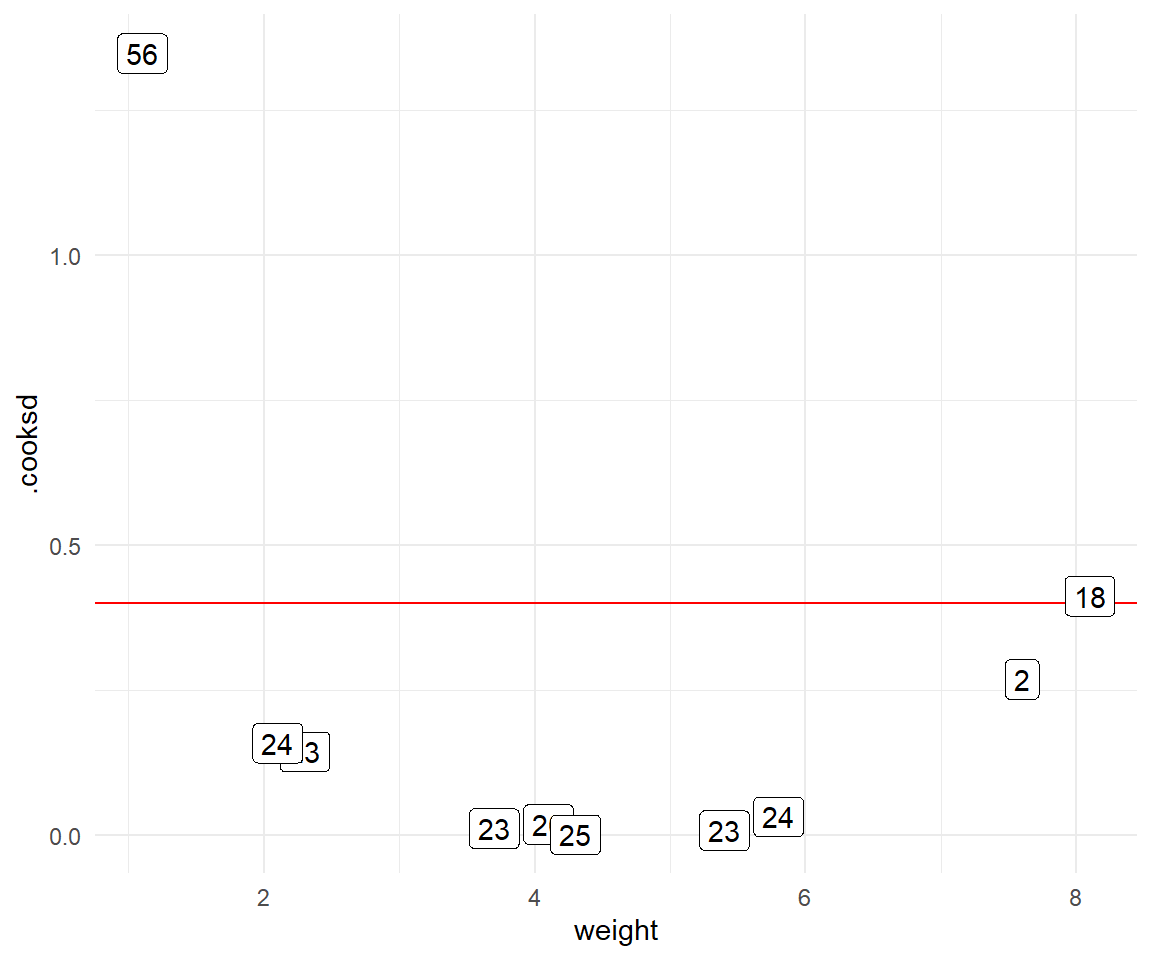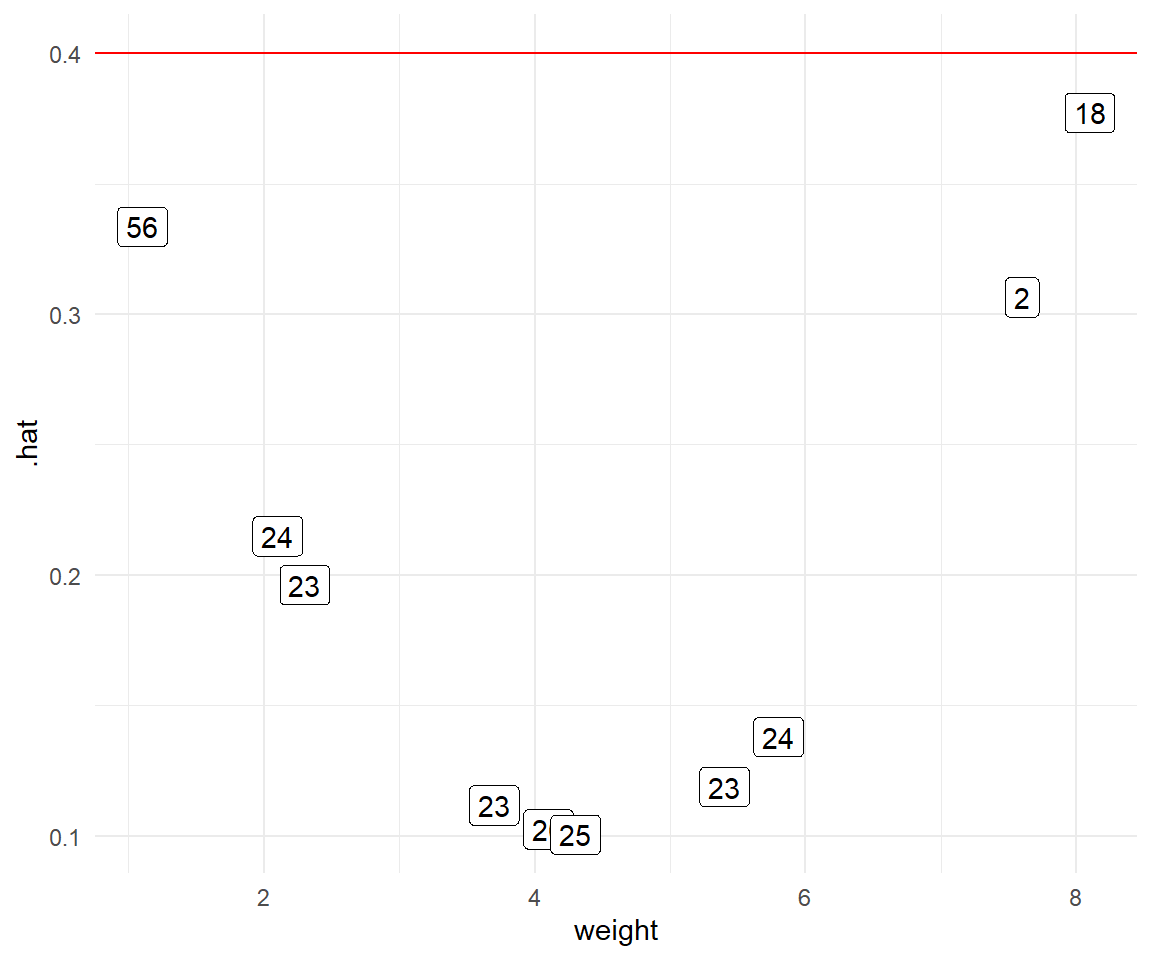```{r echo = FALSE}
pacman::p_load(tidyverse, readxl, knitr, kableExtra)
```
# Ausreißer {#sec-outlier}
*Letzte Änderung am `r format(fs::file_info("stat-modeling-outlier.qmd")$modification_time, '%d. %B %Y um %H:%M:%S')`*
> *"You should be far more concentrated with your current trajectory than with your current results" --- James Clear in Atomic Habits'*
Was sind Ausreißer (eng. *Outlier*) in einem Datensatz? An sich schon eine schwierige Frage. Einige Wissenschaftler behaupten es gebe keine Ausreißer. Die Daten müssten so ausgewertet werden wie die Daten erhoben wurden. Was es gäbe wären technische Artefakte, diese müssten entdeckt und entfernt werden. Andere Wissenschaftler meinen, dass Ausreißer schon existieren und entfernt werden müssen, wenn diese Ausreißer nicht zu der Fragestellung oder den restlichen Daten passen. Es ist eine unbekannte Subpopulation, die sich mit einem oder zwei Vertretern in unsere Daten geschmuggelt hat. Diese Subpopulation verzerrt nur das Ergebnis, da wir mit diesen wenigen anderen Beobachtungen sowieso keine Aussage treffen können. @cook2021philosophy meint in seiner wissenschaftlichen Veröffentlichung [The Philosophy of Outliers: Reintegrating Rare Events Into Biological Science](https://academic.oup.com/icb/article/61/6/2191/6324573), dass gerade die seltenen Ereignisse, die wir als Ausreißer definieren, dann vielleicht die spannenden Beobachtungen sind. Warum verhält sich gerade diese eine Beobachtung in diesem Experiment so seltsam? Was will uns die Beobachtung mehr über die biologischen Hintergründe verraten? Aber auch im Falle von @cook2021philosophy müssen wir uns sicher sein, dass unsere Ausreißer keine Tippfehler oder einfach nur nicht gegossene Pflanzen sind. Dazu aber gleich nochmal mehr.
Am Ende geht es aber darum Ausreißer zu finden und diese aus den Daten zu entfernen. Wir setzen dann diese Werte der Ausreißer auf `NA` für fehlender Wert (eng. *not available*). Oder aber wir ersetzen die Ausreißer durch passendere Werte aus unseren Daten. Im Prinzip ein wenig wie finde den Ausreißer und imputiere den Ausreißer mit einer anderen Zahl. Mehr zur Imputation von fehlenden Werten findest du in @sec-missing. Vermeide bitte eine Ausreißer/Imputationsschleife in der du immer wieder Ausreißer findest und diese dann wieder imputierst! Gerade dieses Thema Ausreißer kann sehr gut von biologischen Fachexperten diskutiert werden. In den folgenden Abschnitten wollen wir uns verschiedene Möglichkeiten der Detektion von Ausreißern annähern. Es geht wie immer von algorithmisch einfach zu komplexer. Es ist auch möglich mit der Hauptkomponentenanalyse Ausreißer zu finden, aber das ist dann Thema in dem entsprechenden @sec-pca-main. Bitte dann dort einmal nachschauen. Darüber hinaus gebe ich zuerst nochmal eine kleine Auswahl an Literatur zu dem Thema Ausreißer. Die kannst du auch überspringen, wenn dich das Thema nicht tiefer interessiert. Ein weitreichenden Überblick liefert aber auf jeden Fall @boukerche2020outlier mit ihrer wissenschaftlichen Veröffentlichung [Outlier Detection: Methods, Models, and Classification](https://dl.acm.org/doi/abs/10.1145/3381028?casa_token=eXl2SvgkPNcAAAAA:Lgs0l4CXmw3mXyzSMVj9-_M2ry0F-lTyfsYUszWhkRJU9TNg5-JjzCaBaOeFSVifSCkvoyQdeuCvvQ).
::: {layout="[15,85]" layout-valign="top"}
{fig-align="center" width="100%"}
> Bitte beiße dich nicht an der *statistischen* Auslegung eines Ausreißers fest. Du bist der Herr oder die Frau über deine Daten. Kein Algorithmus weiß mehr als du. Das macht statistischen Engel natürlich traurig...
:::
Bitte beachte, dass wenn du weist, dass ein Wert nicht richtig ist, diesen dann auch entfernt. Wenn du während der Beprobung oder Messung feststellst, dass du leider auf dem Feld zu wenig Erde mitgenommen hast, dann trage ein `NA` in die Tabelle ein. Unsinnige Werte einzutragen, nur weil die "ja so entstanden sind", macht keinen Sinn. Auch kann es sein, dass du dich mal vertippst. Das heißt, du hast in die Exceltabelle eine Null oder ein Komma falsch gesetzt. Das findest du dann ja meist in der explorativen Datenanalyse raus. In dem Fall korrigiere diese falschen Werte und mache bitte nicht hier mit der Detektion von Ausreißern weiter. Wenn du selber weist, warum da so ein komischer Wert in der Tabelle steht, dann korrigiere den Wert und schreibe in deinen Bericht, was du getan hast.
Neben der Biologie gibt es das Problem der Ausreißer oder ungewöhnlichen Messwerte auch in der Physik. Dort heißt das Konzept $5\sigma$ (eng. *five sigma*, deu. *fünf sigma*) auch wenn es nach @lyons2013discovering und der wissenschaftlichen Veröffentlichung [Discovering the sigificance of 5$\sigma$](https://arxiv.org/pdf/1310.1284.pdf) nicht unumstritten ist. Vor allem ist es aber ein einfaches Konzept, da wir mit $\sigma$ die Standardabweichung meinen. Ein Fünf-Sigma-Wert entspricht einer Wahrscheinlichkeit, und daher mehr oder minder einem $p$-Wert, von $3 \cdot 10^7$, also etwa einem Auftreten von einem Ereignis mit einer Wahrscheinlichkeit von eins zu 3.5 Millionen. Nehmen wir zum Beispiel ein Experiment, bei dem wir 100 Mal eine Münze werfen. Das erwartete Ergebnis sei 50-mal Kopf und die Standardabweichung $\sigma$ eines solchen Experiments sei fünf. Wenn du nun 55-mal Kopf erhälst, dann ist das ein $1\sigma$-Effekt, bei 60-mal Kopf ist das ein $2\sigma$-Effekt, bei 65-mal ein $3\sigma$-Effekt, bei 70-mal ein $4\sigma$-Effekt und bei 75-mal Kopf ein $5\sigma$-Effekt. Wenn du also einen $5\sigma$-Effekt beobachtest, dann ist es sehr unwahrscheinlich, dass deine Erweartung an 50-mal Kopf wahr ist. Du hast vermutlich eine gefälschte Münze vorliegen. Mehr dazu auch auf der Seite des CERN und dem Artikel [Why do physicists mention "five sigma" in their results?](https://home.cern/resources/faqs/five-sigma)
Soweit unser kleiner Ausflug in die Physik. @michel2020new beschreiben in ihrer Veröffentlichung [New Author Guidelines for Displaying Data and Reporting Data Analysis and Statistical Methods in Experimental Biology](https://jpet.aspetjournals.org/content/jpet/372/1/136.full.pdf) Methoden und Anleitungen für die Veröffentlichung von Studien. Wir wollen uns hier einmal auf die Beschreibung der Ausreißer konzentrieren. So schreiben die Autoren wie folgt.
> *Before identifying outliers, authors should consider the possibility that the data come from a lognormal distribution, which may make a value look as an outlier on a linear but not on a logarithmic scale. --- @michel2020new, p. 139*
Wir sollen also einmal überlegen, ob wir vielleicht Daten vorliegen haben, die keiner Normalverteilung folgen und durch eine Transformation wiederum in eine Normalverteilung überführt werden könnten. Die Ausreißer, die wir beobachten gehören also zu den Daten, wir glauben nur an eine falsche Verteilung der Daten und schließen deshalb die Beobachtungen aus. Mehr dazu dann auch in dem Kapitel zu der [Transformieren von Daten](#sec-eda-transform).
Und auch @michel2020new schreiben wie folgt, dass die eigentliche Entscheidung bei den Forschenden liegt, die die Daten erhoben haben.
> *The choice of the appropriate method for handling apparent outliers depends on the specific circumstances and is up to the investigators. The \[journal\] ask authors to state in the methods or results section what quality control criteria were used to remove "bad experiments" or outliers, whether these criteria were set in advance, and how many bad points or experiments were removed. --- @michel2020new, p. 139*
Was dich natürlich nicht davon befreit, einmal zu zeigen, welche Daten entfernt wurden und welche nicht. Meistens ist es aber natürlich so, dass die Ausreißer schon einen Effekt ausmachen, sondt müsste man die Werte ja auch nicht entfernen.
> *It may also make sense to report in an online supplement the details on every value or experiment removed as outliers, and to report in that supplement how the results would differ if outliers were not removed. --- @michel2020new, p. 139*
Nun ist die Ausreißerbestimmung (eng. *outlier detection*) auch nicht umstritten. So schreiben @zimek2018there in ihrer etwas längeren Veröffentlichung [There and back again: Outlier detection between statistical reasoning and data mining algorithms](https://findresearcher.sdu.dk/ws/files/153197807/There_and_Back_Again.pdf) folgenden Absatz zu Ausreißern und was Ausreißer sind.
