
53 Modellieren in R
Letzte Änderung am 07. November 2025 um 11:17:04
“Ich weiß nicht weiter; Ich will mich verändern; Doch wie fang ich’s an?” — Tocotronic, Die Unendlichkeit
Dieses Startkapitel gibt dir nochmal eine Übersicht über das statistische Modellieren in R. Hier liegt vor allem der Fokus auf R. Es gibt eben eine Reihe von zusätzlichen Pakten, die es dir erlauben noch mehr aus einem statistischen Modell rauszuholen. Am Ende wurde es mir dann aber zu detailliert alle Pakete in jedem Kapitel vorzustellen und anzuwenden. Das ist auch nicht immer sinnig. Häufig willst du erstmal nur das Modell rechnen. Später kannst du dann noch tiefer ins Detail gehen oder aber komplexere Verfahren nutzen. Ich tue mich also etwas schwer dieses Kapitel einzuordnen. Entweder packen wir es ans Ende vom statistischen Modellieren und schauen, dann wie wir alles in R machen. Das steht aber etwas der Intuition entgegen, dass wir in jedem Kapitel zum statistischen Modellieren ja schon was selber machen wollen. In R gibt es dazu dann noch sehr gute Pakete, die das Modellieren sehr viel einfacher machen, dabei dann aber auch für den Anfänger etwas komplexer sind. Ich habe mich daher entschieden, diese aktuelle und komplexere Modellierung einmal hier am Anfang vorzustellen und in den folgenden Kapiteln teilweise darauf zu verweisen, wenn ich es sinnig fand. Du kannst alle Modelle auf althergebrachte Art und Weise rechnen ohne was zu verpassen. Aber manchmal möchte man dann auch effizienter Modellieren. Dafür ist dann dieses Kapitel da: Eine erweiterte Idee von der statistischen Modellierung zu erlangen. Fangen wir also erstmal mit der naheliegenden Frage an.
53.1 Allgemeiner Hintergrund

Modelle sollten visualisiert werden. Oder andersherum, wenn wir etwas in Zusammenhang setzen wollen, dann sollten wir diesen Zusammenhang auch darstellen können. Manchmal scheint es nicht möglich, aber dann lohnt sich das ausprobieren und nachdenken, wie Variablen miteinander visualisiert werden können. Oder wie wir allgemeiner wie folgt als eine Art Flowchart schreiben können.
Das R Paket {modelbased} schlägt folgenden Weg für das Modellieren vor. Dabei sind es nur fünf Schritte, die wir iterativ durchführen können.
- Zeichne zuerst, was du visualisieren möchtest. Nutze hierzu auch erstmal nur eine Skizze und danach die echten Daten.
- Erstelle ein Modell für deine Visualisierung.
- Wähle das beste Modell nach statistischen Maßzahlen aus.
- Visualisiere das beste Modell in deiner Visualisierung. Bringe also Modell und Daten zusammen.
- Untersuchen die Parameter des Modells um mehr über die Zusammenhänge zu erfahren.
In dem Buch Statistical Thinking for the 21st Century — Practical statistical modeling? findest du dann nochmal einen anderen Prozess vorgeschlagen. Die Idee ist ähnlich, aber ergänzt noch um ein paar Punkte.
- Formuliere deine wissenschaftliche Fragestellung.
- Identifiziere oder sammle die entsprechenden Daten.
- Bereite die Daten für die statistische Analyse vor.
- Bestimme das geeignete statistische Modell. Nehme im Zweifel mehrere Modelle in deine Betrachtung.
- Passen das statistische Modell an die Daten an.
- Überprüfe das statistische Modell kritisch, um sicherzustellen, dass das Modell richtig passt.
- Teste die Hypothese und quantifizieren mögliche Effektgrößen.
Am Ende bauen wir immer ein Modell der Wirklichkeit aus unseren Daten. Wir messen selten alles was es zu messen gibt oder wert wäre gemessen zu werden. Daher sind unsere Modelle der Daten immer falsch, aber manchmal eben dann doch nützlich. Wenig Beobachtungen decken weniger Wirklichkeit ab und daher sind diese Modell schon intuitiv schlechter als Modelle mit mehr Beobachtungen. Aber lasse dich nicht abschrecken. auch mit weniger Daten lassen sich Schlüsse über Zusammenhänge finden. Nachdem wir einmal kurz klären, was genau ich immer meine, wenn ich von Faktoren und Kovariaten schreibe, gehen wir nochmal auf das Modell als Idee ein.
Sprachlicher Hintergrund
“In statistics courses taught by statisticians we don’t use”independent variable” because we use independent on to mean stochastic independence. Instead we say predictor or covariate (either). And, similarly, we don’t say “dependent variable” either. We say response.” — User berf auf r/AskStatistics
Wenn wir uns mit dem statistischen Modellieren beschäftigen wollen, dann brauchen wir auch Worte um über das Thema reden zu können. Statistik wird in vielen Bereichen der Wissenschaft verwendet und in jedem Bereich nennen wir dann auch Dinge anders, die eigentlich gleich sind. Daher werde ich mir es hier herausnehmen und auch die Dinge so benennen, wie ich sie für didaktisch sinnvoll finde. Wir wollen hier was verstehen und lernen, somit brauchen wir auch eine klare Sprache.
In dem folgenden Kasten erkläre ich nochmal den Gebrauch meiner Begriffe im statistischen Testen. Es ist wichtig, dass wir hier uns klar verstehen. Zum einen ist es angenehmer auch mal ein Wort für ein Symbol zu schreiben. Auf der anderen Seite möchte ich aber auch, dass du dann das Wort richtig einem Konzept im statistischen Modellieren zuordnen kannst. Deshalb einmal hier meine persönliche und didaktische Zusammenstellung meiner Wort im statistischen Modellieren.
WichtigWorte und Bedeutungen im statistischen Modellieren
“Die Grenzen meiner Sprache bedeuten die Grenzen meiner Welt.” — Ludwig Wittgenstein
Hier kommt einmal die Tabelle mit den wichtigsten Begriffen im statistischen Modellieren und wie ich die Worte benutzen werde. Damit wir uns verstehen und du was lernen kannst. In anderen Büchern und Quellen findest du teilweise die Worte in einem anderen Sinnzusammenhang. Das ist gut so dort. Bei mir ist es anders.
| Symbol | Deutsch | Englisch | |
|---|---|---|---|
| LHS | \(Y\) / \(y\) | Messwert / Endpunkt / Outcome / Abhängige Variable | response / outcome / endpoint / dependent variable |
| RHS | \(X\) / \(x\) | Einflussvariable / Erklärende Variable / Fester Effekt / Unabhängige Variable | risk factor / explanatory / fixed effect / independent variable |
| RHS | \(Z\) / \(z\) | Zufälliger Effekt | random effect |
| \(X\) ist kontinuierlich | \(c_1\) | Kovariate 1 | covariate 1 |
| \(X\) ist kategorial | \(f_A\) | Faktor \(A\) mit Level \(A.1\) bis \(A.j\) | factor \(A\) with levels \(A.1\) to \(A.j\) |
Am Ende möchte ich nochmal darauf hinweisen, dass wirklich häufig von der abhängigen Variable (eng. dependent variable) als Messwert und unabhängigen Variablen (eng. independent variable) für die Einflussvariablen gesprochen wird. Aus meiner Erfahrung bringt die Begriffe jeder ununterbrochen durcheinander. Deshalb einfach nicht diese Worte nutzen.

Was ist ein Modell
“Doch in Wahrheit muss Wissen immer zuerst vermutet und dann überprüft werden.” — David Deutsch, Der Anfang der Unendlichkeit
Was ist ein Modell? Da sich unser Modell auf Daten bezieht, denn nichts anderes haben wir ja in R vorliegen, ist unser Modell immer eine Zusammenstellung von Einflussvariablen und häufig einem Messwert. Es gibt einfache Arten der Modellierung wo wir eine Linie durch eine Punktewolke zweier Kovariaten zeichnen. Es gibt aber auch komplexere Modelle, die wie Netze oder Bäume aussehen. Am Ende haben aber alle Modelle eine Basis. Nämlich deine Daten, die du in diese Modelle hinsteckst.
- Was modellieren wir jetzt eigentlich?
-
Wir modellieren die Varianz in den Daten. Dabei versuchen wir die Varianz im Messwert durch die Einflussvariablen zu minimiere. Oder anders formuliert, wir versuchen die Varianz in den Daten den jeweiligen Quellen zuzuordnen und darüber dann neue Erkenntnisse zu erlangen. Meistens ist es dann einfach eine Linie durch die Punkte zu zeichnen.
Somit haben wir immer unsere Daten vorliegen. Wir versuchen jetzt unsere Daten durch unser Modell als statistisches Modell zu verstehen. Wir zerlegen somit die Daten in zwei Komponenten. Den Teil der Messwerte, den wir durch das Modell erklären können und noch den Rest, den wir als Fehler oder unbekannten Messwert erklären. Mehr dazu dann in dem Buch zu Statistical Thinking for the 21st Century — What is a model?. Es geht eben um Daten und die Erklärung der Daten durch ein Modell.
Oder um es etwas anders zu formulieren, “Models are about what changes, and what doesn’t”. Wir wollen also wissen was sich in den Daten ändert und wie wir diese Änderung beschreiben können. Somit wollen wir uns die Frage stellen, was ist eigentlich das Ziel des Modellierens? Wir wollen ja mit der Modellierung der Varianz irgendwas erreichen. In der folgenden Abbilundung siehst du einmal die drei großen Fragefelder, die wir mit einer Modellierung bearbeiten können. Du musst dir dann überlegen, wie du deine wissenschaftliche Fragestellung dann dort unterbringen kannst. Wir können uns fragen, ob es einen kausalen Zusammenhang gibt? Was passiert mit unserem Messwert, wenn sich die Einflussvariablen ändern? Wir können ein prädiktives Modell rechnen in dem wir neue Messwerte anhand neuer Einflussvariablen mit unserem Modell vorhersagen. Oder aber wir wollen Cluster in unseren Daten finden.
