“Beyond this place there be dragons (lat. Hic sunt dracones)” — Captain Picard, Star Trek: The Next Generation, Where Silence Has Lease
Beginnen wir mit dem, was du als erstes vorliegen hast. Daten. Sehr häufig in einer Exceltabelle abgelegt. Und dann beginnen auch schon die Herausforderungen. Was sind eigentlich Daten in R? Was ist eigentlich das Problem mit den Buchstaben und Zahlen? Anscheinend haben Programmiersprachen ein Problem Zahlen und Buchstaben auseinander zuhalten. Eigentlich eher die Arten von Zahlen und Buchstaben die es so gibt. Es gibt nicht nur die eine Zahl und den einen Buchstaben. Je nach Kontext hat eine Zahl und ein Buchstabe eine andere Bedeutung. In den vorherigen Beispielen haben wir uns die Sprungweiten und andere Eigenschaften von Hunden und Katzen angeschaut. Bevor wir uns weiter mit statistischen Kennzahlen beschäftigen, wollen wir uns einmal die Realisierung des Beispiels in R anschauen. Das heißt, wie ist eine Tabelle in R aufgebaut und was sehen wir da eigentlich? Hier siehst du nochmal die Tabelle, wie wir die Tabelle in Microsoft Word darstellen würden.
Tabelle 9.1— Tabelle von sieben Hunde- und Katzenflöhen mit der Sprunglänge [cm], Anzahl an Haaren am rechten Flohbein, Gewicht der Flöhe, Boniturnote sowie der Infektionsstatus für Flohschnupfen. Die erste Spalte animal gibt an, dass wir es hier mit Hunde- und Katzenflöhe zu tun haben. Die Tabelle ist im Long-Format dargestellt.
animal
jump_length
flea_count
weight
grade
infected
dog
5.7
18
2.1
8
FALSE
dog
8.9
22
2.3
8
TRUE
dog
11.8
17
2.8
6
TRUE
dog
5.6
12
2.4
8
FALSE
dog
9.1
23
1.2
7
TRUE
dog
8.2
18
4.1
7
FALSE
dog
7.6
21
3.2
9
FALSE
cat
3.2
12
1.1
7
TRUE
cat
2.2
13
2.1
5
FALSE
cat
5.4
11
2.4
7
FALSE
cat
4.1
12
2.1
6
FALSE
cat
4.3
16
1.5
6
TRUE
cat
7.9
9
3.7
6
FALSE
cat
6.1
7
2.9
5
FALSE
Wir wollen jetzt an der Datentabelle die Besonderheiten von Zahlen und Buchstaben in einer Programmiersprache verstehen. Da wir uns jetzt hier mit der Programmiersprache R beschäftigen wollen, konzentrieren wir uns auf den Fall R. In anderen Programmiersprachen ist die Sachlage ähnlich aber nicht unbedingt gleich. Dabei wollen wir insbesondere die Eigenschaften von Zahlen und Buchstaben lernen, die notwendig sind um mit einem Programm wie R kommunizieren zu können. Nun haben wir in der Tabelle 9.1 mit Daten zu verschiedenen Outcomes, wie Sprungweite [cm], Anzahl an Flöhen auf Hunden und Katzen, die Boniturnoten oder aber den Infektionsstatus. Die Tabelle ist zwar nicht groß aber auch nicht wirklich klein. Wir wollen uns nun damit beschäftigen, die Zahlen sinnvoll in R darzustellen. Wir wollen mit der Darstellung einer Datentabelle in R beginnen, einem tibble.
HinweisEin tibble ist tidy (deu. sauber)
Das Datenformat, was wir hier erarbeiten wollen, nennen wir auch tidy (deu. sauber) nach dem R Paket tidyr was dann auch später mit die Basis für unsere Analysen in R sein wird. Wenn ein Datensatz tidy ist, dann erfüllt er folgende Bedingungen.
Jede Variable ist eine Spalte; jede Spalte ist eine Variable.
Jede Beobachtung ist eine Zeile; jede Zeile ist eine Beobachtung.
Jeder Wert ist eine Zelle; jede Zelle ist ein einziger Wert.
Nach diesen Regeln bauen wir dann jeden Datensatz auf, den wir in einem Experiment gemessen haben.
9.1 Daten als tibble in R
Im Folgenden sehen wir die Daten aus der obigen Tabelle 9.1 in R als tibble dargestellt. Was ist nun ein tibble? Ein tibble ist zu aller erst ein Speicher für Daten in R. Das ist immer sehr abstrakt, deshalb einmal in der Abbildung 9.1 die Idee des tibbles als Datenspeicher in der Analogie eines Schranks. Ein tibble ist ein leerer Schrank, in den du dann Daten hängen kannst.
(a) Ein leerer tibble ist wie ein Schrank der befüllt werden kann.
(b) Ein tibble mit drei Variablen, die wie Kleiderbügel in den Schrank hängen.
Abbildung 9.1— Ein tibble ist ein interner Speicher für Daten in R. Du kannst dir da auch einen leeren Schrank vorstellen. In den Schrank können wir dann Klamotten aufhängen. Statt Klamotten nennen wir die aufgehängten Dinge dann in R Variablen.
