R Code [zeigen / verbergen]
olymp_tbl <- read_excel("data/animal_olympics.xlsx")Letzte Änderung am 04. November 2025 um 21:04:42
“The average teacher explains complexity; the gifted teacher reveals simplicity.” — Robert Breault
Wir brauchen immer mal wieder etwas komplexere Daten und deshalb habe ich die Datensätze, die häufiger vorkommen, hier einmal gebündelt. Die komplexeren Datensätze werden dann in den Kapiteln zur Regressionsanalyse und Modellierung genutzt. Dafür brauchen wir dann größere Datensätze an denen wir dann auch was erkennen können.

Wir beschäftigen uns ja zu Beginn mit den Sprungweiten von verschiedenen Floharten. Hier habe ich dann nochmal einen anderen Datensatz mitgebracht. In meinem kleinen Datensatz zur Olympiade der Tiere habe ich die wissenschaftliche Arbeit von Yang et al. (2014) als Grundlage genommen. Wir haben hier das Körpergewicht und die durchschnittliche Dauer des Urinierens vorliegen. Diese Liste habe ich dann einmal erweitert. Ich habe dann noch die Sprungweiten und Sprunghöhen der Tiere ergänzt, soweit es mit möglich war die entsprechenden Informationen zu finden.
olymp_tbl <- read_excel("data/animal_olympics.xlsx")In der folgenden Tabelle findest du dann einmal einen Auszug aus den Daten. Ich habe hier einige Leerstellen, da ich nicht zu allen Tierarten die entsprechenden Informationen vorliegen habe. Dann müssen wir eben mit Leerstellen leben.
| animal | sex | mass | duration | jump_height | jump_length |
|---|---|---|---|---|---|
| Bat | F | 0.03 | 0.32 | ||
| Bison | M | 907 | 20 | 180 | 214 |
| Cat | F | 5 | 18 | 150 | 183 |
| Chihuahua | M | 3 | 4 | 40 | 76.2 |
| Cow | 510 | 21 | 150 | ||
| Dog | M | 71 | 24 | 150 | 121 |
| … | … | … | … | … | … |
| Rhino | M | 2200 | 17 | ||
| Squirrel | 19 | 5 | 150 | 243 | |
| Tapir | F | 318 | 9 | ||
| Tapir | M | 318 | 59 | ||
| White horse | F | 470 | 10 | ||
| Zebra | M | 430 | 8 | 80 |
Die Daten beinhalten dann die folgenden erhobenen Variablen. Teilweise sind die Informationen dann aus Yang et al. (2014) und Cadiergues et al. (2000) entnommen. In anderen Fällen habe ich das Internet befragt und die erste Information, die valide klang, übernommen.
Dann können wir uns auch einmal einen Auszug aus den Daten in der folgenden Abbildung anschauen. Ich habe mit hier für den Zusammenhang zwischen der Dauer des Urinierens und dem Körpergewicht sowie dem Zusammenhang zwischen der Sprunghöhe und dem Sprunggewicht entschieden.