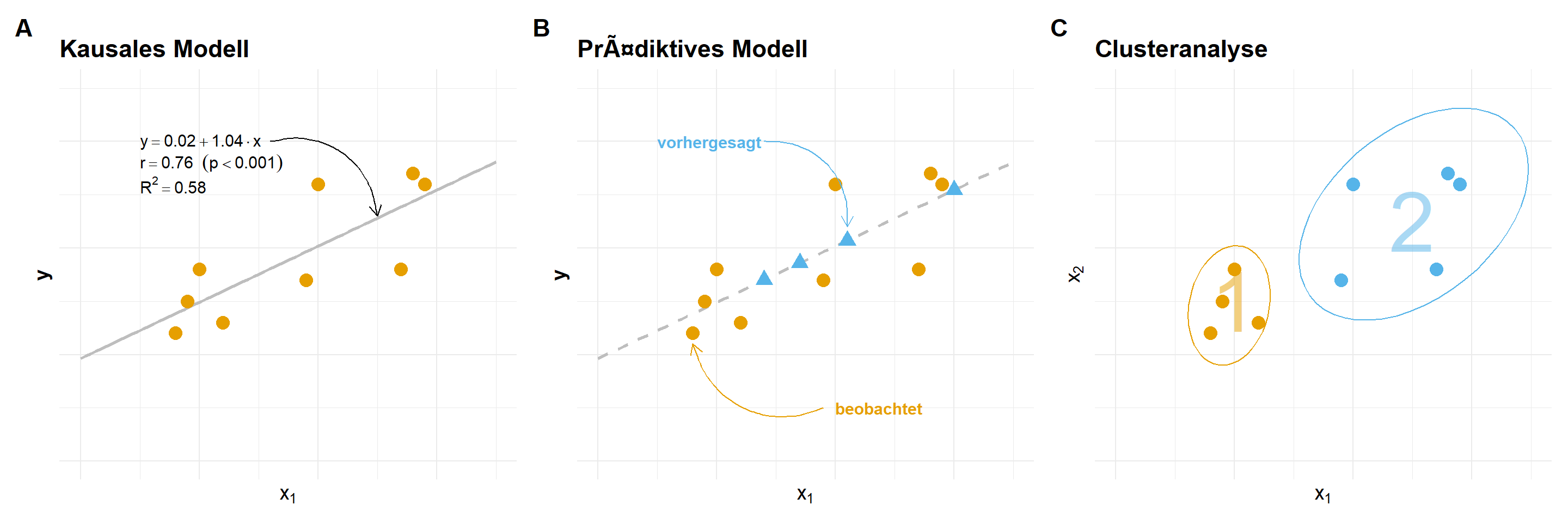
R Pakete zum Modellieren
Neben den R Paketen, die wir in den jeweiligen Kapiteln brauchen, kommen noch folgende R Pakete immer wieder dran. Deshalb sind die R Pakete hier schon mal mit den jeweiligen Internetseiten aufgeführt.
- Das Buch Tidy Modeling with R gibt nochmal einen tieferen Einblick in das Modellieren in R. Wir immer, es ist ein Vorschlag aber kein Muss.
- Das R Paket
{parameters}nutzen wir um die Parameter eines Modells aus den Fits der Modelle zu extrahieren. Teilweise sind die Standardausgaben der Funktionen sehr unübersichtich. Hier hilft das R Paket. - Das R Paket
{performance}hilft uns zu verstehen, ob die Modelle, die wir gefittet haben, auch funktioniert haben. In einen mathematischen Algorithmus können wir alles reinstecken, fast immer kommt eine Zahl wieder raus. - Das R Paket
{tidymodels}nutzen wir als ein R Paket um mit Modellen umgehen zu können und eine Vorhersage neuer Daten zu berechnen. Das Paket{tidymodels}ist wie das Paket{tidyverse}eine Sammlung an anderen R Paketen, die wir brauchen werden. - Das R Paket
{ggeffects}hilft dir bei der Visualisierung von Effekten aus statistischen Modellen. Du kannst hier recht einfach Effekte und andere Maßzahlen aus deinen Modellen darstellen. - Das R Paket
{modelbased}ist ein Wrapper für die R Pakete{marginaleffects}und{emmeans}und sagt von sich selber, dass es die Anwendung der beiden Pakete erleichtert. Das kann man so sehen, muss man aber nicht. - Das R Paket
{marginaleffects}nutzen wir dann im Kapitel zu den Marginal effects models. Daher brauche ich das obige Paket nicht sondern nutze es direkt als Original. Mehr zu den Marginal effects models dann in den entsprechenden Kapiteln zu dem statistischen Modellieren.
Auch gibt es noch andere R Pakete, die wir nutzen können und auch werden. Dafür ist das Feld zu groß und die Anwendungsmöglichkeiten zu komplex. Daher hier nur eine Auswahl an möglichen Pakten und Ideen. Kommen wir als nächstes einmal zu dem theoretischen Teil.
53.2 Theoretisches Modellieren
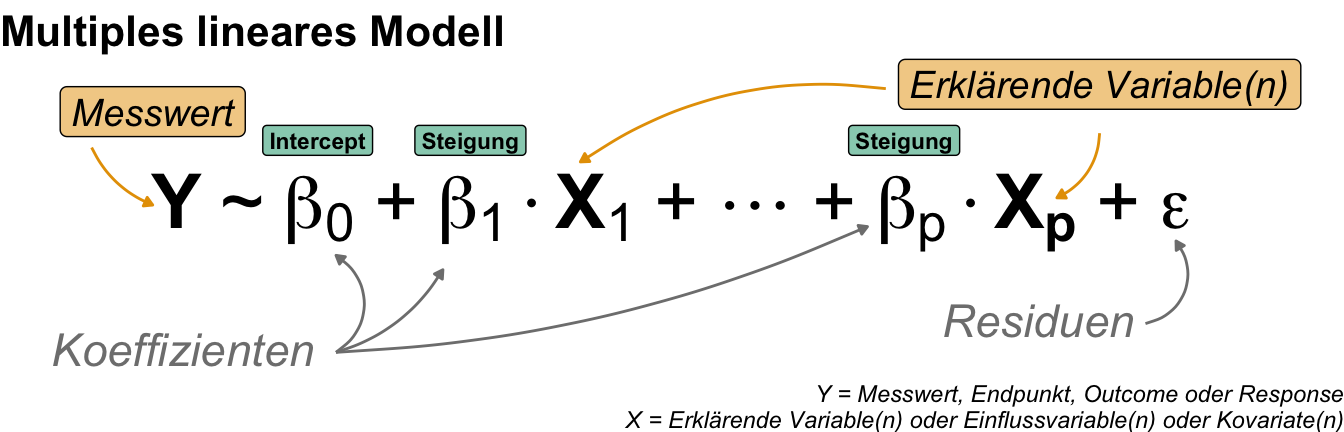
Fangen wir also erstmal allgemeiner an ein Modell und deren Schreibweise zu verstehen. Da wir uns natürlich in R bewegen für die praktische Anwendung, nutzen wir auch die Modellschreibweise, die in R üblich ist. Die Schreibweise ist schon etwas älter und stammt von Wilkinson & Rogers (1973) aus der Arbeit Symbolic Description of Factorial Models for Analysis of Variance. In R wird diese Schreibweise auch formula() genannt. Im Folgenden siehst du einmal ein Modell in einer abstrakten Form. Wir haben den Messwert \(Y\) auf der linken Seite (eng. left hand side, abk. LHS) der Tilde und die Einflussvariablen \(X\) auf der rechten Seite (eng. right hand side, abk. RHS). Dabei steht dann das \(X\) hier einmal als Platzhalter und Sammelbegriff für verschiedene Arten von möglichen Variablen.
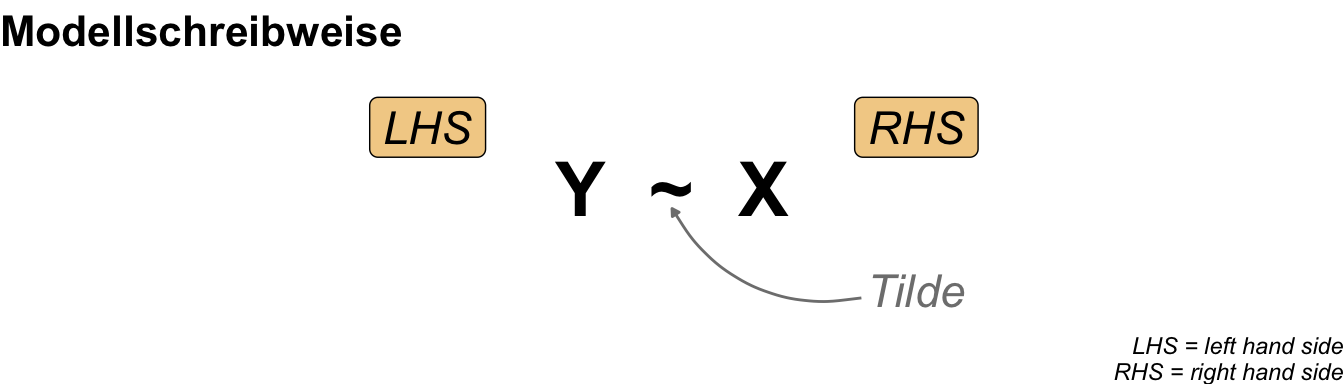
In R sieht es dann etwas anders aus, da wir die Platzhalter \(Y\) für den Messwert und \(X\) für die Einflussvariable durch die Namen der Spalten in unserem Datensatz ersetzen. Der Datensatz liegt dann als tibble() in R vor. Mehr dann dazu in den folgenden Beispielen in den jeweiligen Kapiteln zum Modellieren. Dann sieht das Modell wie in der folgenden Abbildung aus, wenn wir uns einmal die Sprungweite in Abhängigkeit von der Flohart anschauen wollen.

Dann wäre es ja schön, wenn wir nur die linke und rechte Seite neben einer Tilde hätten. Das ist aber nur eine sehr abstrakte Darstellung. Es ha ja auch seinen Grund, warum wir sehr viele Kapitel in diesem Openbook dem Thema des statistischen Modellieren widmen. Wir haben nämlich eine richtig schrecklich nette Familie an Möglichkeiten zusammen.
In der folgenden Abbildung siehst du einmal wie alles mit allem zusammenhängt. Auf der linken Seite siehst du den Messwert \(Y\) der einer Verteilunsgfamilie entstammt. Je nachdem was du wie gemessen hast, folgt dein Messwert \(Y\) einer anderen Verteilung. Konkreter noch, welche Zahlen du für deinen Messwert \(Y\) bestimmt hast. Auf der rechten Seite findest du die Einflussvariable \(X\), die aus mehren Variablen bestehen kann aber nicht muss. Wenn du eine kontinuierliche Einflussvariable vorliegen hast, dann sprechen wir von Kovariaten. Hast du dagegen kategoriale Einflussvariablen, dann sprechen wir von Faktoren mit Leveln als die Gruppen. Je nach Kombination aus Verteilungsfamilie und Einflussvariable hast du dann eine andere Interpretation der Modellierung vorliegen.

Da wir die schrecklich nette Familie ja auch irgendiwe bezeichnen müssen, hat sich folgende Semantik mehr oder minder durchgesetzt. Ich nutze jedenfalls den folgenden Aufbau um zu benennen was ich eigentlich analysieren und modellieren will. Zuerst kommt, ob wir eine Einflussvariable oder mehrere Einflussvariablen betrachten. Wir nennen dann eben die Modellierung eine simple oder multiple Modellierung. Dann kommt die Verteilunsgfamilie des Messwerts als Wort um dann noch zu sagen, ob wir es mit einem gemischten Modell zu tun haben. Haben wir kein gemischtes Modell, dann lassen ignorieren wir den Teil. Häufig sprechen wir auch von einer linearen Regression, wenn wir eine Gaussian linear Regression meinen. Das finde ich aber sehr verwirrend und nicht klar. Deshalb vermeide ich diesen Sprachgebrauch, wenn wir es mit komplexeren Modellen zu tun haben.

Jetzt müssen wir natürlich unsere schematische Abbildung nochmal in R übersetzen. Dort nutzen wir dann je nach Verteilungsfamilie unseres Messwertes \(Y\) eine andere Funktion um die statistischen Modelle anzupassen. Das ist im ersten Moment etwas verwirredn, aber wir können eben nicht mit einer einzigen Funktion alle möglichen Ausprägungen von Zahlen in einem Messwert modellieren. Dafür brauchen wir dann eben mehr Algorithmen und so auch Funktionen.
