R Code [zeigen / verbergen]
t_d <- flea_tbl |>
specify(jump_length ~ animal) |>
hypothesize(null = "independence") |>
calculate(stat = "t", order = c("dog", "cat"))Letzte Änderung am 24. May 2024 um 18:58:06
“Alles andere wäre auch Wahnsinn.” — Bjarne Mädel, Der Tatortreiniger
Wohin mit der Anwendung von statistischen Tests in R? Ich habe mich jetzt hier für ein einführendes zusätzliches Kapitel entschieden. Du erfährst hier nochmal, wie du einfache Gruppenvergleiche in R durchführst. Mit einfachen Gruppenvergleichen meine ich Gruppenvergleiche, die nur zwei Gruppen beinhalten. Konkret heißt es, dass du die Sprungweite von Hunde- und Katzenflöhen miteinander vergleichen möchtest. Wenn du dann noch Fuchsflöhe hast, dann hast du drei Gruppen und wir sind in dem Kapitel zu multiplen Vergleichen & PostHoc-Tests.
Dieses Startkapitel zu den statistischen Gruppenvergleichen gibt dir somit nochmal eine Übersicht über das statistischen Test in R. Wir konzentrieren uns hier einmal auf das R Paket {infer}. Natürlich kannst du auch alle statistischen Tests mit den Standardfunktionen in R rechnen. Das ist auch vollkommen in Ordnung. Für mich hat das R Paket {infer} aber ein paar Vorteile beim Erklären und Verstehen vom statistischen Testen. Du findest aber dann in den folgenden Kapiteln immer beide Varianten. Eine allgemeine Übersicht findest du auf der Hilfeseite mit den Full {infer} Pipeline Examples. Daher siehst du dann auch immer mal diesen Kasten hier in den folgenden Kapiteln. Beispielsweise zeige ich hier dann einmal den Kasten für den t-Test. Du hast dann immer die Wahl, ob du die Standardfunktion aus {base} oder aber die Implementierung in {infer} nutzt.
{infer}
Auch hier können wir den t-Test in dem R Paket {infer} realisieren. Ein Vorteil von {infer} ist, dass wir die Funktionen sehr gut mit dem |> Operator nutzen können. Deshalb hier einmal die bessere Implementierung, da ich finde, dass die Implementierung in {infer} intuitiver zu verstehen ist.
Wir berechnen die Teststatistik für den t-Test \(T_D\) aus den beobachteten Daten.
t_d <- flea_tbl |>
specify(jump_length ~ animal) |>
hypothesize(null = "independence") |>
calculate(stat = "t", order = c("dog", "cat"))Dann bestimmen wir die Verteilung der Nullhypothese zu der wir unsere berechnete Teststatistik \(T_D\) aus den Daten vergleichen.
null_dist_theory <- flea_tbl |>
specify(jump_length ~ animal) |>
assume("t")Dann wollen wir noch die Fläche neben unsere berechnete Teststatistik \(T_D\) um damit den \(p\)-Wert zu bestimmen.
null_dist_theory %>%
get_p_value(obs_stat = t_d, direction = "two-sided")In der Standardfunktion ist natürlich alles super kurz. Leider fehlt auch die Idee was wir eigentlich machen. Wenn du das verstanden hast, dann geht die Funktion t.test() in {base} natürlich schneller.
t.test(jump_length ~ animal, data = data_tbl)Eine detailliertere Einführung mit mehr Beispielen für die Nutzung vom R Paket {infer} findest du im Kapitel Testen in R. Hier soll es dann bei der kurzen Gegenüberstellung bleiben.
Wir wollen folgende R Pakete in diesem Kapitel nutzen.
pacman::p_load(tidyverse, infer, report, conflicted)
conflicts_prefer(dplyr::filter)[conflicted] Will prefer dplyr::filter over any other package.Ich setze auch noch das Theme in {ggplot} global auf theme_minimal() um hier dann bei den Abbildungen jeweils Code zu sparen.
theme_set(theme_minimal(base_size = 12))An der Seite des Kapitels findest du den Link Quellcode anzeigen, über den du Zugang zum gesamten R-Code dieses Kapitels erhältst.