> *"\[A\]n observation (or subset of observations) which appears to be inconsistent with the remainder of that set of data". In about two decades of research in data mining many methods have been proposed to identify such outliers. Much attention has been spent on doing this ever faster, less attention has been attributed to the description "appears to". --- @zimek2018there*
Und so drehen wir uns auch hier etwas im Kreis, denn die Frage bleibt immer, was soll den ein Ausreißer sein? Zu welcher Gruppe an Daten vergleichst du den die einzelnen Werte um zu entscheiden, dass dieser bestimmte Wert jetzt ein Ausreißer ist? Den Gedankengang greifen @sejr2021explainable nochmal mit ihrer Veröffentlichung [Explainable outlier detection: What, for Whom and Why?](https://www.sciencedirect.com/science/article/pii/S2666827021000864) auf. In der Arbeit gehen beide nochmal auf die Problematik ein, dass eine Ausreißerbestimmung immer im Kontext der Forschung und auch der Zielgruppe der Forschung gesehen werden muss. Wem willst du eigentlich die Studie berichten? Was ist das Ziel der Studie und wie sind in diesem Kontext Ausreißer zu sehen?
::: {layout="[15,85]" layout-valign="top"}
{fig-align="center" width="100%"}
> Mein Tipp wäre es jetzt es erstmal mit dem Hampelfilter zu versuchen oder aber der Sigmaregel. Beide Verfahren sind einfach nachzuvollziehen und funktionieren gut. Wenn es komplexer wird, dann gerne das R Paket `{performance}`. Für den Fall, dass du eine Gaussianregression rechnest, dann kannst du auch einmal in das R Paket `{olsrr}` schauen. Im Anwendungsbeispiel am Ende des Kapitels schaue ich mir dann einmal die cook'sche Distanz an, da aus einer Regression wir schnell diese Metrik erhalten.
:::
Siehe dazu auch das Kapitel der [Sensitivitätsanalyse](#sec-sensitivity). Nachdem wir Beobachtungen aus unseren Daten entfernt haben, ist es häufig üblich noch eine Sensitivitätsanalysen durchzuführen. Wir Vergleich dann das *gereinigte* Modell mit *anderen* Modellen. Oder wir wollen die Frage beantworten, was hat eigentlich mein Entfernen von Ausreißern am Ergebnis geändert? Habe ich eine wichtige Beobachtung rausgeschmissen? Am Ende musst du dann natürlich entscheiden, ob das Ergebnis ohne Ausreißer biologisch sinnvoller ist als das Experiment mit Ausreißern. Besonders wenn dann auch andere Ergebnisse rauskommen.
::: callout-tip
## Weitere Tutorien für das Finden von Ausreißern
Wir immer geht natürlich mehr als ich hier Vorstellen kann. Du findest im Folgenden Tutorien, die mich hier in dem Kapitel inspiriert haben.
- [Outliers detection in R](https://statsandr.com/blog/outliers-detection-in-r/) bietet einen sehr schönen Überblick über Möglichkeiten Ausreißer in Daten zu finden. Ich habe Teile des Tutoriums auch hier in dem Kapitel verwendet.
- [8 methods to find outliers in R (with examples)](https://www.reneshbedre.com/blog/find-outliers.html) ist ein ähnliches Tutorium. Es gibt nochmal einen guten Überblick ist aber um einiges kürzer. Daher etwas schneller zu lesen.
- [Outliers detection in R](https://rpubs.com/Alema/1000582) liefert ebenfalls nochmal einen Überblick über die Methoden der Ausreißerbestimmung. Auch hier doppelt sich dann vieles, aber dafür hast du hier nochmal etwas mehr Text und Erklärungen.
- [Detecting Influential Points in Regression with DFBETA(S)](https://library.virginia.edu/data/articles/detecting-influential-points-in-regression-with-dfbetas) wirft nochmal einen Blick auf die DFBETA Methode. Die Methode basiert auf der Messung der Änderung der Koeffizienten einer Regression, wenn eine spezielle Beobachtung entfernt würde. Besonders bei einer multiplen Regression sehr sinnvoll.
:::
## Genutzte R Pakete
::: callout-caution
## Friedhof der R Pakete
In diesem Kapitel ist etwas passiert, was ich noch nie in einem anderem Thema erlebt habe. Ich fand R Pakete bei meiner Recherche, die in den letzten Jahren von CRAN runtergenommen wurden, da die Pakete nicht mehr gepflegt werden. Damit sterben natürlich auch einige der Tutorien weg, dir ich so gefunden hatte. Hier also der Friedhof der R Pakete zu der Ausreißerbestimmung mit dem R Paket `{dlookr}` (in 2023, jetzt wieder mit Unterstützung), `{OutlierDetection}` sowie `{DMwR}`. **All diese R Pakete werden nicht mehr unterstützt.** Einer Nutzung ist dem normalen Anwender abzuraten.
Das [R Paket `{mvoutlier}`](https://cran.r-project.org/web/packages/mvoutlier/index.html) funktioniert zwar noch, aber es gibt nur ein einziges Tutorium [Anomaly Detection](https://rpubs.com/Treegonaut/301942) aus dem Jahr 2017. Darüber hinaus ist das Paket weder mit `{tidyverse}` noch mit `{ggplot}` kompatibel. Deshalb stelle ich das Paket auch nicht weiter vor.
:::
Wir wollen folgende R Pakete in diesem Kapitel nutzen.
```{r echo = TRUE}
#| message: false
set.seed(20240116)
pacman::p_load(tidyverse, magrittr, broom, readxl,
see, performance, ggbeeswarm, olsrr,
outliers,
conflicted)
conflicts_prefer(dplyr::filter)
cbbPalette <- c("#000000", "#E69F00", "#56B4E9", "#009E73",
"#F0E442", "#0072B2", "#D55E00", "#CC79A7")
```
An der Seite des Kapitels findest du den Link *Quellcode anzeigen*, über den du Zugang zum gesamten R-Code dieses Kapitels erhältst.
## Daten
Um die Detektion von Ausreißern besser zu verstehen, schauen wir uns zwei Beispieldaten an. Als erstes einen Datensatz zu dem Wachstum von Wasserlinsen und der Messung derselbigen durch einen Sensor. Wir messen also einmal die Dichte `duckweeds_density` konventionell und wollen dann sehen, ob unser Sensor die Messungen dann widerspiegelt. Hier können wir vermutlich erstmal von einem linearen Wachstum ausgehen, dann aber vermutlich von einer Sättigung. Wir haben un mal nur begrenzt Platz für immer neue sich teilende Wasserlinsen.
```{r}
duckweeds_tbl <- read_excel("data/duckweeds_density.xlsx")
```
In der @tbl-duckweeds siehst du dann einmal einen Auszug aus den Daten zu den Wasserlinsen. Es ist ein sehr einfacher Datensatz mit nur zwei Spalten. Wir haben es eigentlich mit einem nicht linearen Zusammenhang zu tun, aber wir schauen uns hier mal an, was die Algorithmen uns so wiedergeben.
```{r}
#| echo: false
#| message: false
#| warning: false
#| label: tbl-duckweeds
#| tbl-cap: "Auszug aus Wasserlinsendatensatz."
rbind(head(duckweeds_tbl, n = 3),
rep("...", times = ncol(duckweeds_tbl)),
tail(duckweeds_tbl, n = 3)) |>
kable(align = "c", "pipe")
```
Im Weiteren betrachten wir noch das Beispiel der Gummibärchendaten. Auch hier haben wir echte Daten vorliegen, so dass wir eventuell Ausreißer entdecken könnten. Da wir hier fehlende Werte in den Daten haben, entfernen wir alle fehlenden Werte mit der Funktion `na.omit()`. Damit löschen wir jede Zeile in den Daten, wo mindestens ein fehlender Wert auftritt.
```{r}
#| message: false
gummi_tbl <- read_excel("data/gummibears.xlsx") |>
select(module, gender, age, height) |>
mutate(gender = factor(gender, labels = c("männlich", "weiblich"))) |>
na.omit()
```
In der @tbl-gummi-1 ist der Datensatz `gummi_tbl` nochmal als Auszug dargestellt dargestellt. Nun haben wir hier in dem Datensatz zu den Gummibärchen auch keine fehlenden Werte mehr.
```{r}
#| echo: false
#| message: false
#| warning: false
#| label: tbl-gummi-1
#| tbl-cap: "Auszug aus den Gummibärchendaten für das Modul, dem Geschlecht, dem Alter und der Körpergröße."
gummi_raw_tbl <- gummi_tbl |>
mutate_all(as.character)
rbind(head(gummi_raw_tbl, 4),
rep("...", times = ncol(gummi_raw_tbl)),
tail(gummi_raw_tbl, 4)) |>
kable(align = "c", "pipe")
```
Nun wollen wir uns aber erstmal den simpelsten Fall von Ausreißern und die Problematik dahinter visualisieren. Dann arbeiten wir uns zu komplexeren Paketen vor.
## Visualisierung
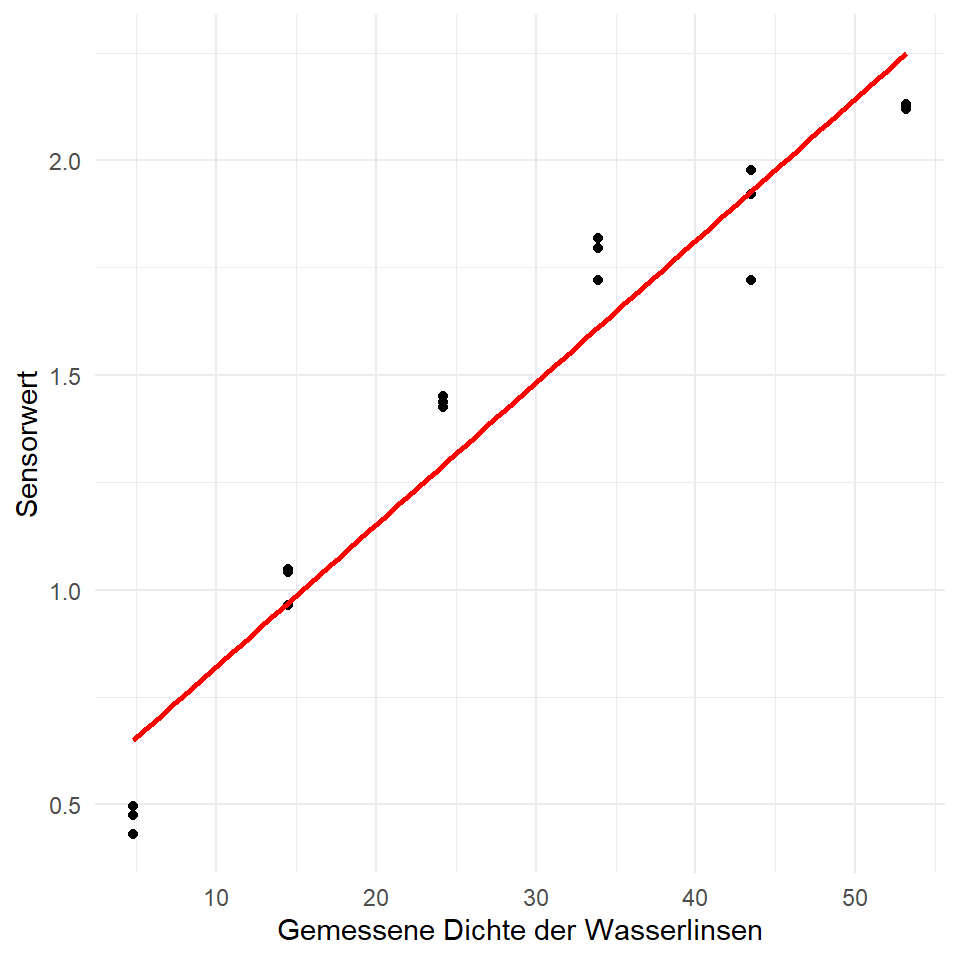
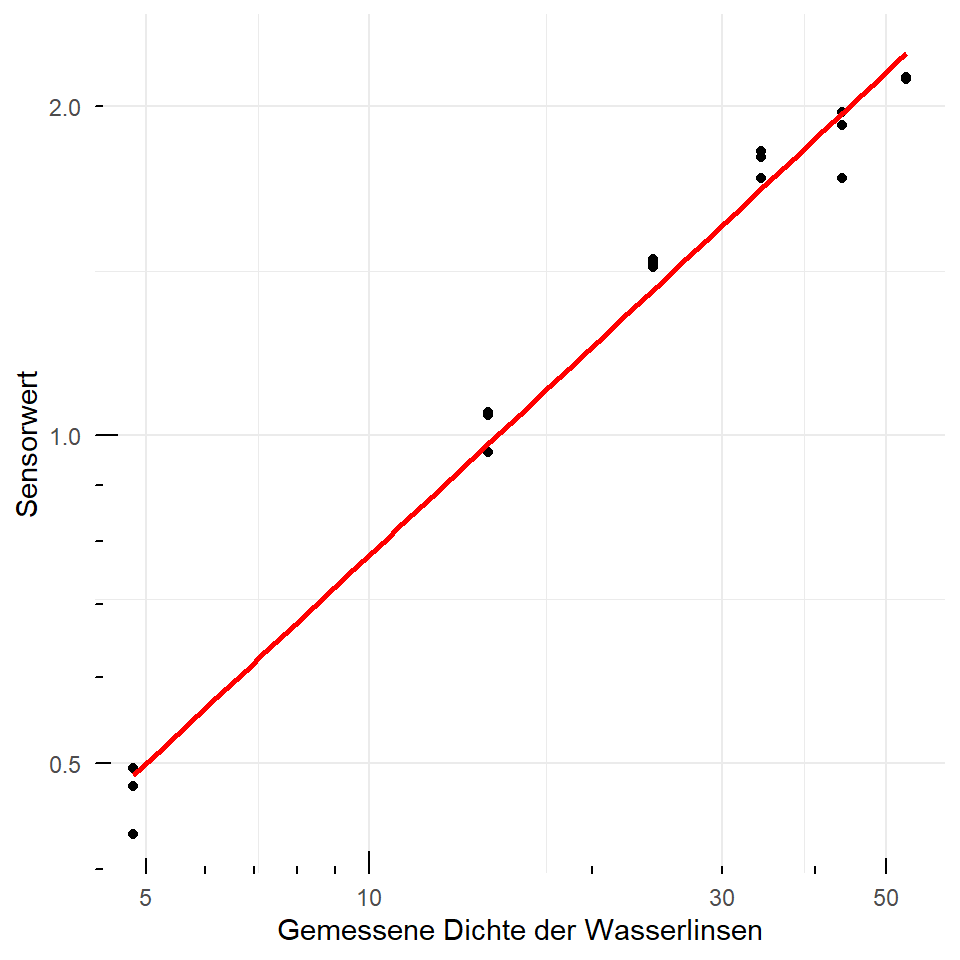
Betrachten wir also als erstes einmal die Daten der Wasserlinsen. Wenn wir von einem linearen Zusammenhang ausgehen würden, dann sehen die Daten so aus, als würde es Ausreißer zu Beginn und zum Ende der Messreihe geben. Manchmal lässt uns aber das Auge trügen und wir haben gar keinen linearen Zusammenhang in unseren Daten. Wenn wir dann eine log-Transformation durchführen, sehen die Daten schon sehr viel linearer aus. Diesen Weg schlägt auch @michel2020new vor, wenn wir Ausreißer an den Rändern beobachten.
> *Before identifying outliers, authors should consider the possibility that the data come from a lognormal distribution, which may make a value look as an outlier on a linear but not on a logarithmic scale. --- @michel2020new, p. 139*
Machen wir das doch einmal in den Daten für unsere Wasserlinsen. In der @fig-outlier-duckweeds-01 siehst du einmal die Daten, wie wir sie gemessen haben und einmal auf der log-Skala. Ich habe dann noch eine Gerade hinzugefügt. Wir sehen, dass sich die log-Transformation schon bemerkbar macht. Klare Ausreißer können wir jetzt schon nicht mehr klar erkennen.
```{r}
#| echo: true
#| warning: false
#| message: false
#| label: fig-outlier-duckweeds-01
#| fig-align: center
#| fig-height: 5
#| fig-width: 5
#| fig-cap: "Visualisierung der Sensorwerte nach Wasserlinsendichte. Pro Dichtewert liegen drei Sensormessungen vor. Es werden einmal die originalen Daten sowie die $log$-transformierten Daten betrachtet."
#| fig-subcap:
#| - "Originale Daten. Aureißer liegen entlang der Geraden."
#| - "$log$ transformierte Daten. Die Bobachtungen folgen mehr der Geraden."
