R Code [zeigen / verbergen]
pacman::p_load(tidyverse, magrittr, readxl, janitor,
corrplot, GGally, ggraph, correlation, see,
conflicted)
conflicts_prefer(dplyr::filter)Letzte Änderung am 29. January 2025 um 09:10:54
“Most of you will have heard the maxim ‘correlation does not imply causation.’ Just because two variables have a statistical relationship with each other does not mean that one is responsible for the other. For instance, ice cream sales and forest fires are correlated because both occur more often in the summer heat. But there is no causation; you don’t light woodlands on fire when you buy a scoop of ice cream.” — Nate Silver, The Signal and the Noise: Why So Many Predictions Fail – But Some Don’t
Die Korrelation gibt uns die Information welche Steigung die Gerade in einer simplen linearen Regression hat. Das ist die einfache Antwort auf die Frage, was die Korrelation aus statistischer Sicht ist. Dabei erlaubt es die Korrelation uns verschiedene Geraden miteinander zu vergleichen auch wenn unsere Variablen unterschiedliche Einheiten haben. Die Korrelation ist nämlich einheitslos. Wir standardisieren durch die Anwendung der Korrelation die Steigung der Geraden dafür auf -1 bis +1. Damit ist die Korrelation ein bedeutendes Effektmaß für die Abschätzung eines Zusammenhangs zwischen zwei Variablen. Wir nutzen die Korrelation in vielen Bereichen der Agrarwissenschaften. Wichtig ist, dass wir immer zwei Variablen, also damit auch Spalten, miteinander vergleichen. Diese Variablen müssen eine Zahl, also numerisch, sein. Im Weiteren schaue dann auch mal in dem Kapitel zu den Effektmaßen und Interrater Reliabilität. Wir wollen dort die Frage beantworten, in wie weit zwei Bewerter die gleichen Boniturnoten vergeben. In der Abbildung 48.1 siehst du einmal eine Darstellung, wie die Korrelation zwischen verschiedenen Variablen dargestellt werden kann.
Es gibt aber ein Problem in dem allgemeinen Sprachgebrauch. Das Wort korrelieren ist zum Gattungsbegriff in der Statistik geworden, wenn es um den Vergleich oder den Zusammenhang von zwei oder mehreren Variablen geht. Das heißt, in der Anwendung wird gesagt, dass wir A mit B korrelieren lassen wollen. Das Wort korrelieren steht jetzt aber nicht für das Konzept statistische Korrelation sondern ist Platzhalter für eine noch vom Anwender zu definierende oder zu findende statistische Methode. Im Weiteren müssen wir beachten, dass nur weil etwas miteinander korreliert muss es keinen kausalen Zusammenhang geben. So ist die Ursache und Wirkung manchmal nicht klar zu benennen. Nehmen wir als plakatives Beispiel dicke Kinder, die viel Fernsehen. Wir würden annehmen, dass zwischen dem Fernsehkonsum und dem Gewicht von Kindern eine hohe Korrelation vorliegt. Sind jetzt aber die Kinder dick, weil die Kinder so viel Fernsehen oder schauen einfach dicke Kinder mehr Fernsehen, da die Kinder dick sind und sich nicht mehr so viel bewegen wollen? Die Internetseite Spurious correlations zeigt verschiedene zufällige Korrelationen zwischen zwei zufällig ausgewählten Variablen aus den USA. Es ist immer wieder spannend zu sehen, was da zufällig miteinander ähnlich agiert.
Wie immer gibt es auch Literatur zu dem Thema Korrelation. Vielleicht brauchst du ja das ein oder andere Zitat oder willst dich einfach mal weiterbilden. Asuero et al. (2006) hebt in seiner Arbeit The Correlation Coefficient: An Overview die unbedingte Bedeutung der Visualisierung des Korrelationskoeffizient \(r\) hervor. Im Folgenden einmal eine der Kernaussagen der Arbeit. Daneben lohnt sich das Lesen und Betrachten der Abbildungen sehr. Meistens denkt man dann doch falsch, da ein Korrelationskoeffizient nicht immer das visualisiert bedeuten mag was man denkt.
A high value of \(r\) is thus seen to be no guarantee at all that a straight line rather than a curve […]. It is for this reason that the plot must always be inspected visually. In short, the \(r\) value is in reality not a measure of model adequacy […]. Residual analysis on this respect is a good way to decide if a linear fit was a good choice. — Asuero et al. (2006)
In der Arbeit Statistics review 7: Correlation and regression von Bewick et al. (2003) werden nochmal die wichtigsten Punkte der Regression und Korrelation behandelt. Ich finde es ist eine sehr schöne Übersichtsarbeit auch über die lineare Regression. Es gibt auch ein extra Abschnitt über die falsche Nutzung (eng. misuse of correlation) mit folgendem Zitat.
One of the most common errors in interpreting the correlation coefficient is failure to consider that there may be a third variable related to both of the variables being investigated, which is responsible for the apparent correlation. Correlation does not imply causation. — Bewick et al. (2003), Misuse of correlation
Denn eigentlich bist nichts so häufig genutzt wie auch falsch verstanden oder falsch interpretiert als die Korrelation. Akoglu (2018) User’s guide to correlation coefficients mit der Interpretation of the Pearson’s and Spearman’s correlation coefficients. Eine Besonderheit stellen in den Agrawissenschaften zum Beispiel räumliche Daten dar. Taylor & Bates (2013) stellen in ihrer Arbeit A discussion on the significance associated with Pearson’s correlation in precision agriculture studies nochmal Besonderheiten der Analyse von autokorrelierten Daten dar. Das heißt, wir messen eine Beobachtung räumlich in der Nähe. Natürlich haben wir dann einen ähnlichen Boden oder klimatische Bedingungen. Hier müssen wir dann speziell schauen, wie wir solche autokorrelierte Daten analysieren. Das ist dann ein anderes Thema im Sinne von zeitlichen Daten (eng. time series) oder räumlichen Daten (eng. spatial data). In eine ähnliche Kerbe schlagen da Shao et al. (2022) in ihrer Veröffentlichung How Accurate Is Your Correlation? Different Methods Derive Different Results and Different Interpretations. In der Arbeit werden noch weitere Möglichkeiten der Korrelationsanalyse vorgestellt, die dieses Kapitel bei weitem Übersteigen. So wird dort nochmal zwischen der Korrelationsanalyse der 1. Generation, was wir mehr oder minder hier machen, und der 2. Generation unterschieden. Viele der Methoden sind natürlich als R Paket implementiert. Wenn dich also mehr interessiert, schaue da gerne einmal rein.
In diesem Kapitel wollen wir uns mit der statistischen Korrelation beschäftigen. Die statistische Korrelation ist weniger aufregender, denn am Ende ist die Korrelation nur eine Zahl zwischen -1 und +1. Eigentlich ist das eine wichtige Botschaft, denn wenn deine berechnete Korrelation nicht zwischen -1 und +1 liegt, dann hast du was anderes berechnet oder aber hier stimmt was nicht.
Wir wollen folgende R Pakete in diesem Kapitel nutzen.
pacman::p_load(tidyverse, magrittr, readxl, janitor,
corrplot, GGally, ggraph, correlation, see,
conflicted)
conflicts_prefer(dplyr::filter)An der Seite des Kapitels findest du den Link Quellcode anzeigen, über den du Zugang zum gesamten R-Code dieses Kapitels erhältst.
Wir wollen uns erstmal mit einem einfachen Datenbeispiel beschäftigen. Wir können die Korrelation auf sehr großen Datensätzen berechnen, wie auch auf sehr kleinen Datensätzen. Prinzipiell ist das Vorgehen gleich. Wir nutzen jetzt aber erstmal einen kleinen Datensatz mit \(n=7\) Beobachtungen. Wir nutzen den Datensatz ist gleich für die händischen Berechnungen, da brauchen wir nicht viele Datenpunkte.
simple_tbl <- tibble(jump_length = c(1.2, 1.8, 1.3, 1.7, 2.6, 1.8, 2.7),
weight = c(0.8, 1, 1.2, 1.9, 2, 2.7, 2.8))In der Tabelle 48.1 ist der Datensatz simplel_tbl dargestellt. Wir wollen den Zusammenhang zwischen der Sprungweite in [cm] und dem Gewicht in [mg] für sieben Beobachtungen modellieren. Oder anders ausgedrückt, wir wollen einfach die Korrelation berechnen.
jump_length und der normalverteilten Variable weight.
| jump_length | weight |
|---|---|
| 1.2 | 0.8 |
| 1.8 | 1.0 |
| 1.3 | 1.2 |
| 1.7 | 1.9 |
| 2.6 | 2.0 |
| 1.8 | 2.7 |
| 2.7 | 2.8 |
In Abbildung 48.2 sehen wir die Visualisierung der Daten simple_tbl in einem Scatterplot mit einer geschätzten Gerade. Wir wollen jetzt mit der Korrelation die Steigung der Geraden unabhängig von der Einheit beschreiben. Oder wir wollen die Steigung der Geraden standardisieren auf -1 bis 1.
ggplot(simple_tbl, aes(weight, jump_length)) +
geom_point() +
stat_smooth(method = "lm", se = FALSE, fullrange = TRUE) +
theme_minimal() +
xlim(0, 3.5) + ylim(0, 3.5)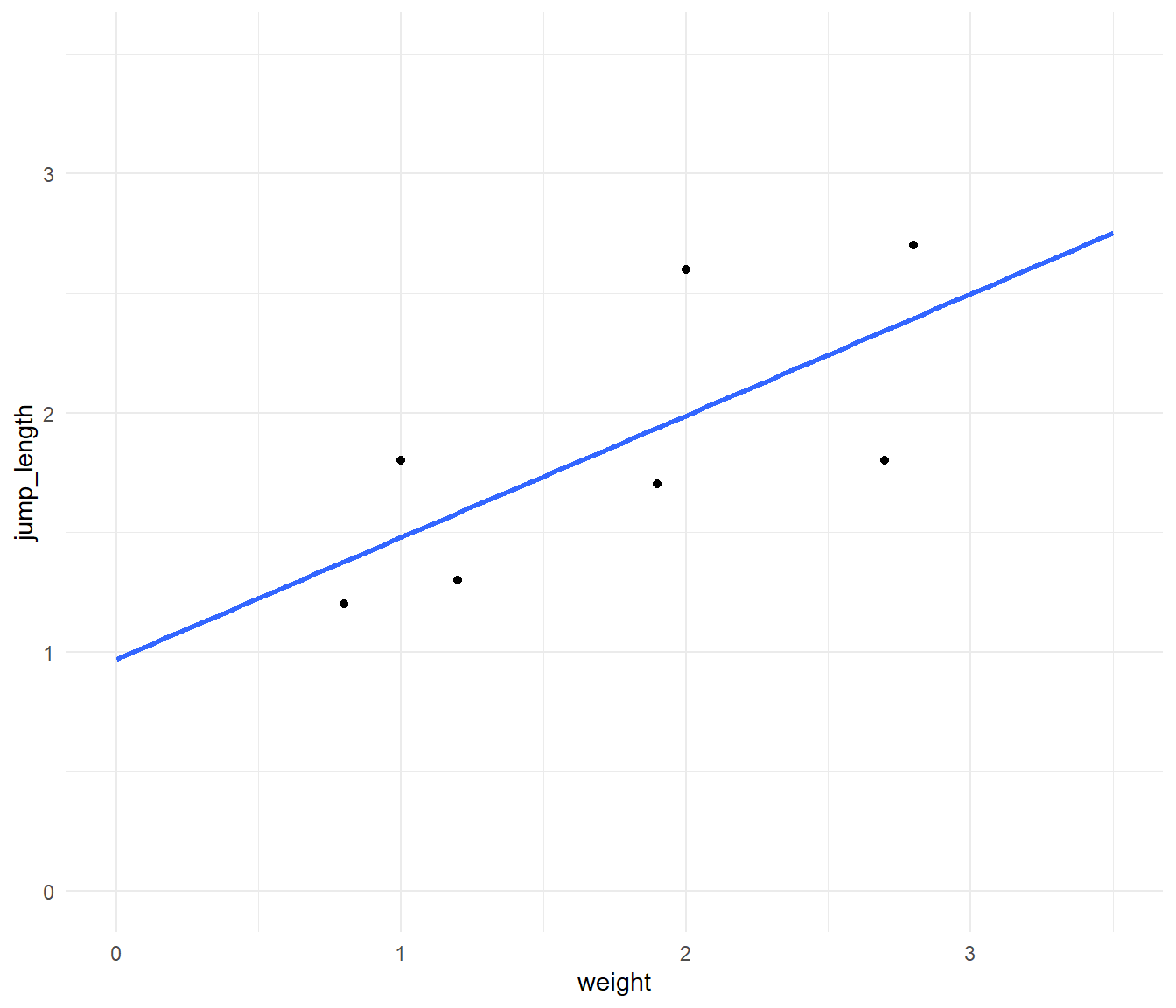
Als nächstes wollen wir uns ein schönes Beispiel aus der Publikation von Matthews (2000) mit dem Titel Storks Deliver Babies (p = 0.008) anschauen. In der Arbeit wird der Frage nachgegangen, ob tatsächlich mehr Störche storks_pairs in einem Gebiet für mehr Babies birth_rate sorgen. Dafür wurden dann neben den Informationen über das Land country noch die Fläche area_km2 sowie die Bevölkerungsdichte humans_millions erhoben. Eine wunderbare Fragestellung, die wir hier dann nochmal detailiert betrachten wollen.
