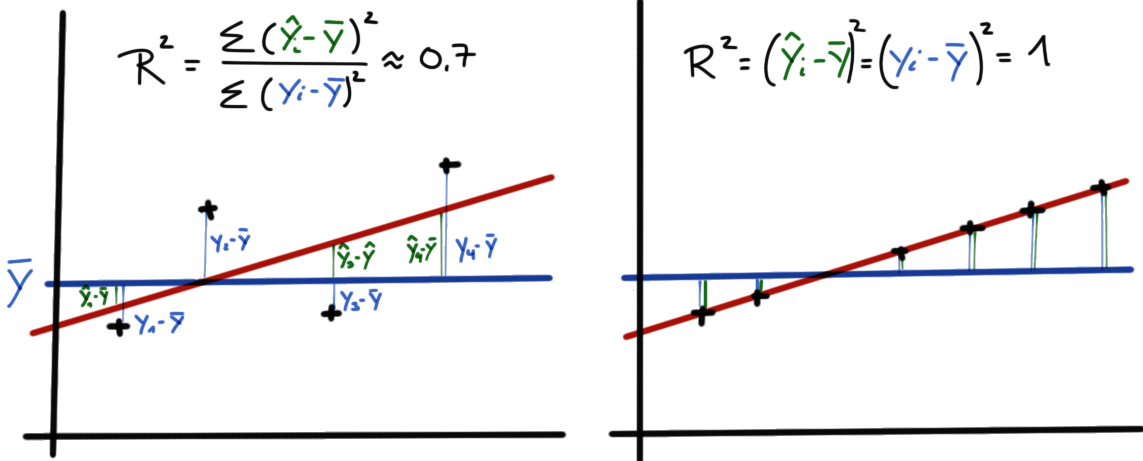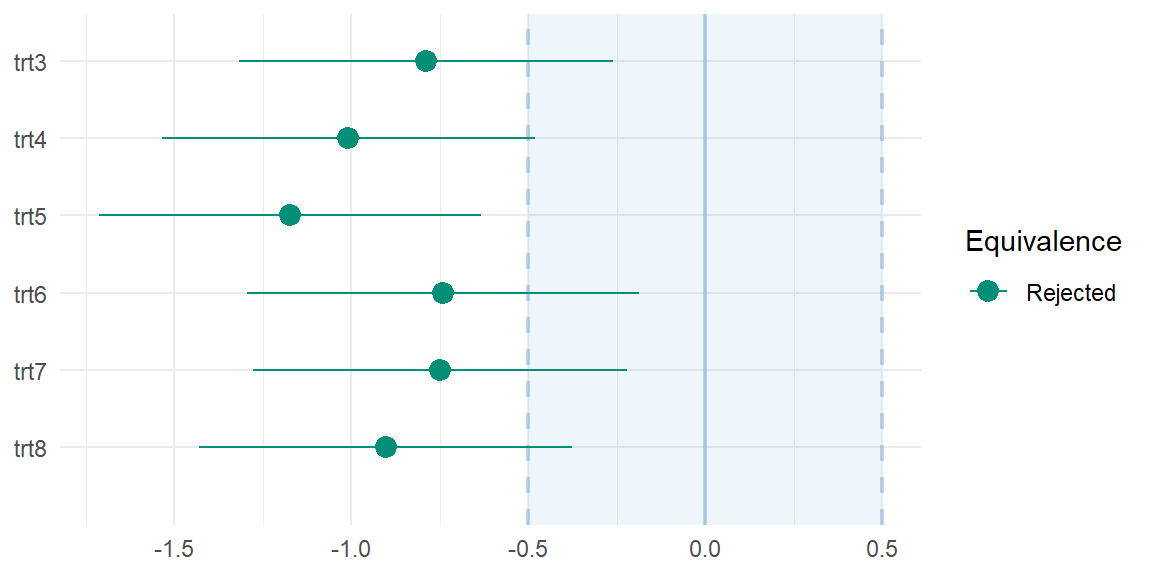```{r echo = FALSE}
#| message: false
pacman::p_load(tidyverse, readxl, knitr, kableExtra, openxlsx)
pacman::p_load(tidyverse, magrittr, broom, readxl,
effectsize, multcompView, multcomp, patchwork,
janitor, see, parameters, yardstick, latex2exp,
rcompanion, emmeans, conflicted)
conflicts_prefer(dplyr::select)
conflicts_prefer(dplyr::filter)
conflicts_prefer(dplyr::mutate)
cbbPalette <- c("#000000", "#E69F00", "#56B4E9", "#009E73",
"#F0E442", "#0072B2", "#D55E00", "#CC79A7")
```
# Äquivalenz oder Nichtunterlegenheit {#sec-noninf}
*Letzte Änderung am `r format(fs::file_info("stat-modeling-noninferiority.qmd")$modification_time, '%d. %B %Y um %H:%M:%S')`*
> *"Absence of evidence is not evidence of absence" --- @altman1995statistics*
::: {.callout-caution appearance="minimal"}
## Dieses Kapitel ist archiviert
{fig-align="center" width="100%"}
Ich benötige die Thematik aktuell nicht in meiner Lehre oder der statistischen Beratung. Mir ist es als Nachschlagewerk aber immer noch wichtig zu behalten. Archivierte Kapitel werden nicht von mir weiter gepflegt oder ergänzt. Auftretende Fehler werden aber natürlich beseitigt, wenn die Fehler mir auffallen oder gemeldet werden.
:::
In diesem Kapitel wollen wir uns mit Gleichheit beschäftigen. Dabei gibt es zwei Arten von Gleichheit. Zum einen können wir uns die technische Gleichheit anschauen oder aber die medizinische- oder Behandlungsgruppengleichheit. Wir definieren die beiden Settings daher wie folgt.
- **Technische Gleichheit** wollen wir nachweisen, wenn wir zwei *technische* Messmethoden miteinander vergleichen. Wir messen also einmal ein Wachstum mit dem Verfahren A und einmal mit dem Verfahren B. In beiden Fällen erhalten wir dann eine kontinuierliche Zahl, wie zum Beispiel das Gewicht. Jetzt wollen wir wissen, ob das Verfahren A gleich dem Verfahren B das Wachstum gemessen hat.
- **Medizinische- oder Behandlungsgleichheit** wollen wir nachweisen, wenn wir verschiedene Behandlungs*gruppen* haben. Damit wollen wir auch verschiedene Hypothesen testen. Diese Behandlungsgruppen vergleichen wir dann zu *einer* Kontrolle oder Standard und wollen nachweisen, dass unsere Behandlungsgruppen *gleich* zu dem Standard sind. Die Anwendung ist auch eher bei Tieren oder Menschen zu finden. Wir wollen hier also explizit keine technische Gleichheit nachweisen.
Je nachdem welche *Gleichheit* du dir anschauen willst, musst du natürlich auch andere statistische Verfahren wählen. Wir schauen uns daher in diesem Kapitel zuerst einmal die technische Gleichheit an - die ich hier mal so benenne - und danach die medizinische Gleichheit, die sich auf das statistische Hypothesentesten bezieht. Bei der *technischen* Gleichheit nutzen wir die lineare Regression und deren Gütekriterien. Bei der *medizinischen* Gleichheit drehen wir die statistischen Null- und Alternativehypothese und haben damit andere Probleme. Wir rechnen aber einen klassischen Hypothesentest.
::: callout-tip
## Weitere Literatur
Am Ende nochmal ein paar Links, die noch von Interesse sein könnten und die ich hier noch nicht verarbeitet habe. Vielleicht mache ich das dann noch oder ich finde noch andere spannende Referenzen. Ich sammle hier dann mal.
- [TOSTER](https://aaroncaldwell.us/TOSTERpkg/) und die dazugehörigen Referenzen auf der Seite geben nochmal einen super Überblick.
- [Marginal Effects Zoo - Equivalence Tests](https://marginaleffects.com/vignettes/equivalence.html#marginal-means-and-emmeans) liefert nochmal einen guten Ansatzpunkt für das Testen auf Gleichheit. Hier wird auch auf die Anwendung von `{emmeans}` eingegangen.
- Der alte Blogpost zu [TOST equivalence testing R package (TOSTER) and spreadsheet](https://daniellakens.blogspot.com/2016/12/tost-equivalence-testing-r-package.html).
- Mehr Informationen zu [Region of Practical Equivalence (ROPE)](https://easystats.github.io/bayestestR/articles/region_of_practical_equivalence.html) aus dem R Paket `{bayestestR}`.
