R Code [zeigen / verbergen]
pacman::p_load(tidyverse, tidymodels, magrittr,
janitor, see, conflicted)
conflicts_prefer(magrittr::set_names)
##
set.seed(2025429)Letzte Änderung am 23. March 2024 um 21:39:15
“Has he lost his mind? Can he see or is he blind? Can he walk at all; Or if he moves, will he fall?” — Black Sabbath, Ironman
Wenn wir von Support Vector Machines (deu. Stützvektormethode, abk. SVM) schreiben, dann schreiben wir auch von einem heutzutage eher selteneren genutzten Algorithmus. Das hat weniger mit den Fähigkeiten des Algorithmus zu tun, als mit der Entscheidung, welche Art von SVM Algorithmus wir nutzen wollen. Daher gibt es wie immer sehr viel theoretische Literatur, aber sehr wenig praktische Anwendung. Der SVM Algorithmus liefert zwar eine Vorhersage, kann aber nicht mit einer Variablen Importance aufwarten. Auch kann der SVM nicht einen Cluster bilden. Am Ende ist der SVM Algorithmus also nur eine Möglichkeit eine gute Vorhersage zu machen. Eigentlich das was wir wollen, aber andere Algorithmen können dann immer noch einen Tick mehr.
Wir wollen folgende R Pakete in diesem Kapitel nutzen.
pacman::p_load(tidyverse, tidymodels, magrittr,
janitor, see, conflicted)
conflicts_prefer(magrittr::set_names)
##
set.seed(2025429)An der Seite des Kapitels findest du den Link Quellcode anzeigen, über den du Zugang zum gesamten R-Code dieses Kapitels erhältst.
In diesem Kapitel wollen wir uns auch auf einen echten Datensatz konzentrieren. Wir nutzen daher einmal den Gummibärchendatensatz. Als unser Label und daher als unser Outcome nehmen wir das Geschlecht gender. Dabei wollen wir dann die weiblichen Studierenden vorhersagen. Im Weiteren nehmen wir nur die Spalte Geschlecht sowie als Prädiktoren die Spalten most_liked, age, semester, und height.
gummi_tbl <- read_excel("data/gummibears.xlsx") |>
mutate(gender = as_factor(gender),
most_liked = as_factor(most_liked)) |>
select(gender, most_liked, age, semester, height) |>
drop_na(gender)Wir dürfen keine fehlenden Werte in den Daten haben. Wir können für die Prädiktoren später die fehlenden Werte imputieren. Aber wir können keine Labels imputieren. Daher entfernen wir alle Beobachtungen, die ein NA in der Variable gender haben. Wir haben dann insgesamt \(n = 878\) Beobachtungen vorliegen. In Tabelle 76.5 sehen wir nochmal die Auswahl des Datensatzes in gekürzter Form.
| gender | most_liked | age | semester | height |
|---|---|---|---|---|
| m | lightred | 35 | 10 | 193 |
| w | yellow | 21 | 6 | 159 |
| w | white | 21 | 6 | 159 |
| w | white | 36 | 10 | 180 |
| m | white | 22 | 3 | 180 |
| m | green | 22 | 3 | 180 |
| … | … | … | … | … |
| w | green | 27 | 17 | 163 |
| m | none | 27 | 2 | 178 |
| m | none | 28 | 5 | 177 |
| w | green | 26 | 2 | 177 |
| w | darkred | 28 | 6 | 174 |
| m | yellow | 36 | NA | 165 |
Unsere Fragestellung ist damit, können wir anhand unserer Prädiktoren männliche von weiblichen Studierenden unterscheiden und damit auch klassifizieren? Um die Klassifikation mit Entscheidungsbäumen rechnen zu können brauchen wir wie bei allen anderen Algorithmen auch einen Trainings- und Testdatensatz. Wir splitten dafür unsere Daten in einer 3 zu 4 Verhältnis in einen Traingsdatensatz sowie einen Testdatensatz auf.
