit sich den Effektschätzer berechnen zu lassen. Die Funktion interpret_kendalls_w() liefert dann auch gleich die Regel für die Bewertung nach.
Kommen wir jetzt nochmal zu den Alternativen zu dem Kruskal-Wallis-Test. Wir auch schon bei dem U-Test stelle ich hier einmal die parametrische Variante vor. Wir transformieren einfahc unseren Messwert in einen Rang und dann rechnen wir ganz normal eine einfaktorielle ANOVA auf den rangtransformierten Daten. Das klingt einfsch und ist es auch.
Dann hier noch schnell die parametrische Lösung des Problems mit der einfaktoriellen ANOVA. Wir wollen jetzt einfach nur unsere Messwerte einmal Rangtransformieren. Dafür nutze ich entweder die Funktion rank() oder aber die folgende Funktion signed_rank(), wenn ich negative Werte in meinen Messungen erwarte.
signed_rank <- function(x) sign(x) * rank(abs(x))Konkret habe ich meine Sprungweiten der Hunde-, Katzen- und Fuchsflöhe. Jetzt mutiere ich die Sprungweite über die Funktion signed_rank() in Ränge und nutze diese Spalte dann für die ANOVA. Ich nutze hier die Funktion anova_test() aus dem R Paket {rstatix}, da ich dann einfacher pipen kann. Wir können die Nullhypothese ablehnen, wir haben einen signifikanten Unterschied in den Sprungweiten.
fac1_tbl |>
mutate(ranked_jump_length = signed_rank(jump_length)) |>
anova_test(ranked_jump_length ~ animal) ANOVA Table (type II tests)
Effect DFn DFd F p p<.05 ges
1 animal 2 18 11.446 0.00062 * 0.56Warum jetzt auf einmal so ein seltsamer Test von dem ich bis vor kurzem auch noch nichts gehört hatte? Ich bin in den Arbeiten von Lüpsen & Rechenzentrum (2015) und Luepsen (2018) darauf gestoßen. Der Vorteil des Van-der-Waerden Tests besteht darin, dass der Test im Vergleich zur einfaktoriellen ANOVA gut abschneidet, wenn die Stichproben der Gruppenpopulation normalverteilt sind, und im Vergleich zum Kruskal-Wallis-Test, wenn die Stichproben nicht normalverteilt sind. Das klingt doch super. Deshalb hier auch die Implementierung in der Formelschreibweise aus dem R Paket {PMCMRplus}.
vanWaerdenTest(jump_length ~ animal, data = fac1_tbl)
Van der Waerden normal scores test
data: jump_length by animal
Van der Waerden chi-squared = 10.662, df = 2, p-value = 0.004839Mit einem p-Wert von \(0.0048\) können wir auch hier die Nullhypothese ablehnen, da der p-Wert kleiner ist als das Signifikanzniveau \(\alpha\) von 5%. Wir haben mindestens einen medianen Unterschied zwischen den Sprungweiten der Hunde-, Katzen- und Fuchsflöhen. Die Hypothesen sind im Prinzip gleich wie bei dem Kruskal-Wallis-Test.
Eigentlich habe ich ja alles in das Kapitel zum Post-hoc Test ausgelagert. Ich möchte aber nicht bei einem sehr langen Kapitel enden, wo ich jeden Test erkläre den es gibt. Das ist nicht Ziel dieses Kochbuchs. Deshalb hier die multiplen Tests für den Kruskal-Wallis-Pfad. Damit hast du dann alles konsistent in einem Rutsch. Bitte beachte hier auch den biologischen interpretierbaren Effektschätzer, den du dann in der Nichtparametrik so nicht vorliegen hast.
Am Ende gibt es dann drei ausgewählte Post-hoc Tests von mir. Du findest in der Arbeit Multiple Mittelwertvergleiche - parametrisch und nichtparametrisch - sowie Adjustierungen mit praktischen Anwendungen mit R und SPSS noch eine fast vollumfängliche Betrachtung. Ich würde dir es aber nicht empfehlen alles zu lesen, das habe ich schon gemacht und dann eben etwas ausgewählt.