#| layout-nrow: 1
ggplot(duckweeds_tbl, aes(duckweeds_density, sensor)) +
geom_point() +
theme_minimal() +
labs(x = "Gemessene Dichte der Wasserlinsen", y = "Sensorwert") +
geom_smooth(method = "lm", se = FALSE, color = "red")
ggplot(duckweeds_tbl, aes(duckweeds_density, sensor)) +
geom_point() +
theme_minimal() +
labs(x = "Gemessene Dichte der Wasserlinsen", y = "Sensorwert") +
scale_x_log10() +
scale_y_log10() +
annotation_logticks(sides = "bl") +
geom_smooth(method = "lm", se = FALSE, color = "red")
```
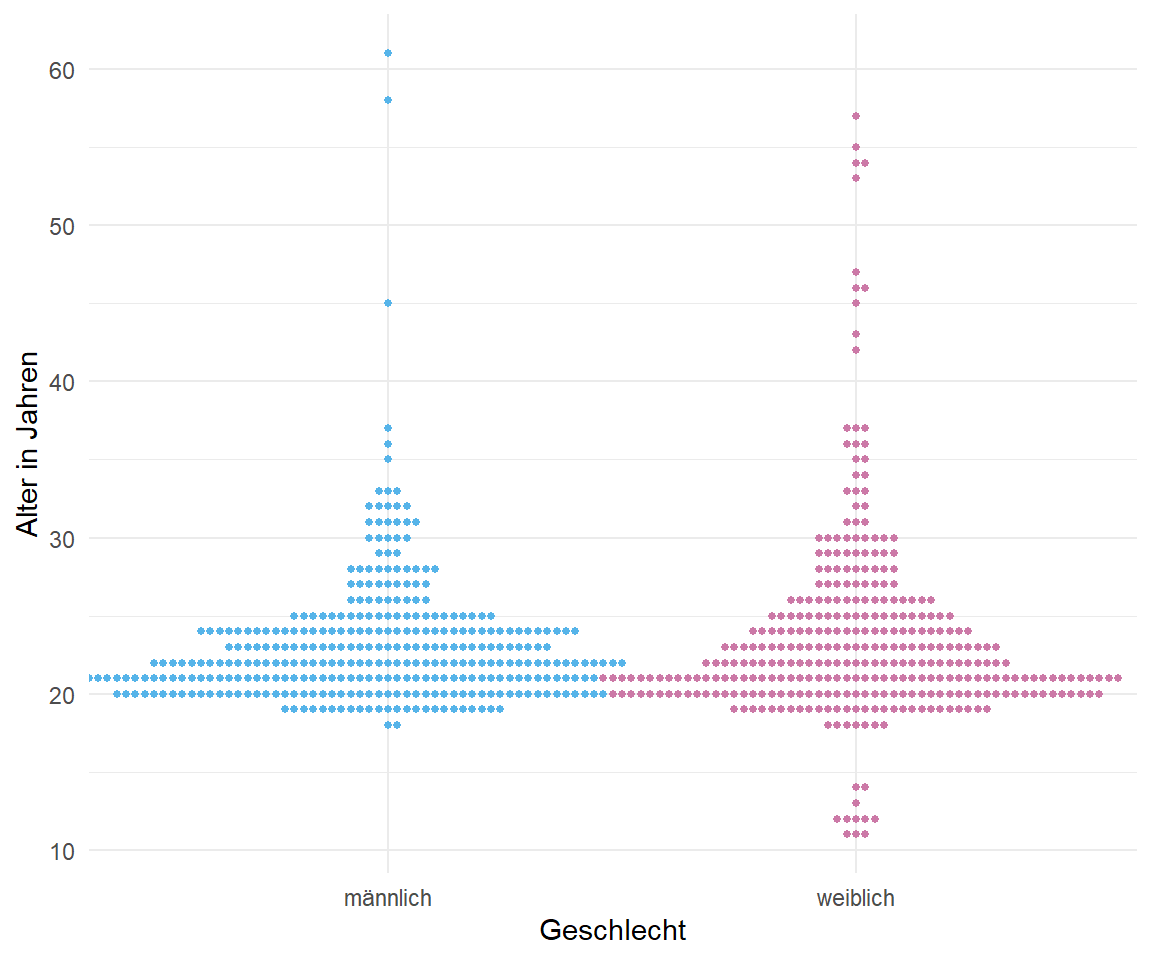
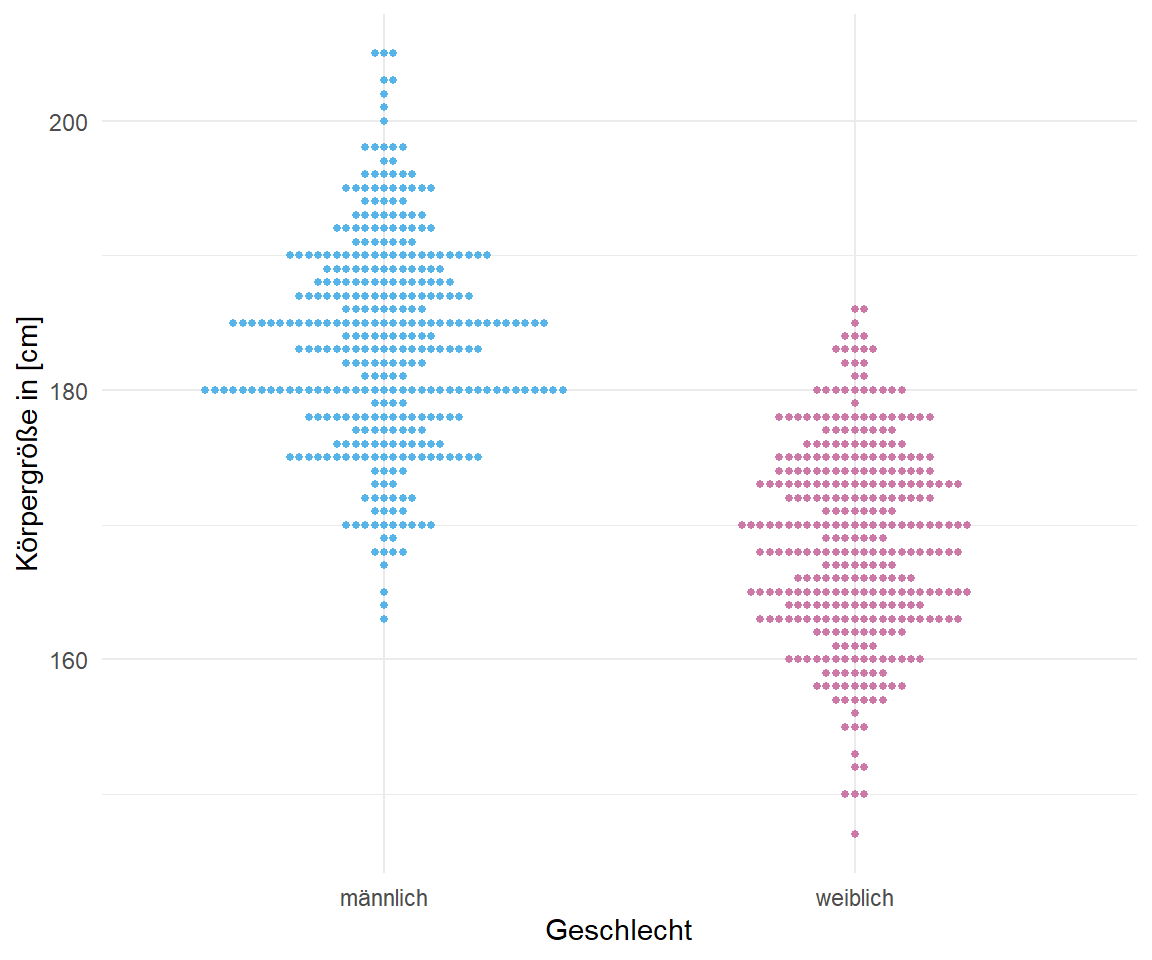
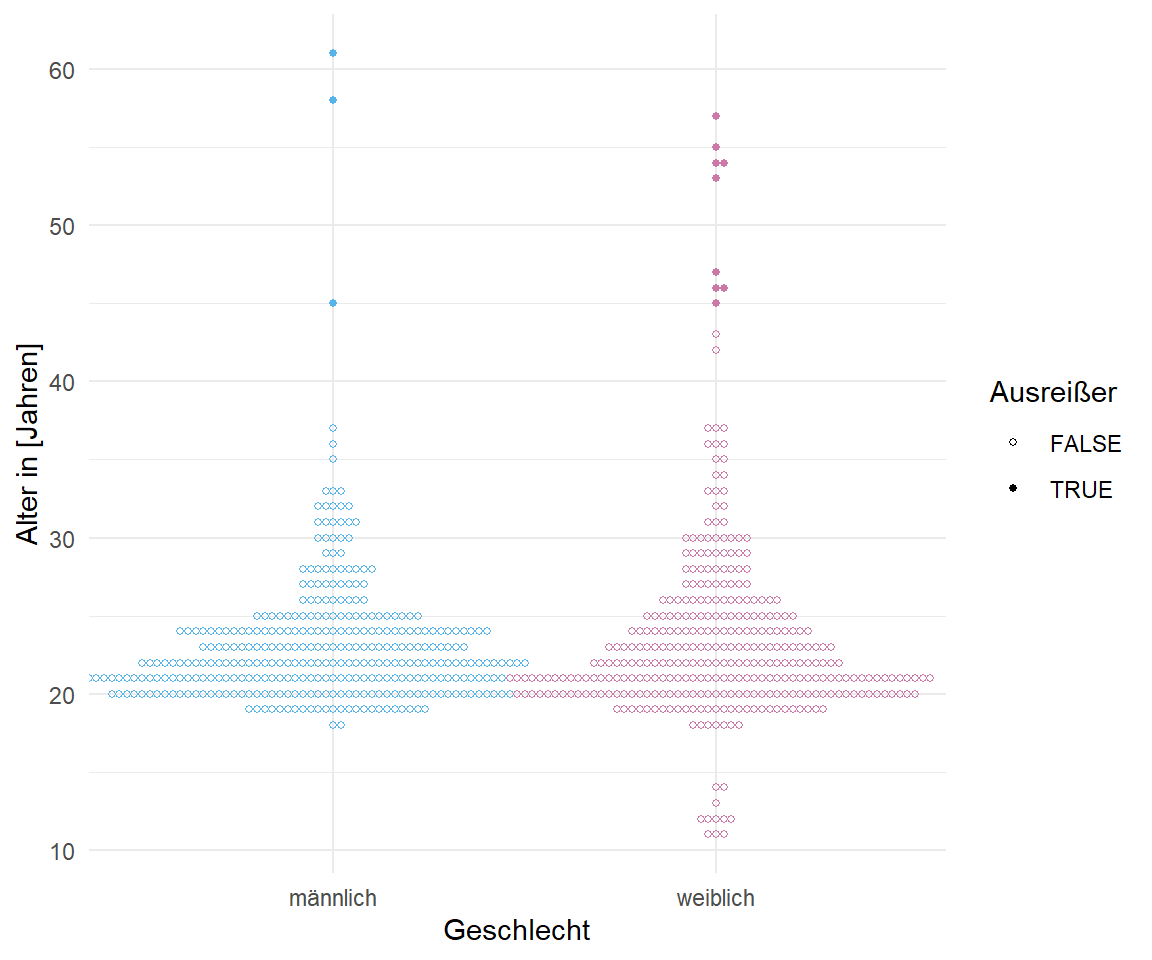
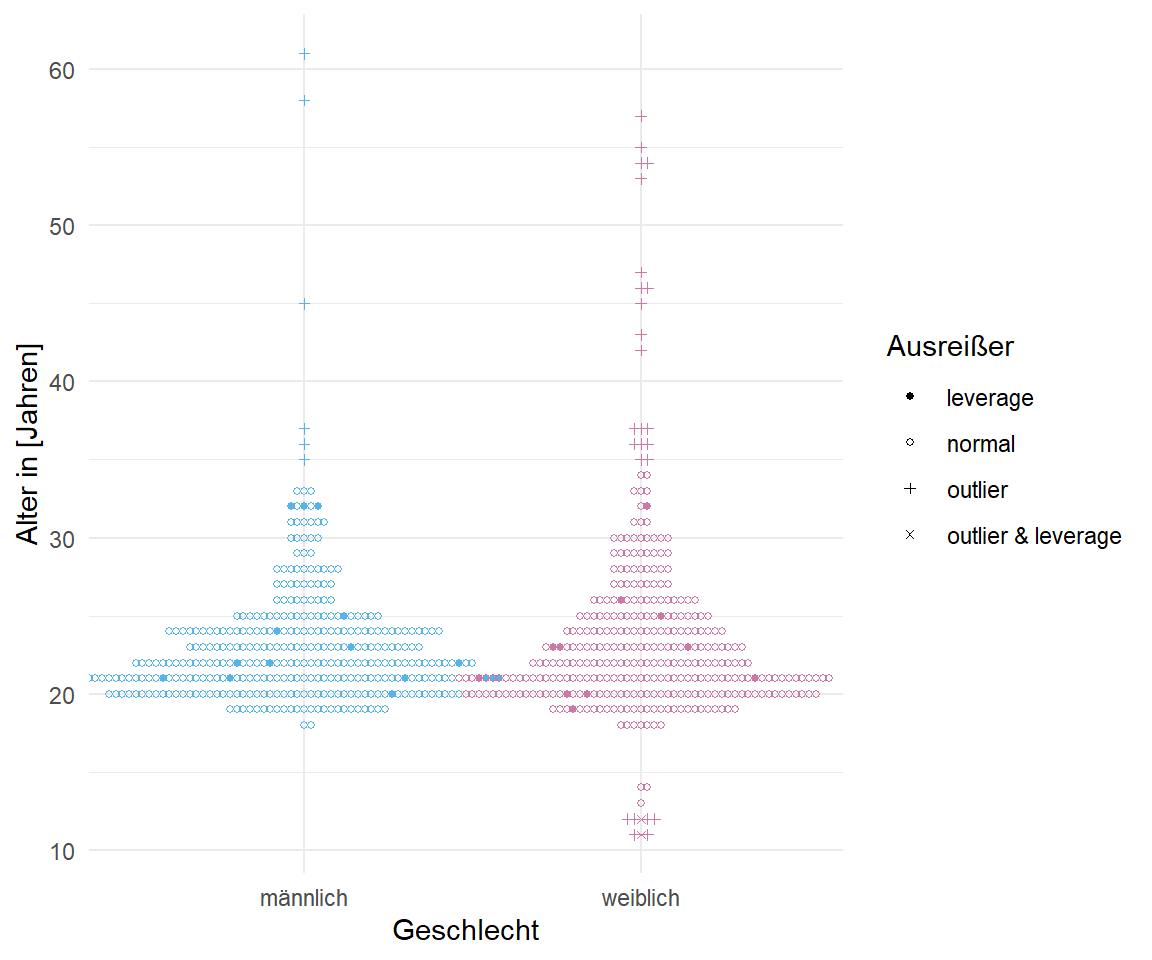
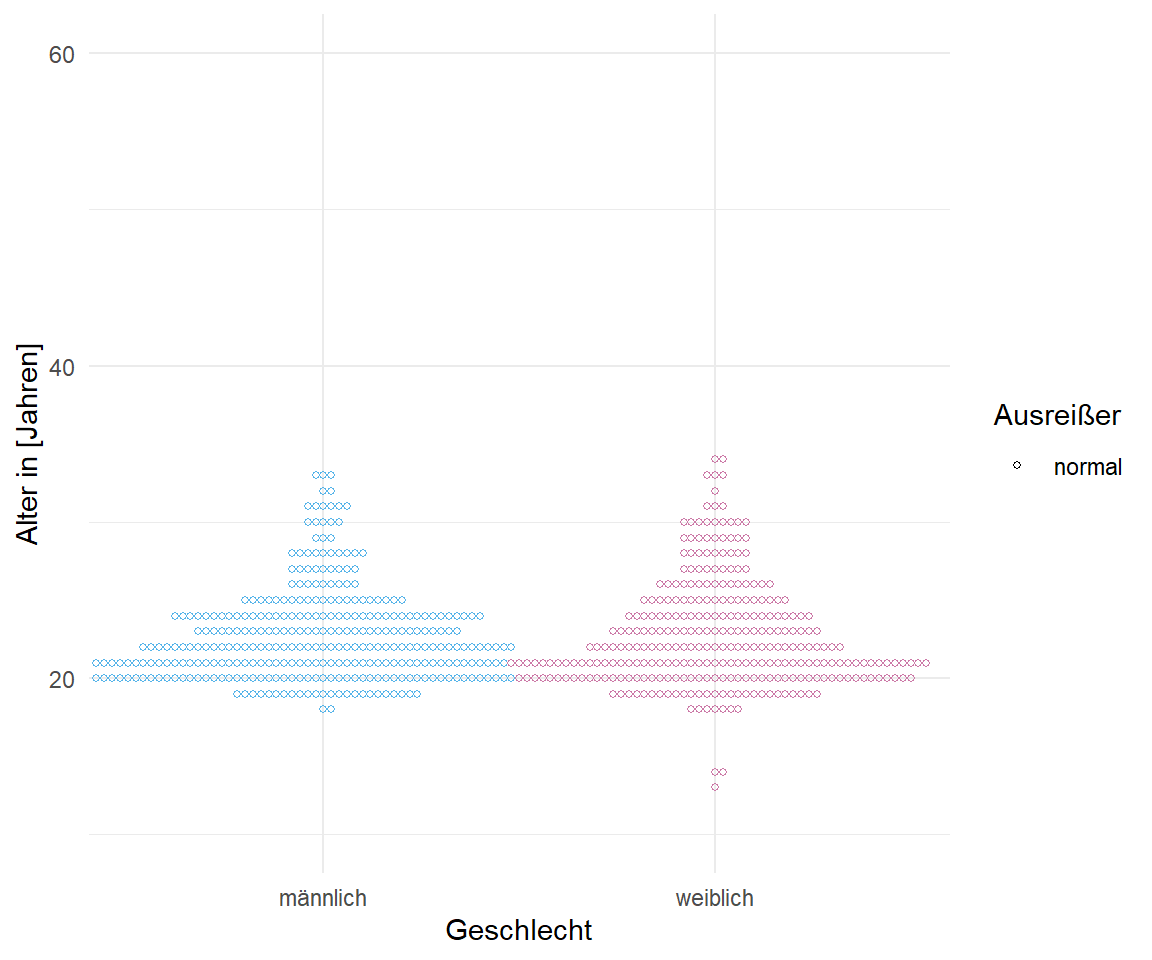
In der @fig-beeswarm-out-0 sehen wir einmal unsere Gummibärchendaten für das Alter in Jahren und die Körpergröße dargestellt. Als potenzielle Ausreißer haben wir hier die Teilnehmerinnnen des Girls Day in den Daten. Zum einen waren es nur Mädchen und zum anderen sehr junge und damit auch kleine Mädchen. Der Großteil der Daten machen ja Studierenden Anfang Zwanzig aus. Im Weiteren habe ich die Gummibärchen auch auf Weiterbildungen gezählt, so dass auch hier Ausreißer im Sinne eines hohen Alters in den Daten sind. Daher haben wir hier schön ein paar Ausreißer in den Daten. Schauen wir mal, ob die Algorithmen diese Ausreißer auch finden.