stork_tbl <- read_excel("data/storks_deliver_babys.xlsx") |>
clean_names() |>
rename(birth_rate = birth_rate_1000_yr)In der Tabelle 48.2 siehst du dann nochmal einen Auszug aus den Daten. Insgesamt haben wir uns siebzehn etwas willkürich gewählte Länder angeschaut zu denen wir die Informationen gefunden haben.
| country | area_km2 | storks_pairs | humans_millions | birth_rate |
|---|---|---|---|---|
| Albania | 28750 | 100 | 3.2 | 83 |
| Austria | 83860 | 300 | 7.6 | 87 |
| Belgium | 30520 | 1 | 9.9 | 118 |
| Bulgaria | 111000 | 5000 | 9 | 117 |
| … | … | … | … | … |
| Romania | 237500 | 5000 | 23 | 367 |
| Spain | 504750 | 8000 | 39 | 439 |
| Switzerland | 41290 | 150 | 6.7 | 82 |
| Turkey | 779450 | 25000 | 56 | 1576 |
Als weiteren Datensatz nutzen wir die Gummibärchendaten und zwar alle numerischen Spalten von count_bears bis zum semester. Dann nehme ich nur die Teilnehmerinnen an der Umfrage, da ich sonst Probleme mit der Körpergröße kriege. Männer und Frauen sind unterschiedlich groß und dann würden wir immer eine Art Effekt von dieser Sachlage bekommen, wenn wir Männer und Frauen nicht getrennt betrachten. Wenn du keine numerischen Daten sondern Worte vorliegen hast, dann kannst du über die Funktion as.factor() dir erst einen Faktor erschaffen und dann über as.numeric() aus dem Faktor eine Zahl machen. Ich zeige dir das hier einmal an der Spalte most_liked.
corr_gummi_tbl <- read_excel("data/gummibears.xlsx") |>
filter(gender == "w") |>
select(count_bears:semester) |>
mutate(most_liked = as.numeric(as.factor(most_liked))) |>
select_if(is.numeric)Dann in der Tabelle 48.3 nochmal ein Auszug aus den Daten. Wir betrachten hier nur die numerischen Spalten, da wir nur über diese eine Korrelation berechnen können. Du siehst wie wir die Worte in der Spalte most_liked dann in einer Zahl umgewandelt haben. Jede der Zahlen steht dann für eine der sechs Farben der Gummibärchen plus die “keine Präferenz”-Kategorie. Da wir die eigentliche Übersetzung nicht brauchen um die Korrelation zu interpretieren, passt das hier ganz gut.
| count_bears | count_color | most_liked | age | height | semester |
|---|---|---|---|---|---|
| 10 | 5 | 7 | 21 | 159 | 6 |
| 9 | 6 | 6 | 21 | 159 | 6 |
| 10 | 5 | 6 | 36 | 180 | 10 |
| 13 | 5 | 2 | 21 | 163 | 3 |
| … | … | … | … | … | … |
| 9 | 5 | 1 | 19 | 175 | 1 |
| 8 | 4 | 2 | 27 | 163 | 17 |
| 9 | 4 | 2 | 26 | 177 | 2 |
| 8 | 4 | 1 | 28 | 174 | 6 |
Wir schauen uns hier die Korrelation nach Pearson an. Die Korrelation nach Pearson nimmt an, dass beide zu korrelierende Variablen einer Normalverteilung entstammen. Wenn wir keine Normalverteilung vorliegen haben, dann nutzen wir die Korrelation nach Spearman. Die Korrelation nach Spearman basiert auf den Rängen der Daten und ist ein nicht-parametrisches Verfahren. Die Korrelation nach Pearson ist die parametrische Variante. Wir bezeichnen die Korrelation entweder mit \(r\) oder dem griechischen Buchstaben \(\rho\) als rho gesprochen.
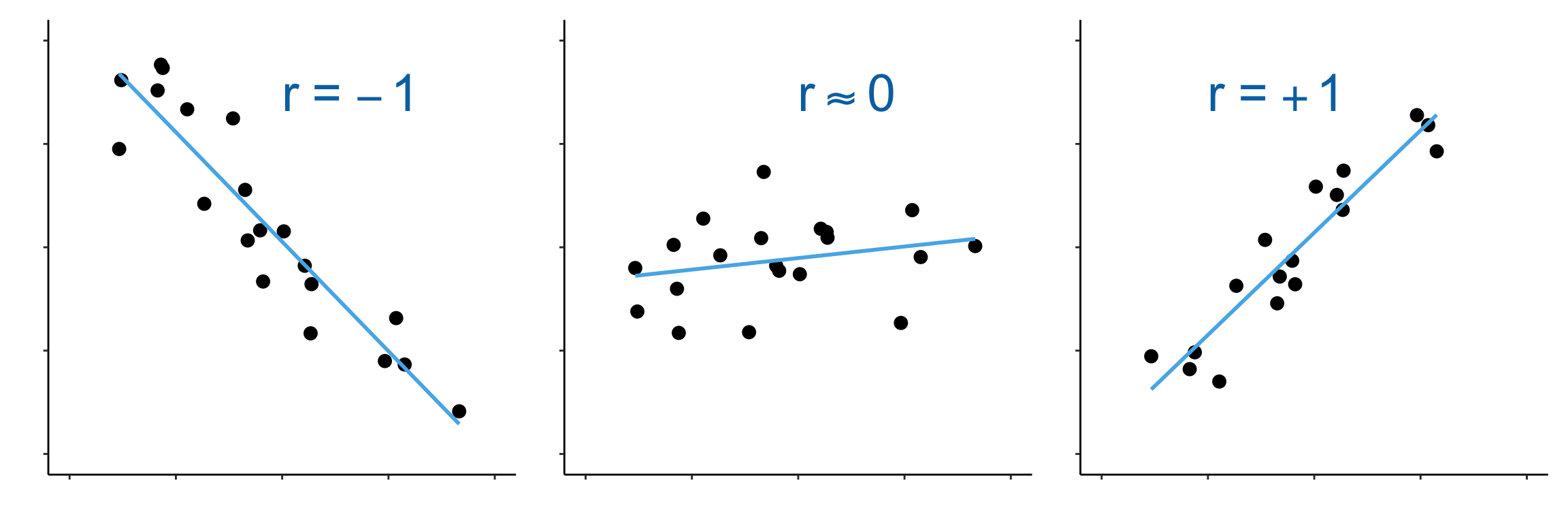
Was macht nun die Korrelation? Die Korrelation gibt die Richtung der Geraden an. Oder noch konkreter die Steigung der Geraden normiert auf -1 bis 1. Die Abbildung 48.3 zeigt die Visualisierung der Korrelation für drei Ausprägungen. Eine Korrelation von \(r = -1\) bedeutet eine maximale negative Korrelation. Die Gerade fällt in einem 45° Winkel. Eine Korrelation von \(r = +1\) bedeutet eine maximale positive Korrelation. Die gerade steigt in einem 45° Winkel. Eine Korrelation von \(r = 0\) bedeutet, dass keine Korrelation vorliegt. Die Grade verläuft parallel zur \(x\)-Achse.
Im Folgenden sehen wir die Formel für den Korrelationskoeffizient nach Pearson. Es gibt natürlich auch noch andere Korrelationskoeffizienten aber hier geht es dann einmal darum das Prinzip zu verstehen und das können wir am Korrelationskoeffizient nach Pearson am einfachsten. Wichtig hierbei, die beiden Variablen, die wir korrelieren wollen, müssen bei dem Korrelationskoeffizienten nach Pearson normalverteilt sein.
\[ \rho = r_{x,y} = \cfrac{s^2_{x,y}}{s_x \cdot s_y} \]
Wir berechnen die Korrelation immer zwischen zwei Variablen \(x\) und \(y\). Es gibt keine multiple Korrelation über mehr als zwei Variablen. Im Zähler der Formel zur Korrelation steht die Kovarianz von \(x\) und \(y\).