:::
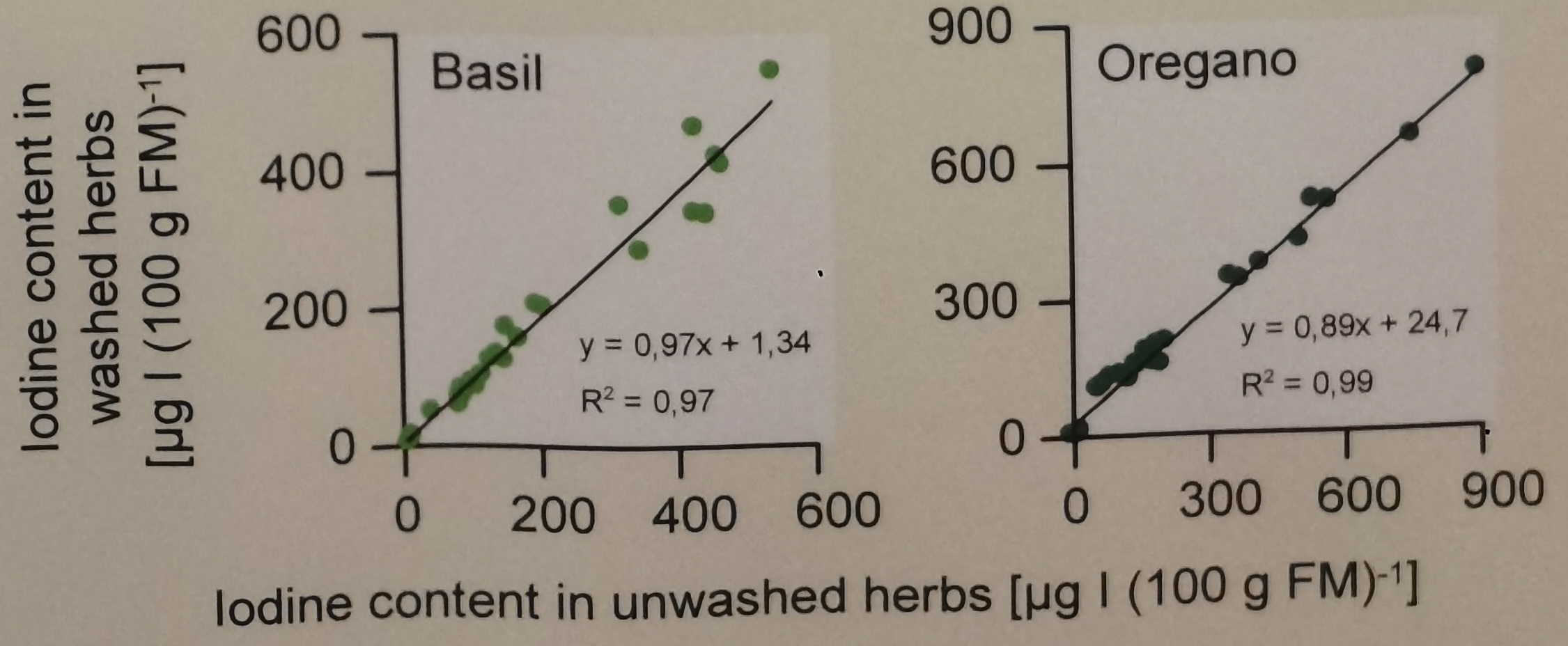
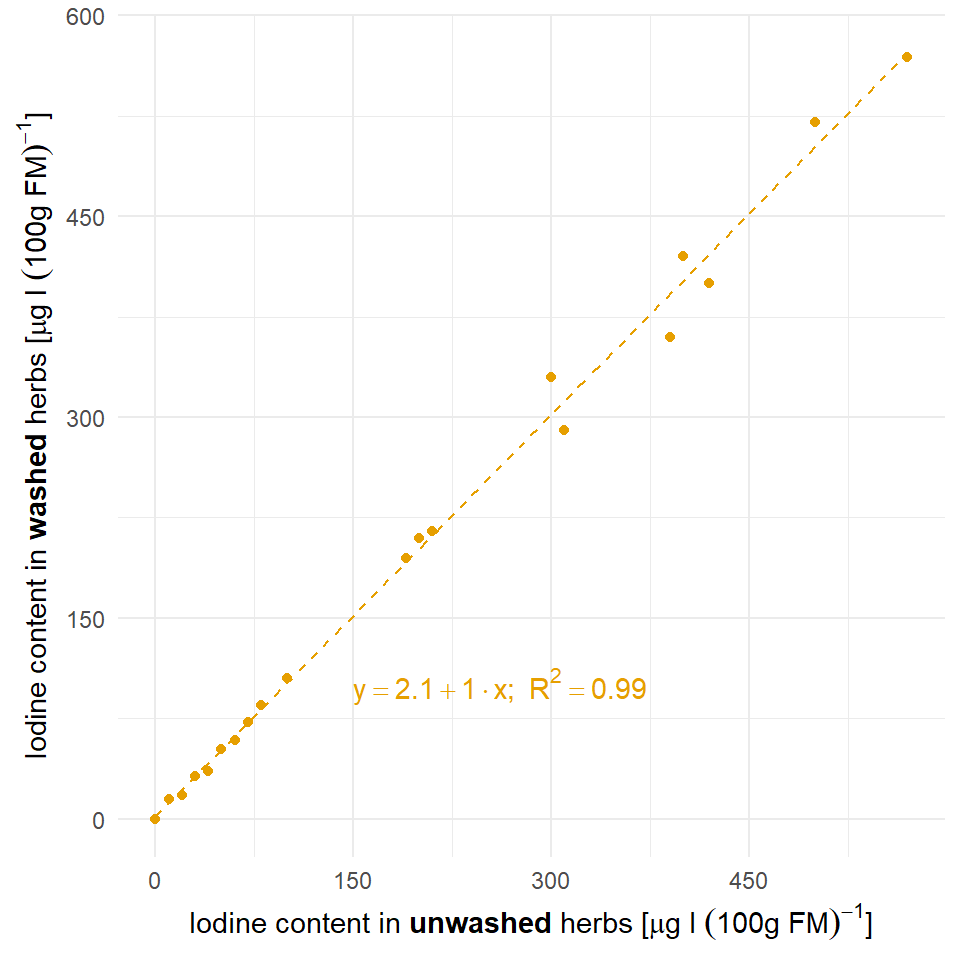
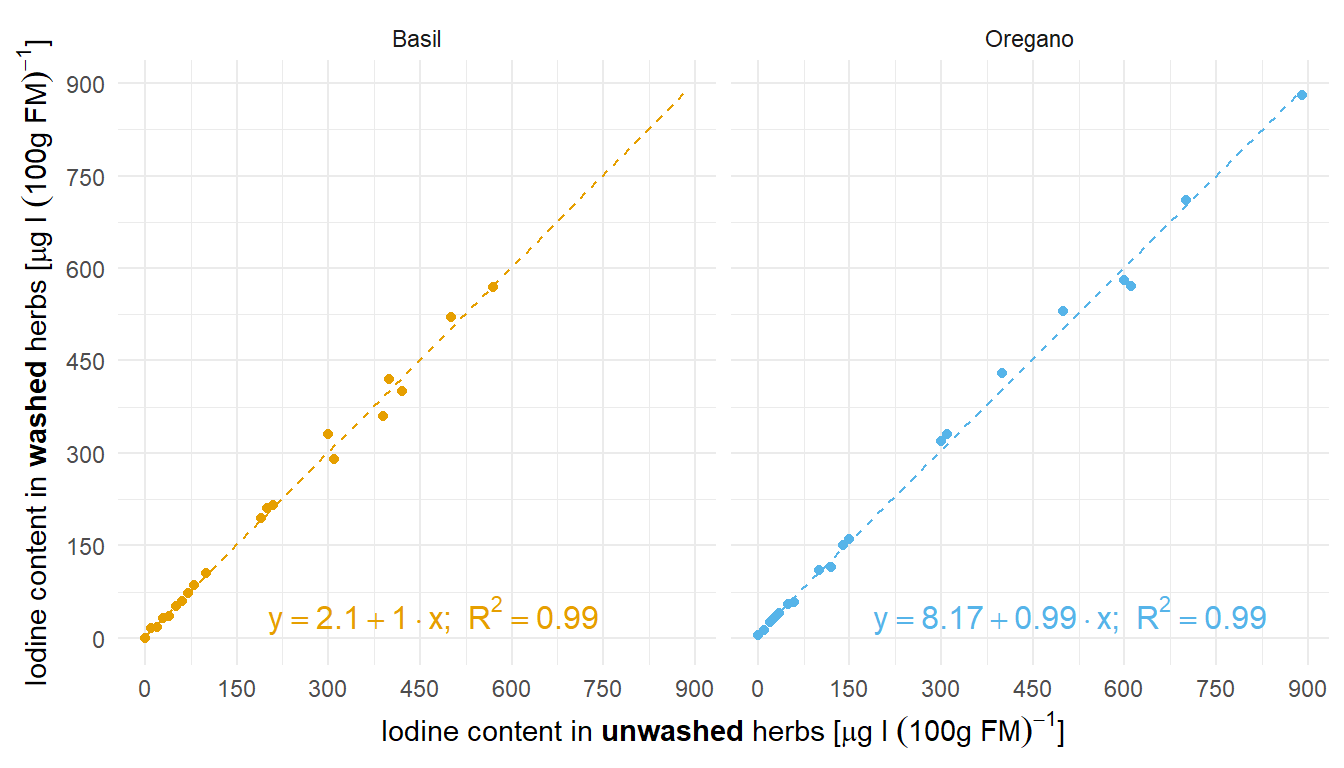
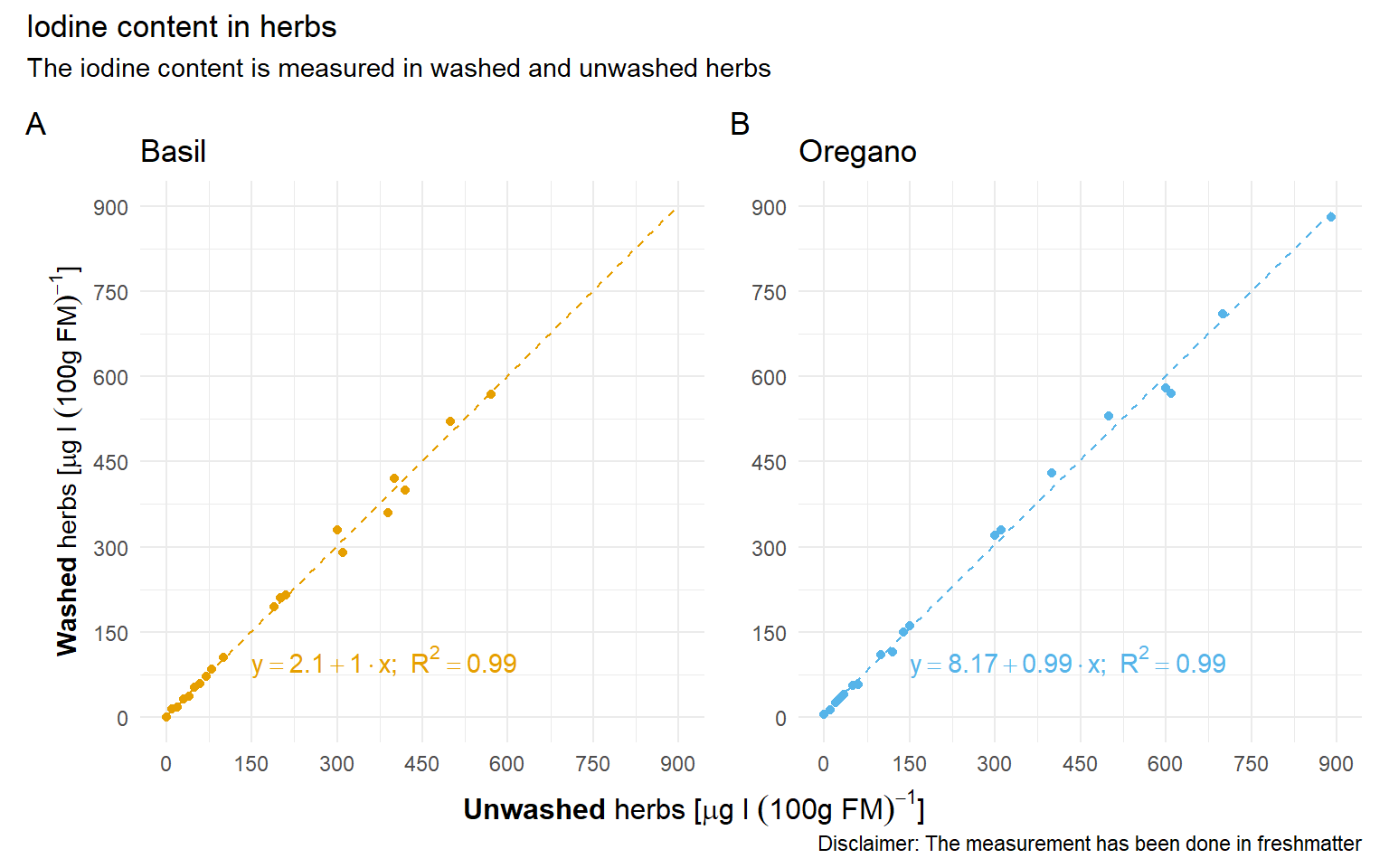
Zum Einstieg in die technische Gleichheit mag dir folgendes Beispiel der Zerforschung einer einfachen linearen Regression dienen. Hier geht es darum den Iodgehalt vor dem Waschen und nach dem Waschen von zwei Kräutern zu vergleichen und zu schauen, ob die beides gleich ist.