- Die Funktion
lm()oderaov()nutzen wir, wenn der Messwert \(Y\) einer Normalverteilung folgt. - Die Funktion
glm()nutzen wir, wenn der Messwert \(Y\) einer andere Verteilung folgt. - Die Funktion
lmer()nutzen wir, wenn der Messwert \(Y\) einer Normalverteilung folgt und wir noch einen Block- oder Clusterfaktor vorliegen haben. - Die Funktion
glmer()nutzen wir, wenn der Messwert \(Y\) einer andere Verteilung folgt und wir noch einen Block- oder Clusterfaktor vorliegen haben.
Im Prinzip folgt die Benennung der Funkionen auch einem übergeordneten Schema, wie ich dir in der folgenden Abbildung einmal versuche zu zeigen. Wir haben im Zentrum das lineare Modell (abk. lm) und dann ergänzen wir die Generalisierung (abk g) oder eben den zufälligen Effekt (abk. *er*) zum Modell. Dadurch haben wir dann die verschiedenen Funktionen einmal zusammen.
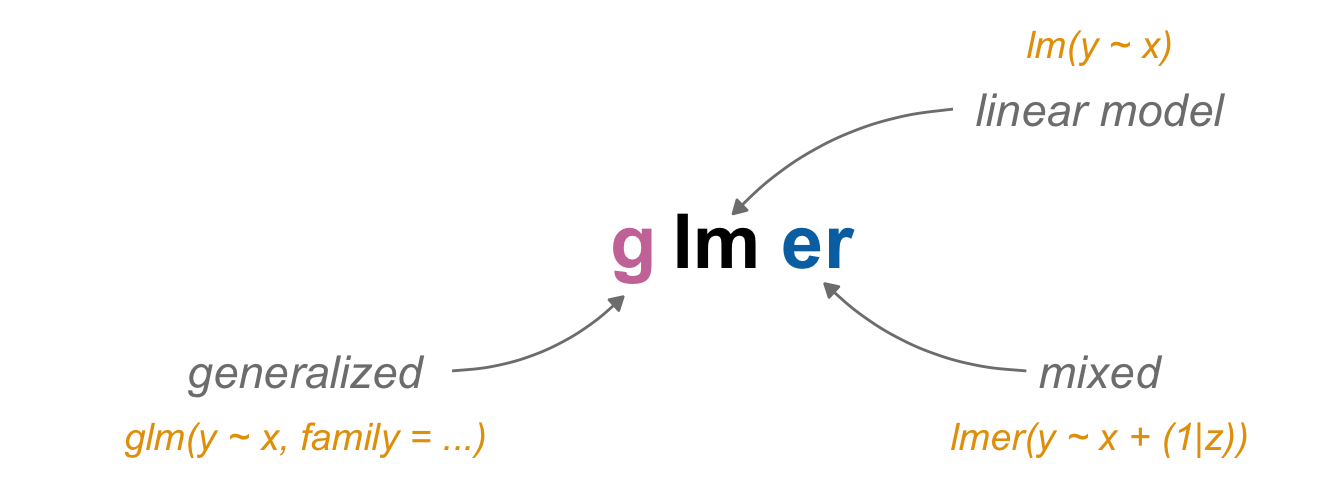
lm() für eine lineare Regression zur generalisierten Variante glm() und der beiden Varianten für die gemischten linearen Modellen lmer() und glmer(). [Zum Vergrößern anklicken]
In diese Funktionen schreiben wir dann die jeweiligen Modelle. Da die Modelle eben auch von den Einflussvariablen abhängen, haben wir jetzt die Wahl zwischen einem simplen Modell, einem multiplen Modell sowie einen gemischten Modell. Dabei ist darauf zu achten, dass ein gemischtes Modell nicht bedeutet, dass wir Kovariaten und Faktoren kombinieren, sondern noch einen zufälligen Clustereffekt als Faktor modellieren wollen. In den folgenden Tabs, habe ich dir nochmal die Modelle aufgeschrieben. Jedes dieser Modelle können wir mit allen Funktionen rechnen. Bachte bitte dabei, dass es sich hier nur um die abstrakte Form handelt.
In einem simplen Modell haben wir nur eine Einflussvariable \(X\) entweder als Faktor oder als Kovariate vorliegen. Wir müssen uns hier als entscheiden, ob wir ein einfaktorielles Modell oder ein einkovariates Modell anpassen wollen. Wir nennen daher diese Art von Modell auch simple lineare Regression, wenn wir ein reines kovariates Modell rechnen.
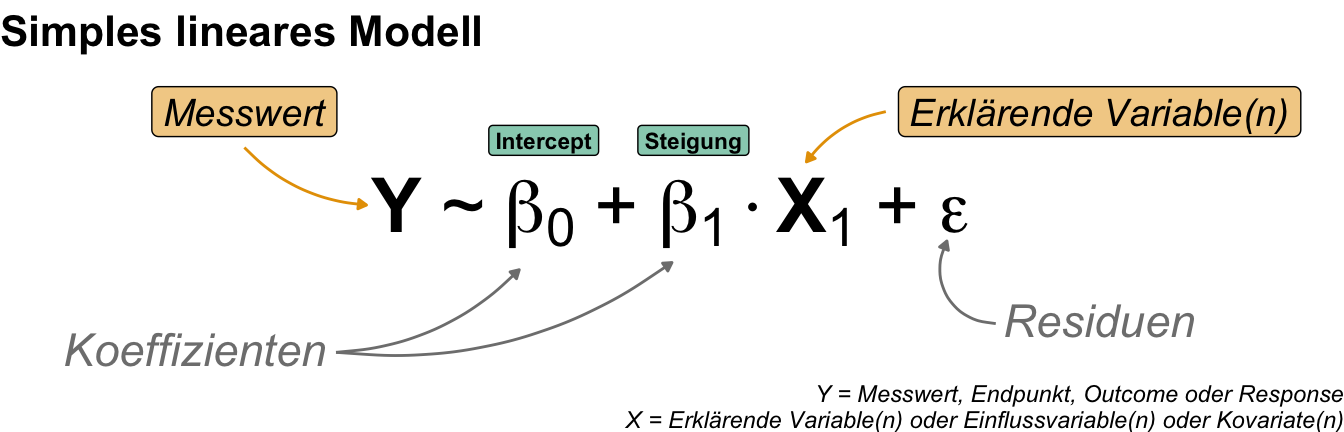
In dem multiplen Modell erweitern wir die Anzahl an erklärenden Variablen um mindestens eine weitere Variable. Ein multiples Modell hat mindestens zwei Einflussvariablen als \(X\). Meistens sind es jedoch mehr als nur zwei Vairablen. Wir können auch eine Kombination aus Faktoren und Kovariaten vorliegen haben, was die Interpretation unserer Modelle immer schwieriger macht.
Wir sprechen von einem gemischten Modell (eng. mixed model), wenn wir neben unseren klassischen Einflussvariablen wie den Kovariaten und Faktoren als feste Effekte noch einen zufälligen Effekt mit in unserem Modell haben. Das Wort “zufällig” ist hier etwas verwirrend, den es beschreibt eigentlich einen zusätzlichen Faktor. Dieser zusätzliche Faktor steht für einen Cluster oder einen Block oder noch allgemeiner für eine Gruppe von Beobachtungen. Die gemischten Modelle sind dabei eine eigene große Klasse von Modellen.

Nachdem wir uns jetzt einmal über den theoretischen Aufbau von Modellen ausgetauscht haben, wollen wir uns einmal die Grundlagen des praktischen Modellierens in R austauschen. Hier gibt es dann natürlich eine eigene Schreibweise um die theoretischen Modelle in R zu übersetzen. Ich nutze auch nicht die vollen Möglichkeiten sondern meistens nur die grundlegenden Möglichkeiten. Aber hier schreibe ich dann einfach mal alle. Dann haben wir alles mal zusammen.
53.3 Genutzte R Pakete
Wir wollen folgende R Pakete in diesem Kapitel nutzen.
R Code [zeigen / verbergen]
pacman::p_load(tidyverse, readxl, emmeans, multcomp, ggpmisc, gtsummary,
tidymodels, modelsummary, ggeffects, modelbased,
conflicted)
conflicts_prefer(dplyr::select)
conflicts_prefer(ggplot2::annotate)An der Seite des Kapitels findest du den Link Quellcode anzeigen, über den du Zugang zum gesamten R-Code dieses Kapitels erhältst.
53.4 Daten
Wir brauchen auch hier nochmal Daten an denen wir uns die Prinzipien des Modellierens in R verstehen zu können. Als Datensatz habe ich nochmal die Modellierung von Flöhen mitgebracht. In dem Datensatz zu der Modellierung von Flöhen finden wir viele Kovariaten sowie Faktoren und verschiedene Messwerte, die von Interesse sind. Wir schauen uns hier die Sprungweiten von Katzenflöhen unter verschiedenen Fütterungebedingungen an. Dabei haben die Katzenflöhe einmal Zuckerwasser, Ketchup sowie Blut als Nahrung erhalten. Als zweiten Faktor betrachten wir dann noch juvenile und adulte Flöhe. Neben diesen beiden Faktoren, haben wir dann noch die Kovariate des Gewichts der Flöhe erhoben. Als weitere Messwerte kommen dann die Bonitur der Flöhe, die Anzahl der Haare an einem Flohbein sowie der Infektionsstatus mit Flohschnupfen in Betracht. Teilweise können wir dann die kontinuierlichen Messwerte auch als Kovariaten in unseren Modellen verwenden. Da sind wir ja nicht festgelegt. Wir laden dann die Daten einmal in R und müssen noch etwas die Faktoren anpassen.
R Code [zeigen / verbergen]
flea_model_tbl <- read_excel("data/fleas_model_data.xlsx") |>
mutate(feeding = as_factor(feeding),
stage = as_factor(stage),
bonitur = as.numeric(bonitur),
infected = factor(infected, labels = c("healthy", "infected"))) |>
select(feeding, stage, weight, jump_length, count_leg, bonitur, infected) Dann können wir uns auch schon mal einen Auszug aus der Datentabelle zu den Sprungweiten der Katzenflöhe anschauen.