```{r }
#| echo: true
#| message: false
#| label: fig-beeswarm-out-0
#| fig-align: center
#| fig-height: 5
#| fig-width: 6
#| fig-cap: "Beeswarmplot als ein Dotplot für eine große Anzahl an Beobachtungen. Hier schauen wir uns einmal das Alter und die Körpergröße aufgeteilt nach Geschlecht an. Wir sehen klar die Gruppe der Ausreißer bei den weiblichen Beobachtungen. Hierbei handelt es sich um die Teilnehmerinnen des Girls Day. Auch ahben wir noch einige ältere Beobachtungen in den Daten."
#| fig-subcap:
#| - "Alter nach Geschlecht"
#| - "Körpergröße nach Geschlecht"
#| layout-nrow: 1
gummi_tbl |>
ggplot(aes(x = gender, y = age, color = gender)) +
geom_beeswarm(size = 1) +
theme_minimal() +
scale_color_okabeito(order = c(2, 7)) +
labs(x = "Geschlecht", y = "Alter in Jahren") +
theme(legend.position = "none")
gummi_tbl |>
ggplot(aes(x = gender, y = height, color = gender)) +
geom_beeswarm(size = 1) +
theme_minimal() +
scale_color_okabeito(order = c(2, 7)) +
labs(x = "Geschlecht", y = "Körpergröße in [cm]") +
theme(legend.position = "none")
```
## Bekannte Kriterien für Ausreißer
Im Folgenden schauen wir uns einmal eine Auswahl an Kriterien für die Detektion von Ausreißern an. Ich nutze dazu dann gleich einmal einen Dummy-Datensatz -- also einen Beispieldatensatz, wo wir wissen was los ist -- in dem ich mir einfach mal zwei Ausreißer hineingelegt habe. Wir schauen dann mal, was die Algorithmen so wiedergeben und ob wir was erkennen können. Du findest noch mehr Möglichkeiten in dem Tutorium [Outliers detection in R](https://statsandr.com/blog/outliers-detection-in-r/). Wir wollen uns hier aber auf ein paar der gängigsten Varianten konzentrieren. In den folgenden Abschnitten danach, schauen wir dann nochmal spezifisch in einzelne R Paket hinein.
- Ausreißer mit Cook\`s Abstand
- Ausreißer mit *leverage* (deu. *Hebelwirkung*)
- Ausreißer mit $\sigma$-Filter
- Ausreißer mit Hampel Filter
- Ausreißer mit einem statistischen Test
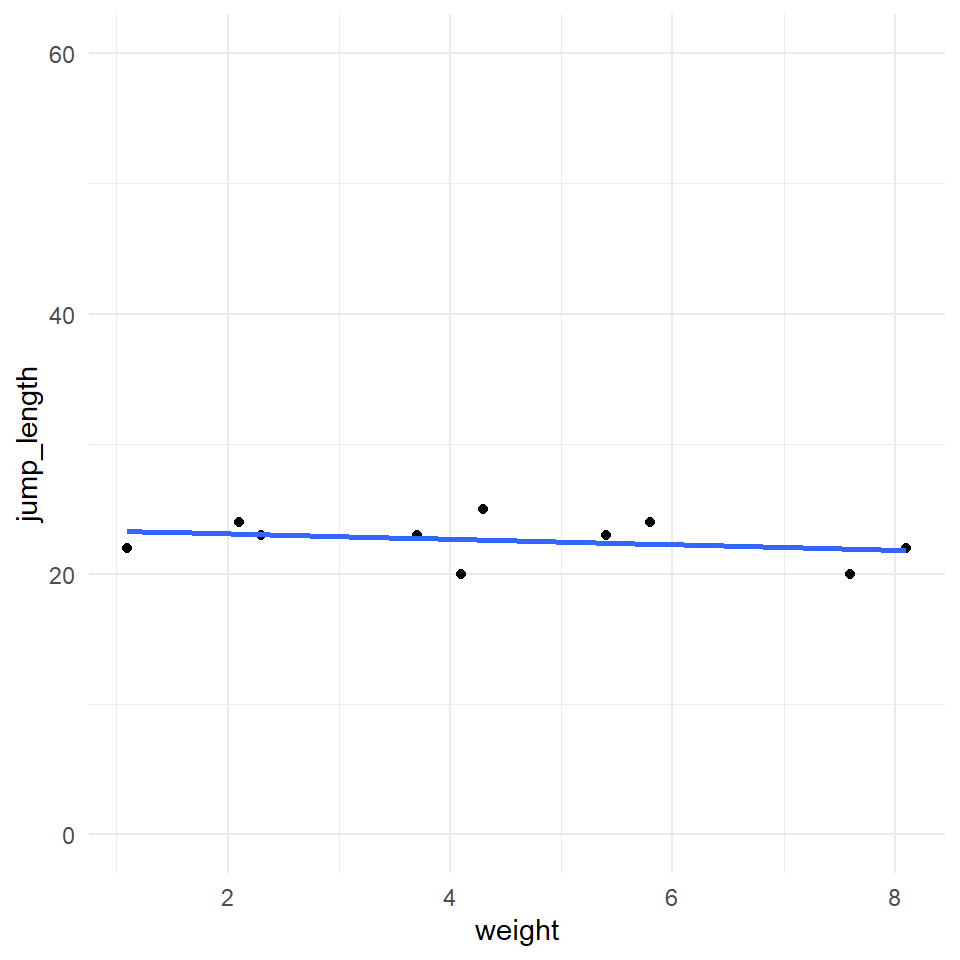
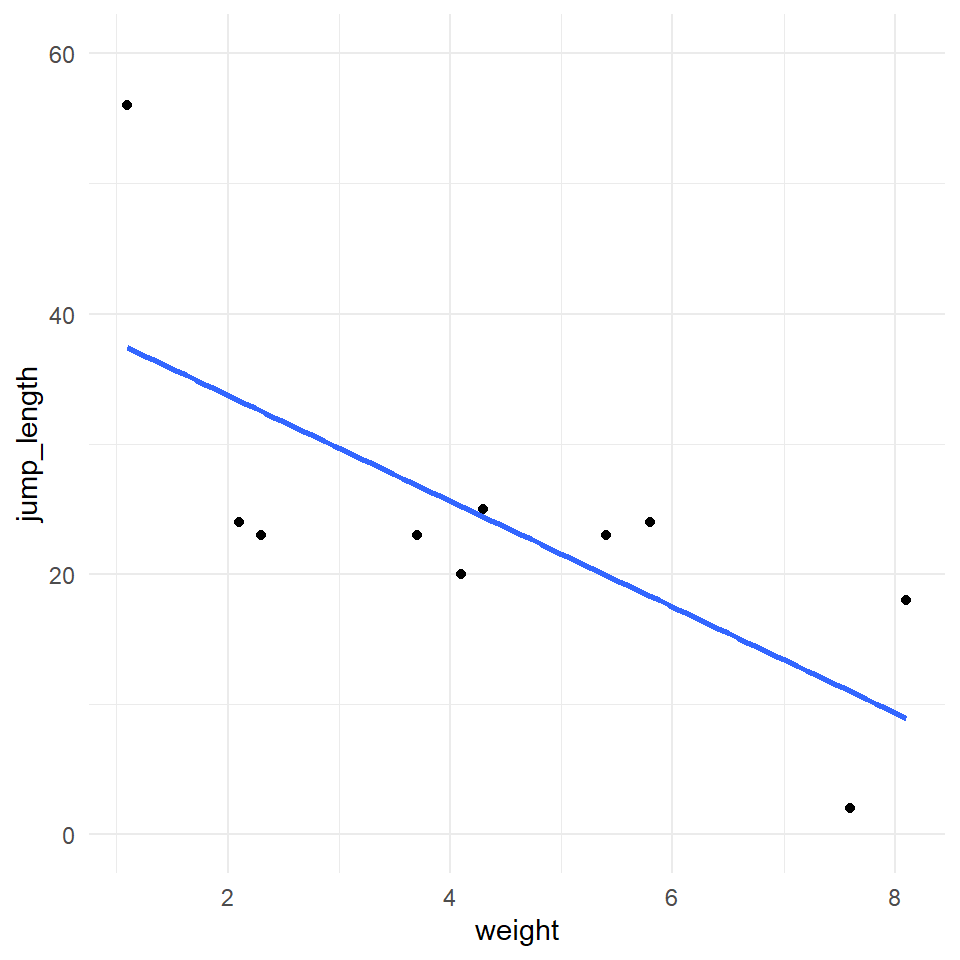
Veranschaulichen wir uns einmal den Zusammenhang an zwei Beispieldaten in der @tbl-cook-tables -- einmal einen Datensatz ohne Ausreißer und dann einen Datensatz mit Ausreißern. Ich nehme dazu einfach das Gewicht in \[mg\] von zehn Flöhen und die jeweilige Sprunglänge in \[cm\]. Als erstes einmal einen Datensatz `no_out_tbl` ohne Ausreißer und dann einen Datensatz `out_tbl` mit den Sprungweiten von $56$cm und $2$cm als Ausreißer. Im Folgenden wollen wir uns natürlich nur den Datensatz mit den zwei Ausreißern anschauen.
```{r}
#| message: false
#| echo: false
#| label: tbl-cook-tables
#| tbl-cap: "Zwei Datentabellen zum Vergleich der Detektion von Ausreißern nach Cook's Abstand."
#| tbl-subcap:
#| - "Keine Ausreißer"
#| - "Zwei Ausreißer"
#| layout-ncol: 2
no_out_tbl <- tibble(weight = c(1.1, 2.3, 2.1, 3.7, 4.1, 5.4, 7.6, 4.3, 5.8, 8.1),
jump_length = c(22, 23, 24, 23, 20, 23, 20, 25, 24, 22))
out_tbl <- tibble(weight = c(1.1, 2.3, 2.1, 3.7, 4.1, 5.4, 7.6, 4.3, 5.8, 8.1),
jump_length = c(56, 23, 24, 23, 20, 23, 2, 25, 24, 18))
no_out_tbl |> kable(align = "c", "pipe")
out_tbl |> kable(align = "c", "pipe")
```
Jetzt schauen wir uns die Daten der obigen Tabellen auch als Visualisierung in @fig-cooks-1 an. Wir sehen die starken Ausreißer in der Visualisierung. Das ist auch so gewollt, wir haben die Ausreißer extra sehr extrem gewählt. Ich habe jetzt bewusst den letzten Ausreißer etwas weniger extrem ausgewählt. Weniger in dem Sinne, dass der Abstand zu den anderen Punkten nicht so groß ist, aber dennoch deutlich. Auch ist die Position herausfordernd für die Algorithmen. Ausreißer an den Rändern können schwer zu erkennen sein. Fangen wir also einmal an die Daten zu untersuchen.
```{r}
#| message: false
#| echo: false
#| label: fig-cooks-1
#| fig-align: center
#| fig-height: 5
#| fig-width: 5
#| fig-cap: "Scatterplots der Datentabelle zum Vergleich der Detektion von Ausreißern nach verschiedenen Algorithmen."
#| fig-subcap:
#| - "Scatterplot ohne Ausreißer"
#| - "Scatterplot mit Ausreißer"
#| layout-nrow: 1
ggplot(data = no_out_tbl, aes(x = weight, y = jump_length)) +
geom_point() +
geom_smooth(method = lm, se = FALSE) +
ylim(0, 60) +
theme_minimal()
ggplot(data = out_tbl, aes(x = weight, y = jump_length)) +
geom_point() +
geom_smooth(method = lm, se = FALSE) +
ylim(0, 60) +
theme_minimal()
```
### Ausreißer mit Cook\`s Abstand
Mit der Cook'schen Distanz können wir herausfinden, ob eine einzelne Beobachtung ein Ausreißer im Zusammenhang zu den anderen Beobachtungen ist. Die Cook'sche Distanz misst, wie stark sich alle geschätzten Werte im Modell ändern, wenn der $i$-te Datenpunkt gelöscht wird. So einfach und auch so simple. Das Ganze machen wir natürlich nicht selber, sondern nutzen dafür die Funktion `augment()` aus dem R Paket `{broom}`. Die Funktion `augment()` braucht aber die Ausgabe einer linearen Regression, damit die Cook'sche Distanz berechnet werden kann. Also eigentlich vom Prozes her ganz einfach. Im Folgenden rechnen wir also eine simple Gaussian lineare Regression auf den Daten und schauen einmal, was wir dann über die einzelnen Beobachtungen erfahren und ob wir die eingestellten Ausreißer wiederfinden.
```{r}
jump_fit <- lm(jump_length ~ weight, data = out_tbl)
```
Wir können nun die Funktion `augment()` nutzen um die Cook'sche Distanz als `.cooksd` aus dem linearen Modellfit zu berechnen. Wir lassen uns noch die Variablen `weight` und `jump_length` wiedergeben um uns später dann die Visualisierung zu erleichtern.
```{r}
cook_tbl <- jump_fit |>
augment() |>
select(weight, jump_length, .cooksd)
cook_tbl
```
Zuerst sehen wir, dass die $1$-ste und die $10$-te Beobachtung relativ hohe Werte der Cook'schen Distanz haben. Das heißt hier ist irgendwas nicht in Ordnung, es könnte sich also um Ausreißer handeln. Das haben wir ja auch so erwartet. Die beiden Beobachtungen sind ja auch unsere erschaffene Ausreißer. Nun brauchen wir noch einen Threshold oder Grenzwert um obkjektiv zu entscheiden ab wann wir eine Beobachtung als Ausreißer definieren. Es hat sich als "Kulturkonstante" der Wert von $4/n$ als Threshold etabliert [@hardin2007generalized].
Grenzwert für Cook's Abstand `.cooksd`
: @hardin2007generalized bezeichnen Werte, die über $4/n$ liegen als problematisch. Dabei ist dann $n$ ist hierbei die Stichprobengröße. Damit haben wir dann auch die entsprechende Literaturquelle.
Berechnen wir also einmal den Threshold für unseren Datensatz indem wir $4$ durch $n = 10$ teilen und erhalten einen Grenzwert von $0.4$ für mögliche Ausreißer. In @fig-cook-2 haben wir den Threshold einmal als rote Linie eingezeichnet. Auf der $x$-Achse ist das Gewicht `weight` der Flöhe eingezeichnet, damit sich die Punkte etwas verteilen. Ich habe als Label die Werte für die Sprungweite `jump_length` vergeben. Damit siehst du dann auch welche $y$-Werte aus den Sprungweiten problematisch sein könnten. Und wir sehen auch sofort was spannendes. Wir entfernen eher unsere Sprungweite $18$ als unsere Sprungweite $2$. Gut, die Sprungweite $56$ ist auf jeden Fall ein Ausreißer, aber die Sprungweite $2$ erwischen wir nicht, sondern entfernen die "richtige" Sprungweite $18$. Deshalb immer Augen auf bei der automatsichen Entfernung von Ausreißern. Algorithmen können sich auch irren.