Dann können wir natürlich auch die Idee etwas komplexer Darstellen. Dabei ist ein tibble erstmal ein Begriff für eine Form die Daten abzuspeichern. So wie es bei IKEA im Sortiment einen Paxschrank zu kaufen gibt, aber natürlich dein Paxschrank zu Hause nicht der einzige Paxschrank ist. In der folgenden Abbildung siehst du dann einmal einen den Datensatz flea_tbl als ein tibble als einen Kleiderschrank mit vier Beobachtungen für drei Variablen abgebildet.
Abbildung 9.2— Darstellung des Datensatzes flea_tbl als Kleiderschrank für die Variablen jump_length, flea_count und weight. Es werden nur die ersten vier Beobachtungen dargestellt. Der Kleiderbügel $ hält eine Variable in dem Datensatz flea_tbl.
Wie lagern wir jetzt aber in einem tibble unsere Daten? Eigentlich genau so wie auch in einer Tabelle in Excel. Das heißt wir lagern unsere Daten in Spalten und Zeilen. Jede Spalte repräsentiert eine Messung oder Variable und die Zeilen jeweils eine Beobachtung. Damit ist das Datenformat tibble auch tidy (deu. sauber) nach dem R Paket tidyr. Wir wollen immer einen tidy Datensatz, bevor es mit der Analyse los geht. Ein tidy Datensatz ist dann auch später die Basis für unsere Analysen in R. Wenn ein Datensatz tidy ist, dann erfüllt er folgende Bedingungen.
Jede Variable ist eine Spalte; jede Spalte ist eine Variable.
Jede Beobachtung ist eine Zeile; jede Zeile ist eine Beobachtung.
Jeder Wert ist eine Zelle; jede Zelle ist ein einziger Wert.
Im Folgenden siehst du den Datensatz flea_tbl einmal ausgegeben.
Schauen wir uns also ein tibble() der obigen Datentabelle einmal näher an. Als erstes erfahren wir, dass wir einen A tibble: 14 x 6 vorliegen haben. Das heißt, wir haben 14 Zeilen und 6 Spalten. In einem tibble wird immer in der ersten Zeile angezeigt wie viele Beobachtungen wir in dem Datensatz haben. Wenn das tibble zu groß wird, werden wir nicht mehr das ganze tibble sehen sondern nur noch einen Ausschnitt. Im Weiteren hat jede Spalte noch eine Eigenschaft unter dem Spaltennamen:
<chr> bedeutet character. Wir haben also hier Worte vorliegen.
<dbl> bedeutet double. Ein double ist eine Zahl mit Kommastellen.
<int> bedeutet integer. Ein integer ist eine ganze Zahl ohne Kommastellen.
<lgl> bedeutet logical oder boolean. Hier gibt es nur die Ausprägung wahr oder falsch. Somit TRUE oder FALSE. Statt den Worten TRUE oder FALSE kann hier auch 0 oder 1 stehen.
<str> bedeutet string der aus verschiedenen character besteht kann, getrennt durch Leerzeichen.
In der folgenden Analogie zum Kleiderschrank nochmal die Idee der Eigenschaften eines Kleiderbügels. Wir können nur gleiche Dinge an einen Kleiderbügel in einen Schrank hängen. So dürfen an dem Kleiderbügel animal nur Worte sein. Es ist ein Kleiderbügel für character oder eben abgekürzt <chr>.
Abbildung 9.3— Jeder Kleiderbügel kann nur einen Typ von Dingen an sich hängen haben. Welche das sind, beschreibt dann immer die Abbkürzung über dem Kleiderbügel.
Wieso ist das jetzt eigentlich wichtig? Wir sehen hier, was R glaubt in den Spalten an Zahlen und Buchstaben vorzufinden. Das mag stimmen, es kann aber auch falsch sein. R ist da manchmal nicht so schlau. Es mag aber sein, dass R sich irrt. Dann müssen wir die Eigenschaften der Spalte ändern. Das ändern von Eigenschaften machen wir mit der Funktion mutate(). Dazu aber dann mehr im Kapitel Daten bearbeiten, wo cih die verschiednenen Funktionen zur Modifikation von einem tibble vorstelle.
9.2 Faktoren als Wörter zu Zahlen
Ein Computer und somit auch eine Programmsprache wie R kann keine Buchstaben verrechnen. Wie soll das auch gehen. Was ist "A" plus "T" oder aber "hund" plus "katze"? Das ergibt keinen Sinn für eine Maschine. Ein Computerprogramm wie R eines ist kann nur mit Zahlen rechnen. Wir haben aber in der obigen Tabelle 9.1 in der Spalte animal Buchstaben stehen. Da wir hier einen Kompromiss eingehen müssen führen wir Faktoren ein. Ein Faktor kombiniert Buchstaben mit Zahlen. Wir als Anwender sehen die Buchstaben, die Wörter bilden. Intern steht aber jedes Wort für eine Zahl, so dass R mit den Zahlen rechnen kann oder aber erkennt, dass es sich um eine Gruppe handelt. Ein Faktor ist eine Variable mit mehreren Faktorstufen oder Leveln. Für uns sieht der Faktor wie ein Wort aus, hinter jedem Wort steht aber eine Zahl mit der gerechnet werden kann. Klingt ein wenig kryptisch, aber wir schauen uns einen factor einmal in R an.
