```{r}
#| echo: false
#| message: false
pacman::p_load(tidyverse, readxl, knitr, kableExtra, broom, patchwork, tinytable, conflicted)
conflict_prefer("extract", "magrittr")
conflicts_prefer(dplyr::filter)
data_tbl <- tibble(animal = gl(2, 4, labels = c("cat", "dog")),
jump_length = c(8.5, 9.9, 8.9, 9.4, 8.0, 7.2, 8.4, 7.5)) |>
arrange(desc(animal))
data_compact_tbl <- tibble(animal = gl(3, 4, labels = c("cat", "dog", "fox")),
jump_length = c(8.5, 9.9, 8.9, 9.4, 8.0, 7.2, 8.4, 7.5,
7.5, 8.1, 6.7, 7.1))
cbbPalette <- c("#000000", "#E69F00", "#56B4E9", "#009E73",
"#F0E442", "#0072B2", "#D55E00", "#CC79A7")
source("images/R/stat-test-basic-R-01.R")
```
# Die Testentscheidung {#sec-stat-entscheidung}
*Letzte Änderung am `r format(fs::file_info("stat-tests-basic.qmd")$modification_time, '%d. %B %Y um %H:%M:%S')`*
> *"Wir können das Universum nicht erklären, sondern nur beschreiben; und wir wissen nicht, ob unsere Theorien wahr sind, wir wissen nur, dass sie nicht falsch sind." --- Harald Lesch*
{{< video https://youtu.be/y5Kdrp299Ko >}}
Wissenschaftliche Forschung basiert auf dem Falsifikationsprinzip. Wir können daher Modelle oder Hypothesen *nur ablehnen* und behalten das weniger schlechte Modell oder die weniger schlechte Hypothese bei. In diesem Kapitel wollen wir uns mit dem statistischen Testen beschäftigen. Wir wollen also Testen, ob wir eine Hypothese ablehnen können. Dabei fangen wir hier mit den Grundprinzipien an, die wir dann bei allen statistischen Tests in den folgenden Kapiteln verwenden können. Im Besonderen konzentrieren wir uns hier auf den t-Test für zwei Stichproben an dem ich einmal die Grundkonzepte statistischen Testens erkläre.
::: {layout="[15,85]" layout-valign="center"}
{fig-align="center" width="100%"}
> Deshalb auch gleiche eine Warnung vorweg. Ich habe mich hier dem allgemeinen Verständnis verpflichtet gefühlt und nicht so sehr der statistischen, sprachlichen Genauigkeit. Man möge mir das Verzeihen.
:::
Das statistische Testen ist dabei eine eigne Philosophie oder Gedankengebäude. Wir führen spezielle, gedankliche Schritte durch um zu einer Entscheidung zu kommen. Es handelt sich mehr oder minder um einen objektiven Prozess um zu einer Entscheidung zu kommen. Diese Entscheidung basiert auf Regeln, die wir dann in der Summe als *statistisches Testen* bezeichnen. Wir schauen uns hier den am meisten verbreiteten Zweig des statistischen Testen an -- wir nutzen hier die frequentistische Statistik. Für die Anwendung ist es egal, aber vielleicht hörst du später mal was von anderen Möglichkeiten um zu einer statistischen Entscheidung zu kommen. Eine andere Möglichkeit wäre das bayesianische Testen, was wir aber hier nicht in den Grundlagen behandeln werden. Deshalb hier einmal erwähnt, nach welche Philosophie wir testen. Wenn dich mehr über das statistische Testen erfahren möchtest, kann ich dir die Veröffentlichung von @gigerenzer2004null sehr ans Herz legen. Dort wird nochmal die Geschichte und die Hintergründe erläutert.
::: {layout="[20,80]"}
{fig-align="center" width="100%"}
> *"Die Zeit, die du für deine Rose verloren hast, sie macht deine Rose so wichtig." --- Antoine de Saint-Exupéry, Der kleine Prinz*
:::
Deine Daten $D$ sind deine Rose. Deine Daten sind was Besonderes für dich, weil du Zeit für die Erstellung der Daten aufgewendet hast. Du hast deine Daten mühselig dem Feld oder dem Labor abgerungen. Hast lange mit der Exceltabelle verbracht oder gebraucht bist du die Fragestellungen für dich verstanden hast. Es sind also nicht *irgendwelche* Daten, sondern eben *deine* Daten. In Wirklichkeit sind deine Daten nur eine rein zufällge Auswahl an Messwerten. Nur das dir es nich in der Form so vorkommt.
So, jetzt geht es aber los. Du erfährst im diesem Kapitel mehr zur statistischen Testentscheidung und welche Konzepte wir beim statistischen Testen nutzen. Wir gehen dabei die vier wichtigsten Konzepte einmal durch.
- Wir verstehen die statistischen Testentscheidung anhand des Konzeptes der Teststatistik $T$ (siehe @sec-teststatistik) und können eine simple Teststatistik berechnen. Du nutzt die Testentscheidung nach der Teststatistik $T$ hauptsächlich in einer schriftlichen Prüfung. In der praktischen Anwendung hat die Teststatistik heutzutage keine Bedeutung mehr.
- Wir können die statistischen Testentscheidung anwenden, da wir das Konzept des $p$-Wertes $Pr(T|H_0)$ verstanden haben (siehe @sec-pwert). Heutzutage treffen wir eine Testentscheidung anhand des $p$-Wertes. Dabei ist der $p$-Wert grob als Wahrscheinlichkeit der Teststatistik anzusehen. Deshalb auch $p$-Wert was im englischen für *p-value*, also *probability value*, steht.
- Wir können die statistische Testentscheidung anhand der neuen statistischen Maßzahl des S-Wertes bewerten (siehe @sec-s-value). Der S-Wert ist eine Transformation des p-Wertes und erlaubt eine intuitivere Interpretation. Wir haben daher eine Idee wie stark unsere Daten von der Nullhypothese abweichen. Oder etwas anders ausgedrückt, wie stark wir von den S-Werten überrrascht werden.
- Wir können die statistischen Testentscheidung anwenden, da wir das Konzept des *Compact letter displays* verstanden haben (siehe @sec-compact-letter-short). Wir können daher einem Boxplot oder Barplot die entsprechenden Buchstaben eines *Compact letter displays* ergänzen und interpretieren.
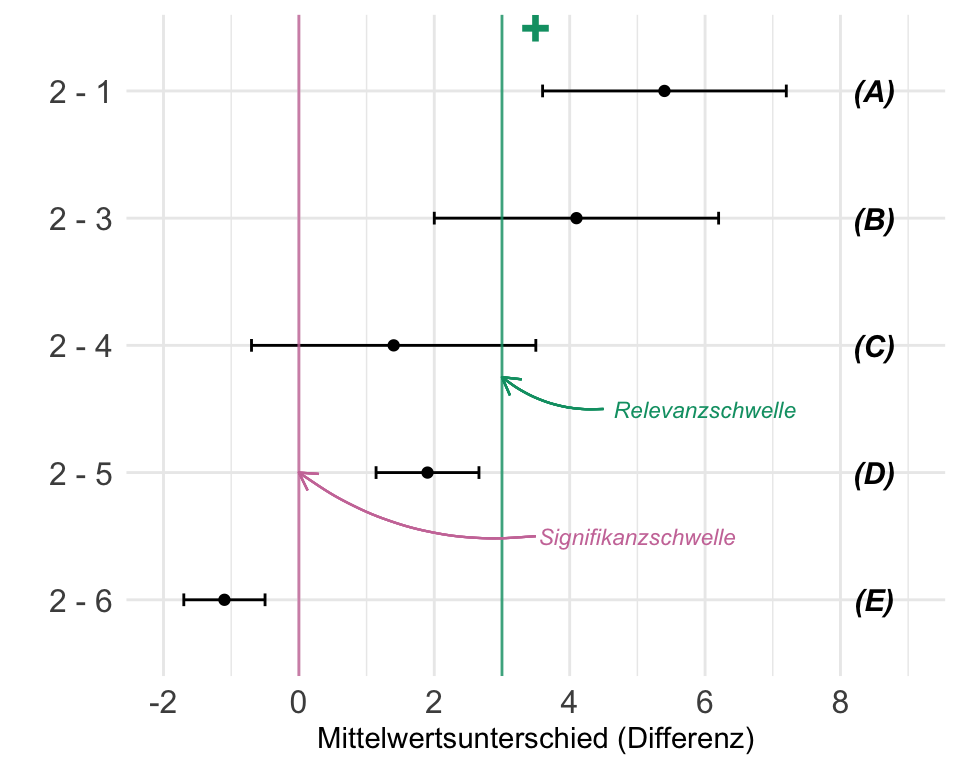
- Wir können die statistischen Testentscheidung anwenden, da wir das Konzept der 95% Konfidenzintervalle verstanden haben (siehe @sec-ki). Wir haben verstanden, dass es einen konzeptionellen Unterschied zwischen dem Begriff *Signifikanz* und *Relevanz* gibt. Die Aussage der Signifikanz ist eine reine Wahrscheinlichkeitsaussage und beinhaltet keine Bewertung der Stärke des beobachteten Effekts.
Diese obigen Konzepte sind so zentral, dass wir immer wieder auf diese zurückkommen werden. Daher ist es wichtig, dass du ein Grundverständnis von dem statistischen Testen für dich erwirbst. Eine wissenschaftliche Abschlussarbeit wirst du ohne einen statistischen Test selten abgeben können.
::: {.callout-note collapse="true"}
## Zerforschen: Veröffentlichung zu den Sprungweiten der Hunde- und Katzenflöhe
Die ursprüngliche Idee zu den Sprungweiten der Hunde- und Katzenflöhe stammt von @cadiergues2000comparison aus der entsprechenden Veröffentlichung [A comparison of jump performances of the dog flea, Ctenocephalides canis (Curtis, 1826) and the cat flea, Ctenocephalides felis felis (Bouché, 1835)](https://www.sciencedirect.com/science/article/pii/S0304401700002740). In der folgenden @fig-zerforschen-fleas siehst du einmal die Zusammenfassung (eng. *abstract*) aus der Arbeit. Wir wollen uns hier einmal auf die berichteten Sprungweiten der Hunde- und Katzenflöhe konzentrieren.
{#fig-zerforschen-fleas fig-align="center" width="100%"}
Wir können jetzt die Mittelwerte der Sprungweiten der Hunde- und Katzenflöhe einmal nehmen und diese Werte dann in die Formel des t-Test setzen. Wir haben ja dafür fast alles was wir brauchen. Die Standardabweichung ist ja in beiden Gruppen der Hunde- und Katzenflöhe gleich. Das einzige was ich hier noch berichten muss ist die Fallzahl $n_g$ der beiden Gruppen mit 450 Flöhen. Dann können wir auch schon die Teststatistik $T_{D}$ mit den Werten aus der Zusammenfassung berechnen.
$$
T_{D} = \cfrac{30.4cm - 19.9cm}{9.1cm \cdot \sqrt{2/450}} = \cfrac{10.5cm}{0.61cm} = 17.21
$$
Dann brauchen wir noch die Freiheitsgrade der t-Verteilung um uns den $p$-Wert berechnen zu können. Wir nutzen dafür die folgende Formel.
$$
df = n_1 + n_2 -2 = 450 +450 -2 = 898
$$
Dann können wir schon die Fläche rechts von der berechneten Teststatistik $T_{D}$ mit der Funktion `pt()` ausrechnen.
```{r}
pt(17.21, 898, lower.tail = FALSE)
```
Wie du siehst erhalten wir einen sehr kleinen $p$-Wert. Das haben wir aber auch erwartet, denn die Teststatistik $T_{D}$ ist ja auch sehr groß! Damit bleibt kaum Fläche rechts von der Teststatistik $T_{D}$ übrig. Damit ist dann der $p$-Wert sehr klein.
:::
## Die Hypothesen {#sec-hypothesen}
Wir können auf allen Daten einen statistischen Test rechnen und erhalten statistische Maßzahlen wie eine Teststatistik oder einen $p$-Wert. Nur leider können wir mit diesen statistischen Maßzahlen nicht viel anfangen ohne die Hypothesen zu kennen. Jeder statistische Test testet eine Nullhypothese. Ob diese Hypothese dem Anwender nun bekannt ist oder nicht, ein statistischer Test testet eine Nullhypothese. Daher müssen wir uns immer klar sein, was die entsprechende Nullhypothese zu unserer Fragestellung ist. Wenn du hier stockst, ist das ganz normal. Eine Fragestellung mit einer statistischen Hypothese zu verbinden ist nicht immer so einfach gemacht.
::: callout-important
## Die Nullhypothese $H_0$ und die Alternativhypothese $H_A$
Die Nullhypothese $H_0$ nennen wir auch die Null oder Gleichheitshypothese. Die Nullhypothese sagt aus, dass zwei Gruppen gleich sind oder aber kein Effekt zu beobachten ist.
$$
H_0: \bar{y}_{1} = \bar{y}_{2}
$$
Die Alternativhypothese $H_A$ oder $H_1$ auch Alternative genannt nennen wir auch Unterschiedshypothese. Die Alternativhypothese besagt, dass ein Unterschied vorliegt oder aber ein Effekt vorhanden ist.
$$
H_A: \bar{y}_{1} \neq \bar{y}_{2}
$$
:::
Als Veranschaulichung nehmen wir das Beispiel aus der unterschiedlichen Sprungweiten in \[cm\] für Hunde- und Katzenflöhe. Wir formulieren als erstes die Fragestellung. Eine Fragestellung endet mit einem Fragezeichen.
*Liegt ein Unterschied zwischen den Sprungweiten von Hunde- und Katzenflöhen vor?*
Wir können die Frage auch anders formulieren.
*Springen Hunde- und Katzenflöhe unterschiedlich weit?*
Wichtig ist, dass wir eine Fragestellung formulieren. Wir können auch mehrere Fragen an einen Datensatz haben. Das ist auch vollkommen normal. Nur hat *jede* Fragestellung ein eigenes Hypothesenpaar. Wir bleiben aber bei dem simplen Beispiel mit den Sprungweiten von Hunde- und Katzenflöhen.
Wie sieht nun die statistische Hypothese in diesem Beispiel aus? Wir wollen uns die Sprungweite in \[cm\] anschauen und entscheiden, ob die Sprungweite für Hunde- und Katzenflöhen sich unterscheidet. Eine statistische Hypothese ist eine Aussage über einen Parameter einer Population. Wir entscheiden jetzt, dass wir die *mittlere* Sprungweite der Hundeflöhe $\bar{y}_{dog}$ mit der *mittleren* Sprungweite der Katzenflöhe $\bar{y}_{cat}$ vergleichen wollen. Es ergibt sich daher folgendes Hypothesenpaar.
$$
\begin{aligned}
H_0: \bar{y}_{dog} &= \bar{y}_{cat} \\
H_A: \bar{y}_{dog} &\neq \bar{y}_{cat} \\
\end{aligned}
$$
Es ist wichtig sich in Erinnerung zu rufen, dass wir nur und ausschließlich Aussagen über die Nullhypothese treffen werden. Das *frequentistische* Hypothesentesten kann nichts anders. Wir kriegen keine Aussage über die Alternativhypothese sondern nur eine Abschätzung der Wahrscheinlichkeit des Auftretens der Daten im durchgeführten Experiment, wenn die Nullhypothese wahr wäre. Wenn die Nullhypothese war ist, dann liegt kein Effekt oder Unterschied vor. Das *Falisifkationsprinzip* - wir können nur Ablehnen - kommt hier zusammen mit der *frequentistischen Statistik* in der wir nur eine Wahrscheinlichkeitsaussage über das Auftreten der Daten $D$ - unter der Annahme $H_0$ gilt - treffen können.
## Die Testentscheidung...
In den folgenden Kapiteln werden wir verschiedene statistische Tests kennenlernen. Alle statistischen Tests haben gemein, dass ein Test eine Teststatistik $T_{D}$ aus den Daten $D$ berechnet. Darüber hinaus liefert jeder Test auch einen p-Wert (eng. *p-value*). Manche statistischen Test geben auch ein 95% Konfidenzintervall wieder. Eine Testentscheidung gegen die Nullhypothese $H_0$ kann mit jedem der drei statistischen Maßzahlen - Teststatistik $T_{D}$, $p$-Wert und 95% Konfidenzintervall - durchgeführt werden. Die Regel für die Entscheidung, ob die Nullhypothese $H_0$ abgelehnt werden kann, ist nur jeweils anders.
::: {layout="[15,85]" layout-valign="center"}
{fig-align="center" width="100%"}
> Streng genommen gilt die Regel $T_{D} \geq T_{\alpha = 5\%}$ nur für eine Auswahl an statistischen Tests siehe dazu auch @sec-teststatistik. Bei manchen statistischen Tests ist die Entscheidung gedreht. Hier lassen wir das aber mal so stehen...
:::
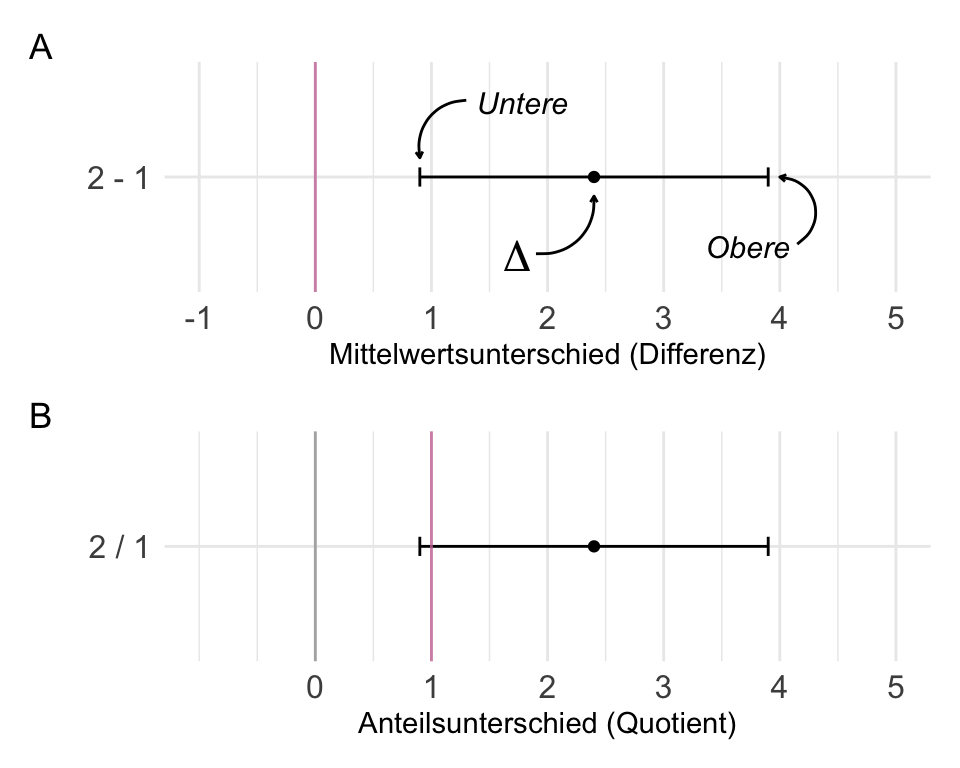
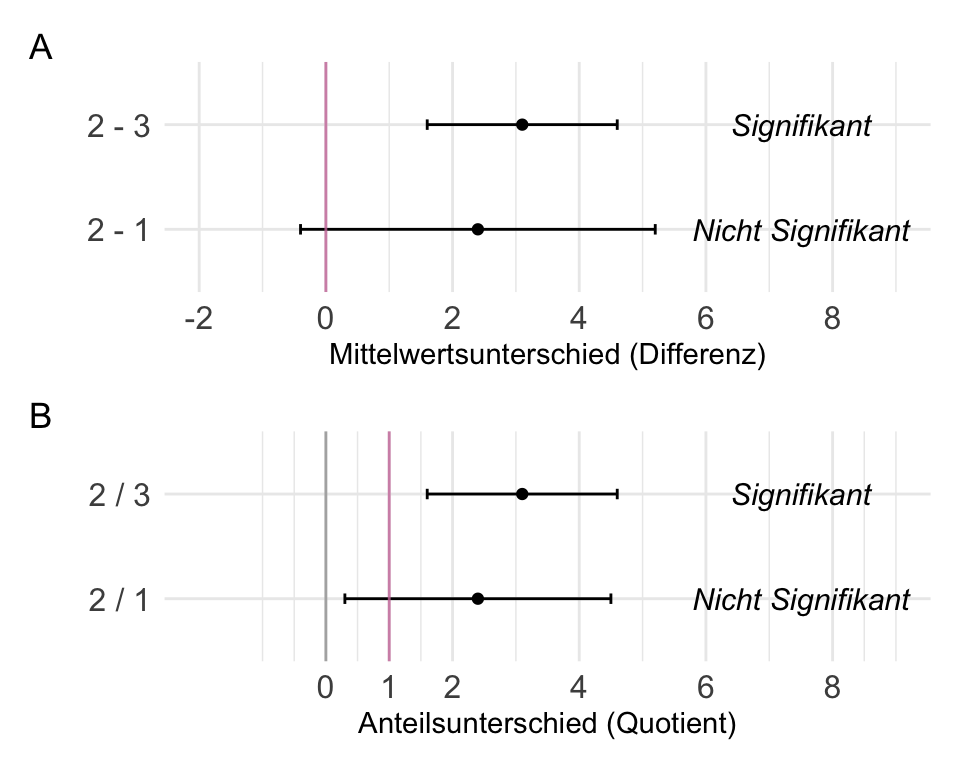
In @tbl-comp-t-p-ki sind die Entscheidungsregeln einmal zusammengefasst. Wir wollen in den folgenden Abschnitten die jeweiligen Entscheidungsregeln eines statistisches Tests anhand der Maßzahl Teststatistik, $p$-Wert und Konfidenzintervall einmal durchgehen. Die Entscheidung nach der Teststatistik ist veraltet und dient nur dem konzeptionellen Verständnisses. In der Forschung angewandt wird der $p$-Wert und das 95% Konfidenzintervall. Im Fall des 95% Konfidenzintervalls müssen wir noch unterschieden, ob wir einen Mittelwertsunterschied $\Delta_{A-B}$ oder aber einen Anteilsunterschied $\Delta_{A/B}$ betrachten.