gummi_data_split <- initial_split(gummi_tbl, prop = 3/4)Wir speichern uns jetzt den Trainings- und Testdatensatz jeweils separat ab. Die weiteren Modellschritte laufen alle auf dem Traingsdatensatz, wie nutzen dann erst ganz zum Schluß einmal den Testdatensatz um zu schauen, wie gut unsere trainiertes Modell auf den neuen Testdaten funktioniert.
gummi_train_data <- training(gummi_data_split)
gummi_test_data <- testing(gummi_data_split)Nachdem wir die Daten vorbereitet haben, müssen wir noch das Rezept mit den Vorverabreitungsschritten definieren. Wir schreiben, dass wir das Geschlecht gender als unser Label haben wollen. Daneben nehmen wir alle anderen Spalten als Prädiktoren mit in unser Modell, das machen wir dann mit dem . Symbol. Da wir noch fehlende Werte in unseren Prädiktoren haben, imputieren wir noch die numerischen Variablen mit der Mittelwertsimputation und die nominalen fehlenden Werte mit Entscheidungsbäumen. Dann müssen wir noch alle numerischen Variablen normalisieren und alle nominalen Variablen dummykodieren. Am Ende werde ich nochmal alle Variablen entfernen, sollte die Varianz in einer Variable nahe der Null sein.
gummi_rec <- recipe(gender ~ ., data = gummi_train_data) |>
step_impute_mean(all_numeric_predictors()) |>
step_impute_bag(all_nominal_predictors()) |>
step_range(all_numeric_predictors(), min = 0, max = 1) |>
step_dummy(all_nominal_predictors()) |>
step_nzv(all_predictors())
gummi_rec── Recipe ──────────────────────────────────────────────────────────────────────── Inputs Number of variables by roleoutcome: 1
predictor: 4── Operations • Mean imputation for: all_numeric_predictors()• Bagged tree imputation for: all_nominal_predictors()• Range scaling to [0,1] for: all_numeric_predictors()• Dummy variables from: all_nominal_predictors()• Sparse, unbalanced variable filter on: all_predictors()Alles in allem haben wir ein sehr kleines Modell. Wir haben ja nur ein Outcome und vier Prädiktoren.
Der theoretische Hintergrund zu dem SVM Algorithmus ist sehr mathematisch. So mathematisch, dass wir hier daraus keinen tieferen Nutzen mehr ziehen. Hier geht es ja um die Anwendung des SVM Algorithmus und nicht um das tiefere mathematische Verständnis. Wie immer gibt es sehr viele Möglichkeiten sich tiefer mit der Mathematik hinter dem SVM Algorithmus zu beschäftigen. Hier wollen wir das nicht.
Es gibt wir immer ein schönes (mathematisches) Tutorial zu den Support vector machines. Von dort ist auch das Beispiel mit den farbigen Kugeln entnommen.
Daher wollen wir mal den SVM Algorithmus etwas anders verstehen. Wir nutzen wieder die Idee, dass wir farbige Punkte oder Bälle voneinander trennen wollen. Im Prinzip kannst du dir die Bälle in der Abbildung 80.1 genau so vorstellen. Wir haben dort sieben gesunde Personen als blaue Kugeln und vier kranke Personen als rote Kugeln, die wir trennen wollen.

In Abbildung 80.2 zeichnen wir eine Gerade, die die Patienten gut voneinander trennt. Auf der einen Seite der Geraden sind die sieben gesunden Patienten und auf der anderen Seite der Geraden die vier kranken Personen.