Für dieses Übersichtskapitel nutzen wir die Daten der Hund- und Katzenflöhe für die Sprunglängen [cm], Anzahl an Flöhen, Gewicht der Flöhe, Boniturnote sowie der Infektionsstatus.
flea_tbl <- read_excel("data/flea_dog_cat.xlsx") |>
mutate(animal = as_factor(animal)) In der Tabelle 30.1 siehst du nochmal den Datensatz in voller Länge. Wir haben jeweils sieben Hunde sowwie sieben Katzenbeobachtungen vorliegen. An den jeweils sieben Beobachtungen haben wir dann unterschiedliche Outcomes \(y\) gemessen. Betrachten wir also einmal im Folgenden verschiedene Möglichkeiten der Analyse von unseren verschiedenen Outcomes \(y\) für die beiden Gruppen der Hunde- und Katzenflöhe.
| animal | jump_length | flea_count | weight | grade | infected |
|---|---|---|---|---|---|
| dog | 5.7 | 18 | 2.1 | 8 | 0 |
| dog | 8.9 | 22 | 2.3 | 8 | 1 |
| dog | 11.8 | 17 | 2.8 | 6 | 1 |
| dog | 5.6 | 12 | 2.4 | 8 | 0 |
| dog | 9.1 | 23 | 1.2 | 7 | 1 |
| dog | 8.2 | 18 | 4.1 | 7 | 0 |
| dog | 7.6 | 21 | 3.2 | 9 | 0 |
| cat | 3.2 | 12 | 1.1 | 7 | 1 |
| cat | 2.2 | 13 | 2.1 | 5 | 0 |
| cat | 5.4 | 11 | 2.4 | 7 | 0 |
| cat | 4.1 | 12 | 2.1 | 6 | 0 |
| cat | 4.3 | 16 | 1.5 | 6 | 1 |
| cat | 7.9 | 9 | 3.7 | 6 | 0 |
| cat | 6.1 | 7 | 2.9 | 5 | 0 |
Wie du schon in der Einleitung zu diesen Kapiteln der statistischen Gruppenvergleiche gelesen hast, gibt es verschiedene Möglichkeiten statistische Maßzahlen zu testen. Zum einen können wir uns Mittelwerte anschauen und diese miteinander oder zu einem festen Wert vergleichen, wenn unser Outcome \(y\) einer Normalverteilung folgt. Wenn unser Outcome \(y\) jedoch nicht einer Normalverteilung folgt und damit auch der Mittelwert nicht die passende zu vergleichende Größe ist, können wir auch Mediane miteinander vergleichen. Etwas seltener haben wir dann den Fall vorliegen, dass wir Anteile oder Prozente in zwei Gruppen vergleichen wollen.
Meine Daten sind normalverteilt. Wenn deine Daten normalverteilt sind, dann kannst du die Mittelwerte miteinander vergleichen. In unserem Beispiel ist die Sprunglänge jump_length oder das Gewicht der Flöhe weight normalverteilt. Wir können also mit einem statistischen Test die mittlere Sprunglänge zwischen Hunde- und Katzenflöhen miteinander vergleichen. Wir würden hier einen t-Test rechnen. Je nachdem, ob die Varianz in den beiden Tiergruppen gleich ist, würden wir uns bei gleicher Varianz für einen Student t-Test entscheiden oder aber bei ungleicher Varianz für einen Welche t-Test.
Der t-Test vergleicht zwei Mittelwerte, gewichtet nach der Standardabweichung und der Fallzahl, miteinander. Etwas statistisch genauer vergleicht der t-Test die Parameter zweier Normalverteilungen miteinander.
Meine Daten sind nicht nromalverteilt. Wenn du Daten vorliegen hast, die keiner Normalverteilung folgen, dann kannst du die Mediane zwischen zwei Grupen miteinander Vergleichen. In unserem Datenbeispiel wäre es die Anzahl an Flöhen flea_count oder die Boniturnote grade, die sich als ein Vergleich der Mediane zwischen den Hunde- und Katzenflöhen anbieten würde. Wir würden in diesem Fall einen Wilcoxon-Mann-Whitney-Test oder U-Test rechnen.
Der U-Test vergleicht die Mediane zweier beliebiger Verteilungen miteinander.
Du bist an einem Vergleich eines Anteils zwischen zwei Gruppen interessiert. Diese Frage kommt in den Agrarwissenschaften eher selten vor. In unserem Beispiel würden wir wissen wollen, ob wir den gleichen Anteil an infizirter Hunde wie auch Katzen in der Spalte infected vorliegen haben. Dafür würden wir die 1 in jeder Gruppe zählen und deren Anteil an der Gesamtzahl an Hunde- oder Katzenflöhen bestimmen. Dann können wir einen \(\mathcal{X}^2\)-Test oder einen Anteilstest rechnen.
Der \(\mathcal{X}^2\)-Test vergleicht die Anteile zweier oder mehrerer Gruppen. Da Anteile Wahrscheinlichkeiten sind, vergleicht der \(\mathcal{X}^2\)-Test damit auch Wahrscheinlichkeiten.
