R Code [zeigen / verbergen]
t_d <- fac1_tbl |>
specify(jump_length ~ animal) |>
calculate(stat = "t", order = c("dog", "cat"))
t_dResponse: jump_length (numeric)
Explanatory: animal (factor)
# A tibble: 1 × 1
stat
<dbl>
1 3.13Letzte Änderung am 25. June 2025 um 12:34:33
“You cannot be a powerful and life-changing presence to some people without being a joke or an embarrassment to others.” — Mark Manson
Beginnen wir unsere Reise durch die statistischen Tests mit dem t-Test. Damit beginnen wir auch historisch korrekt, da der t-Test auch der erste statistische Test war, der entwickelt wurde. Wir sehen die Nutzung des t-Tests in vielen wissenschaftlichen Publikationen, wie zum Beispiel der Veröffentlichung von Erb et al. (2012) zu dem Auftreten von Säugetieren entlang des Appalachian Trail in den USA. Gibt es einen Unterschied im Auftreten von Schwarzbären und Rotfüchsen in Abhängigkeit von der Trailnutzung? Wie du erkennst, handelt es sich hier um Säulendiagramme als Mittelwerte und Standardfehler. Der t-Test versteckt sich hinter den Sternen, die du als eine mögliche Darstellung der p-Werte aus dem statistischen Testen kennst.
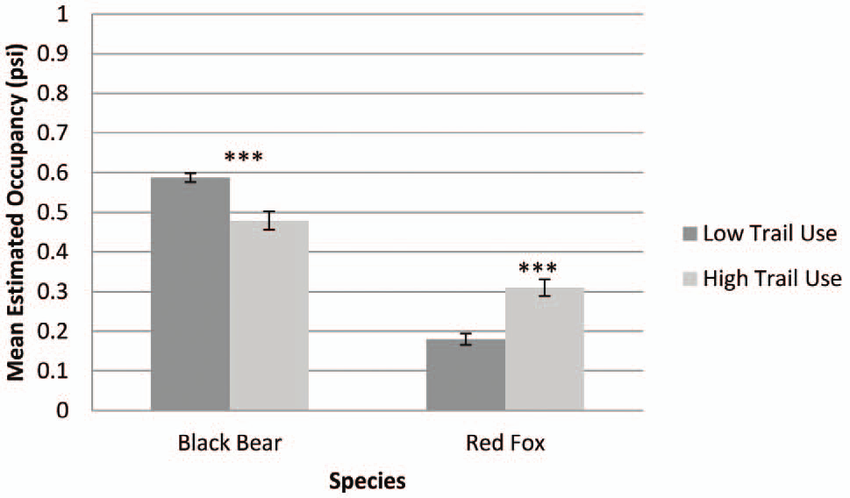
Woher kommen nun die Sterne über die Säulen und was soll ungleiche Varianzen bedeuten? Hier wollen wir dann mal einsteigen und verstehen was der t-Test macht und warum der t-Test für den zwei Gruppenvergleich immer noch der Goldstandard ist.
Der t-Test ist der bedeutende Test, wenn es um das Verständnis der Algorithmen und Konzepte in der Statistik geht. Wir haben den t-Test schon genutzt um die Idee des statistischen Testens zu verstehen und wir werdend den t-Test auch im statistischen Modellieren wiedertreffen. Dort finden wir aber die Teststatistik des t-Tests. Wir werden dort nicht direkt den t-Test rechnen sondern das Konzept des t-Tests wieder nutzen. Natürlich hat der t-Test auch wieder verschiedene Namen, je nachdem welche Software du nutzen möchtest. Deshalb nochmal eine kurze Übersicht in der nachfolgenden Tabelle für R und Excel.
| Name | R | Excel |
|---|---|---|
| Student t-Test | Two Sample t-test | t-Test: Two-Sample Assuming Equal Variances |
| Welch t-Test | Welch Two Sample t-test | t-Test: Two-Sample Assuming Unequal Variances |
Was macht also der t-Test? Der t-Test vergleicht die Mittelwerte zweier Gruppen miteinander. Das heißt wir haben zwei Gruppen, wie Hunde und Katzen, und wollen nun wissen wie sich die Sprungweiten der Hundeflöhe im Mittel von den Katzenflöhen unterscheiden. In R hätten wir damit einen Faktor mit zwei Leveln vorliegen. Darüber hinaus nimmt der t-Test implizit an, das unser Outcome \(y\) normalverteilt ist. Die Varianzen können in beiden Gruppen gleich sein, dann sprechen wir von homogenen Varianzen oder Varianzhomogenität. Wir können den t-Test aber auch mit ungleichen Varianzen in beiden Gruppen rechnen, dann sprechen wir von heterogenen Varianzen oder eben Varianzheterogenität. Wir nutzen dann den Welch t-Test.
Ich kann als Empfehlung nur aussprechen eigentlich immer den Welch t-Test zu nutzen. Sollten die Varianzen dennoch homogen sein, macht der Welch t-Test faktisch nichts schlechter als der Student t-Test. Dafür hat der Student t-Test wirklich Probleme mit ungleichen Varianzen.
Nun ist es so, das wir häufig einen t-Test verwenden müssen, wenn unsere Fallzahl \(n\) sehr klein wird, da nicht-parametrische Methoden dann algorithmisch nicht mehr funktionieren. Hier hilft dann als wissenschaftliche Quelle die Arbeit von Rasch et al. (2007), die auch unter dem Titel The Robustness of Parametric Statistical Methods frei verfügbar ist. Wichtig ist eigentlich nur das folgende Zitat aus dem Abstrakt der wissenschaftlichen Arbeit.
“All the results are that in most practical cases the two-sample t-test is so robust that it can be recommended in nearly all applications.” — Rasch et al. (2007)
Unter den meisten Bedingungen ist der t-Test robust gegen die Verletzung der Normalverteilungsannahme. Wenn wir Varianzheterogenität vorliegen haben, dann können wir ja den Welch t-Test rechnen. Aber auch hier ist es dann wichtig auf den konkreten Datenfall zu schauen. Mehr zu der Thematik gibt es auch von Rasch et al. (2011) in der Veröffentlichugn The two-sample t test: pre-testing its assumptions does not pay off mit dem zentralen Zitat.
“As a result, we propose that it is preferable to apply no pre-tests for the t test and no t test at all, but instead to use the Welch-test as a standard test: its power comes close to that of the t test when the variances are homogeneous […].” — Rasch et al. (2011)
Auch findet De Winter & Dodou (2010) in der Veröffentlichung Five-point Likert items: t test versus Mann-Whitney-Wilcoxon, dass wir uns nicht so richtig um die Normalverteilung sorgen müssen. Auch für Boniturnoten auf der Likertskala kann gut ein t-Test gerechnet werden.
“In conclusion, for five-point Likert items, the t test and wilcoxon mann whitney test generally have similar power, and researchers do not have to worry about finding a difference whilst there is none in the population.” — De Winter & Dodou (2010)
Wenn du direkt aus dem statistischen Testen hierher kommst, dann ist die Berechnung des Student t-Tests für dich kein Problem. Das machen wir im statistischen Testen ja schon als Beispiel für die Teststatistik und den p-Wert. Hier kommen dann gleich fertige Funktionen in R, die dir alles in einem berechnen. Da ist es dann immer etwas schwerer nachzuvollziehen, was die einzelnen Schritte im statistischen Testen eigentlich sind.
Hier hilft dann das R Paket {infer} mit einer Schritt für Schritt Prozedur bei Durchführung des statistischen Testen. Dann machen wir es also einmal genau so, wie wir es schon kennen. Erst die Teststatistik \(T_D\) der Daten berechenen. Dann die Verteilung der Nullhypothese der Grundgesamtheit bestimmen und dann beides zusammenbringen. Ein weiterer Vorteil von {infer} ist, dass wir die Funktionen sehr gut mit dem |> Operator nutzen können.
Als erstes berechnen wir die Teststatistik für den t-Test \(T_D\) aus den beobachteten Daten. Dafür nutzen wir unsere Sprungweiten der Hunde- und Katzenflöhe. Mehr zu den Daten auch gleich weiter unten im Abschnitt zu den genutzen Daten im Kapitel.
t_d <- fac1_tbl |>
specify(jump_length ~ animal) |>
calculate(stat = "t", order = c("dog", "cat"))
t_dResponse: jump_length (numeric)
Explanatory: animal (factor)
# A tibble: 1 × 1
stat
<dbl>
1 3.13Mit der Teststatistik der Daten \(T_D\) können wir so erstmal nichts anfangen. Wir brauchen noch einen vergleich zu der Verteilung der Nullhypothese. Daher bestimmen wir im Folgednen die Verteilung der Nullhypothese zu der wir unsere berechnete Teststatistik \(T_D\) aus den Daten vergleichen wollen.
set.seed(202506)
null_dist_data <- fac1_tbl |>
specify(jump_length ~ animal) |>
hypothesize(null = "independence") |>
generate(reps = 1000, type = "permute") |>
calculate(stat = "t", order = c("dog", "cat"))Dann schauen wir uns einmal die Verteilung der Nullhypothese an. Wie wir sehen können, liegen die meisten Teststatistiken bei der Null. Macht ja auch Sinn, in der Nullhypothese haben wir ja auch Gleichheit zwischend Hunde- und Katzenflöhen angenommen.