| | **Teststatistik** | **p-Wert** | **95% Konfidenzintervall** |
|:--:|:--:|:--:|:--:|
| | $\boldsymbol{T_{D}}$ | $\boldsymbol{Pr(\geq T_{D}|H_0)}$ | $\boldsymbol{KI_{1-\alpha}}$ |
| H$_0$ ablehnen | $T_{D} \geq T_{\alpha = 5\%}$ | $Pr(\geq T_{D}| H_0) \leq \alpha$ | $\Delta_{A-B}$: enthält [*nicht*]{.underline} **0** oder $\Delta_{A/B}$: enthält [*nicht*]{.underline} **1** |
: Zusammenfassung der statistischen Testentscheidung unter der Nutzung der Teststatistik, dem p-Wert und dem 95% Konfidenzintervall. {#tbl-comp-t-p-ki}
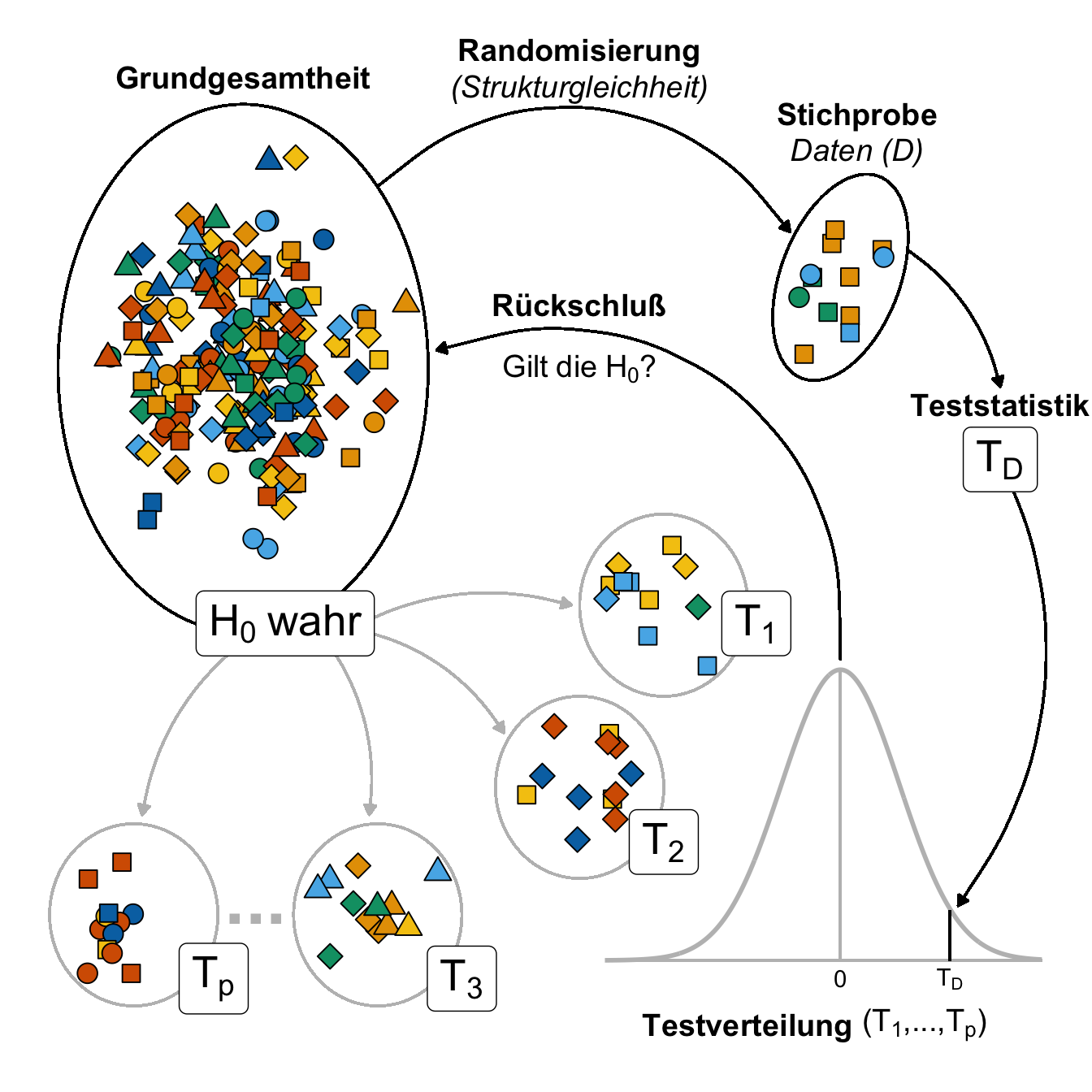
Dann kommen wir nochmal zu einer allgemeinen Übersicht in der @fig-test-preface-theory-01. Du kennst eine vereinfachte Abbildung schon aus dem vorherigen Kapitel zur Einführung in das Testen von Hypothesen. Was sich hier im Prinzip ändert ist der Vergleich zu der Testverteilung, wenn die $H_0$ wahr ist. Unsere Daten $D$ sind ja nur eine mögliche Repräsentation einer zufälligen Auswahl an Beobachtungen. Wir vergleichen dann unsere Daten über die Teststatistik $T_D$ mit allen möglichen Teststatistiken $T_1,..., T_p$ unter der Annahme, dass bei diesen Teststatistiken die Nullhypothese war ist und wir keinen Effekt in der Grundgesamtheit beobachten würden. Aus diesem Vergleich der Teststatistik mit der Verteilung der Teststatistiken unter der Null ziehen wir dann einen Rückschluss über die Gültigkeit der Nullhypothese $H_0$.
```{r}
#| echo: false
#| eval: true
#| message: false
#| warning: false
#| label: fig-test-preface-theory-01
#| fig-align: center
#| fig-height: 7
#| fig-width: 7
#| fig-cap: "Erweiterung der Übersichtsabbildung zum Prinzip des statistischen Testens mit Grundgesamtheit , Randomisierung zur Strukturgleichheit und Stichprobe. Die Daten $D$ in der Stichprobe werden über die Teststatistik $T_D$ mit der Testverteilung von Teststatisiken unter der Null verglichen. Dann kann ein Rückschluss über die Nullhypothese in der Grundgesamtheit über die berechnete Teststatistik $T_D$ getroffen werden. *[Zum Vergrößern anklicken]*"
p
```
### ... anhand der Teststatistik {#sec-teststatistik}
{{< video https://youtu.be/NXbfwE3xLUY >}}
Wir wollen uns dem frequentistischen Hypothesentesten über die Idee der Teststatistik annähern. Die Teststatistik kannst du einfach anhand einer mathematischen Formel ausrechnen. Dabei hat die Teststatistik den Vorteil, dass sie einheitslos ist. Egal ob du das Gewicht zwischen Elefanten \[t\] oder Hamstern \[g\] vergleichst, die Teststatistik wird immer ähnliche numerische Werte annehmen. Du kannst also Teststatistiken über verschiedene Experimente miteinander vergleichen.
Eigenschaften der Teststatistik $\boldsymbol{T_D}$ berechnet aus den Daten $D$
: - Die Teststatistik $T_D$ ist Null, wenn kein Unterschied vorliegt.
- Die Teststatistik $T_D$ hat keine Einheit. $T_D$ ist einheitslos.
- Die Teststatistik $T_D$ ist abhängig von der zu testenden deskriptiven Statistik. Jede deskriptive Statistik hat eine eigene Teststatistikformel.
Im Folgenden sehen wir die Formel für den t-Test, den wir dazu nutzen um zwei Mittelwerte miteinander zu vergleichen. Den t-Test werden wir im @sec-ttest uns nochmal detaillierter anschauen, hier deshalb nur die Formel mit der wir dann die Teststatistik erarbeiten und verstehen werden. Hier nutzen wir deshalb die vereinfachte Formel des Student t-Test um das Konzept der Teststatistik $T$ zu verstehen.
$$
T_{D}=\cfrac{\bar{y}_1-\bar{y}_2}{s_{p} \cdot \sqrt{2/n_g}}
$$
mit
- $\bar{y}_1$ dem Mittelwert für die erste Gruppe.
- $\bar{y}_2$ dem Mittelwert für die zweite Gruppe.
- $s_{p}$ der gepoolten Standardabweichung mit $s_p = \tfrac{s_1 + s_2}{2}$.
- $n_g$ der Gruppengröße der gruppen. Wir nehmen an beide Gruppen sind gleich groß.
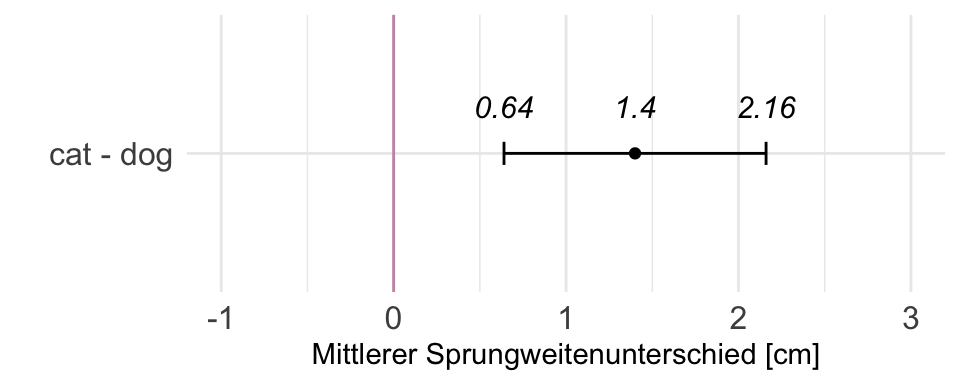
Zum Berechnen der Teststatistik $T_{D}$ aus den Daten $D$ benötigen wir also die zwei Mittelwerte $\bar{y}_1$ und $\bar{y}_2$ sowie deren gepoolte Standardabweichung $s_p$ und die Anzahl der Beobachtungen je Gruppe $n_g$. Im Folgenden wenden wir die Formel des t-Tests einmal auf einen kleinen Beispieldatensatz zu den Sprunglängen in \[cm\] von jeweils $n_g = 4$ Hunde- und Katzenflöhen an. Du siehst in der Formel, dass wir die Einheit \[cm\] dadurch verlieren, dass wir den Mittelwertsunterschied in \[cm\] durch die gepoolte Standardabweichung in \[cm\] teilen. Beide Maßzahlen haben die gleiche Einheit, so dass wir am Ende eine einheitslose Teststatistik $T_{D}$ vorliegen haben. In @tbl-dog-cat-small ist das Datenbeispiel gegeben.
::: panel-tabset
## Datentabelle
```{r}
#| echo: false
#| label: tbl-dog-cat-small
#| tbl-cap: Beispiel für die Berechnung von einem Mittelwertseffekt an der Sprunglänge [cm] von Hunde und Katzenflöhen.
data_tbl |>
kable(align = "c", "pipe")
mean_tbl <- data_tbl |>
group_by(animal) |>
summarise(mean_animal = round(mean(jump_length), 2),
sd_animal = round(sd(jump_length), 2))
mean_cat <- mean_tbl$mean_animal[1]
mean_dog <- mean_tbl$mean_animal[2]
sd_cat <- mean_tbl$sd_animal[1]
sd_dog <- mean_tbl$sd_animal[2]
sd_p <- (sd_cat + sd_dog)/2
t_calc <- round((mean_cat - mean_dog)/((sd_cat + sd_dog)/2 * sqrt(2/4)), 2)
t_k <- round(qt(0.025, 4, lower.tail=FALSE), 2)
```
## R (`tibble`)
Dann hier auch einmal die Werte der Datentabelle als Vektoren für Berechnungen in R. Ich brauche die Zahlen als Vektor um später schnell mal den Mittelwert und die Standardabweichung zu berechnen.
```{r}
dog_vec <- c(8.0, 7.2, 8.4, 7.5)
cat_vec <- c(8.5, 9.9, 8.9, 9.4)
```
Und dann hier nochmal als `tibble`, wie auch die Datentabelle aussieht. Dann kannst du auch alles in R mit der Funktion `t.test()` wie unten gezeigt nachrechnen.
```{r}
data_tbl <- tibble(animal = gl(2, 4, labels = c("dog", "cat")),
jump_length = c(dog_vec, cat_vec))
```
:::
Nun berechnen wir die Mittelwerte und die Standardabweichungen aus der obigen Datentabelle für die Sprungweiten getrennt für die Hunde- und Katzenflöhe. Die Werte setzen wir dann in die Formel ein und berechnen die Teststatistik $T_{D}$ aus unseren experimentellen Daten $D$.
::: panel-tabset
## Mathematik
$$
T_{D}=\cfrac{`r mean_cat`cm - `r mean_dog`cm}{\cfrac{(`r sd_cat`cm + `r sd_dog`cm)}{2} \cdot \sqrt{2/4}} = `r t_calc`
$$
mit
- $\bar{y}_{cat} = `r mean_cat`cm$ dem Mittelwert für die Gruppe *cat*.
- $\bar{y}_{dog} = `r mean_dog`cm$ dem Mittelwert für die Gruppe *dog*.
- $s_{cat} = `r sd_cat`cm$ die Standardabweichung für die Gruppe *cat*.
- $s_{dog} = `r sd_dog`cm$ die Standardabweichung für die Gruppe *dog*.
- $s_p = `r sd_p`cm$ der gepoolten Standardabweichung mit $s_p = \tfrac{`r sd_dog`cm + `r sd_cat`cm}{2}$.
- $n_g = 4$ der Gruppengröße der beiden Gruppen.
## R (Schritt für Schritt)
Hier dann einmal die Berechnung der Teststatistik $T_D$ aus den Daten Schritt für Schritt in R. Erst berechnen wie die gepoolte Standardabweichung `s_p` und setzen diese dann in die Formel ein.
```{r}
dog_vec <- c(8.0, 7.2, 8.4, 7.5)
cat_vec <- c(8.5, 9.9, 8.9, 9.4)
s_p <- (sd(cat_vec) + sd(dog_vec))/2
T_D <- (mean(cat_vec) - mean(dog_vec))/(s_p * sqrt(2/4))
```
Dann runden wir noch das Eregbnis der Teststatistik $T_D$ auf zwei Kommastellen für den besseren Vergleich.
```{r}
T_D |> round(2)
```
## R (Built-in)
Am Ende dann noch der einfache Weg mit der Funktion `t.test()` für die Berechnung der Teststatistik $T_D$ mit dem t-Test. Du findest hier den Wert der Teststatistik mit `t = -3.4685` vor. Das Minus kommt von der Berechnung Hund minus Katze. Ist aber für die Interpretation egal.
```{r}
t.test(jump_length ~ animal, data = data_tbl, var.equal = TRUE)
```
:::
Wir haben nun die Teststatistik $T_{D} = `r t_calc`$ aus unseren Daten berechnet. In der ganzen Rechnerei verliert man manchmal den Überblick. Erinnern wir uns, was wir eigentlich wollten. Die Frage war, ob sich die mittleren Sprungweiten der Hunde- und Katzenflöhe unterschieden. Wenn die $H_0$ wahr wäre, dann wäre der Unterschied $\Delta$ der beiden Mittelwerte der Hunde- und Katzenflöhe gleich Null. Oder nochmal in der Analogie der t-Test Formel, dann wäre im Zähler $\Delta = \bar{y}_{cat} - \bar{y}_{dog} = 0$. Wenn die Mittelwerte der Sprungweite \[cm\] der Hunde- und Katzenflöhe gleich wäre, dann wäre die berechnete Teststatistik $T_{D} = 0$, da im Zähler Null stehen würde. Die Differenz von zwei gleichen Zahlen ist Null.
Je größer die berechnete Teststatistik $T_{D}$ wird, desto unwahrscheinlicher ist es, dass die beiden Mittelwerte per Zufall gleich sind. Wie groß muss nun die berechnete Teststatistik $T_{D}$ werden damit wir die Nullhypothese ablehnen können?
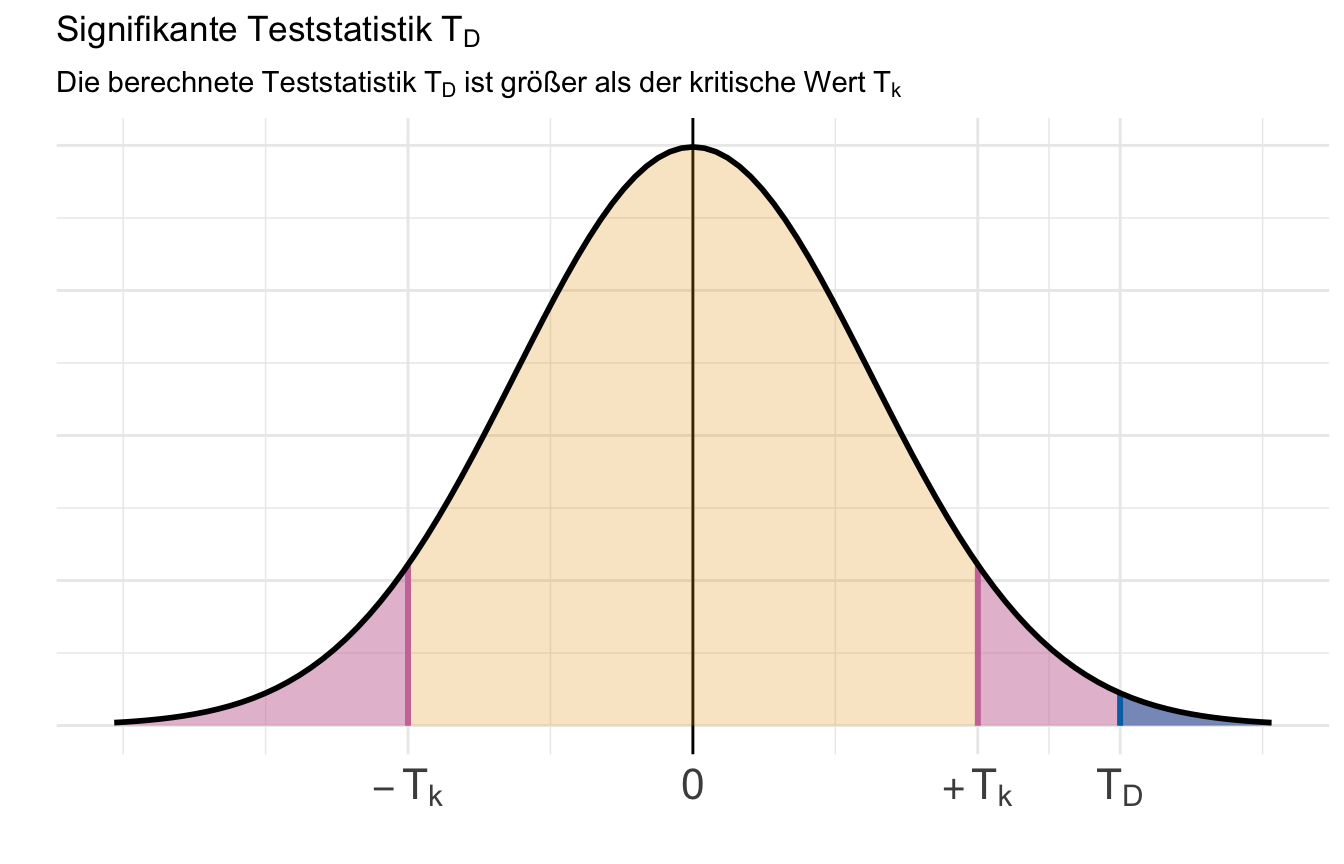
In @fig-test-basic-dist-01 ist die Verteilung aller möglichen $T_{D}$ Werte unter der Annahme, dass die Nullhypothese wahr ist, dargestellt. Wir sehen, dass die t-Verteilung den Gipfel bei $T_{D} = 0$ hat und niedrigere Werte mit steigenden Werten der Teststatistik annimmt. Wenn $T = 0$ ist, dann sind auch die Mittelwerte gleich. Je größer unsere berechnete Teststatistik $T_{D}$ wird, desto unwahrscheinlicher ist es, dass die Nullhypothese gilt.
Eigenschaften der Teststatistik $\boldsymbol{T_{\alpha = 5\%}}$ aus der Grundgesamtheit
: - Die Teststatistik $T_{\alpha = 5\%}$ ist der Grenzwert, wo noch die $H_0$ in der Grundgesamtheit gilt.
- Die Teststatistik $T_{\alpha = 5\%}$ beschreibt einen theoretischen Wert. Der Wert kann nicht biologisch interpretiert werden.
Die t-Verteilung ist so gebaut, dass die Fläche $A$ unter der Kurve gleich $A=1$ ist. Wir können nun den kritischen Wert $T_{\alpha = 5\%}$ berechnen an dem rechts von dem Wert eine Fläche von 0.05 oder 5% liegt. Somit liegt dann links von dem kritischen Wert die Fläche von 0.95 oder 95%. Den kritischen Wert $T_{\alpha = 5\%}$ können wir statistischen Tabellen entnehmen. Oder wir berechnen den kritischen Wert direkt in R mit $T_{\alpha = 5\%} = `r t_k`$.
```{r}
#| echo: false
#| message: false
#| warning: false
#| label: fig-test-basic-dist-01
#| fig-align: center
#| fig-height: 4.5
#| fig-width: 7
#| fig-cap: "Die t-Verteilung aller möglichen Teststatistiken $T$ wenn die Nullhypothese wahr ist zusammen mit einer signifikanten Teststaistik $T_{D}$. Wenn kein Effekt vorliegt sind die beiden Mittelwerte $\\bar{y}_1$ und $\\bar{y}_2$ in etwa gleich groß. Die Differenz der Mittelwerte wäre 0 und somit auch die Teststatistik $T$. Je größer der $T_{D}$ wird desto weniger können wir davon ausgehen, dass die beiden Mittelwerte gleich sind. Liegt der $T_{D}$ über dem kritischen Wert von $T_k$ dann können wir die Nullhypothese ablehnen. *[Zum Vergrößern anklicken]*"
ggplot(data.frame(x = c(-3.25, 3.25)), aes(x)) +
theme_minimal() +
geom_vline(xintercept = 0) +
stat_function(fun = dnorm, xlim = c(-1.6, 1.6),
geom = "area", fill = "#E69F00", alpha = 0.25) +
stat_function(fun = dnorm, xlim = c(-3.25, -1.6),
geom = "area", fill = "#CC79A7", alpha = 0.5) +
geom_segment(x = -1.6, y = 0, xend = -1.6, yend = 0.11, color = "#CC79A7",
linewidth = 1) +
stat_function(fun = dnorm, xlim = c(1.6, 3.25),
geom = "area", fill = "#CC79A7", alpha = 0.5) +
geom_segment(x = 1.6, y = 0, xend = 1.6, yend = 0.11, color = "#CC79A7",
linewidth = 1) +
geom_segment(x = 2.4, y = 0, xend = 2.4, yend = 0.022, color = "#0072B2",
linewidth = 1) +
stat_function(fun = dnorm, xlim = c(2.4, 3.25),
geom = "area", fill = "#0072B2", alpha = 0.5) +
stat_function(fun = dnorm, linewidth = 1) +
scale_x_continuous(breaks = c(-1.6, 0, 1.6, 2.4),
labels = c(expression(-T[alpha*'='*5*'%']),
expression(0),
expression(+T[alpha*'='*5*'%']),
expression(T[D]))) +
theme(axis.text = element_text(size = 16),
axis.text.y = element_blank()) +
labs(x = "", y = "",
title = expression(Signifikante~Teststatistik~T[D]),
subtitle = expression(Die~berechnete~Teststatistik~T[D]~ist~größer~als~der~kritische~Wert~T[alpha*'='*5*'%']))
```
Kommen wir zurück zu unserem Beispiel. Wir haben in unserem Datenbeispiel für den Vergleich von der Sprungweite in \[cm\] von Hunde- und Katzenflöhen eine Teststatistik von $T_{D} = `r t_calc`$ berechnet. Der kritische Wert um die Nullhypothese abzulehnen liegt bei $T_{\alpha = 5\%} = `r t_k`$. Wenn $T_{D} \geq T_{\alpha = 5\%}$ wird die Nullhypothese (H$_0$) abgelehnt. In unserem Fall ist $`r t_calc` \geq `r t_k`$. Wir können die Nullhypothese ablehnen. Es gibt einen Unterschied zwischen der mittleren Sprungweite von Hunde- und Katzenflöhen.
::: callout-caution
## Die Testverteilung $T$ der Grundgesamtheit, wenn $H_0$ gilt
{{< video https://youtu.be/gwoajXU_ey0 >}}
In diesem Exkurs wollen wir einmal überlegen, woher die Testverteilung $T$ herkommt, wenn die $H_0$ gilt. Wir wollen die Verteilung der Teststatistik einmal in R herleiten. Zuerst gehen wir davon aus, dass die Mittelwerte der Sprungweite der Hunde- und Katzenflöhe gleich sind $\bar{y}_{cat} = \bar{y}_{dog} = (9.18 + 7.78)/2 = 8.48$. Daher nehmen wir an, dass die Mittelwerte aus der gleichen Normalverteilung kommen. Wir ziehen also vier Sprungweiten jeweils für die Hunde- und Katzenflöhe aus einer Normalverteilung mit $\mathcal{N}(8.48, 0.57)$. Wir nutzen dafür die Funktion `rnorm()`. Anschließend berechnen wir die Teststatistik. Diesen Schritt wiederholen wir eintausend Mal.
