R Code [zeigen / verbergen]
pacman::p_load(tidyverse, magrittr, broom,
readxl, effectsize, ggpubr,
see, car, conflicted)
conflicts_prefer(plyr::mutate)
conflicts_prefer(dplyr::summarize)Letzte Änderung am 21. November 2024 um 21:58:52
“Yeah, I might seem so strong; Yeah, I might speak so long; I’ve never been so wrong.” — London Grammar, Strong
Die ANOVA (eng. analysis of variance) ist wichtig. Was für ein schöner Satz um anzufangen. Historisch betrachtet ist die ANOVA, das statistische Verfahren was gut per Hand ohne Computer berechnet werden kann. Daher war die ANOVA von den 20zigern bis in die frühen 90ziger des letzten Jahrhunderts das statistische Verfahren der Wahl. Wir brauchen daher die ANOVA aus mehreren Gründen. Die Hochzeiten der ANOVA sind eigentlich vorbei, wir haben in der Statistik für viele Fälle mittlerweile besser Werkzeuge, aber als Allrounder ist die ANOVA immer noch nutzbar. Wir werden immer wieder auf die ANOVA inhaltlich zurück kommen und in vielen Abschlussarbeiten wird die ANOVA immer noch als integraler Bestandteil genutzt. Wofür und wann brauchen wir die ANOVA, wenn wir Daten auswerten?
Wir können die einfaktorielle ANOVA in folgender Form schreiben mit einem \(f_1\) für den Faktor. Damit haben wir einen bessere Übersicht. Wieder ist das \(y\) und der Faktor \(f_1\) jeweils eine separate Spalte in unserem Datensatz.
\[ y \sim f_1 \]
Somit erklärt sich die zweifaktorielle ANOVA schon fast von alleine. Wir erweitern einfach das Modell um einen zweiten Faktor \(f_2\) und haben somit eine zweifaktorielle ANOVA vorliegen. Auch hier müssen wir beachten, dass das \(y\) und die Faktoren \(f_1\) und \(f_2\) jeweils eine separate Spalte in unserem Datensatz sind.
\[ y \sim f_1 + f_2 \]
Wir sehen also, dass die ANOVA zum einen alt ist, aber auch heute noch viel verwendet wird. Daher werden wir in diesem langem Kapitel uns einmal mit der ANOVA ausgiebig beschäftigen. Fangen wir also an, dieses großartige Schweizertaschenmesser der Statistik besser zu verstehen.
Die einfaktorielle ANOVA vergleicht die Parameter mehrerer Normalverteilungen miteinander. Oder etwas anders formuliert, vergleicht die ANOVA die Mittlelwerte von mehreren Gruppen bzw. Behandlungen miteinander.
Die zweifaktorielle ANOVA vergleicht die Parameter mehrerer Normalverteilungen von zwei Faktoren miteinander. Oder etwas anders formuliert, vergleicht die ANOVA die Mittelwerte von mehreren Gruppen bzw. Behandlungen miteinander. Dabei kann die zweifaktorielle ANOVA auch die Interaktion zwischen zwei Variablen abbilden.
Wir wollen folgende R Pakete in diesem Kapitel nutzen.
pacman::p_load(tidyverse, magrittr, broom,
readxl, effectsize, ggpubr,
see, car, conflicted)
conflicts_prefer(plyr::mutate)
conflicts_prefer(dplyr::summarize)An der Seite des Kapitels findest du den Link Quellcode anzeigen, über den du Zugang zum gesamten R-Code dieses Kapitels erhältst.
Die einfaktorielle ANOVA ist die simpelste Form der ANOVA. Wir nutzen einen Faktor \(x\) mit mehr als zwei Leveln. Im Rahmen der einfaktoriellen ANOVA wollen wir uns auch die ANOVA theoretisch einmal anschauen. Danach wie die einfaktorielle ANOVA in R genutzt wird. Ebenso werden wir die einfaktorielle ANOVA visualisieren. Abschließend müssen wir uns noch überlegen, ob es einen Effektschätzer für die einfaktorielle ANOVA gibt.

Die einfaktorielle ANOVA verlangt ein normalverteiltes \(y\) sowie Varianzhomogenität über den Behandlungsfaktor \(x\). Daher alle Level von \(x\) sollen die gleiche Varianz haben. Unsere Annahme an die Daten \(D\) ist, dass das dein \(y\) normalverteilt ist und das die Level vom \(x\) homogen in den Varianzen sind. Später mehr dazu, wenn wir beides nicht vorliegen haben…
Wir wollen uns nun erstmal den einfachsten Fall anschauen mit einem simplen Datensatz. Wir nehmen ein normalverteiltes \(y\) aus den Datensatz flea_dog_cat_fox.csv und einen Faktor mit mehr als zwei Leveln. Hätten wir nur zwei Level, dann hätten wir auch einen t-Test rechnen können.