Wir können mit folgender Formel die Kovarianzen zwischen den beiden Variablen \(x\) und \(y\) berechnen.
\[ s^2_{x,y} = \sum_{i=1}^n(x_i-\bar{x})(y_i-\bar{y}) \]
Die folgende Formel berechnet die quadrierten Abweichung der Beobachtungen von \(x\) zum Mittelwert \(\bar{x}\).
\[ s_x = \sqrt{\sum_{i=1}^n(x_i-\bar{x})^2} \]
Die folgende Formel berechnet die quadrierten Abweichung der Beobachtungen von \(y\) zum Mittelwert \(\bar{y}\).
\[ s_y = \sqrt{\sum_{i=1}^n(y_i-\bar{y})^2} \]
In Tabelle 48.4 ist der Zusammenhang nochmal Schritt für Schritt aufgeschlüsselt. Wir berechnen erst die Abweichungsquadrate von \(x\) und die Abweichungsquadrate von \(y\). Dann noch die Quadrate der Abstände von \(x\) zu \(y\). Abschließend summieren wir alles und ziehen noch die Wurzel für die Abweichungsquadrate von \(x\) und \(y\).
| jump_length \(\boldsymbol{y}\) | weight \(\boldsymbol{x}\) | \(\boldsymbol{(y_i-\bar{y})^2}\) | \(\boldsymbol{(x_i-\bar{x})^2}\) | \(\boldsymbol{(x_i-\bar{x})(y_i-\bar{y})}\) |
|---|---|---|---|---|
| 1.2 | 0.8 | 0.45 | 0.94 | 0.65 |
| 1.8 | 1.0 | 0.01 | 0.60 | 0.06 |
| 1.3 | 1.2 | 0.33 | 0.33 | 0.33 |
| 1.7 | 1.9 | 0.03 | 0.02 | -0.02 |
| 2.6 | 2.0 | 0.53 | 0.05 | 0.17 |
| 1.8 | 2.7 | 0.03 | 0.86 | -0.07 |
| 2.7 | 2.8 | 0.69 | 1.06 | 0.85 |
| \(\sum\) | 2.05 | 3.86 | 1.97 | |
| \(\sqrt{\sum}\) | 1.43 | 1.96 |
Wir können die Zahlen dann aus der Tabelle in die Formel der Korrelation nach Pearson einsetzen. Wir erhalten eine Korrelation von 0.70 und haben damit eine recht starke positve Korrelation vorliegen.
\[ \rho = r_{x,y} = \cfrac{1.97}{1.96 \cdot 1.43} = 0.70 \]
Wir können mit der Funktion cor() in R die Korrelation zwischen zwei Spalten in einem Datensatz berechnen. Wir überprüfen kurz unsere Berechnung und stellen fest, dass wir richtig gerechnet haben.
cor(simple_tbl$jump_length, simple_tbl$weight)[1] 0.7014985Wenn du dich noch an das Eingangszitat erinnerst, dann wirst du dich Fragen, aber wie modellieren wir den jetzt die Korrelation zwischen zwei Variablen \(x\) und \(y\), wenn es noch eine andere versteckte Variable \(z\) gibt, die eigentlich die Korrelation ausmacht. Wir haben ja die Korrelation zwischen Eisverkauf und Waldbränden. Aber die beiden Variablen korrelieren gar nicht miteinander sondern werden sozusagen über die Korrelation von Eis zu Sommer und Sommer zu Waldbränden miteinander verknüpft. Wir haben es hier mit einer partielle Korrelationen (eng. partial correlation) zu tun. Dazu dann mehr in dem folgenden Kasten, da die partielle Korrelationen schon etwas spezieller ist. In R können wir die partielle Korrelationen dann im R Paket {correlation} einfach berechnen und visualisieren.
Was ist die partielle Korrelationen? Partielle Korrelationen \(r_{xy, z}\) beschreiben die Korrelation zwischen zwei Variablen \(x\) und \(y\), wenn für alle Variablen im Datensatz, im einfachtsen Fall für eien weitere Variable \(z\), kontrolliert wird. Ein wesentlicher Vorteil der partiellen Korrelationen besteht nun darin, dass unerwünschte Korrelationen vermieden werden. Wir können uns die Sachlage einmal schematisch in der Abbildung 48.4 anschauen. Wir haben dort die schematische Darstellung der partielle Korrelationen \(r_{xy, z}\) zwischen den Variablen \(x\) und \(y\), die durch die Korrelation zwischen \(x\) und \(z\) sowie \(y\) und \(z\) beeinflusst wird. Wie stark der Effekt von \(z\) ist, hängt vom konkreten Beispiel ab. Die Variable \(z\) kann im extremsten Fall die gesamte Korrelation zwischen \(x\) und \(y\) erklären. In Wirklichkeit liegt dann gar kein Korrelation zwischen \(x\) und \(y\) vor obwohl wir eine Messen. Wir haben eine Scheinkorrelation vorliegen.
flowchart LR
A("x"):::factor <-. r<sub>xz</sub> ..-> B("z"):::confound;
A("x"):::factor <-- r<sub>xy</sub> --> C("y"):::factor;
B("z"):::confound <-. r<sub>yz</sub> ..-> C("y"):::factor;
classDef factor fill:#56B4E9,stroke:#333,stroke-width:0.75px
classDef confound fill:#CC79A7,stroke:#333,stroke-width:0.75px
Wie berechnen wir die partielle Korrelation? Wir nutzen dafür folgende einfache Formel. Es gibt noch andere Formeln, die besonders bei mehr als drei Variablen bessere Ergebnisse erzielen. Für usn soll diese einfache Formel ausreichen.
\[ r_{xy, z} = \cfrac{r_{xy} - r_{xz} \cdot r_{yz}}{\sqrt{(1-r^2_{xz}) \cdot (1-r^2_{yz})}} \]
mit
Schauen wir uns die Formel einmal in Aktion an dem Beispiel von Matthews (2000) in der Arbeit Storks Deliver Babies (p = 0.008) an. In der Arbeit fanden wir eine Korrelation \(r_{xy}\) von \(0.62\) zwischen \(x\) gleich Anzahl der brütenden Störche und \(y\) gleich der Anzahl an Babies in den entsprechenden untersuchten Gebieten. Im Folgenden ein Zitat vom Autor, der korrekterweise anmerkt, dass hier etwas vermutlich nicht stimmig ist.
The most plausible explanation of the observed correlation is, of course, the existence of a confounding variable: some factor common to both birth rates and the number of breeding pairs of storks which […] can lead to a statistical correlation between two variables which are not directly linked themselves. One candidate for a potential confounding variable is land area […] — Matthews (2000)
Dafür müssen wir jetzt einmal die Korrelation zwischen allen Variablen in dem Storchendatensatz berechnen. Ich habe jetzt mal nur die drei Variablen von Interesse ausgewählt, damit wir hier nicht so lange Tabellen erhalten. Dann können wir schauen, ob wir eine partielle Korrelation in den Daten vorliegen haben.
stork_tbl |>
select(area_km2, storks_pairs, birth_rate) |>
correlation()# Correlation Matrix (pearson-method)
Parameter1 | Parameter2 | r | 95% CI | t(15) | p
---------------------------------------------------------------------
area_km2 | storks_pairs | 0.58 | [0.14, 0.83] | 2.75 | 0.016*
area_km2 | birth_rate | 0.92 | [0.79, 0.97] | 9.26 | < .001***
storks_pairs | birth_rate | 0.62 | [0.20, 0.85] | 3.06 | 0.016*
p-value adjustment method: Holm (1979)
Observations: 17Dann bauen wir uns den Sachverhalt einmal in der Abbildung Abbildung 48.5 nach. Wir können dort immer die direkten paarweisen Korrelationen eintragen. Wenn wir das gemacht haben, können wir einmal die partielle Korrelation \(r_{xy, z}\) berechnen. Wie ändert sich also die paarweise Korrelation zwischen \(x\) und \(y\), wenn wir die paarweisen Korrelationen zu \(z\) bereücksichtigen?
flowchart LR
A("stork_pairs"):::factor <-. "0.58" ..-> B("birth_rate"):::confound;
A("stork_pairs"):::factor <-- "0.62" --> C("area_km2"):::factor;
B("area_km2"):::confound <-. "0.81" ..-> C("birth_rate"):::factor;
classDef factor fill:#56B4E9,stroke:#333,stroke-width:0.75px
classDef confound fill:#CC79A7,stroke:#333,stroke-width:0.75px
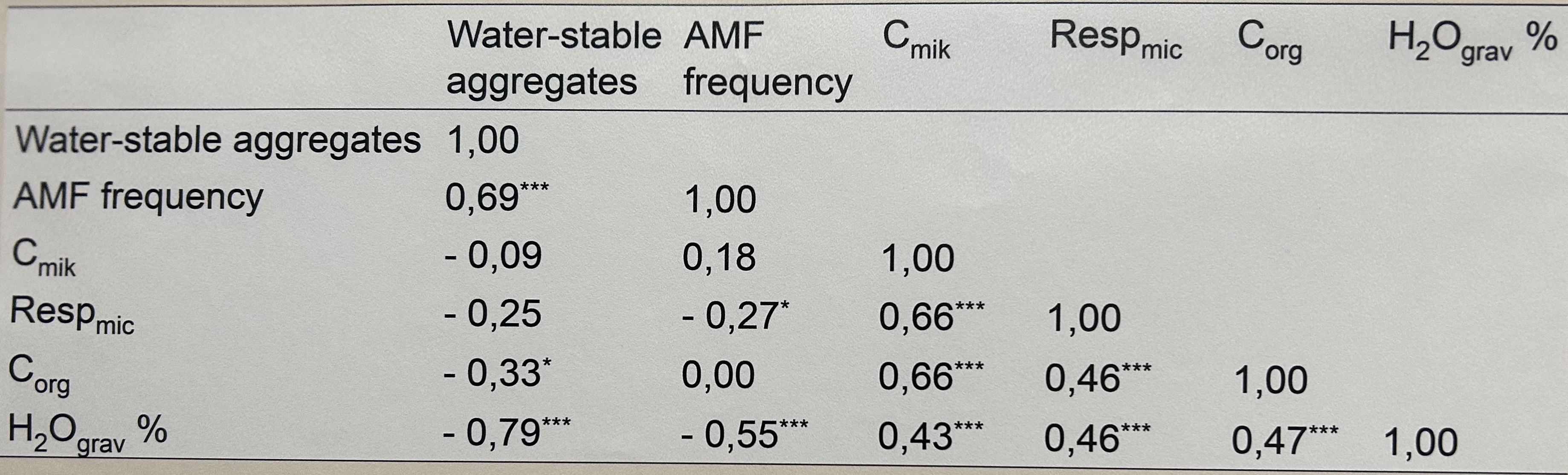
stork_pairs und birth_rate sowie zu der Variable area_km2.
Wir können dann alles einmal in die Formel für die partielle Korrelation einsetzen.
\[ r_{xy, z} = \cfrac{0.62 - 0.58 \cdot 0.92}{\sqrt{(1-0.58^2) \cdot (1-0.92^2)}} = \cfrac{0.15}{0.48} = 0.27 \]
Damit erhalten wir eine partielle Korrelation von nur \(0.27\) anstatt einer direkten Korrelation von \(0.62\). Wie du siehst, haben wir hier einen Effekt von der Landfläche auf beide Variablen der Geburtsrate sowie der Storchenanzahl. Wenn wir die Landfläche nicht berücksichtigen könnte man meinen wir hätten da einen Effekt von Störchen auf die Geburtsrate. Du kannst einfach in der Funktion correlation() einstellen, dass du die partiellen Korrelationen berechnet haben willst. Wie du siehst kommt die gleiche Zahl raus. Auch sehen wir, dass der Zusammenhang zwischen Landfläche und Geburtenrate signifikant ist und eine sehr hohe Korrelation von \(0.88\) hat.
stork_tbl |>
select(area_km2, storks_pairs, birth_rate) |>
correlation(partial = TRUE, p_adjust = "none")# Correlation Matrix (pearson-method)
Parameter1 | Parameter2 | r | 95% CI | t(15) | p
----------------------------------------------------------------------
area_km2 | storks_pairs | 0.02 | [-0.46, 0.50] | 0.09 | 0.929
area_km2 | birth_rate | 0.88 | [ 0.69, 0.96] | 7.21 | < .001***
storks_pairs | birth_rate | 0.27 | [-0.24, 0.67] | 1.10 | 0.289
p-value adjustment method: none
Observations: 17In R haben wir dann die Möglichkeit die Korrelation mit der Standardfunktion cor() ganz klassisch zu bestimmen oder aber auch das R Paket {correlation} zu nutzen. Das R Paket kann dabei vollumfänglich auf das {tidyverse} zugreifen und ist von mir bevorzugt. Wenn es schnell gehen muss oder ich mir nur aml als Demonstration eine Korrelation berechnen will, dann ist die klassiche Variante in R gut, aber für größere Datensätze nutze ich nur noch das R Paket {correaltion} und deren tollen Funktionen.