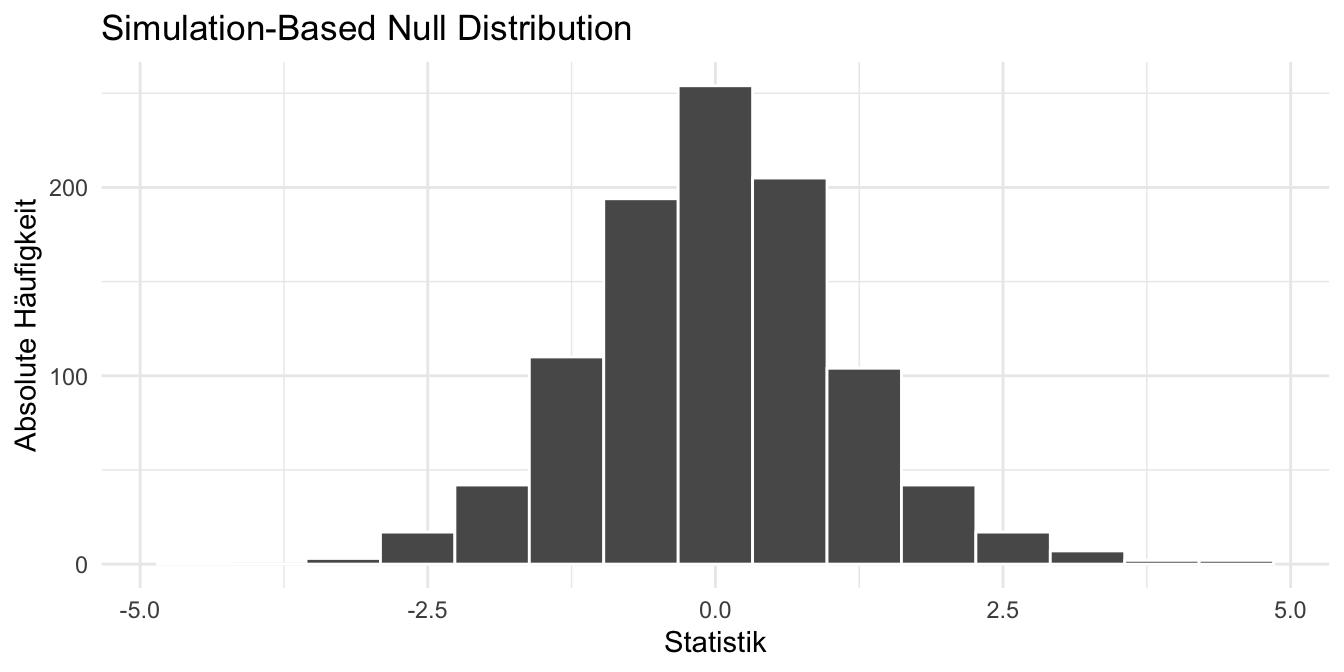
Dann wollen wir noch die Fläche neben unsere berechnete Teststatistik \(T_D\) um damit den \(p\)-Wert zu bestimmen.
null_dist_data %>%
get_p_value(obs_stat = t_d, direction = "two-sided")# A tibble: 1 × 1
p_value
<dbl>
1 0.016Wie du dich noch erinnerst, ist der p-Wert die Fläche neben der berechneten Teststatistik \(T_D\) zu den Verteilungsenden hin. Das wollen wir uns dann in der folgenden Abbildung nochmal anschauen, damit wir den Zusammenhang nochmal besser verstehen.

Die Abfolge der Schritte erfolgt so nicht in der generischen Funktion t.test(), die wir dann in der Anwendung viel nutzen. Daher ist das R Paket {infer} nochmal gut um die Schritte der Berechnung sich klar werden zu lassen. Später nutzen wir dann nur eine Funktion, aber der Prozess ist im Hintergrund immer sehr ähnlich.
Eine detailliertere Einführung mit mehr Beispielen für die Nutzung vom R Paket {infer} findest du im Kapitel Testen in R. Hier soll es dann bei der kurzen Gegenüberstellung bleiben.
Wir wollen folgende R Pakete in diesem Kapitel nutzen.
pacman::p_load(tidyverse, magrittr, broom, readxl,
infer, see, tidyplots, rstatix, ggpubr,
ggrepel, nlme, conflicted)
conflicts_prefer(dplyr::filter)
conflicts_prefer(rstatix::t_test)
set.seed(20221206)An der Seite des Kapitels findest du den Link Quellcode anzeigen, über den du Zugang zum gesamten R-Code dieses Kapitels erhältst.
In den folgendne Abschnitten brauchen wir dann zwei Datensätze. Der erste Datensatz beschreibt Hunde- und Katzenflöhe, die springen und deren Sprungweite dann gemessen wurde. Wir haben hier verschiedene Flöhe vorliegen, die nur einmal springen. Wir können aber auch den Fall haben, dass wir uns wiederholt einen Floh anschauen. Der zweite Datensatz betrachtet Hundeflöhe, die vor der Fütterung und nach der Fütterung gesprungen sind.
Beginnen wir mit einem Datenbeispiel zu den Hunde- und Katzenflöhen. Was brauchen wir damit wir den t-Test rechnen können? Wir brauchen für den t-Test eine Spalte \(y\) mit kontinuierlichen Zahlen und einer Spalte \(x\) in dem wir einen Faktor mit zwei Leveln finden oder eben zwei Gruppen. Jedes Level steht dann für eine der beiden Gruppen. Das war es schon. Schauen wir uns nochmal den Datensatz flea_dog_cat.xlsx in Tabelle 31.2 an und überlegen, was wir dort auswählen können.
fac1_tbl <- read_excel("data/flea_dog_cat.xlsx") |>
mutate(animal = as_factor(animal)) |>
select(animal, jump_length)Wir benötigen für den t-Test ein normalverteiltes \(y\) womit wir uns hier erstmal für die kontinuierliche Sprungweite entscheiden. Dann brauchen wir einen Faktor mit zwei Leveln als \(x\) und da bietet sich natürlich die beiden Gruppen Hunde- und Katzenflöhe an. Wir wählen daher mit select() die Spalte jump_length und animal aus dem Datensatz flea_dog_cat.xlsx aus. Wichtig ist, dass wir die Spalte animal mit der Funktion as_factor() in einen Faktor umwandeln. Anschließend speichern wir die Auswahl in dem Objekt fac1_tbl. Hier dann nochmal die Datentabelle.
| animal | jump_length |
|---|---|
| dog | 5.7 |
| dog | 8.9 |
| dog | 11.8 |
| ... | ... |
| cat | 4.3 |
| cat | 7.9 |
| cat | 6.1 |
Wir haben jetzt die Daten richtig vorbereiten und können uns nun mit dem t-Test beschäftigen. Bevor wir den t-Test jedoch rechnen können, müssen wir uns nochmal überlegen, was der t-Test eigentlich testet und uns die Daten einmal visualisieren. Klassischerweise wollen wir einen t-Test rechnen, da wir zwei Säulen in einem Barplot miteinander vergleichen wollen. Dafür schauen wir uns in Abbildung 31.4 einmal den Barplot und den Boxplot für die Sprungweiten getrennt nach Hund und Katze an.
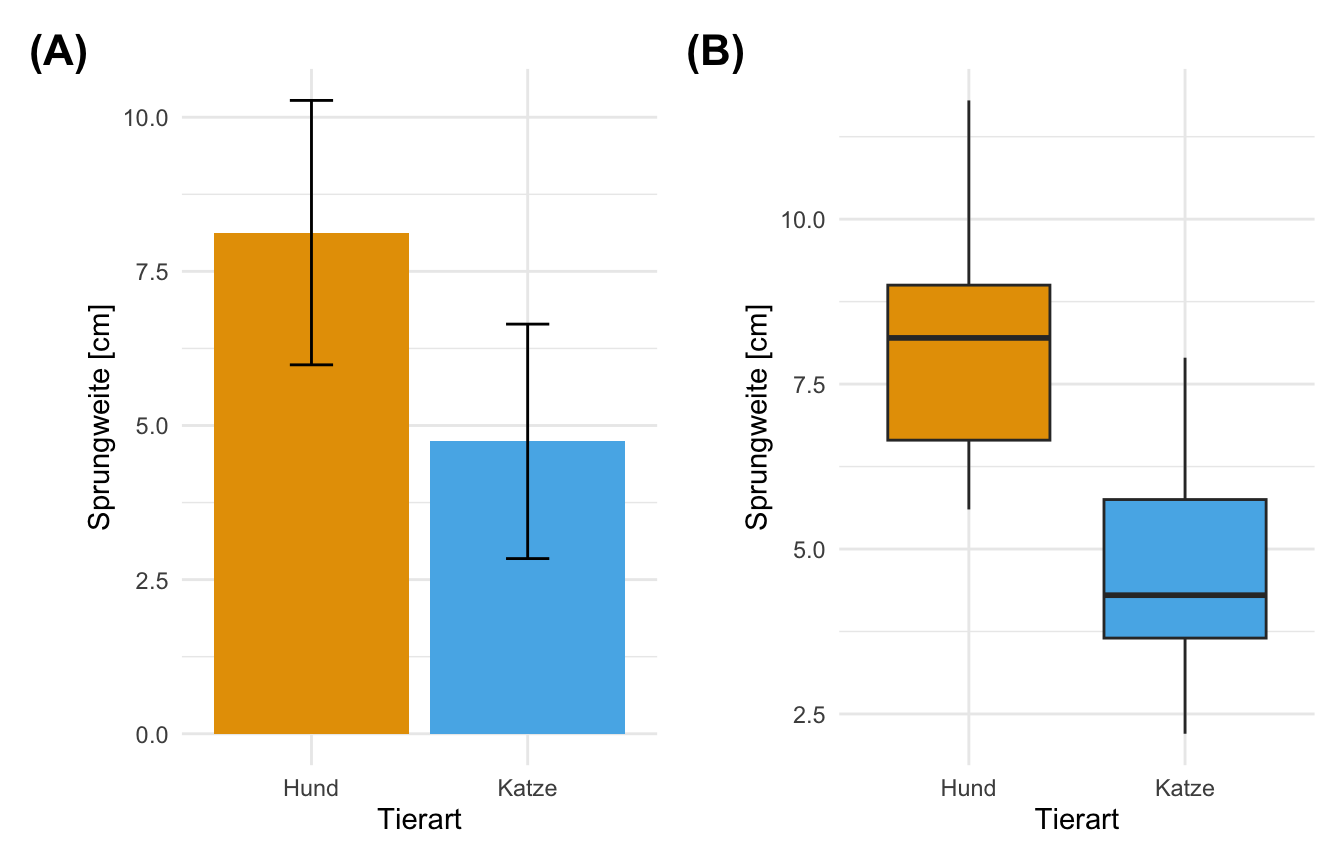
Zum einen sind die Mittelwerte der Barplots nicht auf einer Höhe. Dies spricht schon mal dafür, dass wir hier einen Unterschied in den Sprungweiten vorliegen haben könnten. Schauen wir auch einmal auf die Boxplots. Wir sehen, dass sich die Boxen nicht überschneiden, ein Indiz für einen signifikanten Unterschied zwischen den beiden Gruppen. Im Weiteren liegt der Median in etwa in der Mitte der beiden Boxen. Die Whisker sind ungefähr gleich bei Hunden und Katzen. Ebenso sehen wir bei beiden Gruppen keine Ausreißer. Wir schließen daher nach der Betrachtung der beiden Abbildungen auf Folgendes:
Manchmal ist es etwas verwirrend, dass wir uns in einem Boxplot mit Median und IQR die Daten für einen t-Test anschauen. Immerhin rechnet ja ein t-Test mit den Mittelwerten und der Standardabweichung. Hier vergleichen wir etwas Äpfel mit Birnen. Deshalb in der Abbildung 31.5 der Dotplot mit dem Mittelwert und den entsprechender Standardabweichung als Fehlerbalken.