Was haben wir gemacht? Als erstes haben wir die Spalte animal aus dem Datensatz flea_tbl mit dem Dollarzeichen $ herausgezogen. Mit dem $ Zeichen können wir uns eine einzelne Spalte aus dem Datensatz flea_tbl raus ziehen. Über das $ Symbol kannst du im Kapitel 10.7 mehr erfahren. In der folgenden Abbildung habe ich dir den Zusammenhang nochmal visualisiert.
Abbildung 9.4— Darstellung des Datensatzes flea_tbl als Kleiderschrank für die Variablen jump_length, flea_count und weight. Es werden nur die ersten vier Beobachtungen dargestellt. Der Kleiderbügel $ hält eine Variable in dem Datensatz flea_tbl.
Du kannst dir das $ wie einen Kleiderbügel und das flea_tbl als einen Schrank für Kleiderbügel verstellen. An dem Kleiderbügel hängen dann die einzelnen Zahlen und Worte. Wir nehmen aber nicht den ganzen Vektor sondern nur die Zahlen 1 bis 8, dargestellt durch [1:8]. Die Gänsefüßchen " um dog zeigen uns, dass wir hier Wörter oder charactervorliegen haben. Schauen wir auf das Ergebnis, so erhalten wir sieben Mal dog und einmal cat. Insgesamt die ersten acht Einträge der Datentabelle. Wir wollen diesen Vektor uns nun einmal als Faktor anschauen. Wir nutzen die Funktion as_factor(). Über Funktionen kannst du im Kapitel 10.4 mehr erfahren.
R Code [zeigen / verbergen]
as.factor(flea_tbl$animal[1:8])
[1] dog dog dog dog dog dog dog cat
Levels: cat dog
Im direkten Vergleich verschwinden die Gänsefüßchen " um dog und zeigen uns, dass wir hier keine character mehr vorliegen haben. Darüber hinaus sehen wir auch, dass die der Faktor jetzt Levels hat. Exakt zwei Stück. Jeweils einen für dog und einen für cat. Wir werden später Faktoren benötigen, wenn wir zum Beispiel eine einfaktorielle ANOVA rechnen. Hier siehst du schon den Begriff Faktor wieder.
9.3 Von Wörtern und Objekten
Das mag etwas verwirrend sein, denn es gibt in R Wörter string <str> oder character <chr>. Wörter sind was anderes als Objekte. Streng genommen sind beides Wörter, aber in Objekten werden Dinge gespeichert wohin gegen das Wort einfach ein Wort ist. Deshalb kennzeichnen wir Wörter auch mit Gänsefüßchen als "wort" und zeigen damit, dass es sich hier um einen String handelt. Wir tippen "animal" in R und erhalten "animal" als Wort zurück. Das sehen wir auch an dem Ausdruck mit den Gänsefüßchen.
R Code [zeigen / verbergen]
"animal"
[1] "animal"
Wir tippen animal ohne die Anführungszeichen in R und erhalten den Inhalt von animal ausgegeben. Dafür müssen wir aber das Objekt animal erst einmal über den Zuweisungspfeil <- erschaffen. Über den Zuweisungspfeil <- kannst du im Kapitel 10.5 mehr erfahren.
R Code [zeigen / verbergen]
animal <-c("dog", "cat", "fox")animal
[1] "dog" "cat" "fox"
Sollte es das Objekt animal nicht geben, also nicht über den Zuweisungspfeil <- erschaffen worden, dann wird eine Fehlermeldung von R ausgegeben:
Fehler in eval(expr, envir, enclos) : Objekt 'animal' nicht gefunden
Das Konzept des Objekts als Speicher für Dinge und der Unterschied zum Wort ist hier etwas sehr abstrakt. Wenn wir aber in R anfangen zu arbeiten wird dir das Konzept klarer werden. Hier müssen wir aber einmal Objekte einführen, damit wir auch etwas in R speichern können und nicht immer wieder neu erschaffen müssen.
9.4 Weitere Datenformate
Neben dem tibble gibt es noch andere R Pakete, die sich mit Daten beschäftigen. Wir konzentrieren uns hier aber auf den tibble, da er vollkommen ausreicht um unsere Analysen durchzuführen. Mehr brauchen wir nicht.
Tabelle 9.2 zeigt eine Übersicht wie einzelne Variablennamen und deren zugehörigen Beispielen sowie den Namen in R, der Informatik allgemein, als Skalenniveau und welcher Verteilungsfamilie die Variable angehören würde. Variablennamen meint hier immer den Namen der Spalte im Datensatz bzw. tibble Leider ist es so, dass wieder gleiche Dinge unterschiedliche benannt werden. Aber an dieses doppelte Benennen können wir uns in der Statistik schon mal gewöhnen.