```{r}
set.seed(20201021)
T_vec <- map_dbl(1:1000, function(...){
dog_vec <- rnorm(n = 4, mean = 8.48, sd = 0.57)
cat_vec <- rnorm(n = 4, mean = 8.48, sd = 0.57)
s_p <- (sd(cat_vec) + sd(dog_vec))/2
T_calc <- (mean(cat_vec) - mean(dog_vec))/(s_p * sqrt(2/4))
return(T_calc)
}) |> round(2)
```
Nachdem wir eintausend Mal die Teststatistik unter der $H_0$ berechnet haben, schauen wir uns die sortierten ersten 100 Werte der Teststatistik einmal an. Wir sehen, dass extrem kleine Teststatistiken bis sehr große Teststatistiken *zufällig* auftreten können, auch wenn die Mittelwerte für das Ziehen der Zahlen gleich waren.
```{r}
T_vec |> magrittr::extract(1:100) |> sort()
```
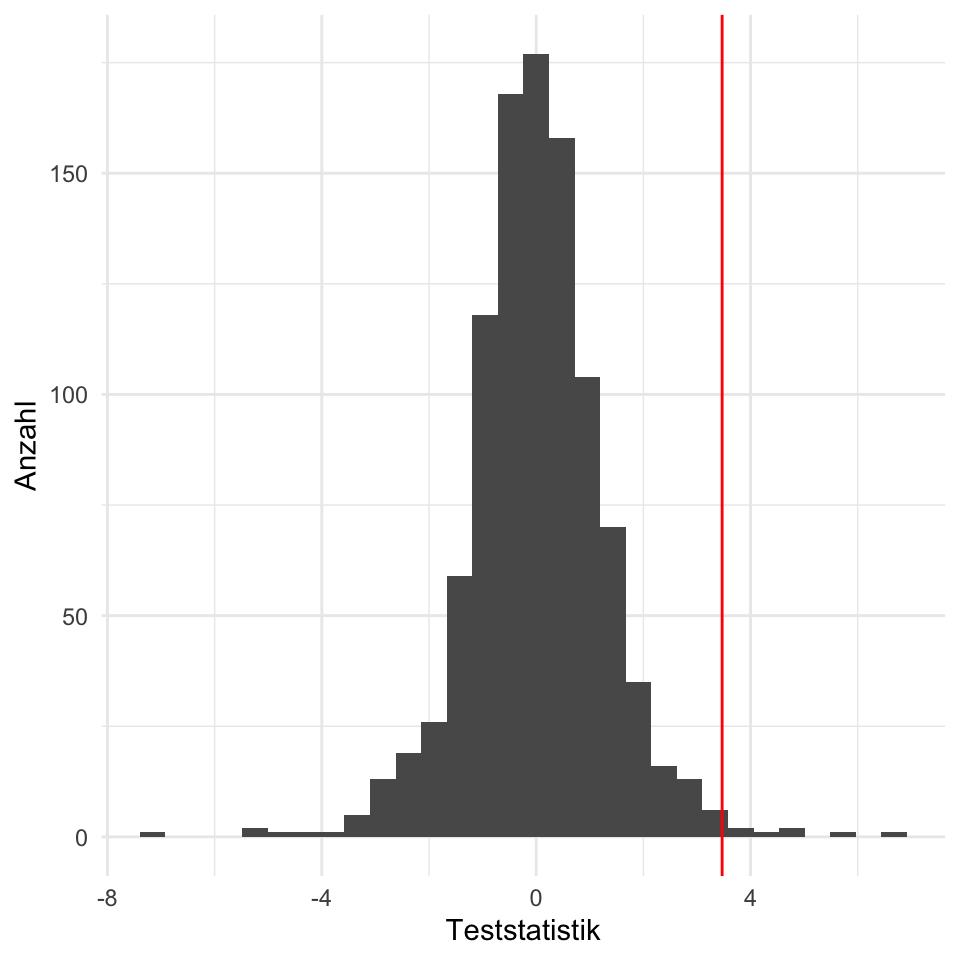
Unsere berechnete Teststatistik war $T_{D} = `r t_calc`$. Wenn wir diese Zahl mit den ersten einhundert, sortierten Teststatistiken vergleichen, dann sehen wir, dass nur 4 von 100 Zahlen größer sind als unsere berechnete Teststatistik. Wir beobachten also sehr seltene Daten wie in @tbl-dog-cat-small, wenn wir davon ausgehen, dass kein Unterschied zwischen der Sprungweite der Hunde- und Katzenflöhe vorliegt.
In @fig-test-basic-01 sehen wir die Verteilung der berechneten eintausend Verteilungen nochmal als ein Histogramm dargestellt. Wiederum sehen wir, dass unsere berechnete Teststatistik - dargestellt als rote Linie - sehr weit rechts am Rand der Verteilung liegt.
```{r}
#| echo: true
#| message: false
#| label: fig-test-basic-01
#| fig-align: center
#| fig-height: 5
#| fig-width: 5
#| fig-cap: "Histogramm der 1000 gerechneten Teststaistiken $T_{D}$, wenn die $H_0$ war wäre und somit kein Unterschied zwischen den Mittelwerten der Sprungweiten der Hunde- und Katzenflöhe vorliegen würde."
ggplot(as_tibble(T_vec), aes(x = value)) +
theme_minimal() +
labs(x = "Teststatistik", y = "Anzahl") +
geom_histogram() +
geom_vline(xintercept = 3.47, color = "red")
```
:::
Nun ist es leider so, dass jeder statistische Test seine eigene Teststatistik $T$ hat. Daher ist es etwas mühselig sich immer neue und andere kritische Werte für jeden Test zu merken. Es hat sich daher eingebürgert, sich nicht die Teststatistik für die Testentscheidung gegen die Nullhypothese zu nutzen sondern den $p$-Wert. Den $p$-Wert wollen wir uns in dem folgenden Abschnitt anschauen.
::: callout-note
## Entscheidung mit der berechneten Teststatistik
Bei der Entscheidung mit der Teststatistik müssen wir zwei Fälle unterschieden.
(1) Bei einem t-Test und einem $\mathcal{X}^2$-Test gilt, wenn $T_{D} \geq T_{\alpha = 5\%}$ wird die Nullhypothese (H$_0$) abgelehnt.
(2) Bei einem Wilcoxon-Mann-Whitney-Test gilt, wenn $T_{D} < T_{\alpha = 5\%}$ wird die Nullhypothese (H$_0$) abgelehnt.
**Achtung --** Wir nutzen die Entscheidung mit der Teststatistik *nur und ausschließlich* in der Klausur. In der praktischen Anwendung hat die Betrachtung der berechneten Teststatistik *keine* Verwendung mehr.
:::
### ... anhand des p-Wertes {#sec-pwert}
{{< video https://youtu.be/uW4Pj-gD-o0 >}}
In dem vorherigen Abschnitt haben wir gelernt, wie wir zu einer Entscheidung gegen die Nullhypothese anhand der Teststatistik kommen. Wir haben einen kritischen Wert $T_{\alpha = 5\%}$ definiert bei dem rechts von dem Wert 5% der Werte liegen. Anstatt nun den berechneten Wert $T_{D}$ mit dem kritischen Wert $T_{\alpha = 5\%}$ zu vergleichen, vergleichen wir jetzt die Flächen rechts von den jeweiligen Werten. Wir machen es uns an dieser Stelle etwas einfacher, denn wir nutzen immer den absoluten Wert der Teststatistik. Wir schreiben $\boldsymbol{Pr}$ und meinen damit eine Wahrscheinlichkeit (eng. *probability*). Häufig wird auch nur das $P$ verwendet, aber dann kommen wir wieder mit anderen Konzepten in die Quere.
Eigenschaften des $p$-Wertes
: - Der $p$-Wert ist die bedingte Wahrscheinlichkeit der Teststatistik $T_D$. Deshalb auch $p$-Wert für *p* gleich *probability*.
- Der $p$-Wert liefert somit *nur* eine Wahrscheinlichkeitsaussage.
- Der $p$-Wert ist die bedingte Wahrscheinlichkeit die Teststatistik $T_D$ zu beobachten, wenn in der Grundgesamtheit die $H_0$ gilt.
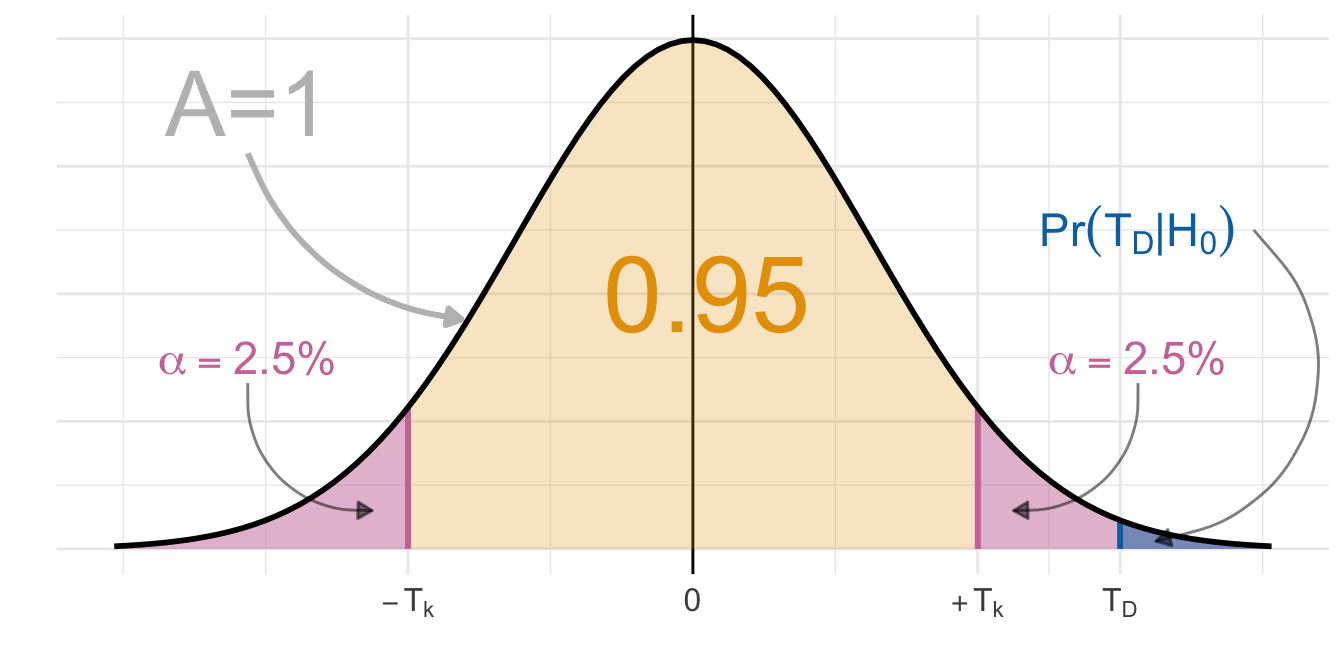
In @fig-test-basic-dist-01 sind die Flächen auch eingetragen. Da die gesamte Fläche unter der t-Verteilung mit $A = 1$ ist, können wir die Flächen auch als Wahrscheinlichkeiten lesen. Die Fläche rechts von der berechneten Teststatistik $T_{D}$ wird $Pr(T_{D}|H_0)$ oder $p$-Wert genannt. Die *gesamte* Fläche rechts von dem kritischen Wert $T_{\alpha = 5\%}$ wird $\alpha$ genannt und liegt bei 5%. Wir können also die Teststatistiken oder den p-Wert mit dem $\alpha$-Niveau von 5% vergleichen.
| Teststatistik $T$ | Fläche $A$ |
|:------------------:|:-----------------------------:|
| $T_{D}$ | $Pr(T_{D}|H_0)$ oder $p$-Wert |
| $T_{\alpha = 5\%}$ | $\alpha$ |
: Zusammenhang zwischen der Teststatistik $T$ und der Fläche $A$ rechts von der Teststatistik. Die Fläche rechts von der berechneten Teststatistik $T_{D}$ wird $Pr(T|H_0)$ oder $p$-Wert genannt. Die Fläche rechts von dem kritischen Wert $T_{\alpha = 5\%}$ wird $\alpha$ genannt und liegt bei 5%. {#tbl-t-und-A}
```{r}
#| echo: false
#| message: false
#| warning: false
#| label: fig-test-basic-dist-01b
#| fig-align: center
#| fig-height: 3.5
#| fig-width: 7
#| fig-cap: "Die t-Verteilung aller möglichen $T$ wenn die Nullhypothese wahr ist. Daher liegt kein Effekt vor und die beiden Mittelwerte $\\bar{y}_1$ und $\\bar{y}_2$ wären in etwa gleich groß. Die Differenz der Mittelwerte wäre 0. Je größer der $T_{D}$ wird desto weniger können wir davon ausgehen, dass die beiden Mittelwerte gleich sind. Liegt der $T_{D}$ über dem kritischen Wert von $T_{\\alpha = 5\\%}$ dann wir die Nullhypothese abgelehnt. *[Zum Vergrößern anklicken]*"
ggplot(data.frame(x = c(-3.25, 3.25)), aes(x)) +
theme_minimal() +
geom_vline(xintercept = 0) +
stat_function(fun = dnorm, xlim = c(-1.6, 1.6),
geom = "area", fill = "#E69F00", alpha = 0.25) +
stat_function(fun = dnorm, xlim = c(-3.25, -1.6),
geom = "area", fill = "#CC79A7", alpha = 0.5) +
geom_segment(x = -1.6, y = 0, xend = -1.6, yend = 0.11, color = "#CC79A7",
linewidth = 1) +
stat_function(fun = dnorm, xlim = c(1.6, 3.25),
geom = "area", fill = "#CC79A7", alpha = 0.5) +
geom_segment(x = 1.6, y = 0, xend = 1.6, yend = 0.11, color = "#CC79A7",
linewidth = 1) +
geom_segment(x = 2.4, y = 0, xend = 2.4, yend = 0.022, color = "#0072B2",
linewidth = 1) +
stat_function(fun = dnorm, xlim = c(2.4, 3.25),
geom = "area", fill = "#0072B2", alpha = 0.5) +
stat_function(fun = dnorm, linewidth = 1) +
scale_x_continuous(breaks = c(-1.6, 0, 1.6, 2.4),
labels = c(expression(-T[alpha*'='*5*'%']),
expression(0),
expression(+T[alpha*'='*5*'%']),
expression(T[D]))) +
annotate("text", x = 0.08, y = 0.2, label = expression(0.95), size = 14,
color = "#E69F00") +
annotate("text", x = -2.5, y = 0.15, label = expression(alpha==2.5*'%'), size = 6,
color = "#CC79A7") +
annotate("text", x = 2.5, y = 0.15, label = expression(alpha==2.5*'%'), size = 6,
color = "#CC79A7") +
annotate("text", x = 2.5, y = 0.25, label = expression(Pr(T[D]*'|'*H[0])), size = 6,
color = "#0072B2") +
geom_curve(x = -2.5, y = 0.13, xend = -1.8, yend = 0.03,
arrow = arrow(length = unit(0.03, "npc"), type = "closed"),
curvature = 0.5, color = "black", alpha = 0.3) +
geom_curve(x = 2.5, y = 0.13, xend = 1.8, yend = 0.03,
arrow = arrow(length = unit(0.03, "npc"), type = "closed"),
curvature = -0.5, color = "black", alpha = 0.3) +
geom_curve(x = 3.15, y = 0.25, xend = 2.6, yend = 0.006,
arrow = arrow(length = unit(0.03, "npc"), type = "closed"),
curvature = -0.7, color = "black", alpha = 0.3) +
annotate("text", x = -2.5, y = 0.35, label = "A=1", size = 12,
color = "gray") +
geom_curve(x = -2.5, y = 0.31, xend = -1.3, yend = 0.18,
arrow = arrow(length = unit(0.03, "npc"), type = "closed"),
curvature = 0.3, color = "gray", linewidth = 1) +
theme(axis.text = element_text(size = 12),
axis.text.y = element_blank()) +
labs(x = "", y = "")
```
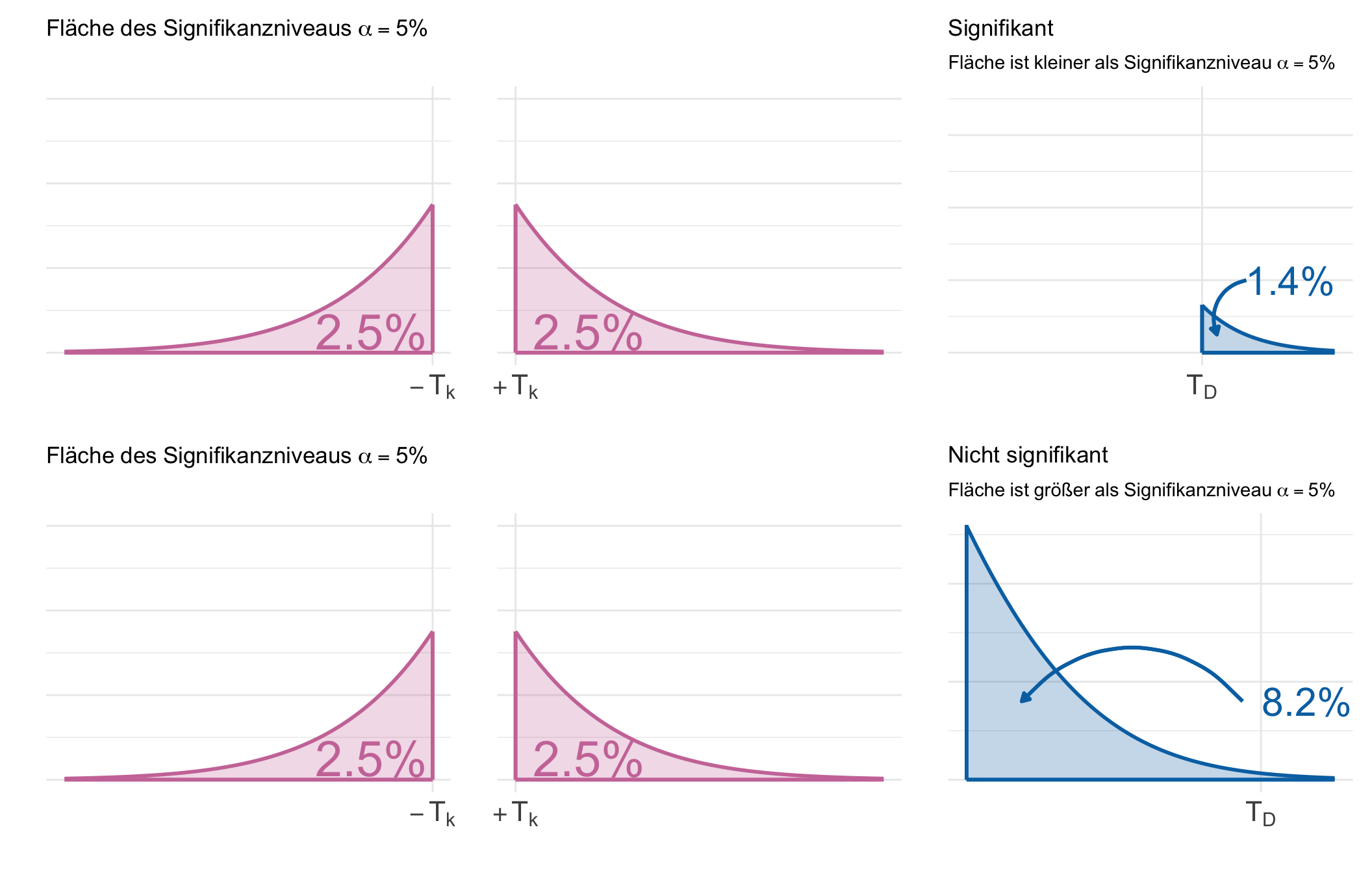
In der folgenden @fig-test-basic-dist-02 ist dann nochmal der Zusammenhang aus der Tabelle als eine Abbildung visualisiert. Mit dem $p$-Wert entscheiden wir anhand von *Flächen*. Wir schauen uns in diesem Fall die beiden Seiten der Testverteilung mit jeweils $T_{\alpha = 2.5\%}$ für $-T_K$ und $T_K$ an und vergleichen die Flächen rechts neben der berechneten Teststatistik $T_{D}$.
```{r}
#| echo: false
#| message: false
#| warning: false
#| label: fig-test-basic-dist-02
#| fig-align: center
#| fig-height: 7
#| fig-width: 11
#| fig-cap: "Wir vergleichen bei der Entscheidung mit dem $p$-Wert nicht die berechnete Teststatistik $T_{D}$ mit dem kritischen Wert $T_{\\alpha = 5\\%}$ sondern die Flächen rechts von den jeweiligen Teststatistiken mit $A_K = 5\\%$ und $A_{D}$ als den $p$-Wert. Die Flächen links und rechts von $T_{\\alpha = 2.5\\%}$ sind nochmal separat dargestellt. An dem Flächenvergleich machen wir dann die Testentscheidung fest. *[Zum Vergrößern anklicken]*"
p1 <- ggplot(data.frame(x = c(2.5, 4)), aes(x)) +
theme_minimal() +
stat_function(fun = dnorm, color = "#CC79A7", linewidth = 1, xlim = c(2.5, 4)) +
stat_function(fun = dnorm, xlim = c(2.5, 4),
geom = "area", fill = "#CC79A7", alpha = 0.25) +
geom_segment(x = 2.5, y = 0, xend = 4, yend = 0., color = "#CC79A7",
linewidth = 1) +
geom_segment(x = 2.5, y = 0, xend = 2.5, yend = 0.0175, color = "#CC79A7",
linewidth = 1) +
annotate("text", x = 2.8, y = 0.0025, label = "2.5%", size = 10,
color = "#CC79A7") +
theme(axis.text.y = element_blank(),
axis.text = element_text(size = 16)) +
scale_x_continuous(breaks = 2.5, label = expression(+T[alpha*'='*5*'%']),
limits = c(2.45, 4)) +
labs(x = "", y = "")
p2 <- ggplot(data.frame(x = c(-2.5, -4)), aes(x)) +
theme_minimal() +
stat_function(fun = dnorm, color = "#CC79A7", linewidth = 1, xlim = c(-2.5, -4)) +
stat_function(fun = dnorm, xlim = c(-2.5, -4),
geom = "area", fill = "#CC79A7", alpha = 0.25) +
geom_segment(x = -2.5, y = 0, xend = -4, yend = 0., color = "#CC79A7",
linewidth = 1) +
geom_segment(x = -2.5, y = 0, xend = -2.5, yend = 0.0175, color = "#CC79A7",
linewidth = 1) +
annotate("text", x = -2.75, y = 0.0025, label = "2.5%", size = 10,
color = "#CC79A7") +
theme(axis.text.y = element_blank(),
axis.text = element_text(size = 16)) +
scale_x_continuous(breaks = -2.5, label = expression(-T[alpha*'='*5*'%']),
limits = c(-4, -2.45)) +
labs(x = "", y = "",
title = expression(Fläche~des~Signifikanzniveaus~alpha==5*'%'))
p3 <- ggplot(data.frame(x = c(2.5, 4)), aes(x)) +
theme_minimal() +
stat_function(fun = dnorm, color = "#0072B2", linewidth = 1, xlim = c(3.1, 4)) +
stat_function(fun = dnorm, xlim = c(3.1, 4),
geom = "area", fill = "#0072B2", alpha = 0.25) +
geom_segment(x = 3.1, y = 0, xend = 4, yend = 0., color = "#0072B2",
linewidth = 1) +
geom_segment(x = 3.1, y = 0, xend = 3.1, yend = 0.0033, color = "#0072B2",
linewidth = 1) +
annotate("text", x = 3.7, y = 0.005, label = "1.4%", size = 8,
color = "#0072B2") +
geom_curve(x = 3.4, y = 0.005, xend = 3.2, yend = 0.00125,
arrow = arrow(length = unit(0.03, "npc"), type = "closed"),
curvature = 0.5, color = "#0072B2", alpha = 1,
linewidth = 1) +
theme(axis.text.y = element_blank(),
axis.text = element_text(size = 16)) +
scale_x_continuous(breaks = 3.1, label = expression(T[D]),
limits = c(1.5, 4)) +
scale_y_continuous(limits = c(0, 0.0175)) +
labs(x = "", y = "",
title = "Signifikant",
subtitle = expression(Fläche~ist~kleiner~als~Signifikanzniveau~alpha==5*'%'))
p4 <- ggplot(data.frame(x = c(1.5, 3.5)), aes(x)) +
theme_minimal() +
stat_function(fun = dnorm, color = "#0072B2", linewidth = 1, xlim = c(1.5, 4)) +
stat_function(fun = dnorm, xlim = c(1.5, 4),
geom = "area", fill = "#0072B2", alpha = 0.25) +
geom_segment(x = 1.5, y = 0, xend = 3.5, yend = 0., color = "#0072B2",
linewidth = 1) +
geom_segment(x = 1.5, y = 0, xend = 1.5, yend = 0.13, color = "#0072B2",
linewidth = 1) +
annotate("text", x = 3.35, y = 0.04, label = "8.2%", size = 8,
color = "#0072B2") +
geom_curve(x = 3, y = 0.04, xend = 1.8, yend = 0.04,
arrow = arrow(length = unit(0.03, "npc"), type = "closed"),
curvature = 0.5, color = "#0072B2", alpha = 1,
linewidth = 1) +
theme(axis.text.y = element_blank(),
axis.text = element_text(size = 16)) +
scale_x_continuous(breaks = 3.1, label = expression(T[D]),
limits = c(1.5, 3.5)) +
labs(x = "", y = "",
title = "Nicht signifikant",
subtitle = expression(Fläche~ist~größer~als~Signifikanzniveau~alpha==5*'%'))
p2 + scale_y_continuous(limits = c(0, 0.03)) +
p1 + scale_y_continuous(limits = c(0, 0.03)) +
p3 +
p2 + scale_y_continuous(limits = c(0, 0.03)) +
p1 + scale_y_continuous(limits = c(0, 0.03)) +
p4 +
plot_layout(ncol = 3)
```
Der p-Wert oder $Pr(T|H_0)$ ist eine Wahrscheinlichkeit. Eine Wahrscheinlichkeit kann die Zahlen von 0 bis 1 annehmen. Dabei sind die Grenzen einfach zu definieren. Eine Wahrscheinlichkeit von $Pr(A) = 0$ bedeutet, dass das Ereignis A nicht auftritt; eine Wahrscheinlichkeit von $Pr(A) = 1$ bedeutet, dass das Ereignis A eintritt. Der Zahlenraum dazwischen stellt jeden von uns schon vor große Herausforderungen. Der Unterschied zwischen 40% und 60% für den Eintritt des Ereignisses A sind nicht so klar zu definieren, wie du auf den ersten Blick meinen magst. Ein frequentistischer Hypothesentest beantwortet die Frage, mit welcher Wahrscheinlichkeit $Pr$ die Teststatistik $T$ aus dem Experiment mit den Daten $D$ zu beobachten wären, wenn es keinen Effekt gäbe ($H_0$ ist wahr).