{infer}Es gibt in R mindestens zwei Möglichkeiten einen statistischen Gruppenvergleich zwischen zwei Gruppen zu rechnen. Zum einen stelle ich hier immer die Standardimplementierung {base} jedes statistischen Tests sowie die Nutzung des neuen R Paketes {infer} vor. Eine allgemeine Übersicht findest du auf der Hilfsseite mit den Full {infer} Pipeline Examples. Ich gehe dann auf die einzelnen Beispiele dann in den folgenden Kapiteln ein. Hier soll es erstmal um den allgeminen Ablauf in {infer} gehen. Was müssen wir machen, damit wir in {infer} einen Gruppenvergleich rechnen können? Dabei wird dir vielelicht auch klar, warum teilweise der Ansatz von {infer} etwas intuitiver ist, als die einfache Verwenung der Standardfunktion in {base}.
Wie gehen wir als vor? Die Idee von {infer} orientiert sich sehr schön an dem allgemeinen Prinzip des statistischen Testens. Als erstes müssen wir uns natürlich unsere Teststatistik \(T_D\) aus unseren Daten berechnen. Danach berechnen wir uns eine Nullverteilung zu der der wir unsere berechneten Teststatistik aus den Daten \(T_D\) vergleichen. Dann können wir uns auch den p-Wert visualisieren lassen und schauen, ob alles soweit geklappt hat. Am Ende geht dann auch noch ein 95% Konfidenzintervall, wenn du genug Daten vorliegen hast. Das ist vermutlich die einzige Einschränkung, wenn du nicht genug Beobachtungen pro Gruppe hast, dann gehen die Konfidenzintervalle mit {infer} eher schwieriger. Dazu dann aber weiter unten mehr.
Ich nutze hier als Beispiel für den Weg in {infer} den t-Test. Deshalb auch gleich die Option stat = "t" in allen möglichen Funktionen. Wie du dann aber in den folgenden Kapiteln sehen wirst, geht da natürlich noch mehr. Wir können als Option auch andere Statistiken wählen. Ich habe einmal in den folgenden Tabs und Tabellen alle möglichen Optionen an zu testenden Statistiken dargestellt. Das R Paket {infer} unterstützt dabei nur theoretische Tests für einen oder zwei Mittelwerte über die t-Verteilung oder einen oder zwei Anteile über die z-Verteilung. Wir können die Funktion calculate() nutzen um zwischen den verschiedenen statistischen Maßzahlen zu wählen, die wir Testen wollen. Dabei haben wir dann eine große Auswahl an auch einigen etwas exotischeren Werten, wie zum Beispiel die Summe oder aber dem Quotienten zweier Mittelwerte.
Du hast eine statistische Maßzahl wie den Mittelwert oder den Median erhoben und möchtest testen, ob sich dieser Wert von einem festen, vorgegebenen Wert unterscheidet? Dann kann dir diese Option hier helfen. In hypothesize() musst du dann die Option null = "point" angeben. Siehe dazu weiter unten den Ablauf.
{infer} sowie der Funktion calculate() zu einer Konstanten und der Option stat = statistisch Testen lassen.
stat = |
Frage & Beispiel |
|---|---|
"mean" |
Unterscheidet sich der beobachtete Mittelwert von einem vorgegebenen Mittelwert? Ist mein beobachteter Mittelwert \(\bar{y}_D = 14.2\) signifikant von \(\bar{y}_{H_0} = 10\) unterschiedlich? |
"median" |
Unterscheidet sich der beobachtete Median von einem vorgegebenen Median? Ist mein beobachteter Mittelwert \(\tilde{y}_D = 13.9\) signifikant von \(\tilde{y}_{H_0} = 9\) unterschiedlich? |
"sum" |
Unterscheidet sich die beobachtete Summe von einer vorgegebenen Summe? Ist meine beobachtete Summe \(\sum_D = 212.2\) signifikant von \(\sum_{H_0} = 200\) unterschiedlich? |
"sd" |
Unterscheidet sich die beobachtete Standardabweichung von einer vorgegebenen Standardabweichung? Ist meine beobachtete Standardabweichung \(s_D = 12.2\) signifikant von \(s_{H_0} = 15\) unterschiedlich? |
"prop" |
Unterscheidet sich der beobachtete Anteil von einem vorgegebenen Anteil? Ist mein beobachteter Anteil \(Pr_D = 0.23\) signifikant von \(Pr_{H_0} = 0.5\) unterschiedlich? |
"count" |
Unterscheidet sich die beobachtete Anzahl von einer vorgegebenen Anzahl? Ist meine beobachtete Anzahl \(n_D = 123\) signifikant von \(n_{H_0} = 100\) unterschiedlich? |
Du hast zwei Gruppen und in diesen Gruppen jeweils eine statistische Maßzahl wie den Mittelwert, Median oder Anteile berechnet? Dann kannst du über folgende Optionen einen statistischen Test für den Vergleich der beiden Maßzahlen rechnen. In hypothesize() musst du dann die Option null = "independence" angeben. Siehe dazu weiter unten den Ablauf.