::: {.callout-note collapse="true"}
## Zerforschen: Technische Gleichheit vom Waschen von Kräutern?
{{< include zerforschen/zerforschen-simple-regression.qmd >}}
:::
## Genutzte R Pakete
Wir wollen folgende R Pakete in diesem Kapitel nutzen.
```{r echo = TRUE}
#| message: false
pacman::p_load(tidyverse, magrittr, broom, readxl,
effectsize, multcompView, multcomp,
janitor, see, parameters, yardstick,
rcompanion, emmeans, conflicted)
conflicts_prefer(dplyr::select)
conflicts_prefer(dplyr::filter)
conflicts_prefer(dplyr::mutate)
cbbPalette <- c("#000000", "#E69F00", "#56B4E9", "#009E73",
"#F0E442", "#0072B2", "#D55E00", "#CC79A7")
```
An der Seite des Kapitels findest du den Link *Quellcode anzeigen*, über den du Zugang zum gesamten R-Code dieses Kapitels erhältst.
## Daten
Als erstes wollen wir uns einmal die Daten für die Überprüfung der technischen Gleichheit anschauen. Die Daten stammen aus Dronenüberflügen zur Bestimmung der Grasdichte auf Weideflächen aus der Datei `drone_tech.xlsx`. Dabei haben wir zum einen die Grasdichte traditionell mit einem Druckstab gemessen `pressure_stick` und vergleichen diese Werte dann mit den Werten aus dem Dronenüberflug. Der Drohnenüberflug liefert uns Bilder und aus den Bildern extrahieren wir einen RGB-Wert (abk. *Red, Green, Blue*) in der Spalte `drone_rgb` oder einen CMYK-Wert (abk. *Cyan, Magenta, Yellow (Gelb), Key (Schwarz)*) in der Spalte `drone_cmyk`. Wir wollen nun schauen, ob wir die drei Werte sinnvoll in ein Verhältnis setzen können. Ein Auszug aus den Daten ist nochmal in der @tbl-equal-tech-01 dargestellt.
```{r}
#| message: false
#| echo: false
set.seed(20230564)
drone_tbl <- tibble(pressure_stick = rnorm(317, 1000, 200),
drone_rgb = -1000 + 1.20 * pressure_stick + rnorm(length(pressure_stick), 100, 60),
drone_cmyk = -1200 + 0.2 * pressure_stick + rpois(length(pressure_stick), 1200)) |>
mutate_if(is.numeric, round, 2) |>
filter(drone_rgb > 1 & drone_cmyk > 1)
write.xlsx(drone_tbl, "data/drone_tech.xlsx", rowNames = FALSE)
```
```{r}
#| message: false
#| echo: false
#| tbl-cap: "Datentabelle für den technischen Vergleich eines Druckstabes und dem RGB-Werten eines Dronenüberflugs auf die Grasdichte auf Weideflächen."
#| label: tbl-equal-tech-01
rbind(head(drone_tbl, n = 3),
rep("...", times = ncol(drone_tbl)),
tail(drone_tbl, n = 3)) |>
kable(align = "c", "pipe")
```
In unserem zweiten Datenbeispiel schauen wir uns die Keimungsdaten nach Behandlung mit sechs biologischen Pilzmittel unter zwei Kältebehandlungen aus der Datei `cold_seeds.xlsx` an. Dabei ist wichtig zu wissen, dass es eine Kontrolle gibt, die das chemische Standardpräparat repräsentiert. Wir wollen jetzt wissen, ob unsere biologischen Alternativen *gleich* gut sind. Das heißt, wir wollen nicht mehr oder weniger als das Standardpräparat sondern gleichviel. Als Outcome zählen wir die Sporen auf den jungen Keimlingen. Da unsere Pflanze auch eine Kältebehandlung überstehen würde, haben wir auch noch die beiden Kältevarianten mit untersucht. In der @tbl-noninf-01 sind die Daten einmal dargestellt.
```{r}
#| message: false
#| echo: false
cold_seed_raw_tbl <- read_excel("data/cold_seeds.xlsx") |>
mutate_if(is.numeric, round, 2)
cold_seed_tbl <- cold_seed_raw_tbl
```
```{r}
#| message: false
#| echo: false
#| tbl-cap: "Nicht transformierter Datensatz zu dem Keimungsexperiment mit biologischen Pilzpräparaten."
#| label: tbl-noninf-01
rbind(head(cold_seed_raw_tbl, n = 6),
rep("...", times = ncol(cold_seed_raw_tbl)),
tail(cold_seed_raw_tbl, n = 6)) |>
kable(align = "c", "pipe")
```
Wir müssen jetzt leider nochmal ran und die Daten etwas aufräumen. Zum einen muss die erste Behandlung raus, hier handelt es sich nur um eine positive Kontrolle, ob überhaupt etwas gewachsen ist. Dann wollen wir uns die Daten auch log-transformieren. Das hat den Grund, dass die statistischen Verfahren in der Äquivalenzanalyse eine Normalverteilung verlangen. Mit der log-Transformation erreichen wir log-normalverteilte Daten, die einer Normalverteilung recht nahe kommen. Am Ende wollen wir dann auch die zweite Behandlung so benennen, dass wir auch immer die Kontrolle erkennen.
```{r}
cold_seed_tbl <- cold_seed_tbl |>
clean_names() |>
filter(trt != 1) |>
mutate(trt = as_factor(trt),
log_cold = log(cold),
log_non_cold = log(non_cold),
trt = fct_recode(trt, ctrl = "2"))
```
Es ergibt sich dann die @tbl-noninf-02. Wir werden dann in der folgenden Analyse nur noch die log-transformierten Spalten `log_cold` und `log_non_cold` nutzen.
```{r}
#| message: false
#| echo: false
#| tbl-cap: "Transformierter Datensatz zu dem Keimungsexperiment mit biologischen Pilzpräparaten."