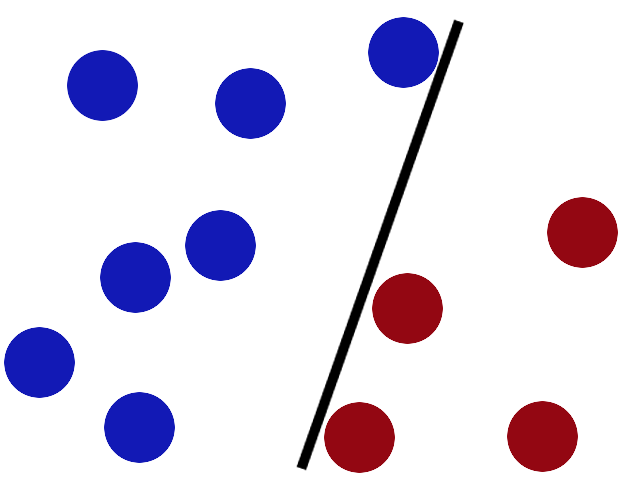
Nun kommt zu unserem Trainingsdatensatz ein Schwall neuer Patienten hinzu und wir ergänzen die Beobachtungen in der Abbildung 80.3. Wir haben immer noch unsere ursprüngliche Gerade, aber diese Gerade trennt die neuen Beobachtungen nicht mehr gut auf. Ein kranker Patient ist auf der falschen Seite der Geraden. Es gibt wahrscheinlich einen besseren Platz, um die Gerade jetzt zu platzieren.
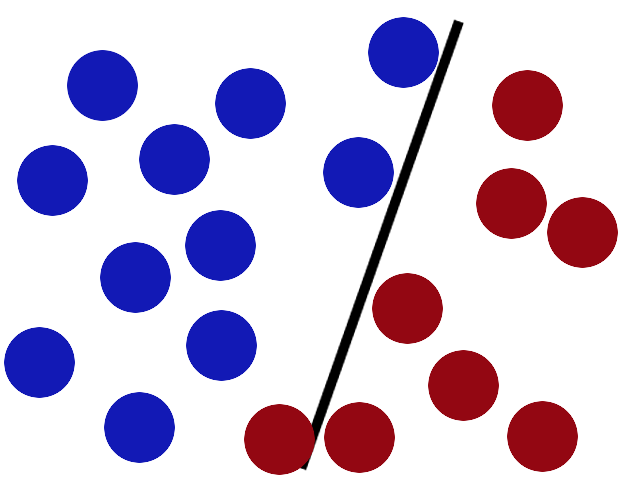
In der Abbildung 80.4 sehen wir die Vorgegehensweise des SVM Algorithmus. Der SVM Algorithmus versucht die Gerade an der bestmöglichen Stelle zu platzieren, indem der Algorithmus auf beiden Seiten der Geraden einen möglichst großen Abstand einhalten.
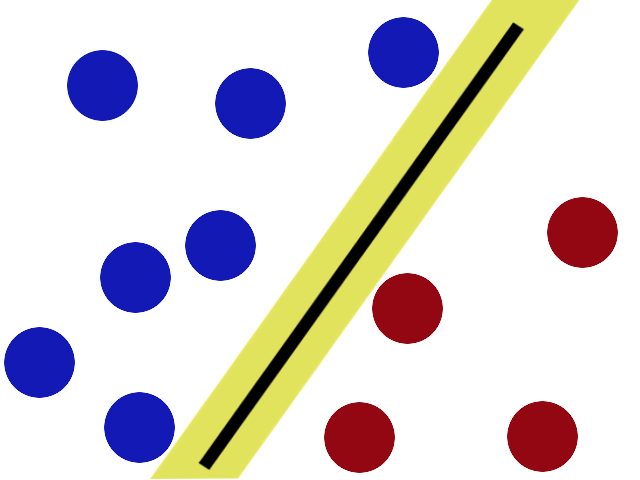
Wenn wir jetzt in der Abbildung 80.5 wieder zu unserem angewachsenen Trainingsdaten zurückkehren, sehen wir, dass unsere Klassifikation der gesunden und kranken Beobachtungen gut funktioniert. Der SVM Algorithmus hat durch den optimierten Abstand der Geraden einen optimalen Klassifikator gefunden.