{infer} sowie der Funktion calculate() und der Option stat = statistisch Testen lassen.
stat = |
Frage & Beispiel |
|---|---|
"diff in means" |
Berechnet eine Statistik für die Differenz zweier Mittelwerte. Ist mein beobachteter Mittelwert der Sprungweiten der Hundeflöhe \(\bar{y}_{dog} = 14.2\) signifikant von den beobachteten Mittelwert der Katzenflöhe \(\bar{y}_{cat} = 10\) unterschiedlich? |
"diff in medians" |
Berechnet eine Statistik für die Differenz zweier Mediane. Ist mein beobachteter Median der Sprungweiten der Hundeflöhe \(\tilde{y}_{dog} = 10.2\) signifikant von den beobachteten Median der Katzenflöhe \(\tilde{y}_{cat} = 8.5\) unterschiedlich? |
"diff in props" |
Berechnet eine Statistik für die Differenz zweier Anteile. Ist mein beobachteter Anteil an Infektionen der Hundeflöhe \(Pr_{dog} = 0.43\) signifikant von den beobachteten Anteil an Infektionen der Katzenflöhe \(Pr_{cat} = 0.76\) unterschiedlich? |
"ratio of means" |
Berechnet eine Statistik für das Verhältnis zweier Mittelwerte. Ist mein beobachteter Mittelwert der Sprungweiten der Hundeflöhe \(\bar{y}_{dog} = 14.2\) signifikant von den beobachteten Mittelwert der Katzenflöhe \(\bar{y}_{cat} = 10\) unterschiedlich? |
"ratio of props" |
Berechnet eine Statistik für das Verhältnis zweier Anteile. Ist mein beobachteter Anteil an Infektionen der Hundeflöhe \(Pr_{dog} = 0.43\) signifikant von den beobachteten Anteil an Infektionen der Katzenflöhe \(Pr_{cat} = 0.76\) unterschiedlich? |
"odds ratio" |
Berechnet eine Statistik für das Chancenverhältnis zweier Anteile. Ist die Chance von Hunden sich mit Flöhen zu infizieren unterschiedlich zu der Chance von Katzen sich mit Flöhen zu infizieren? |
"slope" |
Berechnet eine Statistik über die Steigung einer Geraden zwischen zwei Variablen. Hier bitte das Kapitel zur lineare Regression verwenden. |
"correlation" |
Berechnet eine Statistik über die Korrelation zweier Variablen. Hier bitte das Kapitel zur Korrelationsanalyse verwenden. |
Manchmal wollen wir einfach einen statistischen Test nachkochen. Das können wir dann mit der Hilfe der folgenden Statistiken machen. Das ist jetzt vermutlich aber eher ein Nischenthema in diesem Kapitel hier. Die Anwendung zeige ich dir dann immer mal wieder, aber du kannst auch ohne weiteres die Standardfunktionen in R nutzen.
{infer} sowie der Funktion calculate() und der Option stat = statistisch Testen lassen.
stat = |
Frage & Beispiel |
|---|---|
"chisq" |
Berechnet die Teststatistik eines \(\mathcal{X}^2\)-Tests |
"f" |
Berechnet die Teststatistik einer ANOVA |
"t" |
Berechnet die Teststatistik eines t-Tests |
"z" |
Berechnet die Teststatistik eines standardisierten z-Tests |
Wenn wir die Teststatistik \(T_D\) aus unseren Daten berechnen wollen, dann können wir dies in dem R Paket {infer} auf zwei Arten tun. Zum einen über die Funktionen specify(), hypothesize() und calculate() oder aber über die zusammenfassende Funktion observed(). Je nachdem wie gut du schon im Thema drin bist, ist natürlich die Funktion observe() kürzer und etwas weniger Code. Da die Funktion observe() eben auch nur die drei Funktionen zusammenfasst, erkläre ich jetzt erstmal den etwas längeren Weg. Du kannst dann dir nochmal beides in den folgenden Tabs einmal anschauen. Wie immer ist es eine Geschmacksfrage, wie du dir die Sachen berechnen willst. Der etwas längere Weg über drei Funktionen ist dann auch etwas logischer und besser nachzuvollziehen. Wenn man alles verstanden hat, dann ist natürlich observe() schneller.
Im Folgenden einmal der etwas längere Weg die beobachtete Teststatistik \(T_D\) aus unseren Daten zu berechnen. Ich persönlich mag den längeren Weg lieber, da ich hier besser sehe, was ich eigentlich mache.
specify()Die Funktion legt fest, was unser Outcome und was unsere Gruppen sind. Oder noch konkreter, in welcher Spalte unseres Datensatzes ist das Outcome jump_length und in welcher Spalte die Gruppen animal verortet?
hypothesize()Die Funktion legt fest, ob wir zwei Gruppen auf einen Unterschied mit der Option null = "independence" testen wollen oder aber wissen wollen, ob sich der Wert von unserem Outcome von einem fixen Wert mit der Option null = "point" unterscheidet.
calculate()Die Funktion rechnet dann die Teststatistik stat in der Ordnung order. Wenn wir zum Beispiel zwei Mittelwerte haben, dann können wir über die Ordnung angeben, welcher Mittelwert von welchem abgezogen wird.