Wir nutzen die Korrelation in R selten nur für zwei Variablen. Meistens schauen wir uns alle numerischen Variablen gemeinsam in einer Abbildung an. Wir nennen diese Abbildung auch Korrelationsplot. Faktoren sind keine numerischen Variablen. Daher kann es sein, dass für dein Experiment kein Korrelationsplot in Frage kommt. Wir schauen uns jetzt nochmal einen die Berechnung für den Datensatz simple_tbl an. Wir müssen für die Korrelation zwischen zwei Variablen diese Variablen mit dem $-Zeichen aus dem Datensatz extrahieren. Die Funktion cor() kann nur mit Vektoren oder ganzen numerischen Datensätzen arbeiten.
Wir können den Korrelationskoeffizienten nach Pearson mit der Option method = "pearson" auswählen, wenn wir normalverteilte Daten vorliegen haben. Das heißt, dass alle unsere Spalten, mit denen wir die paarweisen Korrelationen berechnen wollen, einer Normalverteilung folgen müssen.
cor(simple_tbl$jump_length, simple_tbl$weight, method = "pearson")[1] 0.7014985Je mehr Variablen du dann hast, desto unwahrscheinlicher wird es natürlich, dass alle einer Normalverteilung folgen. Dann können wir die nicht-parametrische Variante des Korrelationskoeffizienten nach Spearman berechnen. Wir nutzen dazu die Option method = "spearman".
cor(simple_tbl$jump_length, simple_tbl$weight, method = "spearman")[1] 0.792825Bei stetigen Daten wird dann meist statt des Korrelationskoeffizienten nach Spearman gerne der nach Kendall berechnet. Aber das sind dann schon die Feinheiten. Wir nutzen dazu die Option method = "kendall".
cor(simple_tbl$jump_length, simple_tbl$weight, method = "kendall")[1] 0.6831301Wir können auch einen statistischen Test für die Korrelation rechnen. Die Nullhypothese \(H_0\) wäre hierbei, dass die Korrelation \(r = 0\) ist. Die Funktion cor.test() liefert den entsprechenden \(p\)-Wert für die Entscheidung gegen die Nullhypothese.
cor.test(simple_tbl$jump_length, simple_tbl$weight, method = "pearson")
Pearson's product-moment correlation
data: simple_tbl$jump_length and simple_tbl$weight
t = 2.201, df = 5, p-value = 0.07899
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.1092988 0.9517673
sample estimates:
cor
0.7014985 Aus dem Test erhalten wir den \(p\)-Wert von \(0.079\). Damit liegt der \(p\)-Wert über den Signifikanzniveau von \(\alpha\) gleich 5%. Wir können somit die Nullhypothese nicht ablehnen. Wir sehen hier, die Problematik der kleinen Fallzahl. Obwohl unsere Korrelation mit \(0.7\) groß ist erhalten wir einen \(p\)-Wert, der nicht die Grenze von 5% unterschreitet. Wir sehen, dass die starre Grenze von \(\alpha\) auch Probleme bereitet.
{correlation}Das R Paket {correlation} erlaubt es, die Korrelation in R zu berechnen und hilft wirklich bei der Anwendung. Die ursprünglichen Funktion in R passen überhaupt nicht zum {tidyverse} und so ist es gut, dass wir hier eine andere Möglichkeit haben, die auch noch viel mehr kann als die klassischen Funktion in R. Die zentrale Funktion ist dabei die Funktion correlation(). Wir können eine Vielzahl an Korrelationskoeffizienten auswählen. Wenn du keine Methode über die Option method = eingibst, dann wird der Korrelationskoeffizient nach Pearson unter der Annahme von normalverteilten Daten gerechnet. Die kannst es dir auch einfacher machen und die Funktion über die Option method = "auto" selber wählen lassen. Ich bevorzuge aber den Korrelationskoeffizient nach Spearman, wenn ich sehr viele Variablen miteinander vergleichen möchte. Im Normalfall werden die \(p\)-Werte adjustiert, dass stelle ich hier aber einmal ab. Sonst nutze gerne die Option p_adjust = "bonferroni", wenn du für sehr viele Vergleiche adjustieren willst.
Wenn du nun die Funktion aufrufst, dann erhälst du alle paarweisen Korrelationen in deinem Datensatz über alle Variablen. Daher baue ich mir immer erstmal über select() einen Datensatz zusammen, den ich dann analysieren will. Sonst hast du da Spalten in deiner Auswertung, die dich gar nicht interessieren. Die Spalte rho gibt dir dann den Korrelationskoeffizient wieder. Dann erhälst du noch die 95% Konfidenzintervalle sowie den \(p\)-Wert für den Korrelationskoeffizient. Hier testen wir, ob der Korrelationskoeffizient unterschiedlich von der Null ist.
cor_stork_res <- stork_tbl |>
correlation(method = "spearman", p_adjust = "none")
cor_stork_res# Correlation Matrix (spearman-method)
Parameter1 | Parameter2 | rho | 95% CI | S | p
-----------------------------------------------------------------------------
area_km2 | storks_pairs | 0.63 | [ 0.21, 0.86] | 298.73 | 0.006**
area_km2 | humans_millions | 0.84 | [ 0.60, 0.94] | 127.16 | < .001***
area_km2 | birth_rate | 0.83 | [ 0.57, 0.94] | 138.00 | < .001***
storks_pairs | humans_millions | 0.33 | [-0.19, 0.71] | 544.00 | 0.191
storks_pairs | birth_rate | 0.42 | [-0.09, 0.75] | 475.16 | 0.095
humans_millions | birth_rate | 0.96 | [ 0.88, 0.98] | 36.04 | < .001***
p-value adjustment method: none
Observations: 17Wir haben jetzt einige signifikante Korrelationskoeffizienten. Jetzt ist es wichtig, dass wir nicht nur auf die Signifikanz schauen, sondern auch fragen, ist der Korrelationskoeffizient relevant? Das heißt, ist der Korrelationskoeffizient weit genug weg von der Null um für uns auch eine Aussagekraft zu haben. Hier können wir uns für die bessere Übersicht auch einmal die Korrelationsmatrix wiedergeben lassen.
cor_stork_res |>
summary(redundant = TRUE)# Correlation Matrix (spearman-method)
Parameter | area_km2 | storks_pairs | humans_millions | birth_rate
------------------------------------------------------------------------
area_km2 | | 0.63** | 0.84*** | 0.83***
storks_pairs | 0.63** | | 0.33 | 0.42
humans_millions | 0.84*** | 0.33 | | 0.96***
birth_rate | 0.83*** | 0.42 | 0.96*** |
p-value adjustment method: noneDas sieht dann schon relevant aus. Viele der signifikanten Korrelationskoeffizienten sind irgendwie bei knapp \(0.8\) was dann auch signifikant unterschiedlich von Null ist und auch eine sehr große Korrelation beschreibt. Ich würde hier schon von einem Zusammenhang ausgehen. In der Abbildung 48.6 siehst du dann die Matrix nochmal visualisiert. Die Farben entsprechen dann der Richtung der Korrelation. Je kräftiger der Farbton, desto größer ist die Korrelation.
cor_stork_res |>
summary(redundant = TRUE) |>
plot()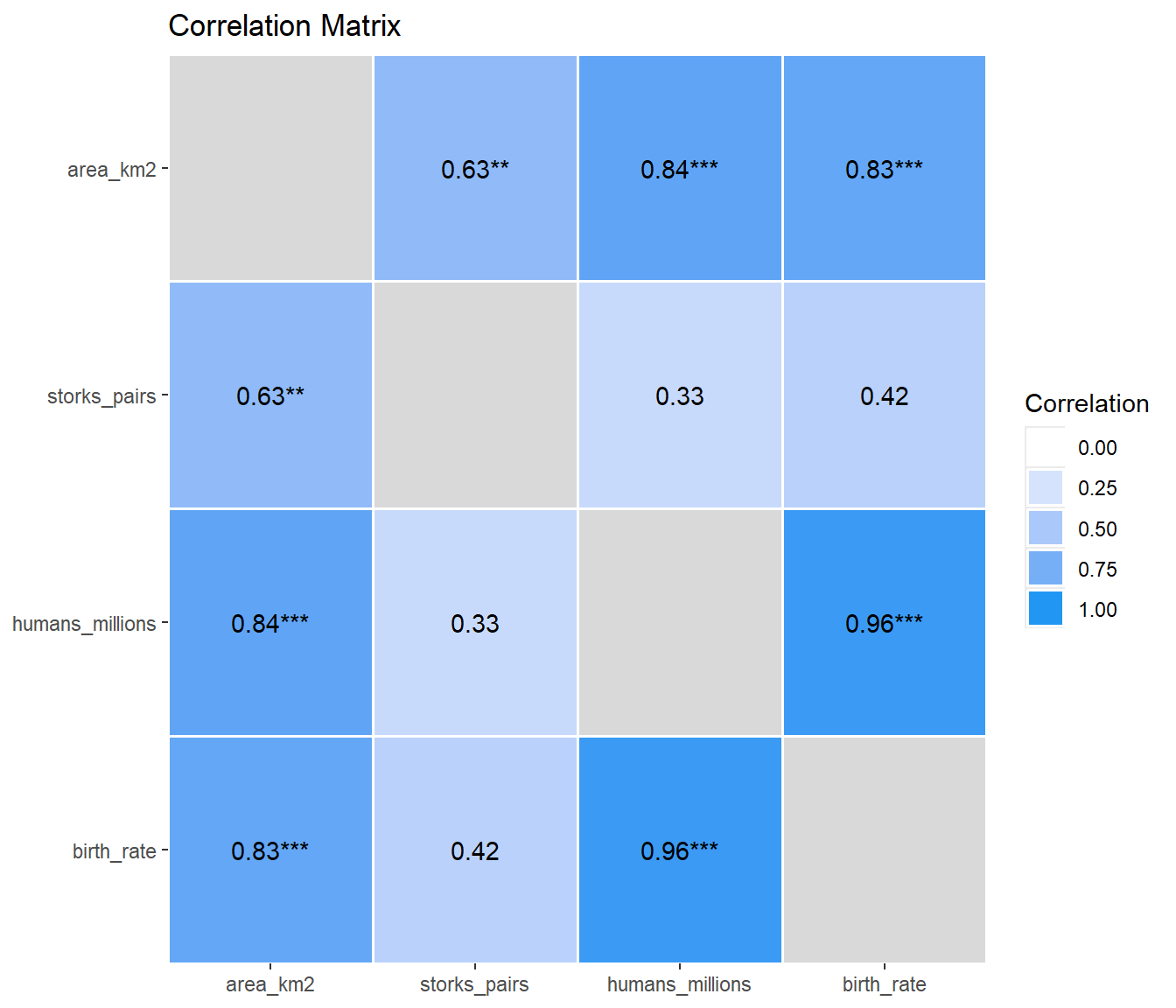
Eine angenehme Funktion in dem R Paket {correlation} ist die Funktion cor_test(). Wir haben hier zum einen die Möglichkeit direkt Spaltennamen in die Funktion zu pipen. Auf der anderen Seite können wir die Funktion auch gleich in der Funktion plot() visualisieren. Das ist super praktisch, wenn du dir die Daten einmal anschauen willst und sehen willst, ob der Korrelationskoeffizient gepasst hat. Ich nutze die Funktion gerne in meiner Arbeit als schnelle Visualisierung einer Korrelation in einem Scatterplot. Sonst sind es schon ein paar mehr Zeilen Code mit {ggplot}.