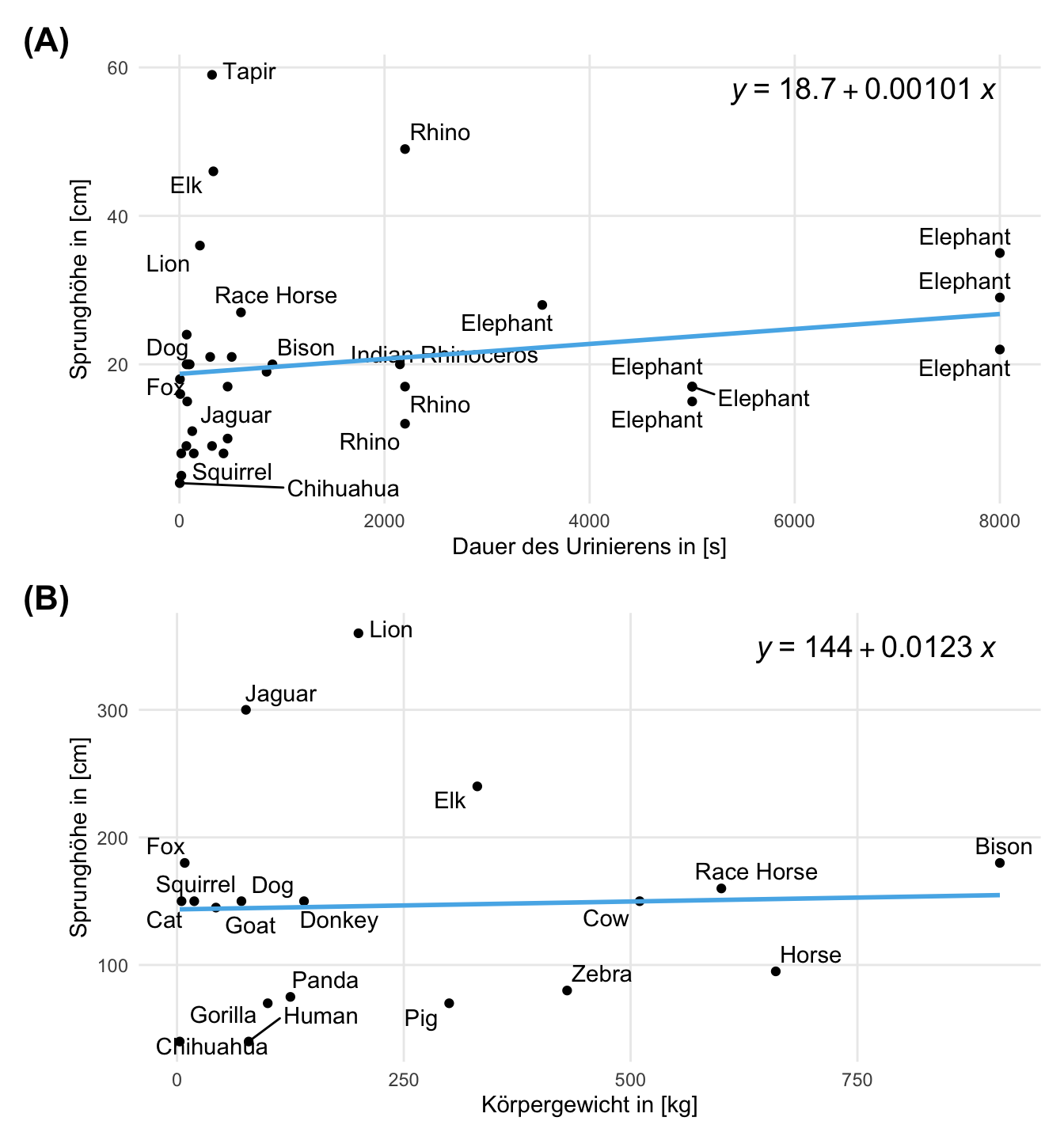
Wir nutzen den Datensatz in verschiedenen Kapiteln.
Du findest die Datei animal_olympics.xlsx auf GitHub jkruppa.github.io/data/ als Excel Datei.
Neben den klassischen Daten aus dem Bereich der Agrawissenschaften sammle ich auch so den ein oder anderen Datensatz. Hier haben wir dann einmal den Datensatz zu den Fahrrädern in Osnabrück vorliegen. An einer Straße in Osnabrück werden die Fahrräder gezählt. Genau genommen sind es nicht nur Fahrräder sondern auch Autos oder andere Gefährte, die die Fahrradstraße entlangfahren. Aber das ist nur eine Kleinigkeit. Ich habe immer mal wieder in den Jahren 2024 und 2025 die Informationen von der Säule unregelmäßig erhoben. Dazu dann noch die Temperatur und auch ob es geregnet hat.
bikes_tbl <- read_excel("data/bikes_count.xlsx") |>
mutate(jahr = as_factor(jahr))Dann können wir uns die Daten einmal in der folgenden Tabelle anschauen. Wir müssen dann vermutlich später nochmal ran und die Uhrzeiten und die Werte für das Datum richtig formatieren. Aber du siehst hier schonmal einen guten Überblick.