Das R Paket {conover.test} hat die Funktion conover.test() implementiert. Mehr Informationen findest du auch unter Conover-Iman test. Der Conover-Test ist eigentlich die bessere Variante als der Dunn’s Test, der auch häufig empfohlen wird. Er ist eine Verallgemeinerung des Kruskal-Wallis-Tests und basiert auf der t-Verteilung und ist eine Alternative zum Dunn-Test, der auf der z-Verteilung basiert. Der Conover-Iman Test kann eine größere statistische Power als der Dunn-Test haben. Ich habe hier als Adjustierung die Bonferronikorrektur gewählt.
conover.test(fac1_tbl$jump_length, fac1_tbl$animal,
method = "bonferroni") Kruskal-Wallis rank sum test
data: x and group
Kruskal-Wallis chi-squared = 11.1965, df = 2, p-value = 0
Comparison of x by group
(Bonferroni)
Col Mean-|
Row Mean | cat dog
---------+----------------------
dog | -3.296167
| 0.0060*
|
fox | -4.651600 -1.355433
| 0.0003* 0.2881
alpha = 0.05
Reject Ho if p <= alpha/2Der Conover–Iman Test liefert uns auch gleich noch den Kruskal-Wallis-Test mit. Der p-Wert ist nur stark gerundet und daher hier dann schon Null. Dann erhalten wir noch für jeden paarweisen Vergleich den Mittelwertsunterschied und den p-Wert. Signifikante Unterschiede werden dann zusätzlich noch mit einem Stern * markiert. Bei sehr vielen Gruppen wird dann die Darstellung etwas wirr, aber das ist dann wieder ein anderes Problem und Thema.
Wir haben dann in dem R Paket {rstatix} die Implementierung des Dunn’s Test mit der Funktion dunn_test(). Der Dunn’s Test ist meiner Meinung nach nicht die erste Wahl. Wir haben hier etwas ungünstige statistische Eigenschaften beim Dunn’s Test. Deshalb sehe ich den Test als veraltet an und würde den Test eher auf den Friedhof schicken. Sehe den Test hier als Referenz, damit du den Test auch findest.
fac1_tbl |> dunn_test(jump_length ~ animal)# A tibble: 3 × 9
.y. group1 group2 n1 n2 statistic p p.adj p.adj.signif
* <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <chr>
1 jump_length dog cat 7 7 -2.31 0.0212 0.0423 *
2 jump_length dog fox 7 7 0.948 0.343 0.343 ns
3 jump_length cat fox 7 7 3.25 0.00114 0.00342 ** Beim Dunn’s Test sind die Entscheidungen ähnlich wie bei dem Conover–Iman Test nur das die p-Werte etwas größer sind. Das würde bei kleineren Effekten der Sprungweitenunterschiede dann doch was ausmachen. Hier haben wir Glück, dass der Dunn’s Test dann doch noch alles findet.
Nach der Publikation von Luepsen (2018) ist der van-der-Waerden Test die beste Variante für den multiplen Vergleich. Der Vorteil des van-der-Waerden Tests besteht darin, dass der Test im Vergleich zur einfaktoriellen ANOVA gut abschneidet, wenn die Stichproben der Gruppenpopulation normalverteilt sind, und im Vergleich zum Kruskal-Wallis-Test, wenn die Stichproben nicht normalverteilt sind. Ich würde daher den van-der-Waerden Test als Post-hoc Test verwenden.
vanWaerdenAllPairsTest(jump_length ~ animal, data = fac1_tbl,
p.adjust.method = "bonferroni")
Pairwise comparisons using van der Waerden normal scores test for
multiple comparisons of independent samplesdata: jump_length by animal dog cat
cat 0.0127 -
fox 0.8831 0.0011
P value adjustment method: bonferroniWir erhalten auch hier die gleichen Entscheidungen wir bei den anderen beiden Post-hoc Tests. Ich habe mich dann hier auch für die Bonferronikorrektur entschieden. Die Ergebnisse sind hier etwas sparsamer, am Ende erhälst du dann hier nur die adjustierten p-Werte und das war es dann.