In anderen Büchern liest man an dieser Stelle auch gerne etwas über die *Likelihood*, nicht so sehr in deutschen Büchern, schon aber in englischen Veröffentlichungen. Im Englischen gibt es die Begrifflichkeiten einer *Likelihood* und einer *Probability*. Meist wird beides ins Deutsche ungenau mit Wahrscheinlichkeit übersetzt oder wir nutzen einfach *Likelihood*. Was aber auch nicht so recht weiterhilft, wenn wir ein Wort mit dem gleichen Wort übersetzen. Es handelt sich hierbei aber um zwei unterschiedliche Konzepte. Deshalb Übersetzen wir *Likelihood* mit Plausibilität und *Probability* mit Wahrscheinlichkeit.
Im Folgenden berechnen wir den $p$-Wert in R mit der Funktion `t.test()`. Mehr dazu im @sec-ttest, wo wir den t-Test und deren Anwendung im Detail besprechen. Hier fällt der $p$-Wert etwas aus den Himmel. Wir wollen aber nicht per Hand Flächen unter einer Kurve berechnen sondern nutzen für die Berechnung von $p$-Werten statistische Tests in R.
```{r}
#| echo: false
data_tbl <- tibble(animal = gl(2, 4, labels = c("cat", "dog")),
jump_length = c(8.5, 9.9, 8.9, 9.4, 8.0, 7.2, 8.4, 7.5))
t.test(jump_length ~ animal, data = data_tbl, var.equal = TRUE) |>
tidy() |>
select(statistic, p.value)
```
Wir sagen, dass wir ein *signifikantes* Ergebnis haben, wenn der $p$-Wert kleiner ist als die Signifikanzschwelle $\alpha$ von 5%. Wenden wir also das Wissen einmal an. Wir erhalten einen $p$-Wert von 0.013 und vergleichen diesen Wert zu einem $\alpha$ von 5%. Ist der $p$-Wert kleiner als der $\alpha$-Wert von 5%, dann können wir die Nullhypothese ablehnen. Da 0.013 kleiner ist als 0.05 können wir die Nullhypothese und damit die Gleichheit der mittleren Sprungweiten in \[cm\] ablehnen. Wir sagen, dass wir ein signifikantes Ergebnis vorliegen haben.
::: callout-note
## Entscheidung mit dem p-Wert
Wenn der p-Wert $\leq \alpha$ dann wird die Nullhypothese (H$_0$) abgelehnt. Das Signifikanzniveau $\alpha$ wird als Kulturkonstante auf 5% oder 0.05 gesetzt. Die Nullhypothese (H$_0$) kann auch Gleichheitshypothese gesehen werden. Wenn die H$_0$ gilt, liegt kein Unterschied zwischen z.B. den Behandlungen vor.
:::
Manchmal willst du die p-Werte nicht nur einfach so darstellen sondern eben etwas schöner formatieren. Sehr kleine p-Werte könntest du auch runden oder aber als Sterne darstellen. Deshalb können wir folgende Funktionen in R nutzen um unsere p-Werte anders zu formatieren. Wenn du mehr dazu lesen willst, dann gibt es noch die Quelle von @aguinis2021reporting mit der wissenschaftlichen Veröffentlichung [On reporting and interpreting statistical significance and p values in medical research](https://pmc.ncbi.nlm.nih.gov/articles/PMC8005799/) oder aber du schaust in das Tutorium [How to report P values in journals](https://www.graphpad.com/support/faq/how-to-report-p-values-in-journals/).
::: panel-tabset
## `{base}`
In der Standardvariante können wir mit der Funktion `format.pval()` unsere p-Werte gut runden und ganz kleine p-Werte auf $<0.001$ setzen oder eben einen anderen Grenzwert wählen. Ich finde die Wahl mit der Anzahl an Kommastellen noch praktisch.
```{r}
p_val <- c(0.0004, 0.0015, 0.013, 0.044, 0.067, 0.24, 1)
format.pval(p_val, eps = 0.001, digits = 2)
```
## `{scales}`
Einiges mehr kann die Funktion `pvalue()` aus dem R Paket `{scales}`. Hier können wir auch einstellen, wann die p-Werte gerundet und als $<$ angegeben werden sollen. Darüber hinaus können wir noch die Kommastelle formatieren und einen Prefix wählen, wenn wir wollen.
```{r}
library(scales)
p_val <- c(0.0004, 0.0015, 0.013, 0.044, 0.067, 0.24, 1)
pvalue(p_val, accuracy = 0.001, decimal.mark = ".", prefix = NULL, add_p = FALSE)
```
## Sterne
Es gibt auch die Traditiion die Signifikanz durch Sterne darzustellen. Damit du das dann nicht selber bauen musst, die es die Funktion `stars.pval()` aus dem R Paket `{gtools}`, die für dich die Umwandlung von p-Werten in Sterne übernimmt. Da du dadurch aber den Vergleich der einzelnen p-Werte und deren Interpretation als Wahrscheinlichkeit verlierst, ist die Umwandlung mittlerweise umstritten.
```{r}
library(gtools)
p_val <- c(0.0004, 0.0015, 0.013, 0.044, 0.067, 0.24)
stars.pval(p_val)
```
:::
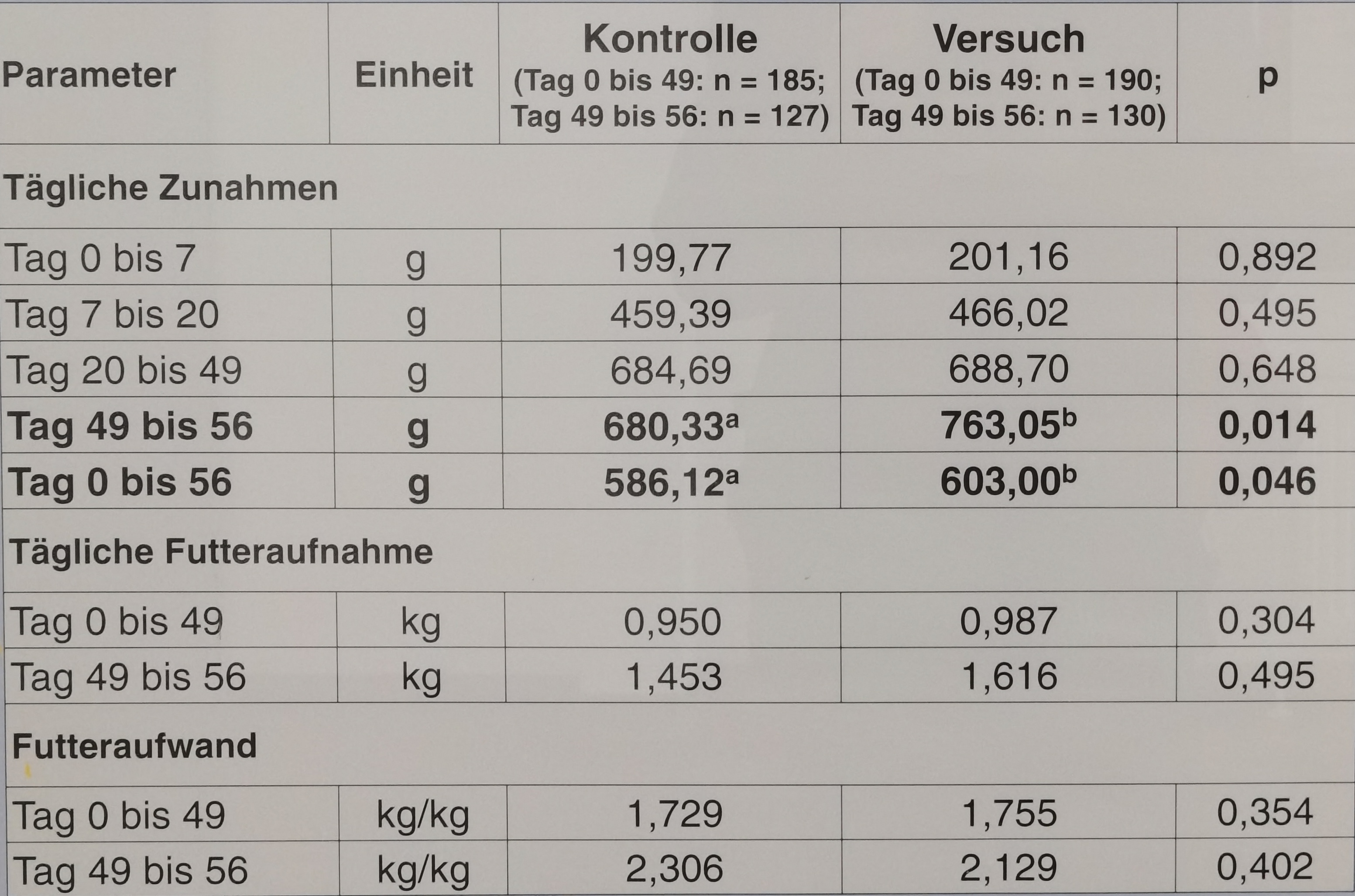
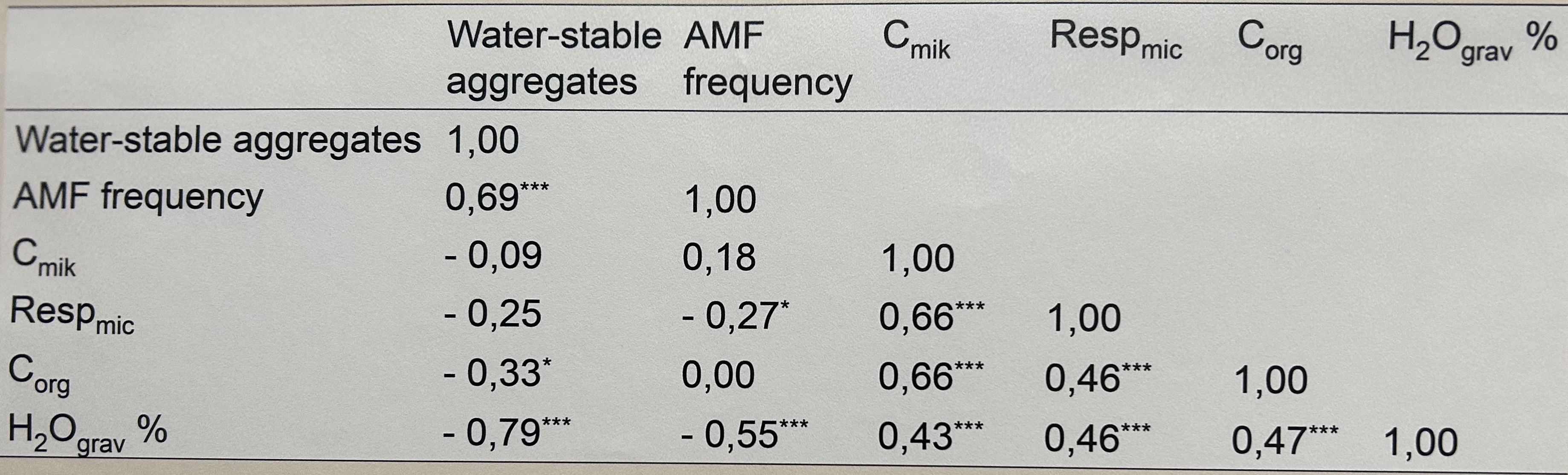
Im Folgenden möchte ich dir dann noch ein paar Beispiele der Verwendung des p-Wertes in der Praxis geben. Ich habe die Abbildungen zum Teil in der Hochschule Osnabrück gemacht. Hier siehst du dann einmal wie vielfältig dann der p-Wert auch dargestellt wird. Wir können den p-Wert als Zahl darstellen oder aber auch als Sterne `*` mit der entsprechenden Erklärung in der Überschrift. In Abbildungen wird dann auch gerne einmal eine Klammer über die Vergleiche gesetzt und an die Klammer die p-Werte oder die Sterne ergänzt.
::: panel-tabset
## Beispiel 1
![Darstellung der signifikanten Unterschiede in einem statistischen Modell anhand des p-Wertes. Hier sind die p-Werte als Zahl dargestellt und die signifikanten p-Werte fett hervorgehoben. *\[Zum Vergrößern anklicken\]*](images/eda/zerforschen_table_pvalue.jpg){#fig-pretest-barplot-02 fig-align="center" width="100%"}
## Beispiel 2
![Darstellung der signfifikanten Unterschiede in einer Korrelationsanalyse anhand der Darstellung mit Sternen für die Signifikanz. Je mehr Sterne, desto kleiner ist der entsprechende p-Wert. *\[Zum Vergrößern anklicken\]*](images/eda/zerforschen_corr_table.jpeg){#fig-pretest-barplot-01 fig-align="center" width="100%"}
## Beispiel 3
![Darstellung der signifikanten Unterschiede anhand eines Sterns `*` und der entsprechenden Erklärung in der Überschrift. Hier steht ein Stern allgemein für einen signifikanten Unterschied ohne weitere Staffelung. *\[Zum Vergrößern anklicken\]*](images/eda/zerforschen_table_pvalue_2.jpg){#fig-pretest-barplot-02 fig-align="center" width="100%"}
## Beispiel 4
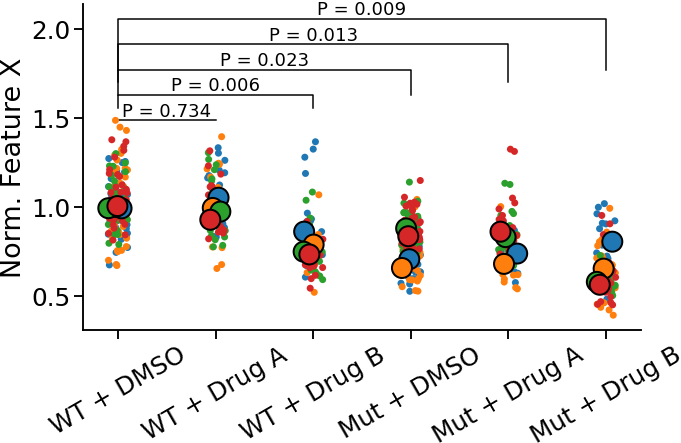
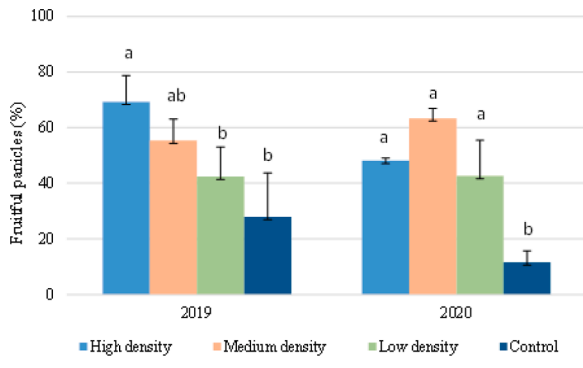
![Darstellung der paarweisen Unterschiede aller Gruppen zu der Kontrolle WT+DMSO. Hier sind die p-Werte über den vergleichenden Klammern als Zahl dargestellt. Die signifikanten Unterschiede zur Kontrolle müssen mit einem gewählten Signifikanzniveau ermittelt werden. *\[Zum Vergrößern anklicken\]*](images/eda/zerforschen_pvalue_3.png){#fig-pretest-barplot-02 fig-align="center" width="100%"}
:::
### ... anhand des S-Wertes {#sec-s-value}
Jetzt kommt mal was Neues in dem Sinne, dass wir hier mal eine neue statistische Maßzahl einführen, die es erst seit 2020 mit ursprünglichen Arbeit von @rafi2020semantic mit dem Titel [Semantic and cognitive tools to aid statistical science: replace confidence and significance by compatibility and surprise](https://bmcmedresmethodol.biomedcentral.com/articles/10.1186/s12874-020-01105-9) gibt. Wir führen hier den S-Wert (eng. *S-value*) oder auch Überrasschungswert (eng. *surprisal value*) ein. Wir wollen hier den p-Weret durch einen etwas intuitiveren Wert ablösen. Wir haben damit dann eine andere Zahl, die wir dann nicht mehr wie eine Wahrscheinlichkeit intepretieren.
::: callout-tip
## Mehr Literatur zum S-Wert
Zu dem S-Wert hat @rothman2021rothman in der Veröffentlichung [Rothman Responds to “Surprise!”](https://academic.oup.com/aje/article/190/2/194/5869592?login=false) nochmal einen eigenen Kommentar abgegeben. Es haben sich dann weitere Arbeiten angeschossen. Unter Anderem von @cole2021surprise und der Veröffentlichung [Surprise!](https://academic.oup.com/aje/article/190/2/191/5869593?login=false) sowie der Arbeit von @shafer2021testing und der entsprechenden Veröffentlichung [Testing by Betting: A Strategy for Statistical and Scientific Communication](https://academic.oup.com/jrsssa/article/184/2/407/7056412?login=false#396831406). Darüber hinaus gibt es auch noch von @mansournia2022p die Veröffentlichung [P-value, compatibility, and S-value](https://www.sciencedirect.com/science/article/pii/S2590113322000153#bi0005). Alle drei gemeinsam arbeiten das Problem des p-Wertes und deren Interpretierbarkeit ab. Am Ende möchte ich hier auch nicht die Kritik am S-Wert auslassen. In dem Blogpost [‘S-values’, ‘p-values’ and conceptualising statistics](https://corplingstats.wordpress.com/2020/11/02/s-values/) wird nochmal auf die Probleme des S-Wertes eingegangen. Auch wird hier nochmal sehr viel Hintergrund zum statistsichen Testen gegeben, was jetzt nicht jeder braucht um den S-Wert zu interpretieren.
:::
Kommen wir erstmal zur mathematischen Beschreibung des $S$-Wertes. Dabei ist der S-Wert eine logarithmische Transformation des p-Wertes. Das klingt jetzt erstmal komplizierter als es ist. Wir berechnen den S-Wert wie folgt.
$$
\mbox{S-value} = -\log_2(\mbox{p-value})
$$
mit
- $p-value$, dem berechnteten p-Wert aus einem statistsichen Test oder Modell
- $-\log_2$, dem negativen binären Logarithmus
Damit können wir jeden p-Wert in einen S-Wert übersetzen indem wir einfach den p-Wert transformieren. Warum sollten wir das tun? Da der p-Wert eine bedingte Wahrscheinlichkeit ist, haben wir häufig Probleme den p-Wert intuitiv zu interpretieren. Hier kann dann der S-Wert helfen, der eben durch die Transformation keine Wahrscheinlichkeit mehr ist.
Eigenschaften des $S$-Wertes
: - Der $S$-Wert hat eine intuitive Interpretation, die auf der Beobachtung aller Köpfwürfe bei einem fairen Münzwurf beruht.
- Der S-Wert entspricht der Anzahl aufeinanderfolgender "Kopf"-Würfe.
- Der $S$-Wert ist *keine* Wahrscheinlichkeit und liegt damit *nicht* im Intervall $[0,1]$.
- Der $S$-Wert beschreibt damit eine Anzahl oder Bits an Informationen.
Beginnen wir also eimal damit den S-Wert im Sinne des fairen Münzwurf zu interpretieren. Dabei gelten folgende Hypothesen für unsere Überlegung. Wir haben eine vermutlich faire Münze. Wenn wir jetzt diese Münze werfen, dann können wir Zahl oder Kopf erhalten. Wenn die Münze fair ist, dann müssen wir bei wiederholten Werfend er Münze in 50% der Fälle Zahl und in 50% der Fälle Kopf erhalten. Oder etwas anders ausgedrückt, die Wahrscheinlichkeit $Pr(Kopf)$ ist gleich 0.5 über die Anzahl an Würfen. Damit ergibt sich folgendes Hypothesenpaar. Die Nullhypothese beinhaltet wiederum die Gleichheit.
$$
\begin{aligned}
H_0 &= \mbox{Die Münze ist fair, es gilt}\; Pr(Kopf) = 0.5\\
H_A &= \mbox{Die Münze ist unfair, es gilt}\; Pr(Kopf) \neq 0.5
\end{aligned}
$$
Jetzt können wir uns den Zusammenhang von S-Wert und der Wahrscheinlichkeit Kopf zu werfen einmal in der folgenden Abbildung anschauen. Die Wahrscheinlichkeit einmal Kopf zu werfen $Pr(Kopf)$ ist $\tfrac{1}{2}$. Zweimal Kopf zu werden ist dann schon $\tfrac{1}{2} \cdot \tfrac{1}{2}$ gleich 0.25. Die Wahrscheinlichkeit sinkt mehrfach Kopf hintereinander zu werfen. Diese Anzahl an Kopf nacheinander ist der S-Wert. Der S-Wert ist damit die übersetzte Wahrscheinlichkeit des p-Wertes in die Anzahl aufeinanderfolgender "Kopf"-Würfe.