| feeding | stage | weight | jump_length | count_leg | bonitur | infected |
|---|---|---|---|---|---|---|
| sugar_water | adult | 16.42 | 77.2 | 63 | 4 | infected |
| sugar_water | adult | 12.62 | 56.25 | 55 | 1 | healthy |
| sugar_water | adult | 15.57 | 73.42 | 112 | 2 | healthy |
| … | … | … | … | … | … | … |
| ketchup | juvenile | 7.18 | 83.38 | 423 | 4 | infected |
| ketchup | juvenile | 6.6 | 104.48 | 548 | 5 | infected |
| ketchup | juvenile | 4.19 | 130.18 | 869 | 5 | healthy |
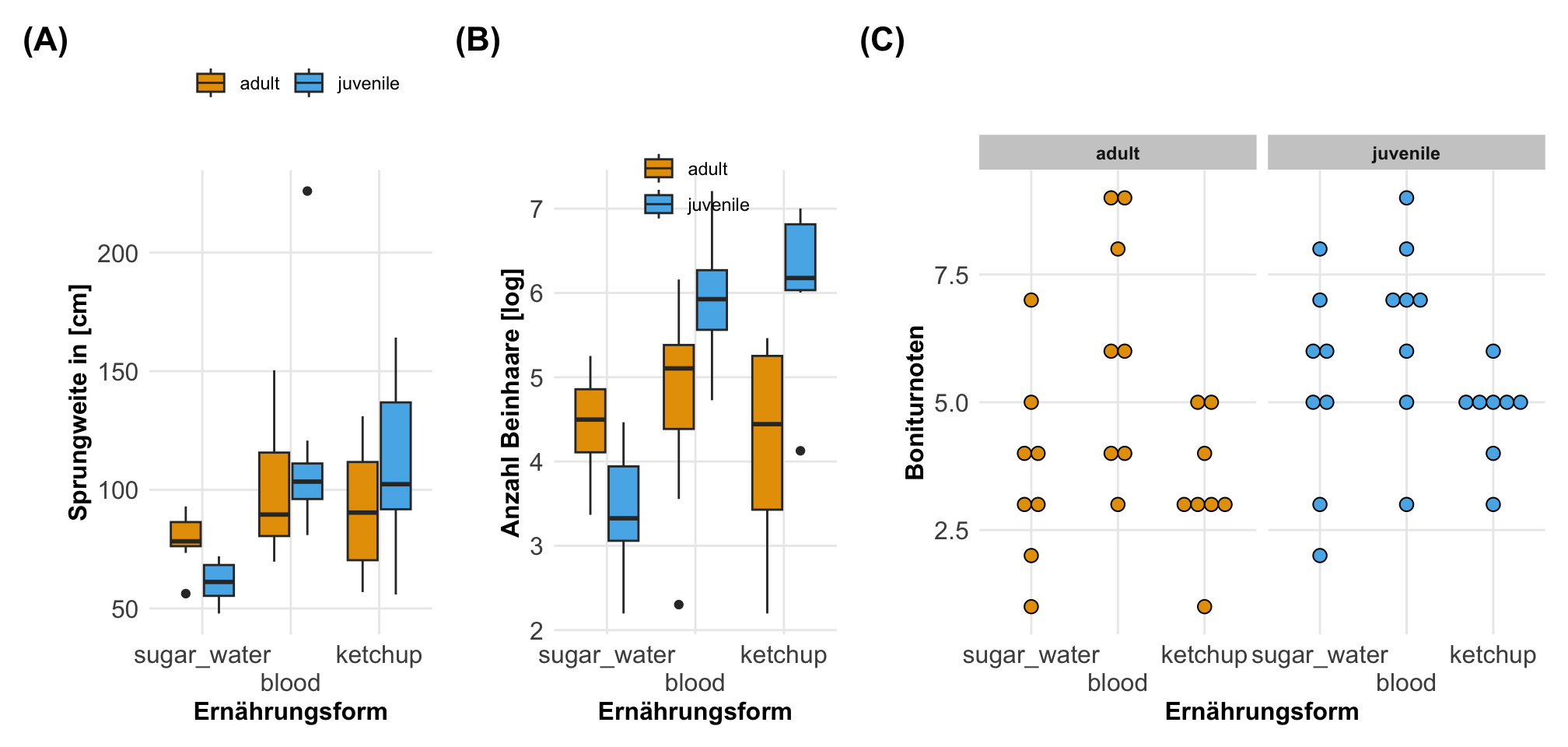
Dann können wir uns einmal ausgewählte Boxplots und Dotplots für die Flohdaten anschauen. Wir sehen hier sehr schön, dass sich die Sprungweiten über die Ernährungsformen und den Entwicklungsständen anscheinend unterschieden. Auch haben wir Effekte in der Anzahl an Beinhaaren. Die Boniturnoten sehen eher etwas gleichmäßiger aus. Die eigentlichen Effekte oder statistischen Tests wollen wir dann auszugsweise in den folgenden Abschnitten einmal rechnen.
53.5 Formelschreibweise in R
Wir gehen wir nun praktisch in R vor? Dafür brauchen wir nochmal kurz unsere Idee der linken sowie rechten Seite der Tilde. Zusammen bilden die beiden Seiten ja ein Modell in R. In der folgenden Abbildung siehst du nochmal das Konzept. Auf der linken Seite haben wir unseren Messwert und auf der rechten Seite dann mindestens eine, wenn nicht mehr, Einflussvariablen stehen. Daher unterscheiden wir gleich einmal die beiden Seiten und betrachten die Erstellung eines Modells getrennt.
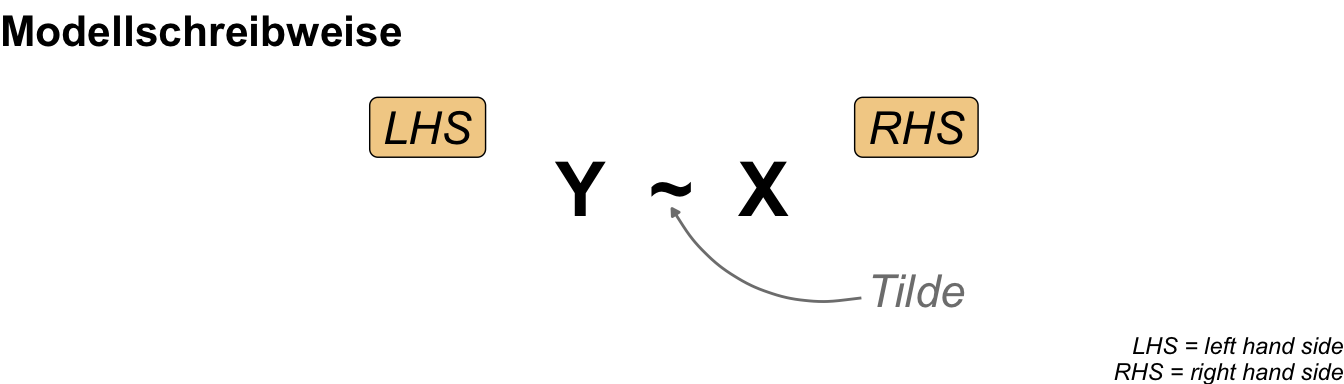
Wir immer gibt es wieder einiges mehr zu den Modellen in R und deren Schreibweise. Ich habe mich an den folgenden Blogs, Tutorien und Seiten orientiert. Vielleicht findest du ja dort nochmal mehr Informationen, die dir wertvoll sind. Hier ist es dann immer das Extrakt vieler Quellen. Wir steigen dann aber gleich mal in die Beschreibung der linken und der rechten Seite der Tilde ein.
TippWeitere Tutorien für die Formelschreibweise in R
Hier findest du nochmal ein paar Links und Webseiten, die sich mit der Formelschreibweise in R beschäftigen. Teilweise dienten die Seiten für mich als Inspiration. Häufig findest du noch mehr informationen als hier zusammengetragen wurden.
- Model Formulae in R gibt dir nochmal einen Überblick über die Möglichkeiten ein Modell in R zu formulieren. Hier gibt es eine Menge an Beispielen.
- Das R Formula Tutorial liefert nochmal einen sehr umfangreichen Einstieg in das Modellieren in R und wie wir das im allgemeinen machen würden. Dabei wird auf die Standardfunktionen eingegangen und der Fokus liegt eben Anfängern im Modellieren.
- Die Hilfeseite zu
formula()in{stats}gibt nochmal die Grundlagen der Formelschreibweise in R in der üblichen Hilfeform. Manchmal sind die Hilfeseiten hilfreich, für Anfänger aber aus meiner Erfahrung heraus eher weniger. - The R Formula Cheatsheet ist nochmal eine gute Idee, wenn du schon die Grundlagen kennst, dich aber nochmal über die Möglichkeiten die gehen schlau machen möchtest.
- Formulae in R – ANOVA and other models, mixed and fixed erweitert nochmal die Formelschreibweise für die faktoriellen Experimente in der Form der ANOVA und der gemischten Modelle. Je nach Fachgebiet ist das eine Nische oder dein ganzer Wissenschaftsbereich.
Right-hand side (abk. RHS)
Auf der rechten Seite der Tilde stehen die Einflussvariablen. Wir haben mindestens eine Einflussvariable in einem simplen Modell vorliegen. Wenn wir mehrere Einflussvariablen in unser Modell aufnehmen wollen, dann verbinden wir die Einflussvariablen mit einem Pluszeichen + miteinander. Wir können dann noch weitere Terme hinzufügen. Diese Terme können dann zusätzliche Faktoren oder Kovariaten beschreiben. Oder wir ergänzen einen Interaktionsterm zum Modell. Wir haben auch die Möglichkeiten die Fehler etwas anders zu modellieren, wenn wir zum Beispiel eine komplexere ANOVA rechnen wollen. Wenn wir uns eine Kovariate anschauen, dann können wir auch Polynome bestimmen, wenn wir zum Beispiel eine quadratische Funktion ergänzen wollen. Dazu kommen dann noch die Möglichkeit Transformationen direkt im Modell zu machen. Davon rate ich aber ab, deshalb lassen wir es hier mal lieber. Wir bauen uns einen sauberen Datensatz und auf dem Modellieren wir dann. In der folgenden Tabelle siehst du nochmal gängige Symbole und deren Bedeutung in der Modellierung der rechten Seite des Modells.
| Symbol | Bedeutung | Beispiel |
|---|---|---|
~ |
Trennt die LHS mit dem Messwert von der RHS mit den Einflussvariablen in dem Modell. | y ~ x |
+ |
Addiert eine Einflussvariable auf der RHS in dem Modell. | y ~ x + z |
. |
Nimm alle Spalten aus dem Datensatz außer y mit in das Modell. |
y ~ . |
- |
Entferne eine Einflussvariable aus dem Modell. | y ~ . - x |
1 oder 0 |
Entfernt den Intercept aus dem Modell und setze den Intercept auf Null. | y ~ 0 + x oder y ~ x - 1 |
: |
Konstruiert einen Interaktionsterm. | y ~ fa + fb + fa:fb |
* |
Erstellt alle Kombinationen aus den entsprechenden Einflussvariablen plus Interaktionsterme. | y ~ fa * fb |
^ |
Erstellt Interaktionen höherer Ordnung zwischen allen Einflussvariablen. | y ~ (fa + fb + fc)^3 |
I() |
Das as-is Symbol in der Modellschreibweise und erlaubt somit quadratische Einflussvariablen. |
y ~ x + I(x^2) |
poly() |
Erlaubt Polynome für eine Einflussvariable zu erstellen. Die bessere Alternative zu quadratische Termen. | y ~ poly(x, 2) |
Left-hand side (abk. LHS)
Auf der linken Seite der Tilde steht dann unser Messwert. Wir haben in einem normalen Modell immer nur den einen Messwert stehen. Wenn wir uns in der Überlebenszeitanalyse befinden, dann können wir auch auch zwei Werte dort im Objekt surv() finden. Ebenso bei der der Durchführung der binomialen oder quasibinomialen Modellierung geben wir entweder eine Erfolgswahrscheinlichkeit, eine zweispaltige Matrix mit den Spalten für die Anzahl der Erfolge und Misserfolge oder einen Faktor an, bei dem die erste Stufe für Misserfolg und die anderen für Erfolg auf der linken Seite der Gleichung stehen. Das ist jetzt aber schon eher sehr speziell. Im Normalfall steht einfach nur unser Messwert links.
| Symbol | Bedeutung | Beispiel |
|---|---|---|
y |
Erhobener Messwert, der in dem statistischen Modell analysiert werden soll. | jump_length ~ . |
Surv(t, f) |
In dem Objekt Surv() haben wir erst die Spalte für die Zeit t und dann die Spalte für das Eintreten des Ereignisses f mit \(0/1\) in einer survfit() Funktion. |
Surv(time, death) ~ . |
cbind(n, 1-n) |
Die Spalte mit der Anzahl des Ereignisses sowie die Spalte mit dem Gegenereignis in einer glm() Funktion. |
cbind(disease, no_disease) ~ . |
Hilfreiche Funktionen
Wenn es eine Funktion gibt, die mir immer mal wieder beim Bauen von Formeln in R geholfen hat, dann ist es die Funktion reformulate(). Wir können nämlich der Funktion die linke Seite sowie die rechte Seite des Modells einfach als Wörter angeben und dann erhalten wir die Formelaschreibweise in R zurück. Das ist manchmal super praktisch.