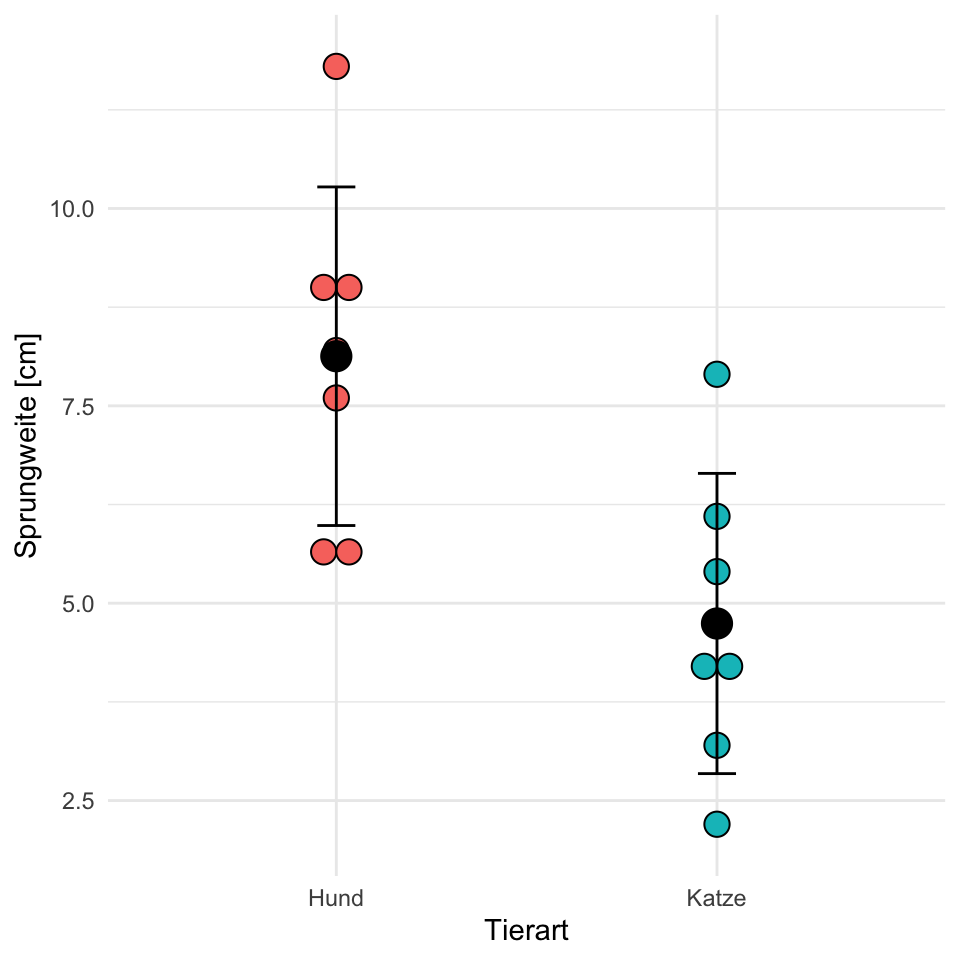
Wir nutzen aber später häufig den Boxplot zur Visualisierung der einzelnen Gruppen. Über den Boxplot können wir auch gut abschätzen, ob wir eine annähernde bzw. approximative Normalverteilung vorliegen haben. Häufig werden aber auch Barplots verlangt, so dass du hier relativ frei bist, was du verwendest. Am Ende ist es aber nicht so wichtig, ob wir eine Normalverteilung vorliegen haben oder nicht. Der t-Test ist recht robust gegen eine Abweichung. Viel wichtiger ist, das du eben Mittelwerte vergleichst. Also dann zum Beispiel mittlere Boniturnoten oder mittlere Anzahlen.
Der t-Test erlaubt auch abhängige Daten zu analysieren. Das heißt wir haben die gleichen sieben Hundeflöhe wiederholt gemessen. Einmal haben wir einen Hundefloh gemessen bevor er was gegessen hat, also hungrig ist, und einmal nachdem der gleiche Floh sich satt gegessen hat. Daher haben wir hier abhängige oder verbundene Bebachtungen. Im folgenden einmal der Datensatz eingelesen im Wide-Format.
paired_tbl <- read_excel("data/flea_dog_cat_repeated.xlsx") Wie du sehen kannst haben wir die sieben Flöhe wiederholt gemessen. Die Daten sind nicht im tidy-Format, da nicht jede Zeile nur eine Messunfg für eine Beobachtung beinhaltet. Das ändern wir dann einmal gleich in Long-Format.
| id | hungrig | satt |
|---|---|---|
| 1 | 5.2 | 6.1 |
| 2 | 4.1 | 5.2 |
| 3 | 3.5 | 3.9 |
| 4 | 3.2 | 4.1 |
| 5 | 4.6 | 5.3 |
Dann hier nochmal die Long-Formatvariante mit der Funktion pivot_longer(). Wir brauchen das Long-Format für die Auswertung in den unteren Abschnitten für das R Paket {rstatix}.
paired_long_tbl <- paired_tbl |>
pivot_longer(cols = hungrig:satt,
values_to = "jump_length",
names_to = "trt") Manchmal ist es schwer zu verstehen, was jetzt wiederholt oder gepaart heißen soll. Deshalb hier nochmal die Visualiserung der Daten für die beiden Sprünge vor und nach der Fütterung. Ich habe die Messungen, die zusammengehören mit einer Linie verbunden. Dazu dann auch noch die jeweiligen IDs der Flöhe ergänzt.
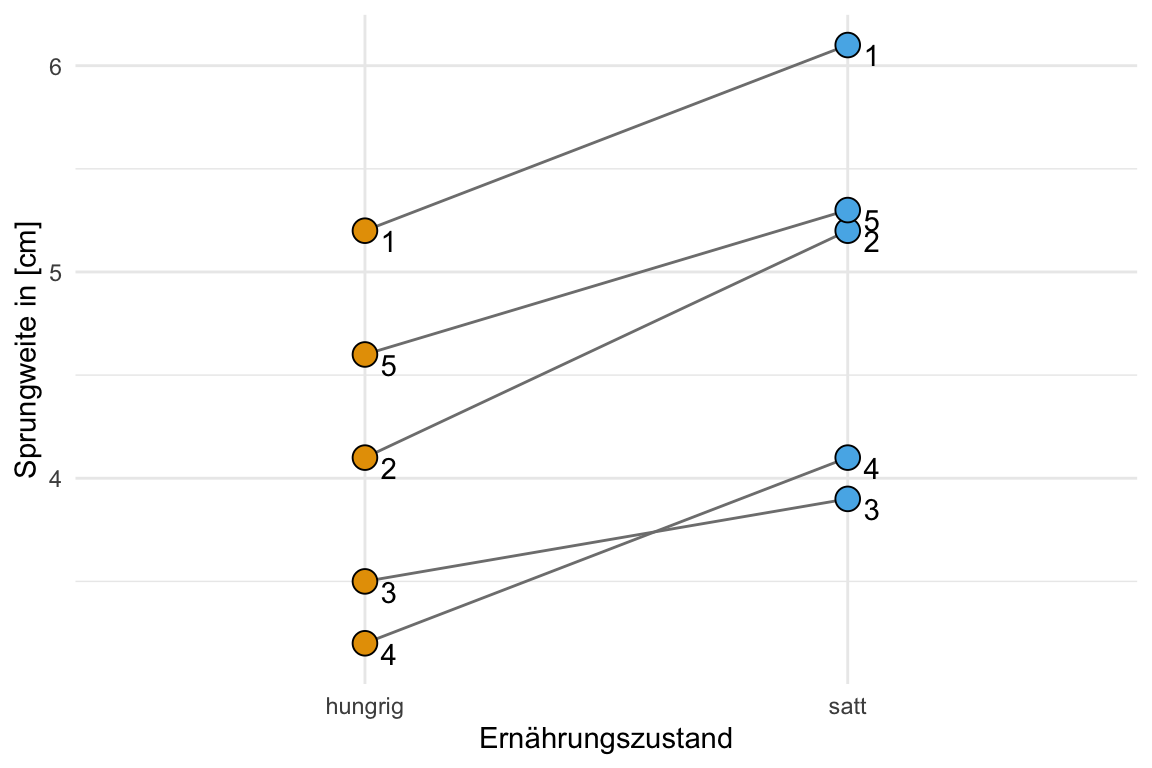
Ohne eine Hypothese ist das Ergebnis eines statistischen Tests wie auch der t-Test nicht zu interpretieren. Wir berechnen eine Teststatistik und einen p-Wert. Beide statistischen Maßzahlen machen eine Aussage über die beobachteten Daten \(D\) unter der Annahme, das die Nullhypothese \(H_0\) gilt.
Wie lautet nun das Hypothesenpaar des t-Tests? Der t-Test vergleicht die Mittelwerte von zwei Gruppen. Die Nullhypothese ist auch die Gleichheitshypothese. Die Alternativehypothese haben wir auch als Unterschiedshypothese bezeichnet.
Daher ergibt sich für unser Beispiel mit den Sprungweiten für Hunde- und Katzenflöhen folgende Hypothesen. Die Nullhypothese sagt, dass die mittleren Sprungweite für die Hundeflöhe gleich der mittleren Sprungweite der Katzenflöhe ist. Die Alternativehypothese sagt aus, dass sich die mittlere Sprungweite von Hunde- und Katzenflöhen unterscheidet.
\[ \begin{aligned} H_0: \bar{y}_{dog} &= \bar{y}_{cat} \\ H_A: \bar{y}_{dog} &\neq \bar{y}_{cat} \\ \end{aligned} \]
Wir testen grundsätzlich auf ein zweiseitiges \(\alpha\)-Niveau von 5%.