Damit haben wir dann auch alles zusammen und können einmal für unseren Sprunglängen der Hunde- und Katzenflöhe die Teststatistik t eines t-Tests berechnen.
t_d <- flea_tbl |>
specify(jump_length ~ animal) |>
hypothesize(null = "independence") |>
calculate(stat = "t", order = c("dog", "cat"))Dann schauen wir uns einmal die berechnete Teststatistik \(T_D\) aus den Daten an. Beachte wie immer, die Teststatistik ist eine einheitslose Statistik und sagt erstmal so nichts weiter aus.
t_dResponse: jump_length (numeric)
Explanatory: animal (factor)
Null Hypothesis:...
# A tibble: 1 × 1
stat
<dbl>
1 3.13Hier die schnelle Variante. Du gibt es im Prinzip gleich in der Funktion die Formel für den Vergleich ein. Dann spezifizierst du die Statistik, die berechnet werden soll und musst noch die Ordnung der beiden Gruppen angeben. Die Variante ist natürlich super kompakt und macht vermutlich mehr Sinn, wenn du mehrere Tests rechnest und die Idee hinter {infer} verstanden hast.
t_d <- flea_tbl |>
observe(jump_length ~ animal,
stat = "t", order = c("dog", "cat"))Dann schauen wir uns einmal die berechnete Teststatistik \(T_D\) aus den Daten an. Beachte wie immer, die Teststatistik ist eine einheitslose Statistik und sagt erstmal so nichts weiter aus.
t_dResponse: jump_length (numeric)
Explanatory: animal (factor)
# A tibble: 1 × 1
stat
<dbl>
1 3.13Mit der Teststatistik \(T_D\) aus unseren Daten können wir dann weitermachen und unseren \(p\)-Wert berechnen in dem wir die Teststatistik \(T_D\) zu einer Verteilung der Nullhypothese vergleichen.
Wie eben schon erwähnt, können wir mit der Teststatistik \(T_D\) aus unseren Daten so nichts anfangen. Wir müssen die Teststatistik \(T_D\) zu einer Verteilung einer Nullhypothese vergleichen, damit wir eine Aussage über die Wahrscheinlichkeit unserer Daten unter der Annahme, dass die Nullhypothese wahr ist, berechnen können. Wir nutzen die Funktion hypothesize() um die Verteilung der Null zu generieren.
hypothesize()Die Funktion legt fest, ob wir zwei Gruppen auf einen Unterschied mit der Option null = "independence" testen wollen oder aber wissen wollen, ob sich der Wert von unserem Outcome von einem fixen Wert mit der Option null = "point" unterscheidet.
Wir haben in dem R Paket {infer} zwei Möglichkeiten die Verteilung einer Nullhypothese zu berechnen. Entweder nutzen wir unsere Daten um aus den Daten eine Verteilung der Null zu simulieren oder aber wir nehmen eine Verteilung der Null an und können so eine theoretische Verteilung der Nullhypothese nutzen. Beides zeige ich dann einmal in den folgenden Tabs.
Der Code sieht eigentlich fast genau so aus, wie bei der Berechnung der Teststatistik \(T_D\). Das stimmt ja auch zu großen Teilen. Wir generieren uns aus den Daten mit der Funktion generate() die Verteilung einer Null. Du kannst hier zwischen zwei Verfahren wählen, ich würde hier permute nutzen, wenn du nicht so viele Beobachtungen in den Gruppen vorliegen hast. Die Idee ist, dass du deine beiden Gruppenzugehörigkeiten zufällig den gemessenen Werten zuweist. Dann berechnest du wieder die Teststatistik und fertig ist deine Verteilung der Nullhypothese mit 1000 Wiederholungen.
null_dist_data <- flea_tbl |>
specify(jump_length ~ animal) |>
hypothesize(null = "independence") |>
generate(reps = 1000, type = "permute") |>
calculate(stat = "t", order = c("dog", "cat"))Viele statistische Maßzahlen, wie der t-Test, haben eine bekannte, theoretische Verteilung. Dementsprechend müsstest du dir die Verteilung der Nullhypothese aus einer t-Statistik nicht simulieren. Wir können hier einfach die t-Verteilung annehmen. Dafür haben wir dann die Funktion assume(). Wenn du nicht so gut vertraut mit den ganzen Verteilungen bist, dann hilft meistens die Simulation eher weiter.
null_dist_theory <- flea_tbl |>
specify(jump_length ~ animal) |>
assume("t")Dann schauen wir uns die Teststatistik \(T_D\) zusammen mit der Nullhypothese an. Eigentlich kommt ja jetzt erst der eigentliche statistsiche Test. Weil wir eben auch gerade zwei Verteilungen von der Null berechnet haben, einmal die simulierte und einmal die theoretische Verteilung, haben wir jetzt auch wieder zwei Möglichkeiten des Vergleichens. Daher einmal der Vergleich von der Teststatistik \(T_D\) zu der simulierten Null aus den Daten sowie der Vergleich zu der theoretischen Verteilung der Nullhypothese eines t-Tests.