Tabelle 9.2— Zusammenfassung und Übersicht von Variablennamen und deren Benennung in R, in der Informatik allgemein, als Skalenniveau und die dazugehörige Verteilungsfamilie.
Variablenname
Beispiel
R
Infomatik
Skalenniveau
Verteilungsfamilie
weight
12.3, 12.4, 5.4, 21.3, 13.4
numeric
double
continuous
Gaussian
count
5, 0, 12, 23, 1, 4, 21
integer
integer
discrete
Poisson
dosis
low, mid, high
ordered
categorical / ordinal
Ordinal
field
mainz, berlin, kiel
factor
categorical
Multinomial
cancer
0, 1
factor
dichotomous / binary / nominal
Binomial
treatment
“placebo”, “aspirin”
character
character/string
dichotomous / binary / nominal
Binomial
birth
2001-12-02, 2005-05-23
date
Quellcode
# Daten in R {#sec-letter-number}*Letzte Änderung am `r format(fs::file_info("programing-letters-numbers.qmd")$modification_time, '%d. %B %Y um %H:%M:%S')`*> *"Beyond this place there be dragons (lat. Hic sunt dracones)" --- Captain Picard, Star Trek: The Next Generation, Where Silence Has Lease*```{r}#| warning: false#| echo: falsepacman::p_load(tidyverse, readxl, knitr, kableExtra)flea_tbl <-read_excel("data/flea_dog_cat.xlsx") |>mutate(flea_count =as.integer(flea_count),infected =as.logical(infected))```{{< video https://youtu.be/4X9lHO_hRCU >}}Beginnen wir mit dem, was du als erstes vorliegen hast. Daten. Sehr häufig in einer Exceltabelle abgelegt. Und dann beginnen auch schon die Herausforderungen. Was sind eigentlich Daten in R? Was ist eigentlich das Problem mit den Buchstaben und Zahlen? Anscheinend haben Programmier*sprachen* ein Problem Zahlen und Buchstaben auseinander zuhalten. Eigentlich eher die Arten von Zahlen und Buchstaben die es so gibt. Es gibt nicht nur die eine Zahl und den einen Buchstaben. Je nach Kontext hat eine Zahl und ein Buchstabe eine andere Bedeutung. In den vorherigen Beispielen haben wir uns die Sprungweiten und andere Eigenschaften von Hunden und Katzen angeschaut. Bevor wir uns weiter mit statistischen Kennzahlen beschäftigen, wollen wir uns einmal die Realisierung des Beispiels in R anschauen. Das heißt, wie ist eine Tabelle in R aufgebaut und was sehen wir da eigentlich? Hier siehst du nochmal die Tabelle, wie wir die Tabelle in Microsoft Word darstellen würden.```{r}#| echo: false#| label: tbl-dog-cat-letter#| tbl-cap: "Tabelle von sieben Hunde- und Katzenflöhen mit der Sprunglänge [cm], Anzahl an Haaren am rechten Flohbein, Gewicht der Flöhe, Boniturnote sowie der Infektionsstatus für Flohschnupfen. Die erste Spalte `animal` gibt an, dass wir es hier mit Hunde- und Katzenflöhe zu tun haben. Die Tabelle ist im Long-Format dargestellt."flea_tbl |>kable(align ="c", "pipe")```Wir wollen jetzt an der Datentabelle die Besonderheiten von Zahlen und Buchstaben in einer Programmiersprache verstehen. Da wir uns jetzt hier mit der Programmiersprache R beschäftigen wollen, konzentrieren wir uns auf den Fall R. In