| jahr | datum | uhrzeit | tag | tag_im_Jahr | kw | anzahl_tag | anzahl_cum | regen | temp |
|---|---|---|---|---|---|---|---|---|---|
| 2024 | 2024-09-16 | 1899-12-31 08:19:00 | 2024-09-16 | 260 | 38 | 187 | 771920 | 0 | 16 |
| 2024 | 2024-09-17 | 1899-12-31 08:22:00 | 2024-09-17 | 261 | 38 | 311 | 774630 | 0 | 15 |
| 2024 | 2024-09-18 | 1899-12-31 08:18:00 | 2024-09-18 | 262 | 38 | 206 | 777100 | 0 | 16 |
| 2024 | 2024-09-19 | 1899-12-31 08:18:00 | 2024-09-19 | 263 | 38 | 180 | 779552 | 0 | 15 |
| … | … | … | … | … | … | … | … | … | … |
| 2025 | 2025-10-24 | 1899-12-31 09:09:00 | 2025-10-24 | 297 | 43 | 459 | 1071789 | 0 | 11 |
| 2025 | 2025-10-29 | 1899-12-31 14:34:00 | 2025-10-29 | 302 | 44 | 2423 | 1087757 | 0 | 12 |
| 2025 | 2025-11-03 | 1899-12-31 08:17:00 | 2025-11-03 | 307 | 45 | 730 | 1102181 | 0 | 11 |
| 2025 | 2025-11-04 | 1899-12-31 15:45:00 | 2025-11-04 | 308 | 45 | 3032 | 1109169 | 0 | 15 |
Dann können wir auch einmal schnell die Anzahl an Fahrrädern zum Ende des Jahres 2024 vorhersagen.
lm(anzahl_cum ~ tag_im_Jahr, filter(bikes_tbl, jahr == 2024)) |>
predict(tibble(tag_im_Jahr = 366)) 1
989322.1 Genauso machen wir das dann auch einmal für das Jahr 2025 und erkennen sogleich, dass es hier schon einiges an Unterschied gibt.
lm(anzahl_cum ~ tag_im_Jahr, filter(bikes_tbl, jahr == 2025)) |>
predict(tibble(tag_im_Jahr = 365)) 1
1341154 In der folgenden Abbildung habe ich dir dann mal den Verlauf über den Herbst der Jahre dargestellt. Neben der unterschiedlichen Steigung sehen wir auch, dass wir wirklich im Jahr 2025 die eine Million Fahrräder locker erreicht haben. Das Ganze war dann im Jahr 2024 sehr viel knapper. Am Ende des Jahres fahren dann einfach keine Fahrräder mehr.
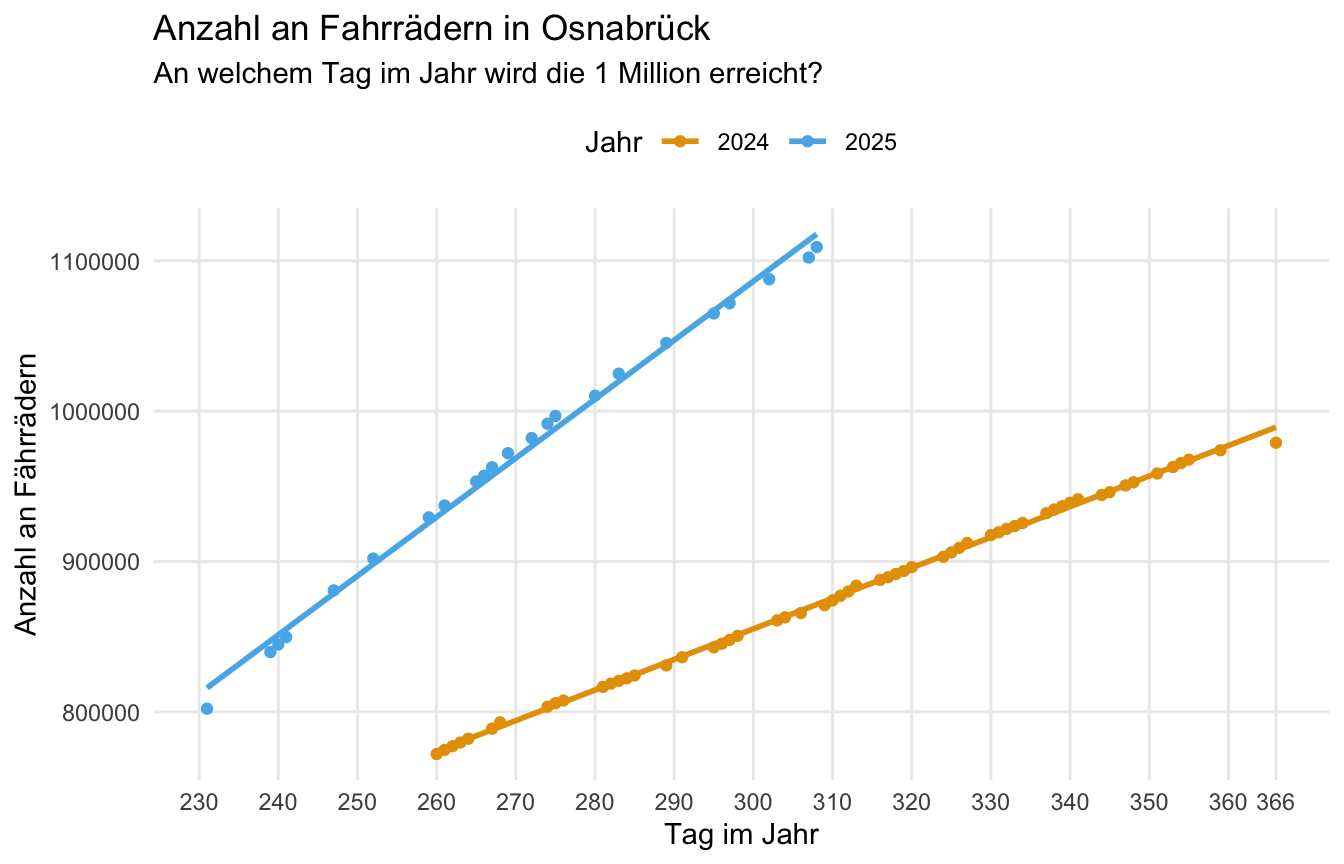