```{r}
#| echo: true
#| message: false
#| label: fig-cook-2
#| fig-align: center
#| fig-height: 5
#| fig-width: 6
#| fig-cap: "Visualisierung der Ausreißer nach der Cook'schen Distanz. Die Grenze als rote Linie ist mit $4/n = 0.4$ berechnet worden."
ggplot(cook_tbl, aes(weight, .cooksd)) +
geom_hline(yintercept = 0.4, color = "red") +
geom_label(aes(label = jump_length)) +
theme_minimal()
```
Was wir jetzt mit den Ausreißern machen, müssen wir uns überlegen. Im Prinzip haben wir zwei Möglichkeiten. Entweder entfernen wir die Beobachtungen aus unserem Datensatz oder aber wir setzen die Werte der Ausreißer auf `NA` oder eine andere *passendere* Zahl. Ich würde immer empfehlen, die Ausreißer einfach zu entfernen. Das kannst du einfach in deinem Excelfile machen oder etwas komplizierter wie hier über die Funktionen `which()` oder eben `filter()`. Weil es hier am Anfang noch relativ einfach sein soll, entfernen wir einfach die beiden Ausreißer aus unseren Daten. Wir erhalten dann einen kleineren Datensatz mit $n = 8$ Beobachtungen. Leider ist jetzt unser Ausreißer $2$ noch drin.
::: panel-tabset
## ... über `which()`
Wir können jetzt mit der Funktion `which()` bestimmen welche Beobachtungen wir als Ausreißer identifiziert haben.
```{r}
#| message: false
remove_weight_id <- which(cook_tbl$.cooksd > 0.4)
```
Dann können wir einfach die Beobachtungen entfernen. Wir entfernen hier einfach die Zeilen, die im Objekt `remove_weight_id` hinterlegt sind.
```{r}
#| message: false
out_tbl[-remove_weight_id, ]
```
## ... über `augment()`
Oder wir nutzen die Funktion `filter()` auf der Ausgabe der Funktion `augment()`. Ich persönlich mag ja diese Variante hier mehr, aber es kommt immer auf den Kontext an.
```{r}
jump_fit |>
augment() |>
select(weight, jump_length, .cooksd) |>
filter(.cooksd <= 0.4)
```
:::
Die nächste Möglichkeit wäre auf dem kleineren Datensatz *nochmal* eine Ausreißeranalyse zu rechnen und zu hoffen, dass wir jetzt alle Ausreißer erwischen. Dann stellt sich aber die Frage wie lange wir das machen wollen. Am Ende haben wir dann ja kaum noch Daten über, wenn es schlecht läuft.
Du siehst, dieser Zugang über die Cook'sche Distanz an die Detektion von Ausreißern ist sehr simple. Wir schauen einfach auf die Cook'sche Distanz und haben so einen schnellen Überblick. Ich empfehle auch gerne dieses Vorgehen um einmal einen Überblick über die Daten zu erhalten. Leider liefern nicht alle Modelle eine Cook'sche Distanz, daher müssen wir uns jetzt etwas strecken und noch andere Verfahren einmal ausprobieren. Und am Ende müssen wir natürlich auch schauen, ob wir die richtigen Ausreißer entfernt haben.
### Ausreißer mit *leverage*
Eine weitere Möglichkeit Ausreißer zu finden ist mit der Hebelwirkung (eng. *leverage*) von einzelnen Beobachtungen. Die Frage ist hier, haben einzelne Punkte einen besonderen Einfluss auf den Verlauf der Geraden haben. Beeinflusst also ein einzelner Punkt den Verlauf der Geraden besonders? Punkte, die an den Rändern liegen haben meist ein größeren Einfluss auf den Verlauf der Geraden als Punkte in der Wolke. Wir können usn auch über die Funktion `augment()` die Werte für die Hebelwirkung der einzelnen Beobachtungen als `.hat`-Werte wiedergeben lassen.
```{r}
leverage_tbl <- jump_fit |>
augment() |>
select(weight, jump_length, .hat)
```
Wenn wir nur eine Einflussvaribale vorliegen haben, dann ist der Grenzwert der *leverage* faktisch identisch mit dem Grenzwert für Cook'sche Distanz. Wenn du aber mehr $x$ in deinem Modell hast, dann musst den Grenzwert anpassen.
Grenzwert für Leverage `.hat`
: Im Allgemeinen sollte ein Punkt mit einer Hebelwirkung von mehr als $(2k+2)/n$ sorgfältig geprüft werden, wobei $k$ die Anzahl der Einflussvariablen und $n$ die Anzahl der Beobachtungen ist.
In unserem Fall wäre dann $k = 1$ sowie $n = 10$, so dass wir auf einen Grenzwert von $(2\cdot 1 +2)/10 = 0.4$ kommen, wie auch schon bei Cook's Distanz. Das ist eigentlich schon alles. Wir können uns dann in der @fig-hat-2 einmal die Werte für *leverage* anschauen. Ich habe wieder den Grenzwert als rote Linie ergänzt und in den Kästchen stehen dann immer die Messwerte der Sprungweite. Hier sehen wir dann spannenderweise, dass wir gar keine Ausreißer finden. Ja, auch das kann passieren. Wir sehen zwar, dass sich drei Messwerte ungünstig verhalten und hohe `.hat`-Werte haben, aber noch würden diese Werte unter dem Grenzwert von $0.4$ liegen. Mit mehr Beobachtungen und damit auch Fallzahl würde der Grenzwert auch niedriger liegen. So sieht man wieder, für gewisse Methoden brauchst du dann einfach auch Fallzahl.
```{r}
#| echo: true
#| message: false
#| label: fig-hat-2
#| fig-align: center
#| fig-height: 5
#| fig-width: 6
#| fig-cap: "Visualisierung der Ausreißer nach der *leverage*. Die Grenze als rote Linie ist mit 0.4 berechnet worden."
ggplot(leverage_tbl, aes(weight, .hat)) +
geom_hline(yintercept = 0.4, color = "red") +
geom_label(aes(label = jump_length)) +
theme_minimal()
```
### Ausreißer mit $\boldsymbol{\sigma}$ Filter
Eine andere Möglichkeit besondere Werte oder eben auch Ausreißer zu finden ist die Sigmamethode (sym. $\sigma$). Dabei machen wir uns zu nutzen, dass unter der Annahme der Normalverteilung, unsere Werte symmetrisch nach der Standardabweichung $\sigma$ um unseren Mittelwert verteilt sind. Damit haben wir auch gleich eine grundlegende Annahme an unsere Daten. Die Sigmamethode funktioniert nur, wenn wir normalverteilte Daten vorliegen haben. Haben wir das, dann können wir den Mittelwert berechnen und über die entsprechende Standardabweichung dann abschätzen wie häufig unsere einzelnen Beobachtungen aufgetreten wären. In der @tbl-outlier-sigma habe ich dir einmal die Wahrscheinlichkeiten des Auftretens einer Beobachtung in dem Intervall $\mu \pm k \cdot \sigma$ für verschiedene $k$-Werte dargestellt. Haben wir zum Beispiel eine mittlere Körpergröße von $180cm$ bei Männern mit einer Standardabweichung $\sigma$ von $10cm$ in unseren Gummibärchendaten vorliegen, dann sollten $68\%$ unserer Männer im Intervall $[170; 190]$ liegen. Es wäre also auch damit sehr unwahrscheinlich einen Mann mit der Größe von $220cm$ anzutreffen, da dieser schon im Bereich von $4\sigma$ liegen würde. Damit wäre nur ein Mann von ca. 16000 so groß.
| $\boldsymbol{\sigma}$ | Wahrscheinlichkeit des Auftretens | Chance des Auftretens |
|:--:|:--:|:--:|
| $\mu \pm 1 \cdot \sigma$ | $\mathbf{68.26}00000\%$ | |
| $\mu \pm 2 \cdot \sigma$ | $\mathbf{95.46}00000\%$ | $1:20$ |
| $\mu \pm 3 \cdot \sigma$ | $\mathbf{99.73}00000\%$ | $1:370$ |
| $\mu \pm 4 \cdot \sigma$ | $\mathbf{99.9937}000\%$ | $1:15873$ |
| $\mu \pm 5 \cdot \sigma$ | $\mathbf{99.999943}0\%$ | $1:1.7 \cdot 10^6$ |
| $\mu \pm 6 \cdot \sigma$ | $\mathbf{99.9999996}\%$ | $1:2.5 \cdot 10^8$ |
: Wahrscheinlichkeiten für das Auftreten einer Beobachtung in dem Intervall $\mu \pm k \cdot \sigma$ für normalverteilte Daten. {#tbl-outlier-sigma}
Wir können wir nun die Sigmaregel an unseren Daten anwenden? Wir haben dazu wieder verschiedene Möglichkeiten. Zuerst wollen wir einmal die Sigmaregel auf die Residuen unser Regression anwenden. Die Residuen beschreiben ja den Abstand der einzelnen Punkte zu der Geraden und sind von sich normalverteilt. Wir erhalten die Residuen `.resid` mit der Funktion `augment()` aus dem R Paket `{broom}`. Die Werte `.fitted` beschreiben unsere Sprungweiten auf der Geraden.
```{r}
resid_tbl <- jump_fit |>
augment() |>
select(weight, jump_length, .fitted, .resid)
resid_tbl
```
Wir können jetzt für die Residuen die Standardabweichung bestimmen und schauen in wie weit die einzelnen Beobachtungen um die Gerade streuen unter den jeweiligen Sigmabereichen. Die Standardabweichung haben wir ja zusammen *mit* den Ausreißern berechnet. Wenn also unsere Gerade sehr schief ist, dann werden die Ausreißer ja auch irgendwie mit in dem Bereich von einem vielfachen von Sigma liegen. Die Gerade wird ja so optimiert, dass möglichst die Residuen zu allen Punkten klein ist.
```{r}
sd(resid_tbl$.resid)
```
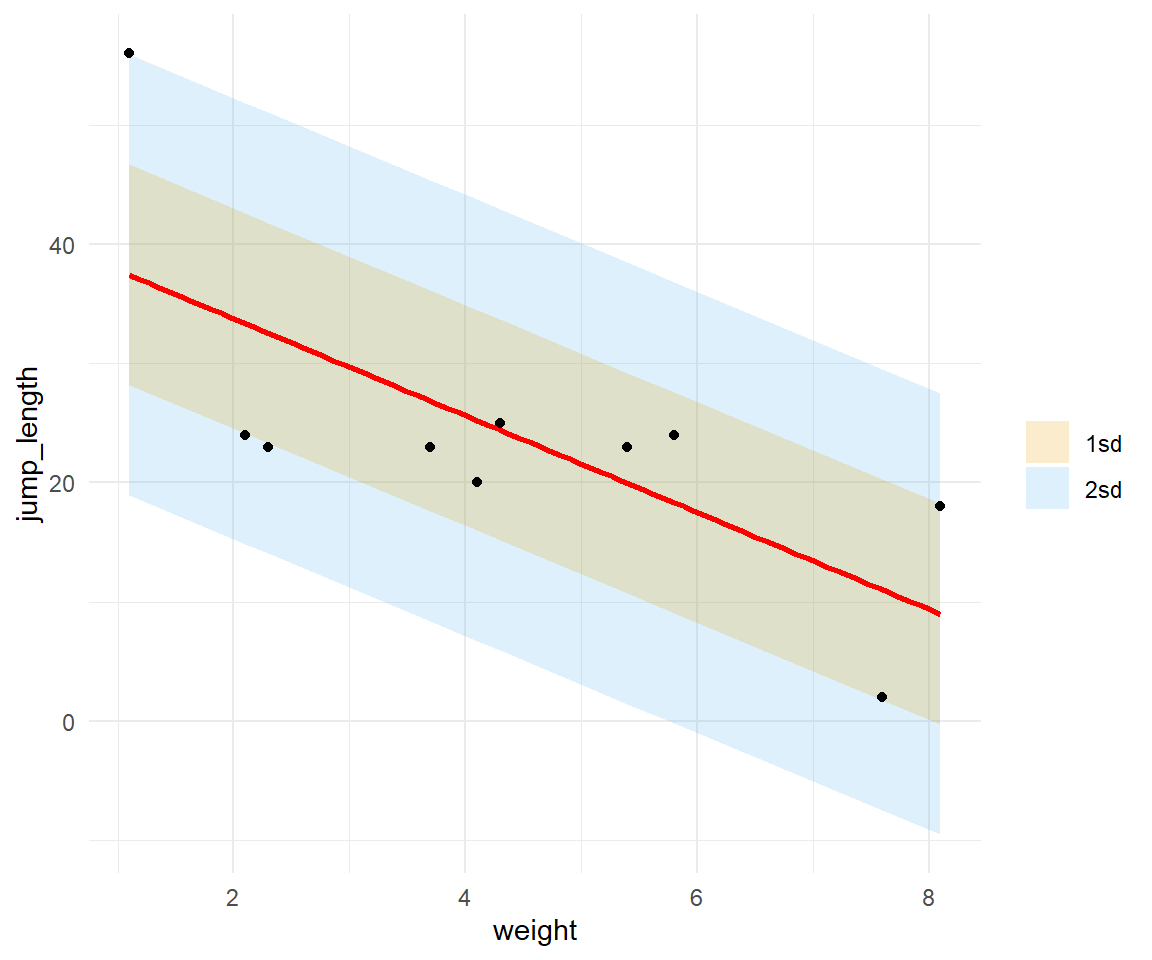
Jetzt können wir uns in der @fig-sd-1 einmal die Gerade mit der Standardabweichung der Residuen für verschiedene $k$ anschauen. Wie du siehst liegen alle Beobachtungen noch in der Bandbreite von $2\sigma$. Da Problem ist eben, dass die beiden Ausreißer die Gerade so verschieben, dass dann die beiden Ausreißer doch nicht so schlimm sind, wenn wir die Sachlage von der Geraden aus betrachten.
```{r}
#| echo: true
#| message: false
#| label: fig-sd-1
#| fig-align: center
#| fig-height: 5
#| fig-width: 6
#| fig-cap: "Visualisierung der Sigmaregel auf den Residuen der Geraden."
resid_tbl |>
ggplot(aes(weight, jump_length)) +
theme_minimal() +
geom_ribbon(aes(ymin = .fitted - 2 * sd(.resid),
ymax = .fitted + 2 * sd(.resid),
fill = "2sd"),
alpha = 0.2) +
geom_ribbon(aes(ymin = .fitted - 1 * sd(.resid),
ymax = .fitted + 1 * sd(.resid),
fill = "1sd"),
alpha = 0.2) +
geom_smooth(method = "lm", se = FALSE, color = "red") +
scale_fill_okabeito(name = "") +
geom_point()
```
Hier müssten wir im Prinzip erst die *potenziellen* Ausreißer entfernen und dann die Gerade rechnen und schauen, ob unsere potenziellen Ausreißer noch im Intervall wären. Damit säumen wir das Pferd aber von hinten auf. Das wollen wir dann einmal machen. Wir entscheiden jetzt, dass die Werte der Sprunglänge von $56$ und $2$ potenzielle Ausreißer sind.
```{r}
sd_out_tbl <- out_tbl |>
mutate(potential_outlier = c(1, 0, 0, 0, 0, 0, 1, 0, 0, 0))
sd_out_tbl
```
Dann filtern wir einmal die potenziellen Ausreißer aus unseren Daten raus und rechnen den Mittelwert und die Standardabweichung der Sprungweite aus. Hier sehen wir schon, dass sich die Werte unterscheiden. Dadurch, dass wir die beiden potenziellen Ausreißer entfernt haben fällt unsere Standardabweichung $\sigma$ von $9.25$ auf nur $2.33$. Ein starkes Indiz, dass wir es hier mit Ausreißern zu tun haben. Oder zumindestens mit so extremen Werten, dass wir ein sehr viel größere Standardabweichung mit den Werte vorliegen haben als ohne die Werte.