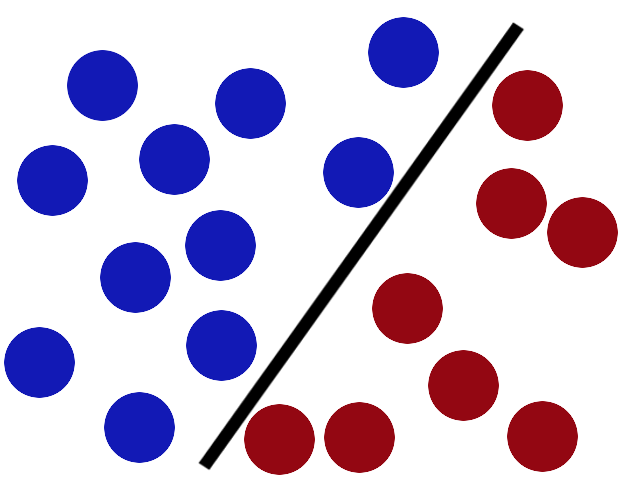
Nun gibt es aber neben der Geraden noch einen anderen Trick, den wir mit dem SVM Algorithmus durchführen können. Schauen wir uns dazu einmal die Abbildung 80.6 an. Wir sehen in dem neuen Trainingsdatensatz fünf gesunde und fünf kranke Beobachtungen. nur sind diese Beobachtungen nicht mehr so verteilt, dass wir die Beobachtungen mit einer Geraden trennen könnten. Hier kommt jetzt der Kerneltrick des SVM Algorithmus zu tragen.

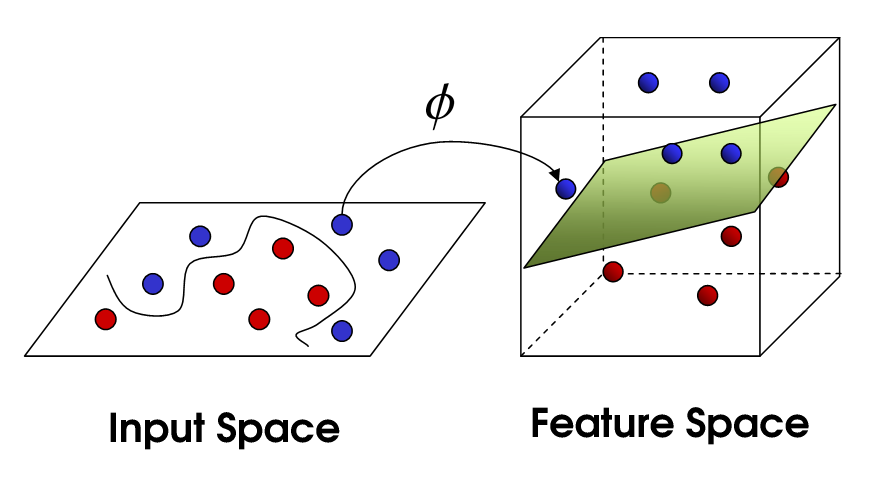
Wir können mit keiner Geraden der Welt die Punkte voneinander trennen. Jetzt nutzen wir den Kerneltrick in Abbildung 80.7 um unsere 2-D Abbildung in eine 3-D Abbildung umzuwandeln. Jetzt können wir mit einer Ebene die Patienten voneinander trennen. Wir bringen also unsere Beobachtungen durch eine Transformation in eine andere Dimension und können in dieser Dimension die Beobachtungen mit einer Ebene trennen.