In der folgenden Abbildung siehst du einmal die simulierte Nullhypothese aus unseren Daten zusammen mit der berechneten Teststatistik \(T_D\). Wir haben ja 1000 Teststatistiken berechnet unter der Annahme, dass wir keinen Effekt in den Daten vorliegen haben. Dafür hatten wir den Bezug von den Gruppen zu dem Outcome aufgelöst. Die eingefärbte Fläche ist dann der p-Wert.
visualize(null_dist_data) +
shade_p_value(obs_stat = t_d, direction = "two-sided") +
labs(x = "Statistik", y = "Absolute Häufigkeit")
Da wir hier in unserem Beispiel einen t-Test gerechnet haben, haben wir auch die theoretische Verteilung der Nullhypothese eines t-Tests vorliegen. Diese habe ich dann auch einmal in der folgenden Abbildung visualisiert. Da wir hier nicht auf echte Daten angewiesen sind, ist die Kurve auch sehr schön glatt. Die eingefärbte Fläche ist dann der \(p\)-Wert.
visualize(null_dist_theory) +
shade_p_value(obs_stat = t_d, direction = "two-sided") +
labs(x = "Statistik", y = "Relative Häufigkeit")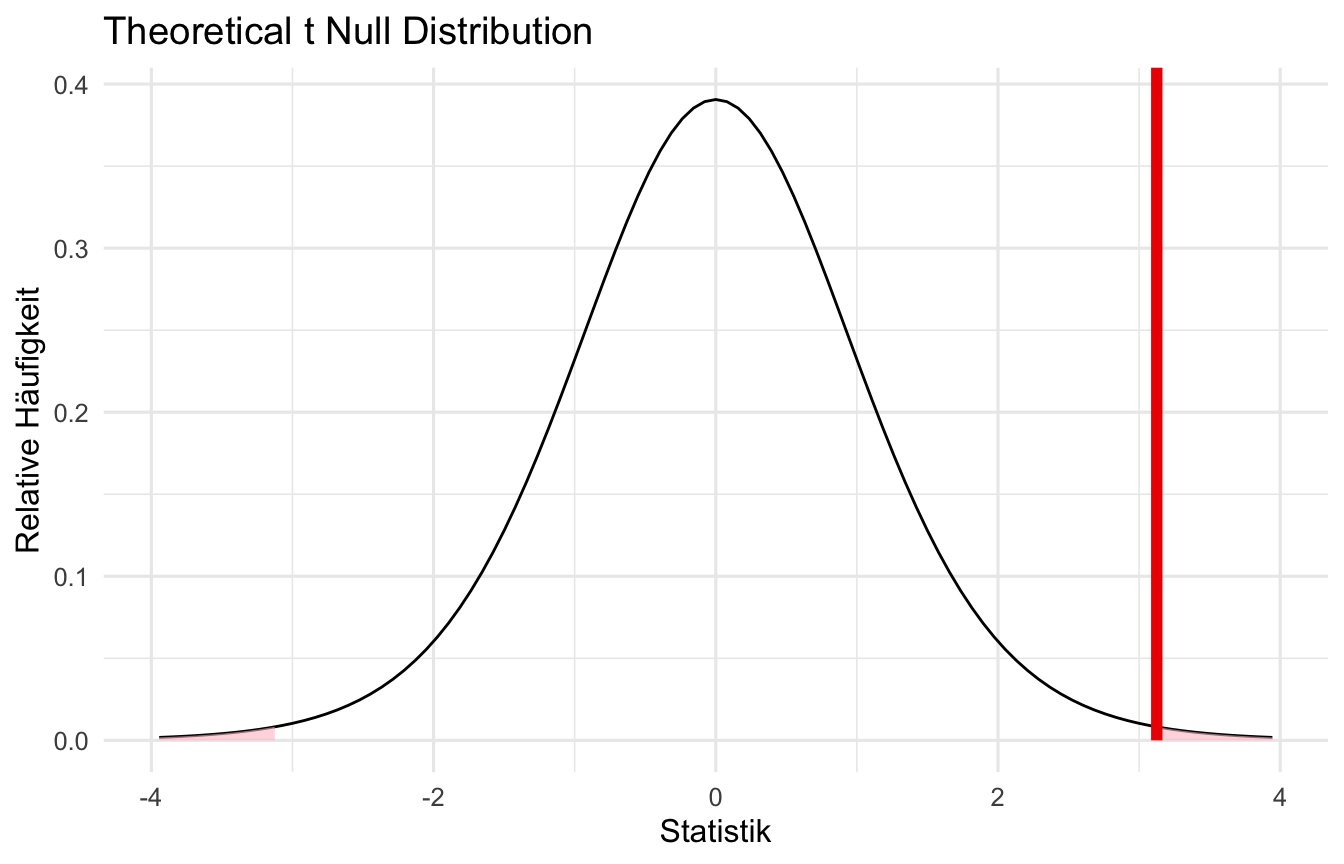
In den beiden Abbildungen können wir zwar schön die eingefärbten Flächen als die \(p\)-Werte identifizieren, aber leider wollen wir nicht nur die Werte sehen sondern auch die numerischen Werte der Flächen haben. Dafür nutzen wir dann die Funktion get_p_value(), die uns dann erlaubt aus einer Verteilung der Nullhypothese die Fläche neben der beobachteten Teststatistik \(T_D\) zu berechnen. Wir machen das jetzt einmal für die simulierte Nullhypothese und erhalten folgenden \(p\)-Wert. Wenn wir den \(p\)-Wert aus den echten Daten simulieren, dann ist er nicht so genau wie der \(p\)-Wert aus der theoretischen Verteilung der Nullhypothese.
null_dist_data %>%
get_p_value(obs_stat = t_d, direction = "two-sided")# A tibble: 1 × 1
p_value
<dbl>
1 0.014Auch hier dann einmal zum Vergleich, der \(p\)-Wert aus der theoretischen Verteilung der Nullhypothese. Prinzipiell ist dieser \(p\)-Wert vorzuziehen, aber nicht immer ist eine theoretische Verteilung der Null unter der Statistik, die wir nutzen, bekannt.
null_dist_theory %>%