```{r}
#| echo: false
#| eval: true
#| message: false
#| warning: false
#| label: fig-theo-s-value-coin
#| fig-align: center
#| fig-height: 4
#| fig-width: 7
#| fig-cap: "Der S-Wert beschreibt die Anzahl an nacheinander geworfenen Kopf bei einem Münzwurf. Der S-Wert ist damit die übersetzte Wahrscheinlichkeit des p-Wertes in eine Anzahl an Kopf hintereinander. *[Zum Vergrößern anklicken]*"
library(emojifont)
ggplot(tibble(x = 1:4, y = 1:4), aes(x,y)) +
theme_void() +
geom_emoji("slightly_smiling_face", x = 2.5, y = 4, color = "black", size = 20) +
geom_emoji("slightly_smiling_face", x = c(2,3), y = 3, color = "black", size = 20) +
geom_emoji("slightly_smiling_face", x = c(1.5, 2.5, 3.5), y = 2, color = "black", size = 20) +
geom_emoji("slightly_smiling_face", x = 1:4, y = 1, color = "black", size = 20) +
annotate("text", x = 5.5, y = 4:1,
label = c(expression(frac(1, 2)~"="~0.5),
expression(frac(1, 2) %.% frac(1, 2)~"="~0.25),
expression(frac(1, 2) %.% frac(1, 2) %.% frac(1, 2)~"="~0.125),
expression(frac(1, 2) %.% frac(1, 2) %.% frac(1, 2) %.% frac(1, 2)~"="~0.0625))) +
annotate("text", x = 0.1, y = 4:1, label = c("S-value = 1", "S-value = 2",
"S-value = 3", "S-value = 4"),
fontface = 2, size = 4) +
scale_x_continuous(limits = c(-0.1, 6)) +
scale_y_continuous(limits = c(0.5, 4.5)) +
labs(title = "Der S-Wert und der Münzwurf",
subtitle = "S-Wert und Wahrscheinlichkeit Kopf nacheinander zu werfen") +
theme(plot.title = element_text(size = 17),
plot.subtitle = element_text(size = 12, face = "italic"))
```
Ein p-Wert von $0.05$ entspricht somit ungefähr einem S-Wert von 4. Wenn wir also viermal hintereinander Kopf werfen, dann sind wir langsam skeptisch, ob unsere Münze noch fair ist und wir die Nullhypothese beibehalten können. Den Zusammenhang habe ich dir nochmal in der folgenden Tabelle dargestellt. Du findest einmal die Teststatistik $T_D$ der Daten. Je größer $T_D$ desto kleiner der entsprechende p-Wert. Der S-Wert wiederum spiegelt jetzt auch den Trend in der Teststatistik wieder.
```{r}
#| echo: false
#| message: false
#| warning: false
#| label: tbl-t-p-s
#| tbl-cap: "Zusammenhang zwischen der Teststatistik $T_D$ der Daten, dem entsprechenden p-Wert sowie den berechneten S-Wert. Der S-Wert kann als Anzahl Kopf nacheinander bei einem Münzwurf interpretiert werden."
tibble(t = c(1, 1.96, 3, 4),
p = pt(t, Inf, lower.tail = FALSE) * 2,
s = -log2(p)) |>
mutate(p = round(p, 4),
s = round(s)) |>
set_names(c("Teststatistik $T_D$", "p-Wert", "S-Wert")) |>
tt(width = 1, align = "c", theme = "striped")
```
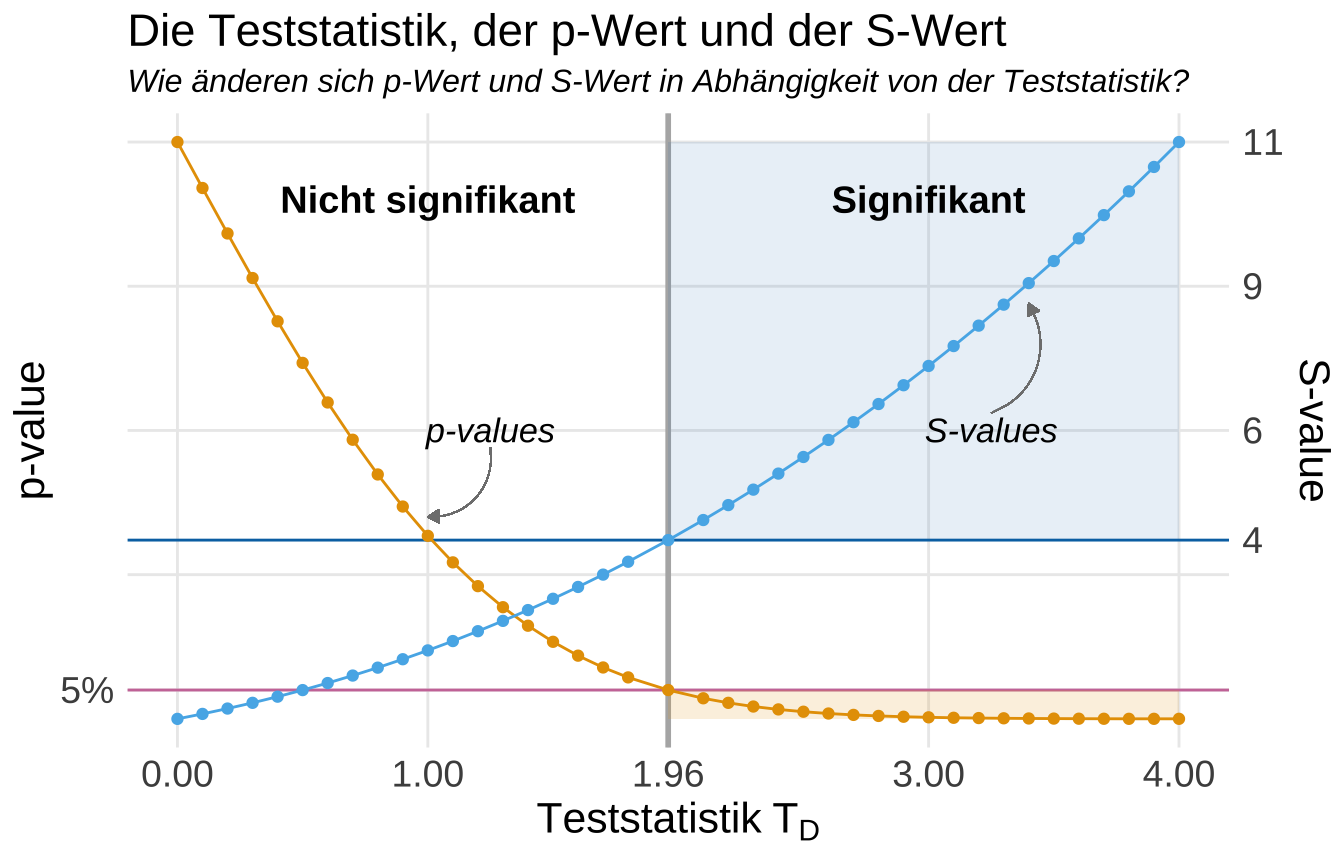
Ja und dann kann man sich das alles auch visualisieren um eine Idee davon zu bekommen wie die Teststatistik $T_D$ deiner Daten und die p-Werte sowie die S-Werte miteinander zusammenhängen. In der folgenden Abbidlung habe ich das einmal gemacht. Wenn die Teststatistik $T_D$ kleiner als 1.96 ist, dann ist die Teststatistik nicht signifikant. Damit ist dann auch der p-Wert nicht signifikant und der S-Wert auch nicht. Wie du siehst fällt der p-Wert mit steigender Teststatistik $T_D$. Gleichsam steigt der S-Wert an.
```{r}
#| echo: false
#| eval: true
#| message: false
#| warning: false
#| label: fig-theo-s-value
#| fig-align: center
#| fig-height: 4.5
#| fig-width: 7
#| fig-cap: "Zusammenhang zwischen der Teststatistik $T_D$ der Daten und dem p-Wert sowie dem S-Wert. Die Signifikanzgrenze $T_{\\alpha=5\\%}$ ist hier bei 1.96 gesetzt. Damit sind p-Werte kleiner als 5% signifikant wie auch S-Werte größer als 4 signifikant. *[Zum Vergrößern anklicken]*"
s_tbl <- tibble(t = sort(c(seq(0, 4, by = 0.1), 1.96)),
p = pt(t, Inf, lower.tail = FALSE)*2,
s = -log2(p),
s_y = s/(max(s))) |>
mutate_if(is.numeric, round, 4) |>
filter(t != 2.0 & t != 1.9) |>
pivot_longer(cols = c("p", "s_y"),
values_to = "values",
names_to = "grp") |>
mutate(grp = factor(grp, labels = c("p-value", "S-value")))
ggplot(s_tbl, aes(t, values, color = grp)) +
theme_minimal() +
geom_hline(yintercept = 0.05, color = "#CC79A7", linetype = 1) +
geom_hline(yintercept = 0.3099, color = "#0072B2", linetype = 1) +
geom_vline(xintercept = 1.96, color = "gray70", linetype = 1, size = 1) +
annotate("rect", xmin = 1.96, xmax = 4, ymin = 0, ymax = 0.05, fill="#E69F00", alpha = 0.15) +
annotate("rect", xmin = 1.96, xmax = 4, ymin = 0.3099, ymax = 1, fill="#0072B2", alpha = 0.1) +
geom_point() +
geom_line() +
scale_y_continuous(sec.axis = sec_axis(name = "S-value", ~ . * 11.47,
breaks = c(0.3099, 0.5, 0.75, 1) * 11.47,
labels = round(c(0.3099, 0.5, 0.75, 1) * 11.47)),
breaks = c(0.05, 0.25, 0.5, 0.75, 1),
labels = c("5%", "", "", "", "")) +
scale_x_continuous(breaks = c(0, 1, 1.96, 3, 4)) +
annotate("text", x = c(1, 3), y = 0.9, label = c("Nicht signifikant", "Signifikant"),
size = 5, fontface = 2) +
annotate("text", x = c(1.25, 3.25), y = 0.5, label = c("p-values", "S-values"),
size = 4.5, fontface = 3) +
geom_curve(x = 1.25, y = 0.47, xend = 1, yend = 0.35, linewidth = 0.25,
arrow = arrow(length = unit(0.02, "npc"), type = "closed"),
curvature = -0.5, color = "gray50") +
geom_curve(x = 3.25, y = 0.53, xend = 3.4, yend = 0.72, linewidth = 0.25,
arrow = arrow(length = unit(0.02, "npc"), type = "closed"),
curvature = 0.5, color = "gray50") +
scale_color_okabeito() +
labs(x = expression(Teststatistik~T[D]),
y = "p-value", color = "", title = "Die Teststatistik, der p-Wert und der S-Wert",
subtitle = "Wie änderen sich p-Wert und S-Wert in Abhängigkeit von der Teststatistik?") +
theme(legend.text = element_text(size = 14),
legend.title = element_text(size = 14, face = 2),
axis.text.y = element_text(size = 14),
axis.title.x = element_text(size = 16),
axis.title.y = element_text(size = 16),
axis.text.x = element_text(size = 14),
plot.title = element_text(size = 17),
plot.subtitle = element_text(size = 12, face = "italic"),
plot.caption = element_text(size = 12),
legend.position = "none",
panel.grid.minor.y = element_blank(),
panel.grid.minor.x = element_blank())
```
In dem R Paket `{marginaleffects}` sind die S-Werte mit in der Ausgabe von Funktionen implementiert. Sonst müssen wir noch die S-Werte aus den p-Werten händisch selber berechnen, was aber auch nicht so das Problem ist. Wir können ja einfach mit der Funktion `mutate()` und `log2()` uns die S-Werte selber bauen.
```{r}
tibble(p_value = c(0.05, 2.3e-3, 0.23, 0.01)) |>
mutate(S_value = -log2(p_value))
```
Ganz konkret haben wir ja in unserem Beispiel mit den Hunde- und Katzenflöhen einen p-Wert von 0.0133 erhalten. Jetzt können wir einfach $-\log_2(0.0133)$ rechnen um einen S-Wert von 6.23 zu erhalten. Wenn unsere Hunde- und Katzenflöhe gleich weit springen würden, dann wäre das gleich wahrscheinlich, wie sechsmal hintereinander Kopf zu werfen. So oft Kopf hintereinander spricht nicht für die Nullhypothese.
### ... anhand des *Compact letter display* {#sec-compact-letter-short}
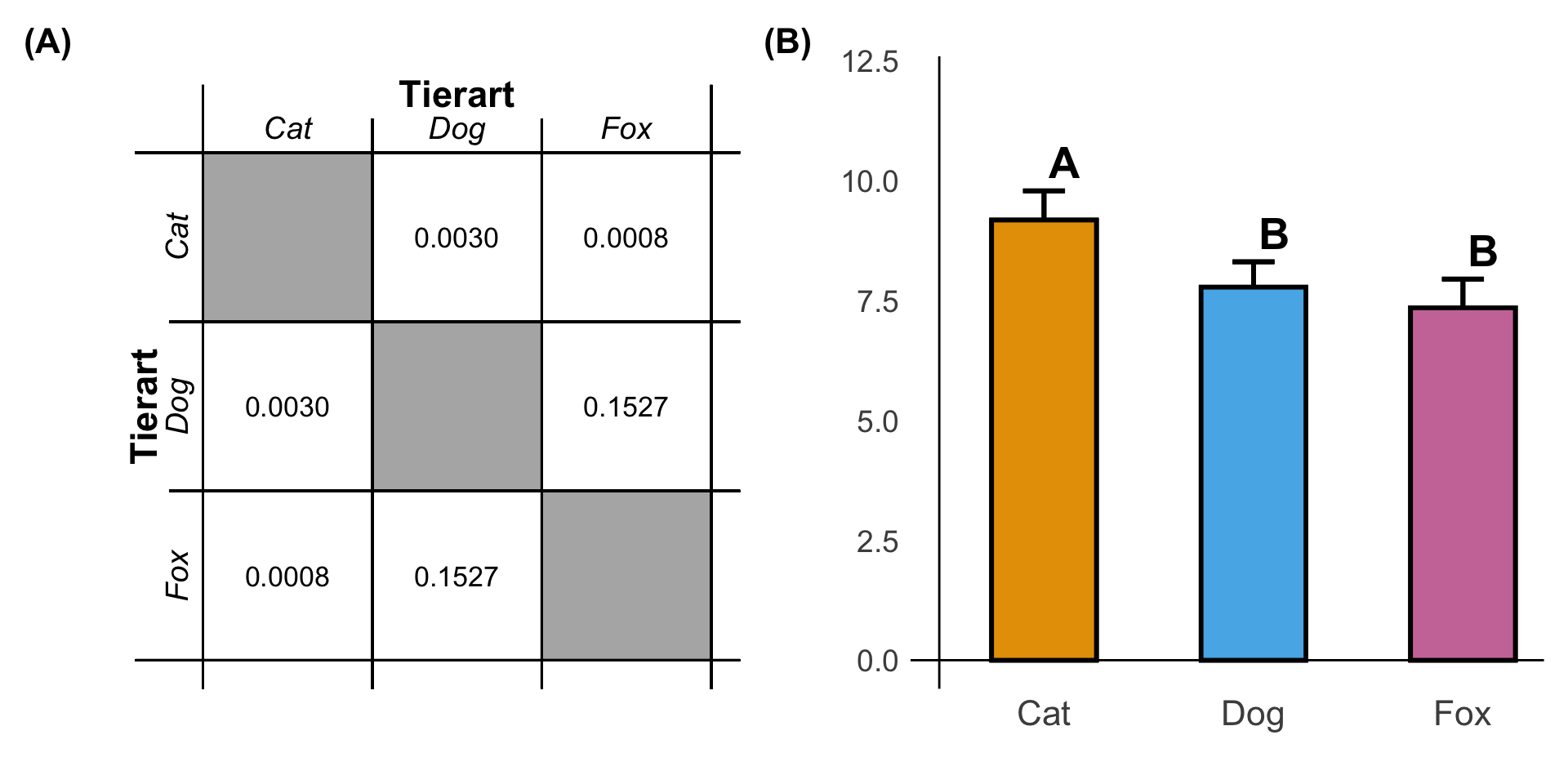
Eine weitere Möglichkeit die Visualisierung der Daten mit einer Aussage zur Signifikanz zu verbinden ist das *Compact letter display* (abk. *CLD*). Das Verfahren wurde von @piepho2004algorithm entwickelt und ist noch relativ jung. Für das *Compact letter display* gibt es keine entsprechende deutsche Übersetzung, so dass wir hier dann mit dem Denglisch leben müssen. Mehr zu der Implementierung des *Compact letter display* in R findest du im entsprechenden weiterführenden [Kapitel zum Post-hoc-Test](#sec-posthoc). Die Interpretation des *Compact letter display* ist auf den ersten Blick noch intuitiver als der $p$-Wert.
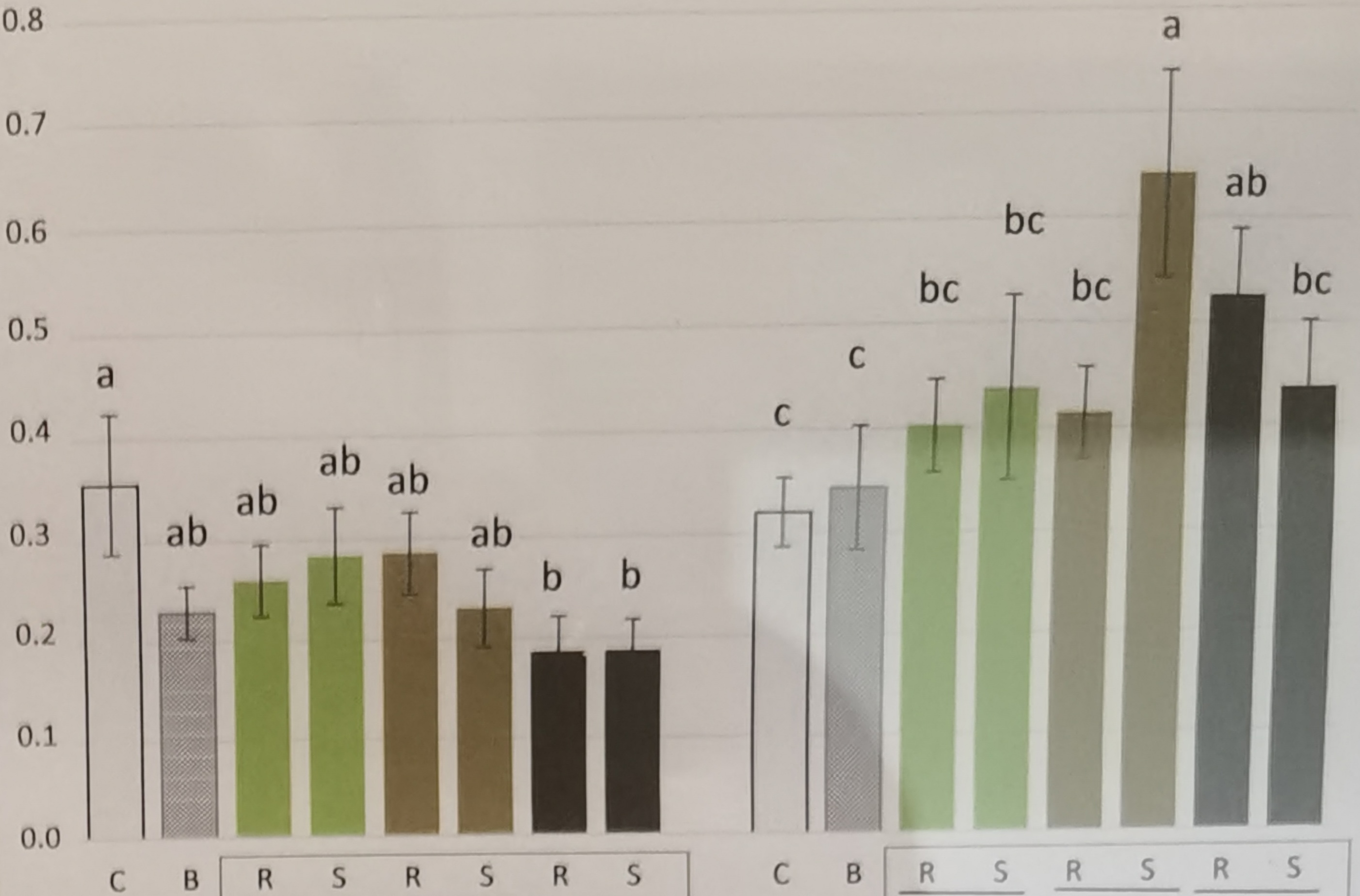
Wir schauen bei *Compact letter display*, ob zwei Gruppen sich den gleichen Buchstaben teilen. Wenn dies der Fall ist, dann unterscheiden sich die Gruppen nicht voneinander. Die Sache wird dadurch komplizierter, dass wir meistens nicht nur zwei Gruppen miteinander vergleichen sondern gleich mehrere Gruppen. Dadurch ergeben sich dann Sonderfälle bei den Buchstaben. Darüber hinaus basiert das *Compact letter display* dennoch auf $p$-Werten, so dass wir hier ein Verfahren mit zwei Schritten vorliegen haben. Erst berechnen wir wieder unsere $p$-Werte mit einem statistischen Test und dann können wir das *Compact letter display* für die Vergleiche bestimmen. Gerne ergänzen wir Barplots mit den entsprechenden Buchstaben aus einem *Compact letter display*.
In den folgenden Tabs gehe ich dann einmal auf die Theorie und die Sonderfälle mit geteilten Buchstaben beim *Compact letter display* ein. Dann rechnen wir nochmal die $p$-Werte für einen multipen Vergleich mit mehreren Tierarten anhand der Sprunglänge durch. Dadurch wird dir vielleicht nochmal klarer, wie das *Compact letter display* funktioniert.
::: panel-tabset
## Theoretisch
Betrachten wir einmal das *Compact letter display* aus einem theoretischen Blickwinkel. Wir haben drei Gruppen vorliegen und wollen wissen, ob ein Unterschied zwischen den Gruppen vorliegt. Jede der Gruppen wollen wir in einem Barplot mit einem Buchstaben versehen. Dafür brauchen wir dann auch die Matrix der p-Werte aller Gruppenvergleiche zwischen den drei Gruppen. Betrachten wir also folgende Fälle für das *Compact letter display*.
1) In der @fig-barplot-compact-01 sehen wir ein *Compact letter display* mit keinem signifikanten Unterschied zwischen den Gruppen. Wir können die Nullhypothese nicht ablehnen.
2) In der @fig-barplot-compact-02 sehen wir ein *Compact letter display* mit signifikanten Unterschieden zwischen den Gruppen. Wir können die Nullhypothese für alle Vergleiche ablehnen.
3) In der @fig-barplot-compact-03 sehen wir ein *Compact letter display* mit signifikanten und nicht signifikanten Unterschieden zwischen den Gruppen. Wir können die Nullhypothese für alle Vergleiche mal ablehnen und mal nicht ablehnen.