```{r}
sd_out_tbl |>
filter(!potential_outlier) |>
summarise(Mittelwert = mean(jump_length),
Standardabweichung = sd(jump_length))
```
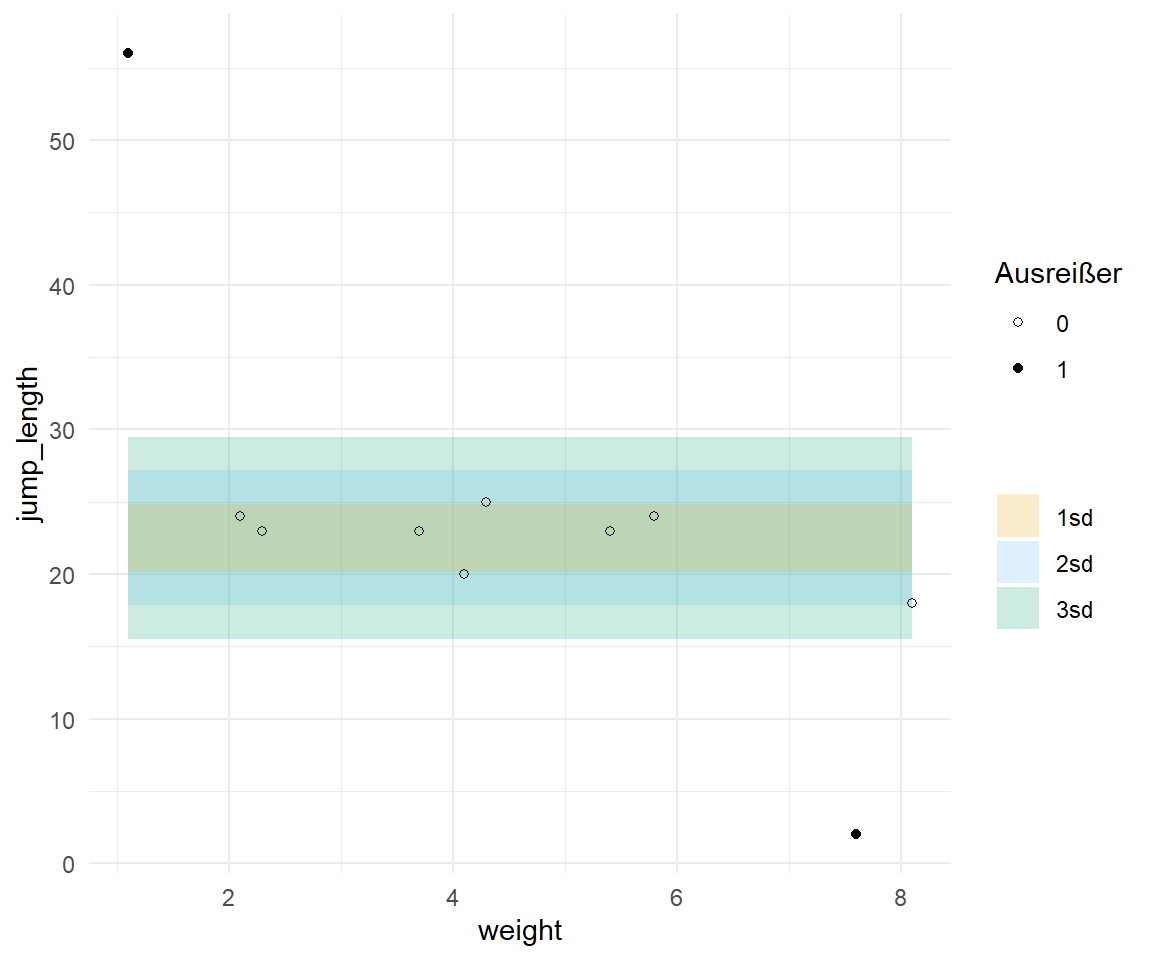
In der @fig-sd-2 sehen wir dann einmal das Ergebnis unseres Vorgehens. Die $\circ$ stellen dabei die Beobachtungen dar, die wir nicht als Ausreißer deklariert haben. Die $\bullet$ repräsentieren dann unsere potenziellen Ausreißer. Dann konnte ich mit den $\circ$-Werten einmal den Mittelwert berechnen und die Standardabweichungen für $k$ von 1 bis 3 einfärben. Wir sehen klar, dass die potenziellen Ausreißer nicht in den Sigmaintervallen liegen. Daher wären die beiden potenziellen Ausreißer schon ungewöhnliche Repräsentation den der anderen Werte. Wie immer, liegt hier natürlich das Problem darin, dass wir irgendwie vorab definieren müssen, welche der Werte denn als potenzielle Ausreißer in Frage kommen. Aber meistens kannst du das dann doch, so dass die Sigmaregel eine gute Methode ist einfach und schnell Ausreißer zu definieren.
```{r}
#| echo: true
#| message: false
#| label: fig-sd-2
#| fig-align: center
#| fig-height: 5
#| fig-width: 6
#| fig-cap: "Darstellung der Sigmaregel mir vorher deklarierten Ausreißern. Die Sigmaintervalle wurden auf den $\\circ$-Werten berechnet und die zwei potenziellen Ausreißer als $\\bullet$-Werte vorab definiert und somit aus der Berechnung herausgenommen."
sd_out_tbl |>
ggplot(aes(weight, jump_length)) +
theme_minimal() +
geom_ribbon(aes(ymin = 22.5 - 3 * 2.33,
ymax = 22.5 + 3 * 2.33,
fill = "3sd"), alpha = 0.2) +
geom_ribbon(aes(ymin = 22.5 - 2 * 2.33,
ymax = 22.5 + 2 * 2.33,
fill = "2sd"), alpha = 0.2) +
geom_ribbon(aes(ymin = 22.5 - 1 * 2.33,
ymax = 22.5 + 1 * 2.33,
fill = "1sd"), alpha = 0.2) +
scale_fill_okabeito(name = "") +
geom_point(aes(shape = as_factor(potential_outlier))) +
scale_shape_manual(name = "Ausreißer", values = c(1, 19))
```
### Ausreißer mit Hampelfilter
Jetzt kann man sich natürlich fragen, wenn es eine Sigmaregel gibt in der wir den Mittelwert plusminus $k$-mal die Standardabweichung rechnen, geht das denn nicht auch mit dem Median $\tilde{y}$ anstatt dem Mittelwert? Ja geht auch. Und deshalb heißt dieser Filter dann Hampelfilter. Ja, das ist dann immer in der Statistik so, dass auf einmal die Sachen wieder nach den Erfinder heißen und man sich das nicht am Namen merken kann, was der Filter oder die Methode macht. Der Hampelfilter gibt uns aber auch in Intervall $I$ wieder, in dem wir sagen würden, dass wir alle Beobachtungen wiederfinden sollten. Wenn wir Beobachtungen außerhalb des Intervalls $I$ vorliegen haben, dann sind diese Beobachtungen Ausreißer. Wir berechnen das Intervall $I$ für den Hampelfilter wie folgt.
$$
I = [\tilde{y} - 3 \cdot MAD;\; \tilde{y} + 3 \cdot MAD]
$$
Wir nehmen einfach den Median $\tilde{y}$ und addieren und subtrahieren das dreifache des $MAD$-Wertes. Den Wert für $MAD$ mit der [Median absolute deviation](https://en.wikipedia.org/wiki/Median_absolute_deviation) (deu. *Mittlere absolute Abweichung vom Median*, abk. *MAD*) können wir dann ebenfalls recht einfach wie folgt berechnen. Der MAD ist damit der Median der absoluten Abweichungen aller Beobachtungen vom Median. Sozusagen der Median vom Median.
$$
MAD = \tilde{d}\; \mbox{mit}\; d = y_i - |\tilde{y}|
$$
Weil das sich meistens dann doch wirrer anhört als es ist, hier einmal ein Zahlenbeispiel mit sieben willkürlich gewählten Zahlen in dem Vektor $y$.
```{r}
y <- c(1, 2, 4, 6, 9, 12, 15)
```
Dann berechnen wir einfach einmal den Median. Da ich die Zahlenreihe schon vorab sortiert habe, sieht man gleich, dass der Median $6$ ist.
```{r}
median(y)
```
Jetzt berechnen wir noch den absoluten Abstand von jeder Beobachtung $y$ zu dem Median $\tilde{y}$ gleich 6 und sortieren die Werte wieder. Denn dann können wir wieder den mittleren Wert als Median für unseren $MAD$-Wert bestimmen.
```{r}
(y - median(y)) |> abs() |> sort()
```
Damit wäre der $MAD$ in unserem Beispiel auch $4$ und das können wir auch mit der Funktion $mad()$ einmal überprüfen. Wir müssen hier noch als `constant` gleich 1 wählen, da wir sonst noch einen Korrekturterm in der Formel erhalten, die wir hier nicht brauchen.
```{r}
mad(y, constant = 1)
```
Dann können wir auch schon das Intervall für unser Beispiel aufschreiben.
$$
I = [6 - 3 \cdot 4;\; 6 + 3 \cdot 4] = [-6; 18]
$$
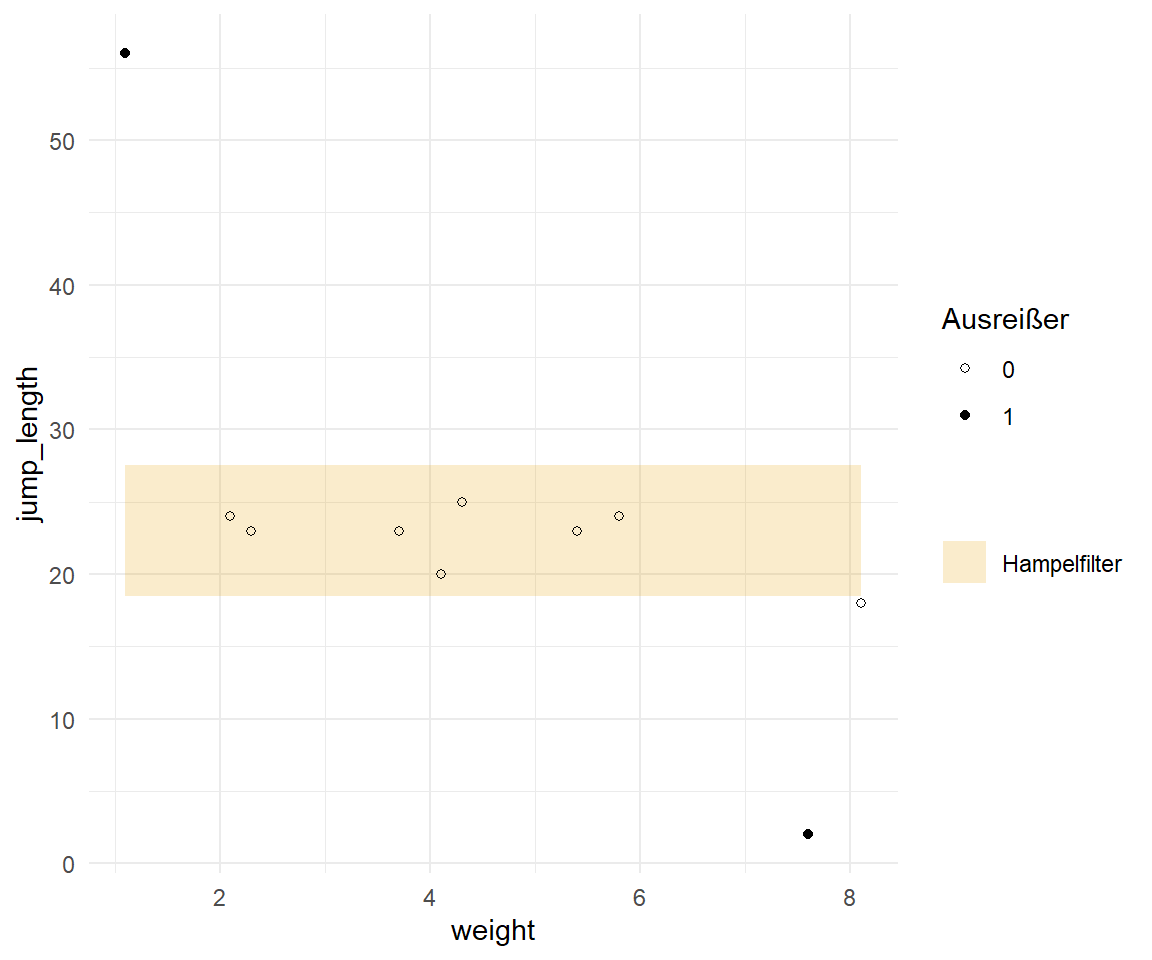
Dann können wir den Hampelfilter einmal auf unserem Beispiel der Sprungweitendaten anwenden. Ich nehme hier den vollen Datensatz und deklarieren nicht vorab potenzielle Ausreißer wie bei der Sigmaregel. Das ist eigentlich ein Vorteil des Hampelfilters, wir müssen hier nicht so viel vorher als potenzielle Ausreißer definieren.
```{r}
out_tbl |>
summarise(Median = median(jump_length),
MAD = mad(jump_length, constant = 1))
```
Damit ahben wir einen Median von $23$ und einen MAD-Wert von $1.5$ vorliegen. Somit kann ich mir dann im `geom_ribbon()` das Intervall in der @fig-hampel-1 einmal visualisieren. Das hat ziemlich gut funktioniert. Wir sehen, dass unsere beiden Ausreißer außerhalb des Intervalls des Hampelfilters liegen. Die letzte Beobachtung liegt ziemlich genau auf der Grenze, was nicht weiter schlimm ist. Hier würde ich dann ein Auge zudrücken.
```{r}
#| echo: true
#| message: false
#| label: fig-hampel-1
#| fig-align: center
#| fig-height: 5
#| fig-width: 6
#| fig-cap: "Darstellung des Hampelfilters mir vorher deklarierten Ausreißern. Der Hampelfilter wurde auf allen Werten berechnet und gibt die beiden Ausreißer ($\\bullet$-Wert) wieder."
sd_out_tbl |>
ggplot(aes(weight, jump_length)) +
theme_minimal() +
geom_ribbon(aes(ymin = 23 - 3 * 1.5,
ymax = 23 + 3 * 1.5,
fill = "Hampelfilter"), alpha = 0.2) +
scale_fill_okabeito(name = "") +
geom_point(aes(shape = as_factor(potential_outlier))) +
scale_shape_manual(name = "Ausreißer", values = c(1, 19))
```
### Ausreißer mit einem statistischen Test
Neben den einfachen Regeln, gibt es auch die Möglichkeit einen statistischen Test für Ausreißer zu rechnen. Alle Folgenden drei Tests funktionieren nur auf annähernd normalverteilten Daten. Das ist schon mal die erste wichtige Einschränkung. Wir schauen also, ob wirklich alle Beobachtungen zu einer Normalverteilung passen. Die Beobachtungen, die dann nicht passen, schmeißen wir raus. Also im Prinzip testen wir uns eine Normalverteilung zusammen. Neben dieser Einschränkung gibt es dann bei allen drei Tests noch weitere. Ich selber mag die statistischen Tests auf einen Ausreißer nicht. Zum einen sehr viel Arbeit diese zu Programmieren und durchzuführen und zum anderen nutzen mir die Informationen aus dem Testen wenig. Für die Ausführung in R besuche auch gerne das Tutorium [Outliers detection in R - Statistical tests](https://statsandr.com/blog/outliers-detection-in-r/#statistical-tests).
- Der **Grubbs’s Test** lässt sich in R mit der Funktion `grubbs.test()` in dem R Paket `{outliers}` finden. Neben der Annahme, dass unsere Daten normalvertelt sind, testet der Grubb's Test immer nur eine einzige Beobachtung, ob diese Beobachtung ein Ausreißer ist. Das macht die Sache schon sehr aufwendig und es wird auch immer nur der kleinste oder der größte Wert betrachtet.
- Der **Dixon’s Test** ist die Grubb's Variante für eine kleine Stichprobe von weniger als $n = 25$ Beobachtungen. Aber auch hier Testen wir nur eine Beobachtung, ob diese Beobachtung ein Ausreißer ist. Darüber hinaus betrachtet der Dixon’s Test auch nur den kleinsten oder größten Wert. Die Funktion `dixon.test()` findest du ebenfalls in dem R Paket `{outliers}`.
- Der **Rosner’s Test** mit der R Funktion `rosnerTest()` aus dem R Paket `{EnvStats}` erlaubt das Testen von mehreren Ausreißern auf einmal. Hier brauchen wir aber eine Fallzahl von mehr als 20 Beobachtungen, sonst funktioniert der Test nicht robust. Der größte Nachteil hier ist, dass du vorher sagen musst, wie viele Ausreißer $k$ den in deinen Daten drin sind. Wenn du zu wenig angibst, dann übersiehst du welche und bei einer zu großem $k$ kommt der Algorithmus nicht mit.
Wir anfangs schon erwähnt, bin ich kein Fan der statistischen Tests auf Ausreißer. Am Ende testet und schneidet man sich eine Normalverteilung aus den Daten, auch wenn ursprünglich gar keine Normalverteilung vorlag. Plus du hast die ganzen Probleme des statistischen Testens mit Fehlerraten. Aber auf der anderen Seite ist es ja hier auch ein Nachschlagewerk.
