```{r echo = FALSE}
pacman::p_load(tidyverse, readxl, knitr, kableExtra)
```
# Variablenselektion {#sec-variable-selection}
*Letzte Änderung am `r format(fs::file_info("stat-modeling-variable-selection.qmd")$modification_time, '%d. %B %Y um %H:%M:%S')`*
> *"Denn im Formulieren des Problems ist die Lösung schon enthalten!" --- Käptn Peng & Die Tentakel von Delphi, Meister und Idiot*
Die Selektion von Variablen in einem Modell. Ein schwieriges Thema. Entweder kenne ich mein Experiment und habe das Experiment so geplant, dass nur die bedeutenden Variablen mit in dem Experiment sind oder ich habe keine Ahnung. Gut, dass ist überspitzt und gemein formuliert. Wir wollen uns in diesem Kapitel den Fall anschauen, dass du sehr viele Variablen $x$ erhoben hast und nun *statistisch* bestimmen willst, welche Variablen nun mit in das finale Modell sollen. Achtung, ich spreche hier nicht von einem Blockdesign oder aber einem Feldexperiment. Da hat die Variablenselektion nichts zu suchen. Daher tritt der Fall der Variablenselektion eher in dem Feld Verhaltensbiologie oder aber auch Ökologie auf. Ebenfalls kann die Anwendung in automatisch erfassten Daten einen Sinn machen. Wir nutzen dann die Variablenselektion (eng. *feature selection*) zu Dimensionsreduktion des Datensatzes. Der Datensatz soll damit einfacher sein... ob der Datensatz das damit auch wird, ist wieder eine andere Frage.
::: {layout="[15,85]" layout-valign="top"}
{fig-align="center" width="100%"}
> In diesem Kapitel prügeln wir aber einen statistischen Engel. Wir werden hier mal schauen müssen, was alles geht und was nicht. Variablen Selektion ist faktisch nicht *ein* Kapitel sondern ein Regal(kilo)meter voll mit Büchern.
:::
Zu der Frage welches Verfahren denn nun das richtige Verfahren zur Selektion von Variablen ist, gibt es die Standardantwort in der Statistik: *Es kommt auf die Fragestellung an...*. Oder aber was ist wie gut implementiert, dass wir das Verfahren einigermaßen gut nutzen können. Wir gehen daher von einfach zu kompliziert und du musst dann schauen, was du nutzen willst und kannst. Wir müssen zum Beispiel unterscheiden, welcher Verteilung das Outcome $y$ folgt. Wenn wir ein normalverteiltes $y$ haben, dann haben wir andere Möglichkeiten, als wenn wir uns ein poissonverteiltes oder binominalverteiltes $y$ anschauen.
::: column-margin
Das [R Paket `{olsrr}`](https://olsrr.rsquaredacademy.com/articles/variable_selection.html) erlaubt eine weitreichende Variablen Selektion, wenn ein normalverteiltes Outcome $y$ vorliegt.
:::
Im Folgenden will ich *kurz* die fünf Mythen der Variablenselektion von @heinze2017five zusammenfassen. Wie immer ersetzt meine deutsche Zusammenfassung und Auswahl nicht das eigenständige Lesen der *englischen* Orgnialquelle, wenn du die Informationen in deiner Abschlussarbeit zitieren willst.
1) **Die Anzahl der Variablen in einem Modell sollte reduziert werden, bis es 10 Ereignisse pro Variable gibt.** Simulationsstudien haben gezeigt, dass multivariable Modelle bei zu niedrigen Verhältnissen von Ereignissen bzw. Beobachtungen pro Variable (eng *events per variable*, abk. *EPV*) sehr instabil werden. Aktuelle Empfehlungen besagen, dass je nach Kontext mindestens 5-15 EPV verfügbar sein sollten. Wahrscheinlich sind sogar viel höhere Werte wie 50 EPV erforderlich, um annähernd stabile Ergebnisse zu erzielen.
2) **Nur Variablen mit nachgewiesener Signifikanz des univariaten Modells sollten in ein Modell aufgenommen werden.** Die univariable Vorfilterung trägt nicht zur Stabilität des Auswahlprozesses bei, da sie auf stochastischen Quanten beruht und dazu führen kann, dass wichtige Anpassungsvariablen übersehen werden.
3) **Nicht signifikante Effekte sollten aus einem Modell entfernt werden.** Regressionskoeffizienten hängen im Allgemeinen davon ab, welche anderen Variablen in einem Modell enthalten sind, und ändern folglich ihren Wert, wenn eine der anderen Variablen in einem Modell weggelassen wird.
4) **Der berichtete P-Wert quantifiziert den Typ-I-Fehler einer fälschlich ausgewählten Variablen.** Ein P-Wert ist ein Ergebnis der Datenerhebung und -analyse und quantifiziert die Plausibilität der beobachteten Daten unter der Nullhypothese. Daher quantifiziert der P-Wert nicht den Fehler vom Typ I. Es besteht auch die Gefahr einer falschen Eliminierung von Variablen, deren Auswirkungen durch die bloße Angabe des endgültigen Modells eines Variablenauswahlverfahrens überhaupt nicht quantifiziert werden können.