anderen Programmiersprachen ist die Sachlage ähnlich aber nicht unbedingt gleich. Dabei wollen wir insbesondere die Eigenschaften von Zahlen und Buchstaben lernen, die notwendig sind um mit einem Programm wie R kommunizieren zu können. Nun haben wir in der @tbl-dog-cat-letter mit Daten zu verschiedenen Outcomes, wie Sprungweite \[cm\], Anzahl an Flöhen auf Hunden und Katzen, die Boniturnoten oder aber den Infektionsstatus. Die Tabelle ist zwar nicht groß aber auch nicht wirklich klein. Wir wollen uns nun damit beschäftigen, die Zahlen sinnvoll in R darzustellen. Wir wollen mit der Darstellung einer Datentabelle in R beginnen, einem `tibble`.::: callout-note## Ein `tibble` ist *tidy* (deu. *sauber*)Das Datenformat, was wir hier erarbeiten wollen, nennen wir auch *tidy* (deu. *sauber*) nach dem [R Paket `tidyr`](https://tidyr.tidyverse.org/) was dann auch später mit die Basis für unsere Analysen in R sein wird. Wenn ein Datensatz *tidy* ist, dann erfüllt er folgende Bedingungen.1. Jede Variable ist eine Spalte; jede Spalte ist eine Variable.2. Jede Beobachtung ist eine Zeile; jede Zeile ist eine Beobachtung.3. Jeder Wert ist eine Zelle; jede Zelle ist ein einziger Wert.Nach diesen Regeln bauen wir dann jeden Datensatz auf, den wir in einem Experiment gemessen haben.:::## Daten als `tibble` in RIm Folgenden sehen wir die Daten aus der obigen @tbl-dog-cat-letter in R als `tibble` dargestellt. Was ist nun ein `tibble`? Ein `tibble` ist zu aller erst ein Speicher für Daten in R. Das ist immer sehr abstrakt, deshalb einmal in der @fig-tibble die Idee des `tibble`s als Datenspeicher in der Analogie eines Schranks. Ein `tibble` ist ein leerer Schrank, in den du dann Daten hängen kannst.::: {#fig-tibble layout-ncol="2"}{#fig-tibble-empty fig-align="center" width="80%"}{#fig-tibble-full fig-align="center" width="80%"}Ein `tibble` ist ein interner Speicher für Daten in R. Du kannst dir da auch einen leeren Schrank vorstellen. In den Schrank können wir dann Klamotten aufhängen. Statt Klamotten nennen wir die aufgehängten Dinge dann in R Variablen.:::Dann können wir natürlich auch die Idee etwas komplexer Darstellen. Dabei ist ein `tibble` erstmal ein Begriff für eine Form die Daten abzuspeichern. So wie es bei IKEA im Sortiment einen Paxschrank zu kaufen gibt, aber natürlich *dein* Paxschrank zu Hause nicht der einzige Paxschrank ist. In der folgenden Abbildung siehst du dann einmal einen den Datensatz `flea_tbl` als ein `tibble` als einen Kleiderschrank mit vier Beobachtungen für drei Variablen abgebildet.