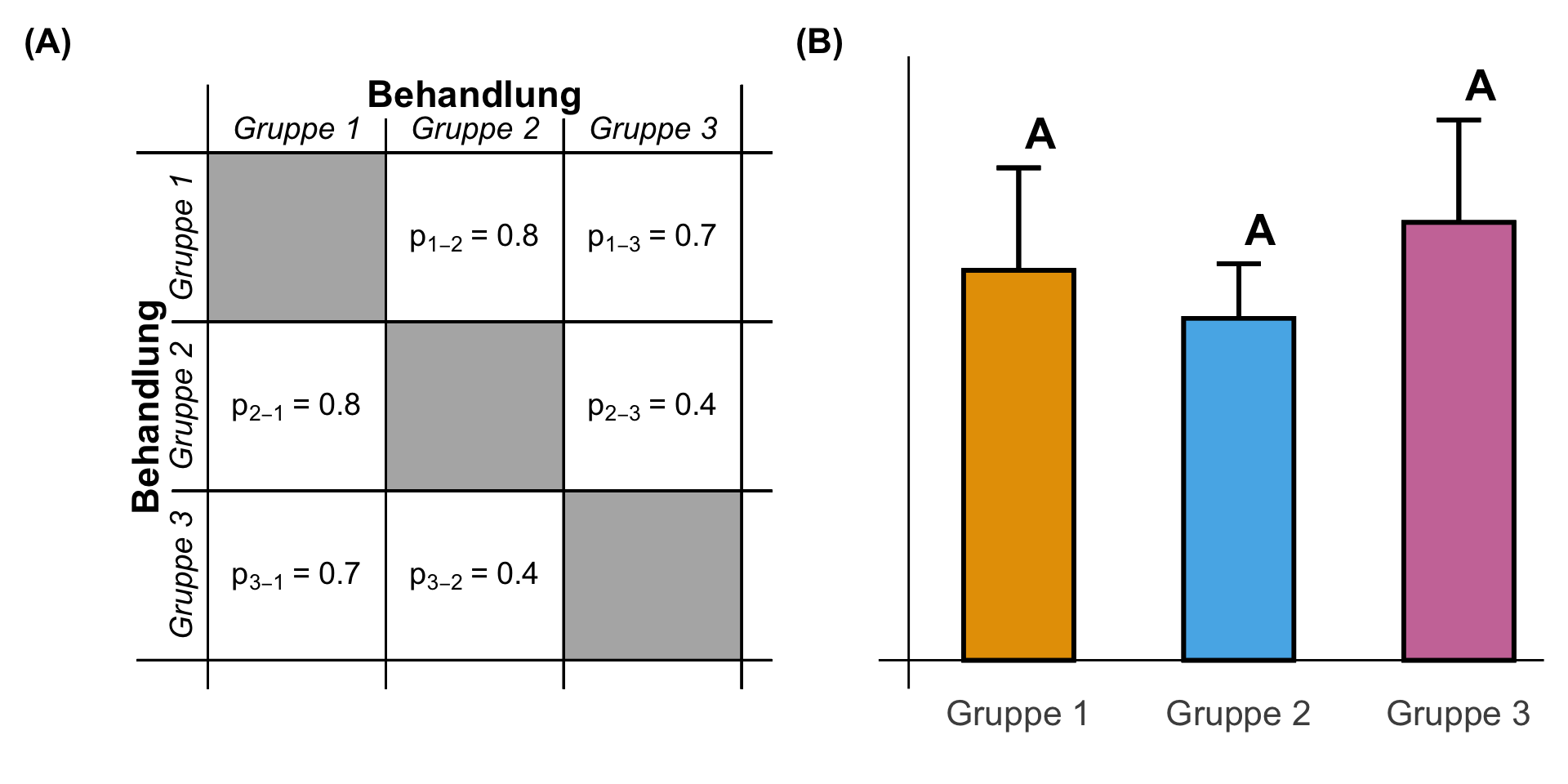
Gehen wir also einmal die Möglichkeiten durch. Im Folgenden also einmal ein *Compact letter display* für einen nicht signifikanten Unterschied zwischen den drei Gruppen. Wir haben daher nur p-Werte größer als das Signifikanzniveau $\alpha$ gleich 5% vorliegen. Die Barplots liegen somit auch fast alle auf einer ähnlichen Höhe. Die Mittelwerte sind somit fast identisch für alle drei Gruppen. Alle drei Barplots haben somit den gleichen Buchstaben `A`.
```{r}
#| echo: false
#| message: false
#| warning: false
#| label: fig-barplot-compact-01
#| fig-align: center
#| fig-height: 5
#| fig-width: 10
#| fig-cap: "Darstellung des *Compact letter display* für keinen signifikanten Unterschied zwischen den drei Gruppen. Alle drei Gruppen teilen sich den gleichen Buchstaben. Daher sind auch alle $p$-Werte der entsprechenden paarweisen Vergleiche nicht signifikant. **(A)** Matrix der $p$-Werte der paarweisen Vergleiche der drei Gruppen. **(B)** Barplots oder Säulendigramm der Mitelwerte der drei Gruppen zusammen mit dem *Compact letter display*. *[Zum Vergrößern anklicken]*"
p1 <- tibble(x = c(1, 2, 3), y = 8.13) |>
ggplot(aes(x, y)) +
theme_minimal() +
geom_vline(xintercept = 0.5) +
geom_hline(yintercept = 0) +
ylim(0, 12) +
xlim(0.5, NA) +
geom_rect(aes(xmin = 0.75, xmax = 1.25, ymin = 0, ymax = 8.13), fill = "#E69F00",
color = "black", linewidth = 1) +
geom_segment(x = 1, y = 8.13, xend = 1, yend = 10.27, color = "black",
linewidth = 1, linetype = 1) +
geom_segment(x = 0.9, y = 10.27, xend = 1.1, yend = 10.27, color = "black",
linewidth = 1, linetype = 1) +
geom_rect(aes(xmin = 1.75, xmax = 2.25, ymin = 0, ymax = 7.13), fill = "#56B4E9",
color = "black", linewidth = 1) +
geom_segment(x = 2, y = 7.13, xend = 2, yend = 8.27, color = "black",
linewidth = 1, linetype = 1) +
geom_segment(x = 1.9, y = 8.27, xend = 2.1, yend = 8.27, color = "black",
linewidth = 1, linetype = 1) +
geom_rect(aes(xmin = 2.75, xmax = 3.25, ymin = 0, ymax = 9.13), fill = "#CC79A7",
color = "black", linewidth = 1) +
geom_segment(x = 3, y = 9.13, xend = 3, yend = 11.27, color = "black",
linewidth = 1, linetype = 1) +
geom_segment(x = 2.9, y = 11.27, xend = 3.1, yend = 11.27, color = "black",
linewidth = 1, linetype = 1) +
scale_x_continuous(breaks = c(1, 2, 3), label = c("Gruppe 1", "Gruppe 2", "Gruppe 3")) +
annotate("text", x = c(1.1, 2.1, 3.1), y = c(11, 9, 12), label = c("A", "A", "A"),
size = 7, fontface = 2) +
labs(x = "", y = "") +
theme(legend.position = "none",
axis.text.x = element_text(size = 16),
axis.text.y = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank())
p2 <- tibble(x = 0:17,
y = 0:17) |>
ggplot(aes(x, y)) +
theme_minimal() +
xlim(0, 17) +
ylim(0, 17) +
## col
annotate("rect", xmin = 12, xmax = 17, ymin = 0, ymax = 5, fill = "gray70") +
annotate("rect", xmin = 7, xmax = 12, ymin = 5, ymax = 10, fill = "gray70") +
annotate("rect", xmin = 2, xmax = 7, ymin = 10, ymax = 15, fill = "gray70") +
geom_segment(x = 2, y = -2, xend = 2, yend = 17, color = "black",
linewidth = 0.5) +
geom_segment(x = 7, y = -1, xend = 7, yend = 16, color = "black",
linewidth = 0.5) +
geom_segment(x = 12, y = -2, xend = 12, yend = 16, color = "black",
linewidth = 0.5) +
geom_segment(x = 17, y = -2, xend = 17, yend = 17, color = "black",
linewidth = 0.5) +
annotate("text", x = 4.5, y = 15.75, label = "Gruppe 1",
size = 5, color = "black", fontface = "italic") +
annotate("text", x = 9.5, y = 15.75, label = "Gruppe 2",
size = 5, color = "black", fontface = "italic") +
annotate("text", x = 14.5, y = 15.75, label = "Gruppe 3",
size = 5, color = "black", fontface = "italic") +
annotate("text", x = 9.5, y = 16.75, label = "Behandlung",
size = 6, color = "black", fontface = "bold") +
## row
geom_segment(y = 0, x = 0, yend = 0, xend = 19, color = "black",
linewidth = 0.5) +
geom_segment(y = 5, x = 1, yend = 5, xend = 18, color = "black",
linewidth = 0.5) +
geom_segment(y = 10, x = 1, yend = 10, xend = 18, color = "black",
linewidth = 0.5) +
geom_segment(y = 15, x = 0, yend = 15, xend = 19, color = "black",
linewidth = 0.5)+
annotate("text", x = 1.25, y = 2.5, label = "Gruppe 3",
size = 5, angle = 90, color = "black", fontface = "italic") +
annotate("text", x = 1.25, y = 7.5, label = "Gruppe 2",
size = 5, angle = 90, color = "black", fontface = "italic") +
annotate("text", x = 1.25, y = 12.5, label = "Gruppe 1",
size = 5, angle = 90, color = "black", fontface = "italic") +
annotate("text", x = 0.25, y = 7.5, label = "Behandlung",
size = 6, angle = 90, color = "black", fontface = "bold") +
## lower tri
annotate("text", x = 4.5, y = 7.5, label = expression(p[2-1]~'='~0.8),
size = 5, color = "black") +
annotate("text", x = 4.5, y = 2.5, label = expression(p[3-1]~'='~0.7),
size = 5, color = "black") +
annotate("text", x = 9.5, y = 2.5, label = expression(p[3-2]~'='~0.4),
size = 5, color = "black") +
## upper tri
annotate("text", x = 14.5, y = 7.5, label = expression(p[2-3]~'='~0.4),
size = 5, color = "black") +
annotate("text", x = 14.5, y = 12.5, label = expression(p[1-3]~'='~0.7),
size = 5, color = "black") +
annotate("text", x = 9.5, y = 12.5, label = expression(p[1-2]~'='~0.8),
size = 5, color = "black") +
labs(x = "", y = "") +
theme(legend.position = "none",
axis.text.x = element_blank(),
axis.text.y = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank())
p2 + p1 +
plot_layout(ncol = 2) +
plot_annotation(tag_levels = 'A') +
plot_annotation(tag_levels = 'A', tag_prefix = '(', tag_suffix = ')') &
theme(plot.tag = element_text(size = 16, face = "bold"))
```
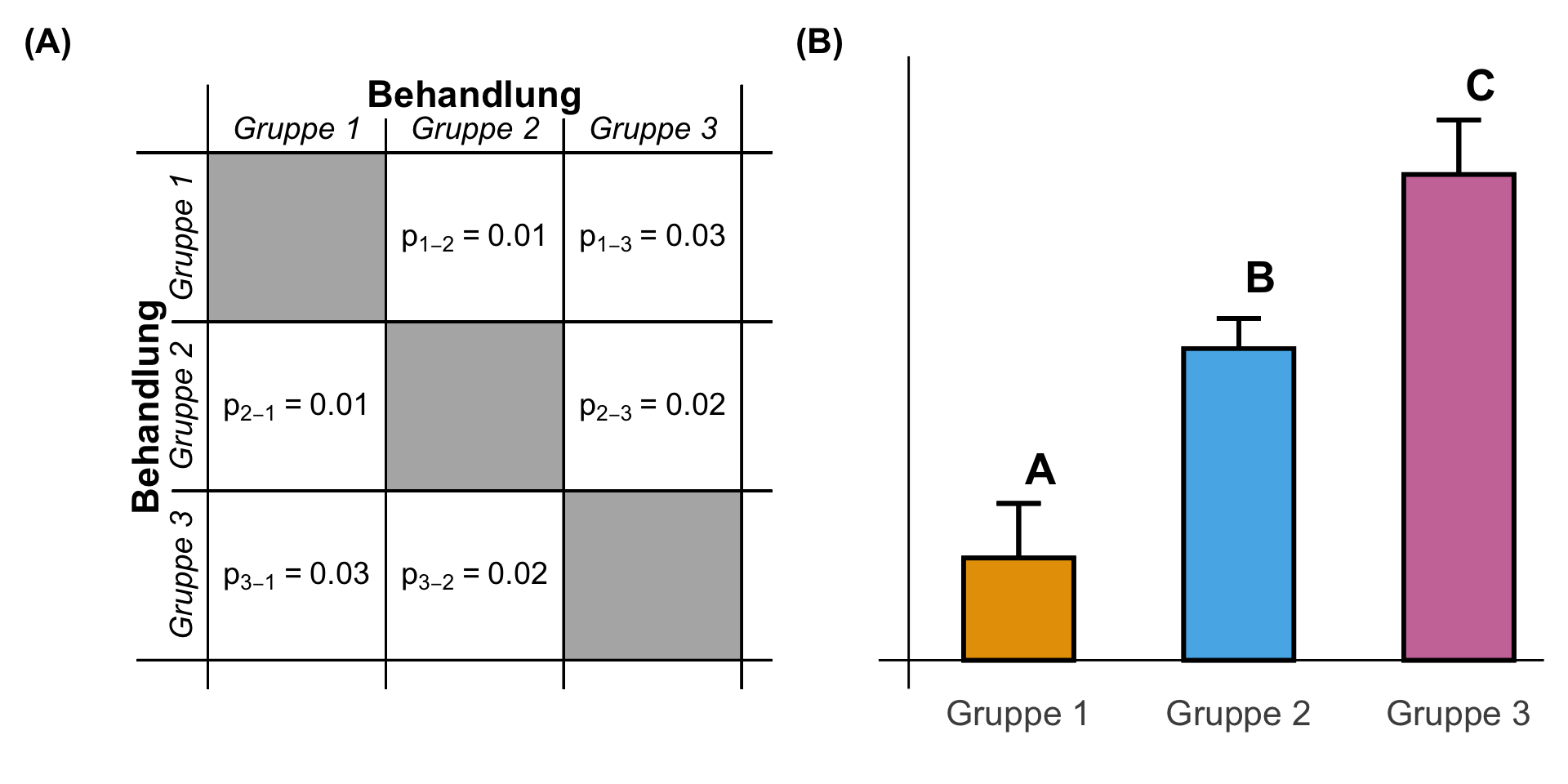
Wenn sich alle drei Gruppen voneinander unterscheiden, dann sehen wir zum einen, dass die Barplots nicht mehr auf einer Höhe liegen. Die Mittelwerte unterscheiden sich in allen frei Gruppen. Daher haben wir auch p-Werte die alle unter dem Signifikanzniveau $\alpha$ gleich 5% liegen. Damit haben wir dann auch ein *Compact letter display* mit drei verschiedenen Buchstaben `A`, `B` und `C` vorliegen. Keiner der Gruppen ist gleich einer anderen Gruppe.
```{r}
#| echo: false
#| message: false
#| warning: false
#| label: fig-barplot-compact-02
#| fig-align: center
#| fig-height: 5
#| fig-width: 10
#| fig-cap: "Darstellung des *Compact letter display* für signifikante Unterschiede zwischen allen drei Gruppen. Alle drei Gruppen haben unterschiedliche Buchstaben zugeordnet. Daher sind auch alle $p$-Werte der entsprechenden paarweisen Vergleiche signifikant. **(A)** Matrix der $p$-Werte der paarweisen Vergleiche der drei Gruppen. **(B)** Barplots oder Säulendigramm der Mitelwerte der drei Gruppen zusammen mit dem *Compact letter display*. *[Zum Vergrößern anklicken]*"
p1 <- tibble(x = c(1, 2, 3), y = 8.13) |>
ggplot(aes(x, y)) +
theme_minimal() +
geom_vline(xintercept = 0.5) +
geom_hline(yintercept = 0) +
ylim(0, 12) +
xlim(0.5, NA) +
geom_rect(aes(xmin = 0.75, xmax = 1.25, ymin = 0, ymax = 2.13), fill = "#E69F00",
color = "black", linewidth = 1) +
geom_segment(x = 1, y = 2.13, xend = 1, yend = 3.27, color = "black",
linewidth = 1, linetype = 1) +
geom_segment(x = 0.9, y = 3.27, xend = 1.1, yend = 3.27, color = "black",
linewidth = 1, linetype = 1) +
geom_rect(aes(xmin = 1.75, xmax = 2.25, ymin = 0, ymax = 6.5), fill = "#56B4E9",
color = "black", linewidth = 1) +
geom_segment(x = 2, y = 7.13, xend = 2, yend = 6.5, color = "black",
linewidth = 1, linetype = 1) +
geom_segment(x = 1.9, y = 7.13, xend = 2.1, yend = 7.13, color = "black",
linewidth = 1, linetype = 1) +
geom_rect(aes(xmin = 2.75, xmax = 3.25, ymin = 0, ymax = 10.13), fill = "#CC79A7",
color = "black", linewidth = 1) +
geom_segment(x = 3, y = 10.13, xend = 3, yend = 11.27, color = "black",
linewidth = 1, linetype = 1) +
geom_segment(x = 2.9, y = 11.27, xend = 3.1, yend = 11.27, color = "black",
linewidth = 1, linetype = 1) +
scale_x_continuous(breaks = c(1, 2, 3), label = c("Gruppe 1", "Gruppe 2", "Gruppe 3")) +
annotate("text", x = c(1.1, 2.1, 3.1), y = c(4, 8, 12), label = c("A", "B", "C"),
size = 7, fontface = 2) +
labs(x = "", y = "") +
theme(legend.position = "none",
axis.text.x = element_text(size = 16),
axis.text.y = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank())
p2 <- tibble(x = 0:17,
y = 0:17) |>
ggplot(aes(x, y)) +
theme_minimal() +
xlim(0, 17) +
ylim(0, 17) +
## col
annotate("rect", xmin = 12, xmax = 17, ymin = 0, ymax = 5, fill = "gray70") +
annotate("rect", xmin = 7, xmax = 12, ymin = 5, ymax = 10, fill = "gray70") +
annotate("rect", xmin = 2, xmax = 7, ymin = 10, ymax = 15, fill = "gray70") +
geom_segment(x = 2, y = -2, xend = 2, yend = 17, color = "black",
linewidth = 0.5) +
geom_segment(x = 7, y = -1, xend = 7, yend = 16, color = "black",
linewidth = 0.5) +
geom_segment(x = 12, y = -2, xend = 12, yend = 16, color = "black",
linewidth = 0.5) +
geom_segment(x = 17, y = -2, xend = 17, yend = 17, color = "black",
linewidth = 0.5) +
annotate("text", x = 4.5, y = 15.75, label = "Gruppe 1",
size = 5, color = "black", fontface = "italic") +
annotate("text", x = 9.5, y = 15.75, label = "Gruppe 2",
size = 5, color = "black", fontface = "italic") +
annotate("text", x = 14.5, y = 15.75, label = "Gruppe 3",
size = 5, color = "black", fontface = "italic") +
annotate("text", x = 9.5, y = 16.75, label = "Behandlung",
size = 6, color = "black", fontface = "bold") +
## row
geom_segment(y = 0, x = 0, yend = 0, xend = 19, color = "black",
linewidth = 0.5) +
geom_segment(y = 5, x = 1, yend = 5, xend = 18, color = "black",
linewidth = 0.5) +
geom_segment(y = 10, x = 1, yend = 10, xend = 18, color = "black",
linewidth = 0.5) +
geom_segment(y = 15, x = 0, yend = 15, xend = 19, color = "black",
linewidth = 0.5)+
annotate("text", x = 1.25, y = 2.5, label = "Gruppe 3",
size = 5, angle = 90, color = "black", fontface = "italic") +
annotate("text", x = 1.25, y = 7.5, label = "Gruppe 2",
size = 5, angle = 90, color = "black", fontface = "italic") +
annotate("text", x = 1.25, y = 12.5, label = "Gruppe 1",
size = 5, angle = 90, color = "black", fontface = "italic") +
annotate("text", x = 0.25, y = 7.5, label = "Behandlung",
size = 6, angle = 90, color = "black", fontface = "bold") +
## lower tri
annotate("text", x = 4.5, y = 7.5, label = expression(p[2-1]~'='~0.01),
size = 5, color = "black") +
annotate("text", x = 4.5, y = 2.5, label = expression(p[3-1]~'='~0.03),
size = 5, color = "black") +
annotate("text", x = 9.5, y = 2.5, label = expression(p[3-2]~'='~0.02),
size = 5, color = "black") +
## upper tri
annotate("text", x = 14.5, y = 7.5, label = expression(p[2-3]~'='~0.02),
size = 5, color = "black") +
annotate("text", x = 14.5, y = 12.5, label = expression(p[1-3]~'='~0.03),
size = 5, color = "black") +
annotate("text", x = 9.5, y = 12.5, label = expression(p[1-2]~'='~0.01),
size = 5, color = "black") +
labs(x = "", y = "") +
theme(legend.position = "none",
axis.text.x = element_blank(),
axis.text.y = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank())
p2 + p1 +
plot_layout(ncol = 2) +
plot_annotation(tag_levels = 'A') +
plot_annotation(tag_levels = 'A', tag_prefix = '(', tag_suffix = ')') &
theme(plot.tag = element_text(size = 16, face = "bold"))
```
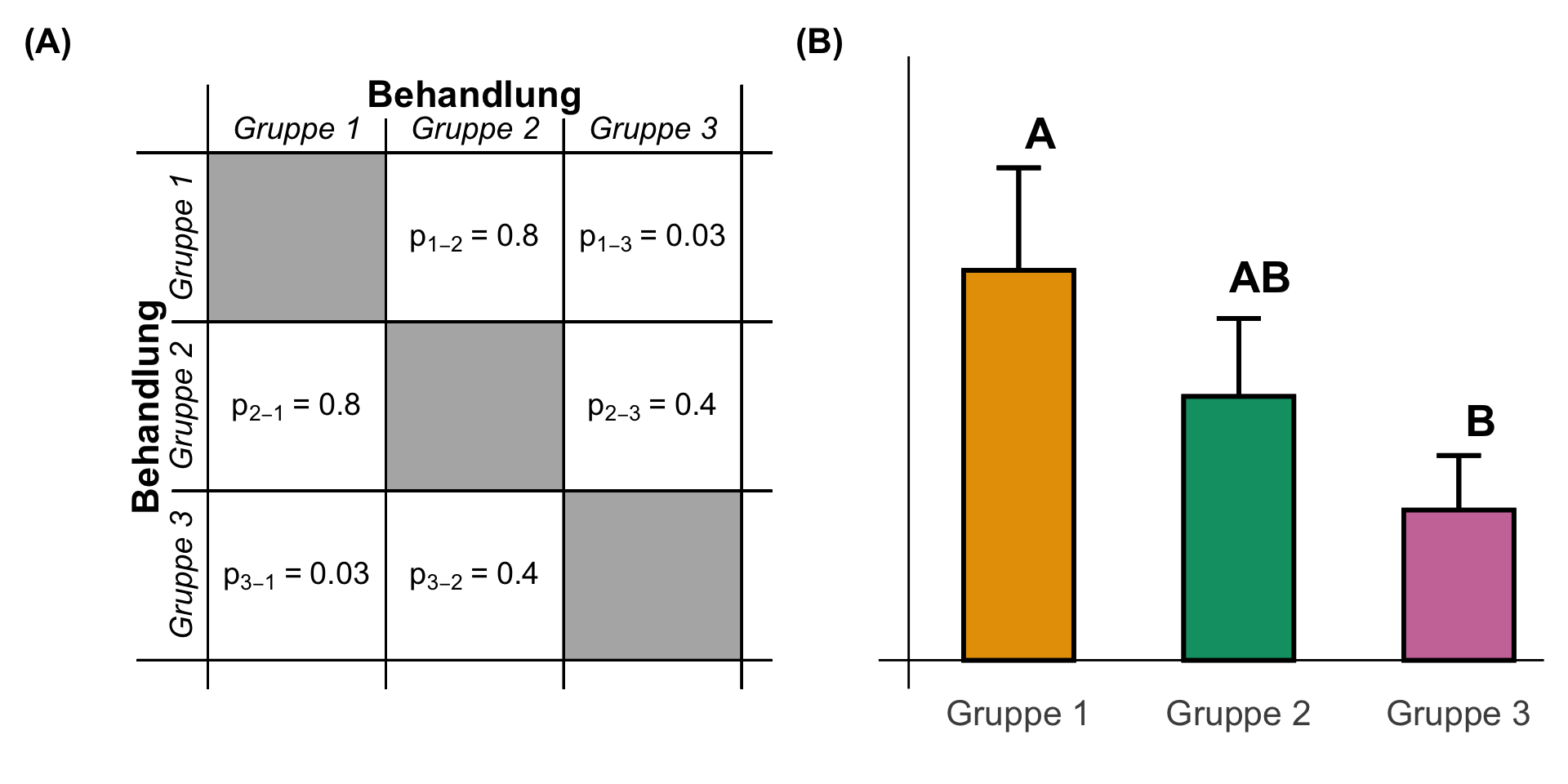
Wenn wir viele Gruppen testen, kommt es häufig dazu, dass wir nicht alle Gruppen nicht signifikant oder signifikant vorfinden. Das *Compact letter display* zeigt uns dann Gruppen an, die zu einigen anderen Gruppen signifikant unterschiedlich sind, zu anderen Gruppen aber nicht. Dadurch haben einige Barplots nicht nur einen Buchstaben sondern zwei oder mehr. In unserem theoretischen Fall ist die Gruppe 1 signifikant unterschiedlich von der Gruppe 3 aber nicht signifikant unterschiedlich von Gruppe 2. Daher geben wir der Gruppe 2 die Buchstaben `AB` um auszudrücken, dass sich die Gruppe zwei eben nicht von der Gruppe 1 oder der Gruppe 3 unterscheidet.