5) **Variablenauswahl vereinfacht die Analyse.** Für das jeweilige Problem muss eine geeignete Variablenauswahlmethode gewählt werden. Statistiker haben die Rückwärtselimination als die zuverlässigste unter den Methoden empfohlen, die sich mit Standardsoftware leicht durchführen lassen. Eine Auswahl ist eine "harte Entscheidung", die aber oft auf vagen Größen beruht. Untersuchungen zur Modellstabilität sollten jede angewandte Variablenauswahl begleiten, um die Entscheidung für das schließlich berichtete Modell zu rechtfertigen oder zumindest die mit der Auswahl der Variablen verbundene Unsicherheit zu quantifizieren.
Im Weiteren sei auch noch auf @heinze2018variable und @talbot2019descriptive verwiesen. Beide Veröffentlichungen liefern nochmal einen fundierten Block auf die Variablenselektion. Wiederum ist das natürlich nur ein winziger Ausschnitt aus der Literatur zur Variablenselektion. Im Zweifel einfach einmal bei [Google Scholar](https://scholar.google.com/scholar?hl=de&as_sdt=0%2C5&q=variable+selection+review&btnG=) nach Variablenselektion suchen und schauen was so in dem Feld der eigenen Forschung alles gemacht wird.
::: callout-caution
## Sensitivitätsanalysen nach der Variablenselektion
*"Variable selection should always be accompanied by sensitivity analyses to avoid wrong conclusions."* [@heinze2017five, p. 9]
Nachdem wir Variablen aus unseren Daten entfernt haben, ist es üblich noch eine Sensitivitätsanalysen durchzuführen. Wir Vergleich dann das selektierte Modell mit *anderen* Modellen. Oder wir wollen die Frage beantworten, was hat eigentlich meine Variablenselektion am Ergebnis geändert? Habe ich eine wichtige Variable rausgeschmissen? Das machen wir dann gesammelt in dem @sec-sensitivity zu den Sensitivitätsanalysen.
:::
## Genutzte R Pakete
Wir wollen folgende R Pakete in diesem Kapitel nutzen.
```{r echo = TRUE}
#| message: false
pacman::p_load(tidyverse, magrittr, dlookr,
MASS, ranger, Boruta, broom,
scales, olsrr, gtsummary, parameters,
conflicted)
conflicts_prefer(dplyr::select)
conflicts_prefer(dplyr::filter)
```
An der Seite des Kapitels findest du den Link *Quellcode anzeigen*, über den du Zugang zum gesamten R-Code dieses Kapitels erhältst.
## Daten
Um die Variablenselektion einmal durchzuführen nurtzen wir zwei Datensätze. Zum einen den Datensatz zu den Kichererbsen in Brandenburg mit einem normalverteilten Outcome $y$ mit `dryweight`. Wir laden wieder den Datensatz in R und schauen uns einmal die Daten in @tbl-chickpea-var als Auszug aus dem Tabellenblatt an.
[Wir du schon siehst, wir brauchen Fallzahl um hier überhaupt was zu machen. Bitte keine Variablenselektion im niedrigen zweistelligen Bereich an Beobachtungen.]{.aside}
```{r}
#| message: false
#| warning: false
chickpea_tbl <- read_excel("data/chickpeas.xlsx")
```
Wir sehen, dass wir sehr viele Variablen vorleigen haben. Sind denn jetzt alle Variablen notwendig? Oder können auch ein paar Variablen raus aus dem Modell. So viele Beobachtungen haben wir mit $n = 95$ ja nicht vorliegen. Daher wollen wir an diesem Datensatz die Variablenselektion unter der Annahme eines normalverteilten $y$ durchgehen.
```{r}
#| echo: false
#| message: false
#| warning: false
#| label: tbl-chickpea-var
#| tbl-cap: Auszug aus dem Daten zu den Kichererbsen in Brandenburg.
#| column: page
rbind(head(chickpea_tbl, 3),
rep("...", times = ncol(chickpea_tbl)),
tail(chickpea_tbl, 3)) |>
kable(align = "c", "pipe")
```
Was wir auch noch wissen, ist wie die Effekte in den Daten *wirklich* sind. Die Daten wurden ja künstlich erstellt, deshalb hier die Ordnung der Effektstärke für jede Variable. Im Prinzip müsste diese Reihenfolge auch bei der Variablenselektion rauskommen. Schauen wir mal, was wir erhalten.
$$
y \sim \beta_0 + 3 * sand + 2 * temp + 1.5 * rained - 1.2 * forest + 1.1 * no3
$$
Viele Beispiele laufen immer unter der Annahme der Normalverteilung. Deshalb als zweites Beispiel nochmal die Daten von den infizierten Ferkeln mit einem binomialverteilten Outcome $y$ mit `infected`. Auch hier können wir uns den Auszug der Daten in @tbl-pigs-var anschauen.