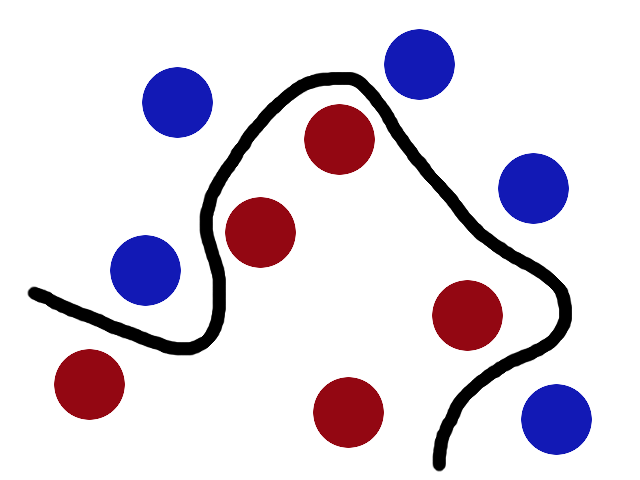
Wenn wir dann die Ebene wieder zurücktransfomieren erhalten wir eine kurvige Linie, die unsere Beobachtungen in Abbildung 80.8 voneinander trennt.
Das war jetzt eine sehr bildliche Darstellung des SVM Algorithmus. Aber im Prinzip ist das die Idee. Wir machen den Kernel Trick nur matematisch komplizierter und auch die Rücktransformation ist nicht simpel. Das müssen wir aber auch nicht selber für uns machen, denn dafür haben wir ja einen Computer. Das eigentliche Problem ist die Wahl des korrekten Kernels. Und das ist eigentlich auch die Qual der Wahl. Wir müssen vorab festlegen, welcher Kernel es sein soll. Und da geht dann das Tuning los.
Leider ist es nicht so, dass wir eine SVM Funktion haben. Wir haben insgesamt drei Funktionen. Jede dieser Funktionen entspricht einem Kernel und muss getrennt voneinander einem Tuning unterzogen werden. Wir haben folgende Funktionen mit den entsprechenden Kernels zu Verfügung.
svm_linear heißt, wir nehmen einen linearen Zusammenhang an. Wir können die Beobachtungen mit einer einfachen Gerade voneinander trennen.svm_poly heißt, wir nehmen ein Polynom eines bestimmten Gerades und glauben, dass wir mit diesem Kernel die Beobachtungen voneinander trennen können.svm_rbf_mod heißt, wir haben einen radialen Kernel und hoffen, dass wir mit einer radialen Funktion die Beobachtungen trennen können.Und damit geht das Leid eigentlich schon los. Wir können gar nicht wissen, welcher der drei SVM Algorithmen am besten auf unsere Daten passt. Also müssen wir alle drei einemal anwenden. Dann müssten wir eigentlich auch alle drei Algorithmen einem Tuning unterziehen. Du siehst, es wird viel Arbeit. Wir lassen hier das Tuning weg und ich zeige dir, wie du mit der Funktion map() dir etwas Arbeit ersparen kannst.
Als erstes wollen wir den linearen Kernel einmal definieren. Wir haben hier zwei Parameter die wir einem Tuning unterziehen könnten.
svm_lin_mod <- svm_linear(cost = 1, margin = 0.1) |>
set_engine("kernlab") |>
set_mode("classification") Als zweites schauen wir uns den polynominale Kernel an und setzen einmal den Grade des Polynomes auf drei. Einfach mal so aus dem Bauch raus um zu zeigen, was dann so passieren kann.
svm_poly_mod <- svm_poly(cost = 1, margin = 0.1, degree = 3) |>
set_engine("kernlab") |>
set_mode("classification") Als letztes schauen wir uns noch den radialen Kernel einmal an. Auch hier haben wir nur zwei Tuningparameter zu Verfügung.
svm_rbf_mod <- svm_rbf(cost = 1, margin = 0.1) |>
set_engine("kernlab") |>
set_mode("classification") Jetzt machen wir alles in einem Schritt. Was wir vorher in mehreren Schritten gemaht haben, machen wir jetzt auf einer Liste lst() in der die Modelle der drei Kernel definiert sind. Wir nutzen die Funktion map() um auf dieser Liste die Workflows mit dem Rezept der Gummibärchen zu initialisieren. Dann Pipen wir die Workflows weiter in die fit() Funktion und wollen dann danach auch gleich die Vorhersage auf dem Testdatensatz rechnen. Danach wählen wir dann auf allen Listen noch gender und die Vorhersagen als die pred-Spalten aus.