Wir sehen dann in der Abbildung 48.7 einmal den Zusammenhang. Die Korrelation beschreibt ja die einheistlose Steigung. Die Korrelation \(r\) mit \(0.62\) ist signifikant mit einem \(p\)-Wert von \(0.008\) welcher ja unter dem Signifikanzniveau liegt. Einzig die beiden Beobachtungen rechts mit knapp 30000 sowie 25000 Storchenpaaren ziehen die Gerade sehr nach oben. Hier müsste man sich nochmal eine partielle Korrelation anschauen um zu sehen, ob es hier nicht noch andere Effekt einer anderen Variable in den Daten gibt.
stork_tbl |>
cor_test("storks_pairs", "birth_rate") |>
plot() +
theme_minimal()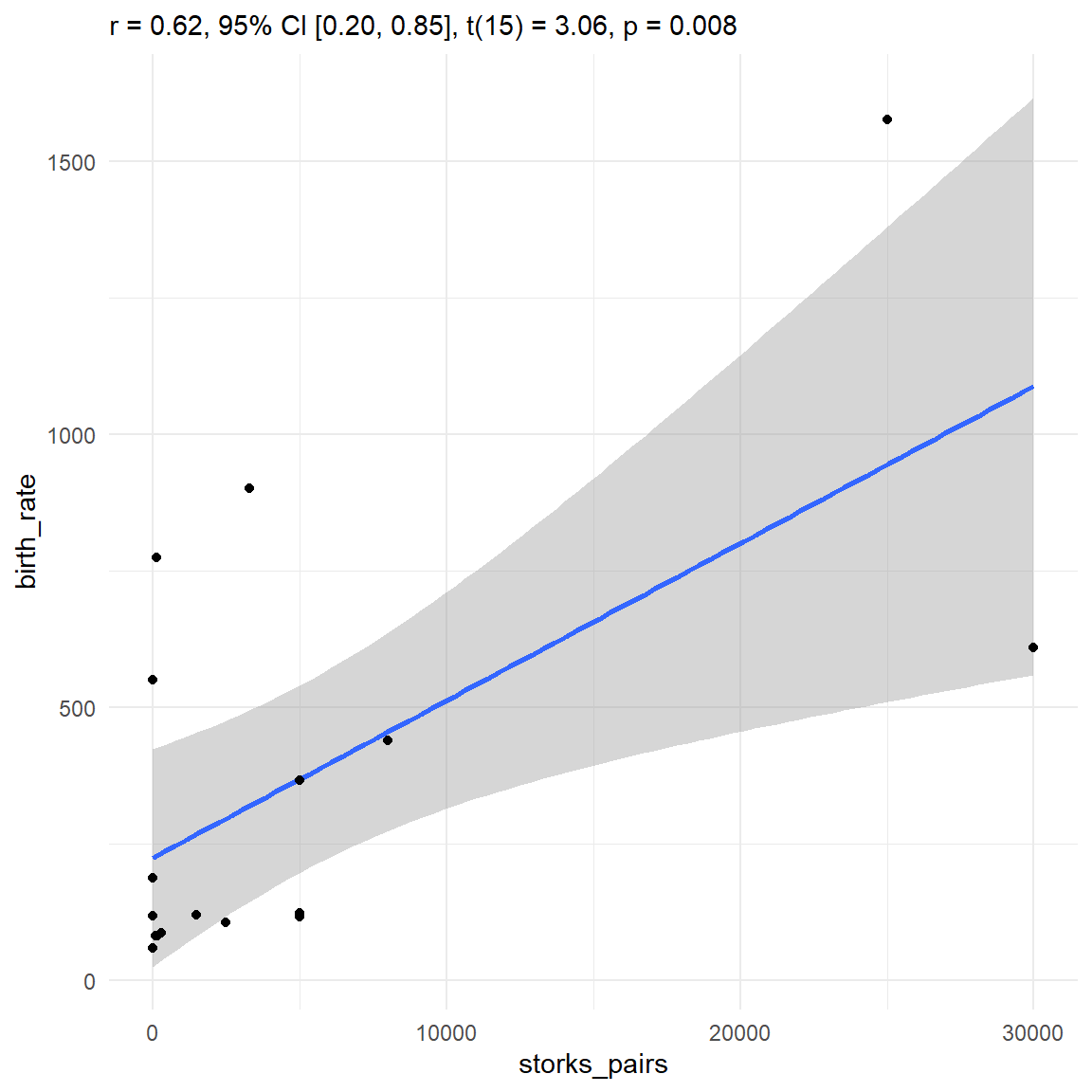
storks_pairs und der Geburtenrate birth_rate. Wie man gut sieht, wird die gerade von nur ein paar Punkten getrieben. Hier müsste nochmal geschaut werden, ob nicht eine partielle Korrelation mehr Aussagekraft hätte.
Als letztes erlaubt das R Paket noch die Darstellung der Daten in einem gaußsches grafisches Modell (eng. Gaussian Graphical Model). Wir visualisieren uns damit die partielle Korrelationen (eng. partial correlation). Ein gaußsches grafisches Modell besteht dabei aus einer Reihe von Variablen, die durch Kreise dargestellt werden, und einer Reihe von Linien, die die Beziehungen zwischen den Variablen visualisieren. Die Dicke dieser Linien stellt die Stärke der Beziehungen zwischen den Variablen dar. Daher kannst du davon ausgehen, dass ein Fehlen einer Linie keine oder nur sehr schwache Beziehungen zwischen den relevanten Variablen darstellt. Insbesondere erfassen diese Linien im Gaußschen Grafikmodell partielle Korrelationen. Partielle Korrelationen beschreiben die Korrelation zwischen zwei Variablen, wenn für alle Variablen im Datensatz kontrolliert wird. Ein wesentlicher Vorteil der partiellen Korrelationen besteht nun darin, dass unerwünschte Korrelationen vermieden werden. Mehr zu dem Thema findest du auch bei Bhushan et al. (2019) in deren Arbeit Using a Gaussian Graphical Model to Explore Relationships Between Items and Variables in Environmental Psychology Research.
Im Folgenden nutzen wir einmal die Funktion correlation() mit der Option partial = TRUE. Zuerst haben wir dann nur noch die Anzahl an Beobachtungen in den Daten für die wir auch überall einen Wert haben. Sonst hätten wir ja noch die Möglichkeit, dass bei einzelnen Variablenpaaren mehr Beobachtungen übrig bleiben. Dann können wir auch schon unsere partielle Korrelation einmal in der Abbildung 48.8 abbilden. Wir setzen dann noch andere Farben mit der Funktion scale_edge_color_continuous() für wenig partielle Korrelation zu viel Korrelation. Wir sehen auch hier ganz klar, dass wir eine partielle Korrelation zwischen der Landfläche und der Geburtenrate haben und weniger zwischen den Storchpaaren und der Geburtenrate. Für solche Darstellungen und Untersuchungen sind die graphischen Modelle super.
stork_tbl |>
correlation(partial = TRUE) |>
plot() +
scale_edge_color_continuous(low = "#000004FF", high = "#FCFDBFFF")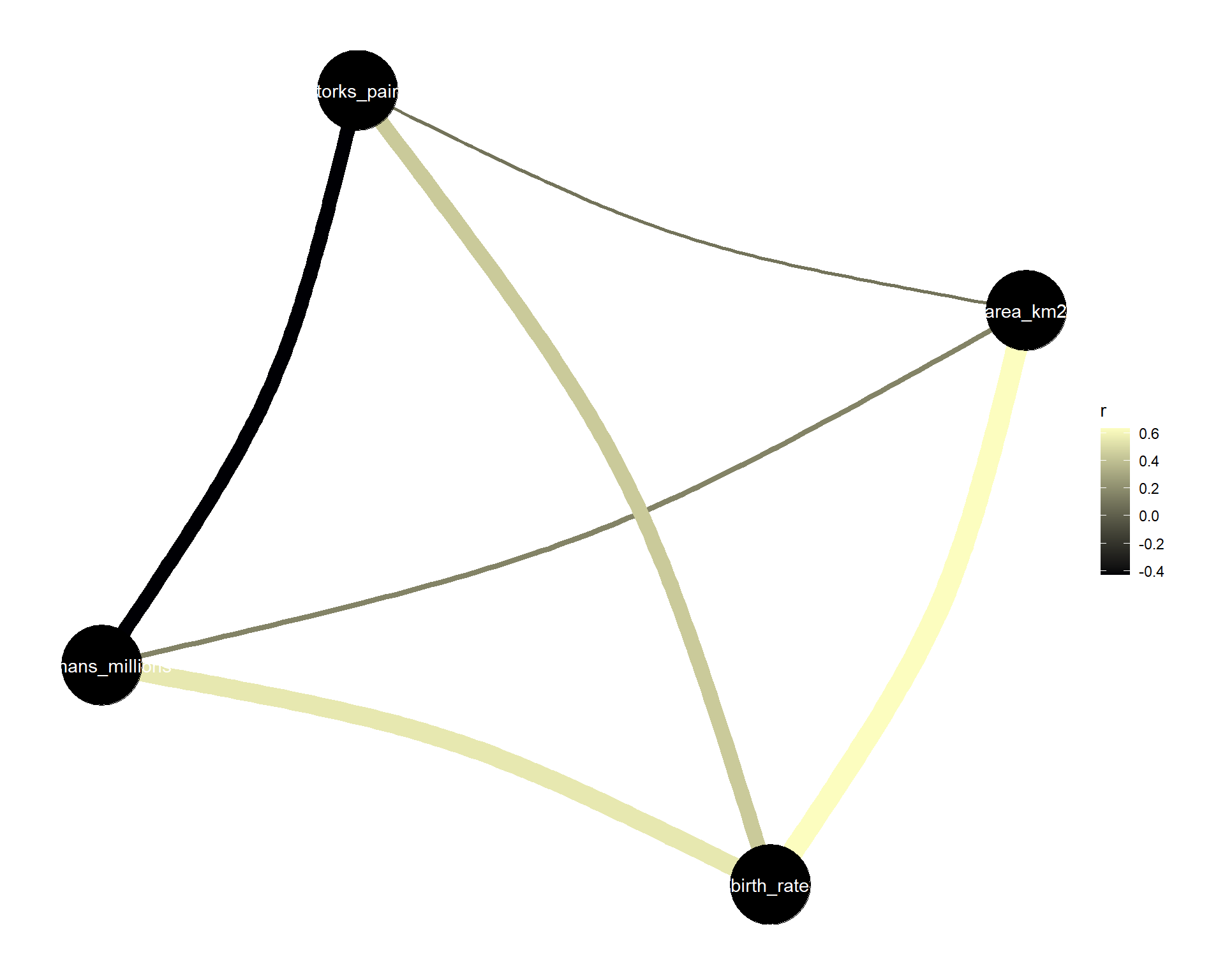
Abschließend wollen wir uns noch die Funktion corrplot() aus dem gleichnamigen R Paket {corrplot} anschauen. Die Hilfeseite zum Paket ist sehr ausführlich und bietet noch eine Reihe an anderen Optionen. Wir benötigen dafür einen etwas größeren Datensatz mit mehreren numerischen Variablen. Wir nutzen daher den Gummibärchendatensatz und selektieren die Spalten count_bears bis semester aus. Wir brauchen für die Funktion corrplot() eine Matrix mit den paarweisen Korrelationen. Wir können diese Matrix wiederum mit der Funktion cor() erstellen. Wir müssen dazu aber erstmal alle numerischen Variablen mit select_if() selektieren und dann alle fehlenden Werte über na.omit() entfernen.