Dann wollen wir mal den t-Test berechnen. Den t-Test gibt es in drei Varianten, je nachdem, was wir für Fallzahlen oder aber Varianzen vorliegen haben. Wir können den t-Test wie immer mit der Hand berechnen oder aber in R sowie in Excel. Wir konzentrieren uns hier einmal auf die händsiche Berechnung für die Klausur und die Anwendung in R. Ich habe aber nochmal ein Video aufgenommen für die Anwendung des t-Tests in Excel. Manchmal gibt es ja den Notfall, dass nur Excel geht. Du müsstest die Formel des t-Test in der einfachen Form des Student t-Test gleich wiedererkennen, denn an dem t-Test erkläre ich die statistische Testtheorie und die Testentscheidung.
Fangen wir mit den einfacheren der beiden t-Tests an, dem Student t-Test. Der Student t-Test heißt so komisch, weil der Erfinder William Sealy Gosset zum Zeitpunkt der Entwicklung der Formel bei Guinness-Brauerei gearbeitet hat. Die Firma wollte aber nicht, dass seine Entdeckungen veröffentlicht werden. Also entschied sich Gosset unter einem Pseudonym seine Ideen zu präsentieren. Warum Gosset nun unbedingt Student als Pseudonym wählen musste, wird wohl sein Geheimnis bleiben. Deshalb der etwas wirre Name des t-Tests für Varianzhomogenität.
Die Formel des Student t-Test für Varianzhomogenität müsste dir noch aus dem Kapitel zur Testentscheidung bekannt vorkommen. Die Formel ist recht einfach, deshalb nutze ich den Student t-Test in dem Kapitel für die Einführung zur Teststatistik und dem p-Wert. Was brauchen wir nun für einen Student t-Test? Liegt ein normalverteiltes \(y\) vor und sind die Varianzen für die beiden zu vergleichenden Gruppen homogen \(s^2_{1} = s^2_{2}\), können wir einen Student t-Test rechnen. Wir nutzen dazu die folgende Formel des Student t-Tests.
\[ T_{D} = \cfrac{\bar{y}_{1}-\bar{y}_{2}}{s_{p} \cdot \sqrt{\cfrac{2}{n_{g}}}} \]
mit
Dann nutzen wir die vereinfachte Formel für die gepoolte Standardabweichung \(s_p\). Das hat den einfachen Grund, dass wir eben den t-Test nur in der Klausur händisch rechnen. Und hier machen wir uns es dann etwas einfacher.
\[ s_{p} = \cfrac{s_{1} + s_{2}}{2} \]
mit

Eigentlich wäre hier folgende Formel mit \(s_{p} = \sqrt{\frac{1}{2} (s^2_{dog} + s^2_{cat})}\) richtig, da wir eigentlich die Varianzen mitteln müssten und dann die Wurzel ziehen. Aber auch hier erwischen wir einen Statistikengel um es etwas einfacher zu machen.
Dann kannst du in den folgenden Tab auch dir einmal anschauen, wie die Berechnung des Student t-Tests für das Beispiel mit den Sprungweiten der Hunde- und Katzenflöhe ablaufen würde.
Wenn wir einen Student t-Test per Hand berechnen wollen, dann brauchen wir ja einiges an statistischen Maßzahlen. Hier erstmal nochmal die Formel, damit wir dann für Wissen, welche der statistischen Maßzahlen wir benötigen.
\[ T_{D} = \cfrac{\bar{y}_{dog}-\bar{y}_{cat}}{s_{p} \cdot \sqrt{\cfrac{2}{n_{g}}}} \]
Wir wollen nun die Werte für \(\bar{y}_{dog}\), \(\bar{y}_{cat}\) und \(s_{p}\) berechnen. Der Wert von \(n_g\) ist ja mit sieben schon bekannt. Wir nutzen hierfür die folgenden Formeln aus dem Kapitel zur deskriptiven Statistik. Wichtig ist nochmal, dass wir annehmen, dass die Varianz der Hundeflöhe ungefähr gleich ist zu der Varianz der Katzenflöhe mit \(s^2_{cat} = s^2_{dog}\).
Fangen wir einmal an mit den Mittelwerten der Sprungweiten der Hunde- und Katzenflöhe.
\[ \bar{y}_{dog} = \cfrac{5.7 + 8.9 + 11.8 + 5.6 + 9.1 + 8.2 + 7.6}{7} = 8.13 \]
\[ \bar{y}_{cat} = \cfrac{3.2 + 2.2 + 5.4 + 4.1 + 4.3 + 7.9 + 6.1}{7} = 4.74 \]
Dann berechnen wir jeweils die Varianz der Sprungweite der Hunde- und Katzenflöhe. Dafür brauchen wir jetzt den Mittelwert der Sprungweiten.
\[ s^2_{dog} = \cfrac{(5.7 - 8.13)^2 + (8.9 - 8.13)^2 + \cdots + (7.6 - 8.13)^2}{7-1} = 4.60 \]
\[ s^2_{cat} = \cfrac{(3.2 - 4.74)^2 + (2.2 - 4.74)^2 + \cdots + (6.1 - 4.74)^2}{7-1} = 3.62 \]
Wenn wir die Varianz haben, können wir auch gleich die Standardabweichungen der Sprungweite der Hunde- und Katzenflöhe berechnen. Wir brauchen die einzelnen Standardabweichungen, um diese dann im Anschluss zusammenzufassen (eng. pool).
\[ s_{dog} = \sqrt{4.60} = 2.14 \]
\[ s_{car} = \sqrt{3.62} = 1.90 \]
Jetzt können wir die gepoolte Standardabweichung aus den einzelnen Standardabweichungen der Sprungweiten der Hunde- und Katzenflöhe berechnen.
\[ s_{p} = \cfrac{2.14 + 1.90}{2} = 2.02 \]
Abschließend setzen wir alle berechneten Werte in den Formel des Student t-Test ein. Wir können jetzt \(s_p\) und die Mittelwerte sowie die Gruppengröße \(n_g = 7\) in die Formel für den Student t-Test einfach einsetzen und die Teststatistik \(T_{D}\) berechnen.
\[ T_{D} = \cfrac{8.13 - 4.74}{2.02 \cdot \sqrt{\cfrac{2}{7}}} = 3.14 \]
Wir erhalten eine Teststatistik \(T_{D} = 3.14\) die wir mit dem kritischen Wert \(T_{\alpha = 5\%} = 2.17\) vergleichen können. Da \(T_{D} > T_{\alpha = 5\%}\) ist, können wir die Nullhypothese ablehnen. Wir haben ein signifikanten Unterschied zwischen den mittleren Sprungweiten von Hunde- und Katzenflöhen nachgewiesen.
Soweit für den Weg zu Fuß. Wir rechnen in der Anwendung keinen Student t-Test per Hand. Wir nutzen die Formel t.test(). Da wir den Student t-Test unter der Annahme der Varianzhomogenität nutzen wollen, müssen wir noch die Option var.equal = TRUE wählen. Die Funktion t.test() benötigt erst die das \(y\) und \(x\) in der Modellschreibweise mit den Namen, wie die beiden Variablen auch im Datensatz fac1_tbl stehen. In unserem Fall ist die Modellschreibweise dann jump_length ~ animal. Im Weiteren müssen wir noch den Datensatz angeben den wir verwenden wollen durch die Option data = fac1_tbl. Dann können wir die Funktion t.test() ausführen.
t.test(jump_length ~ animal,
data = fac1_tbl, var.equal = TRUE)
Two Sample t-test
data: jump_length by animal
t = 3.1253, df = 12, p-value = 0.008768
alternative hypothesis: true difference in means between group dog and group cat is not equal to 0
95 percent confidence interval:
1.025339 5.746089
sample estimates:
mean in group dog mean in group cat
8.128571 4.742857 Wir erhalten eine sehr lange Ausgabe, die auch etwas verwirrend aussieht. Gehen wir die Ausgabe einmal durch. Ich gehe nicht auf alle Punkte ein, sondern konzentriere mich hier auf die wichtigsten Aspekte.
t = 3.12528 ist die berechnete Teststatistik \(T_{D}\). Der Wert unterscheidet sich leicht von unserem berechneten Wert. Der Unterschied war zu erwarten, wir haben ja auch die t-Test Formel vereinfacht.p-value = 0.0087684 ist der berechnete p-Wert \(Pr(T_{D}|H_0)\) aus der obigen Teststatistik. Daher die Fläche rechts von der Teststatistik.95 percent confidence interval: 1.0253394 5.7460892 ist das 95% Konfidenzintervall. Die erste Zahl ist die untere Grenze, die zweite Zahl ist die obere Grenze.Wir erhalten hier dreimal die Möglichkeit eine Aussage über die \(H_0\) zu treffen. In dem obigen Output von R fehlt der kritische Wert \(T_{\alpha = 5\%}\). Daher ist die berechnete Teststatistik für die Testentscheidung nicht verwendbar. Wir nutzen daher den p-Wert und vergleichen den p-Wert mit dem \(\alpha\)-Niveau von 5%. Da der p-Wert kleiner ist als das \(\alpha\)-Niveau können wir wie Nullhypothese ablehnen. Wir haben einen signifikanten Unterschied. Die Entscheidung mit dem Konfidenzintervall benötigt die Signifikanzschwelle. Da wir hier einen Mittelwertsvergleich vorliegen haben ist die Signifikanzschwelle gleich 0. Wenn die 0 im Konfidenzintervall liegt können wir die Nullhypothese nicht ablehnen. In unserem Fall ist das nicht der Fall. Das Konfidenzintervall läuft von 1.025 bis 5.75. Damit ist die 0 nicht im Konfidenzintervall enthalten und wir können die Nullhypothese ablehnen. Wir haben ein signifikantes Konfidenzintervall vorliegen.
Wie wir sehen fehlt der Mittelwertsunterschied als Effekt \(\Delta\) in der Standardausgabe des t-Tests in R. Wir können den Mittelwertsunterschied selber berechnen oder aber die Funktion tidy() aus dem R Paket {broom} nutzen. Da der Funktion tidy() kriegen wir die Informationen besser sortiert und einheitlich wiedergegeben. Da tidy eine Funktion ist, die mit vielen statistischen Tests funktioniert müssen wir wissen was die einzelnen estimate sind. Es hilft in diesem Fall sich die Visualisierung der Daten anzuschauen und die Abbildung mit den berechneten Werten abzugleichen.
t.test(jump_length ~ animal,
data = fac1_tbl, var.equal = TRUE) |>
tidy() # A tibble: 1 × 10
estimate estimate1 estimate2 statistic p.value parameter conf.low conf.high
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 3.39 8.13 4.74 3.13 0.00877 12 1.03 5.75
# ℹ 2 more variables: method <chr>, alternative <chr>Wir erkennen als erstes den Mittelwertsunterschied zwischen den beiden Gruppen von \(3.39cm\). Danach folgen die einzelnen Mittelwerte der Sprungweiten der Hunde und Katzenflöhe mit jeweils \(8.13cm\) und \(4.74cm\). Darauf folgt noch der p-Wert als p.value mit 0.00891 und die beiden Grenzen des Konfidenzintervalls [1.03; 5.75].