R Code [zeigen / verbergen]
reformulate(termlabels = "feeding * stage + weight",
response = "jump_length")jump_length ~ feeding * stage + weightEs gibt noch die update() Funktion, die uns erlaubt dynamisch Modelle zu aktualisieren. Ich würde das aber überhaupt nicht empfehlen, da du dann schnell mal den Überblick verlieren kannst, was jetzt wie im Modell ist. Ich habe das nie richtig verstanden, was der Vorteil davon sein soll, dass Modell einfach zu kopieren und dann zu ändern. Am Ende musst du die Modelle sowieso miteinander vergleichen um zu sehen welches Modell das beste Modell ist.
53.6 Praktisches Modellieren
Wenn wir von dem praktischen Modellieren in R sprechen, dann können wir grob zwischen dem Standard {base} in R und neueren Paketen unterscheiden. Dabei sind die neueren Pakete vorallem darauf optimiert, dass wir auf Listen oder aber mit dem Pipe-Operator arbeiten können. Nichts spricht dagegen mit den klassischen Funktionen zu arbeiten. In den folgenden Kapiteln nutze ich auch die Implemntierungen in {base} und {stats}, die schon sehr alt sind. Die Funktionen lm(), glm() und Weitere finktionieren aber super und sind für den alltäglichen Gebrauch auch sehr gut geeignet. Manchmal werden aber die Daten größer, da wir mehr Messwerte vorliegen haben oder aber einfach mehr Einflussvariablen. Dann gibt es bessere Lösungen. Davon möchte ich hier dann einige vorstellen.
Wenn du mit R Modellieren willst, dann bietet sich das R Paket {tidymodels} auf jeden Fall an. Dazu dann noch das Openbook Tidy Modeling with R lesen und du kannst anfangen. Dort wird sehr sauber einmal die Modelle und deren Überprüfung hergeleitet. In dem R Paket {tidymodels} geht auch das R Paket {parsnip} auf, welches wir hier gleich einmal vorstellen wollen. Neben dieser Paketwelt gibt es dann noch die Möglichkeiten das R Paket {easystats} mit den R Paketen {performance} und {parameters} sowie anderen tollen Paketen zu nutzen. Ich finde, dass sich die {tidymodels} eher im Bereich der Vorhersage bewegen und nicht so sehr in den erklärenden Modellen. Dafür sind dann die R Pakete aus {easystats} besser geeignet. Wenn es dann aber um die nicht linearen Modelle geht, dann würde ich immer auf {marginaleffects} als R Paket verweisen. Ja, es gibt vieles und das ist dann auch gut so. Es gibt ja auch viele wissenschaftliche Fragestellungen zu beantworten.

“Welche Modellwelt ist jetzt besser? Die von
{tidymodels}oder die von{easystats}? Dazu kommt ja dann noch{marginaleffects}, wenn wir uns mit nicht linearen Modellen oder ganz spezielle Hypothesen testen beschäftigen wollen. Daher nutze ich alles. Ich nutze die{base}Implementierungen und dann eben Funktionen aus den anderen Paketen. Bei Gruppenvergleichen darf{emmeans}nicht fehlen. Es ist eine Freude!” — Jochen Kruppa-Scheetz, meiner bescheidener Meinung nach.
In den folgenden Abschnitten gehen wir jetzt einmal ein paar R Pakete durch, die ich immer wieder für das Modellieren nutze. Ich gehe hier nicht nochmal auf die großen Pakete wie {emmeans} ein oder eben auf {marginaleffects}, da diese Pakete schon ihr eigenen Kapitel vorliegen haben. Daher ist es hier eine wie auch immer geartete Auswahl, die sich vermutlich immer wieder etwas erweitern wird. Nicht alle Pakete sind speziell für das Modellieren zuständig sondern dienen auch der Darstellung von Ergebnissen. Hier sei aber auf jeden Fall nochmal auf das R Paket {performance} und das R Paket {parameters} verwiesen. Ohne die beiden Pakete ist das Arbeiten mit {base} Modellierungen wie lm() oder glm() sehr anstrengend.
53.6.1 … mit {gtsummary}
Wenn wir mit dem Modellieren anfangen wollen, dann ist es immer sehr hilfreich sich erstmal eine Übersicht über die Einflussvariablen zu beschaffen. Insbesondere wenn wir Faktor als Haupteinfluss oder aber einen binären Messwert vorliegen haben. So können wir uns fragen, wie sind eigentlich alle Variablen für die Entwicklungsstände verteilt? Wir haben hier das R Paket {gtsummary} als super Option, um uns mehr über die Daten anzeigen zu lassen. Auch hier gibt es mehrere Funktionen, die wir nutzen können. Ich stelle hier einmal meine wichtigsten Funktionen vor, die ich gerne nutze.
Die Funktion tbl_summary() liefert dir eine Tabelle mit p-Werten, die du dann auch noch nach einer Variable aufteilen kannst. Hier gibt es dann die Möglichkeit einmal für einen binären Messwert wie dem Flohschnupfen oder aber für einen Faktor aufzuteilen. Beides ist möglich und hängt von der Fragestellung ab. Bei den p-Werten wäre ich immer zurückhaltend, die sind nur zur Orientierung da und ich würde dann immer eine saubere Modellierung oder Gruppenvergleich anschließen. Anbei einmal die Flohdaten ohne die Bonitur aufgeteilt für den Einwicklungsstand.
R Code [zeigen / verbergen]
flea_model_tbl |>
select(-bonitur) |>
tbl_summary(by = stage) |>
add_p()| Characteristic | adult N = 241 |
juvenile N = 241 |
p-value2 |
|---|---|---|---|
| feeding | >0.9 | ||
| sugar_water | 8 (33%) | 8 (33%) | |
| blood | 8 (33%) | 8 (33%) | |
| ketchup | 8 (33%) | 8 (33%) | |
| weight | 13.4 (11.4, 16.4) | 5.7 (4.7, 7.1) | <0.001 |
| jump_length | 85 (74, 101) | 91 (65, 106) | >0.9 |
| count_leg | 115 (45, 189) | 338 (55, 528) | 0.071 |
| infected | 0.042 | ||
| healthy | 14 (58%) | 7 (29%) | |
| infected | 10 (42%) | 17 (71%) | |
| 1 n (%); Median (Q1, Q3) | |||
| 2 Pearson’s Chi-squared test; Wilcoxon rank sum exact test; Wilcoxon rank sum test | |||
Die Funktion tbl_regression() ist mächtig, da wir mit der Funktion unsere schon angepassten Modelle sauber ausgeben lassen können. Wenn wir zum Beispiel eine logistische Regression rechnen, dann wollen wir meistens die Koeffizienten wieder zurück transformieren. Das geht dann ganz einfach in der Funktion. Hier haben wir dann ein multiples Modell gerechnet.
R Code [zeigen / verbergen]
glm(infected ~ weight + stage + feeding, data = flea_model_tbl,
family = binomial) |>
tbl_regression(exponentiate = TRUE)| Characteristic | OR | 95% CI | p-value |
|---|---|---|---|
| weight | 1.06 | 0.88, 1.29 | 0.6 |
| stage | |||
| adult | — | — | |
| juvenile | 6.83 | 0.92, 68.3 | 0.073 |
| feeding | |||
| sugar_water | — | — | |
| blood | 7.54 | 1.44, 52.8 | 0.025 |
| ketchup | 1.06 | 0.23, 4.84 | >0.9 |
| Abbreviations: CI = Confidence Interval, OR = Odds Ratio | |||
Manchmal wollen wir aber nicht ein multiples Modell mit alles Einflussvariablen rechnen, sondern für jede Einflussvariable ein simples Modell. Das ist dann meistens sehr aufwendig, da wir dann ja für jede Einflussvariable ein Modell hinschreiben und das dann rechnen müssen. Hier hilft die Funktion tbl_uvregression(), dir eben jedesmal ein simples Modell rechnet und uns dann eine Tabelle wiedergibt. Das ist natürlich super einfach und wir können auch noch die Modelle anpassen. Je nach Modell müssen wir dann eine andere Familie wählen und natürlich schauen, welche Einflussvariablen alle einmal in einem simplen Modell gerechnet werden sollen.
R Code [zeigen / verbergen]
tbl_uvregression(
flea_model_tbl,
method = glm,
y = infected,
method.args = list(family = binomial),
exponentiate = TRUE,
include = c("weight", "stage", "feeding")
)| Characteristic | N | OR | 95% CI | p-value |
|---|---|---|---|---|
| weight | 48 | 0.93 | 0.82, 1.03 | 0.2 |
| stage | 48 | |||
| adult | — | — | ||
| juvenile | 3.40 | 1.06, 11.8 | 0.045 | |
| feeding | 48 | |||
| sugar_water | — | — | ||
| blood | 5.57 | 1.22, 32.0 | 0.035 | |
| ketchup | 1.00 | 0.24, 4.10 | >0.9 | |
| Abbreviations: CI = Confidence Interval, OR = Odds Ratio | ||||
Ich nutze gerne das R Paket {gtsummary}, wenn ich erste Übersichten über Daten und Variablen erstellen möchte. Wie sehen die Zusammenhänge aus? Welche Variablen gibt es in welcher Häufigkeit für die einzelnen Messwerte? All das ist ja im Prozess der Datenanalyse sehr wertvoll. Auch hilft es Dritten, die sich die Daten einmal anschauen wollen um eine Diskussionsgrundlage zu haben.
53.6.2 … mit {modelsummary}
Das R Paket {modelsummary} ist wunderbar, wenn wir Daten oder Modelle zusammenfassen und einmal über die Variablen schauen wollen. Einmal ist es hier die Übersicht, die wir uns mit der Funktion datasummary_skim() geben können. Wir erhalten wirklich eine Menge Informationen sowie ein Histogramm der Verteilung. Manchmal ist es hilfreich, manchmal dann eben nicht.
R Code [zeigen / verbergen]
flea_model_tbl |>
datasummary_skim()| Unique | Missing Pct. | Mean | SD | Min | Median | Max | Histogram | |
|---|---|---|---|---|---|---|---|---|
| weight | 48 | 0 | 10.0 | 5.5 | 2.7 | 8.0 | 25.7 |  |
| jump_length | 48 | 0 | 93.2 | 33.9 | 47.9 | 85.8 | 225.9 |  |
| count_leg | 46 | 0 | 251.1 | 305.5 | 9.0 | 138.5 | 1351.0 |  |
| bonitur | 9 | 0 | 4.9 | 2.0 | 1.0 | 5.0 | 9.0 |  |
| N | % | |||||||
| feeding | sugar_water | 16 | 33.3 | |||||
| blood | 16 | 33.3 | ||||||
| ketchup | 16 | 33.3 | ||||||
| stage | adult | 24 | 50.0 | |||||
| juvenile | 24 | 50.0 | ||||||
| infected | healthy | 21 | 43.8 | |||||
| infected | 27 | 56.2 |
Die Funktion datasummary_crosstab() ist dafür da uns einmal für verschiedene Faktoren und einem kategorialen Messwert die ganzen Anzahlen der Faktorkombinationen wiedergeben zu lassen. Das ist für eine Übersicht super, als Bericht manchmal dann zu viel. Auch hier nutze ich die Funktion im Rahmen meiner Datenanalyse als Übersicht und weniger als eine Tabelle, die ich Dritten wiedergebe.