## Ausreißer mit `{performance}`
Nun wollen wir uns den echten Daten zuwenden und dort einmal schauen, ob wir Ausreißer finden können. Wir nutzen hierzu einmal die Funktion `check_outliers()` aus dem R Paket `{performance}`. Die Funktion `check_outliers()` rechnet nicht *eine* statistische Maßzahl für die Bestimmung eines Ausreißers sondern eine ganze Reihe an Maßzahlen und gewichtet diese Maßzahlen. Am Ende trifft die Funktion `check_outliers()` dann eine Entscheidung welche Beobachtungen Ausreißer sind. Dabei werden alle Variablen betrachtet. Es gibt keinen Unterschied zwischen $y$ oder $x$. Wir nutzen den ganzen Datensatz. Mehr zu der Funktion auf der Hilfeseite zu [Outliers detection (check for influential observations)](https://easystats.github.io/performance/reference/check_outliers.html). Wie immer kann die Funktion weit mehr, als das ich hier diskutieren kann. Wir wollen jetzt einmal für den Gummibärchendatensatz schauen, ob wir unsere Girl's Day Teilnehmerinnen als Ausrißer finden oder aber die etwas älteren Semester meiner Statistikweiterbildungen.
```{r}
out_performance_obj <- check_outliers(gummi_tbl)
out_performance_obj
```
Wir finden also zwölf Ausreißer in unseren Daten. Wir können diese Beobachtungen einmal mit der Funktion `filter()` rausziehen und uns anschauen. Wir sehen, dass wir hier die älteren Semester in den Daten als Ausreißer wiederfinden, jedoch nicht die Teilnehmerinnen des Girl's Day.
```{r}
gummi_tbl |>
filter(out_performance_obj)
```
Dann bauen wir uns einmal einen Datensatz mit einer zusätzlichen Spalte `outlier` in der wir uns markieren, welche Beobachtung ein Ausreißer nach der Funktion `check_outliers()` ist. Dann können wir den Datensatz nutzen um uns einmal die Ausreißer in den gesammten Daten zu visualisieren.
```{r}
gummi_performance_out_tbl <- gummi_tbl |>
mutate(outlier = out_performance_obj)
```
In der @fig-beeswarm-out-gummi-0 siehst du einmal die Ausreißer als $\bullet$-Werte und die normalen Beobachtungen als $\circ$-Werte. Wie du ziemlich gut erkennen kannst, werden die älteren Personen als Ausreißer gefunden nicht jedoch die jungen Teilnehmerinnen des Girl's Day. Die Ausreißer beziehen sich auch auf das Alter und nicht auf die Körpergröße. Durch die Körpergröße finden wir keine zusätzlichen Ausreißer in den Daten.
```{r }
#| echo: true
#| message: false
#| label: fig-beeswarm-out-gummi-0
#| fig-align: center
#| fig-height: 5
#| fig-width: 6
#| fig-cap: "Der Beeswarm ist ein Dotplot für eine große Anzahl an Beobachtungen. Hier schauen wir uns einmal das Alter und die Körpergröße aufgeteilt nach Geschlecht an. Die gefundenen Ausreißer sind mit $\\bullet$ markiert, die nromalen Beobachtungen als $\\circ$ dargestellt."
#| fig-subcap:
#| - "Alter nach Geschlecht"
#| - "Körpergröße nach Geschlecht"
#| layout-nrow: 1
gummi_performance_out_tbl |>
ggplot(aes(x = gender, y = age, color = gender, shape = outlier)) +
geom_beeswarm(size = 1) +
theme_minimal() +
scale_color_okabeito(order = c(2, 7), guide = "none") +
scale_shape_manual(name = "Ausreißer", values = c(1, 19)) +
labs(x = "Geschlecht", y = "Alter in [Jahren]")
gummi_performance_out_tbl |>
ggplot(aes(x = gender, y = height, color = gender, shape = outlier)) +
geom_beeswarm(size = 1) +
theme_minimal() +
scale_color_okabeito(order = c(2, 7), guide = "none") +
scale_shape_manual(name = "Ausreißer", values = c(1, 19)) +
labs(x = "Geschlecht", y = "Körpergröße in [cm]")
```
Jetzt müssten wir eigentlich einmal mit den Optionen und Methoden in der Funktion `check_outlier()` spielen und verschiedene Einstellungen testen. Das übersteigt dann aber natürlich dieses Kapitel. So gibt es auch eine `plot()` Funktion, aber diese stößt bei der Menge an Beobachtungen in den Gummibärchendaten an die Grenze. Wir sehen dann einfach in der Abbildung nichts mehr. Wir können auch Ausreißer anhand eines Modells ermitteln, aber auch hier hilft dann die Hilfeseite der Funktion `check_outlier()` unter [Outliers detection (check for influential observations)](https://easystats.github.io/performance/reference/check_outliers.html) weiter.
## Ausreißer mit `{olsrr}`
Eine weitere Möglichkeit Ausreißer zu finden bietet das R Paket `{olsrr}`, wenn wir uns nur auf normalverteilte Daten konzentrieren. Die grundlegende Idee ist dabei, dass wir ein Modell mit `lm()` gerechnet haben und jetzt anhand des Modellfits schauen wollen, ob wir auffällige Beobachtungen gegeben dem Modell in unseren Daten haben. Im einfachsten Fall schauen wir dabei, ob wir dann Beobachtungen haben, die weiter weg von der Geraden liegen. Das R Paket `{olsrr}` hat eine Vielzahl an Funktionen, die wir nutzen können um auffällige Beobachtungen zu finden. Schau dir einfach einmal das [R Paket und die Webseite](https://olsrr.rsquaredacademy.com/articles/influence_measures) näher an. Nervig ist vor allem, dass wir keine reinen `{ggplot}` Objekte wiederkriegen, so dass wir dann nicht mal eben mit `+` das Layout oder andere Dinge ändern können. Das macht uns dann hässliche Abbildungen und ich mag keine hässlichen Abbildungen. Daher sind die Abbildungen eher was für den Anhang als in der Arbeit selber. Auch ist das Extrahieren der Ausreißer aus dem `{olsrr}` Objekt dann nicht so richtig einfach. Da hätte ich mir eigentlich mehr erhofft. Nur die Abbildung ist zwar schön, aber ich will ja auch die Beobachtungen als Objekt in R wieder haben. Sonst muss ich mir das ja alles mühselig wieder eintippen.
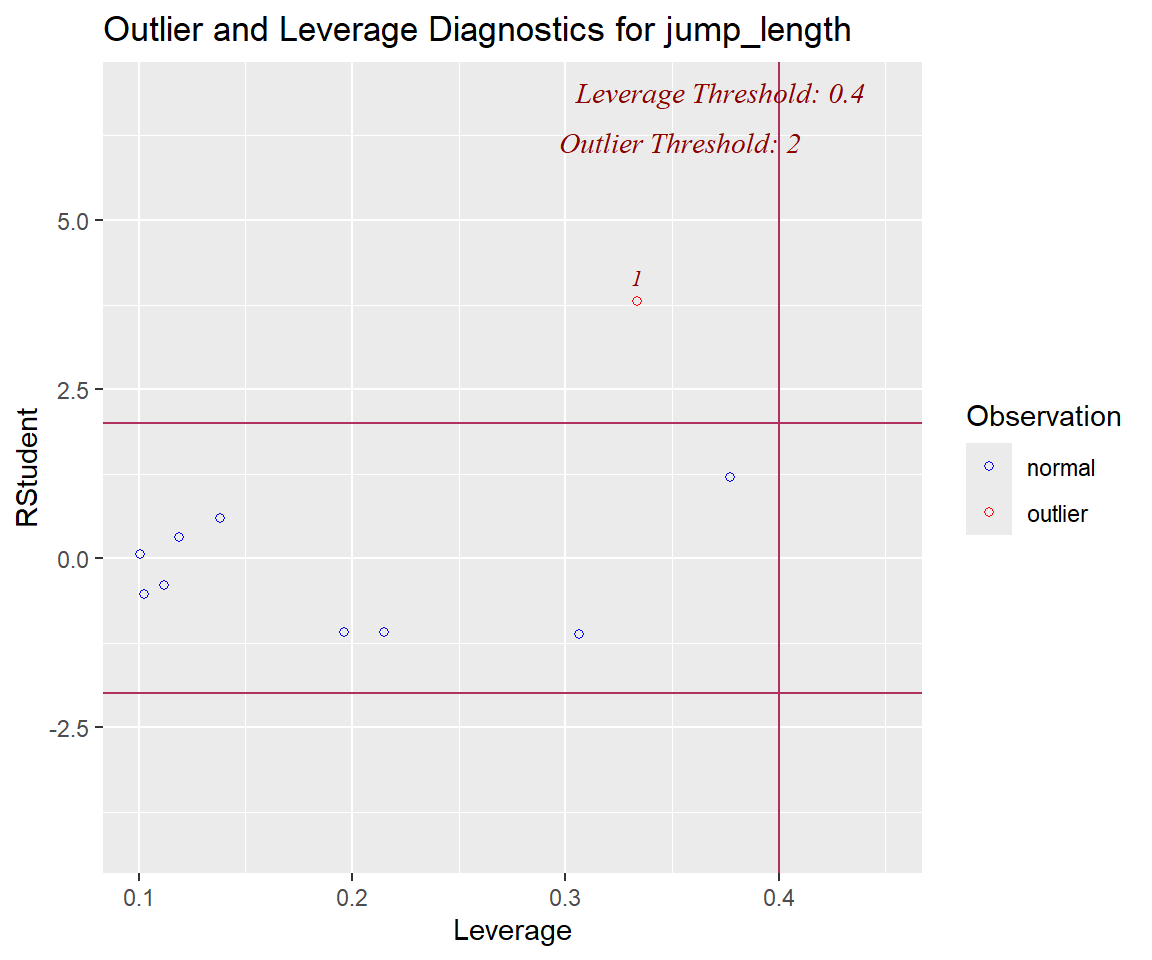
In der @fig-olsrr-2 siehst du dann einmal die Ausgabe der Diagnoseabbildung für die Ausreißer sowie der *leverage*. Hier finden wir dann die erste Beobachtung als klaren Ausreißer, die andere Beobachtung jedoch nicht. Da die Abbildung dann auch mit den echten Werten von $x$ und $y$ zu tun hat, muss man immer etwas genauer schauen, welche Beobachtung nun für welche Werte steht. Der Grenzwert für die Ausreißer ist wie oben schon erklärt auf $0.4$ gesetzt.
```{r}
#| echo: true
#| message: false
#| label: fig-olsrr-2
#| fig-align: center
#| fig-height: 5
#| fig-width: 6
#| fig-cap: "Die Ausreißer und *leverage* Diagnoseabbildung für unsere Sprungweitendaten. Der Ausreißer an der ersten Position wird erkannt, der andere Ausreißer hingegen nicht."
jump_fit |>
ols_plot_resid_lev()
```
Schauen wir uns dann nochmal ein größeres Beispiel mit den Gummibärchendaten an. Hier bilden wir erstmal das Modell in dem Sinne, dass wir rausfinden wollen, ob das Alter von dem Geschlecht und der Körpergröße abhängt. Dann schauen wir, ob wir Beobachtungen haben, die nicht richtig passen. Auch hier hoffe ich die Teilnehmerinnen vom Girl's Day oder aber meine älteren Teilnehmer von einem Workshop wiederzufinden.
```{r}
gummi_fit <- lm(age ~ gender + height, data = gummi_tbl)
```
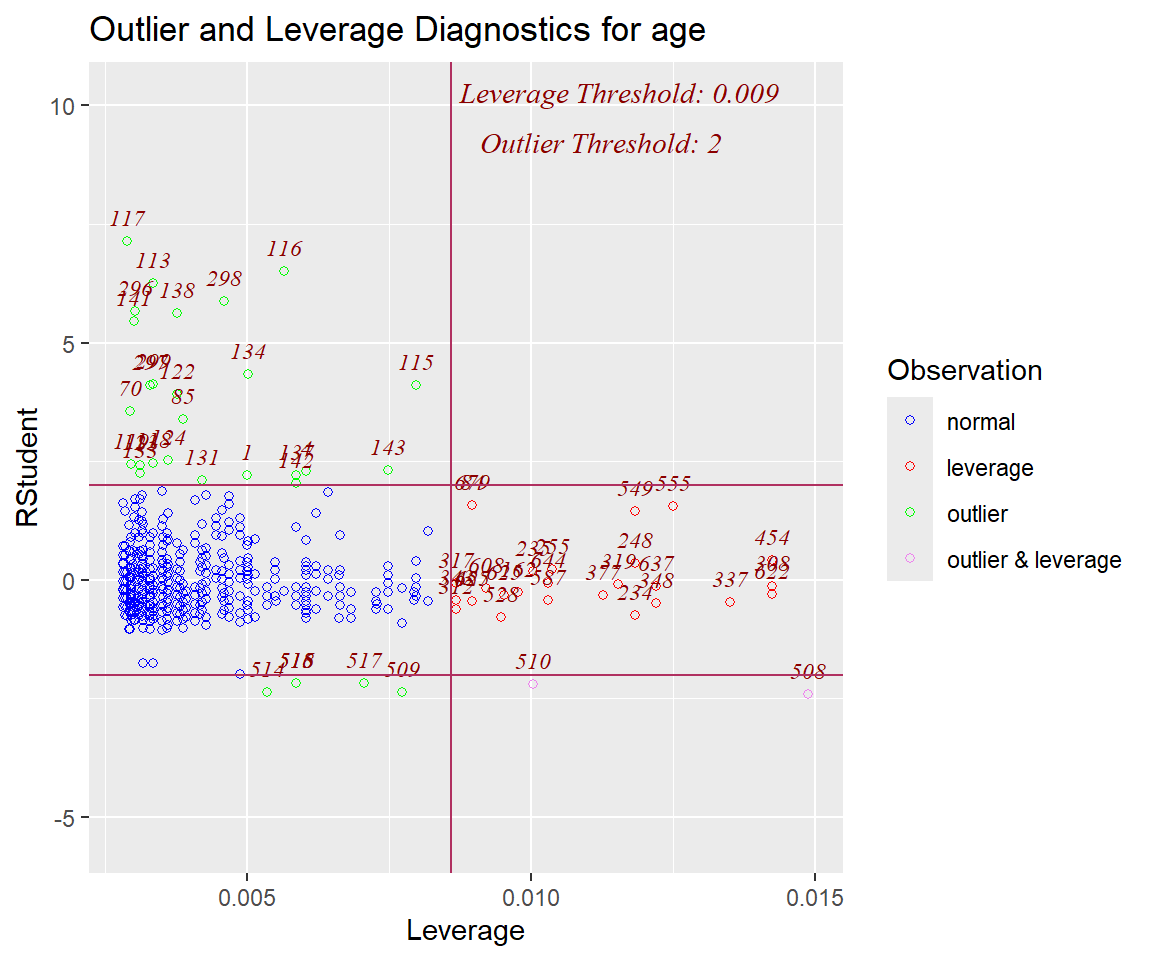
Dann schauen wir uns einmal in der @fig-olsrr-0 einmal die Diagnoseabbildung für die Ausreißer sowie der *leverage* für die Gummibärchendaten an. Da ist man doch sehr überrascht, dass so viele Ausreißer in den Daten erkannt werden. Meine Güte sind das viele Beobachtungen, die wir rauschmeißen würden. Auch hier hilft es dann nur, sich die Ausreißer einmal in den echten Daten anzuschauen, damit wir wissen, was wir da entfernen würden.
```{r}
#| echo: true
#| message: false
#| label: fig-olsrr-0
#| fig-align: center
#| fig-height: 5
#| fig-width: 6
#| fig-cap: "Die Ausreißer und *leverage* Diagnoseabbildung für unsere Gummibärchendaten. Hier werden reichlich Ausreißer in unseren Daten erkannt."
ols_plot_resid_lev(gummi_fit)
```
Leider müssen wir uns jetzt etwas umnständlich die Daten aus dem Plot ziehen. Allgemein ist die Arbeit mit den Objekten der Abbildungen nicht so super gelöst. Jedenfalls habe ich da keine guten Funktionen auf die Schnelle gefunden. Wir können uns aber die Daten `data` aus dem Plotobjekt rausziehen. Wir müssen aber mit `print_plot = FALSE` verhindern, dass uns der Plot angezeigt wird, sonst haben wir immer alles voll mit den Abbildungen. In dem Datensatz steht dann in der Spalte `color`, welche Beobachtung ein Ausreißer ist. Ja, ist dämlich, aber was will man machen.