Dann schauen wir uns noch einen Datensatz von hohen Bäumen an. Wir haben hier einen sehr simplen Datensatz, aber wir können hier gut den Zusammenhang zwischen einem statistischen und mathematischen Modell diskutieren. Den es gibt ja einen Zusammenhang zwischen den Umfang und dem Volumen eines Objektes oder eben Baum. Wir finden den Datensatz im R Paket {tidymodels}.
pacman::p_load(tidymodels)Ein bisschen mehr kannst du auch Von dem Umfang von Bäumen woanders lesen. Wir konzentrieren uns hier einmal auf die Daten und nutzen diese Daten später in anderen Kapiteln. Der Baumumfang circumfence ist gemessen in Zoll, die Höhe height ist gemessen in Fuß und Volumen volume ist gemessen in Kubikfuß. Das ist grässlich und deshalb alles einmal in Zentimeter umgerechnet. Das ist dann auch sinnvoller. Wir laden also einmal die Daten und mutieren dann die Spalten entsprechend.
data(trees)
trees_tbl <- trees |>
as_tibble() |>
set_names(c("circumfence", "height", "volume")) |>
mutate(circumfence_cm = circumfence * 2.54,
height_cm = height * 30.48,
volume_cm3 = volume * 30.48^3) |>
mutate_all(round, 2) |>
select(circumfence_cm, height_cm, volume_cm3)In der folgenden Tabelle ist dann nochmal ein Auszug aus den Daten zu sehen. Ich habe dann mal schnell auf zwei Kommastellen gerundet.
| circumfence_cm | height_cm | volume_cm3 |
|---|---|---|
| 21.08 | 2133.6 | 291663.52 |
| 21.84 | 1981.2 | 291663.52 |
| 22.35 | 1920.24 | 288831.84 |
| 26.67 | 2194.56 | 464396.28 |
| 27.18 | 2468.88 | 532356.72 |
| 27.43 | 2529.84 | 557841.88 |
| … | … | … |
| 43.94 | 2468.88 | 1568753.3 |
| 44.45 | 2499.36 | 1577248.36 |
| 45.47 | 2438.4 | 1650872.16 |
| 45.72 | 2438.4 | 1458317.6 |
| 45.72 | 2438.4 | 1444159.18 |
| 52.32 | 2651.76 | 2180397.19 |
Dann bietet sich auch hier einmal eine Abbildung an. Ich habe dann einmal den Zusammenhang zwischen den Baumumfang und der Baumhöhe dargestellt und die Volumen einmal als größer werdende Kreise. Später dann mehr zu der Modellierung dieser Daten in den entsprechenden Kapiteln oder aber YouTube Videos.