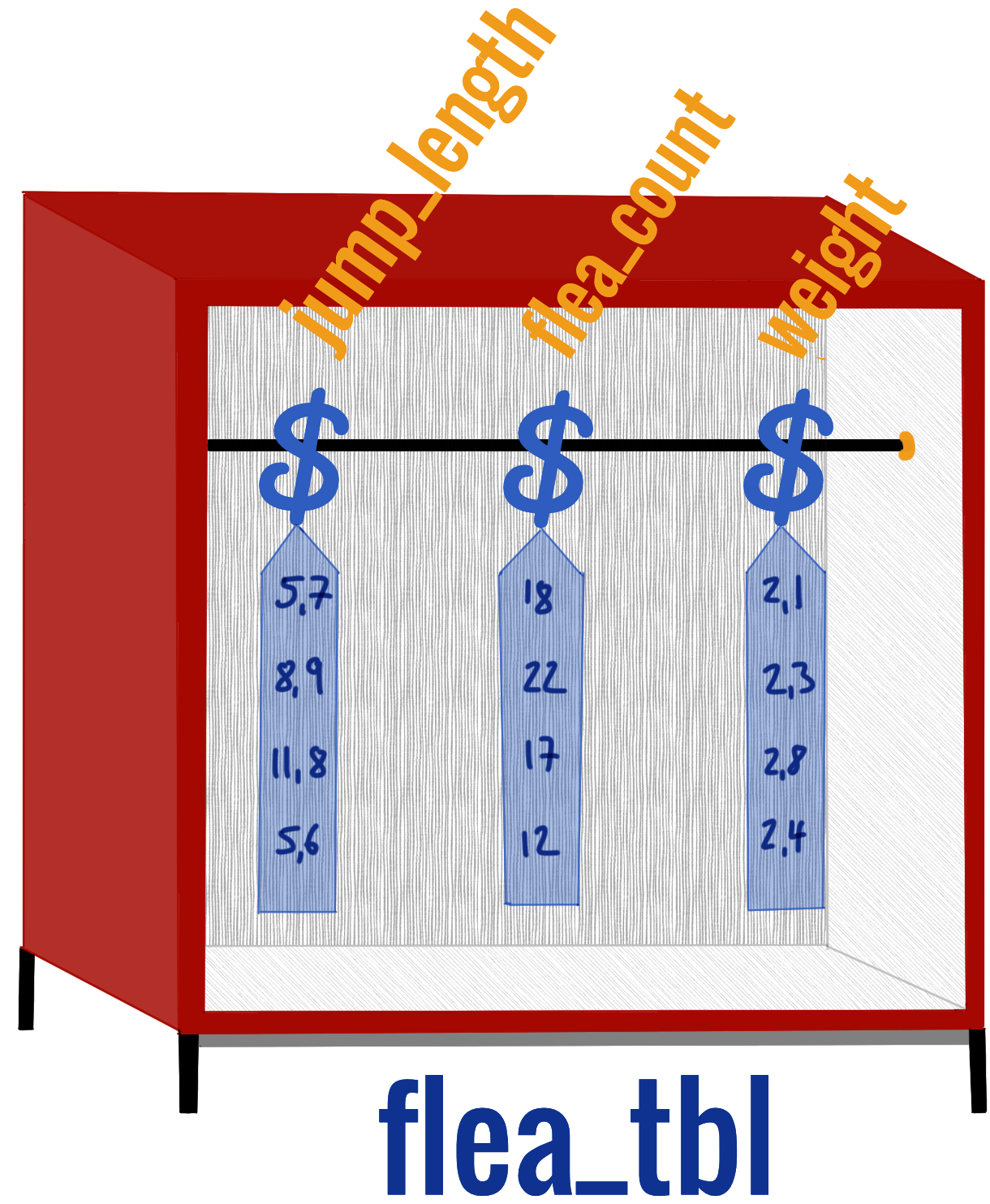{#fig-flea-tbl fig-align="center" width="50%"}Wie lagern wir jetzt aber in einem `tibble` unsere Daten? Eigentlich genau so wie auch in einer Tabelle in Excel. Das heißt wir lagern unsere Daten in Spalten und Zeilen. Jede Spalte repräsentiert eine Messung oder Variable und die Zeilen jeweils eine Beobachtung. Damit ist das Datenformat `tibble` auch *tidy* (deu. *sauber*) nach dem [R Paket `tidyr`](https://tidyr.tidyverse.org/). Wir wollen immer einen *tidy* Datensatz, bevor es mit der Analyse los geht. Ein *tidy* Datensatz ist dann auch später die Basis für unsere Analysen in R. Wenn ein Datensatz *tidy* ist, dann erfüllt er folgende Bedingungen.1. Jede Variable ist eine Spalte; jede Spalte ist eine Variable.2. Jede Beobachtung ist eine Zeile; jede Zeile ist eine Beobachtung.3. Jeder Wert ist eine Zelle; jede Zelle ist ein einziger Wert.Im Folgenden siehst du den Datensatz `flea_tbl` einmal ausgegeben.```{r echo = FALSE}flea_tbl ```Schauen wir uns also ein `tibble()` der obigen Datentabelle einmal näher an. Als erstes erfahren wir, dass wir einen `A tibble: 14 x 6` vorliegen haben. Das heißt, wir haben 14 Zeilen und 6 Spalten. In einem `tibble` wird immer in der ersten Zeile angezeigt wie viele Beobachtungen wir in dem Datensatz haben. Wenn das `tibble` zu groß wird, werden wir nicht mehr das ganze `tibble` sehen sondern nur noch einen Ausschnitt. Im Weiteren hat jede Spalte noch eine Eigenschaft unter dem Spaltennamen:- `<chr>` bedeutet `character`. Wir haben also hier Worte vorliegen.- `<dbl>` bedeutet `double`. Ein `double` ist eine Zahl mit Kommastellen.- `<int>` bedeutet `integer`. Ein `integer` ist eine ganze Zahl ohne Kommastellen.- `<lgl>` bedeutet `logical` oder `boolean`. Hier gibt es nur die Ausprägung *wahr* oder *falsch*. Somit `TRUE` oder `FALSE`. Statt den Worten `TRUE` oder `FALSE` kann hier auch 0 oder 1 stehen.- `<str>` bedeutet `string` der aus verschiedenen `character` besteht kann, getrennt durch Leerzeichen.In der folgenden Analogie zum Kleiderschrank nochmal die Idee der Eigenschaften eines Kleiderbügels. Wir können nur gleiche Dinge an einen Kleiderbügel in einen Schrank hängen. So dürfen an dem Kleiderbügel `animal` nur Worte sein. Es ist ein Kleiderbügel für `character` oder eben abgekürzt `<chr>`.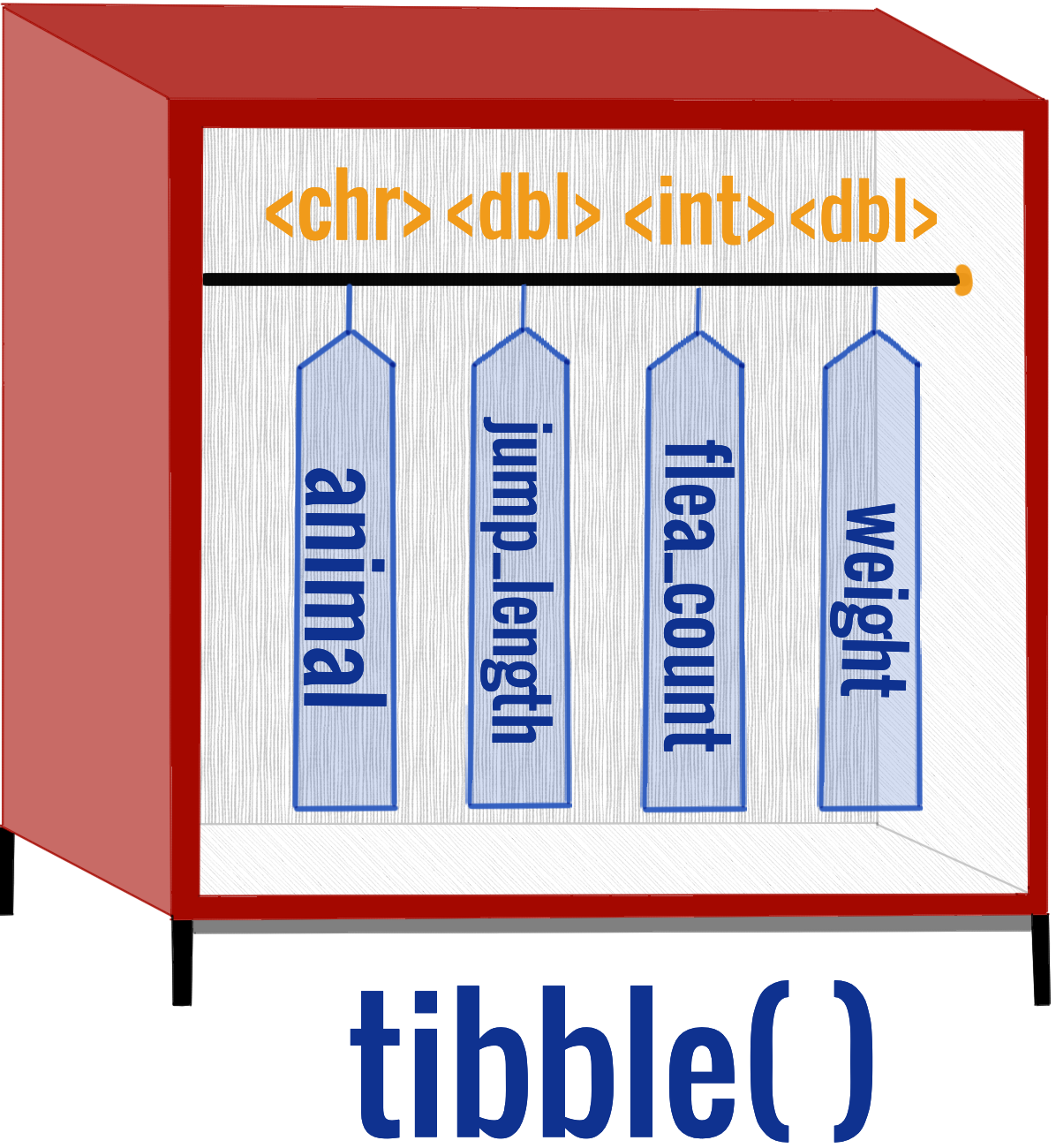{#fig-tibble-full-attr fig-align="center" width="50%"}Wieso ist das jetzt eigentlich wichtig? Wir sehen hier, was R glaubt in den Spalten an Zahlen und Buchstaben vorzufinden. Das mag stimmen, es kann aber auch falsch sein. R ist da manchmal nicht so schlau. Es mag aber sein, dass R sich irrt. Dann müssen wir die Eigenschaften der Spalte ändern. Das ändern von Eigenschaften machen wir mit der Funktion `mutate()`. Dazu aber dann mehr im [Kapitel Daten bearbeiten](#sec-dplyr), wo cih die verschiednenen Funktionen zur Modifikation von einem `tibble` vorstelle.