```{r}
#| message: false
#| warning: false
pig_tbl <- read_excel("data/infected_pigs.xlsx")
```
Das schöne an diesem Datensatz ist jetzt, dass wir mit $n = 412$ Beobachtungen sehr viele Daten vorliegen haben. Daher können wir auch alle Methoden gut verwenden und haben nicht das Problem einer zu geringen Fallzahl.
```{r}
#| echo: false
#| message: false
#| warning: false
#| label: tbl-pigs-var
#| tbl-cap: Auszug aus dem Daten zu den kranken Ferkeln.
#| column: page
rbind(head(pig_tbl, 3),
rep("...", times = ncol(pig_tbl)),
tail(pig_tbl, 3)) |>
kable(align = "c", "pipe")
```
Auch in diesem Beispiel wurden die Daten von mir mit folgenden Effekten generiert. Schauen wir mal, was die Variablenselektion bei der hohen Fallzahl mit den Variablen macht bzw. welche Sortierung am Ende rauskommt.
$$
y \sim \beta_0 + 2 * crp + 0.5 * sex + 0.5 * frailty + 0.2 * bloodpressure + 0.05 * creatinin + 0.01 * weight
$$
Damit haben wir unsere beiden Beispiel und jetzt gehen wir mal eine Auswahl an Methoden zur Variablenselektion durch. Besonders hier, haltet den statistsichen Engel nah bei euch. Es wird leider etwas ruppig für den statistischen Engel.
## Methoden der Variablenselektion
In den folgenden Abschnitten wollen wir uns eine Reihe an Methoden anschauen um eine Variablenselektion durchzuführen. Dabei gehen wir von einfach nach komplex. Wobei das komplex eher die Methode und nicht die Anwendung meint. Wir nutzen R Pakete und gehen nicht sehr ins Detail *wie* der Algorithmus jetzt die Auswahl trifft. Für den Hintergrund sind dann die Verweise auf die anderen Kapitel.
### Per Hand
Manchmal ist der Anfang auch das Ende. Wir müssen ja gar keinen Algorithmus auf unsere Daten loslassen um eine Variablenselektion durchzuführen. Deshalb möchte ich gleich den ersten Abschnitt mit einem Zitat von @heinze2017five beginnen.
*"Oft gibt es keinen wissenschaftlichen Grund, eine (algorithmische) Variablenauswahl durchzuführen. Insbesondere erfordern Methoden der (algorithmische) Variablenselektion einen viel größeren Stichprobenumfang als die Schätzung eines multiplen Modells mit einem festen Satz von Prädiktoren auf der Grundlage (klinischer) Erfahrung."* [Übersetzt und ergänzt nach @heinze2017five, p. 9]
Fazit dieses kurzen Abschnitts. Wir können auf alles Folgende einfach verzichten und uns überlegen welche Variablen *sinnvollerweise* mit ins Modell sollen und das mit unserem Expertenwissen begründen. Gut, und was ist, wenn ich kein Experte bin? Oder wir aber *wirklich* Neuland betreten? Dann können wir eine Reihe anderer Verfahren nutzen um uns algortimisch einer Wahrheit anzunähern.
### Univariate Vorselektion
Und weiter geht es mit Zitaten aus @heinze2017five zu der Variablenselektion. Dazu musst du wissen, dass die univariate Vorselektion sehr beliebt war und auch noch ist. Denn die univariate Vorselektion ist einfach durchzuführen und eben auch gut darzustellen.
*"Obwohl die univariable Vorfilterung nachvollziehbar und mit Standardsoftware leicht durchführbar ist, sollte man sie besser ganz vergessen, da sie für die Erstellung multivariabler Modelle weder Voraussetzung noch von Nutzen ist."* [Übersetzt nach @heinze2017five, p. 8]
[Ich sage immer, auch mit einem Hammer kann man Scheiben putzen. Halt nur einmal... Deshalb auch hier die univariate Variante der Vorselektion.]{.aside}
Wir sehen also, eigentlich ist die univariate Variablensleketion nicht so das gelbe vom Ei, aber vielleicht musst die Variablenselektion durchführen, so dass her die Lösung in R einmal dargestellt ist. Wir nutzen einmal die gaussian lineare Regression für den Kichererbsendatensatz. Es ist eine ganze Reihe an Code, das hat aber eher damit zu tun, dass wir die Modellausgabe noch filtern und anpassen wollen. Die eigentliche Idee ist simple. Wir nehmen unseren Datensatz und pipen den Datensatz in select und entfernen unser Outcome `drymatter`. Nun iterieren wir für *jede* Variable `.x` im Datensatz mit der Funktion `map()` und rechnen in jeder Iteration eine gaussian lineare Regression. Dann entferne wir noch den Intercept und sortieren nach den $p$-Werten.
```{r}
chickpea_tbl |>
select(-dryweight) |>
map(~glm(dryweight ~ .x, data = chickpea_tbl, family = gaussian)) |>
map(tidy) |>
map(filter, term != "(Intercept)") |>
map(select, -term, -std.error, -statistic) |>
bind_rows(.id="term") |>
arrange(p.value) |>
mutate(p.value = pvalue(p.value),
estimate = round(estimate, 2))
```
Würden wir nur nach dem Signifikanzniveau von 5% gehen, dann hätten wir die Variablen `sand` und `location` selektiert. Bei der selektion mit dem $p$-Wert wird aber eher eine Schwelle von 15.7% vorgeschlagen [@heinze2017five, p. 9]. Daher würden wir auch noch `no3` und `temp` mit Selektieren und in unser Modell nehmen.