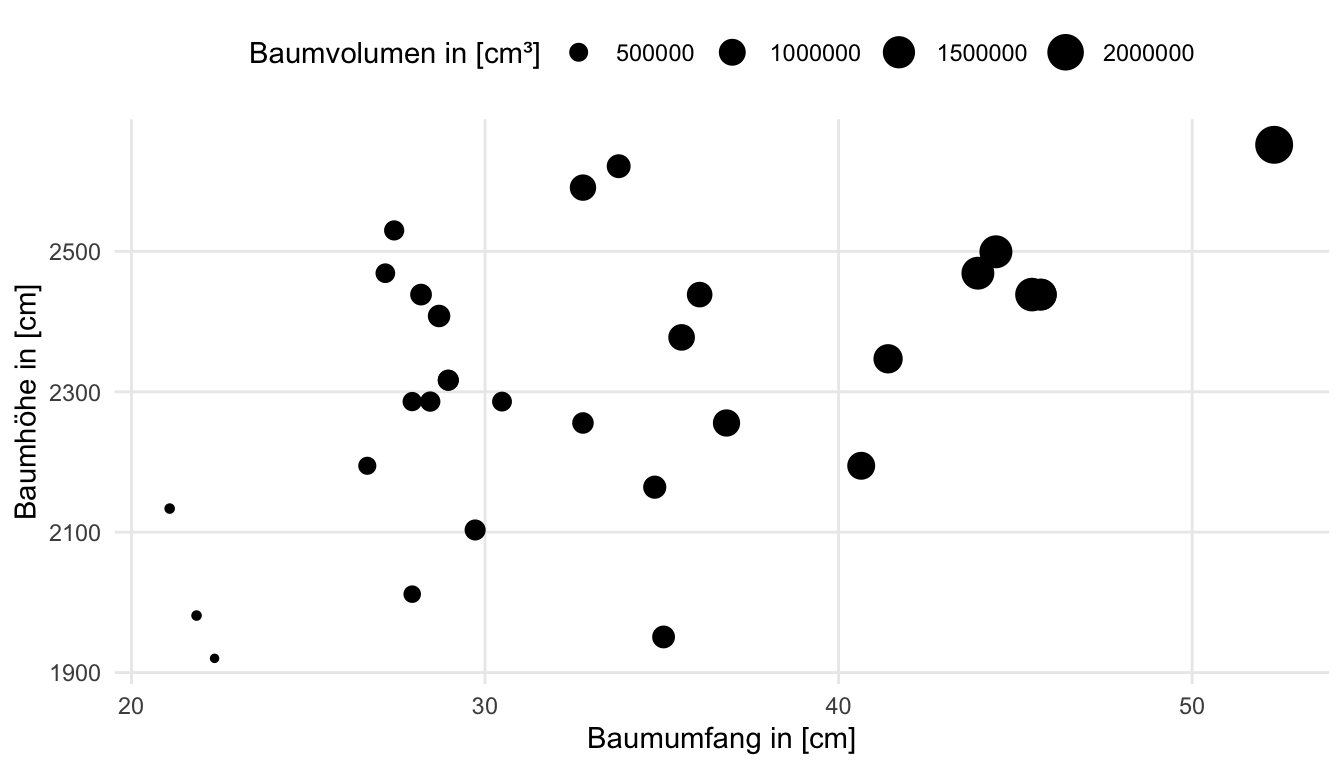
Als ich über den Artikel Stop using iris als Datensatz gestolpert bin, habe ich mich dann auch entschlossen einmal den Datensatz {palmerpenguins} aus dem gleichnamigen Paket zu nutzen und vorzustellen. Wir laden also einmal das R Paket und dann die Daten.