#| label: tbl-noninf-02
cold_seed_tab_tbl <- cold_seed_tbl |>
mutate(trt = as.character(trt)) |>
mutate_if(is.numeric, round, 2)
rbind(head(cold_seed_tab_tbl, n = 4),
rep("...", times = ncol(cold_seed_tab_tbl)),
tail(cold_seed_tab_tbl, n = 4)) |>
kable(align = "c", "pipe")
```
## Technische Gleichheit
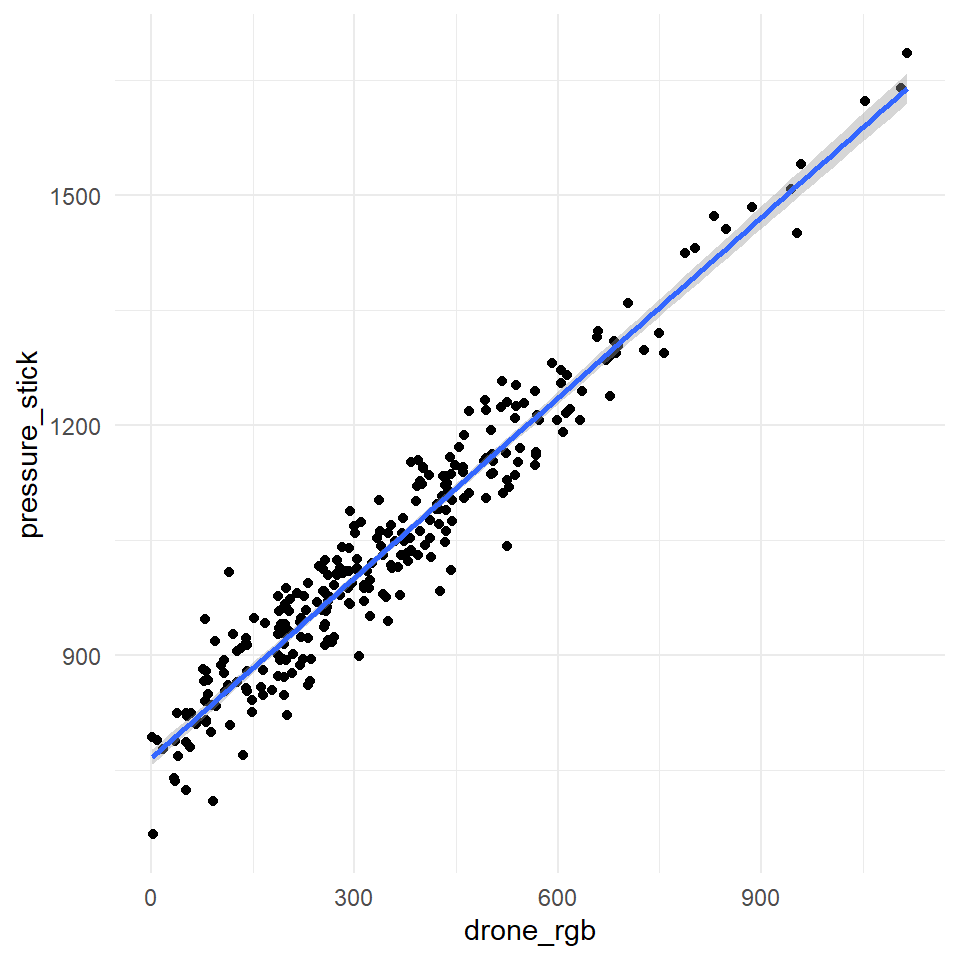
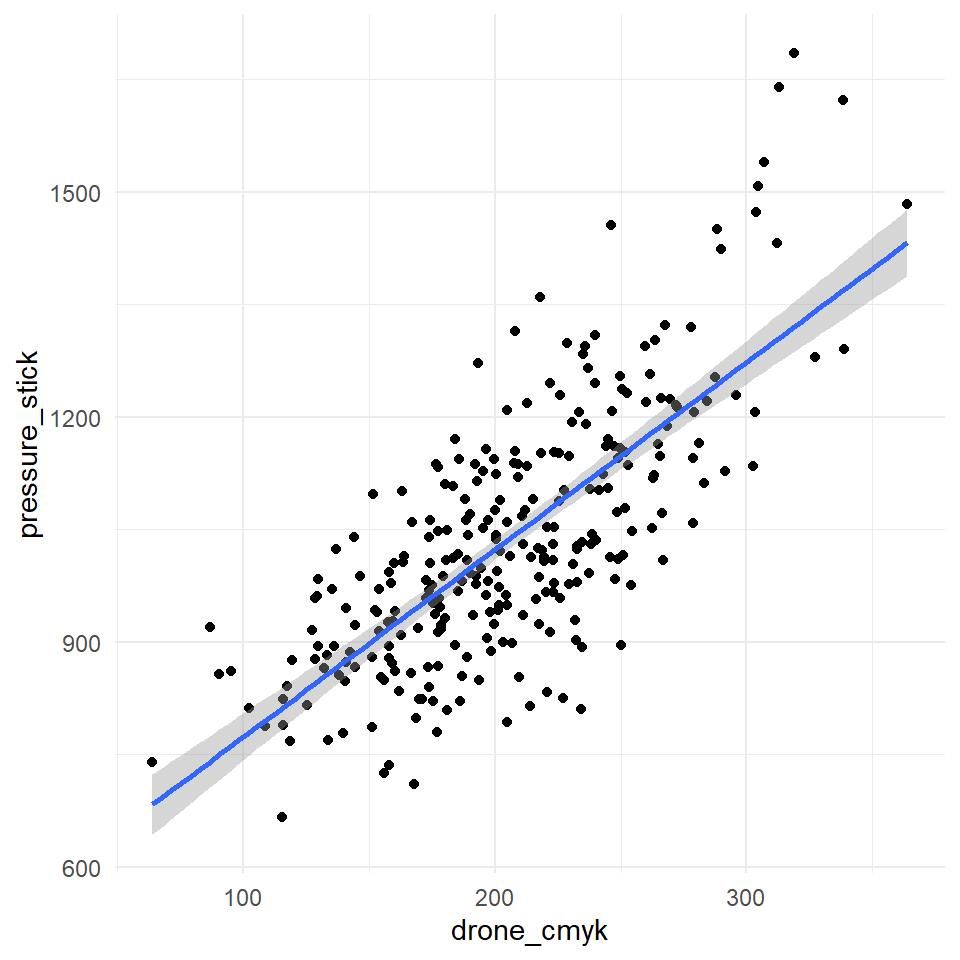
Beginnen wir also mit der Beurteilung von der technischen Gleichheit zweier Verfahren. Ich nutze hier das Wort *technische* Gleichheit, da wir hier nicht zwei Gruppen miteinander vergleichen, sondern eben kontinuierlich gemessene Werte haben und wissen wollen, ob diese gemessenen Werte aus den beiden Verfahren gleich sind. In unserem Beispiel wollen wir wissen, ob wir den Druckstab zum Messen der Grasdichte durch einen Drohnenüberflug erstetzen können. Der Dronenflug produziert Bilder und wir können auf zwei Arten Zahlen aus den Bildern generieren. Wir extrahieren entweder die RGB-Werte der Bilder oder aber die CMYK-Werte. Hier ist natürlich ein Schritt den ich überspringe, wir erhalten am Ende eben einen Wert für ein Bild. Oder andersherum, wir können genau einer Messung mit dem Druckstab ein Bild der Drone zuordnen.
In der @fig-equal-tech-01-1 und in der @fig-equal-tech-01-2 sehen wir den Zusammenhang zwischen dem Druckstab und der Dronenmessung für beide Farbskalenwerte nochmal visualisiert. In einer *idealen* Welt würden alle Punkte auf einer Linie liegen. Das heißt, wir haben einen perfekten Zusammenhang zwischen dem Druckstab und den Farbskalenwerten. So ein perfekter Zusammenhang tritt in der Natur nie auf, deshalb müssen wir uns nun mit statistischen Maßzahlen behelfen.
Wir können die Funktion `geom_smooth()` nutzen um eine lineare Funktion durch die Punkte zu legen. Wir sehen ist der Fehler, dargestellt als grauer Bereich, bei den CMYK-Werten größer. Auch haben wir Punkte die etwas nach oben weg streben. In der RGB-Skala haben wir eher einen linearen Zusammenhang. Im Folgenden wollen wir uns dann einmal die statistischen Maßzahlen zu der Visualisierung anschauen.
```{r}
#| echo: true
#| message: false
#| warning: false
#| label: fig-equal-tech-01
#| fig-align: center
#| fig-height: 5
#| fig-width: 5
#| fig-cap: "Vergleich der beiden Farbskalen aus der Dronenmessung zu der Grasdichte durch den Druckstab."
#| fig-subcap:
#| - "Dronenmessung mit RGB-Werten."
#| - "Dronenmessung mit CMYK-Werten."
#| layout-nrow: 1
ggplot(drone_tbl, aes(drone_rgb, pressure_stick)) +
theme_minimal() +
geom_point() +
geom_smooth(method = "lm", se = TRUE)
ggplot(drone_tbl, aes(drone_cmyk, pressure_stick)) +
theme_minimal() +
geom_point() +
geom_smooth(method = "lm", se = TRUE)
```
### Bestimmtheitsmaß $R^2$
Für die genaueren Werte der linearen Funktion nutzen wir dann die Funktion `lm()`. Wir brauchen die statistischen Maßzahlen höchstens, wenn uns eine Umrechung von den Werten von der einen Messung zu der anderen Messung interessiert.
```{r}
#| message: false
#| warning: false
fit_drone <- lm(pressure_stick ~ drone_rgb, data = drone_tbl)
fit_drone |> model_parameters()
```
Zum einen können wir uns jetzt auch die lineare Funktion und damit den Zusammenhang von dem Druckstab zu der RGB-Farbskala erstellen. Mir der folgenden Formel können wir dann die Werte der Dronen RGB-Farbskala in die Werte des Druckstabes umrechnen.
$$
pressure\_stick = 766.33 + 0.78 \cdot drone\_rgb
$$
Zum anderen erhalten wir mit der Funktion `lm()` dann auch die Möglichkeit das Bestimmtheitsmaß $R^2$ zu berechnen. Du kennst das Bestimmtheitsmaß $R^2$ schon aus dem Kapitel für die Qualität einer linearen Regression. Hier nochmal kurz zusammengefasst, das Bestimmtheitsmaß $R^2$ beschreibt, wie gut die Punkte auf der Geraden liegen. Ein Bestimmtheitsmaß $R^2$ von 1 bedeutet, dass die Punkte perfekt auf der Geraden liegen. Ein Bestimmtheitsmaß $R^2$ von 0, dass die Punkte eher wild um eine potenzielle Graden liegen.
Im Folgenden können wir uns noch einmal die Formel des Bestimmtheitsmaß $R^2$ anschauen um etwas besser zu verstehen, wie die Zusammenhänge mathematisch sind. Zum einen brauchen wir den Mittelwert von $y$ als $\bar{y}$ sowie die Werte der einzelnen Punkte $\bar{y}$ und die Werte auf der Geraden mit $\hat{y}_i$.
$$
\mathit{R}^2 =
\cfrac{\sum_{i=1}^N \left(\hat{y}_i- \bar{y}\right)^2}{\sum_{i=1}^N \left(y_i - \bar{y}\right)^2}
$$
In der @fig-bestimmtheit-tech-01 sehen wir den Zusammenhang nochmal visualisiert. Wenn die Abstände von dem Mittelwert zu den einzelnen Punkten mit $y_i - \bar{y}$ gleich dem Abstand der Mittelwerte zu den Punkten *auf* der Geraden mit $\hat{y}_i- \bar{y}$ ist, dann haben wir einen perfekten Zusammenhang.