```{r}
outlier_tbl <- ols_plot_resid_lev(gummi_fit, print_plot = TRUE) |>
pluck("data") |>
as_tibble()
outlier_tbl
```
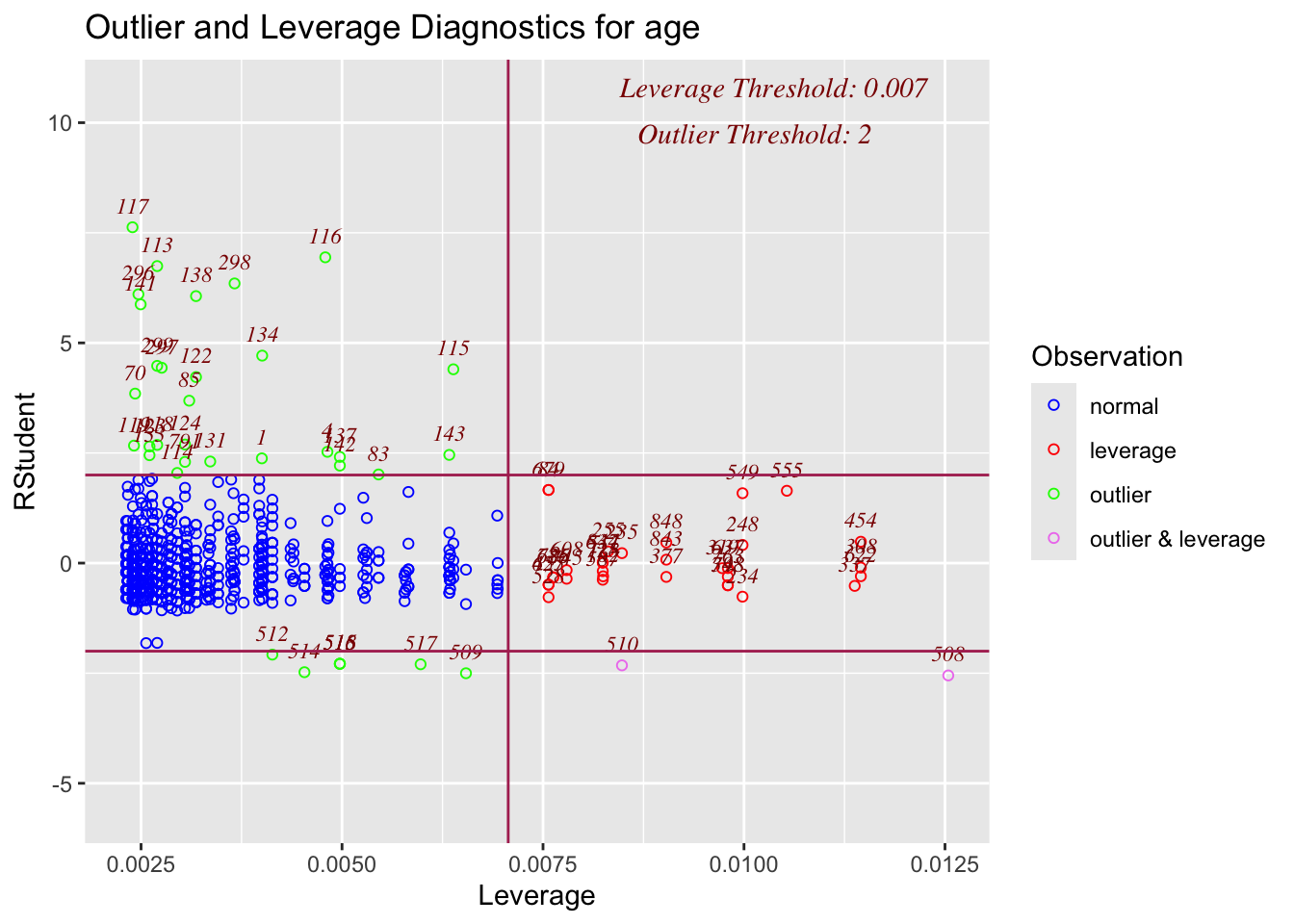
Jetzt können wir anfangen zu filtern. Ich empfehle dir die Spalte `color` zu nehmen und nur nach Beobachtungen mit `normal` zu filtern. Dann entfernst du alle Ausreißer aus den Daten. Wir haben aber nicht nur Ausreißer mit dem Label `outlier` in den Daten sondern auch welche mit dem Label `leverage` oder aber nach beiden Kriterien. Deshalb musst du schauen, welche Beobachtungen du dann rauschmeißen willst bzw. behalten willst. Ich filtere hier mal nach `normal`. In der @fig-olsrr-1 siehst du dann einmal auf der linken Seite die Daten mit den Labels für die jeweiligen Ausreißer. Immerhin finden wir hier auch wieder alle älteren Semester plus einen Teil der jüngeren Teilnehmerinnen des Girl's Day. Wir entfernen aber eine Menge an Datenpunkten. Insbesondere das Entfernen nach der *leverage* muss kritisch hinterfragt werden. Die angeblichen Ausreißer nach *leverage* liegen ja direkt in den Punktewolken. Das Entfernen würde ich also hinterfragen und dann komplexer filtern.
```{r}
#| echo: true
#| message: false
#| label: fig-olsrr-1
#| fig-align: center
#| fig-height: 5
#| fig-width: 6
#| fig-cap: "Die Gummibärchendaten einmal mit markierten Ausreißern und einmal gefiltert nach `normal` in der Saplte `color`. Das Filtern über die Spalte `color` ist natürlich sehr unintuitiv. Wir sehen, dass wir eine Menge an Beobachtungen aus den Daten entfernen."
#| fig-subcap:
#| - "Orginaldaten mit markierten Ausreißern."
#| - "Bereinigte Daten ohne Ausreißer"
#| layout-nrow: 1
gummi_tbl |>
bind_cols(outlier_tbl) |>
ggplot(aes(x = gender, y = age, color = gender, shape = color)) +
geom_beeswarm(size = 1) +
theme_minimal() +
scale_color_okabeito(order = c(2, 7), guide = "none") +
scale_shape_manual(name = "Ausreißer", values = c(19, 1, 3, 4)) +
labs(x = "Geschlecht", y = "Alter in [Jahren]")
gummi_tbl |>
bind_cols(outlier_tbl) |>
filter(color == "normal") |>
ggplot(aes(x = gender, y = age, color = gender, shape = color)) +
geom_beeswarm(size = 1) +
theme_minimal() +
scale_color_okabeito(order = c(2, 7), guide = "none") +
scale_shape_manual(name = "Ausreißer", values = c(1)) +
labs(x = "Geschlecht", y = "Alter in [Jahren]") +
ylim(10, 60)
```
Wie du siehst ist eine Detektion von Ausreißern nicht so einfach. Zum einen brauchen wir dazu Daten, damit wir auch Ausreißer finden können. Zu irgendwas müssen wir ja die einzelnen Beobachtungen vergleichen. Zum anderen können wir auch extrem viele Beobachtungen entfernen und haben uns dann eine Normalverteilung zusammengeschnitten. Es bleibt ein Drahtseilakt.
::: callout-tip
## Anwendungsbeispiel: Ausreißer in einer simplen Regression
Wie auch in den anderen Kapiteln gibt es hier nochmal ein Anwendungsbeispiel für die Messung vom Keimfähigkeit durch ein Standardverfahren `standard` sowie ein Färbeverfahren `colorink` der Samen. Durch das Einfärben soll die Keimfähigkeit sehr viel früher erkannt werden, als es mit den konventionellen Verfahren möglich ist. Hier geht es jetzt aber erstmal darum, ob wir technische Gleichheit vorliegen haben. Damit wir aber überhaupt schauen können, ob die beiden Verfahren das Gleiche produzieren müssen wir sicher sein, dass wir keine auffälligen Werte in den Daten haben. Es kann ja sein, dass bei den biologischen Proben der eine oder andere Samen defekt ist oder aber andere Probleme wie Parasitenbefall vorlagen und dadurch die Keimfähigkeit verändert ist.
```{r}
standard_colorink_tbl <- read_excel("data/standard_colorink.xlsx")
```
Wir rechnen jetzt einmal ein lineare Regression mit der Funktion `lm()`. Wenn sich die beiden Verfahren nicht unterscheiden würden, dann lägen alle Beobachtungen auf einer Geraden.
```{r}
fit <- lm(standard ~ colorink, standard_colorink_tbl)
```
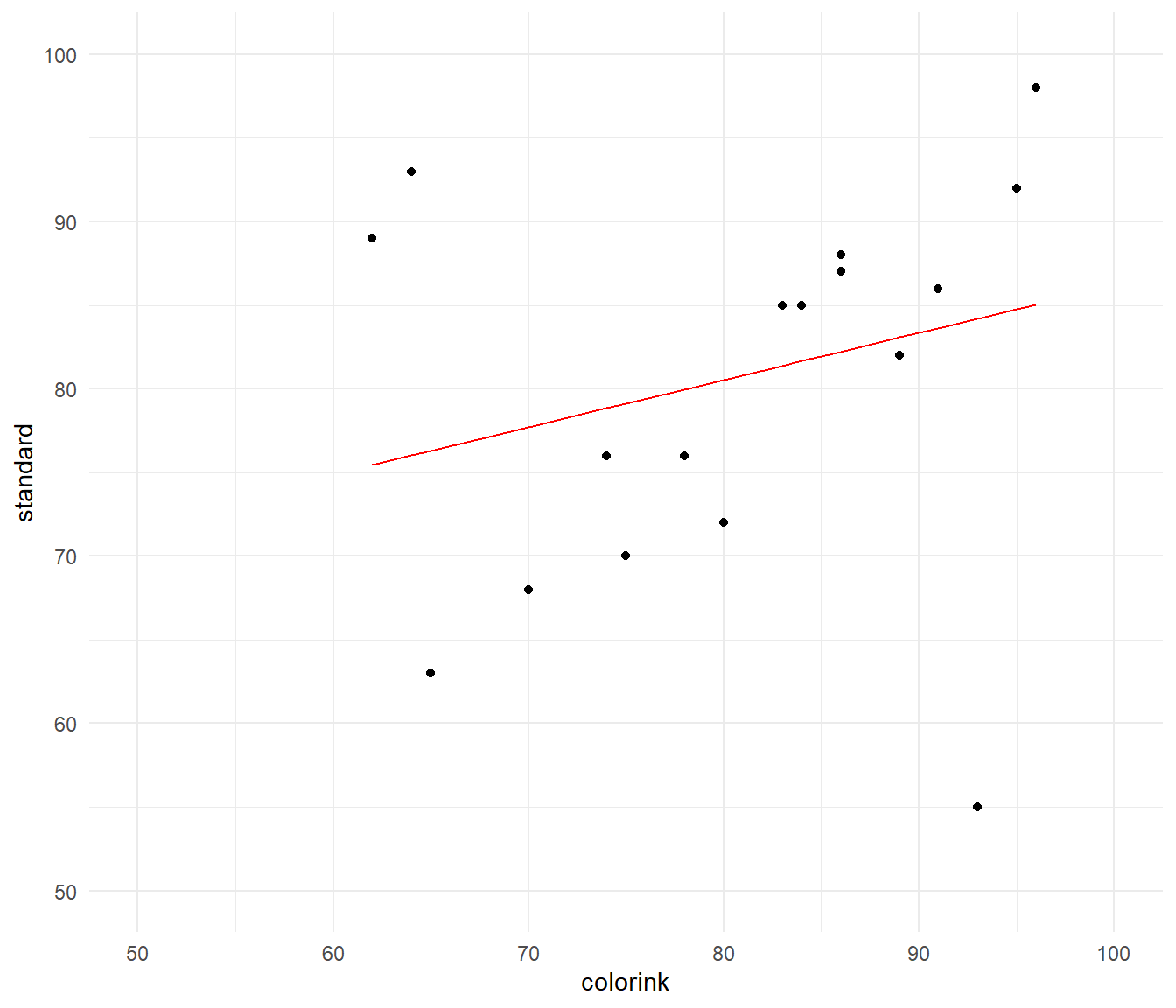
Dann schauen wir uns einmal die Daten in der @fig-app-compare-outlier-0 einmal an. Ich habe die Regression als Gerade einmal durch die Punktewolke gelegt. Wir sehen, dass es hier mindestens drei Beobachtungen gibt, die aussehen als wären sie potenzielle Ausreißer. Die Gerade folgt auch nicht den Punkten und die Abbildung sieht also nicht sehr schlüssig aus. Daher wollen wir einmal schauen, ob wir Ausreißer hier finden können.
```{r}
#| message: false
#| echo: true
#| warning: false
#| label: fig-app-compare-outlier-0
#| fig-align: center
#| fig-height: 6
#| fig-width: 7
#| fig-cap: "Scatterplot der Standardbehandlung zu der Färbebehandung mit drei potenziellen Ausreißern und einer Regressiongeraden. Es ist klar zu erkennen, dass die potenziellen Ausreißer die Gerade stark beeinflussen und somit die Gerade nicht die Punktewolke repräsentiert."
standard_colorink_tbl |>
ggplot(aes(colorink, standard)) +
theme_minimal() +
ylim(50, 100) + xlim(50, 100) +
geom_point() +
geom_line(aes(y = predict(fit)), color = "red")
```
Hier nochmal kurz das Bestimmtheitsmaß $R^2$ als Maßzahl wie gut die Punkte auf der Geraden liegen. Wie du sehen kannst ist der Wert sehr schlecht. Wir würden bei einer perfekten Übereinstimmung faktisch ein Bestimmtheitsmaß $R^2$ von 1 erwarten. Bei einem Bestimmtheitsmaß $R^2$ von 1 würden die Punkte alle auf einer geraden liegen. Es gebe keine Abweichung von den Punkten zu der Geraden.
```{r}
fit |> r2()
```
Mit der Funktion `augment()` aus dem R Paket `{broom}` können wir uns einfach die Hebelwirkung (eng. *leverage*) sowie den cook'schen Abstand wiedergeben lassen. Damit haben wir schon zwei sehr gute Maßzahlen um herauszufinden, ob wir Ausreißer in den Daten vorliegen haben. Damit ist dann nämlich $k$ gleich 1.
```{r}
fit |> augment()
```
Hier nochmal von oben kopiert die Regeln für die Hebenwirkung und den cook'schen Abstand. Wir rechnen hier bei beiden Grenzwerten die gleiche Zahl aus, da wir nur eine $x$-Variable mit `colorink` vorliegen haben. P
Leverage `.hat`
: Im Allgemeinen sollte ein Punkt mit einer Hebelwirkung von mehr als $(2k+2)/n$ sorgfältig geprüft werden, wobei $k$ die Anzahl der Prädiktorvariablen und n die Anzahl der Beobachtungen ist. Unsere Grenze wäre damit bei $(2 \cdot 1 + 2)/18 = 0.22$
Cook's Abstand `.cooksd`
: @hardin2007generalized bezeichnen Werte, die über $4/n$ liegen als problematisch. $n$ ist hierbei die Stichprobengröße. Unsere Grenze wäre damit bei $4/18 = 0.22$
Dann können wir auch schon einen Filter setzen und entscheiden hier einmal nach dem cook'schen Abstand. Wenn eine Beobachtung einen Wert größer als $0.22$ in der Spalte `.cooksd` hat, dann setzen wir diese Beobachtung als Ausreißer. Prinzipiell kannst du natürlich auch mit den anderen vorgestellten Methoden rechnen, aber hier zeige ich einmal den cook'schen Abstand.
```{r}
clean_tbl <- fit |>
augment() |>
mutate(outlier = ifelse(.cooksd > 0.22, "ja", "nein"))
```
In der @fig-app-compare-outlier-1 siehst du einmal das Ergebnis der Ausreißerbestimmung. Wir finden bei der Anzahl an Beobachtungen dann auch unsere drei auffälligen Werte als Ausreißer wieder. Wenn wir die Ausreißer entfernen, dann erhalten wir eine sehr gute Gerade, die auch gut durch die Punkte läuft. Wir würden dann die Beobachtungen aus der Exceldatei entfernen und dann nur noch mit den gereinigten Daten weitermachen. Aber Achtung, bitte nicht die Orginaldaten löschen, eventuell musst du ja später nochmal die Abbildungen mit den Ausreißern erstellen. Ich empfehle da immer einen neuen Tab in der Exceldatei anzulegen.
```{r}
#| message: false
#| echo: true
#| warning: false
#| label: fig-app-compare-outlier-1
#| fig-align: center
#| fig-height: 6
#| fig-width: 7
#| fig-cap: "Scatterplot der Standardbehandlung zu der Färbebehandung mit drei potenziellen Ausreißern und einer Regressiongeraden. Die Ausreißer nach dem cook'schen Abstand sind durch $\\circ$-Werte dargestellt. Die normalen Beobachtungen sind durch $\\bullet$-Werte abgebildet."
clean_tbl |>
ggplot(aes(colorink, standard, shape = outlier)) +
theme_minimal() +
ylim(50, 100) + xlim(50, 100) +
geom_point() +
geom_smooth(data = filter(clean_tbl, outlier != "ja"), method = "lm", color = "red", se = FALSE) +
scale_shape_manual(name = "Ausreißer", values = c(1, 19))
```
:::
## Referenzen {.unnumbered}