## Faktoren als Wörter zu Zahlen{{< video https://youtu.be/qSi2ZwRQj6M >}}Ein Computer und somit auch eine Programmsprache wie R kann keine Buchstaben *verrechnen*. Wie soll das auch gehen. Was ist `"A"` plus `"T"` oder aber `"hund"` plus `"katze"`? Das ergibt keinen Sinn für eine Maschine. Ein Computerprogramm wie R eines ist kann nur mit Zahlen rechnen. Wir haben aber in der obigen @tbl-dog-cat-letter in der Spalte `animal` Buchstaben stehen. Da wir hier einen Kompromiss eingehen müssen führen wir Faktoren ein. Ein Faktor kombiniert Buchstaben mit Zahlen. Wir als Anwender sehen die Buchstaben, die Wörter bilden. Intern steht aber jedes Wort für eine Zahl, so dass R mit den Zahlen rechnen kann oder aber erkennt, dass es sich um eine Gruppe handelt. Ein *Faktor* ist eine Variable mit mehreren *Faktorstufen* oder *Leveln*. Für uns sieht der Faktor wie ein Wort aus, hinter jedem Wort steht aber eine Zahl mit der gerechnet werden kann. Klingt ein wenig kryptisch, aber wir schauen uns einen `factor` einmal in R an.```{r }flea_tbl$animal[1:8]```Was haben wir gemacht? Als erstes haben wir die Spalte `animal` aus dem Datensatz `flea_tbl` mit dem Dollarzeichen `$` herausgezogen. Mit dem `$` Zeichen können wir uns eine einzelne Spalte aus dem Datensatz `flea_tbl` raus ziehen. Über das `$` Symbol kannst du im @sec-dollar mehr erfahren. In der folgenden Abbildung habe ich dir den Zusammenhang nochmal visualisiert.{#fig-flea-tbl fig-align="center" width="50%"}Du kannst dir das `$` wie einen Kleiderbügel und das `flea_tbl` als einen Schrank für Kleiderbügel verstellen. An dem Kleiderbügel hängen dann die einzelnen Zahlen und Worte. Wir nehmen aber nicht den ganzen Vektor sondern nur die Zahlen 1 bis 8, dargestellt durch `[1:8]`. Die Gänsefüßchen `"` um `dog` zeigen uns, dass wir hier Wörter oder `character`vorliegen haben. Schauen wir auf das Ergebnis, so erhalten wir sieben Mal `dog` und einmal `cat`. Insgesamt die ersten acht Einträge der Datentabelle. Wir wollen diesen Vektor uns nun einmal als Faktor anschauen. Wir nutzen die Funktion `as_factor()`. Über Funktionen kannst du im @sec-R-function mehr erfahren.```{r}as.factor(flea_tbl$animal[1:8])```Im direkten Vergleich verschwinden die Gänsefüßchen `"` um `dog` und zeigen uns, dass wir hier keine `character` mehr vorliegen haben. Darüber hinaus sehen wir auch, dass die der Faktor jetzt `Levels` hat. Exakt zwei Stück. Jeweils einen für `dog` und einen für `cat`. Wir werden später Faktoren benötigen, wenn wir zum Beispiel eine einfaktorielle ANOVA rechnen. Hier siehst du schon den Begriff *Faktor* wieder.## Von Wörtern und ObjektenDas mag etwas verwirrend sein, denn es gibt in R Wörter `string <str>` oder `character <chr>`. Wörter sind was anderes als Objekte. Streng genommen sind beides Wörter, aber in Objekten werden Dinge gespeichert wohin gegen das Wort einfach ein Wort ist. Deshalb kennzeichnen wir Wörter auch mit Gänsefüßchen als `"wort"` und zeigen damit, dass es sich hier um einen String handelt. Wir tippen `"animal"` in R und erhalten `"animal"` als Wort zurück. Das sehen wir auch an dem Ausdruck mit den Gänsefüßchen.