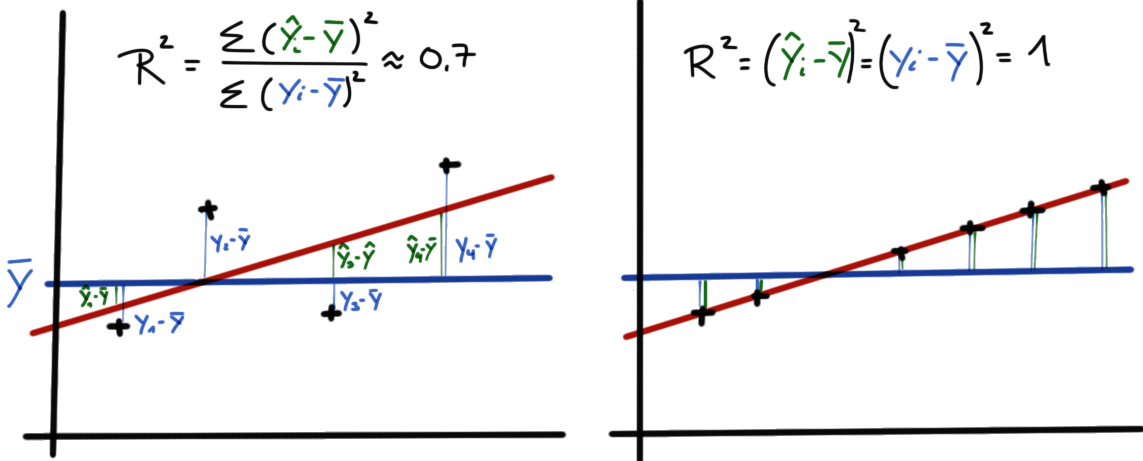{#fig-bestimmtheit-tech-01 fig-align="center"}
Wir können die Funktion `glance()` nutzen um uns das `r.squared` und das `adj.r.squared` wiedergeben zu lassen.
```{r}
#| message: false
fit_drone |>
glance() |>
select(r.squared)
```
Wir haben wir ein $R^2$ von $0.932$ vorliegen. Damit erklärt unser Modell bzw. die Gerade 93.2% der Varianz. Der Anteil der erklärten Varianz ist auch wunderbar hoch, so dass wir davon ausgehen können, dass der Druckstab und die RGB-Werte der Drone ungefähr das Gleiche wiedergeben.
### Korrelation
Neben der Information wie gut die Punkte auf der Geraden liegen, also wie die Punkte um die Gerade streuen, können wir uns auch die Korrelation und damit die Steigung der Gerade wiedergeben lassen. Das Bestimmtheitsmaß $R^2$ sagt uns nämlich nichts über die Richtung der Geraden aus. Die Korrelation liefert uns die Steigung der Geraden mit dem Vorzeichen.
Wir können hier verschiedene Korrelationsmaße berechnen. Am häufigsten werden wir die Korrelation nach Pearson berechnen, da wir von einem normalverteilten $y$ ausgehen. Wenn dies nicht der Fall sein sollte empfiehlt sich stattdessen den Korrelationkoeffizienten nach Spearman zu nutzen.
```{r}
drone_tbl %$%
cor(pressure_stick, drone_rgb, method = "pearson") |>
round(2)
drone_tbl %$%
cor(pressure_stick, drone_rgb, method = "spearman") |>
round(2)
```
::: column-margin
Wir nutzen hier den `%$%`-Operator, da wir in die Funktion `cor()` die Spalten übergeben wollen. Die Funktion `cor()` ist relativ alt und möchte daher keinen Datensatz sondern zwei Vektoren.
:::
Nachdem wir die Korrelation berechnet haben, sehen wir das wir einen *positiven* Zusammenhang vorliegen haben. Die Gerade durch die Punkte steigt an und ist fast eine 45$^{\circ}$ Gerade, da wir eine Korrelation nahe 1 vorliegen haben.
### MSE, RMSE, nRMSE und MAE
Neben der Betrachtung der Abweichung vom Mittelwert von $y$ können wir uns auch die Abstände von den geschätzten Punkten *auf* der Geraden $\hat{y}_i$ zu den eigentlichen Punkten anschauen $y_i$. Wir haben jetzt zwei Möglichkeiten die Abstände zu definieren.
1. Wir schauen uns die quadratischen Abstände mit $(y_i - \hat{y}_i)^2$ an. Wir berechnen dann die mittlere quadratische Abweichung (eng. *mean square error* abk. *MSE*).
2. Wir schauen uns die absoluten Abstände mit $|y_i - \hat{y}_i|$ an. Wir berechnen dann den mittleren absoluten Fehler (eng. *mean absolute error*, abk. *MAE*).
Im Folgenden betrachten wir erst den MSE und seine Verwandten. Wie wir an der Formel sehen, berechnen wir für den MSE einfach nur die quadratische Abweichung zwischen den Beobachtungen $y_i$ und den Werten auf der berechneten Geraden $\hat{y}_i$. Dann summieren wir alles auf und teilen noch durch die Anzahl der Beobachtungen also Punkte $n$.
$$
MSE = \cfrac{1}{n}\sum^n_{i=1}(y_i - \hat{y}_i)^2
$$
Häufig wollen wir dann nicht die *quadratischen* Abweichungen angeben. Wir hätten dann ja auch die Einheit der Abweichung im Quadrat. Daher ziehen wir die Wurzel aus dem MSE und erhalten den *root mean square error* (abk. *RMSE*). Hierfür gibt es dann keine gute Übersetzung ins Deutsche.
$$
RMSE = \sqrt{MSE} = \sqrt{\cfrac{1}{n}\sum^n_{i=1}(y_i - \hat{y}_i)^2}
$$
Der RMSE ist ein gewichtetes Maß für die Modellgenauigkeit, das auf der gleichen Skala wie das Vorhersageziel angegeben wird. Einfach ausgedrückt kann der RMSE als der durchschnittliche Fehler interpretiert werden, den die Vorhersagen des Modells im Vergleich zum tatsächlichen Wert aufweisen, wobei größere Vorhersagefehler zusätzlich gewichtet werden.
Je näher der RMSE-Wert bei 0 liegt, desto genauer ist das Modell. Der RMSE-Wert wird auf derselben Skala zurückgegeben wie die Werte, für das du Vorhersagen treffen willst. Es gibt jedoch keine allgemeine Regel für die Interpretation von den Wertebereichen des RMSE. Die Interpretation des RMSE kann nur innerhalb deines Datensatzes bewertet werden.
```{r}
drone_tbl |>
rmse(pressure_stick, drone_rgb)
```
Als letzte Möglichkeit sei noch der normalisierte *root mean square error* (abk. *nRMSE*) genannt. In diesem Fall wird der RMSE nochmal durch den Mittelwert von $y$ geteilt.
$$
nRMSE = \cfrac{RMSE}{\bar{y}} = \cfrac{\sqrt{MSE}}{\bar{y}} = \cfrac{\sqrt{\cfrac{1}{N}\sum^N_{i=1}(y_i - \hat{y}_i)^2}}{\bar{y}}
$$
In wie weit jetzt jedes MSE Abweichungsmaß sinnvoll ist und auch in der Anwendung passen mag, sei einmal dahingestellt. Wichtig ist hier zu Wissen, dass wir die MSE-Fehler nutzen um verschiedene Verfahren zu vergleichen. Ein kleiner Fehler ist immer besser. Ein einzelner MSE-Wert an sich, ist dann immer schwer zu interpretieren.
Als Alternative zu den MSE-Fehlern bietet sich dann der MAE an. Hier schauen wir dann auf die *absoluten* Abstände. Wir nehmen also das Vorzeichen raus, damit sich die Abstände nicht zu 0 aufaddieren. Wir haben dann folgende Formel vorliegen.
$$
MAE = \cfrac{1}{n}\sum^n_{i=1}|y_i - \hat{y}_i|
$$
Der MAE hat gegenüber dem RMSE Vorteile in der Interpretierbarkeit. Der MAE ist der Durchschnitt der absoluten Werte der Fehler. MAE ist grundsätzlich leichter zu verstehen als die Quadratwurzel aus dem Durchschnitt der quadrierten Fehler. Außerdem beeinflusst jede einzelne Abweichung den MAE in direktem Verhältnis zum absoluten Wert der Abweichung, was bei der RMSE nicht der Fall ist. Der MAE ist nicht identisch mit dem mittleren quadratischen Fehler (RMSE), auch wenn einige Forscher ihn so angeben und interpretieren. MAE ist konzeptionell einfacher und auch leichter zu interpretieren als RMSE: Es ist einfach der durchschnittliche absolute vertikale oder horizontale Abstand zwischen jedem Punkt in einem Streudiagramm und der Geraden.
```{r}
drone_tbl |>
mae(pressure_stick, drone_rgb)
```
Wir können uns mit der Funktion `metrics()` auch die Fehler zusammenausgeben lassen.
```{r}
drone_tbl |>
metrics(pressure_stick, drone_rgb)
```
Wie schon oben geschrieben, der MSE und Co. sind nur in einem Vergleich sinnvoll. Deshalb hier nochmal der Vergleich der beiden Farbskalen der Dronenbilder.
```{r}
drone_tbl |>
metrics(pressure_stick, drone_rgb)
drone_tbl |>
metrics(pressure_stick, drone_cmyk)
```
Wir schon zu erwarten ist auch hier der Fehler bei den RGB-Werten kleiner als bei den CMYK-Werten. Daher würden wir uns hier für die Umrechnung der RGB-Werte entscheiden.
## Medizinische- oder Behandlungsgleichheit
::: callout-important
## Disclaimer - Wichtig! Lesen!
Der folgende Text ist ein *Lehr*text für Studierende. Es handelt sich keinesfalls um eine textliche Beratung für Ethikanträge oder Tierversuchsanträge geschweige den der Auswertung einer klinischen Studie. Alle Beispiel sind im Zweifel an den Haaren herbeigezogen und dienen nur der Veranschaulichung *möglicher* Sachverhalte.
Antragsteller:innen ist die statistische Beratung von einer entsprechenden Institution dringlichst angeraten.