Es gibt ja immer zwei Wege nach Rom. Deshalb hier auch nochmal die Funktion `tbl_uvregression()` aus dem R Paket `{gtsummary}`, die es erlaubt die univariaten Regressionen über alle Variablen laufen zu lassen. Wir kriegen dann auch eine schöne @tbl-chick-gt wieder.
::: column-margin
Das R Paket `{gtsummary}` erlaubt es Ergebnisse der Regression in dem [Tutorial: tbl_regression](https://www.danieldsjoberg.com/gtsummary/articles/tbl_regression.html) gut darzustellen.
:::
```{r}
#| echo: true
#| message: false
#| warning: false
#| label: tbl-chick-gt
#| tbl-cap: "Univariate Regression mit der Funktion `tbl_uvregression()`."
chickpea_tbl |>
tbl_uvregression(
method = glm,
y = dryweight,
method.args = list(family = gaussian),
pvalue_fun = ~style_pvalue(.x, digits = 2)
) |>
add_global_p() |> # add global p-value
add_q() |> # adjusts global p-values for multiple testing
bold_p() |> # bold p-values under a given threshold (default 0.05)
bold_p(t = 0.10, q = TRUE) |> # now bold q-values under the threshold of 0.10
bold_labels()
```
Nun führen wir die univariate Regression erneut auf den Ferkeldaten aus. Hier ändern wir nur die `family = binomial`, da wir hier jetzt eine logistische lineare Regression rechnen müssen. Unser Outcome `infected` ist ja $0/1$ codiert. Sonst ändert sich der Code nicht.
```{r}
pig_tbl |>
select(-infected) |>
map(~glm(infected ~ .x, data = pig_tbl, family = binomial)) |>
map(tidy) |>
map(filter, term != "(Intercept)") |>
map(select, -term, -std.error, -statistic) |>
bind_rows(.id="term") |>
arrange(p.value) |>
mutate(p.value = pvalue(p.value),
estimate = round(estimate, 2))
```
In diesem Fall reicht die Schwelle von 15.7% nur für zwei Variablen [@heinze2017five, p. 9]. Wir erhalten die Variablen `crp` und `bloodpressure` für das Modell selektiert.
In der @tbl-pig-gt sehen wir dann nochmal die Anwendung der Funktion `tbl_uvregression()` auf den Ferkeldatensatz. Ich musste hier die Option `pvalue_fun = ~style_pvalue(.x, digits = 2)` entfernen, da sonst die Variable `crp` keinen $p$-Wert erhält. Leider sehe ich den $p$-Wert mit $<0.001$ in meiner Ausgabe in R aber wie du siehst, wird die Tabelle auf der Webseite nicht korrekt angezeigt. Das Problem von automatischen Tabellen. Ein Fluch und Segen zugleich. Du musst immer wieder überprüfen, ob die Optionen dann auch für sich und deine Analyse passen.
```{r}
#| echo: true
#| message: false
#| warning: false
#| label: tbl-pig-gt
#| tbl-cap: "Univariate Regression mit der Funktion `tbl_uvregression()`."
pig_tbl |>
tbl_uvregression(
method = glm,
y = infected,
method.args = list(family = binomial),
exponentiate = TRUE
) |>
add_global_p() |> # add global p-value
add_nevent() |> # add number of events of the outcome
add_q() |> # adjusts global p-values for multiple testing
bold_p() |> # bold p-values under a given threshold (default 0.05)
bold_p(t = 0.10, q = TRUE) |> # now bold q-values under the threshold of 0.10
bold_labels()
```
Neben der Berechnung von univariaten logistischen Regressionen ist auch die Darstellung der Daten in einer @tbl-pigs-table1 bei Medizinern sehr beliebt. Deshalb an dieser Stelle auch die Tabelle 1 (eng. *table 1*) für die Zusammenfasung der Daten getrennt nach dem Infektionsstatus zusammen mit dem $p$-Wert. Ich nutze hier die Funktion `tbl_summary()` aus dem R Paket `{gtsummary}`.
```{r}
#| echo: true
#| message: false
#| warning: false
#| label: tbl-pigs-table1
#| tbl-cap: Zusammenfasung der Daten getrennt nach dem Infektionsstatus zusammen mit dem $p$-Wert.
pig_tbl |> tbl_summary(by = infected) |> add_p()
```
Tja, auch hier ist dann die Frage, wie sortiere ich Variablen. Da es sich bei dem *table 1*-Stil um eine Übersichtstabelle handelt, ist die Tabelle nach den Variablen sortiert. Auch hier finden wir dann die Variablen `crp` und `bloodpressure` wieder. Das Problem hierbei ist natürlich, dass sich die $p$-Werte unterscheiden. Das muss ja auch so sein, denn eine logitische Regression ist nun mal kein *Wilcoxon rank sum test* oder ein *Pearson's Chi-squared test*.