Ich würde eher die Implementierung in {rstatix} der Standardimplementierung in {stats} vorziehen, da wir hier die Daten über die Pipe in die Funktion weiterleiten können. Das macht es dann doch etwas einfacher. Am Ende kommt aber das gleiche raus, so dass ich die Funktion hier als Alternative stehen lasse. Das wir noch eine Datentabelle als Ausgabe kriegen, ist natürlich auch super schön.
t_test(jump_length ~ animal,
data = fac1_tbl, var.equal = TRUE) |>
select(group1, group2, p)# A tibble: 1 × 3
group1 group2 p
<chr> <chr> <dbl>
1 dog cat 0.00877Ich habe einmal ein Video eingesprochen indem ich nochmal zeige, wie du in Excel einen t-Test rechnen kannst. Ich empfehle grundsätzlich, wenn es schon Excel sein muss, immer den Welch t-Test zu rechnen. In Excel heißt dann der Welch t-Test t-Test: Two-Sample Assuming Unequal Variances. Ich kann es nicht so richtig empfehlen, alles in Excel zu rechnen. Die Möglichkeiten sind doch arg begrenz. Aber ich kann verstehen, dass es manchmal sein muss.
Jetzt stellt sich natürlich sofort die Frage, was ist, wenn ich nicht die gleichen Varianzen in den beiden Gruppen vorliegen habe oder aber eben mir nicht sicher bin, ob die Varianzen wirklich gleich sind? Dann kannst du auch den Welch t-Test nutzen. Der Welch t-Test verlangt keine Varianzhomogenität zwischen den beiden Gruppen. Es kann also die Varianz jeweils unterschiedliche sein. Auch kann die Fallzahl in den beiden Gruppen variieren, was manchmal auch sehr praktisch sein kann. Im Allgemeinen empfehle ich eigentlich immer als Standard, wie es auch in R ist, den Welch t-Test zu nutzen. Wenn die Varianzen homogen sind, dann verlierst du nicht viel. Auf der anderen Seite gewinnst du aber mehr, wenn die Varianzen heterogen sind.
Der Welch t-Test ist auch in der Lage mit Varianzheterogenität umzugehen. Das heißt, wenn die Varianzen der beiden Gruppen nicht gleich sind. Eigentlich haben wir damit die generalisierte Formel für den t-Test vorliegen. Neben der unterschiedlichen Varianz erlaubt der Welch t-Test nämlich auch unterschiedliche Gruppengrößen zu verwenden. Wir haben dann folgende Formel vorliegen. Wir können nun wirklich jeden der drei statistischen Parameter, Mittelwert, Varianz und Fallzahl der Gruppe, entsprechend anpassen.
\[ T_{D} = \cfrac{\bar{y}_1 - \bar{y}_2}{\sqrt{\cfrac{s^2_1}{n_1} + \cfrac{s^2_2}{n_2}}} \]
mit
Wir sehen, dass sich die Formel dadurch etwas ändert. Da wir nicht mehr annehmen, dass die Varianzen homogen und daher gleich sind, können wir auch keinen gepoolten Varianzschätzer \(s_p\) berechnen. Die Varianzen gehen einzeln in die Formel des Welch t-Tests ein. Ebenso müssen die beiden Gruppen nicht mehr gleich groß sein. Statt einen Wert \(n_g\) für die Gruppengröße können wir auch die beiden Gruppengrößen mit \(n_1\) und \(n_2\) separat angeben.
Wir könne auch kurz die Formel des Student t-Test aus der Formel des Welch t-Test herleiten. Wir müssen dazu annehmen, dass wir gleiche Fallzahlen \(n_1 = n_2\) sowie die gleiche Varianz \(s^2_1 = s^2_2\) in den beiden Gruppen vorliegen haben. Dann sehen wir, dass die Formel des Welch t-Test im Nenner in sich zusammenfällt und wir die einfache Formel des Student t-Test erhalten.
\[ \begin{align} T_{D} &= \cfrac{\bar{y}_1 - \bar{y}_2}{\sqrt{\cfrac{s^2_1}{n_1} + \cfrac{s^2_1}{n_1}}}\\ &= \cfrac{\bar{y}_1 - \bar{y}_2}{\sqrt{\cfrac{s^2_1 + s^2_1}{n_1}}}\\ &= \cfrac{\bar{y}_1 - \bar{y}_2}{\sqrt{\cfrac{2 \cdot s^2_1}{n_1}}}\\ &= \cfrac{\bar{y}_1 - \bar{y}_2}{s_1 \cdot \sqrt{\cfrac{2}{n_1}}} \end{align} \]
Eine Sache muss ich noch erwähnen, wenn du den Welch t-Test nutzt, dann ändern sich auch die Freiheitsgrade für die t-Verteilung, wenn die Nullhypothese gilt, nach einer etwas schrägen Formel. Daher muss man noch bedenken, dass die Freiheitsgrade anders berechnet werden. Die Freiheitsgrade werden wie folgt mit einer etwas komplexeren Formel berechnet.
\[ df = \cfrac{\left(\cfrac{s^2_1}{n_1} + \cfrac{s^2_2}{n_2}\right)^2}{\cfrac{\left(\cfrac{s^2_1}{n_1}\right)^2}{n_1-1} + \cfrac{\left(\cfrac{s^2_2}{n_2}\right)^2}{n_2-1}} \]
Was aber in der eigentlichen Anwendung nichts zur Sache tut. Deshalb gehen wir hier auch nicht tiefer darauf ein. In der Anwendung wird intern schon mit den angepassten Freiheitsgraden gerechnet und händisch nutzten wir diese Formel nicht, wenn wir den Welch t-Test ausrechnen.
Wenn wir einen Welch t-Test per Hand berechnen wollen, dann brauchen wir ja einiges an statistischen Maßzahlen. Hier erstmal nochmal die Formel, damit wir dann für Wissen, welche der statistischen Maßzahlen wir benötigen.
\[ T_{D} = \cfrac{\bar{y}_{dog} - \bar{y}_{cat}}{\sqrt{\cfrac{s^2_{dog}}{n_{dog}} + \cfrac{s^2_{cat}}{n_{cat}}}} \]
Wir wollen nun die Werte für \(\bar{y}_{dog}\), \(\bar{y}_{cat}\) und die beiden Varianzen \(s^2_{dog}\) sowie \(s^2_{cat}\) berechnen. Die Fallzahlen für die beiden Gruppen sind ja mit jeweils sieben Flöhen schon bekannt. Wir nutzen hierfür die folgenden Formeln aus dem Kapitel zur deskriptiven Statistik. Wichtig ist nochmal, dass wir annehmen, dass die Varianz der Hundeflöhe nicht gleich der Varianz der Katzenflöhe mit \(s^2_{cat} \neq s^2_{dog}\) ist.
Fangen wir einmal an mit den Mittelwerten der Sprungweiten der Hunde- und Katzenflöhe.
\[ \bar{y}_{dog} = \cfrac{5.7 + 8.9 + 11.8 + 5.6 + 9.1 + 8.2 + 7.6}{7} = 8.13 \]
\[ \bar{y}_{cat} = \cfrac{3.2 + 2.2 + 5.4 + 4.1 + 4.3 + 7.9 + 6.1}{7} = 4.74 \]
Dann berechnen wir jeweils die Varianz der Sprungweite der Hunde- und Katzenflöhe. Dafür brauchen wir jetzt den Mittelwert der Sprungweiten.
\[ s^2_{dog} = \cfrac{(5.7 - 8.13)^2 + (8.9 - 8.13)^2 + \cdots + (7.6 - 8.13)^2}{7-1} = 4.60 \]
\[ s^2_{cat} = \cfrac{(3.2 - 4.74)^2 + (2.2 - 4.74)^2 + \cdots + (6.1 - 4.74)^2}{7-1} = 3.62 \]
Abschließend setzen wir alle berechneten Werte in den Formel des Welch t-Test ein. Wir können jetzt die Varianzen der beiden Gruppen, die Mittelwerte sowie die Gruppengröße \(n_{dog} = n_{cat} = 7\) in die Formel für den Student t-Test einfach einsetzen und die Teststatistik \(T_{D}\) berechnen.
\[ T_{D} = \cfrac{8.13 - 4.74}{\sqrt{\cfrac{4.60}{7} + \cfrac{3.62}{7}}} = 3.13 \]
Wir erhalten eine Teststatistik \(T_{D} = 3.13\) die wir mit dem kritischen Wert \(T_{\alpha = 5\%} = 2.17\) vergleichen können. Da \(T_{D} > T_{\alpha = 5\%}\) ist, können wir die Nullhypothese ablehnen. Wir haben ein signifikanten Unterschied zwischen den mittleren Sprungweiten von Hunde- und Katzenflöhen nachgewiesen.
Wir schauen uns gleich die Umsetzung in R an. Wir nutzen erneut die Funktion t.test() und zwar diesmal mit der Option var.equal = FALSE. Damit geben wir an, dass die Varianzen heterogen zwischen den beiden Gruppen sind. Wir nutzen in unserem Beispiel die gleichen Zahlen und Daten wie schon im obigen Student t-Test Beispiel.
t.test(jump_length ~ animal,
data = fac1_tbl, var.equal = FALSE)
Welch Two Sample t-test
data: jump_length by animal
t = 3.1253, df = 11.831, p-value = 0.008906
alternative hypothesis: true difference in means between group dog and group cat is not equal to 0
95 percent confidence interval:
1.021587 5.749842
sample estimates:
mean in group dog mean in group cat
8.128571 4.742857 Wir erhalten eine sehr lange Ausgabe, die auch etwas verwirrend aussieht. Gehen wir die Ausgabe einmal durch. Ich gehe nicht auf alle Punkte ein, sondern konzentriere mich hier auf die wichtigsten Aspekte.
t = 3.1253 ist die berechnete Teststatistik \(T_{D}\). Der Wert unterscheidet sich leicht von unserem berechneten Wert. Der Unterschied war zu erwarten, wir haben ja auch die t-Test Formel vereinfacht.p-value = 0.008906 ist der berechnete p-Wert \(Pr(T_{D}|H_0)\) aus der obigen Teststatistik. Daher die Fläche rechts von der Teststatistik.95 percent confidence interval: 1.021587 5.749842 ist das 95% Konfidenzintervall. Die erste Zahl ist die untere Grenze, die zweite Zahl ist die obere Grenze.Wir nutzen auch hier den p-Wert für unsere Testentscheidung. Daher vergleichen wir den p-Wert mit dem \(\alpha\)-Niveau von 5%. Da der p-Wert kleiner ist als das \(\alpha\)-Niveau können wir wie Nullhypothese ablehnen. Wir haben einen signifikanten Unterschied. Die Entscheidung mit dem Konfidenzintervall benötigt die Signifikanzschwelle. Wenn die 0 im Konfidenzintervall liegt können wir die Nullhypothese nicht ablehnen. Das Konfidenzintervall läuft von 1.022 bis 5.75. Damit ist die 0 nicht im Konfidenzintervall enthalten und wir können die Nullhypothese ablehnen. Wir haben ein signifikantes Konfidenzintervall vorliegen.