:::
Wir eingangs schon geschrieben wollen wir bei der *Medizinische- oder Behandlungsgleichheit* nachweisen, dass sich verschiedene Behandlungs*gruppen* zu *einer* Kontrolle oder Standard *gleich* oder äquivalent sind. Wir haben es hier als mit einem klassischen Gruppenvergleich zu tun, bei dem wir die Hypothesen drehen. Wenn wir auf Unterschied testen, dann haben wir in der Nullhypothese $H_0$ die Gleichheit zwischen zwei Mittelwerten stehen. Wir wollen die Gleichheit der Mittelwerte ablehnen. Wir schreiben also unsere beiden Hypothesenpaare wie folgt.
::: column-margin
Wie immer gibt es auch tolle Tutorien wie das Tutorium von Daniël Lakens [Equivalence Testing and Interval Hypotheses](https://lakens.github.io/statistical_inferences/09-equivalencetest.html)
:::
Statistischer Test auf Unterschied
: $$
\begin{aligned}
H_0: \bar{y}_{1} &= \bar{y}_{2} \\
H_A: \bar{y}_{1} &\neq \bar{y}_{2} \\
\end{aligned}
$$
Wenn wir jetzt einen statistischen Teste für die Äquivalenz oder Nichtunterlegenheit rechnen wollen, dann drehen wir das Hypothesenpaar. Wir wollen jetzt in der Nullhypothese die "Ungleichheit" der Mittelwerte ablehnen.
Statistischer Test auf Gleichheit
: $$
\begin{aligned}
H_0: \bar{y}_{1} &\neq \bar{y}_{2} \\
H_A: \bar{y}_{1} &= \bar{y}_{2} \\
\end{aligned}
$$
Und hier beginnt auch schon die Krux. Konnten wir uns relativ einfach einigen, dass ein Mittelwertesunterschied $\Delta$ von 0 eine Gleichheit zwischen den beiden Mittelwerten der beiden Gruppen bedeutet, so ist die Festlegung auf einen Unterschied schon schwieriger. Die Bewertung, ob zwei Mittelwerte sich für zwei Gruppen unterscheiden, kann nur im Kontext der biologischen oder medizinischen Fragestellung beantwortet werden. Die Diskussion, ob ein $\Delta$ von 0.1 noch gleich oder ungleich ist, kann rein numerisch schwer geführt werden. Deshalb gibt es einige Richtlinien und Richtwerte.
Aus dem Grund definieren wir Äquivalenzgrenzen oder Äquivalenzzone. Die Äquivalenzzone wird durch eine untere Äquivalenzgrenze und/oder eine obere Äquivalenzgrenze definiert. Die untere Äquivalenzgrenze (UEG) definiert deine untere Grenze der Akzeptanz für die Mittelwertsdifferenz. Die obere Äquivalenzgrenze (UEL) definiert die obere Grenze der Akzeptanz für die Mittelwertsdifferenz. Jede Abweichung von der Mittelwertsdifferenz, die innerhalb dieses Bereichs der Äquivalenzgrenzen liegt, wird als unbedeutend angesehen. Du kannst hier statt Mittelwertsdifferenz natürlich auch in Anteilen denken, wenn es um das Odds ratio oder Risk ratio geht.
Als erstes Beispiel einer Behörde hier einmal das Zitat der Europäische Behörde für Lebensmittelsicherheit (EFSA) für die Zulassung eines Pilzmittels aus unseren Beispiel. Hier sei angemerkt, dass viele statistische Methoden von einem normalverteilten Outcome oder aber approximativ log-normalverteilten Outcome ausgehen. Deshalb werden die Äquivalenzgrenzen hier auch auf der $log$-Skala benannt.
> "The limits for equivalence were set to $-\cfrac{1}{2}\log$ and $\cfrac{1}{2}\log$ equal to -0.5 and 0.5 because of the log transformation of the outcome." --- [Europäische Behörde für Lebensmittelsicherheit (EFSA)](https://www.efsa.europa.eu/de)
Häufig werden die Effekte aus verschiedenen Studien auch skaliert, damit wir dann die Effekte besser vergleichen können. Als Skalierung bietet sich eine Normalisierung oder Standardisierung an. Als Beispiel in den Pflanzenwissenschaften sei @van2019equivalence genannt. @van2019equivalence führen Analysen zum Schutz vor unbeabsichtigten Auswirkungen von gentechnisch verändertem Mais auf die Umwelt oder die menschliche Gesundheit durch \[[Link](https://www.sciencedirect.com/science/article/pii/S0278691519300572)\]. Hier hilft besonders sich von anderen Studien *vor* dem Experiment zu inspirieren zu lassen. Um eine ausgiebige Literaturrecherche kommt man dann meist nicht rum.
Auch sei noch das Institut für Qualität und Wirtschaftlichkeit im Gesundheitswesen (IQWiG) erwähnt, welches für die Regulierung von Anwendungen in der Humanmedizin zu tun hat. Da sind ja die Grenzen immer etwas fließend. Wann ist ein Medikament *nur* für die Agrarwissenschaften relevant und hate keine Auswirkungen auf den Menschen? Diese Frage lasse ich hier offen. Hier hilft aber auch der Blick in das Papier *Allgemeine Methoden* und dann das Kapitel 9. Hier einmal ein Zitat aus dem Abschnitt zu dem Nachweis zur Gleichheit. Wir sehen. so einfach ist die Sachlage nicht.
> "Umgekehrt erfordert auch die Interpretation nicht statistisch signifikanter Ergebnisse Aufmerksamkeit. Insbesondere wird ein solches Ergebnis nicht als Nachweis für das Nichtvorhandensein eines Effekts (Abwesenheit bzw. Äquivalenz) gewertet." --- Kapitel 9.3.5 Nachweis der Gleichheit in [Allgemeine Methoden des Institut für Qualität und Wirtschaftlichkeit im Gesundheitswesen (IQWiG)](https://www.iqwig.de/ueber-uns/methoden/methodenpapier/)
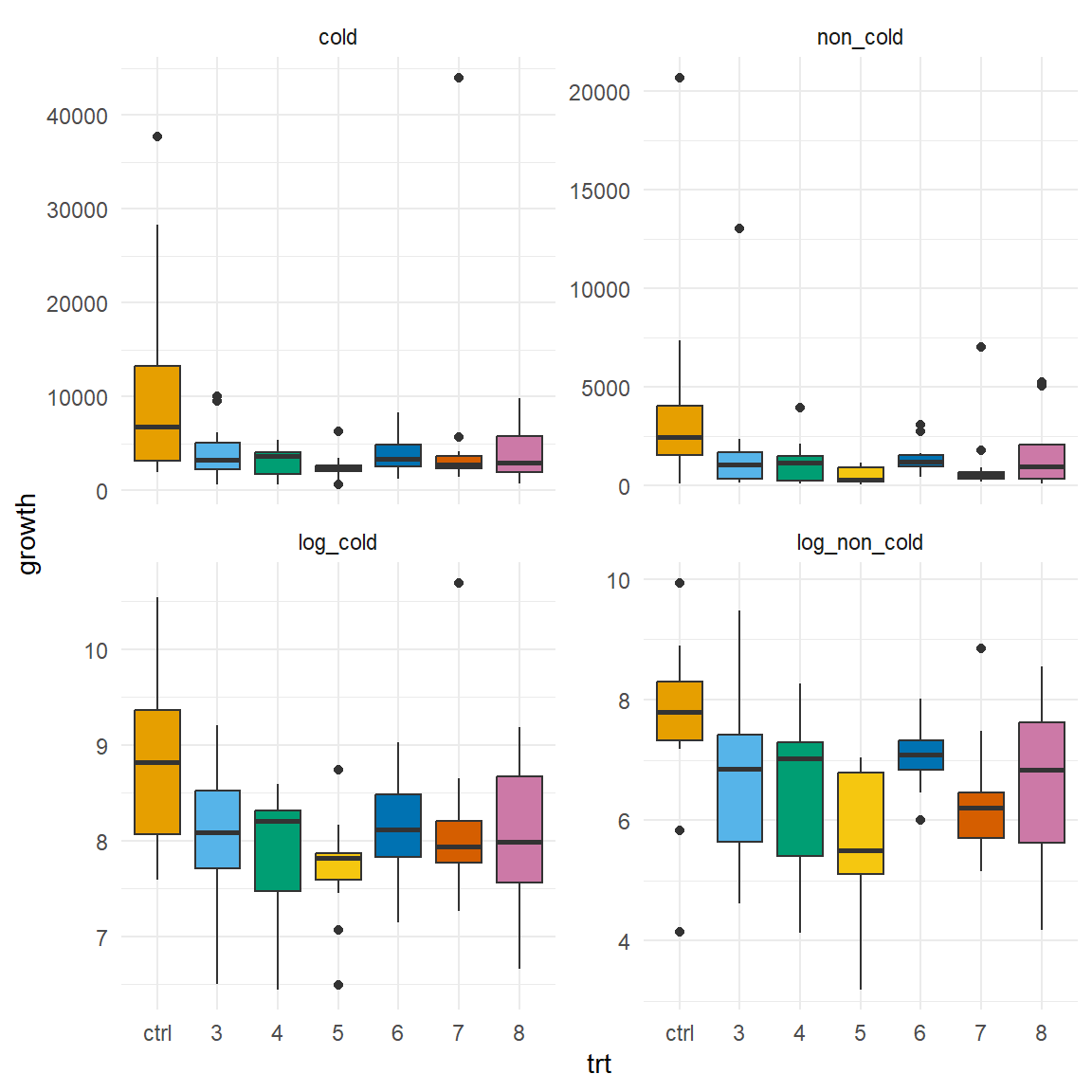
Schauen wir uns nun nochmal unsere Keimungsdaten nach Behandlung mit sechs biologischen Pilzmittel unter zwei Kältebehandlungen an. Wenn wir den Richtlinien der EFSA folgen, dann rechnen wir auf den $\log$-transformierten Daten. Die $\log$-transformierten Daten sind damit auch approximativ normalverteilt, so dass wir hier dann alle statistischen Methoden nutzen können, die eine Normalverteilung voraussetzen. In der @fig-noninf-1 sehen wir, dass die $\log$-transformierten Daten eindeutig mehr einer Normalverteilung folgen.