Fassen wir als Fazit dieses Abschnitts zusammen wie unsere Modelle nach der Variablenslektion aussehen würde. In unserem Beispiel für die Kichererbsen im sandigen Brandenburg würden wir dann folgendes Modell nehmen.
$$
y \sim \beta_0 + sand + location + no3 + temp
$$
Unsere infizierten Ferkel würden dann folgendes selektiertes Modell erhalten.
$$
y \sim \beta_0 + crp + bloodpressure
$$
Schauen wir mal, was die anderen Algorithmen noch so finden.
### Sonderfall Gaussian linear Regression
Für die gaussian lineare Regression gibt es mit dem R Paket `{oslrr}` eine große Auswahl an [Variable Selection Methods](https://olsrr.rsquaredacademy.com/articles/variable_selection.html). Einfach mal die Möglichkeiten anschauen, die dort angeboten werden. Wir nutzen jetzt nicht alles was din `oslrr` möglich ist, sondern nur eien Auswahl. Zuerst müssen wir wieder unser Modell fitten. Wir nehmen alle Variablen mit rein und nutzen die Funktion `lm()` für ein lineares Modell mit einem normalverteilten Outcome $y$ mit `dryweight`.
```{r}
chickenpea_fit <- lm(dryweight ~ temp + rained + location + no3 + fe + sand + forest,
data = chickpea_tbl)
```
Nun gibt es wirklich viele Lösungen in dem R Paket `{oslrr}`. Ich möchte einmal die Variante mit `ols_step_all_possible` präsentieren. In dem Fall rechnen wir alle Modelle die gehen. Und damit meine ich wirklich alle Modelle. Deshalb filtern wir noch nach dem $R^2_{adj}$ um nicht von dem Angebot erschlagen zu werden. Darüber hinaus möchte ich nur Modelle sehen, die maximal vier Variablen mit in dem Modell haben. Das ist zufällig von mir gewählt... ich will ja ein kleineres Modell haben.
```{r}
ols_step_all_possible(chickenpea_fit)$result |>
as_tibble() |>
arrange(desc(adjr)) |>
filter(n <= 4) |>
select(predictors, adjr, aic)
```
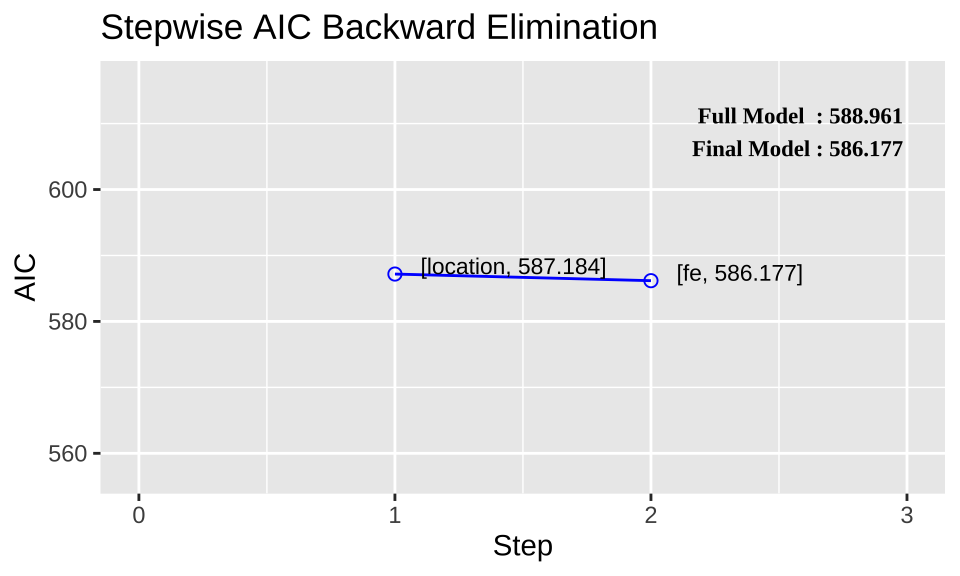
Eine Alternative ist die Funktion `ols_step_backward_aic()`, die es erlaubt die Selektion anhand dem $AIC$-Wert zu machen. Der $AIC$-Wert beschreibt die Güte eines Modells und je kleiner der $AIC$-Wert ist, desto besser ist das Modell im Vergleich zu anderen Modellen gleicher Art. Da der $AIC$-Wert von den Daten abhängt in denen der $AIC$-Wert geschätzt wurde, können verschiedene $AIC$-Werte nicht übergreifend vergleichen werden.
```{r}
chick_step_aic <- ols_step_backward_aic(chickenpea_fit)
```
In @fig-ols-diag sehen wir einmal den Verlauf der $AIC$-Wert durch die Entfernung der jeweiligen Variable. Wenn du auf die y-Achse schaust, ist der Effekt numerisch nicht sehr groß. Davon darf man sich aber nicht beeindrucken lassen., Wir erhalten ein besseres Modell, wenn wir Variablen entfernen. Darüber hinaus sehen wir auch eine Sättigung.