svm_aug_lst <- lst(svm_lin_mod,
svm_poly_mod,
svm_rbf_mod) |>
map(~workflow(gummi_rec, .x)) |>
map(~fit(.x, gummi_train_data)) |>
map(~augment(.x, gummi_test_data)) |>
map(~select(.x, gender, matches("pred"))) Setting default kernel parameters svm_aug_lst$svm_lin_mod
# A tibble: 220 × 4
gender .pred_class .pred_m .pred_w
<fct> <fct> <dbl> <dbl>
1 m m 0.991 0.00893
2 w w 0.0303 0.970
3 m w 0.162 0.838
4 m m 0.811 0.189
5 w w 0.0498 0.950
6 m m 0.809 0.191
7 w w 0.0299 0.970
8 m w 0.396 0.604
9 w w 0.0571 0.943
10 m m 0.967 0.0329
# ℹ 210 more rows
$svm_poly_mod
# A tibble: 220 × 4
gender .pred_class .pred_m .pred_w
<fct> <fct> <dbl> <dbl>
1 m m 0.948 0.0518
2 w w 0.472 0.528
3 m w 0.478 0.522
4 m m 0.536 0.464
5 w w 0.455 0.545
6 m m 0.512 0.488
7 w w 0.478 0.522
8 m w 0.488 0.512
9 w w 0.334 0.666
10 m m 0.627 0.373
# ℹ 210 more rows
$svm_rbf_mod
# A tibble: 220 × 4
gender .pred_class .pred_m .pred_w
<fct> <fct> <dbl> <dbl>
1 m m 0.791 0.209
2 w w 0.0725 0.927
3 m w 0.146 0.854
4 m m 0.894 0.106
5 w w 0.0362 0.964
6 m m 0.815 0.185
7 w w 0.0790 0.921
8 m w 0.337 0.663
9 w w 0.0358 0.964
10 m m 0.856 0.144
# ℹ 210 more rowsJetzt haben wir also alles als eine Liste vorliegen. Das macht uns dann die weitere Darstellung einfach. Wenn du einen Listeneintrag haben willst, dann kannst du auch mit der Funktion pluck() dir einen Eintrag nach dem Namen herausziehen. Wenn du den Listeneintrag $svm_rbf_mod willst, dann nutze pluck(svn_aug_lst, "svm_rbf_mod").
Ja, kannst du. Wenn du nur eine Kreuzvalidierung durchführen willst, findest du alles im Kapitel 78 für den \(k\)-NN Algorithmus. Du musst dort nur den Workflow ändern und schon kannst du alles auch auf den Support Vector Machine Algorithmus anwenden. Wenn du den Support Vector Machine Algorithmus auch tunen willst, dann schaue einfach nochmal im Kapitel 79.5 zum Tuning von xgboost rein.
Jetzt lassen wir uns auf der Liste der Vorhersagen nochmal für alle Kernel der SVM Algorithmen die Konfusionsmatrizen ausgeben.
svm_cm <- svm_aug_lst |>
map(~conf_mat(.x, gender, .pred_class))
svm_cm$svm_lin_mod
Truth
Prediction m w
m 84 14
w 20 102
$svm_poly_mod
Truth
Prediction m w
m 82 19
w 22 97
$svm_rbf_mod
Truth
Prediction m w
m 87 18
w 17 98Das sieht doch recht gut aus. Nur unser Polynomerkernel hat anscheinend Probleme die Geschlechter gut voneinander aufzutrennen. Du siehst, hier muss eben auch ein Tuning her. Selber den Grad des Polynoms zu treffen das passt ist sehr schwer oder eigentlich nur mit Glück hinzukriegen.