get_p_value(obs_stat = t_d, direction = "two-sided")# A tibble: 1 × 1
p_value
<dbl>
1 0.00891Als Fazit lässt sich ziehen, dass beide \(p\)-Werte einen signifikanten Unterschied zwischen den Sprungweiten der Hunde- und Katzenflöhe zeigen. Das der \(p\)-Wert aus der theoretischen Verteilung der Null kleiner ist verwundert bei der etwas geringen Fallzahl in unserem Datenbeispiel nicht. Wenn du mehr Beobachtungen in deinen Gruppen hast, dann werden sich die \(p\)-Werte der simulierten und theoretischen Verteilung angleichen.
Im Folgenden wollen wir einmal das 95% Konfidenzintervall für einen Mittelwertsvergleich "diff in means" berechnen. Auch hier helfen dann die Beispiele von {infer} zu den Konfidenzintervallen. Wir machen das jetzt nicht für eine Teststatistik t, da uns ehrlicherweise nicht interessiert, in wie weit unsere beobachtete Teststatistik \(T_D\) in ein 95% Konfidenzintervall fällt. Daher müssen wir nochmal eine neue Teststatistik aus unseren Daten berechnen. Diesmal nehmen wir also als statistische Maßzahl, für die wir dir Statistik \(T_D\) berechnen wollen, den Unterschied in den Mittelwerten der Sprungweite zwischen den Hunde- und Katzenflöhen.
t_d <- flea_tbl |>
specify(jump_length ~ animal) |>
calculate(stat = "diff in means", order = c("dog", "cat"))Dann brauchen wir noch die Verteilung der Nullhypothese um die 95% Konfidenzintervalle berechnen zu können. Dafür nutze ich hier jetzt mal als Permutationsverfahren das Bootstraping mit type = bootstrap. Ich würde hier die 95% Konfidenzintervalle aus dem Bootstraping bevorzugen. Dann haben wir auch schon unsere Verteilung der Null und können diese Nutzen um unsere 95% Konfidenzintervalle zu bestimmen.
boot_dist <- flea_tbl |>
specify(jump_length ~ animal) |>
hypothesize(null = "independence") |>
generate(reps = 1000, type = "bootstrap") |>
calculate(stat = "diff in means", order = c("dog", "cat"))Jetzt gibt es zwei Möglichkeiten die 95% Konfidenzintervalle zu bestimmen. Entweder über die Perzentile und damit dem 2.5% und 97.5% Quantile oder aber über den Standardfehler. Ich zeige dir einmal beides in den folgenden Tabs.