Wir sehen das viele Zahlen nahezu gleich zum Student t-Test sind. Das liegt auch daran, dass wir in unserem Daten keine große Abweichung von der Varianzhomogenität haben. Wir erhalten die gleichen Aussagen wie auch schon im Student t-Test. Schauen wir uns nochmal die Ausgabe der Funktion tidy() zum Abschluss an.
t.test(jump_length ~ animal,
data = fac1_tbl, var.equal = FALSE) |>
tidy() # A tibble: 1 × 10
estimate estimate1 estimate2 statistic p.value parameter conf.low conf.high
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 3.39 8.13 4.74 3.13 0.00891 11.8 1.02 5.75
# ℹ 2 more variables: method <chr>, alternative <chr>Ich würde eher die Implementierung in {rstatix} der Standardimplementierung in {stats} vorziehen, da wir hier die Daten über die Pipe in die Funktion weiterleiten können. Das macht es dann doch etwas einfacher. Am Ende kommt aber das gleiche raus, so dass ich die Funktion hier als Alternative stehen lasse. Das wir noch eine Datentabelle als Ausgabe kriegen, ist natürlich auch super schön.
t_test(jump_length ~ animal,
data = fac1_tbl, var.equal = FALSE) |>
select(group1, group2, p)# A tibble: 1 × 3
group1 group2 p
<chr> <chr> <dbl>
1 dog cat 0.00891Ich habe einmal ein Video eingesprochen indem ich nochmal zeige, wie du in Excel einen t-Test rechnen kannst. Ich empfehle grundsätzlich, wenn es schon Excel sein muss, immer den Welch t-Test zu rechnen. In Excel heißt dann der Welch t-Test t-Test: Two-Sample Assuming Unequal Variances. Ich kann es nicht so richtig empfehlen, alles in Excel zu rechnen. Die Möglichkeiten sind doch arg begrenz. Aber ich kann verstehen, dass es manchmal sein muss.
Wir sehen hier etwas besser, dass es kaum Abweichungen gibt. Alles egal? Nicht unbedingt. Das Problem ist eher das Erkennen von Varianzheterogenität in sehr kleinen Datensätzen. Kleine Datensätze meint Datensätze unter 30 Beobachtungen je Gruppe. Erst aber dieser Anzahl lassen sich unverzerrte Histogramme zeichnen und so aussagekräftige Abschätzungen der Varianzhomogenität oder Varianzheterogenität treffen.
Für das Erkennen von Normalverteilung und Varianzheterogenität werden häufig so genannte Vortest empfohlen. Aber auch hier gilt, bei kleiner Fallzahl liefern die Vortests keine verlässlichen Ergebnisse. In diesem Fall ist weiterhin die Beurteilung über einen Boxplot sinnvoller. Du findest hier mehr Informationen im Kapitel zum Pre-Test oder Vortest.
Es kommt häufiger mal vor, dass wir an dem gleichen Tier oder der gleichen Pflanze Messungen durchführen. Dann haben wir es mit abhängigen oder verbundenen Beobachtungen zu tun. Hier müssen wir dann zu einem anderen t-Test greifen, nämlich den t-Test für abhängige Beobachtungen. Wir nennen den t-Test auch gerne gepaarten t-Test (eng. paired t test).
Was ist nun der theoretische Hintergrund des gepaarten t-Test? Wir brauchen dafür zwei Spalten, die jeweils zwei Messungen am gleichen Tier oder an der gleichen Pflanze darstellen. Dann bilden wir die Differenz der Messwerte für die erste Messung sowie der zweiten Messung und nennen diesen Wert dann \(\Delta\) (deu. Delta). Wir rechnen den Test also auf der deskriptiven Statistik der Differenzen. Es ergeben sich dann die folgenden Hypothesenpaare für den gepaarten t-Test.
Wir testen, ob der Mittelwert der Differenzen gleich Null ist. \[\bar{\Delta} = 0\]
Als Alternative ist der Mittelwert der Differenzen ungleich Null. \[\bar{\Delta} \neq 0\]
Dann brauchen wir natürlich auch eine Datentabelle mit der ID der Beobachtung, damit auch klar wird, dass wir eine Beobachtung zweimal messen. Dann kommen die beiden Messungen und anschließend die berechnete Differenz der beiden Messungen. Zwischen den Messungen kann natürlich beliebig viel Zeit vergehen. Je länger der Zeitraum, desto eher könntest du von unabhängigen Beobachtungen ausgehen.
| ID Beobachtung | Messung 1 | Messung 2 | Differenz \(\boldsymbol{\Delta}\) |
|---|---|---|---|
| 1 | \(y_{11}\) | \(y_{21}\) | \(\Delta_1 = y_{11} - y_{21}\) |
| 2 | \(y_{12}\) | \(y_{22}\) | \(\Delta_2 = y_{12} - y_{22}\) |
| 3 | \(y_{13}\) | \(y_{23}\) | \(\Delta_3 = y_{13} - y_{23}\) |
| \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) |
| n | \(y_{1n}\) | \(y_{2n}\) | \(\Delta_n = y_{1n} - y_{2n}\) |
| \(\bar{\Delta}\) |
Wir nutzen folgende Formel für den gepaarten t-Test für verbundene Stichproben. Wir teilen als deen Mittelwert der Differenzen durch die Standardabweichung der Differenzen. Dann multiplizieren wir mit der Anzahl der Beobachtungen.
\[ T_{D} = \sqrt{n}\cdot\cfrac{\bar{\Delta}}{s_{\Delta}} \]
mit
Den Wert der Teststatistik aus den Daten \(T_{D}\) können wir dann wie immer mit einem kritischen Wert mit \(T_{\alpha = 5\%}\) vergleichen. Diesen Wert \(T_{\alpha = 5\%}\) erhälst du dann in der Klausur oder aber ist den Anwendungsprogrammen bekannt. Da musst du dir in der Anwendung keine Gedanken zu machen.
Im folgenden Datenbeispiel in Tabelle 31.5 haben wir eine verbundene Stichprobe. Das heißt wir haben nicht zehn Flöhe gemessen sondern fünf Flöhe jewiels zweimal. Einmal haben wir die Sprungweite der Flöhe im ungefütterten Zustand hungrig und einmal im gefütterten Zustand satt gemessen. Wir wollen nun wissen, ob der Fütterungszustand Auswirkungen auf die Sprungweite in [cm] hat. Hier dann nochmal die Tabelle als Erinnerung.
| hungrig | satt | diff |
|---|---|---|
| 5.2 | 6.1 | 0.9 |
| 4.1 | 5.2 | 1.1 |
| 3.5 | 3.9 | 0.4 |
| 3.2 | 4.1 | 0.9 |
| 4.6 | 5.3 | 0.7 |
Als erstes brauchen wir den Mittelwert der Differenzen. Daher berechnen wir einmal den Mittelwert der Differenzen \(\Delta\) wie folgt aus.
\[ \bar{\Delta} = \cfrac{0.9 + 1.1 + 0.4 + 0.9 + 0.7}{5} = 0.8 \]
Und dann brauchen wir auch einmal die Standardabweichung der einzelnen Differenzen zu dem Mittelwert der Differenzen \(\bar{\Delta}\). Wir rechnen natürlich die Standardabweichung als Wurzel der Varianz aus. Deshalb die Wurzel hier in der Formel.
\[ s_{\Delta} = \sqrt{\cfrac{(0.9 - 0.8)^2 + (1.1 - 0.8)^2 + \cdots + (0.7 - 0.8)^2}{n-1}} \]
Wir können jetzt \(\bar{\Delta}\) als Mittelwert der Differenzen die Standardabweichung der Differenzen \(s_{\Delta}\) in die Formel für den t-Test für verbundene Beobachtungen einsetzen.
\[ T_{D} = \sqrt{5}\cfrac{0.8}{0.26} = 6.88 \]
Jetzt brauchen wir natürlich noch einen kritischen Wert \(T_{\alpha = 5\%}\) und der wäre in diesem Fall gleich \(1.86\). Damit können wir dann die Nullhypothese ablehnen, dass wir keinen Effekt der Behandlung vorliegen haben. Es macht einen Unterschied, wie wir die Flöhe gefüttert haben. Da das \(\Delta\) positiv ist, können wir auch sagen, dass gefütterte Flöhe weiter springen als nicht gefütterte Flöhe.
Dann haben wir hier einmal unseren kleinen Datensatz, den wir für unseren gepaarten t-Test nutzen wollen. Wir brauchen die id um später nochmal die Daten besser darstellen zu können. Ich möchte nämlich in den Ergebnisabbildungen weiter unten die Beobachtungen miteinander verbinden.
Um den die Funktion t.test()in R mit der Option paired = TRUE für den paired t-Test zu nutzen, müssen wir die Daten jeweils als Vektor in die Funktion übergeben. Daher als erstes die Spalte mit den Informationen zu den ungefütterten Flöhen und dann die Spalte mit der Information zu den gefütterten Flöhen. Wir wollen nun wissen, ob der Fütterungszustand nun eine Auswirkungen auf die Sprungweite in [cm] hat.
t.test(paired_tbl$satt, paired_tbl$hungrig,
paired = TRUE)
Paired t-test
data: paired_tbl$satt and paired_tbl$hungrig
t = 6.7612, df = 4, p-value = 0.002496
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
0.4714866 1.1285134
sample estimates:
mean difference
0.8 Die Ausgabe des paired t-Test ähnelt stark der Aussage des Student t-Test. Wir erhalten ebenfalls den wichtigen p-Wert mit 0.0025 sowie das 95% Konfidenzintervall mit [0.47; 1.13]. Zum einen ist \(0.0025 < \alpha\) und somit können wir die Nullhypothese ablehnen, zum anderen ist auch die 0 nicht mit in dem Konfidenzintervall, womit wir auch hier die Nullhypothese ablehnen können.