pacman::p_load(palmerpenguins)Da die Daten schon aufgearbeitet sind, brauchen wir hier nicht viel machen. Es gibt noch eine rohe Version der Daten, wo dann mehr gemacht werden muss, aber mir reicht hier die aufgearbeitete Version allemal.
data("penguins")
penguins_tbl <- penguinsDann kommen wir auch schon zu dem Auszug aus den Daten. Wir haben hier zwei Faktoren mit jeweils drei Arten und zwei Inseln vorliegen sowie eben einiges an numerischen Messwerten für die Pinguine. Dazu kommt noch das Geschlecht und eben auch das Messjahr. Hier können wir dann einiges an Gruppenvergleichen entsprechend rechnen.
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | year |
|---|---|---|---|---|---|---|---|
| Adelie | Torgersen | 39.1 | 18.7 | 181 | 3750 | male | 2007 |
| Adelie | Torgersen | 39.5 | 17.4 | 186 | 3800 | female | 2007 |
| Adelie | Torgersen | 40.3 | 18 | 195 | 3250 | female | 2007 |
| Adelie | Torgersen | 2007 | |||||
| Adelie | Torgersen | 36.7 | 19.3 | 193 | 3450 | female | 2007 |
| Adelie | Torgersen | 39.3 | 20.6 | 190 | 3650 | male | 2007 |
| … | … | … | … | … | … | … | … |
| Chinstrap | Dream | 45.7 | 17 | 195 | 3650 | female | 2009 |
| Chinstrap | Dream | 55.8 | 19.8 | 207 | 4000 | male | 2009 |
| Chinstrap | Dream | 43.5 | 18.1 | 202 | 3400 | female | 2009 |
| Chinstrap | Dream | 49.6 | 18.2 | 193 | 3775 | male | 2009 |
| Chinstrap | Dream | 50.8 | 19 | 210 | 4100 | male | 2009 |
| Chinstrap | Dream | 50.2 | 18.7 | 198 | 3775 | female | 2009 |
Adler sind großartige Tiere und deshalb wollen wir auch Adler bemessen. Dann haben wir einen Datensatz mit dem wir arbeiten und uns die Tiere genauer anschauen können. Wir laden wieder unser Paket und dann die entsprechenden Daten.
pacman::p_load(Stat2Data)Hier nutze ich die Daten wie sie eben vorliegen. Später können wir dann noch die Datenaufarbeiten und schöner machen. Hier eben einmal die rohen Daten zu den Adlern.
data("Hawks")
hawks_tbl <- Hawks |>
as_tibble()In der folgenden Tabelle siehst du einmal die Daten zu den Adlern. Wir haben hier eine ganze Reihe an Variablen von Zeitangaben bis hin dem Alter als Faktor in adult und juvenile. Dann haben wir noch einiges gemessen, wenn es möglich war. Wir haben hier also spannende Daten mit einiges an fehlenden Daten vorliegen.
| Month | Day | Year | CaptureTime | ReleaseTime | BandNumber | Species | Age | Sex | Wing | Weight | Culmen | Hallux | Tail | StandardTail | Tarsus | WingPitFat | KeelFat | Crop |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 9 | 19 | 1992 | 13:30 | 877-76317 | RT | I | 385 | 920 | 25.7 | 30.1 | 219 | |||||||
| 9 | 22 | 1992 | 10:30 | 877-76318 | RT | I | 376 | 930 | 221 | |||||||||
| 9 | 23 | 1992 | 12:45 | 877-76319 | RT | I | 381 | 990 | 26.7 | 31.3 | 235 | |||||||
| 9 | 23 | 1992 | 10:50 | 745-49508 | CH | I | F | 265 | 470 | 18.7 | 23.5 | 220 | ||||||
| 9 | 27 | 1992 | 11:15 | 1253-98801 | SS | I | F | 205 | 170 | 12.5 | 14.3 | 157 | ||||||
| 9 | 28 | 1992 | 11:25 | 1207-55910 | RT | I | 412 | 1090 | 28.5 | 32.2 | 230 | |||||||
| … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … | … |
| 11 | 18 | 2003 | 14:07 | 1207-53144 | RT | I | 366 | 805 | 23.5 | 25.7 | 217 | 222 | 1.5 | 0.25 | ||||
| 11 | 18 | 2003 | 14:44 | 1177-04777 | RT | I | 380 | 1525 | 26 | 27.6 | 224 | 227 | 3 | 0 | ||||
| 11 | 19 | 2003 | 10:18 | 803-05985 | SS | I | F | 190 | 175 | 12.7 | 15.4 | 150 | 153 | 4 | 0 | |||
| 11 | 19 | 2003 | 12:02 | 1807-53145 | RT | I | 360 | 790 | 21.9 | 27.6 | 211 | 215 | 2 | 0 | ||||
| 11 | 20 | 2003 | 9:56 | 1177-04778 | RT | I | 369 | 860 | 25.2 | 28 | 207 | 210 | 2 | 0 | ||||
| 11 | 20 | 2003 | 13:30 | 1207-53145 | RT | A | 199 | 1290 | 28.7 | 32.1 | 222 | 226 | 1 | 0 |
Im Folgenden schauen wir uns den anonymisierten Datensatz zu einer Ferkelinfektion an. Wir haben verschiedene Gesundheitsparameter an den Ferkeln gemessen und wollen an diesen Rückschließen, ob diese Gesundheitsparameter etwas mit der Infektion zu tun haben. Insgesamt haben wir gut \(400\) Ferkel an vier verschiedenen Orten in Niedersachsen gemessen.
| age | sex | location | activity | crp | frailty | bloodpressure | weight | creatinin | infected |
|---|---|---|---|---|---|---|---|---|---|
| 61 | male | northeast | 15.31 | 22.38 | robust | 62.24 | 19.05 | 4.44 | 1 |
| 53 | male | northwest | 13.01 | 18.64 | robust | 54.21 | 17.68 | 3.87 | 1 |
| 66 | female | northeast | 11.31 | 18.76 | robust | 57.94 | 16.76 | 3.01 | 0 |
| 59 | female | north | 13.33 | 19.37 | robust | 56.15 | 19.05 | 4.35 | 1 |
| 63 | male | northwest | 14.71 | 21.57 | robust | 55.38 | 18.44 | 5.27 | 1 |
| 55 | male | northwest | 15.81 | 21.45 | robust | 60.29 | 18.42 | 4.78 | 1 |
| … | … | … | … | … | … | … | … | … | … |
| 54 | female | north | 11.82 | 21.5 | pre-frail | 55.32 | 19.75 | 3.92 | 1 |
| 56 | male | west | 13.91 | 20.8 | frail | 58.37 | 17.28 | 7.44 | 0 |
| 57 | male | northwest | 12.49 | 21.95 | pre-frail | 56.66 | 16.86 | 2.44 | 1 |
| 61 | male | northwest | 15.26 | 23.1 | robust | 57.18 | 15.55 | 3.08 | 1 |
| 59 | female | north | 13.13 | 20.23 | robust | 56.64 | 18.6 | 3.41 | 0 |
| 63 | female | north | 10.01 | 19.89 | robust | 57.46 | 18.6 | 4.2 | 1 |
Auch hier haben wir nur eingeschränkte Informationen zu den erhobenen Variablen. Daher müssen wir schauen, dass die Variablen in etwa Sinn ergeben.
Wir nutzen den Datensatz unter anderem in der logistischen Regression in Kapitel 59.
Du findest die Datei infected_pigs.xlsx auf GitHub jkruppa.github.io/data/ als Excel Datei.
In der folgenden Datentabelle wollen wir uns die Anzahl an Hechten in verschiedenen nordamerikanischen Flüßen anschauen. Jede Zeile des Datensatzes steht für einen Fluss. Wir haben dann in jedem Fluss die Anzahl an Hechten gezählt und weitere Flussparameter erhoben. Wir fragen uns, ob wir anhand der Flussparameter eine Aussage über die Anzahl an Hechten in einem Fluss machen können. Die Daten zu den langnasigen Hechten stammt von Salvatore S. Mangiafico - An R Companion for the Handbook of Biological Statistics.