```{r}
#| echo: true
#| message: false
#| warning: false
#| label: fig-noninf-1
#| fig-align: center
#| fig-height: 6
#| fig-width: 6
#| fig-cap: "Boxplots der Wachstumsraten des Pilzes in der Standardkontrolle sowie den sechs neunen Präparaten. Die oberen Abbildungen sind auf der normalen Datenskala, die unteren Abbildungen sind $\\log$-transformiert."
cold_seed_tbl |>
pivot_longer(cold:last_col(),
names_to = "type",
values_to = "growth") |>
mutate(type = as_factor(type)) |>
ggplot(aes(trt, growth, fill = trt)) +
theme_minimal() +
geom_boxplot() +
facet_wrap(~ type, scales = "free_y") +
scale_fill_okabeito() +
theme(legend.position = "none")
```
Im Folgenden gehen wir jetzt von einfach nach kompliziert. Daher schauen wir uns erstmal die einfachste statistische Methode an, die wir nutzen können und werden dann inhaltlich komplizierter.
### ANOVA mit Effektschätzer
Als erstes *missbrauchen* wir die ANOVA für den Nachweis der Gleichheit. Das ist die Schlechteste der denkbaren Möglichkeiten aber im Rahmen einer Bachelorarbeit oder aber um sich einen ersten Überblick zu verschaffen sinnvoll. Warum ist die die ANOVA so schlecht? Wir testen hier weiterhin die Nullhypothese auf Gleichheit. Wenn wir also einen signifikante ANOVA vorfinden, dann würden wir die Nullhypothese der Gleichheit ablehnen und auf einen Mittelwertsunterschied schließen. Wie wir schon vorab gelernt haben, ist eine *nicht* signifikante ANOVA kein schlüssiger Beweis für die Gültigkeit der Nullhypothese der Gleichheit. Wir arbeiten mit dem Falsifikationsprinzip, wir können nur Hypothesen ablehnen. Eine abgelehnte Hypothese bedeutet aber nicht im Umkehrschluss, dass die Gegenhypothese wahr ist. Daher nutzen wir hier die ANOVA als einen Art Seismographen. Eine signifikante ANOVA deutet auf einen Unterschied in den Mittelwerten hin, dann ist es vermutlich unwahrscheinlich, dass wir Gleichheit vorliegen haben.
Schauen wir uns dazu einmal die zwei einfaktoriellen ANOVA's für die kälte und nicht-kälte Behandlung einmal an. Als erstes rechnen wir eine einfacktorielle ANOVA und schauen, ob wir ein signifkantes Eregbnis vorliegen haben.
```{r}
#| message: false
lm_non_cold_fit <- lm(log_non_cold ~ trt, data = cold_seed_tbl)
lm_non_cold_fit |> anova() |> model_parameters()
```
Da der $p$- Wert kleiner ist als das Signifikanzniveau $\alpha$ müssen wir die Nullhypothese der Gleichheit ablehnen. Mindestens einen paarweisen Unterschied zwischen den Gruppen gibt es. Prinzipiell könnten wir natürlich hoffen, dass alle Gruppen gleich zur Kontrolle sind und sich nur zwei Behandlungsgruppen unterscheiden, aber es ist schonmal ein schlechtes Zeichen, wenn wir eine signifikante ANOVA vorliegen haben und auf Gleichheit der Behandlungen zur Kontrolle aus sind.
Schauen wir nochmal auf den Effekt. Wenn wir einen großen Effekt der Behandlungsgruppen vorliegen haben, dann deutet dies auch nicht gerade auf gleiche Gruppenunterschiede.
```{r}
#| message: false
lm_non_cold_fit |> eta_squared()
```
Wir sehen, dass wir nur 18% der Varianz durch unsere Behandlungsgruppen erklären. Daher würden wir hier nicht von einem großen Effekt ausgehen. Würde auch hier viel Varianz erklärt, dann könnten wir hier auch aufhören. Schauen wir uns nochmal die andere Art der Vorbehandlung an.
Jetzt schauen wir nochmal wo die paarweisen Unterschiede sind. Wir nutzen dazu den `pairwise.t.test()`. Darüber hinaus haben wir bei den nicht-kälte behandelten Samen eine stark unterschiedliche Streuung der einzelnen Beobachtungen in den Gruppen. Durch die unterschiedlichen Varianzen in den Gruppen setzten wir `pool.sd = FALSE` und nehmen hier Varianzheterogenität an. Dann schauen wir uns einmal das *compact letter display* an und sehen, welche Behandlungen sich voneinander unterscheiden oder nicht.
```{r}
#| message: false
cold_seed_tbl %$%
pairwise.t.test(log_non_cold, trt, pool.sd = FALSE,
p.adjust.method = "none") |>
extract2("p.value") |>
fullPTable() |>
multcompLetters()
```
Wir sehen, dass wir Unterschiede haben. Da wir hier nur zur Kontrolle vergleichen wollen, schauen wir nach dem Buchstaben der Kontrolle und sehen, dass wir hier den *letter* `a`haben. Wir interpretieren das *compact letter display* nun etwas statistisch schief in dem Sinne, das gleiche Buchstaben Gleichheit aussagen. Immerhin unterscheiden sich die Behandlungen 3, 4, 6 und 8 nicht von der Kontrolle.
Den gleichen Ablauf können wir jetzt auch einmal für die kälte-behandleten Samen machen. Wir rechnen wieder als erstes eine einfaktorielle ANOVA und schauen, ob wir einen signifikanten Unterschied zwischen den Gruppen haben.
```{r}
#| message: false
lm_cold_fit <- lm(log_cold ~ trt, data = cold_seed_tbl)
lm_cold_fit |> anova() |> model_parameters()
```
Auch hier zeigt die signifikante ANOVA, dass wir mindestens einen paarweisen Mittelwertsunterschied zwischen den Behandlungsgruppen haben. Welche Gruppen sich nun unterscheiden werden wir dann gleich einmal in dem paarweisen t-Test uns anschauen. Vorher nochmal schauen wir nochmal wie stark der Effekt der Behandlungsgruppen ist.
```{r}
#| message: false
lm_cold_fit |> eta_squared()
```
Auch hier können wir 18% der Varianz in dem Wachstum durch die Behandlungsgruppen erklären. Das ist recht wenig. Schauen wir aber jetzt einmal den paarweisen t-Test an. Die Varianzen sind ungefähr gleich in den Gruppen, die Boxplots haben ungefähr die gleiche Ausdehnung nach der Logarithmierung. Deshalb nutzen wir hier einmal die Funktionalität von `{emmeans}`. Wir können bei der [Funktion `emeans()` eine Deltaschranke](https://cran.r-project.org/web/packages/emmeans/vignettes/re-engineering-clds.html#equiv-CLDs) einführen. Dann haben wir mit dem *compact letter display* ein Test auf Nichtunterlegenheit oder eben Gleichheit. Ich wähle hier mal eine Option von `delta = 1` in der Funktion `cld()` um einfach mal zu zeigen, wie es dann aussieht.
```{r}
#| message: false
lm_cold_fit |>
emmeans(~ trt) |>
cld(Letters = letters, adjust = "none", delta = 1) |>
arrange()
```
Hier unterscheiden sich nun alle Behandlungsgruppen von der Kontrolle. Die neuen Behandlungen unterscheiden sich aber untereinander nicht. Jetzt können wir uns noch anschauen, wie groß den der Mittelwertsunterschied für die einzelnen Behandlungen jeweils ist. Das kann uns die Funktion `pwpm()` wiedergeben.
```{r}
#| message: false
lm_cold_fit |>
emmeans(~ trt) |>
pwpm(adjust = "none")
```
Wir lesen `Lower triangle: Comparisons (estimate) earlier vs. later` und damit wird jeweils der `ctrl`- Mittelwert minus den Behandlungsmittelwerten in der ersten Spalte angegeben. Wir sehen, dass die Kontrolle immer ein größeres Wachstum hat. Damit haben wir zwar keine Gleichheit gezeigt, aber unsere Behandlungen haben alle *weniger* als die Kontrolle. Eventuell reicht das ja aus, wir haben zwar nicht gleich viel Wachstum wie die Kontrolle, aber durchgehend weniger.
Das war jetzt hier natürlich die Version für Arme bzw. wenn wir im Rahmen einer Abschlussarbeit noch zusätzlich was berechnen wollen. Wenn es etwas aufwendiger sein soll, dann gibt es natürlich auch richtige statistischen Methoden für den Äquivalenztest.
### Äquivalenztest
Wenn wir wirklich in unserem Experiment oder Studie einen Äquivalenztest gleich von Anfang an rechnen wollen, dann können wir auch in R auf ein weitreichendes Angebot an Paketen und Funktionen zurückgreifen. Wie immer ist die Frage, was wollen wir? Wichtig ist, dass wir immer eine Gruppe brauchen zu der wir die Äquivalenz oder Gleichheit bestimmen wollen. Im Weiteren haben wir die Wahl zwischen zwei Ansätzen. Einmal den frequentistischen Ansatz sowie die bayesianische Variante. Ich möchte hier nicht mehr so ins Detail gehen, wir nutzen den frequentistischen Ansatz. Das hat auch den Vorteil, dass wir die Äquivalenz an 95% Konfidenzintervallen überprüfen. Mehr gibt es dann jeweils auf den beiden Hilfeseiten der Funktionen.
- Einmal den frequentistischen Ansatz aus dem Paket `{parameters}` durch die Funktion [parameters::equivalence_test()](https://easystats.github.io/parameters/reference/equivalence_test.lm.html)
- Oder die bayesianische Variante aus dem R Paket `{bayestestR}` durch die Funktion [bayestestR::equivalence_test()](https://easystats.github.io/bayestestR/reference/equivalence_test.html)
Wichtig ist, dass wir immer zum ersten Level des Faktors der Behandlung vergleichen! Das heißt, deine Kontrollgruppe sollte immer die erste Gruppe sein und das erste Level haben. Du kannst sonst mit der Funktion `fct_relevel()` und `mutate()` die Level neu anordnen. Wir haben hier aber das Glück, dass wir die Kontrolle als erstes Level der Behandlung `trt` vorliegen haben.