```{r}
#| echo: false
#| message: false
#| warning: false
#| label: fig-barplot-compact-03
#| fig-align: center
#| fig-height: 5
#| fig-width: 10
#| fig-cap: "Darstellung des *Compact letter display* für teilweise signifikante Unterschiede zwischen den drei Gruppen. Die drei Gruppen haben daher gleiche und unterschiedliche Buchstaben zugeordnet. Daher sind auch die $p$-Werte der entsprechenden paarweisen Vergleiche nur teilweise für Vergleiche signifikant. **(A)** Matrix der $p$-Werte der paarweisen Vergleiche der drei Gruppen. **(B)** Barplots oder Säulendigramm der Mitelwerte der drei Gruppen zusammen mit dem *Compact letter display*. *[Zum Vergrößern anklicken]*"
p1 <- tibble(x = c(1, 2, 3), y = 8.13) |>
ggplot(aes(x, y)) +
theme_minimal() +
geom_vline(xintercept = 0.5) +
geom_hline(yintercept = 0) +
ylim(0, 12) +
xlim(0.5, NA) +
geom_rect(aes(xmin = 0.75, xmax = 1.25, ymin = 0, ymax = 8.13), fill = "#E69F00",
color = "black", linewidth = 1) +
geom_segment(x = 1, y = 8.13, xend = 1, yend = 10.27, color = "black",
linewidth = 1, linetype = 1) +
geom_segment(x = 0.9, y = 10.27, xend = 1.1, yend = 10.27, color = "black",
linewidth = 1, linetype = 1) +
geom_rect(aes(xmin = 1.75, xmax = 2.25, ymin = 0, ymax = 5.5), fill = "#009E73",
color = "black", linewidth = 1) +
geom_segment(x = 2, y = 7.13, xend = 2, yend = 5.5, color = "black",
linewidth = 1, linetype = 1) +
geom_segment(x = 1.9, y = 7.13, xend = 2.1, yend = 7.13, color = "black",
linewidth = 1, linetype = 1) +
geom_rect(aes(xmin = 2.75, xmax = 3.25, ymin = 0, ymax = 3.13), fill = "#CC79A7",
color = "black", linewidth = 1) +
geom_segment(x = 3, y = 3.13, xend = 3, yend = 4.27, color = "black",
linewidth = 1, linetype = 1) +
geom_segment(x = 2.9, y = 4.27, xend = 3.1, yend = 4.27, color = "black",
linewidth = 1, linetype = 1) +
scale_x_continuous(breaks = c(1, 2, 3), label = c("Gruppe 1", "Gruppe 2", "Gruppe 3")) +
annotate("text", x = c(1.1, 2.1, 3.1), y = c(11, 8, 5), label = c("A", "AB", "B"),
size = 7, fontface = 2, color = c("black", "black", "black")) +
labs(x = "", y = "") +
theme(legend.position = "none",
axis.text.x = element_text(size = 16),
axis.text.y = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank())
p2 <- tibble(x = 0:17,
y = 0:17) |>
ggplot(aes(x, y)) +
theme_minimal() +
xlim(0, 17) +
ylim(0, 17) +
## col
annotate("rect", xmin = 12, xmax = 17, ymin = 0, ymax = 5, fill = "gray70") +
annotate("rect", xmin = 7, xmax = 12, ymin = 5, ymax = 10, fill = "gray70") +
annotate("rect", xmin = 2, xmax = 7, ymin = 10, ymax = 15, fill = "gray70") +
geom_segment(x = 2, y = -2, xend = 2, yend = 17, color = "black",
linewidth = 0.5) +
geom_segment(x = 7, y = -1, xend = 7, yend = 16, color = "black",
linewidth = 0.5) +
geom_segment(x = 12, y = -2, xend = 12, yend = 16, color = "black",
linewidth = 0.5) +
geom_segment(x = 17, y = -2, xend = 17, yend = 17, color = "black",
linewidth = 0.5) +
annotate("text", x = 4.5, y = 15.75, label = "Gruppe 1",
size = 5, color = "black", fontface = "italic") +
annotate("text", x = 9.5, y = 15.75, label = "Gruppe 2",
size = 5, color = "black", fontface = "italic") +
annotate("text", x = 14.5, y = 15.75, label = "Gruppe 3",
size = 5, color = "black", fontface = "italic") +
annotate("text", x = 9.5, y = 16.75, label = "Behandlung",
size = 6, color = "black", fontface = "bold") +
## row
geom_segment(y = 0, x = 0, yend = 0, xend = 19, color = "black",
linewidth = 0.5) +
geom_segment(y = 5, x = 1, yend = 5, xend = 18, color = "black",
linewidth = 0.5) +
geom_segment(y = 10, x = 1, yend = 10, xend = 18, color = "black",
linewidth = 0.5) +
geom_segment(y = 15, x = 0, yend = 15, xend = 19, color = "black",
linewidth = 0.5)+
annotate("text", x = 1.25, y = 2.5, label = "Gruppe 3",
size = 5, angle = 90, color = "black", fontface = "italic") +
annotate("text", x = 1.25, y = 7.5, label = "Gruppe 2",
size = 5, angle = 90, color = "black", fontface = "italic") +
annotate("text", x = 1.25, y = 12.5, label = "Gruppe 1",
size = 5, angle = 90, color = "black", fontface = "italic") +
annotate("text", x = 0.25, y = 7.5, label = "Behandlung",
size = 6, angle = 90, color = "black", fontface = "bold") +
## lower tri
annotate("text", x = 4.5, y = 7.5, label = expression(p[2-1]~'='~0.8),
size = 5, color = "black") +
annotate("text", x = 4.5, y = 2.5, label = expression(p[3-1]~'='~0.03),
size = 5, color = "black") +
annotate("text", x = 9.5, y = 2.5, label = expression(p[3-2]~'='~0.4),
size = 5, color = "black") +
## upper tri
annotate("text", x = 14.5, y = 7.5, label = expression(p[2-3]~'='~0.4),
size = 5, color = "black") +
annotate("text", x = 14.5, y = 12.5, label = expression(p[1-3]~'='~0.03),
size = 5, color = "black") +
annotate("text", x = 9.5, y = 12.5, label = expression(p[1-2]~'='~0.8),
size = 5, color = "black") +
labs(x = "", y = "") +
theme(legend.position = "none",
axis.text.x = element_blank(),
axis.text.y = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank())
p2 + p1 +
plot_layout(ncol = 2) +
plot_annotation(tag_levels = 'A') +
plot_annotation(tag_levels = 'A', tag_prefix = '(', tag_suffix = ')') &
theme(plot.tag = element_text(size = 16, face = "bold"))
```
## Händisch
Das *Compact letter display* geht natürlich auch händisch und dafür müssen wir dann einmal etwas ausholen. Da wir nicht nur zwei Gruppen brauchen, sondern der Sinn des *Compact letter displays* erst bei mehr als zwei Gruppen so richtig zum Vorschein kommt. Im Folgenden wollen wir daher einmal an einem erweiterten Datenbeispiel mit Hunde-, Katzen- und Fuchsflöhen einen statistischen Test rechnen um rauszufinden, ob sich die Sprungweiten der Flöhe unterscheiden. Dann können wir aus der Matrix der p-Werte das *Compact letter display* ableiten. In der folgenden Tabelle findest du einmal die Sprungweiten von jeweils vier Flöhen jeder der drei Tierarten.
```{r}
#| echo: false
#| warning: false
#| label: tbl-dog-cat-fox-small
#| tbl-cap: "Beispieldaten der Sprunglänge [cm] von Fuchs-, Hunde- und Katzenflöhen."
mean_tbl <- data_compact_tbl |>
group_by(animal) |>
summarise(mean_animal = round(mean(jump_length), 2),
sd_animal = round(sd(jump_length), 2))
mean_cat <- mean_tbl$mean_animal[1]
mean_dog <- mean_tbl$mean_animal[2]
mean_fox <- mean_tbl$mean_animal[3]
sd_cat <- mean_tbl$sd_animal[1]
sd_dog <- mean_tbl$sd_animal[2]
sd_fox <- mean_tbl$sd_animal[3]
sd_cd <- (sd_cat + sd_dog)/2
sd_cf <- (sd_cat + sd_fox)/2
sd_df <- (sd_fox + sd_dog)/2
t_d_cd <- round((mean_cat - mean_dog)/((sd_cat + sd_dog)/2 * sqrt(2/4)), 2)
t_d_cf <- round((mean_cat - mean_fox)/((sd_cat + sd_fox)/2 * sqrt(2/4)), 2)
t_d_df <- round((mean_fox - mean_dog)/((sd_fox + sd_dog)/2 * sqrt(2/4)), 2)
t_k <- round(qt(0.025, 4, lower.tail=FALSE), 2)
data_compact_tbl |>
mutate(animal = as_factor(animal)) |>
pivot_wider(names_from = animal,
values_from = "jump_length") |>
unnest(cols = c(cat, dog, fox)) |>
kable(align = "c", "pipe")
```
Aus den Daten können wir dann die p-Werte der paarweisen Vergleiche über einen statistischen Test berechnen. Dafür brauchen wir einmal die Mittelwertsdifferenz und die gepoolte Standardabweichung aus den obigen Daten. Das machen wir dann für jeden der drei möglichen Vergleiche zwischen den Tierarten. Dann rechnen wir noch die Teststatistik $T_D$ eines Student t-Tests als statistischen Test um über die Teststatistik $T_D$ an die p-Werte zu kommen.
| Vergleich | Mittelwertsdifferenz | Gepoolte Standardabweichung | Teststatistik $T_D$ |
|:--:|:--:|:--:|:--:|
| cat - dog | $`r mean_cat` - `r mean_dog` = `r mean_cat - mean_dog`$ | $(`r sd_cat` + `r sd_dog`)/2 = `r sd_cd`$ | $`r t_d_cd`$ |
| cat - fox | $`r mean_cat` - `r mean_fox` = `r mean_cat - mean_fox`$ | $(`r sd_cat` + `r sd_fox`)/2 = `r sd_cf`$ | $`r t_d_cf`$ |
| fox - dog | $`r mean_fox` - `r mean_dog` = `r mean_fox - mean_dog`$ | $(`r sd_fox` + `r sd_dog`)/2 = `r sd_df`$ | $`r t_d_df`$ |
: Die berechneten Teststatistiken eines Student t-Test aus der Mittelwertsdifferenz und der gepoolten Standardabweichung für die Vergleiche der Sprunglängen der unterschiedlichen Tierarten. {#tbl-sum-compact}
Jetzt könnten wir die berechneten Teststatistiken $T_D$ mit dem kritische Wert $T_{\alpha = 5\%} = `r t_k`$ vergleichen und eine Entscheidung über die Nullhypothese treffen. Oder wir nutzen die Funktion `pt()` um uns die p-Werte berechnen zu lassen. Ich habe hier dann die absoluten Werte eingetragen damit ich es etwas leichter habe.
```{r}
pt(c(3.47, 4.28, 1.08), 10, lower.tail = FALSE) |> round(4)
```
Wir sehen gleich, dass wir es mit zwei signifikanten Unterschieden und einem nicht signifikanten Unterschied zu tun haben. Daher könnten wir hier auch eine Gruppe vorliegen haben, die zwei Buchstaben des *Compact letter displays* trägt. Muss aber nicht.
Tipp zur händischen Erstellung
: Sortiere erst deine Barplots oder Säulendiagramme in absteigender Reihenfolge des mittleren Effekts. Oder andersherum, links sind die höchsten Säulen und rechts die niedrigsten Säulen.
In der folgenden Abbildung siehst du dann einmal die Matrix der p-Werte für die Vergleiche zwischen den Sprunglängen der drei Tierarten. Ich habe auch für die bessere Übersicht den Barplot einmal in absteigender Effektstärke sortiert. Daher kommen als erstes die Katzenflöhe mit den weitesten Mittelwert der Sprunglänge, dann kommen die Hunde und dann die Füchse. Da sich die Katzenflöhe in der Sprungweite sowohl von den Hunde- sowie den Fuchsflöhen unterschieden, erhalten die Katzenflöhe ein `A`. Da sich die Hundeflöhe nicht von den Fuchsflöhen unterscheiden erhalten beide ein `B`.
```{r}
#| echo: false
#| message: false
#| warning: false
#| label: fig-barplot-compact-04
#| fig-align: center
#| fig-height: 5
#| fig-width: 10
#| fig-cap: "Darstellung des *Compact letter display* für die signifikante Unterschiede zwischen den drei Tierarten. Die Katzenflöhe unterscheiden sich signifikant von den Hunde- und Fuchsflöhen. Die Buchstaben unterschieden sich. Es gibt keinen signifikanten Unterschied zwischen Hunde- und Fuchsflöhen. Die Buchstaben sind gleich. **(A)** Matrix der $p$-Werte der paarweisen Vergleiche der drei Gruppen. **(B)** Barplots oder Säulendigramm der Mitelwerte der drei Tierarten zusammen mit dem *Compact letter display*. *[Zum Vergrößern anklicken]*"
p1 <- tibble(x = c(1, 2, 3), y = 8.13) |>
ggplot(aes(x, y)) +
theme_minimal() +
geom_vline(xintercept = 0.5) +
geom_hline(yintercept = 0) +
ylim(0, 12) +
xlim(0.5, NA) +
geom_rect(aes(xmin = 0.75, xmax = 1.25, ymin = 0, ymax = 9.18), fill = "#E69F00",
color = "black", linewidth = 1) +
geom_segment(x = 1, y = 9.18, xend = 1, yend = 9.79, color = "black",
linewidth = 1, linetype = 1) +
geom_segment(x = 0.9, y = 9.79, xend = 1.1, yend = 9.79, color = "black",
linewidth = 1, linetype = 1) +
geom_rect(aes(xmin = 1.75, xmax = 2.25, ymin = 0, ymax = 7.78), fill = "#56B4E9",
color = "black", linewidth = 1) +
geom_segment(x = 2, y = 7.78, xend = 2, yend = 8.31, color = "black",
linewidth = 1, linetype = 1) +
geom_segment(x = 1.9, y = 8.31, xend = 2.1, yend = 8.31, color = "black",
linewidth = 1, linetype = 1) +
geom_rect(aes(xmin = 2.75, xmax = 3.25, ymin = 0, ymax = 7.35), fill = "#CC79A7",
color = "black", linewidth = 1) +
geom_segment(x = 3, y = 7.35, xend = 3, yend = 7.95, color = "black",
linewidth = 1, linetype = 1) +
geom_segment(x = 2.9, y = 7.95, xend = 3.1, yend = 7.95, color = "black",
linewidth = 1, linetype = 1) +
scale_x_continuous(breaks = c(1, 2, 3), label = c("Cat", "Dog", "Fox")) +
annotate("text", x = c(1.1, 2.1, 3.1), y = c(9.79, 8.31, 7.95)+0.6, label = c("A", "B", "B"),
size = 7, fontface = 2) +
labs(x = "", y = "") +
theme(legend.position = "none",
axis.text.x = element_text(size = 16),
axis.text.y = element_text(size = 14),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank())
p2 <- tibble(x = 0:17,
y = 0:17) |>
ggplot(aes(x, y)) +
theme_minimal() +
xlim(0, 17) +
ylim(0, 17) +
## col
annotate("rect", xmin = 12, xmax = 17, ymin = 0, ymax = 5, fill = "gray70") +
annotate("rect", xmin = 7, xmax = 12, ymin = 5, ymax = 10, fill = "gray70") +
annotate("rect", xmin = 2, xmax = 7, ymin = 10, ymax = 15, fill = "gray70") +
geom_segment(x = 2, y = -2, xend = 2, yend = 17, color = "black",
linewidth = 0.5) +
geom_segment(x = 7, y = -1, xend = 7, yend = 16, color = "black",
linewidth = 0.5) +
geom_segment(x = 12, y = -2, xend = 12, yend = 16, color = "black",
linewidth = 0.5) +
geom_segment(x = 17, y = -2, xend = 17, yend = 17, color = "black",
linewidth = 0.5) +
annotate("text", x = 4.5, y = 15.75, label = "Cat",
size = 5, color = "black", fontface = "italic") +
annotate("text", x = 9.5, y = 15.75, label = "Dog",
size = 5, color = "black", fontface = "italic") +
annotate("text", x = 14.5, y = 15.75, label = "Fox",
size = 5, color = "black", fontface = "italic") +
annotate("text", x = 9.5, y = 16.75, label = "Tierart",
size = 6, color = "black", fontface = "bold") +
## row
geom_segment(y = 0, x = 0, yend = 0, xend = 19, color = "black",
linewidth = 0.5) +
geom_segment(y = 5, x = 1, yend = 5, xend = 18, color = "black",
linewidth = 0.5) +
geom_segment(y = 10, x = 1, yend = 10, xend = 18, color = "black",
linewidth = 0.5) +
geom_segment(y = 15, x = 0, yend = 15, xend = 19, color = "black",
linewidth = 0.5)+
annotate("text", x = 1.25, y = 2.5, label = "Fox",
size = 5, angle = 90, color = "black", fontface = "italic") +
annotate("text", x = 1.25, y = 7.5, label = "Dog",
size = 5, angle = 90, color = "black", fontface = "italic") +
annotate("text", x = 1.25, y = 12.5, label = "Cat",
size = 5, angle = 90, color = "black", fontface = "italic") +
annotate("text", x = 0.25, y = 7.5, label = "Tierart",
size = 6, angle = 90, color = "black", fontface = "bold") +
## lower tri
annotate("text", x = 4.5, y = 7.5, label = "0.0030",
size = 4.5, color = "black") +
annotate("text", x = 4.5, y = 2.5, label = "0.0008",
size = 4.5, color = "black") +
annotate("text", x = 9.5, y = 2.5, label = "0.1527",
size = 4.5, color = "black") +
## upper tri
annotate("text", x = 14.5, y = 7.5, label = "0.1527",
size = 4.5, color = "black") +
annotate("text", x = 14.5, y = 12.5, label = "0.0008",
size = 4.5, color = "black") +
annotate("text", x = 9.5, y = 12.5, label = "0.0030",
size = 4.5, color = "black") +
labs(x = "", y = "") +
theme(legend.position = "none",
axis.text.x = element_blank(),
axis.text.y = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank())
p2 + p1 +
plot_layout(ncol = 2) +
plot_annotation(tag_levels = 'A') +
plot_annotation(tag_levels = 'A', tag_prefix = '(', tag_suffix = ')') &
theme(plot.tag = element_text(size = 16, face = "bold"))
```
## `{multcompView}`
Manchmal wollen wir die p-Werte in Excel berechnen und brauchen dann aber noch das *Compact letter display* für unsere Abbildung in den Barplots. Leider kann Excel kein *Compact letter display* berechnen, so dass du dann auf R angewiesen bist. Für die Berechnung des *Compact letter displays* aus gegebenen p-Werten brauchts du die Funktion `multcompLetters()` aus dem R Paket `{multcomView}`.
Dabei ist ganz wichtig, dass du die Vergleiche zwischen den Gruppen immer durch ein Minuszeichen `-` voneinander trennst. Wenn du also die beiden Gruppen Kontrolle `ctrl` und die erste Behandlung miteinander verglichen hast und aus einem statistischen Test den p-Wert 0.39087114 erhalten hast, dann musst du für den Vergleich `"trt1-ctrl"` schreiben. Im folgenden Codechunk habe ich dir einmal die drei Vergleiche der Gruppen `ctrl`, `trt1` und `trt2` erstellt. Jeder Vergleich hat einen p-Wert aus einem statististischen Test zugeordnet. Woher der p-Wert kommt, ist hier erstmal zweitrangig.
```{r}
p_vec <- c("trt1-ctrl" = 0.39087114,
"trt2-ctrl" = 0.19799599,
"trt2-trt1" = 0.01200642)
```
Jetzt können wir die Funktion `multcompLetters()` aus dem R Paket `{multcomView}` nutzen um das *Compact letter display* für die drei Behandlungsgruppen zu erstellen. Dafür brauchen wir nur den Vektor `p_vec` mit den p-Werten der Vergleiche. Jeder p-Wert braucht als Namen den Vergleich woher er stammt.
```{r}
library(multcompView)
multcompLetters(p_vec)
```
Das *Compact letter display* kannst du dann bei deinen Säulendiagrammen in Excel entsprechend ergänzen. Weniger Aufwand geht dann leider nicht. Wenn du deine p-Werte in R berechnest, dann gibt es bessere Wege um zum *Compact letter display* zu kommen. Dazu mehr im [Kapitel zum Post-hoc-Test](#sec-posthoc)
:::
Im Folgenden habe ich dir noch ein paar Beispiele für das *Compact letter display* mitgebracht. Hier kannst du dann nochmal sehen, wie das *Compact letter display* in der Praxis angewendet wird. Ich habe hier Fotos von Postern der Hochschule Osnabrück und eine wissenschaftliche Veröffentlichung gewählt. Dann hast du einmal eine Idee wie es am Ende aussehen kann.
::: panel-tabset
## Beispiel 1
![Das *Compact letter display* für ein einfaktorielles Design mit vier Gruppen. Die Wasserdampfdestillation und RQflex Nitrat sind nicht signifikant unterschiedlich, da sich beide Behandlungen den gleichen Buchstaben teilen. *\[Zum Vergrößern anklicken\]*](images/eda/zerforschen_barplot_simple.png){#fig-pretest-barplot-02 fig-align="center" width="100%"}
## Beispiel 2
![Das *Compact letter display* für ein zweifaktorielles Design mit neun Faktorkombinationen. Teilweise haben einzelne Gruppen geteilte Buchstaben, da sich die Mittelwerte nicht eindeutig von jeder Gruppe unterscheiden. *\[Zum Vergrößern anklicken\]*](images/eda/zerforschen_barplot_2fac.png){#fig-pretest-barplot-01 fig-align="center" width="100%"}
## Beispiel 3
![*"Panicles with commercial fruit (%) at 2019 and 2020 harvest. In the same year, different letters indicate significant differences among treatments (Tukey's test p\<0.05)."* Quelle: @sanchez2022hoverfly [*Zum Vergrößern anklicken*]](images/eda/zerforschen_hoverfly.png){#fig-pretest-barplot-02 fig-align="center" width="100%"}
## Beispiel 4
![Das *Compact letter display* für ein einfaktorielles Design mit acht Faktoren aufgeteilt auf zwei Gruppen. Die Buchstaben in der linken Gruppe sind nicht zusammen mit der rechten Gruppe zu interpretieren. Es gibt hier sehr viele intermediäre Behandlungen. Daher teilen sich viele Gruppen zwei Buchstaben. *\[Zum Vergrößern anklicken\]*](images/eda/zerforschen_barplot_root.jpg){#fig-pretest-barplot-02 fig-align="center" width="100%"}
:::
Warum nutzen wir nun das *Compact letter display*? Wenn du viele Gruppen und damit Säulen in einem Barplot hast, dann kannst du recht einfach die Zusammenhänge zeigen. Du siehst auf einem Blick die signifikanten Unterschiede. Obwohl, das stimmt natürlich nur so halb. In Wirklichkeit interessiert dich der signifikante Unterschied, du erhälst aber mit dem *Compact letter display* die Gleichheit wiedergegeben. Das ist dann auch der größte Nachteil des *Compact letter display*, das es eben eine Frage beantwortet, die gar nicht gestellt wurde. Am Ende musst du selber entscheiden, ob das *Compact letter display* in deine Fragestellung sinnvoll ist. Es gibt Gründe das *Compact letter display* zu verwenden, wie auch nicht. Mehr dazu auch auf der Hilfe- und Diskussionsseite mit [Re-engineering CLDs des R Paktes `{emmeans}`](https://cran.r-project.org/web/packages/emmeans/vignettes/re-engineering-clds.html#intro).