R Code [zeigen / verbergen]
datasummary_crosstab(infected ~ feeding * stage,
data = flea_model_tbl)| sugar_water | blood | ketchup | ||||||
|---|---|---|---|---|---|---|---|---|
| infected | adult | juvenile | adult | juvenile | adult | juvenile | All | |
| healthy | N | 6 | 3 | 0 | 3 | 8 | 1 | 21 |
| % row | 28.6 | 14.3 | 0.0 | 14.3 | 38.1 | 4.8 | 100.0 | |
| infected | N | 2 | 5 | 8 | 5 | 0 | 7 | 27 |
| % row | 7.4 | 18.5 | 29.6 | 18.5 | 0.0 | 25.9 | 100.0 | |
| All | N | 8 | 8 | 8 | 8 | 8 | 8 | 48 |
| % row | 16.7 | 16.7 | 16.7 | 16.7 | 16.7 | 16.7 | 100.0 | |
Die größte Stärke des R Paketes ist die Funktion modelsummary(). Mit der Funktion können wir direkt als Tabelle nebeneinander verschiedene Modelle miteinander vergleichen. Das ist großartig, da wir dann direkt sehen, welche Variablen einen Einfluss hätten und wie sich der Einfluss ändert, wenn wir eine andere Einflussvariable mit ins Modell nehmen. Dafür nehmen wir alle Modelle einmal in eine Liste. Die Liste numeriere ich dan meistens einmal kurz durch, damit haben wir dann die Namen der Modelle. Dann können wir gleich die Liste der Modelle nebeneinanderstellen.
R Code [zeigen / verbergen]
model_lst <- list(
"I" = lm(jump_length ~ feeding + stage, data = flea_model_tbl),
"II" = lm(jump_length ~ feeding * stage, data = flea_model_tbl),
"III" = lm(jump_length ~ feeding * stage + weight, data = flea_model_tbl)
)Jetzt nehmen wir die Liste der Modelle und dann dann können wir noch viele Optionen mitgeben. Da hilft dann die Hilfeseite der Funktion weiter. Hier will ich dann einmal auf eine Stelle runden, dann den Intercept aus den Koeffizienten nicht anzeigen und auch nur einen Teil der Gütekriterien der Modelle anzeigen lassen. Hier geht dann noch viel mehr, aber es ist super um Modelle aus einem multiplen Modell miteinander zu vergleichen. Auch kannst du die statistischen Tests rechnen lassen und dir verschiedene Statistiken anzeigen lassen, aber das ist dann hier zu viel.
R Code [zeigen / verbergen]
modelsummary(model_lst,
fmt = 1,
coef_omit = "Intercept",
gof_omit = 'Log.Lik.|F|RMSE')| I | II | III | |
|---|---|---|---|
| feedingblood | 37.9 | 20.7 | 27.0 |
| (10.7) | (14.8) | (15.7) | |
| feedingketchup | 31.7 | 13.2 | 20.3 |
| (10.7) | (14.8) | (16.0) | |
| stagejuvenile | 5.8 | -17.9 | 0.8 |
| (8.7) | (14.8) | (21.9) | |
| feedingblood × stagejuvenile | 34.3 | 26.1 | |
| (21.0) | (22.0) | ||
| feedingketchup × stagejuvenile | 37.0 | 27.0 | |
| (21.0) | (22.6) | ||
| weight | 1.5 | ||
| (1.3) | |||
| Num.Obs. | 48 | 48 | 48 |
| R2 | 0.253 | 0.316 | 0.337 |
| R2 Adj. | 0.202 | 0.234 | 0.241 |
| AIC | 469.4 | 469.1 | 469.6 |
| BIC | 478.7 | 482.2 | 484.6 |
Wenn es um Modellvergleiche geht, dann komme ich nicht um {modellsummary} vorbei. Es ist super praktisch die Modelle nebeneinander zu stellen. Hier gibt es dann aber so viele Optionen, dass du dann immer schauen musst, was du denn brauchst. Du kannst dir p-Werte oder Konfidenzintervalle anzeigen lassen. Oder aber den Standardfehler zusammen mit den Koeffizienten. Hier gibt es dann wirklich viele Optionen. Schaue dir einmal die Hilfeseite von modelsummary() an.
53.6.3 … mit {parsnip}
Das R Paket {parsnip} ist ohne die Modellwelt {tidymodels} nicht zu denken. Wir können noch so viel mehr, wen wir das Paket auch mit dem R Paket {recipes} und anderen Paketen verbinden. Dazu dann aber mehr in den Kapiteln zu der Klassifikation sowie dem maschinellen Lernen. Hier konzentriere ich mich einmal auf das Paket alleine und gehe einmal die Nutzung durch. Beachte bitte, dass das Paket eher für die Vorhersage gebaut ist und nicht so sehr für erklärende Modelle oder gar rein faktorielle Experimente.
HinweisModellkonzept in
{parsnip}
In der folgenden Tabelle findest du einmal die drei Schritte für eine Modellierung in {parsnip}. Wir suchen uns erst die Modellfunktion, dann entscheiden wir uns für den Algorithmus und abschließend passen wir das Modell an.
| Beschreibung | Beispiel | |
|---|---|---|
| (1.) | Wähle ein Modell aus der Liste der Modelle mit der entsprechenden Funktion. | linear_reg() |
| (2.) | Entscheide dich für einen Algorithmus (eng. engine) mit dem du das Modell rechnen willst. | set_engine("lm") |
| (3.) | Passe das Modell mit der entsprechenden Formelschreibweise an. | fit(y ~ x) |
Es geht dann immer noch komplizierter. Schaue dir auch mal dazu dann das R Paket {recipes} an. Hier kannst du dann ganze Workflows bauen.
Dann zeige ich hier einmal den Dreiklang aus dem ein Aufruf in {parsnip} besteht. Als Vorteil ist zum einen zu nennen, dass wir hier alles sauber pipen können. Wir brauchen also keine zusätzlichen Klimmzüge machen. Dann haben wir es ziemlich einfach, wenn wir zum Beispiel mal den Algorithmus ändern wollen oder aber die Formelschreibweise anpassen müssen. Am Ende sind alle Optionen gleich. Das heißt egal welchen Algorithmus wir aufrufen wir haben immer die gleichen Optionsnamen. Das ist natürlich super und wir müssen nicht immer alle Optionsnamen im Kopf haben. Hier also einmal eine einfaktorielle Modellierung.
R Code [zeigen / verbergen]
linreg_reg_fit <- linear_reg() |>
set_engine("lm") |>
fit(jump_length ~ feeding, data = flea_model_tbl) Wenn du dir die Ausgabe anschaust, dann sieht die Ausgabe so ziemlich gleich wie mit lm() alleine aus. Nur das du hier eben dann in der {tidymodels}-Welt weitermachen kannst. Hier möchte ich dann nochmal auf das Openbook Tidy Modeling with R verweisen, da es diesen Abschnitt sprengen würde, wenn wir alles anschauen. Hier kannst du dann auch gerne nochmal tbl_summary() oder modelsummary() ausprobieren. Beide Funktionen fassen die Koeffizinten gut zusammen. Du findest mehr zu den beiden Funktionen in den Abschnitten weiter oben.
R Code [zeigen / verbergen]
linreg_reg_fitparsnip model object
Call:
stats::lm(formula = jump_length ~ feeding, data = data)
Coefficients:
(Intercept) feedingblood feedingketchup
70.01 37.86 31.69 Wenn wir dann eine ANOVA rechnen wollen oder gr einen multiplen Vergleich, dann müssen wir noch einen Extraschritt gehen. In dem Tutorium Tidymodels, interactions and anova - a short tutorial erhalten wir dann nochmal die Hilfestellung mit der Funktion extract_fit_engine(). Mit der Funktion können wir dann die Informationen extrahieren, die wir dann in den folgenden Funktionen brauchen. Hier einmal die Anwendung mit der Funktion anova() oer eben auch aov().
R Code [zeigen / verbergen]
linreg_reg_fit|>
extract_fit_engine() |>
anova()Analysis of Variance Table
Response: jump_length
Df Sum Sq Mean Sq F value Pr(>F)
feeding 2 13206 6602.9 7.3041 0.00179 **
Residuals 45 40680 904.0
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Oder eben auch mit {emmeans}, wenn wir dann die multiplen Vergleiche rechnen wollen. Auch hier kann es je nach Algorithmus noch zu einem Problem kommen. Ich nutze {parsnip} eher selten im Kontext des multiplen Testens. Wir tauschen selten die Algorithmen einmal durch. Da ist dann das folgende Beispiel weiter unten mit {purrr} eventuell interessanter.
R Code [zeigen / verbergen]
linreg_reg_fit|>
extract_fit_engine() |>
emmeans(~ feeding) feeding emmean SE df lower.CL upper.CL
sugar_water 70 7.52 45 54.9 85.1
blood 108 7.52 45 92.7 123.0
ketchup 102 7.52 45 86.6 116.8
Confidence level used: 0.95 Eine detailliertere Einführung mit mehr Beispielen für die Nutzung findest du dann unter R Paket {parsnip} - Beispiele. Bitte beachte, dass wir es hier mehr mit Vorhersagen als mit erklärenden Modellen zu tun haben. Daher ist eben auch der Fokus auf die Klassifikation gelegt und nicht auf erklärende Modelle. Aber wie immer im Leben, man kann nicht alles auf einmal haben.
53.6.4 … mit {ggeffects}
“Package
{ggeffects}is in maintenance mode and will be superseded by the{modelbased}-package from the{easystats}-project.” —{ggeffects}in maintenance mode
Das R Paket {ggeffects} geht ein wenig in dem R Paket {modelbased} auf. Ich finde aber immer noch, dass wir mit {ggeffects} ein paar gute Sachen machen können. Die Idee ist nämlich sich auf die vorhergesagten Messwerte aus dem Modell zu konzentrieren und nicht die Koeffizienten zu interpretieren. Wie du vielleicht aus anderen Kapiteln weißt, ist die Interpretation von Koeffizienten aus einem multiplen Modell nicht so einfach. Insbesondere nicht wenn wir kombinierte Modelle mit Faktoren und Kovariaten vorliegen haben. Da ist es dann meist einfacher nach den vorhergesagten Werten zu schauen und dann über diese Werte eine Aussage über die wissenschaftliche Fragestellung zu treffen. Wie immer sind die Möglichkeiten weitreichend, so dass ich hier nur einen kleinen Teil vorstelle.
“Warum habe ich hier nochmal
{ggeffects}vorgestellt, wenn es doch mit{modelbased}ein neueres Paket gibt? Zum einen da ich die Visualisierungen sehr schön finde und zum anderen da die Hilfeseite nochmal für mich etwas leichter zu lesen war. Oder andersherum, nachdem ich mich mit der Seite von{ggeffects}beschäftigt hatte, war{modelbased}einfacher für mich.” — Jochen Kruppa-Scheetz, meiner bescheidener Meinung nach.