```{r}
#| echo: true
#| message: false
#| label: fig-ols-diag
#| fig-align: center
#| fig-height: 3
#| fig-width: 5
#| fig-cap: "Visualisierung der `ols_step_backward_aic` mit der Reduktion des AIC-Wertes."
plot(chick_step_aic)
```
Gut, und wie sieht nun unser finales Modell aus? Dafür müssen wir usn aus dem Objekt `chick_step_aic` das `model` raus ziehen. Dafür nutzen wir die Funktion `pluck()`. Dann noch die Ausgabe in die Funktion `model_parameters()` gepipt und schon haben wir das finale Modell nach $AIC$-Werten in einer gaussian linearen Regression.
```{r}
#| message: false
#| warning: false
pluck(chick_step_aic, "model") |>
model_parameters()
```
Spannenderweise ist `location` nicht mehr im finalen Modell plus die Variable `location` flog auch sehr früh raus. Das passt auch besser zu den Daten. Ich hatte die Daten so gebaut, dass der Ort eigentlich keinen Effekt haben sollte. Wir sehen, dass je nach Verfahren was anderes herauskommt. Aber Achtung, das schrittweise Verfahren ist der Auswahl nach $p$-Werten auf jeden Fall vorzuziehen!
### Schrittweise mit `stepAIC`
Was das R Paket `{oslrr}` für die gaussian linear Regression kann, kann das R Paket `{MASS}` mit der Funktion `stepAIC` für den Rest der möglichen Verteilungen. Da wir mit dem Fekerldatensatz ein binominales Outcome $y$ mit `infected` vorliegen haben nutzen wir un die Funktion `stepAIC()`. Wir hätten auch den Kichererbsendatensatz mit der Funktion bearbeiten können, aber im Falle der Normalverteilung stehen uns dann eben noch andere Algorithmen zu Verfügung. Wie immer müssen wir zuerst das volle Modell mit der Funktion `glm()` fitten. Wir geben noch die Verteilungsfamilie mit `family = binomial` noch mit an und definieren so eine logistische lineare Regression.
```{r}
#| echo: true
#| message: false
#| eval: true
#| warning: false
fit <- glm(infected ~ age + sex + location + activity + crp + frailty + bloodpressure + weight + creatinin,
data = pig_tbl, family = binomial)
```
Nachdem wir das Modell gefittet haben, können wir das Modell direkt in die Funktion `stepAIC` stecken. Wir nutzen noch die Option `direction = "backward"` um eine Rückwärtsselektion durchzuführen.
```{r}
fit_step <- stepAIC(fit, direction = "backward")
```
Jetzt ist die Selektion durchgelaufen und wir sehen in jeden Schritt welche Variable jeweils entfernt wurde und wie sich dann der $AIC$-Wert ändert. Wir starten mit einem $AIC = 425.65$ und enden bei einem $AIC=415.01$. Schauen wir uns nochmal das finale Modell an.
```{r}
#| message: false
#| warning: false
fit_step |>
model_parameters()
```
Hier erscheint jetzt noch die Variable `sex` mit in der Auswahl. Das hat natürlich auch weitreichende Auswirkungen! Es macht schon einen gewaltigen Unterschied, ob wir annehmen das, dass Geschelcht der Ferkel keinen Einfluss auf die Infektion hat oder eben doch. Wir sehen auch hier, dass wir Aufpassen müssen wenn wir eine Variablenselektion durchführen. Aber Achtung, das schrittweise Verfahren ist der Auswahl nach $p$-Werten auf jeden Fall vorzuziehen!
### Feature Selektion mit `ranger`
In diesem Abschnitt wollen wir die Variablenselektion mit einem maschinellen Lernverfahren durchführen. Im Bereich des maschinellen Lernens heist die Variablenselektion dann aber *Feature Selektion*. Wir versuchen jetzt die Selektion auf den Orginaldaten durchzuführen. Eigentlich wird empfohlen die Daten vorher zu normalisieren und dann mit den maschinellen Lernverfahren zu nutzen.
::: callout-caution
## Standardisieren oder Normalisieren von Daten
Eine Herausforderung für maschinelle Lernverfahren sind nicht normalisierte Daten. Das heist, dass wir Variablen haben, die kategorial oder kontinuierlich sein können oder aber sehr unterschiedlich von den Einheiten sind. Deshalb wird empfohlen die Daten vorher zu Standardisieren oder zu Normalisieren. In dem @sec-eda-transform kannst du mehr über das Transformieren von Daten nachlesen.
:::
Wir nutzen als erstes einen Random Forest Algorithmus wie er in @sec-class-tree beschrieben ist. Es bietet sich hier die Implementation im R Paket `{ranger}` an. Bevor wir aber einen Random Forest auf unsere Daten laufen lassen, Standardisieren wir unsere Daten nochmal. Überall wo wir einen numerischen Wert als Variableneintrag haben rechnen wir eine $z$-Transformation. Wir erhalten dann die standardisierten Daten zurück.