Wenn du das Verfahren der Perzentile nutzt um dir die 95% Konfidenzintervalle berechnen zu lassen, brauchst du eigentlich gar nicht \(T_D\) berechnen. Es reicht vollkommen die Verteilung der Nullhypothese in die Funktion get_ci() zu stecken.
percentile_ci <- boot_dist |>
get_ci(type = "percentile")Dann können wir uns auch schon das 95% Konfidenzintervall für den Mittelwertsvergleich der Sprungweiten der Hunde- und Katzenflöhe wiedergeben lassen.
percentile_ci# A tibble: 1 × 2
lower_ci upper_ci
<dbl> <dbl>
1 1.26 5.35Manchmal wollen wir nicht die Perzentile nutzen sondern die 95% Konfidenzintervalle mit dem Standardfehler und der Differenz der Mittelwerte point_estimate berechnen. Daher hier einmal die Methode mit dem Standardfehler und der Differenz der Mittelwerte.
standard_error_ci <- boot_dist %>%
get_ci(type = "se", point_estimate = t_d)Dann können wir uns auch schon das 95% Konfidenzintervall für den Mittelwertsvergleich der Sprungweiten der Hunde- und Katzenflöhe wiedergeben lassen.
standard_error_ci# A tibble: 1 × 2
lower_ci upper_ci
<dbl> <dbl>
1 1.36 5.41Da der Unterschied zwischen den beiden Verfahren numerisch sehr klein ist und damit eigentlich kaum im direkten Vergleich zu sehen, hier dann nur einmal in der Abbildung 30.3 die 95% Konfidenzintervall für die Methode der Perzentile. Die Darstellung ist eigentlich eher für das Verständnis als für eine Publikation oder Abschlussarbeit. Das wirklich praktische ist hier, dass wir uns auch für Verfahren, wo es eigentlich keine theoretischen 95% Konfidenzintervalle gibt, dennoch welche bauen können. Das finde ich dann wirklich praktisch. Dazu dann mehr in den folgenden Kapiteln, wenn wir es brauchen.
visualize(boot_dist) +
shade_confidence_interval(endpoints = percentile_ci) +
labs(x = "Statistik", y = "Absolute Häufigkeit")
Sehr selten wollen wir nicht zwei Gruppen miteinander vergleichen sondern eine statistische Maßzahl gegen einen Referenzwert. Das heißt, wir wollen wissen, ob die Hundeflöhe unterschiedliche von einer festen Sprungweite mit 10cm springen. Wir setzen also unseren Referenzwert auf 10 und wollen dann Testen, ob sich der beobachtete Mittelwert von der Referenz signifikant unterscheidet.
jump_length_bar <- flea_tbl |>
filter(animal == "dog") |>
specify(response = jump_length) |>
calculate(stat = "mean")Im nächsten Schritt brauchen wir dann wieder unsere Nullverteilung. Hier müssen wir dann den Referenzwert mit mu = 10 als Mittelwert in der Funktion hypothesize() setzen. Wichtig ist hier, dass du die Option null = "point" wählst.
null_dist <- flea_tbl |>
filter(animal == "dog") |>
specify(response = jump_length) |>
hypothesize(null = "point", mu = 10) |>
generate(reps = 1000) |>
calculate(stat = "mean")Abschließend können wir dann wie oben beschrieben den p-Wert bestimmen.
null_dist %>%
get_p_value(obs_stat = jump_length_bar, direction = "two-sided")# A tibble: 1 × 1
p_value
<dbl>
1 0.004Wir sehen, dass sich die mittlere Sprungweite der Hundeflöhe signifikant von dem Referenzwert mit 10cm unterscheidet. Sehr häufig brauchen wir den Test auf einen Referenzwert nicht, aber es ist gut diese Möglichkeit in der statistischen Toolbox zu haben.
{report}Hier nur ganz kurz, da wir dann die Anwendung des R Paket {report} in den folgenden Kapiteln jeweils im Einsatz sehen werden. Das R Paket {report} erlaubt uns die Ausgabe von Funktionen in lesbaren Text umzuwandeln. Gut, der Text ist Englisch, aber da helfen dann andere Übersetzungsprogramme wie DeepL weiter. Deshalb hier nur ein Beispiel, damit du eine Idee von der Nutzung hast.
t.test(jump_length ~ animal, data = flea_tbl) |>
report()Effect sizes were labelled following Cohen's (1988) recommendations.
The Welch Two Sample t-test testing the difference of jump_length by animal
(mean in group dog = 8.13, mean in group cat = 4.74) suggests that the effect
is positive, statistically significant, and large (difference = 3.39, 95% CI
[1.02, 5.75], t(11.83) = 3.13, p = 0.009; Cohen's d = 1.82, 95% CI [0.44,
3.14])Das einzige was ich immer etwas anstrengend finde ist mir dann die Referenzen von der Hilfsseite von {report} rauszusuchen.