Wie immer brauchen wir erstmal ein Modell auf das wir dann die Funktionen anwenden können. Ich habe hier einmal das Modell genommen in dem wir den Entwicklungsstand und das Gewicht der Flöhe vorliegen haben. Dann rechnen wir einmal das multiple Modell.
R Code [zeigen / verbergen]
fit <- lm(jump_length ~ stage * weight, data = flea_model_tbl)Jetzt können wir uns einmal die Sprungweiten für die adulten Flöhe wiedergeben lassen. Das ist selten dass was wir wollen wir haben ja noch die juvenilen Flöhe mit in dem Modell. Auch hier ist immer die Frage, für was möchtest du adjustieren und was soll schlussendlich mit ins Modell und gezeigt werden.
R Code [zeigen / verbergen]
predict_response(fit, term = "weight")# Predicted values of jump_length
weight | Predicted | 95% CI
----------------------------------
2 | 83.04 | 45.42, 120.66
4 | 84.24 | 51.95, 116.53
8 | 86.64 | 64.30, 108.99
12 | 89.05 | 74.02, 104.07
14 | 90.25 | 76.45, 104.04
16 | 91.45 | 76.54, 106.36
20 | 93.85 | 71.75, 115.95
26 | 97.45 | 60.12, 134.79
Adjusted for:
* stage = adultUm beide Entwicklungsstände einmal zu sehen, können wir dann noch den Entwicklungsstand in der Vorhersage der Sprungweiten ergänzen. Dann erhalten wir auch getrennt für die beiden Gruppen die Sprungweiten wiedergegeben. Mit der Option "weight [mean]" könnten wir uns auch nur die Sprungweiten der beiden Entwicklungsstände für das mittlere Gewicht wiedergeben lassen.
R Code [zeigen / verbergen]
predict_response(fit, term = c("weight", "stage"))# Predicted values of jump_length
stage: adult
weight | Predicted | 95% CI
----------------------------------
2 | 83.04 | 45.42, 120.66
6 | 85.44 | 58.29, 112.59
10 | 87.85 | 69.71, 105.98
14 | 90.25 | 76.45, 104.04
18 | 92.65 | 74.72, 110.58
26 | 97.45 | 60.12, 134.79
stage: juvenile
weight | Predicted | 95% CI
----------------------------------
2 | 65.81 | 29.92, 101.69
6 | 97.25 | 83.40, 111.10
10 | 128.69 | 90.47, 166.90
14 | 160.12 | 88.76, 231.49
18 | 191.56 | 86.25, 296.87
26 | 254.44 | 80.72, 428.15Dann können wir auch den paarweisen Vergleich der beiden Entwicklungsstände adjustiert für das mittlere Gewicht rechnen. Auch hier musst du darauf achten, dass du das volle Modell anpasst. Also auch mit allen Interaktionstermen. Sonst kommt hier nichts sinnvolles raus oder eben eine Mittelwertsdifferenz von Null.
R Code [zeigen / verbergen]
predict_response(fit, term = c("weight", "stage")) |>
test_predictions()# Pairwise comparisons
stage | Contrast | 95% CI | p
------------------------------------------------
adult-juvenile | -7.26 | -16.33, 1.81 | 0.114Mit der Option by = stage können wir uns dann auch die Steigungen der Sprungweiten an den mittleren Gewichten für die beiden Entwicklungsstände anschauen. Dann kriegen wir aber keinen paarweisen Vergleich mehr wiedergeben sondern eben die Steigung über die Flohgewichte getrennt für die Entwicklungsstände. Wenn du oben die Interaktion im Modell vergisst, dann ist die Steigung in den beiden Entwicklungsständen gleich.
R Code [zeigen / verbergen]
predict_response(fit, term = c("weight", "stage")) |>
test_predictions(by = "stage")# (Average) Linear trend for weight
stage | Slope | 95% CI | p
---------------------------------------
adult | 0.60 | -2.30, 3.50 | 0.679
juvenile | 7.86 | -0.74, 16.46 | 0.072Dann ist auch häufig die Frage, was diese Steigungen sein sollen. Das können wir uns dann einmal leicht in der folgenden Abbildung anschauen. Wir haben dann einmal die Steigung der Sprungweiten über die Flohgewichte getrennt für die beiden Entwicklungsstände dargestellt. Wir sehen hier sehr schön, dass Steigung für die juvenilen Flöhe viel größer ist als für die adulten Flöhe. Ich habe dann noch Optionen aus {ggplot} ergänzt.
R Code [zeigen / verbergen]
predict_response(fit, term = c("weight", "stage")) |>
plot(show_data = TRUE) +
labs(x = "Gewicht in [mg]", y = "Sprungweite in [cm]",
color = "Entwicklungsstand") +
theme(legend.position = "top")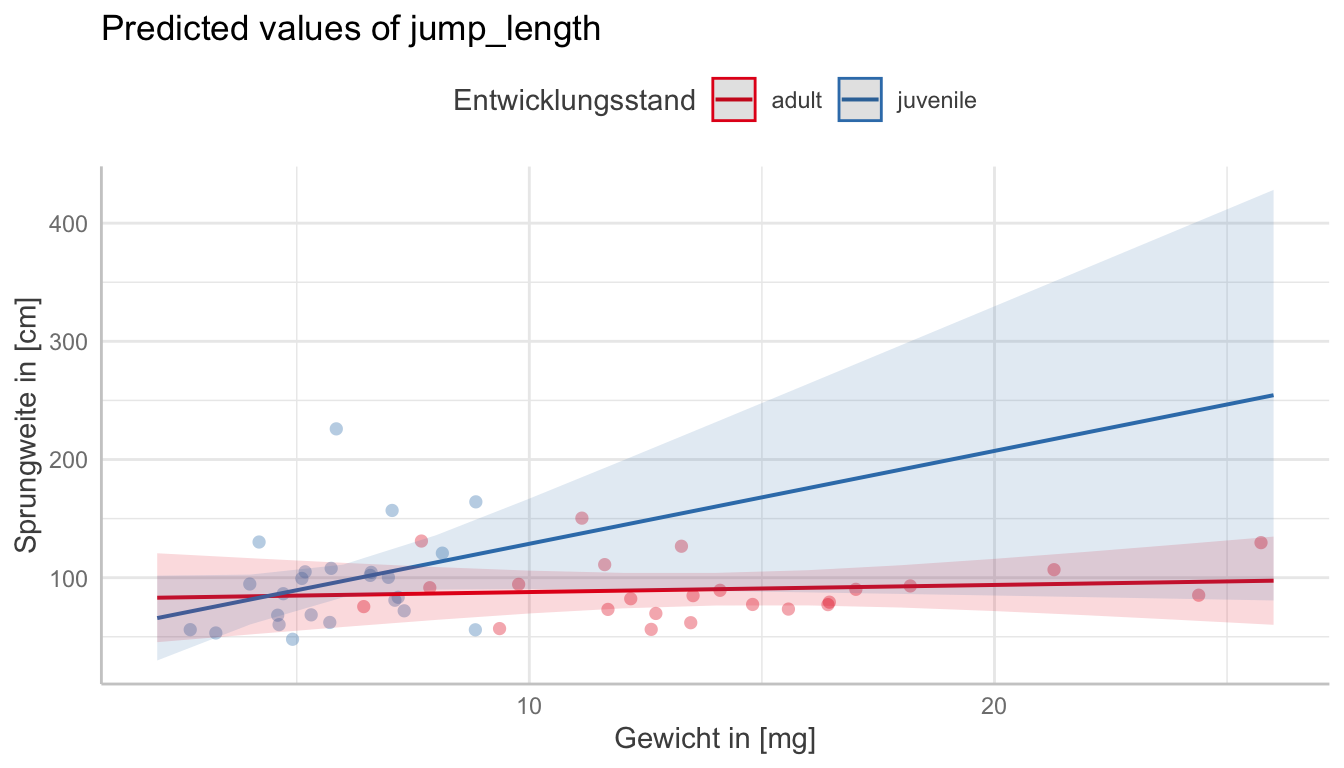
Manchmal Fragen wir uns auch, ob die lineare Modellierung wirklich das beste Modell ist. Daher können wir uns auch einmal die Residuen aus dem Modell anschauen und sehen wie sich die Residuen verteilen. Hier sehen wir, dass wir eine leichte Abweichung haben, aber die Residuen sich relativ gut um die Grade des Modells bewegen. Ich würde hier also keine quadratische Anpassung vornehmen. Mehr zu der Problematik kannst du in der Vignette Introduction: Adding Partial Residuals to Adjusted Predictions Plots nachlesen.
R Code [zeigen / verbergen]
predict_response(fit, terms = c("weight", "stage")) |>
plot(show_residuals = TRUE, show_residuals_line = TRUE) +
labs(x = "Gewicht in [mg]", y = "Sprungweite in [cm]",
color = "Entwicklungsstand") +
theme(legend.position = "top")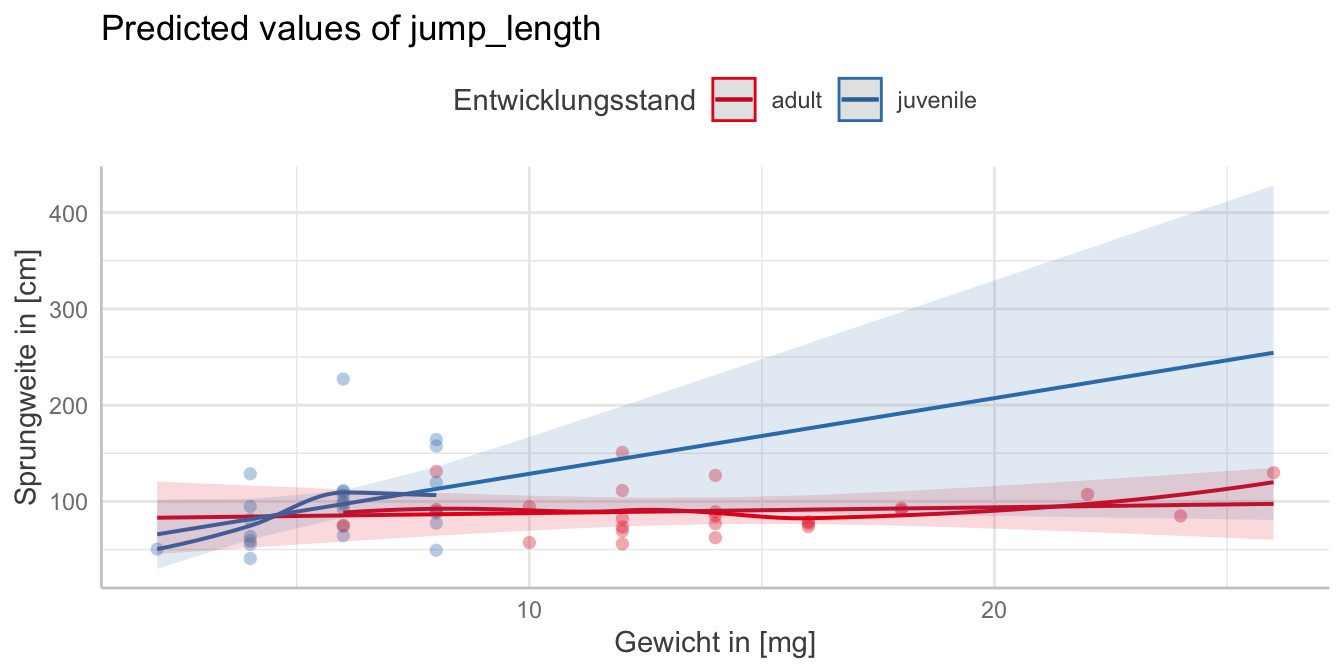
Am Ende ist es dann die Frage wie du hier weiter machen willst, dann empfehle ich dir nochmal in das R Paket R Paket {modelbased} oder eben in das Kapitel zu den Marginal effects models nachzuschauen. Ich mache hier dann einmal Schluss, da es dann wirklich den Rahmen dieses Einführungskapitels sprengen würde. Nehme als Idee mit, dass du neben den Koeffizienten auch die Vorhersagen betrachten kannst.