Im folgenden Schritt müssen wir uns etwas strecken. Ich will nämlich die summary() Funktion auf die Konfusionsmatrizen anwenden und dann die drei Ausgaben in einem Datensatz zusammenführen. Wir haben dann die Metriknamen als eine Spalte und dann die drei Spalten für die Zahlenwerte der drei Methoden.
svm_cm |>
map(summary) |>
map(~select(.x, .metric, .estimate)) |>
reduce(left_join, by = ".metric") |>
set_names(c("metric", "linear", "poly", "radial")) |>
mutate(across(where(is.numeric), round, 3))Warning: There was 1 warning in `mutate()`.
ℹ In argument: `across(where(is.numeric), round, 3)`.
Caused by warning:
! The `...` argument of `across()` is deprecated as of dplyr 1.1.0.
Supply arguments directly to `.fns` through an anonymous function instead.
# Previously
across(a:b, mean, na.rm = TRUE)
# Now
across(a:b, \(x) mean(x, na.rm = TRUE))# A tibble: 13 × 4
metric linear poly radial
<chr> <dbl> <dbl> <dbl>
1 accuracy 0.845 0.814 0.841
2 kap 0.689 0.626 0.681
3 sens 0.808 0.788 0.837
4 spec 0.879 0.836 0.845
5 ppv 0.857 0.812 0.829
6 npv 0.836 0.815 0.852
7 mcc 0.69 0.626 0.681
8 j_index 0.687 0.625 0.681
9 bal_accuracy 0.844 0.812 0.841
10 detection_prevalence 0.445 0.459 0.477
11 precision 0.857 0.812 0.829
12 recall 0.808 0.788 0.837
13 f_meas 0.832 0.8 0.833Wenn wir wieder auf unsere Accuracy als unser primäres Gütemaß schauen, dann sehen wir, dass wir hier ohne Tuning mit dem linearen Kernel am besten fahren würden. Auch sind die anderen Werte meistens für den linearen Kernel am besten. Daher würde ich mich hier für den linearen Kernel entscheiden. Die Frage wäre natürlich, ob die anderen Kernel mit einem Tuning nicht besser wären. Aber diese Frage lassen wir mal offen im Raum stehen.
Schauen wir uns in einem letzten Schritt noch die ROC Kurven für die drei Kernels an. Dafür müssen wir einen Datensatz aus der Liste bilden nachdem wir die Sensitivität und Spezifität für die drei Kernels in der Listenform berechnet haben. Wir können dafür die Funktion bind_rows() nutzen.
roc_tbl <- svm_aug_lst |>
map(~roc_curve(.x, gender, .pred_w, event_level = "second")) |>
bind_rows(.id = "model")In Abbildung 80.9 sehen wir die drei ROC Kurven für die drei Kernels. Wie zu erwarten war, ist der lineare Kernel der beste Kernel. Das hatten wir ja schon oben in der Zusammenfassung der Konfusionsmatrix gesehen. Auch hier zeigt sich sehr schön, wie schlecht dann unser polynominaler Kernel ist. Das war jetzt hier zur Demonstration, aber dennoch zeigt es wie wichtig ein gutes Tuning ist.