| stream | longnose | area | do2 | maxdepth | no3 | so4 | temp |
|---|---|---|---|---|---|---|---|
| basin_run | 13 | 2528 | 9.6 | 80 | 2.28 | 16.75 | 15.3 |
| bear_br | 12 | 3333 | 8.5 | 83 | 5.34 | 7.74 | 19.4 |
| bear_cr | 54 | 19611 | 8.3 | 96 | 0.99 | 10.92 | 19.5 |
| beaver_dam_cr | 19 | 3570 | 9.2 | 56 | 5.44 | 16.53 | 17 |
| beaver_run | 37 | 1722 | 8.1 | 43 | 5.66 | 5.91 | 19.3 |
| bennett_cr | 2 | 583 | 9.2 | 51 | 2.26 | 8.81 | 12.9 |
| … | … | … | … | … | … | … | … |
| seneca_cr | 23 | 18422 | 9.9 | 45 | 1.58 | 8.37 | 20.1 |
| south_br_casselman_r | 2 | 6311 | 7.6 | 46 | 0.64 | 21.16 | 18.5 |
| south_br_patapsco | 26 | 1450 | 7.9 | 60 | 2.96 | 8.84 | 18.6 |
| south_fork_linganore_cr | 20 | 4106 | 10 | 96 | 2.62 | 5.45 | 15.4 |
| tuscarora_cr | 38 | 10274 | 9.3 | 90 | 5.45 | 24.76 | 15 |
| watts_br | 19 | 510 | 6.7 | 82 | 5.25 | 14.19 | 26.5 |
Wie immer haben wir nicht so viele Informationen über die Daten vorliegen. Einiges können wir aber aus den Namen der Spalten in dem Datensatz ableiten. Wir haben in verschiedenen Flüssen die Anzahl an Hechten gezählt und noch weitere Flussparameter gemessen. Ein wenig müssen wir hier auch unsere eigene Geschichte spinnen.
Wir nutzen den Datensatz unter anderem in der Poisson Regression in Kapitel 56.
Du findest die Datei longnose.csv auf GitHub jkruppa.github.io/data/ als Csv Datei.
Im Folgenden schauen wir uns die Daten eines Pilotprojektes zum Anbau von Kichererbsen in Brandenburg an. Wir haben an verschiedenen anonymisierten Bauernhöfen Kichererbsen angebaut und das Trockengewicht als Endpunkt bestimmt. Darüber hinaus haben wir noch andere Umweltparameter erhoben und wollen schauen, welche dieser Parameter einen Einfluss auf das Trockengewicht hat.
| temp | rained | location | no3 | fe | sand | forest | dryweight |
|---|---|---|---|---|---|---|---|
| 25.26 | high | north | 5.56 | 4.43 | 63 | >1000m | 253.42 |
| 21.4 | high | northeast | 9.15 | 2.58 | 51.17 | <1000m | 213.88 |
| 27.84 | high | northeast | 5.57 | 2.19 | 55.57 | >1000m | 230.71 |
| 24.59 | low | north | 7.97 | 1.47 | 62.49 | >1000m | 257.74 |
| 26.51 | low | north | 6.29 | 4.3 | 59.09 | >1000m | 242.03 |
| 22.3 | low | northeast | 6.69 | 4.78 | 58.72 | >1000m | 236.98 |
| … | … | … | … | … | … | … | … |
| 25.04 | low | northeast | 5.64 | 2.22 | 59.47 | >1000m | 240.28 |
| 28.77 | low | west | 6.55 | 2.26 | 61.11 | >1000m | 268.39 |
| 25.47 | low | north | 6.92 | 3.18 | 64.55 | <1000m | 268.58 |
| 29.04 | low | north | 5.64 | 2.87 | 53.27 | >1000m | 236.07 |
| 24.11 | high | northeast | 4.31 | 3.66 | 63 | <1000m | 259.82 |
| 28.88 | low | northeast | 7.92 | 2 | 65.75 | >1000m | 274.75 |
Es ist ja schon fast Mode, aber auch hier haben wir wenig bis gar keine Informationen zu den erhobenen Variablen. Daher machen wir das Beste aus der Sachlage und überlegen uns was hier passen könnte.
Wir nutzen den Datensatz unter anderem in der Gaussian Regression in Kapitel 55.
Du findest die Datei chickpeas.xlsx auf GitHub jkruppa.github.io/data/ als Excel Datei.