::: callout-note
## Entscheidung mit dem *Compact letter display*
Gruppen oder Behandlungen mit dem *gleichen* Buchstaben zeigen *keinen* signifikanten Unterschied. Gruppen oder Behandlungen mit einem unterschiedlichen Buchstaben sind signifikant unterschiedlich.
Eine Besonderheit sind Gruppen mit mehr als einem Buchstaben. Diese Fälle können auftreten, wenn mehr als zwei Gruppen miteinander vergleichen werden.
:::
### ... anhand des 95% Konfidenzintervalls {#sec-ki}
{{< video https://youtu.be/i0becAn_5U4 >}}
Ein statistischer Test der eine Teststatistik $T$ berechnet liefert auch immer einen $p$-Wert. Nicht alle statistischen Tests ermöglichen es ein 95% Konfidenzintervall zu berechnen. @fig-test-basic-ki-00 zeigt ein 95% Konfidenzintervall für den Mittelwertsunterschied sowie dem Anteilsunterschied.
```{r}
#| echo: false
#| message: false
#| warning: false
#| label: fig-test-basic-ki-00
#| fig-align: center
#| fig-height: 4
#| fig-width: 5
#| fig-cap: "Ein 95% Konfidenzintervall. Der Punkt in der Mitte entspricht dem Unterschied oder Effekt $\\Delta$ der beiden zu vergleichenden Gruppen. **(A)** Mittelwertsunterschied ($\\Delta_{y_1-y_2}$) **(B)** Anteilsunterschied ($\\Delta_{y_1/y_2}$). *[Zum Vergrößern anklicken]*"
ki_tbl <- tibble(delta = 2.4,
arms = 1.5)
p0 <- ggplot(ki_tbl) +
theme_minimal() +
geom_point() +
geom_errorbar(aes(ymin = delta - arms, ymax = delta + arms),
width = 0.1) +
scale_y_continuous(limits = c(-1, 5), breaks = seq(-1, 5, 1)) +
coord_flip() +
theme(axis.text = element_text(size = 12))
p1 <- p0 +
aes(x = "2 - 1", y = delta) +
geom_hline(yintercept = 0, color = "#CC79A7", alpha = 0.8) +
labs(x = "", y = "Mittelwertsunterschied (Differenz)") +
annotate("text", x = 1.5, y = 1,
color = "black", vjust= 1.5, hjust = -0.5,
size = 4, label = "Untere", fontface = 3) +
annotate("text", x = 0.75, y = 3,
color = "black", vjust= 1.5, hjust = -0.5,
size = 4, label = "Obere", fontface = 3) +
annotate("text", x = 0.75, y = 1.5,
color = "black", vjust= 1.5, hjust = -0.5,
size = 6, label = expression(Delta)) +
geom_curve(x = 1.4, y = 1.3, xend = 1.1, yend = 0.9,
arrow = arrow(length = unit(0.03, "npc")),
curvature = 0.5) +
geom_curve(x = 0.65, y = 4.15, xend = 1, yend = 4,
arrow = arrow(length = unit(0.03, "npc")),
curvature = 0.8) +
geom_curve(x = 0.6, y = 1.9, xend = 0.9, yend = 2.4,
arrow = arrow(length = unit(0.03, "npc")),
curvature = 0.5)
p2 <- p0 +
aes(x = "2 / 1", y = delta) +
geom_hline(yintercept = 1, color = "#CC79A7", alpha = 0.8) +
labs(x = "", y = "Anteilsunterschied (Quotient)") +
geom_hline(yintercept = 0, color = "black", alpha = 0.3) +
scale_y_continuous(limits = c(-1, 5), breaks = seq(0, 5, 1))
p1 + p2 +
plot_layout(nrow = 2) +
plot_annotation(tag_levels = 'A')
```
Mit *p-Werten* haben wir Wahrscheinlichkeitsaussagen und damit über die *Signifikanz*. Damit haben wir noch keine Aussage über die *Relevanz* des beobachteten Effekts. Mit der Teststatistik $T$ und dem damit verbundenen $p$-Wert haben wir uns *Wahrscheinlichkeiten* angeschaut und erhalten eine *Wahrscheinlichkeitsaussage*. Eine Wahrscheinlichkeitsaussage sagt aber nichts über den Effekt $\Delta$ aus. Also wie groß ist der mittlere Sprung*unterschied* zwischen Hunde- und Katzenflöhen. Die Idee von 95% Konfidenzintervallen ist es jetzt den Effekt mit der Wahrscheinlichkeitsaussage zusammenzubringen und beides in einer *Visualisierung* zu kombinieren.
::: {layout="[15,85]" layout-valign="center"}
{fig-align="center" width="100%"}
> Wir nutzen hier eine von mir *vereinfachte Formel* für das Konfidenzintervall um das Konzept zu verstehen. Später berechnen wir das Konfidenzintervall in R.
:::
Im Folgenden sehen wir also die vereinfachte Formel für das 95% Konfidenzintervall eines t-Tests um es uns etwas einfacher vom Verständnis zu machen. Komplizierter geht es immer, aber das berechnet dann eine Maschine später für uns.
$$
\left[
(\bar{y}_1-\bar{y}_2) -
T_{\alpha = 5\%} \cdot \frac {s_p}{\sqrt{n}}; \;
(\bar{y}_1-\bar{y}_2) +
T_{\alpha = 5\%} \cdot \frac {s_p}{\sqrt{n}}
\right]
$$
Die Formel ist ein wenig komplex, aber im Prinzip einfach, wenn du ein wenig die Formel auf dich wirken lässt. Der linke und der rechte Teil neben dem Semikolon sind fast gleich, bis auf das Plus- und Minuszeichen. Wir sehen folgende mathematische Zusammenhänge in der Formel und entsprechenden dann in der Visualisierung des Konfidenzintervalls.
- $(\bar{y}_{1}-\bar{y}_{2})$ ist der Effekt $\Delta$. In diesem Fall der Mittelwertsunterschied. Wir finden den Effekt als Punkt in der Mitte des Intervalls.
- $T_{\alpha = 5\%} \cdot \frac {s}{\sqrt{n}}$ ist der Wert, der die Arme des Intervalls bildet. Wir vereinfachen die Formel mit $s_p$ für die gepoolte Standardabweichung und $n_g$ für die Fallzahl der beiden Gruppen. Wir nehmen an das beide Gruppen die gleiche Fallzahl $n_1 = n_2$ haben.
Bei der Entscheidung mit dem 95% Konfidenzintervall müssen wir zwei Fälle unterscheiden.
1) Entweder schauen wir uns einen Mittelwertsunterschied ($\Delta_{y_1-y_2}$) an, dann können wir die Nullhypothese (H$_0$) *nicht* ablehnen, wenn die **0** im 95% Konfidenzinterval ist.
2) Oder wir schauen uns einen Anteilsunterschied ($\Delta_{y_1/y_2}$) an, dann können wir die Nullhypothese (H$_0$) *nicht* ablehnen, wenn die **1** im 95% Konfidenzinterval ist.
```{r}
#| echo: false
#| message: false
#| warning: false
#| label: fig-test-basic-ki-01
#| fig-align: center
#| fig-height: 4
#| fig-width: 5
#| fig-cap: "Die Arme des 95% Konfidenzintervalls werden länger oder kürzer je nachdem wie sich die statistischen Maßzahlen $s$ und $n$ verändern. **(A)** Bei einem Mittelwertsunterschied kann die Nullhypothese abgelehnt werden, wenn die 0 nicht im Konfidenzintervall ist; **(B)** bei einem Anteilsunterschied wenn die 1 nicht im Konfidenzintervall ist. *[Zum Vergrößern anklicken]*"
ki_mean_tbl <- tibble(grp = as_factor(c("2 - 1", "2 - 3")),
delta = c(2.4, 3.1),
arms = c(2.8, 1.5))
p1 <- ggplot(ki_mean_tbl) +
aes(x = grp, y = delta) +
theme_minimal() +
geom_point() +
geom_errorbar(aes(ymin = delta - arms, ymax = delta + arms),
width = 0.1) +
scale_y_continuous(limits = c(-2, 9), breaks = c(-2, 0, 2, 4, 6, 8)) +
theme(axis.text = element_text(size = 12)) +
annotate("text", x = 1, y = 7.5,
color = "black",
size = 4, label = "Nicht Signifikant", fontface = 3) +
annotate("text", x = 2, y = 7.5,
color = "black",
size = 4, label = "Signifikant", fontface = 3) +
coord_flip() +
geom_hline(yintercept = 0, color = "#CC79A7", alpha = 0.8) +
labs(x = "", y = "Mittelwertsunterschied (Differenz)")
ki_ratio_tbl <- tibble(grp = as_factor(c("2 / 1", "2 / 3")),
delta = c(2.4, 3.1),
arms = c(2.1, 1.5))
p2 <- ggplot(ki_ratio_tbl) +
aes(x = grp, y = delta) +
theme_minimal() +
geom_point() +
geom_errorbar(aes(ymin = delta - arms, ymax = delta + arms),
width = 0.1) +
scale_y_continuous(limits = c(-2, 9), breaks = c(0, 1, 2, 4, 6, 8)) +
theme(axis.text = element_text(size = 12)) +
annotate("text", x = 1, y = 7.5,
color = "black",
size = 4, label = "Nicht Signifikant", fontface = 3) +
annotate("text", x = 2, y = 7.5,
color = "black",
size = 4, label = "Signifikant", fontface = 3) +
coord_flip() +
geom_hline(yintercept = 1, color = "#CC79A7", alpha = 0.8) +
labs(x = "", y = "Anteilsunterschied (Quotient)") +
geom_hline(yintercept = 0, color = "black", alpha = 0.3)
p1 + p2 +
plot_layout(nrow = 2) +
plot_annotation(tag_levels = 'A')
```
Wir können eine biologische Relevanz definieren, dadurch das ein 95% Konfidenzintervall die Wahrscheinlichkeitsaussage über die Signifikanz, daher ob die Nullhypothese abgelehnt werden kann, mit dem Effekt zusammenbringt. Wo die Signifikanzschwelle klar definiert ist, hängt die Relevanzschwelle von der wissenschaftlichen Fragestellung und weiteren externen Faktoren ab. Die Signifikanzschwelle liegt bei 0, wenn wir Mittelwerte miteinander vergleichen und bei 1, wenn wir Anteile vergleichen. Die @fig-test-basic-ki-02 zeigt fünf 95% Konfidenzintervalle (a-e), die sich anhand der Signifikanz und Relevanz unterscheiden. Bei der Relevanz ist es wichtig zu wissen in welche *Richtung* der Effekt gehen soll. Erwarten wir einen positiven Effekt wenn wir die Differenz der beiden Gruppen bilden oder einen negativen Effekt?
```{r}
#| echo: false
#| message: false
#| warning: false
#| label: fig-test-basic-ki-02
#| fig-align: center
#| fig-height: 4
#| fig-width: 5
#| fig-cap: "Verschiedene signifikante und relevante Konfidenzintervalle: (A) signifikant und relevant; (B) signifikant und nicht relevant; (C) nicht signifikant und nicht relevant; (D) signifikant und nicht relevant, der Effekt ist zu klein; (E) signifikant und potenziell relevant, Effekt zeigt in eine unerwartete Richtung gegeben der Relevanzschwelle. *[Zum Vergrößern anklicken]*"
ki_mean_tbl <- tibble(grp = as_factor(c("2 - 6",
"2 - 5",
"2 - 4",
"2 - 3",
"2 - 1")),
delta = c(-1.1, 1.9, 1.4, 4.1, 5.4),
arms = c(0.6, 0.76, 2.1, 2.1, 1.8))
ggplot(ki_mean_tbl) +
aes(x = grp, y = delta) +
theme_minimal() +
geom_point() +
geom_errorbar(aes(ymin = delta - arms, ymax = delta + arms),
width = 0.1) +
scale_y_continuous(limits = c(-2, 9), breaks = seq(-2, 9, 2)) +
theme(axis.text = element_text(size = 12)) +
annotate("text", x = 1:5, y = 8.5,
color = "black",
size = 4, label = c("(E)", "(D)", "(C)", "(B)", "(A)"), fontface = 4) +
coord_flip() +
geom_hline(yintercept = 0, color = "#CC79A7", alpha = 0.8) +
geom_hline(yintercept = 3, color = "#009E73", alpha = 0.8) +
labs(x = "", y = "Mittelwertsunterschied (Differenz)") +
annotate("text", x = 1.5, y = 5,
color = "#CC79A7",
size = 3, label = "Signifikanzschwelle", fontface = 3) +
annotate("text", x = 2.5, y = 6,
color = "#009E73",
size = 3, label = "Relevanzschwelle", fontface = 3) +
annotate("text", x = 5.5, y = 3.5,
color = "#009E73",
size = 7, label = "+", fontface = 2) +
geom_curve(x = 1.5, y = 3.5, xend = 2, yend = 0,
arrow = arrow(length = unit(0.03, "npc")),
curvature = -0.2, linewidth = 0.4, color = "#CC79A7", alpha = 0.8) +
geom_curve(x = 2.5, y = 4.5, xend = 2.75, yend = 3,
arrow = arrow(length = unit(0.03, "npc")),
curvature = -0.2, linewidth = 0.4, color = "#009E73")
```
Wir wollen uns nun einmal anschauen, wie sich ein 95% Konfidenzintervall berechnet. Wir nehmen dafür die vereinfachte Formel und setzen die berechneten statistischen Maßzahlen ein. In der Anwendung werden wir die Konfidenzintervalle nicht selber berechnen. Wenn ein statistisches Verfahren Konfidenzintervalle berechnen kann, dann liefert die entsprechende Funktion in R das Konfidenzintervall.
::: panel-tabset
## Mathematik
Es ergibt sich Folgende ausgefüllte Formel für das 95% Konfidenzintervalls eines t-Tests für das Beispiel des Sprungweitenunterschieds \[cm\] zwischen Hunde- und Katzenflöhen.
$$
\left[
(`r mean_cat`-`r mean_dog`) -
`r t_k` \cdot \frac {`r sd_p`}{\sqrt{4}}; \;
(`r mean_cat`-`r mean_dog`) +
`r t_k` \cdot \frac {`r sd_p`}{\sqrt{4}}
\right]
$$
mit
- $\bar{y}_{cat} = `r mean_cat`cm$ dem Mittelwert für die Gruppe *cat*.
- $\bar{y}_{dog} = `r mean_dog`cm$ dem Mittelwert für die Gruppe *dog*.
- $T_{\alpha = 5\%} = `r t_k`$ dem kritischen Wert.
- $s_p = `r sd_p`cm$ der gepoolten Standardabweichung mit $s_p = \tfrac{`r sd_cat`cm + `r sd_dog`cm}{2}$.
- $n_g = 4$ der Gruppengröße der Gruppe A und B. Wir nehmen an beide Gruppen sind gleich groß.
Lösen wir die Formel auf, so ergibt sich folgendes 95% Konfidenzintervall des Mittelwertsunterschiedes der Sprungweiten der Hunde- und Katzenflöhe.
$$1.4cm\;[0.64cm; 2.16cm]$$
Den Mittelwertsunterschied von $1.4cm$ habe ich dann händisch selber berechnet.
## R (Built-in)
Natürlich geht es auch flotter mit der Funktion `t.test()` in R. Du erhälst dann direkt die Konfidenzintervalle unter der Zeile `95 percent confidence interval` wiedergeben.
```{r}
t.test(jump_length ~ animal, data = data_tbl, var.equal = TRUE)
```
Das R Paket `{broom}` erlaubt es über die Funktion `tidy()` es sich auch den Mittelwertsunterschied und die beiden Grenzen des Konfidenzintervalls sauber wiedergeben zu lassen.
```{r}
t.test(jump_length ~ animal, data = data_tbl, var.equal = TRUE) |>
tidy() |>
select(estimate, estimate1, estimate2, conf.low, conf.high)
```
:::
Oder dann einmal die Visualisierung des 95% Konfidenzintervall in der @fig-test-basic-ki-example.
```{r}
#| echo: false
#| message: false
#| warning: false
#| label: fig-test-basic-ki-example
#| fig-align: center
#| fig-height: 2
#| fig-width: 5
#| fig-cap: "Visualisierun des 95% Konfidenzintervall des Mittelwertsunterschiedes der Sprungweiten der Hunde- und Katzenflöhe. *[Zum Vergrößern anklicken]*"
ki_tbl <- tibble(delta = 1.4,
arms = 0.76)
ggplot(ki_tbl) +
aes(x = "cat - dog", y = delta) +
theme_minimal() +
geom_point() +
geom_errorbar(aes(ymin = delta - arms, ymax = delta + arms),
width = 0.1) +
scale_y_continuous(limits = c(-1, 3), breaks = seq(-1, 3, 1)) +
coord_flip() +
theme(axis.text = element_text(size = 12)) +
geom_hline(yintercept = 0, color = "#CC79A7", alpha = 0.8) +
labs(x = "", y = "Mittlerer Sprungweitenunterschied [cm]") +
annotate("text", x = 1.2, y = c(0.64, 1.4, 2.16),
color = "black",
size = 4, label = c(0.64, 1.4, 2.16), fontface = 3)
```
Wir können sagen, dass mit 95% Wahrscheinlichkeit das Konfidenzintervall den wahren Effektunterschied $\Delta$ überdeckt. Oder etwas mehr in Prosa, dass wir eine Sprungweiten*unterschied* von 0.64 cm bis 2.16 cm zwischen Hunde- und Katzenflöhen erwarten würden.
Die Entscheidung gegen die Nullhypothese bei einem Mittelwertsunterschied erfolgt bei einem 95% Konfidenzintervall danach ob die Null mit im Konfidenzintervall liegt oder nicht. In dem Intervall $[0.64; 2.16]$ ist die Null nicht enthalten, also können wir die Nullhypothese ablehnen. Es ist mit einem Unterschied zwischen den mittleren Sprungweiten von Hunde- und Katzenflöhen auszugehen.
In unserem Beispiel, könnten wir die Relevanzschwelle für den mittleren Sprungweitenunterschied zwischen Hund- und Katzenflöhen auf 2 cm setzen. In dem Fall würden wir entscheiden, dass der mittlere Sprungweitenunterschied nicht relevant ist, da die 2 cm im Konfidenzintervall enthalten sind. Was wäre wenn wir die Relevanzschwelle auf 4 cm setzen? Dann wäre zwar die Relevanzschwelle nicht mehr im Konfidenzintervall, aber wir hätten Fall (d) in der @fig-test-basic-ki-02 vorliegen. Der Effekt ist einfach zu klein, dass der Effekt relevant sein könnte.
Wir können dann die 95% Konfidenzintervall des Mittelwertsunterschiedes der Hunde- und Katzenflöhe auch nochmal *richtig* in R berechnen. Dafür schaue dann oben einmal in den zweiten Tab bei der beispielberechnung. Wir haben ja oben eine einfachere Formel für die gepoolte Standardabweichung genutzt. Wenn wir also ganz genau rechnen wollen, dann sind die 95% Konfidenzintervall wie oben im Tab gezeigt. Wir nutzen auch hier die Funktion `t.test()`. Mehr dazu im [Kapitel zum t-test](#sec-ttest), wo wir den t-Test und deren Anwendung im Detail besprechen.
::: callout-note
## Entscheidung mit dem 95% Konfidenzintervall
Bei der Entscheidung mit dem 95% Konfidenzintervall müssen wir zwei Fälle unterscheiden.
(1) Entweder schauen wir uns einen Mittelwertsunterschied ($\Delta_{y_1-y_2}$) an, dann können wir die Nullhypothese (H$_0$) *nicht* ablehnen, wenn die **0** im 95% Konfidenzintervall ist.
(2) Oder wir schauen uns einen Anteilsunterschied ($\Delta_{y_1/y_2}$) an, dann können wir die Nullhypothese (H$_0$) *nicht* ablehnen, wenn die **1** im 95% Konfidenzintervall ist.
:::
## Auswirkung des Effektes, der Streuung und der Fallzahl {#sec-delta-n-s}
Wir wollen einmal den Zusammenhang zwischen dem Effekt $\Delta$, der Streuung als Standardabweichung $s$ und Fallzahl $n$ uns näher anschauen. Wir können die Formel des t-Tests wie folgt vereinfachen.
$$
T_{D}=\cfrac{\bar{y}_1-\bar{y}_1}{s_{p} \cdot \sqrt{2/n_g}}
$$
Für die Betrachtung der Zusammenhänge wandeln wir $\sqrt{2/n_g}$ in $1/n$ um. Dadurch wandert die Fallzahl $n$ in den Zähler. Die Standardabweichung verallgemeinern wir zu $s$ und damit allgemein zur Streuung. Abschließend betrachten wir $\bar{y}_A-\bar{y}_B$ als den Effekt $\Delta$. Es ergibt sich folgende vereinfachte Formel.
$$
T_{D} = \cfrac{\Delta \cdot n}{s}
$$
Wir können uns nun die Frage stellen, wie ändert sich die Teststatistik $T_{D}$ in Abhängigkeit vom Effekt $\Delta$, der Fallzahl $n$ und der Streuung $s$ in den Daten. Die @tbl-t-und-p zeigt die Zusammenhänge auf. Die Aussagen in der Tabelle lassen sich generalisieren. So bedeutet eine steigende Fallzahl meist mehr signifikante Ergebnisse. Eine steigende Streuung reduziert die Signifikanz eines Vergleichs. Ein Ansteigen des Effektes führt zu mehr signifikanten Ergebnissen. Ebenso verschiebt eine Veränderung des Effekt das 95% Konfidenzintervall, eine Erhöhung der Streuung macht das 95% Konfidenzintervall breiter, eine sinkende Streuung macht das 95% Konfidenzintervall schmaler. Bei der Fallzahl verhält es sich umgekehrt. Eine Erhöhung der Fallzahl macht das 95% Konfidenzintervall schmaler und eine sinkende Fallzahl das Konfidenzintervall breiter.
| | $T_{D}$ | $Pr(T_{D}|H_0)$ | $KI_{1-\alpha}$ | | $T_{D}$ | $Pr(T_{D}|H_0)$ | $KI_{1-\alpha}$ |
|:--:|:--:|:--:|----|:--:|:--:|:--:|----|
| $\Delta \uparrow$ | steigt | sinkt | verschoben | $\Delta \downarrow$ | sinkt | steigt | verschoben |
| $s \uparrow$ | sinkt | steigt | breiter | $s \downarrow$ | steigt | sinkt | schmaler |
| $n \uparrow$ | steigt | sinkt | schmaler | $n \downarrow$ | sinkt | steigt | breiter |
: Zusammenhang von der Teststatistik $T_{D}$ und dem p-Wert $Pr(\geq T_{D}|H_0)$ sowie dem $KI_{1-\alpha}$ in Abhängigkeit vom Effekt $\Delta$, der Fallzahl $n$ und der Streuung $s$. {#tbl-t-und-p}
## Referenzen {.unnumbered}