Ich würde eher die Implementierung in {rstatix} der Standardimplementierung in {stats} vorziehen, da wir hier die Daten über die Pipe in die Funktion weiterleiten können. Das macht es dann doch etwas einfacher. Am Ende kommt aber das gleiche raus, so dass ich die Funktion hier als Alternative stehen lasse. Das wir noch eine Datentabelle als Ausgabe kriegen, ist natürlich auch super schön.
t_test(jump_length ~ trt, data = paired_long_tbl,
paired = TRUE) |>
select(group1, group2, p)# A tibble: 1 × 3
group1 group2 p
<chr> <chr> <dbl>
1 hungrig satt 0.0025Für vielleicht viele, auch für die sich schon länger mit der Statistik beschäftigen, ist es immer wieder eine Überraschung, dass sich die gängigen statistischen Tests auch als Modelle abbilden lassen. Die Übersicht Common statistical tests are linear models liefert hier nochmal eine wunderbare Tabelle. Ich zeige hier die Modellierungen in lm() sowie gls(), die ja eigentlich als Regression gilt und nicht als Test. Hier siehst du, wie sich dann auch über die Jahre Zusammenhänge herausgestellt haben, die dann methodisch vereinheitlicht wurden. Ich habe dir den direkten Vergleich dann immer in den zweiten Tab gelegt. Dann beginnen wir mit dem linearen Modell mit lm(), die dann auf einer kategoriellen Einflussvariable einen t-Test rechnet.
lm(jump_length ~ animal, data = fac1_tbl) |>
summary()
Call:
lm(formula = jump_length ~ animal, data = fac1_tbl)
Residuals:
Min 1Q Median 3Q Max
-2.5429 -1.3179 -0.1857 0.9214 3.6714
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 8.129 0.766 10.611 1.88e-07 ***
animalcat -3.386 1.083 -3.125 0.00877 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.027 on 12 degrees of freedom
Multiple R-squared: 0.4487, Adjusted R-squared: 0.4028
F-statistic: 9.767 on 1 and 12 DF, p-value: 0.008768t.test(jump_length ~ animal,
data = fac1_tbl, var.equal = TRUE)
Two Sample t-test
data: jump_length by animal
t = 3.1253, df = 12, p-value = 0.008768
alternative hypothesis: true difference in means between group dog and group cat is not equal to 0
95 percent confidence interval:
1.025339 5.746089
sample estimates:
mean in group dog mean in group cat
8.128571 4.742857 Neben der klassischen Regression, die dann homogene Varianzen in den Gruppen annimmt, können wir die Regression auch mit der Funktion gls() aus dem R Paket {nlme} rechen. Dann haben wir auch die Möglichkeit die heterogenen Varianzen in den Gruppen zu berücksichten.
gls(jump_length ~ animal, data = fac1_tbl,
weights = varIdent(form = ~ 1 | animal)) |>
summary()Generalized least squares fit by REML
Model: jump_length ~ animal
Data: fac1_tbl
AIC BIC logLik
62.81397 64.75359 -27.40698
Variance function:
Structure: Different standard deviations per stratum
Formula: ~1 | animal
Parameter estimates:
dog cat
1.0000000 0.8867314
Coefficients:
Value Std.Error t-value p-value
(Intercept) 8.128571 0.8105592 10.028350 0.0000
animalcat -3.385714 1.0833307 -3.125282 0.0088
Correlation:
(Intr)
animalcat -0.748
Standardized residuals:
Min Q1 Med Q3 Max
-1.3371992 -0.6930148 -0.0997879 0.4296630 1.7119904
Residual standard error: 2.144538
Degrees of freedom: 14 total; 12 residualt.test(jump_length ~ animal,
data = fac1_tbl, var.equal = FALSE)
Welch Two Sample t-test
data: jump_length by animal
t = 3.1253, df = 11.831, p-value = 0.008906
alternative hypothesis: true difference in means between group dog and group cat is not equal to 0
95 percent confidence interval:
1.021587 5.749842
sample estimates:
mean in group dog mean in group cat
8.128571 4.742857 Dann haben wir noch den Fall, dass wir einen paarweisen Vergleich rechnen wollen. In dem Fall nutzen wir wieder die Funktion lm() in einem linearen Modell, rechnen aber mit der Differenz. Die Schreibweise ist etwas wild, aber wir schauen einfach, ob sich die Differenz der beiden Spalten von Null unterscheidet. Nichts anderes macht ja auch der gepaarte t-Test.
lm(hungrig - satt ~ 1, data = paired_tbl) |>
summary()
Call:
lm(formula = hungrig - satt ~ 1, data = paired_tbl)
Residuals:
1 2 3 4 5
-0.1 -0.3 0.4 -0.1 0.1
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.8000 0.1183 -6.761 0.0025 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.2646 on 4 degrees of freedomt.test(paired_tbl$satt, paired_tbl$hungrig,
paired = TRUE)
Paired t-test
data: paired_tbl$satt and paired_tbl$hungrig
t = 6.7612, df = 4, p-value = 0.002496
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
0.4714866 1.1285134
sample estimates:
mean difference
0.8 {tidyplots}Häufig wollen wir nicht nur den p-Wert aus einem t-Test berichten sondern natürlich auch gleich die richtige Abbildung dazu haben. Hier gibt es mit dem R Paket {tidyplots} eine gute Möglichkeit. Das R Paket verbindet dabei die Funktionalität von {ggplot} und {ggpubr}. Dabei bleibt es aber dann sehr einfahc zu bedienen. Insbesondere in dem Fall, dass du nur zwei Gruppen in einem t-Test miteinander vergleichen willst.
{tidyplots}
Das R Paket {ggpubr} bietet auch noch andere Alternativen für die Darstellung von statistischen Vergleichen in deinen Daten unter ggpubr: ‘ggplot2’ Based Publication Ready Plots. Vielleicht findest du da auch noch eine bessere Abbildung als hier. Da wir hier sehr viel ähnliches haben, bleibe ich bei {tidyplots}.
Neben den p-Werten, die ich hier mit der Funktion add_test_pvalue() ergänze kannst du auch Sterne mit der Funktion add_test_asterisks() nutzen. Das liegt dann ganz bei dir. Es gibt auch die Möglichkeit nicht signifikante Ergebnisse auszublenden. Mehr dazu findest du dann auf der Hilfeseite zu den statistischen Vergleichen in {tidyplots}. Ich zeige hier dir nur die Standardanwendung. Wichtig ist auch zu wissen, dass wir immer einen Welch t-Test rechnen, also immer für die Varianzheterogenität adjustieren. Das ist auch eigentlich die bessere Variante als der Student t-Test. Häufig ist es sehr schwer in kleinen Fallzahlen abzuschätzen wie die Varianzen in den Gruppen sind. Dann lieber gleich richtig adjsutieren und auf der sicheren Seite sein.
Die Standardabbildung ist sicherlich der Barplot zusammen mit der Standardabweichung als Fehlerbalken. Dann habe ich noch die einzelnen Beobachtungen ergänzt. Die Klammer über den beiden Säulen gibt den Vergleich an und die Zahl ist der p-Wert aus einem Welch t-Test. Wir sehen hier, dass sich die beiden Floharten in den Sprungweiten signifikant unterscheiden. Der p-Wert ist kleiner als das Signifikanzniveau \(\alpha\) gleich 5%.
tidyplot(data = fac1_tbl,
x = animal, y = jump_length, color = animal) |>
add_data_points() |>
add_mean_bar(alpha = 0.4, width = 0.4) |>
add_sd_errorbar(width = 0.2) |>
add_test_pvalue(method = "t_test", hide_info = TRUE) |>
remove_legend() |>
adjust_font(fontsize = 9) |>
adjust_x_axis_title("Flohart") |>
adjust_y_axis_title("Sprungweite in [cm]") |>
rename_x_axis_labels(new_names = c("dog" = "Hund", "cat" = "Katze")) |>
adjust_size(width = NA, height = NA) 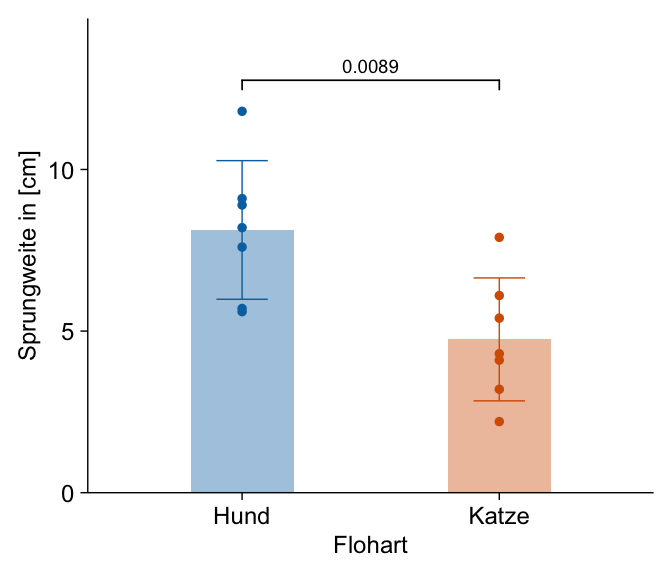
Es gibt auch gute Gründe ienmal den Boxplot zu wählen, wenn wir etwas besser die Verteilung der Sprungweiten darstellen wollen. Ich habe dann noch die einzelnen Beobachtungen ergänzt. Die Klammer über den beiden Säulen gibt den Vergleich an und die Zahl ist der p-Wert aus einem Welch t-Test. Wir sehen hier, dass sich die beiden Floharten in den Sprungweiten signifikant unterscheiden. Der p-Wert ist kleiner als das Signifikanzniveau \(\alpha\) gleich 5%.