```{r}"animal"```Wir tippen `animal` ohne die Anführungszeichen in R und erhalten den Inhalt von `animal` ausgegeben. Dafür müssen wir aber das Objekt `animal` erst einmal über den Zuweisungspfeil `<-` erschaffen. Über den Zuweisungspfeil `<-` kannst du im @sec-R-pfeil mehr erfahren.```{r}animal <-c("dog", "cat", "fox")animal```Sollte es das Objekt `animal` nicht geben, also nicht über den Zuweisungspfeil `<-` erschaffen worden, dann wird eine Fehlermeldung von R ausgegeben:`Fehler in eval(expr, envir, enclos) : Objekt 'animal' nicht gefunden`Das Konzept des Objekts als Speicher für Dinge und der Unterschied zum Wort ist hier etwas sehr abstrakt. Wenn wir aber in R anfangen zu arbeiten wird dir das Konzept klarer werden. Hier müssen wir aber einmal Objekte einführen, damit wir auch etwas in R speichern können und nicht immer wieder neu erschaffen müssen.## Weitere DatenformateNeben dem `tibble` gibt es noch andere R Pakete, die sich mit Daten beschäftigen. Wir konzentrieren uns hier aber auf den `tibble`, da er vollkommen ausreicht um unsere Analysen durchzuführen. Mehr brauchen wir nicht.- [Introduction to `{data.table}`](https://cran.r-project.org/web/packages/data.table/vignettes/datatable-intro.html) liefert nochmal ein anderes R Paket, dass mit Daten arbeiten kann.- [Warum `tibble` besser sind als `data.frame`](https://tibble.tidyverse.org/reference/tibble.html) erklärt, warum wir nicht die veraltete Form des `data.frame` in R nutzen sondern die neuere Implementierung `tibble`.## Zusammenfassung@tbl-skalenniveau zeigt eine Übersicht wie einzelne Variablennamen und deren zugehörigen Beispielen sowie den Namen in R, der Informatik allgemein, als Skalenniveau und welcher Verteilungsfamilie die Variable angehören würde. *Variablennamen* meint hier immer den *Namen der Spalte* im Datensatz bzw. `tibble` Leider ist es so, dass wieder gleiche Dinge unterschiedliche benannt werden. Aber an dieses doppelte Benennen können wir uns in der Statistik schon mal gewöhnen.| Variablenname | Beispiel | R | Infomatik | Skalenniveau | Verteilungsfamilie ||---------------|-----------------------------|-----------|------------------|--------------------------------|--------------------|| weight | 12.3, 12.4, 5.4, 21.3, 13.4 | numeric | double | continuous | Gaussian || count | 5, 0, 12, 23, 1, 4, 21 | integer | integer | discrete | Poisson || dosis | low, mid, high | ordered || categorical / ordinal | Ordinal || field | mainz, berlin, kiel | factor || categorical | Multinomial || cancer | 0, 1 | factor || dichotomous / binary / nominal | Binomial || treatment | "placebo", "aspirin" | character | character/string | dichotomous / binary / nominal | Binomial || birth | 2001-12-02, 2005-05-23 | date ||||: Zusammenfassung und Übersicht von Variablennamen und deren Benennung in R, in der Informatik allgemein, als Skalenniveau und die dazugehörige Verteilungsfamilie. {#tbl-skalenniveau}