cor_mat <- corr_gummi_tbl |>
select_if(is.numeric) |>
na.omit() |>
cor()
cor_mat |> round(3) count_bears count_color most_liked age height semester
count_bears 1.000 0.324 0.091 0.199 0.007 0.121
count_color 0.324 1.000 0.011 0.011 -0.011 -0.012
most_liked 0.091 0.011 1.000 -0.017 -0.102 0.074
age 0.199 0.011 -0.017 1.000 0.001 0.124
height 0.007 -0.011 -0.102 0.001 1.000 -0.071
semester 0.121 -0.012 0.074 0.124 -0.071 1.000Wir sehen das in der Korrelationsmatrix jeweils über und unterhalb der Diagonalen die gespiegelten Zahlen stehen. Wir können jetzt die Matrix cor_mat in die Funktion corrplot() stecken und uns den Korrelationsplot in Abbildung 48.9 einmal anschauen.
corrplot(cor_mat)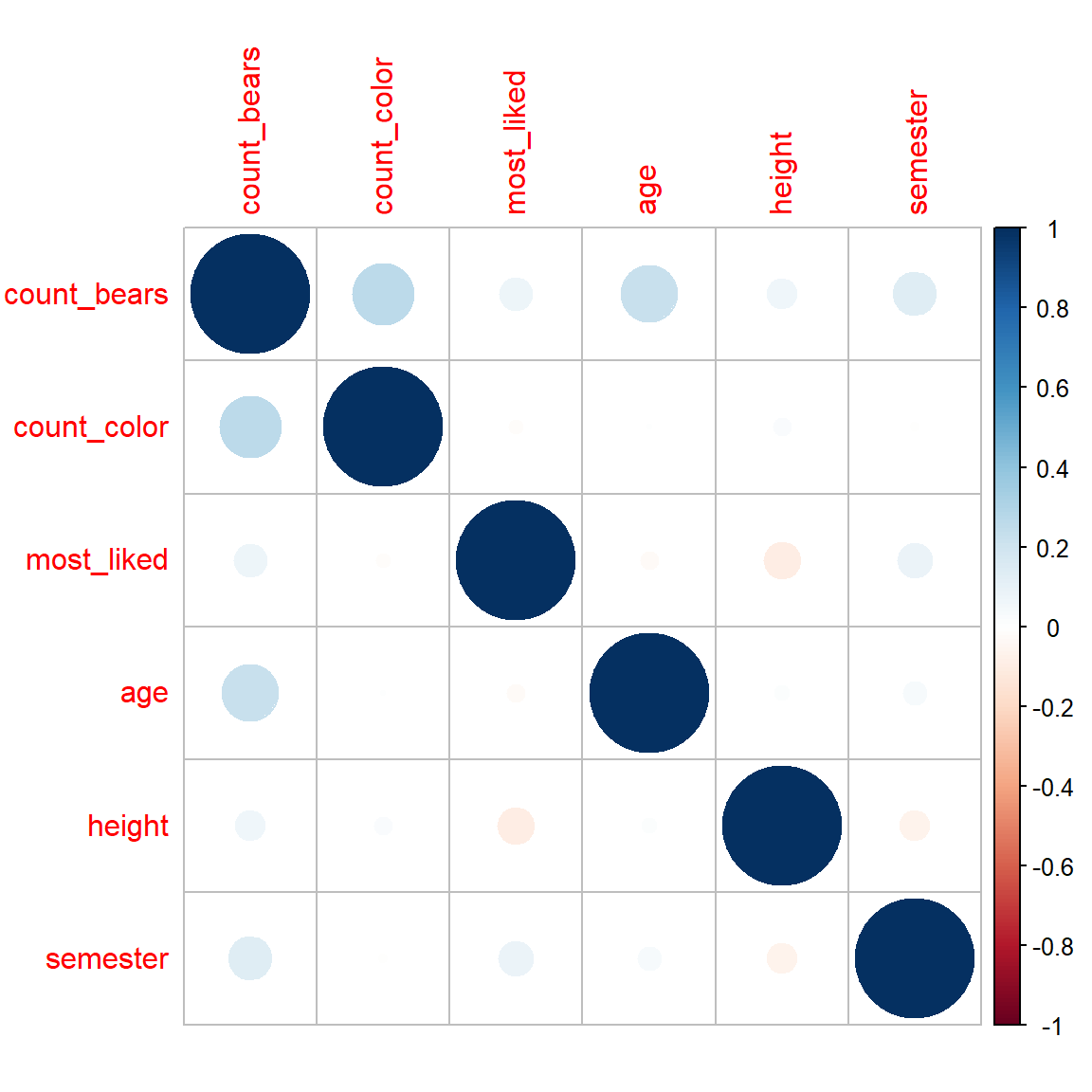
Wir sehen in Abbildung 48.9, dass wir eine schwache positive Korrelation zwischen count_color und count_bears haben, angezeigt durch den schwach blauen Kreis. Der Rest der Korrelation ist nahe Null, tendiert aber eher ins negative. Nun ist in dem Plot natürlich eine der beiden Seiten überflüssig. Wir können daher die Funktion corrplot.mixed() nutzen um in das untere Feld die Zahlenwerte der Korrelation darzustellen.
corrplot.mixed(cor_mat)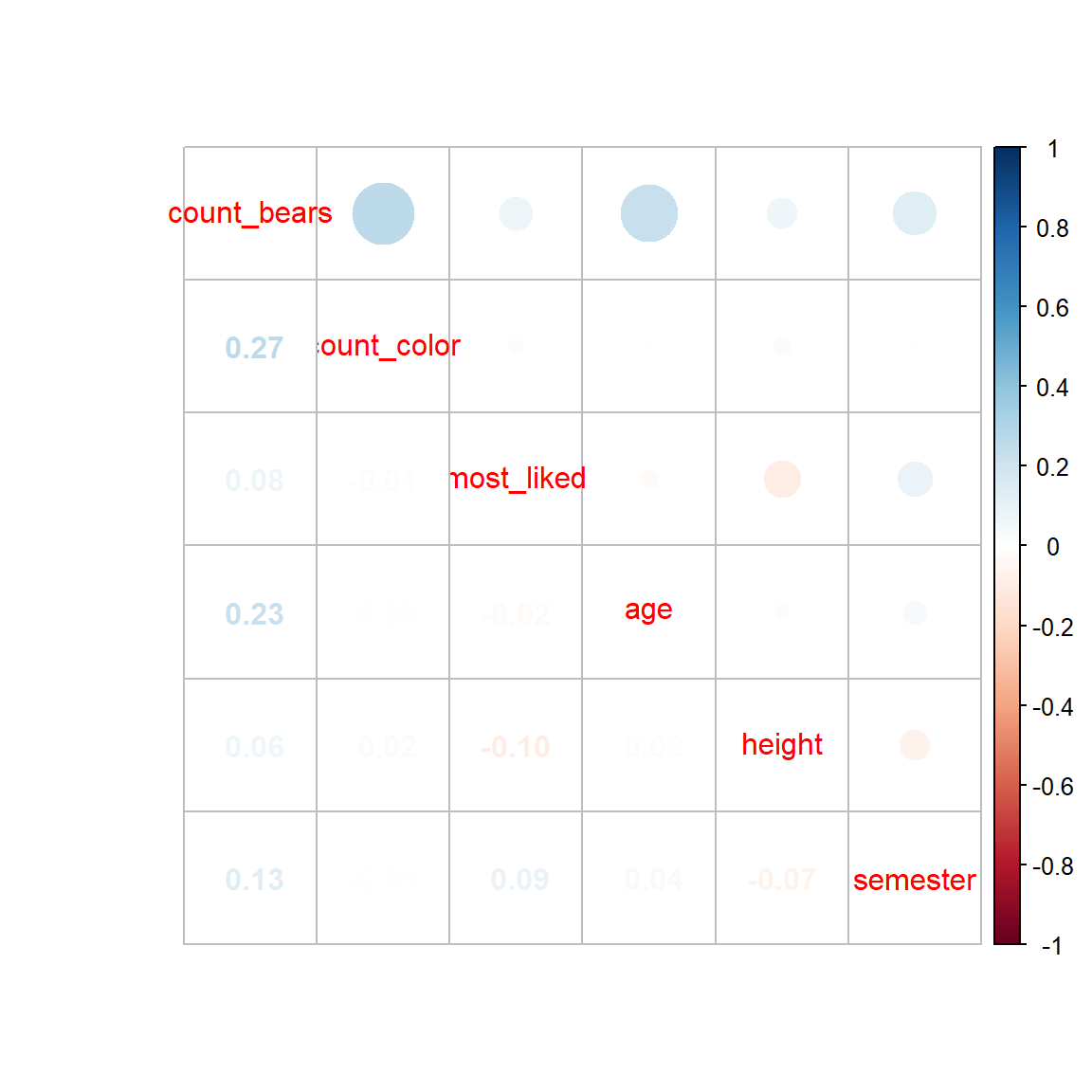
Es gibt noch eine Vielzahl an weiteren Möglichkeiten in den Optionen von der Funktion corr.mixed(). Hier hilft dann die Hilfeseite der Funktion oder aber die Hilfeseite zum Paket. Eine weitere Möglichkeit kontinuierliche Daten darzustellen ist das R Paket {GGally} mit der Funktion ggpairs(). Hier können wir die paarweisen Zusammenhänge von Variablen, also den Spalten, darstellen. Prinzipiell geht es auch mit kategorialen Variablen, aber wir konzentrieren uns hier nur auf die numerischen. Im Folgenden wählen wir also nur die numerischen Spalten in unseren Gummibärchendaten einmal aus und nutzen die selektierten Daten dann einmal in der Funktion ggpairs().