roc_tbl |>
ggplot(aes(x = 1 - specificity, y = sensitivity, col = model)) +
theme_minimal() +
geom_path() +
geom_abline(lty = 3) +
scale_color_okabeito()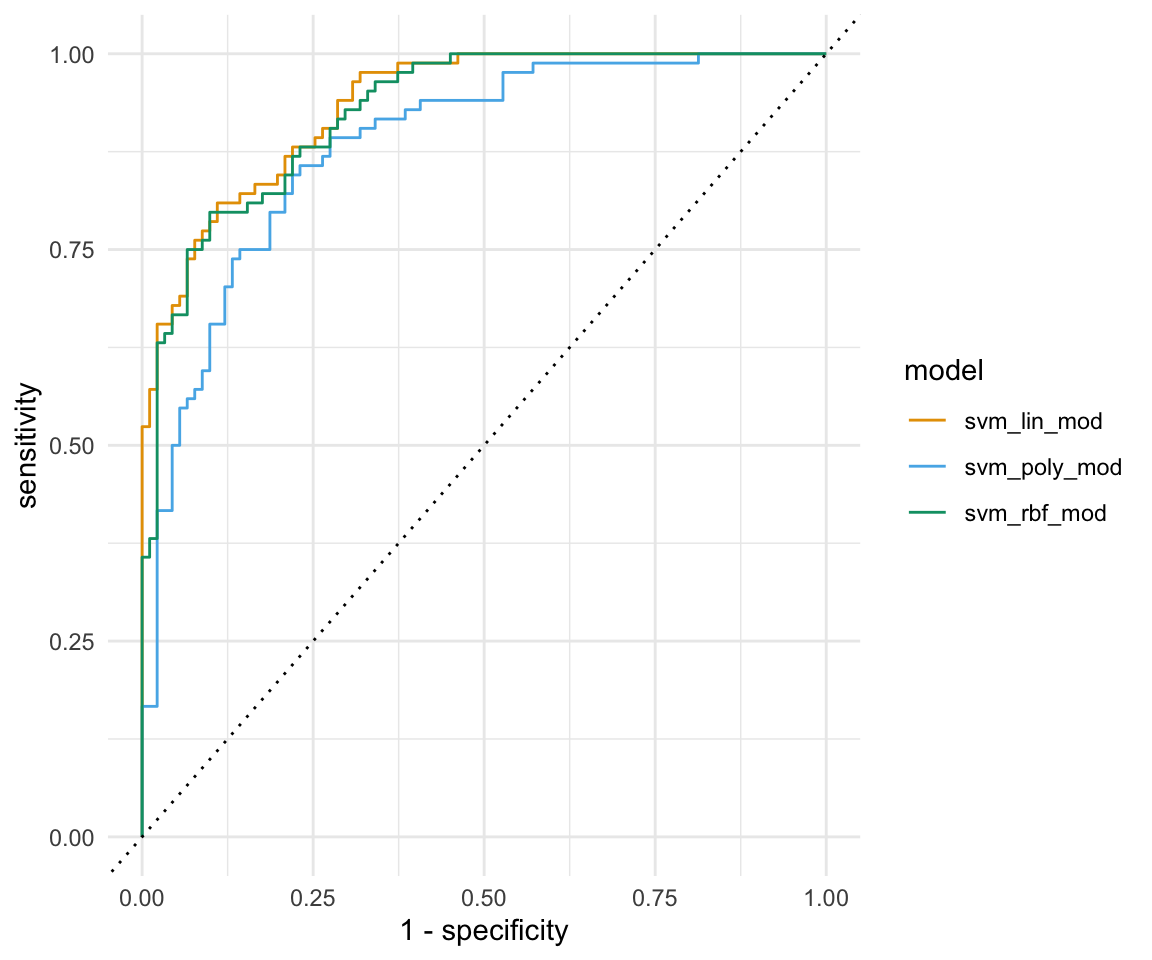
Damit wären wir auch schon am Ende des Kapitels über den SVM Algorithmus. Wie du schon merkst, müssen wir viel rechnen, wenn wir mit den SVM Kerneln was Vorhersagen wollen. Wenn wir den richtigen Kernel gefunden haben, dann können wir auch eine gute Vorhersage erreichen. Nun müssen auch diesen Kernel erstmal algorithmisch finden, dass heißt also viele Kernels ausprobieren. Und am Ende ist natürlich die Implementierung hier im genutzten R Paket {parsnip} nicht die Weisheit letzter Schluss. Es gibt noch sehr viel mehr R Pakete, die sich mit SVM Algorithmen beschäftigen. Aber das wäre dann eine Literatursuche für dich. Vorerst endet das Kapitel jetzt hier.