Wie gehen wir nun vor? Die Funktion `equivalence_test()` berechnet 95% Konfidenzintervalle für die paarweisen Vergleiche von jeder Behandlung zur Kontrolle. Wir erhalten also sechs 95% Konfidenzintervalle. Im Weiteren müssen wir entscheiden wie groß der Bereich der Äquivalenzzone sein soll. Wir müssen also über die Option `range =` Grenzen definieren und lassen die Funktion `equivalence_test()` die Grenzen selbstständig berechnen. Ich empfehle immer die Grenzen aus der Litertaur zu nehmen. In unserem Fall sind es die $\log$-Grenzen aus der EFSA Regulierung mit -0.5 und 0.5, die setzen wir dann in die Option `range =` ein. Die `range` repräsentiert hierbei die *Region of Practical Equivalence (ROPE)* oder eben unsere Äquivalenzgrenzen.
```{r}
#| message: false
#| warning: false
res_non_cold <- parameters::equivalence_test(lm_non_cold_fit,
ci = 0.95,
range = c(-0.5, 0.5))
res_non_cold
```
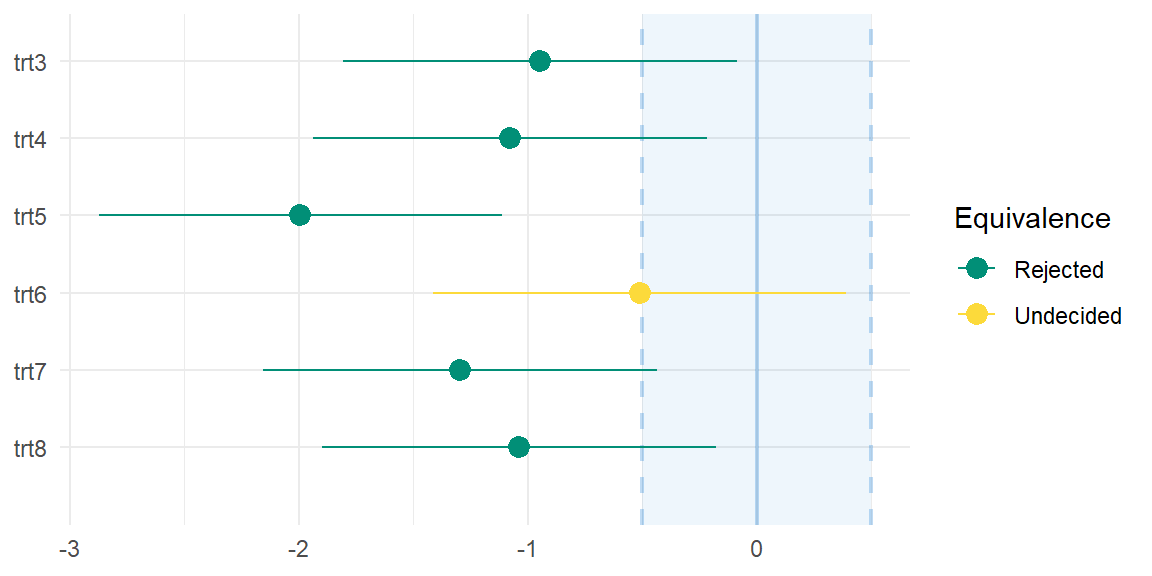
Wir sehen also einmal das Ergebnis unseres Äquivalenztest. Wichtig hierbei ist, dass wir zu der Kontrolle testen. Unsere Kontrolle steckt in dem `(Intercept)` und die Effekte aus der linearen Regression in `lm_non_cold_fit` beziehen sich ja alle auf den Intercept, so wird das Modell mit kategorialen Variablen gebaut. In der Spalte `% in ROPE` sehen wir in wie weit der Unterschied zwischen den Behandlungen, dargestellt als 95% Konfidenzintervall, in den Äquivalenzgrenzen liegt. In der folgenden Spalte `H0` dann die Entscheidung für oder gegen die die Nullhypothese im Sinne der Gleichheit. Gut, das ist etwas wirr, schauen wir uns einmal die @fig-noninf-2 an, dann wird es klarer.
```{r}
#| echo: true
#| message: false
#| warning: false
#| label: fig-noninf-2
#| fig-align: center
#| fig-height: 3
#| fig-width: 6
#| fig-cap: "Darstellung der zweiseitigen 95% Konfidenzintervalle für die Vergleiche der Behandlungen zu der Kontrolle. Liegt ein 95% Konfidenzintervall in den Äquivalenzgrenzen so kann die Nullhypothese und damit Gleichheit zur Kontrolle nicht abgelehnt werden."
plot(res_non_cold) +
theme_minimal()
```
Als Ergebnis können wir mitnehmen, dass keine der Behandlungen gleich zur Kontrolle ist. Die Behandlung 6 ist noch am nächsten dran, gleich zu sein, aber wir können hier anhand den Daten keine Entscheidung treffen. Am Ende unterscheiden sich alle Behandlungen von der Kontrolle.
Als anderes Beispiel schauen wir uns dann einmal noch die kälte Behandlung an. Hier sehen wir dann schon ein anderes Bild. Die Interpretation ist die gleiche wie eben schon. Wir wollen, dass die 95% Konfidenzintervalle in den Äquivalenzgrenzn von `ROPE: [-0.50 0.50]` liegen.
```{r}
#| message: false
#| warning: false
res_cold <- parameters::equivalence_test(lm_cold_fit,
ci = 0.95,
range = c(-0.5, 0.5))
res_cold
```
In der @fig-noninf-3 sehen wir den Zusammenhang nochmal visualisiert. Hier fällt nochmal deutlicher auf, dass alle Behandlungen geringere Wachstumszahlen aufweisen. Wir könnten also Gleichheit auch so definieren, dass weniger oder gleich auch als äquivalent gilt. Das hängt natürlich vom biologischen Kontext ab, aber wir machen das jetzt einfach mal.
```{r}
#| echo: true
#| message: false
#| warning: false
#| label: fig-noninf-3
#| fig-align: center
#| fig-height: 3
#| fig-width: 6
#| fig-cap: "Darstellung der zweiseitigen 95% Konfidenzintervalle für die Vergleiche der Behandlungen zu der Kontrolle. Liegt ein 95% Konfidenzintervall in den Äquivalenzgrenzen so kann die Nullhypothese und damit Gleichheit zur Kontrolle nicht abgelehnt werden."
plot(res_cold) +
theme_minimal()
```
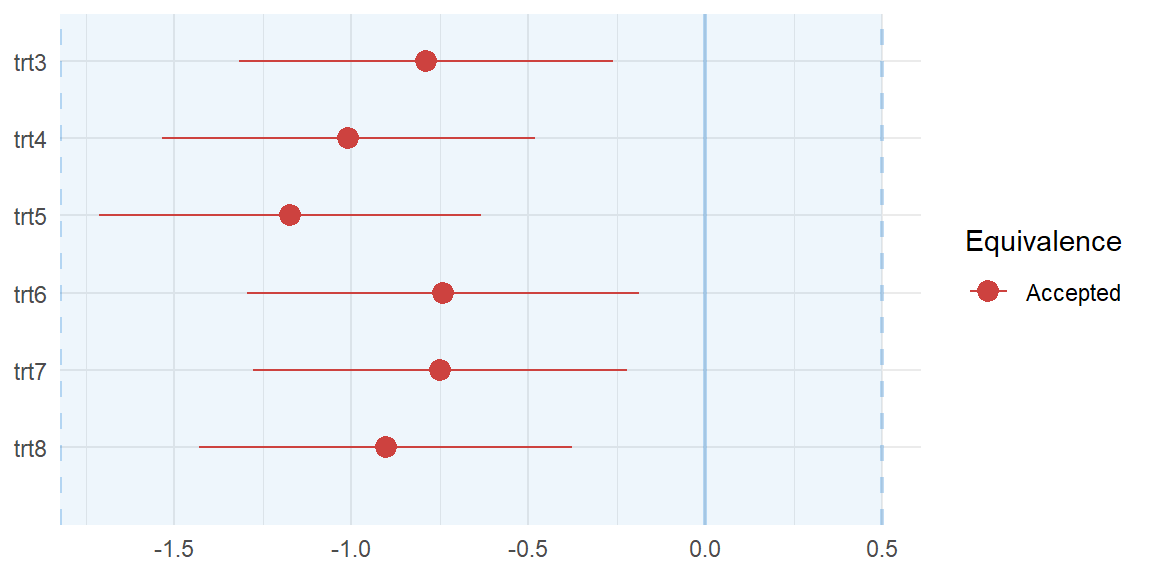
Wenn du keine untere oder obere Grenze möchtest, also eigentlich nur eine Grenze, dann kannst du die andere Grenze auf Unendlich `Inf` setzen. Wir setzen hier mal die untere Grenze der Äquivalenz auf `-Inf` und testen somit faktisch nur einseitig.
```{r}
#| message: false
#| warning: false
res_low_cold <- parameters::equivalence_test(lm_cold_fit,
ci = 0.95,
range = c(-Inf, 0.5))
res_low_cold
```
Wir sehen jetzt, dass sich alle 95% Konfidenzintervalle im ROPE-Bereich befinden. Damit sind dann auch alle Behandlungen gleich zur Kontrolle. Das gilt natürlich nur, da wir weniger als gleich definiert haben! Schauen wir nochmal in der @fig-noninf-4 uns die Visualisierung an.
```{r}
#| echo: true
#| message: false
#| warning: false
#| label: fig-noninf-4
#| fig-align: center
#| fig-height: 3
#| fig-width: 6
#| fig-cap: "Darstellung der einseitigen 95% Konfidenzintervalle für die Vergleiche der Behandlungen zu der Kontrolle. Liegt ein 95% Konfidenzintervall in den Äquivalenzgrenzen so kann die Nullhypothese und damit Gleichheit zur Kontrolle nicht abgelehnt werden. Hier wurde nur einseitig getestet, da weniger als die Kontrolle in dem biologischen Kontext auch als Äquivalenz zählt."
plot(res_low_cold) +
theme_minimal()
```
## Referenzen {.unnumbered}