corr_gummi_tbl <- corr_gummi_tbl |>
select_if(is.numeric)Der ggpairs-Plot baut sich als eine Matrix auf, in der jede Variable mit jeder anderen Variable verglichen wird. Damit ergibt sich auf der Diagonalen ein Selbstvergleich und die obere Hälfte und untere Hälfte der Matrix beinhalten die gleichen Informationen. Hier setzt dann ggpairs() an und erlaubt in jede der drei Bereiche, obere Hälfte (upper), der Diagonalen (diag) sowie der unteren Hälfte (lower), eigene Abbildungen oder Maßzahlen für die Vergleiche der Variablen zu verwenden. In der Abbildung 48.11 siehst du die Standardausgabe der Funktion ggpairs() auf einen Datensatz. Auf der unteren Hälfte ist der Scatterplot mit den einzelnen Beobachtungen, in der Diagonalen die Dichte der Variablen sowie im oberen Bereich die Korrelation zwischen den Variablen angegeben. Die Korrelation wurde auch noch einen statistischen Test unterworfen, so dass wir hier auch Sternchen für die Signifikanz bekommen.
ggpairs(corr_gummi_tbl) +
theme_minimal()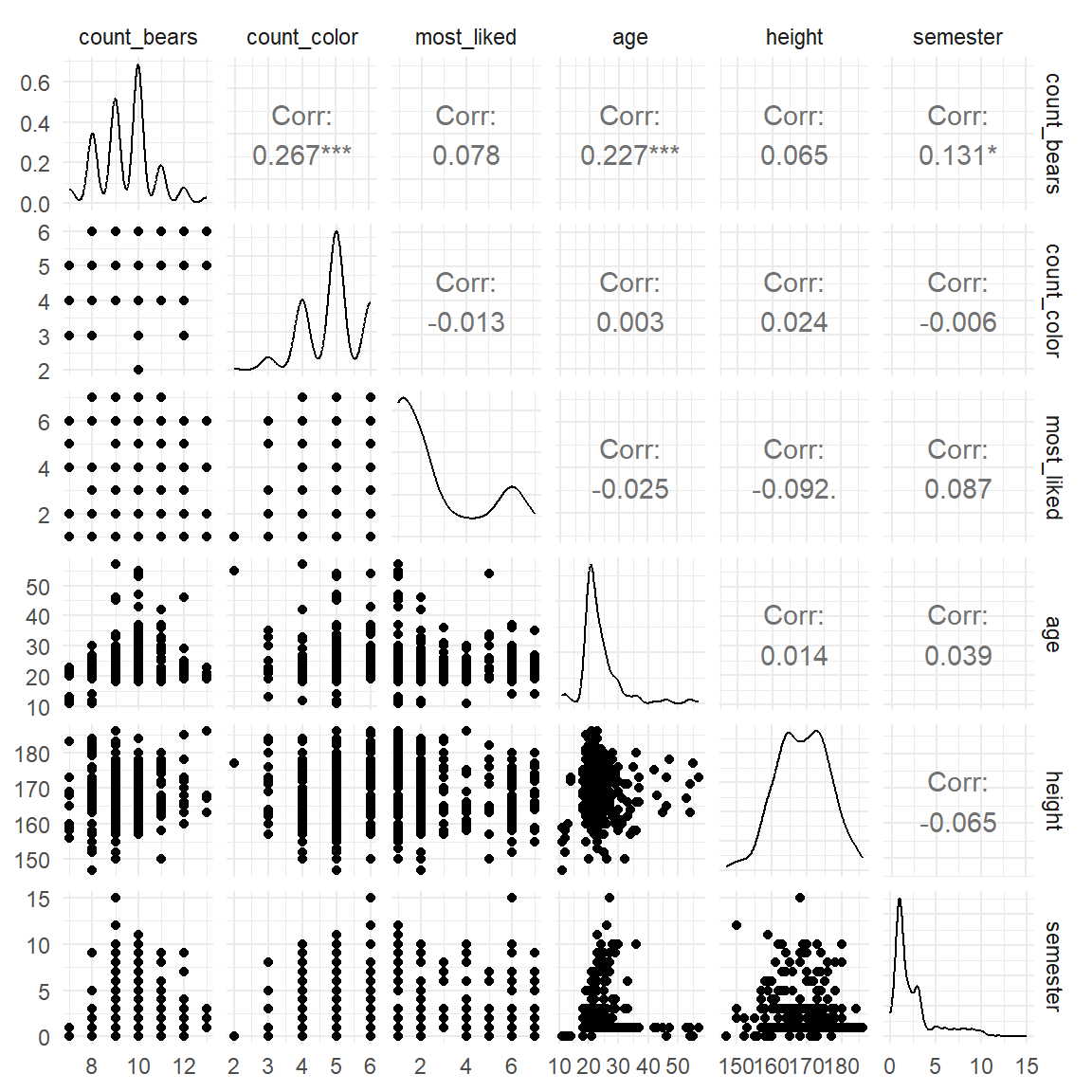
ggpairs() mit allen paarweisen Vergleichen der numerischen Variablen. Auf der unteren Hälfte ist der Scatterplot, in der Diagonalen die Dichte der Variablen sowie im oberen Bereich die Korrelation zwischen den Variablen angegeben.
Die Standardabbildung ist okay, wenn du mal in die Daten schauen willst. Aber eigentlich sind wir an einer schöneren Abbildung interessiert. Wie immer, was ist schon schön, aber ich zeige dir einmal, wie du die Abbildungen in den jeweiligen Bereichen ändern kannst. Bei {GGally} hilft mir eigentlich immer am besten den konkreten Sachverhalt zu googlen, den ich ändern will. Wenn es zu viel wird, dann hilft es mehr sich die Abbildungen dann doch selber zu bauen und über {patachwork} zusammenzukleben. Es geht halt nicht beides, schnell und flexibel. In den folgenden Tabs findest du jeweils eine Funktion, die den oberen, diagonalen und unteren Bereich modifiziert. Die Funktion rufen wir dann in der Funktion ggpairs() auf.
Wir wollen in den oberen Bereich die Korrelation haben, aber ohen die Sternchen und ohne das Wort Corr:. Deshalb müssen wir uns hier nochmal die Korrelationsfunktion selber nachbauen.
cor_func <- function(data, mapping, method, symbol, ...){
x <- eval_data_col(data, mapping$x)
y <- eval_data_col(data, mapping$y)
corr <- cor(x, y, method=method, use='complete.obs')
ggally_text(
label = paste(symbol, as.character(round(corr, 2))),
mapping = aes(),
xP = 0.5, yP = 0.5,
color = 'black'
)
}Auf der Diagonalen wollen wir die Desnityplots haben. Die sind auch so da, aber ich färbe die Plots hier nochmal rot ein. Einfach damot du siehst, was man machen kann.
diag_fun <- function(data, mapping) {
ggplot(data = data, mapping = mapping) +
geom_density(fill = "red", alpha = 0.5)
}In dem unteren Bereich wollen wir die Punkte etwas kleiner haben, deshalb das feom_point2() aus dem R Paket {see}. Dann möchte ich noch die Regressionsgrade einmal zeichnen. Auch hier geht dann mehr, wenn du loess oder aber den Standardfehler sehen willst.
lower_fun <- function(data, mapping) {
ggplot(data = data, mapping = mapping) +
geom_point2() +
geom_smooth(method = "lm", formula = y ~ x, se = FALSE)
}Und dann sammeln wir alles ein und bauen uns die Abbildung 48.12. Wir machen uns es hier etwas einfacher und schreiben gleich das Symbol \(\rho\) als ASCII-Zeichen, da sparen wir etwas nerven. Ansonsten siehst du wie durch die Optionen upper =, diag = und lower = die obigen Funktionen zugewiesen werden und damit dann die einzelnen Bereiche individuell gebaut werden. Wichtig finde ich noch die Möglichkeit, die Seitennamen der Abbildung dann hier in der Funktion über columnLabels = sauber zu benennen.
ggpairs(corr_gummi_tbl,
upper = list(continuous = wrap(cor_func, method = 'pearson', symbol = expression('\u03C1 ='))),
diag = list(continuous = wrap(diag_fun)),
lower = list(continuous = wrap(lower_fun)),
columnLabels = c("Anzahl Bärchen", "Anzahl Farben", "Meist gemocht",
"Alter", "Größe", "Semester")) +
theme_minimal()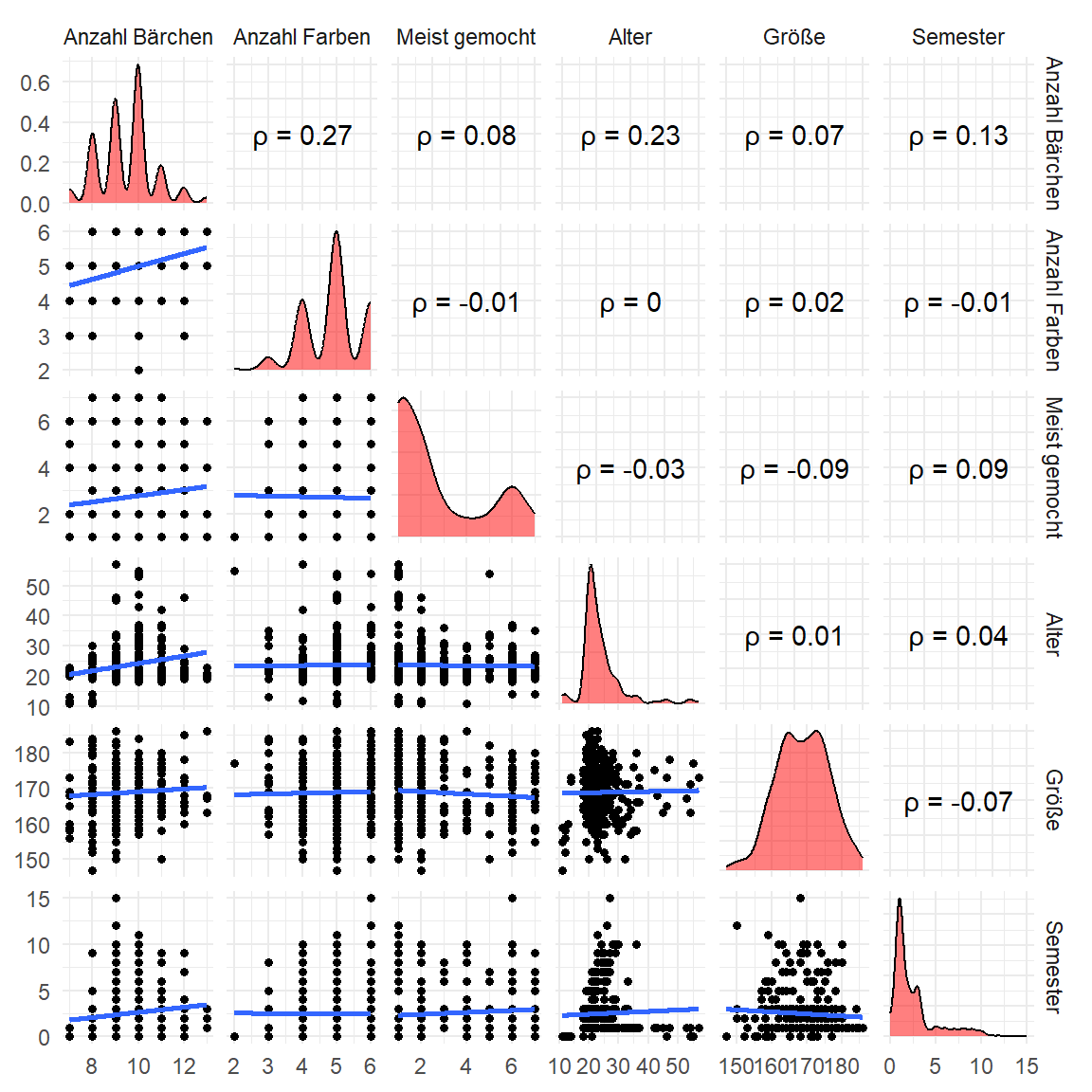
ggpairs() mit allen paarweisen Vergleichen der numerischen Variablen. Auf der unteren Hälfte ist der Scatterplot zusammen mit der Regressionsgrade aus stat_smooth(), in der Diagonalen die eingefärbte Dichte der Variablen sowie im oberen Bereich die Korrelation zwischen den Variablen ohne die Signifikanz und der Überschrift Corr: sondern mit \(\rho\) angegeben.