```{r}
pig_norm_tbl <- pig_tbl |>
mutate(across(where(is.character), as_factor),
across(where(is.numeric), dlookr::transform, "zscore"))
pig_norm_tbl
```
Den Random Forest rechnen wir mit der Funktion `ranger()`. Dafür müssen wir wieder unser vollständiges Modell definieren und können dann die Funktion starten. Damit wir eine Variablenwichtigkeit (eng. *variable importance*) wiederbekommen, müssen wir noch die Option `importance = "permutation"` verwenden.
```{r}
#| echo: true
#| message: false
#| warning: false
fit_raw <- ranger(infected ~ age + sex + location + activity + crp + frailty + bloodpressure + weight + creatinin,
data = pig_tbl, ntree = 1000, importance = "permutation")
pluck(fit_raw, "variable.importance") |>
sort(decreasing = TRUE) |>
round(3)
```
Wir sehen, dass wir als wichtigste Variable wiederum `crp` zurückbekommen. Danach wird es schon etwas schwieriger, da die Werte sehr schnell kleiner werden und auch ein Art Plateau bilden. Daher würde man hier nur annehmen, dass `crp` bedeutend für das Modell ist. Es kann aber auch sein, dass hier eine kontinuierliche Variable sehr vom Algorithmus bevorzugt wurde. Daher schauen wir uns die Sachlage einmal mit den standardisierten Daten an.
```{r}
#| echo: true
#| message: false
#| warning: false
fit_norm <- ranger(infected ~ age + sex + location + activity + crp + frailty + bloodpressure + weight + creatinin,
data = pig_norm_tbl, ntree = 1000, importance = "permutation")
pluck(fit_norm , "variable.importance") |>
sort(decreasing = TRUE) |>
round(3)
```
Auch hier erhalten wir ein ähnliches Bild. Audf jeden Fall ist `crp` bedeutend für den Infektionsstatus. Danach werden die Werte etwas zufällig. Wir können Werte für die *variable importance* nicht unter Datensätzen vergleichen. Jeder Datensatz hat seine eigene *variable importance*, die von den Werten in dem Datensatz abhängt.
Wir ziehen als Fazit, dass wir nur `crp` als bedeutenden Wert für die Klassifikation des Infektionsstatus ansehen würden. Hier stehen wir wirklich etwas wie das Schwein vor dem Uhrwerk, denn was nun richtiger ist, `stepAIC` oder `ranger` lässt sich so einfach nicht bewerten. Zum einen wollen wir ja eigentlich mit Random Forest eine Klassifikation durchführen und mit linearen Regressionsmodellen eher kausale Modelle schätzen. Am Ende musst du selber abschätzen, was in das finale Modell soll. Ich kann ja auch den Threshold für den Variablenausschluss selber wählen. Wähle ich einen Threshold von $0.008$, dann hätte ich `crp`, `weight`, `bloodpressure` und `sex` mit in dem finalen Modell.
### Feature Selektion mit `boruta`
Mit dem Boruta Algorithmus steht uns noch eine andere Implemnetierung des Random Forest Algorithmus zu verfügung um Feature Selektion zu betreiben. Wir nutzen wieder den Boruta Algorithmus in seine einfachen Form und gehen nicht tiefer auf alle Optionen ein. Wir nehmen wieder als Beispiel den Datensatz zu den infizierten Ferkeln und nutzen in diesem Fall auch nur die rohen Daten. Über eine Standardisierung könnte man wiederum nachdenken.
::: column-margin
Ich empfehle noch das Tutorium [Feature Selection in R with the Boruta R Package](https://www.datacamp.com/tutorial/feature-selection-R-boruta). Wir gehen hier nicht tiefer auf die Funktionalität von Boruta ein.
:::
::: callout-caution
## Standardisieren oder Normalisieren von Daten
Eine Herausforderung für maschinelle Lernverfahren sind nicht normalisierte Daten. Das heist, dass wir Variablen haben, die kategorial oder kontinuierlich sein können oder aber sehr unterschiedlich von den Einheiten sind. Deshalb wird empfohlen die Daten vorher zu Standardisieren oder zu Normalisieren. In dem @sec-eda-transform kannst du mehr über das Transformieren von Daten nachlesen.
:::
Um die Funktion `Boruta()` zu nutzen brauchen wir wieder das Modell und den Datensatz. Sonst ist erstmal nichts weiter anzugeben. Die Funktion läuft dann durch und gibt auch gleich den gewollten Informationshappen. Wichtig ist hierbei, dass wir natürlich noch andere Optionen mit angeben können. Wir können die Anzahl an Iterationen erhöhen und andere Tuning Parameter eingeben. Hier muss man immer schauen was am besten passt. Da würde ich auch immer rumprobieren und auf der Hilfeseite der Funktion `?Boruta` einmal nachlesen.