tidyplot(data = fac1_tbl,
x = animal, y = jump_length, color = animal) |>
add_data_points() |>
add_boxplot(alpha = 0.4, box_width = 0.3) |>
add_test_pvalue(method = "t_test", hide_info = TRUE) |>
remove_legend() |>
adjust_font(fontsize = 9) |>
adjust_x_axis_title("Flohart") |>
adjust_y_axis_title("Sprungweite in [cm]") |>
rename_x_axis_labels(new_names = c("dog" = "Hund", "cat" = "Katze")) |>
adjust_size(width = NA, height = NA) 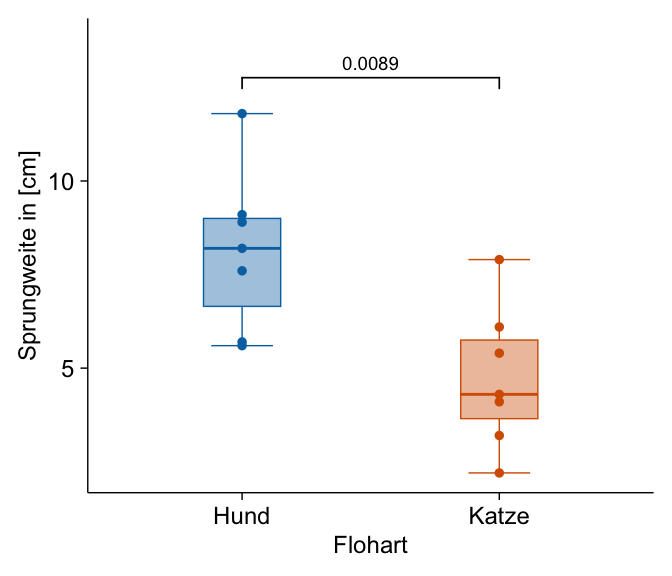
Am Ende wollen wir uns dann nochmal den gepaarten t-Test anschauen. Hier ist dann die Abbildung realtiv einfach. Wir können da die Daten paired_tbl aus dem gepaarten t-Test nutzen nachdem wir die Daten in das Long-Format überführt haben. Etwas schwieriger ist dann der p-Wert, den p-Wert müssen wir dann erst selber errechnen und dann ergänzen. Hier nutzen wir dann den gepaarten Datensatz in dem Long-Format.
Jetzt können wir den gepaarten t-Test rechnen und zwar aus dem R Paket {rstatix}. Dann müssen wir noch alles so umbauen, dass wir die Informationen dann in {tidyplots} auch nutzen können.
stats_tbl <- paired_long_tbl |>
arrange(id) |>
t_test(jump_length ~ trt, paired = TRUE) |>
add_significance() |>
add_xy_position()Wir nutzen hier die Funktion stat_pvalue_manual() um händisch die p-Werte zu den Dotplot mit den Mittelwert und Standardabweichung zu ergänzen. Die Verbindungen zwischen den Beobachtungen haben wir dann durch add_line() erzeugt. Ich gebe zu, dass ist etwas komplizierter. Wenn du dann die Sterne haben willst, dann musst due das Label auf "p.signif" setzen. Dann werden statt der p-Werte "p" dir die Sterne * angezeigt. Wir sehen hier, dass sich die beiden Fütterungslevel in den Sprungweiten signifikant unterscheiden. Der p-Wert ist kleiner als das Signifikanzniveau \(\alpha\) gleich 5%.
paired_long_tbl |>
tidyplot(x = trt, y = jump_length, color = trt, fill = NA) |>
add_line(group = id, color = "grey") |>
add_data_points() |>
add_mean_dash(width = 0.2) |>
add_sd_errorbar(width = 0.2) |>
add(stat_pvalue_manual(stats_tbl, size = 7/.pt, label = "p",
bracket.nudge.y = 0.1)) |>
remove_legend() |>
adjust_font(fontsize = 9) |>
adjust_x_axis_title("Fütterung") |>
adjust_y_axis_title("Sprungweite in [cm]") |>
reorder_x_axis_labels("unfed", "fed") |>
rename_x_axis_labels(new_names = c("fed" = "gefüttert", "unfed" = "ungefüttert")) |>
adjust_size(width = NA, height = NA) 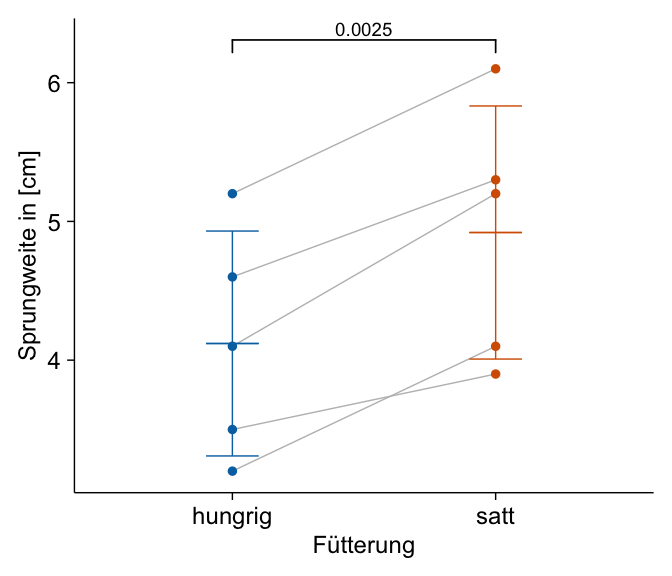
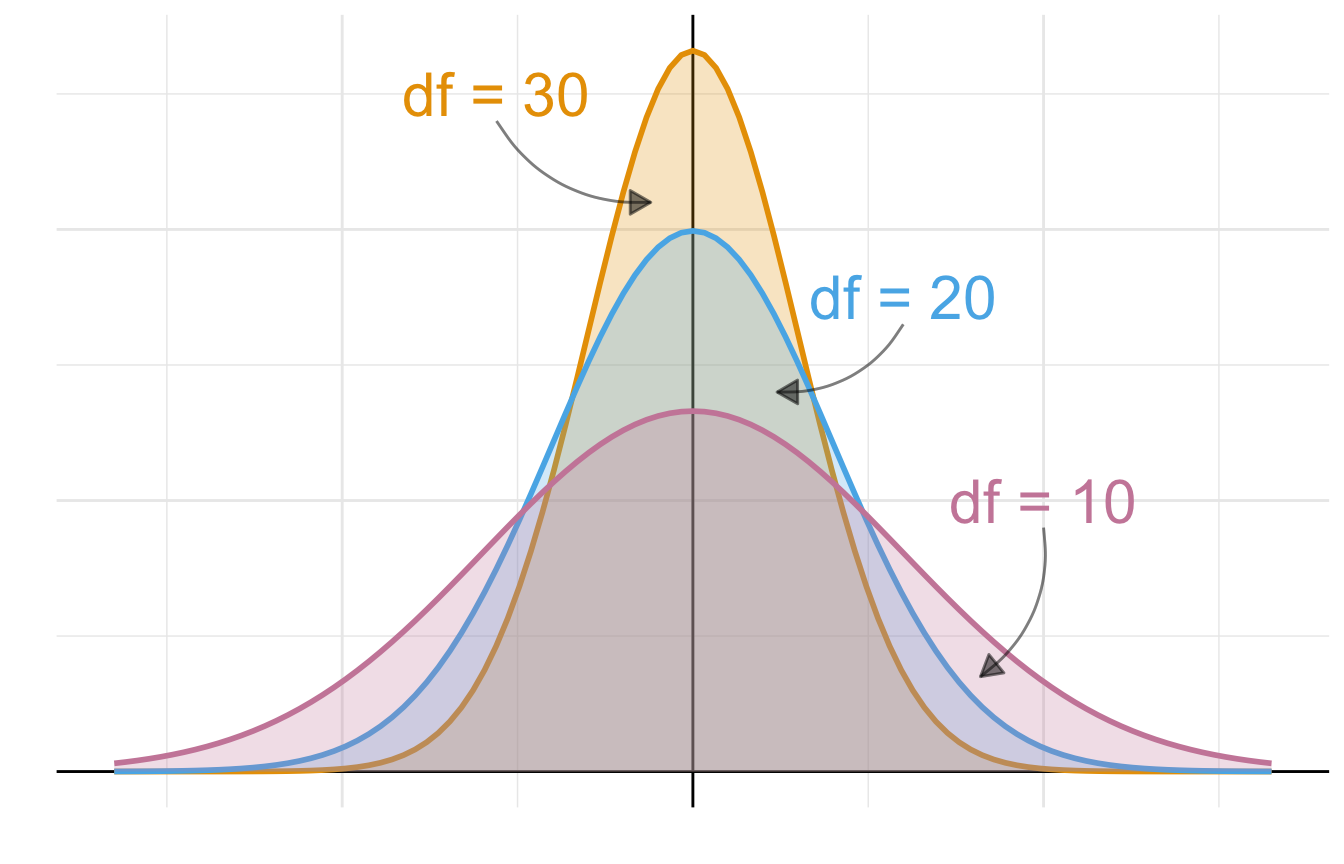
Der t-Verteilung der Teststatistiken des t-Tests verhält sich nicht wie eine klassische Normalverteilung, die durch den Mittelwert und die Standardabweichung definiert ist. Die t-Verteilung ist nur durch die Freiheitsgrade definiert. Der Freiheitsgrad (eng. degree of freedom, abk. df) in einem t-Test mit zwei Gruppen mit den Fallzahlen \(n_1\) und \(n_2\) ist gegeben durch \(df = n_1 + n_2 -2\). Damit beschreiben die Freiheitsgrade grob die gesamte Fallzahl in einen Datensatz mit nur zwei Gruppen. Je mehr Fallzahl in den beiden Gruppen desto großer der Freiheitsgrad eines t-Tests.
Die Abbildung 31.10 visualisiert diesen Zusammenhang von Freiheitsgraden und der Form der t-Verteilung. Je kleiner die Freiheitsgrade und damit die Fallzahl in unseren beiden Gruppen, desto weiter sind die Verteilungsschwänze. Wie du sehen kannst, reicht die rote Verteilung mit einem Freiheitsgrad von \(df = 10\) viel weiter nach links und rechts als die anderen Verteilungen mit niedrigeren Freiheitsgraden. Daher benötigen wir auch größere \(T_{D}\) Werte um ein signifikantes Ergebnis zu erhalten. Denn die Fläche unter der t-Verteilung ist immer gleich 1 und somit wandert dann der kritische Wert \(T_{\alpha = 5\%}\) immer weiter nach außen. Das macht ja auch Sinn, wenn wir wenige Beobachtungen vorliegen haben, dann brauchen wir größere Werte der Teststatistik um an einen signifikanten Effekt glauben zu können.