Hier hilft es dann auch mal mit den Themes theme_minimal() oder theme_void(). In der Abbildung 48.13 habe ich die Labels durch die Funktion axisLabels = "internal" auf die Diagonale gesetzt. Dann musst du entweder die Namen kürzer machen oder aber den Plot größer. Ich habe mich hier für kürzere Namen entschieden. Dementsprechenden spiele einfach mal mit den Möglichkeiten, bis du eine gute Abbildung für dich gefunden hast.
ggpairs(corr_gummi_tbl,
lower = list(continuous = wrap(lower_fun)),
columnLabels = c("Bärchen", "Farben", "Gemocht",
"Alter", "Größe", "Semester"),
axisLabels = "internal") +
theme_minimal()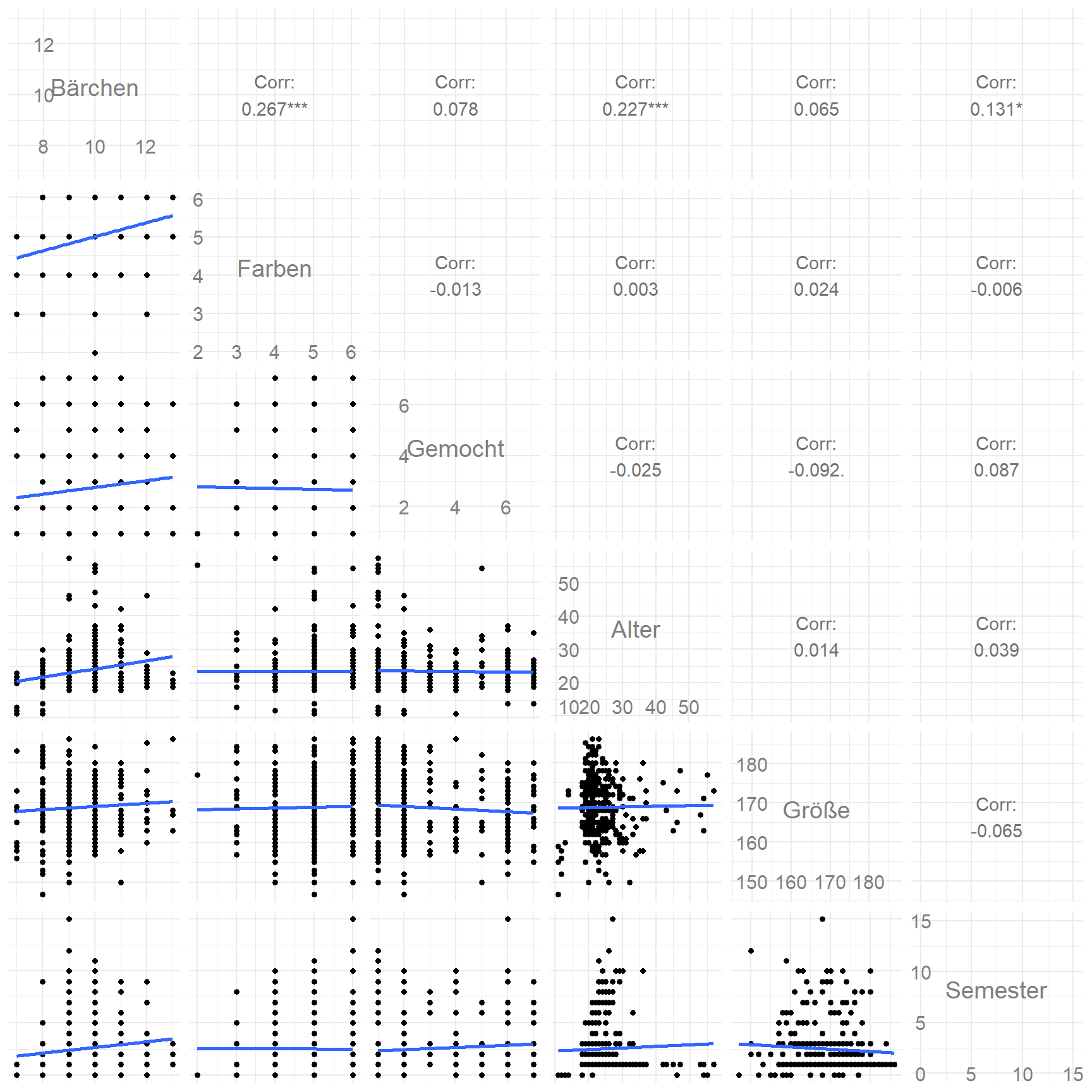
ggpairs() mit allen paarweisen Vergleichen der numerischen Variablen. Hier einmal mit internen Achsenbeschrfitungen und zur Abwechselung dem Theme theme_minimal().
In der Abbildung 48.14 können wir uns noch einmal den Vorteil der Korrelation als ein einheitsloses Maß anschauen. Wenn wir uns nur die Steigung der beiden Gerade betrachten würden, dann wäre die Steigung \(\beta_{kopfgewicht} = 0.021\) und die Steigung \(\beta_{strunkdurchmesser} = 5.15\). Man könnte meinen, das es keinen Zusammenhang zwischen der Boniturnote und dem Kopfgewicht gäbe wohl aber einen starken Zusammenhang zwischen der Boniturnote und dem Durchmesser. Die Steigung der Geraden wird aber stark von den unterschiedlich skalierten Einheiten von Kopfgewicht in [g] und dem Strunkdurchmesserdurchmesser in [cm] beeinflusst.
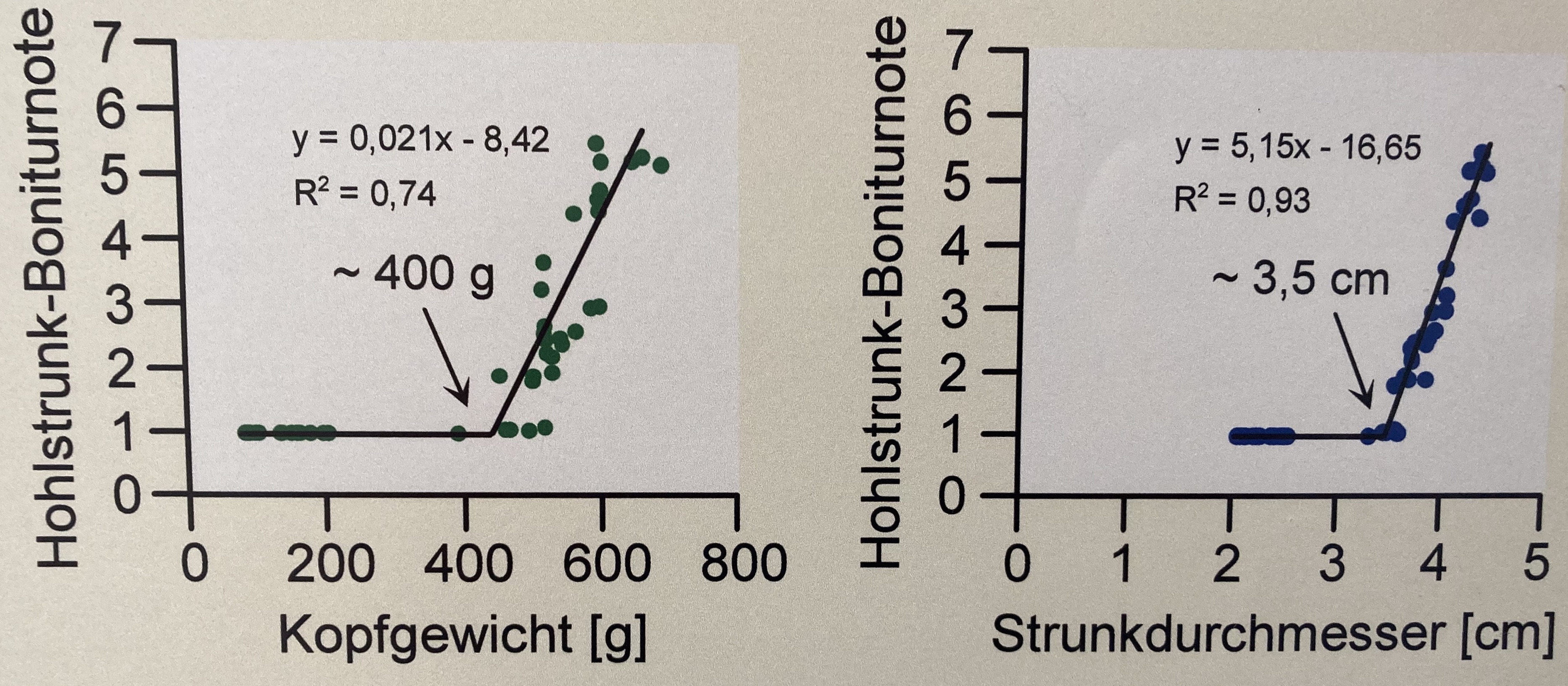
Wir wollen den Zusammenhang nochmal mit der Korrelation überprüfen, da die Korrelation nicht durch die Einheiten von \(y\) und \(x\), in diesem Fall den Einheiten von Kopfgewicht in [g] und dem Durchmesser in [cm], beeinflusst wird. Wir bauen uns zuerst einen künstlichen Datensatz in dem wir die Informationen aus der Geradengleichung nutzen. Dann addieren wir mit der Funktion rnorm() noch einen kleinen Fehler auf jede Beobachtung drauf.
strunk_tbl <- tibble(durchmesser = seq(3.5, 4.5, by = 0.05),
bonitur = 5.15 * durchmesser - 16.65 + rnorm(length(durchmesser), 0, 1))
kopf_tbl <- tibble(gewicht = seq(410, 700, by = 2),
bonitur = 0.021 * gewicht - 8.42 + rnorm(length(gewicht), 0, 1))Wir können und jetzt einmal die Korrelation aus den Daten berechnen. Die Koeffizienten der Geraden sind die gleichen Koeffizienten wie in der Abbildung 48.14. Was wir aber sehen, ist das sich die Korrelation für beide Gerade sehr ähnelt oder fast gleich ist.
strunk_tbl %$%
cor(durchmesser, bonitur, method = "spearman")[1] 0.7805195kopf_tbl %$%
cor(gewicht, bonitur, method = "spearman")[1] 0.8929097Wie wir sehen, können wir mit der Korrelation sehr gut verschiedene Zusammenhänge vergleichen. Insbesondere wenn die Gerade zwar das gleiche Outcome haben aber eben verschiedene Einheiten auf der \(x\)-Achse. Prinzipiell geht es natürlich auch für die Einheiten auf der \(y\)-Achse, aber meistens ist das Outcome der konstante Modellteil.