53.6.5 … mit {purrr}
Was macht das R Paket {purrr} so besonders? Wir können mit dem R Paket eine Menge auf Listen rechnen. Wir müssen uns also nicht mehr die Mühe machen für jeden Messwert \(Y\) ein eigenes Modell zu bauen sondern können alles was wir brauchen in einer Liste ablegen. Hier ist der Optimierung keine Grenzen gesetzt, die ich mir hier aber setze. Ich werde immer das gleiche Modell mit den selben Einflussvariablen auf die verschiedenen Messwerte rechnen. Wenn das auch geändert wird, dann wird es etwas wilder. Das geht aber auch, du musst dir dann eben zwei Listen bauen. Einmal eine Liste mit den Modellen in Formelschreibweise und einmal die Liste mit den Verteilungsfamilien.
Die zentrale Funktion in {purrr} ist map(). Wir können mit map() unterschiedliche andere Funktionen auf eine Liste anwenden. Wenn wir dabei über zwei Listen iterieren wollen, also für mehrere Endpunkte wie bei den Flohdaten, dann nutzen wir die Funktion map2(). Mit map2() können wir die Verteilungsfamilie in glm() zusätzlich anpassen, wenn wir unterschiedliche Messwerte haben. Wir bauen hier einmal die Familien für die Messwerte in den Flohdaten. Hier ist es ganz wichtig, dass wir die Messwerte alphanumerisch sortieren! Sonst kriegen wir nachher Probleme bei dem Aufruf von map2(). Wir setzen hier also die Anzahl der Haare auf die Poissonverteilung, den Infektionsstatus auf die Binomialverteilung und die Sprungweite auf die Normalverteilung. Das ist dann die Liste mit den Verteilungsfamilien.
R Code [zeigen / verbergen]
family_lst <- lst(count_leg = quasipoisson(),
infected = binomial(),
jump_length = gaussian())Dann bauen wir noch unseren Datensatz. Hierzu entfernen wir einmal die Boniturnoten, da wir die Boniturnoten nicht mit einem glm() auswerten können. Das müssen wir dann extra machen. Die Infektionszeit müssen wir wieder numerisch machen, damit wir eine Spalte mit numerischen Werten haben. Ein Faktor wird durch die Umwandlung in numerisch zu 1/2 anstatt von 0/1. Daher ziehen wir dann nochmal -1 von den Werten des umgewandelten Faktors ab. Dann bauen wir noch einen Long-Formatdatensatz und schreiben die Namen der Messwerte in eine Spalte outcome und die Werte in die Spalte rsp. Dann sortieren wir nochmal alles wieder alphanumerisch und sind soweit fertig.
R Code [zeigen / verbergen]
flea_long_tbl <- flea_model_tbl |>
mutate(infected = as.numeric(infected)-1) |>
select(-bonitur) |>
pivot_longer(cols = jump_length:last_col(),
names_to = "outcome",
values_to = "rsp") |>
arrange(outcome, feeding, stage)Die zentrale Idee ist, dass wir unseren Datensatz nach den Messwerten in der Spalte outcome aufteilen. Durch die Funktion split() erhalten wir eine Liste mit den jeweiligen Messwerten in einem Listeneintrag. Aber Achtung, die Liste ist immer alphanumerisch sortiert. Egal wie du die Messwerte sortiert hast. Daher immer auch die Familienliste oben alphanumerisch sortieren.
R Code [zeigen / verbergen]
flea_lst <- flea_long_tbl |>
split(~ outcome)Dann können wir uns auch schon zu der Regression begeben. Hier haben wir die Liste der Messwerte die wir in die Funktion map2() pipen. Dann brauchen wir noch die Familienliste und den Aufruf der Funktion glm() für die Regression. Die Werte aus der ersten Liste sprechen wir mit .x und die Werte aus der zweiten Liste mit .y an. Dann haben wir einmal alle Modelle gerechnet und können die Ergebnisse anschauen.
R Code [zeigen / verbergen]
glm_lst <- flea_lst |>
map2(family_lst,
~glm(rsp ~ feeding + stage + feeding:stage,
data = .x, family = .y))Am besten dann nochmal nachschauen ob wir auch wirklich die richtigen Verteilungsfamilien zu den Messwerten zugeordnet haben. Hier sehen wir dann auch, dass es gut geklappt hat. Dann rechnen wir auf allen Modellen einmal eine ANOVA aus dem R Paket {car}. Im letzten Tab schauen wir uns dann einmal die Anwendung in {emmeans} an. Am Ende ist es dann immer die Frage, ob wir dass alles so über alle Listeneinträge wollen oder nicht doch besser die Listeneinträge einzeln bearbeiten. Aber das soll ja hier nicht die Frage sein.
Als erstes prüfen wir einmal ob wir dann alle Messwerte mit den richtigen Verteilungsfamilien angepasst haben. Zwar gibt es auch Fehlermeldungen, wenn es überhaupt nicht passt, aber häufig gehen viele Verteilungen algorithmisch auch auf Messwerte, die nicht dieser Verteilung folgen.
R Code [zeigen / verbergen]
glm_lst |>
map(pluck, "family")$count_leg
Family: quasipoisson
Link function: log
$infected
Family: binomial
Link function: logit
$jump_length
Family: gaussian
Link function: identity Das sieht doch super aus. Jeder Messwert hat die Verteilung, die wir auch dann am Anfang ausgewählt haben. Es ist immer gut nochmal alles zu überprüfen.
Dann können wir auch einmal eine ANOVA auf allen Messwerten rechnen. Ob das jetzt so eine gute Idee ist auch Messwerte mit einer ANOVA zu testen, die eben dann keiner Normalverteilung folgen, ist eine andere Frage. Es geht dann aber. Und auch hier können wir die ANOVA Funktion austauschen. Dazu dann mehr in den Kapiteln zu der ANOVA und deren Varianten. Hier geht es mehr darum, dass es so geht.
R Code [zeigen / verbergen]
glm_lst |>
map(car::Anova)$count_leg
Analysis of Deviance Table (Type II tests)
Response: rsp
LR Chisq Df Pr(>Chisq)
feeding 30.222 2 2.737e-07 ***
stage 22.772 1 1.824e-06 ***
feeding:stage 11.085 2 0.003916 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
$infected
Analysis of Deviance Table (Type II tests)
Response: rsp
LR Chisq Df Pr(>Chisq)
feeding 7.1530 2 0.0279734 *
stage 4.8797 1 0.0271739 *
feeding:stage 18.2272 2 0.0001102 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
$jump_length
Analysis of Deviance Table (Type II tests)
Response: rsp
LR Chisq Df Pr(>Chisq)
feeding 15.0436 2 0.0005412 ***
stage 0.4632 1 0.4961163
feeding:stage 3.8778 2 0.1438635
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Hier kommen wir dann nochmal zu komplexeren Beispielen in dem wir dann einmal das R Paket {emmeans} für die paarweisen Vergleiche anwenden. Dafür brauchen wir dann einmal eine Liste mit {emmeans}-Objekten in denen wir dann die Vergleiche definieren. Ich mache hier einmal alles nur einfaktoriell sonst wird die Ausgabe noch länger.
R Code [zeigen / verbergen]
emm_lst <- glm_lst |>
map(~emmeans(.x, specs = ~ feeding, type = "response"))Dann können wir auch alle paarweisen Vergleiche rechnen. Dann wollen wir noch alles als ein tibble-Objekt vorliegen haben. Am Ende machen wir dann ein Datensatz aus der Liste und ergänzen noch eine Spalte mit den Messwerten. Schon an der Grenze zu kaum lesbar, aber schon schick, dass es so geht. Ich würde am Ende noch mit select() etwas in den Spalten aufräumen und nur die nehmenm die mich dann auch interessieren.
R Code [zeigen / verbergen]
emm_lst |>
map(~contrast(.x, method = "pairwise", adjust = "bonferroni")) |>
map(as_tibble) |>
bind_rows(.id = "outcome")# A tibble: 9 × 11
outcome contrast ratio SE df null z.ratio p.value odds.ratio
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 count_leg sugar_wat… 0.213 9.07e- 2 Inf 1 -3.64 8.31e-4 NA
2 count_leg sugar_wat… 0.238 1.04e- 1 Inf 1 -3.27 3.17e-3 NA
3 count_leg blood / k… 1.11 3.06e- 1 Inf 1 0.393 1 e+0 NA
4 infected sugar_wat… NA 6.19e- 2 Inf 1 -0.00544 1 e+0 3.26e-5
5 infected sugar_wat… NA 9.50e+ 6 Inf 1 0.00448 1 e+0 4.99e+3
6 infected blood / k… NA 4.12e+11 Inf 1 0.00701 1 e+0 1.53e+8
7 jump_length sugar_wat… NA 1.05e+ 1 42 NA NA 2.40e-3 NA
8 jump_length sugar_wat… NA 1.05e+ 1 42 NA NA 1.27e-2 NA
9 jump_length blood - k… NA 1.05e+ 1 42 NA NA 1 e+0 NA
# ℹ 2 more variables: estimate <dbl>, t.ratio <dbl>Wir können auch das Compact letter display uns erstellen lassen. Das ist gar nicht mehr so viel komplizierter. Am Ende kann die Liste sehr lang werden, hier haben wir dann mit den wenigen Messwerten und dem einfaktoriellen Design eben noch Glück.
R Code [zeigen / verbergen]
emm_lst |>
map(~cld(.x, Letters = letters, adjust = "bonferroni")) |>
map(as_tibble) |>
bind_rows(.id = "outcome") |>
select(outcome, feeding, .group)# A tibble: 9 × 3
outcome feeding .group
<chr> <fct> <chr>
1 count_leg sugar_water " a "
2 count_leg ketchup " b"
3 count_leg blood " b"
4 infected ketchup " a"
5 infected sugar_water " a"
6 infected blood " a"
7 jump_length sugar_water " a "
8 jump_length ketchup " b"
9 jump_length blood " b" Braucht man {purrr} um so viele Modelle nacheinander durchzurechnen? Sicherlich nicht. Du kannst dir auch über Copy&Paste alles zusammenbauen und dann nacheinander rechnen. Häufig macht das auch mehr Sinn, da sich die Messwerte meist auch von der Darstellung unterscheiden. Dann hast du einen Abschnitt oder aber eine Datei für einen Messwert und alles hat seine Ordnung. Ich habe dieses Verfahren gerne genutzt, wenn es wirklich viele Messwerte waren und wir rausfinden wollten, ob überhaupt was interessantes in den Daten vorlag.
Referenzen
Wilkinson, G., & Rogers, C. (1973). Symbolic description of factorial models for analysis of variance. Journal of the Royal Statistical Society Series C: Applied Statistics, 22(3), 392–399.