```{r}
set.seed(20221031)
boruta_output <- Boruta(infected ~ age + sex + location + activity + crp + frailty + bloodpressure + weight + creatinin,
data = pig_tbl)
boruta_output
```
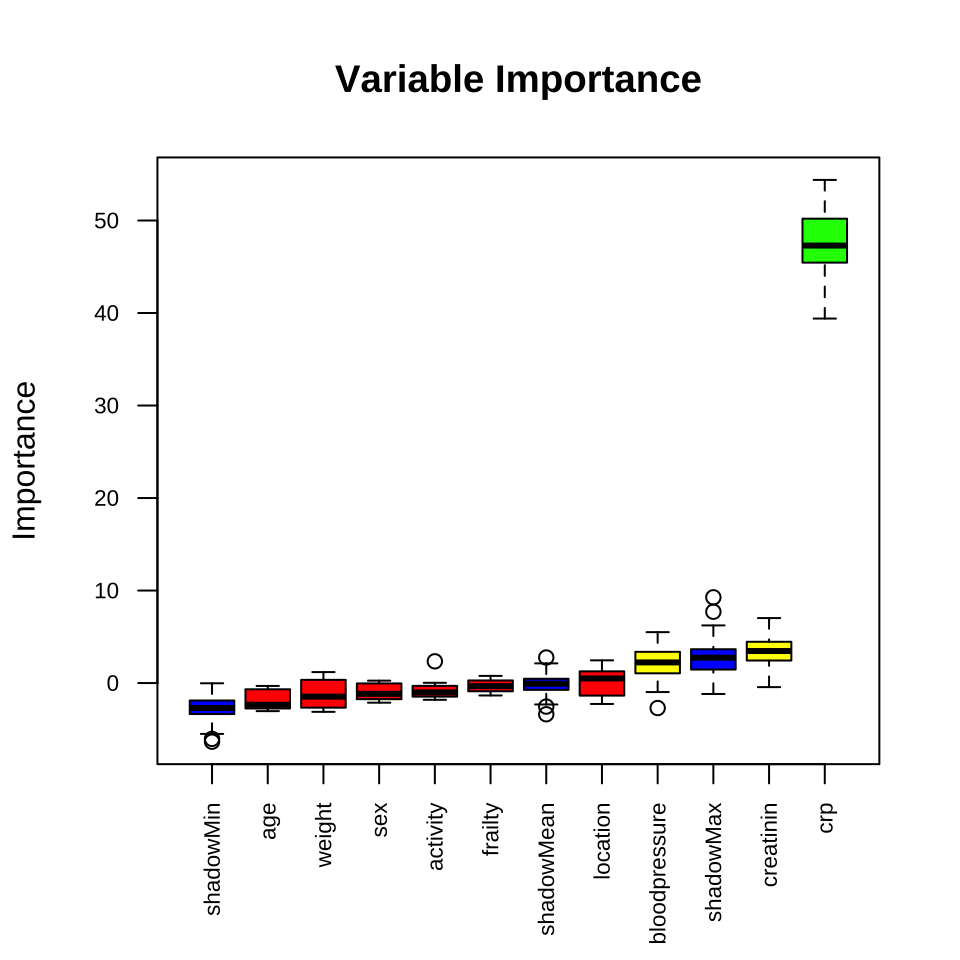
Manchmal ist es super praktisch, wenn eine Funktion einem die Antwort auf die Frage welche Variable bedeutend ist, gleich liefert. Wir erhalten die Information, dass die Variable `crp` als bedeutsam angesehen wird. Wir können uns den Zusammenhang auch in der @fig-buruta auch einmal anschauen. Die grünen Variablen sind die bedeutenden Variablen.
```{r}
#| echo: true
#| message: false
#| label: fig-buruta
#| fig-align: center
#| fig-height: 5
#| fig-width: 5
#| fig-cap: "Visualisierung der Boruta Ausgabe."
plot(boruta_output, cex.axis=.7, las=2, xlab="", main="Variable Importance")
```
Am Ende finden wir auch hier die Variable `crp` als einziges als bedeutend wieder. Wenn wir noch Variablen haben die verdächtig oder vorläufig bedeutend sind, angezeigt durch `2 tentative attributes left: bloodpressure, sex`, dann können wir noch die Funktion `TentativeRoughFix()` nutzen. Die Funktion `TentativeRoughFix()` rechnet die Variablen nochmal nach und versucht alle Variablen in bedeutend oder nicht bedeutend zu klassifizieren. Wir haben ja zwei *tentative* Variablen in unseren Fall vorliegen, also nutzen wir noch kurz die Funktion um uns auch hier Klarheit zu schaffen.
```{r}
TentativeRoughFix(boruta_output)
```
Am Ende ist die klare Aussage einer Funktion auch immer ein zweischneidiges Schwert. Wir verlieren jetzt noch die beiden *tentative* Variablen. Wo wir bei `ranger` die Qual der Wahl haben, werden wir bei `Boruta` eher vor vollendete Tatsachen gestellt. Meistens neigt man nach einer `Boruta`-Analyse nicht dazu noch eine zusätzliche Variable mit ins Modell zu nehmen. Dafür ist dann die Ausgabe zu bestimmt, obwohl die Entscheidung am Ende auch genau so unsicher ist wie von `ranger` und den anderen Modellen.
## Referenzen {.unnumbered}