Im Folgenden selektieren mit der Funktion select() die beiden Spalten jump_length als \(y\) und die Spalte animal als \(x\). Danach müssen wir noch die Variable animal in einen Faktor mit der Funktion as_factor() umwandeln.
fac1_tbl <- read_csv2("data/flea_dog_cat_fox.csv") |>
select(animal, jump_length) |>
mutate(animal = as_factor(animal))Wir erhalten das Objekt fac1_tbl mit dem Datensatz in Tabelle 30.1 nochmal dargestellt.
jump_length und einem Faktor animal mit drei Leveln.
| animal | jump_length |
|---|---|
| dog | 5.7 |
| dog | 8.9 |
| dog | 11.8 |
| dog | 5.6 |
| dog | 9.1 |
| dog | 8.2 |
| dog | 7.6 |
| cat | 3.2 |
| cat | 2.2 |
| cat | 5.4 |
| cat | 4.1 |
| cat | 4.3 |
| cat | 7.9 |
| cat | 6.1 |
| fox | 7.7 |
| fox | 8.1 |
| fox | 9.1 |
| fox | 9.7 |
| fox | 10.6 |
| fox | 8.6 |
| fox | 10.3 |
Wir bauen daher mit den beiden Variablen mit dem Objekt fac1_tbl folgendes Modell für die spätere Analyse in R.
\[ jump\_length \sim animal \]
Bevor wir jetzt das Modell verwenden, müssen wir uns nochmal überlegen, welchen Schluß wir eigentlich über die Nullhypothese machen. Wir immer können wir nur die Nullhypothese ablehnen. Daher überlegen wir uns im Folgenden wie die Nullhypothese in der einfaktoriellen ANOVA aussieht. Dann bilden wir anhand der Nullhypothese noch die Alternativehypothese.
Die ANOVA betrachtet die Mittelwerte und nutzt die Varianzen um einen Unterschied nachzuweisen. Daher haben wir in der Nullhypothese als Gleichheitshypothese. In unserem Beispiel lautet die Nullhypothese, dass die Mittelwerte jedes Levels des Faktors animal gleich sind.
\[ H_0: \; \bar{y}_{cat} = \bar{y}_{dog} = \bar{y}_{fox} \]
Die Alternative lautet, dass sich mindestens ein paarweiser Vergleich in den Mittelwerten unterschiedet. Hierbei ist das mindestens ein Vergleich wichtig. Es können sich alle Mittelwerte unterschieden oder eben nur ein Paar. Wenn eine ANOVA die \(H_0\) ablehnt, also ein signifikantes Ergebnis liefert, dann wissen wir nicht, welche Mittelwerte sich unterscheiden.
\[ \begin{aligned} H_A: &\; \bar{y}_{cat} \ne \bar{y}_{dog}\\ \phantom{H_A:} &\; \bar{y}_{cat} \ne \bar{y}_{fox}\\ \phantom{H_A:} &\; \bar{y}_{dog} \ne \bar{y}_{fox}\\ \phantom{H_A:} &\; \mbox{für mindestens ein Paar} \end{aligned} \]
Wir schauen uns jetzt einmal die ANOVA theoretisch an bevor wir uns mit der Anwendung der ANOVA in R beschäftigen.
Kommen wir zurück zu den Daten in Tabelle 30.1. Wenn wir die ANOVA per Hand rechnen wollen, dann ist nicht das Long Format die beste Wahl sondern das Wide Format. Wir haben ein balanciertes Design vorliegen, dass heißt in jeder Level sind die gleiche Anzahl Beobachtungen. Wir schauen uns jeweils sieben Flöhe von jeder Tierart an. Für eine ANOVA ist aber ein balanciertes Design nicht notwendig, wir können auch mit ungleichen Gruppengrößen eine ANOVA rechnen. Statt einer einfaktoriellen ANOVA könnten wir auch gleich einen pairwise.t.test()rechnen. Historisch betrachtet ist die einfaktorielle ANOVA die Visualisierung des paarweisen t-Tests.
Eine einfaktorielle ANOVA macht eigentlich keinen großen Sinn, wenn wir anschließend sowieso paarweise Vergleich, wie in Kapitel 40 beschrieben, rechnen. Aus der Historie stellte sich die Frage, ob es sich lohnt die ganze Arbeit für die paarweisen t-Tests per Hand zu rechnen. Daher wurde die ANOVA davor geschaltet. War die ANOVA nicht signifikant, dann konnte man sich dann auch die Rechnerei für die paarweisen t-Tests sparen.
In Tabelle 30.2 sehen wir die Daten einmal als Wide-Format dargestellt.
fac1_tbl für die jeweils \(j=7\) Beobachtungen für den Faktor animal.
| j | dog | cat | fox |
|---|---|---|---|
| 1 | 5.7 | 3.2 | 7.7 |
| 2 | 8.9 | 2.2 | 8.1 |
| 3 | 11.8 | 5.4 | 9.1 |
| 4 | 8.2 | 4.1 | 9.7 |
| 5 | 5.6 | 4.3 | 10.6 |
| 6 | 9.1 | 7.9 | 8.6 |
| 7 | 7.6 | 6.1 | 10.3 |
Wir können jetzt für jedes der Level den Mittelwert über all \(j=7\) Beobachtungen berechnen.
\[ \begin{aligned} \bar{y}_{dog} &= 8.13 \\ \bar{y}_{cat} &= 4.74 \\ \bar{y}_{fox} &= 9.16 \\ \end{aligned} \]
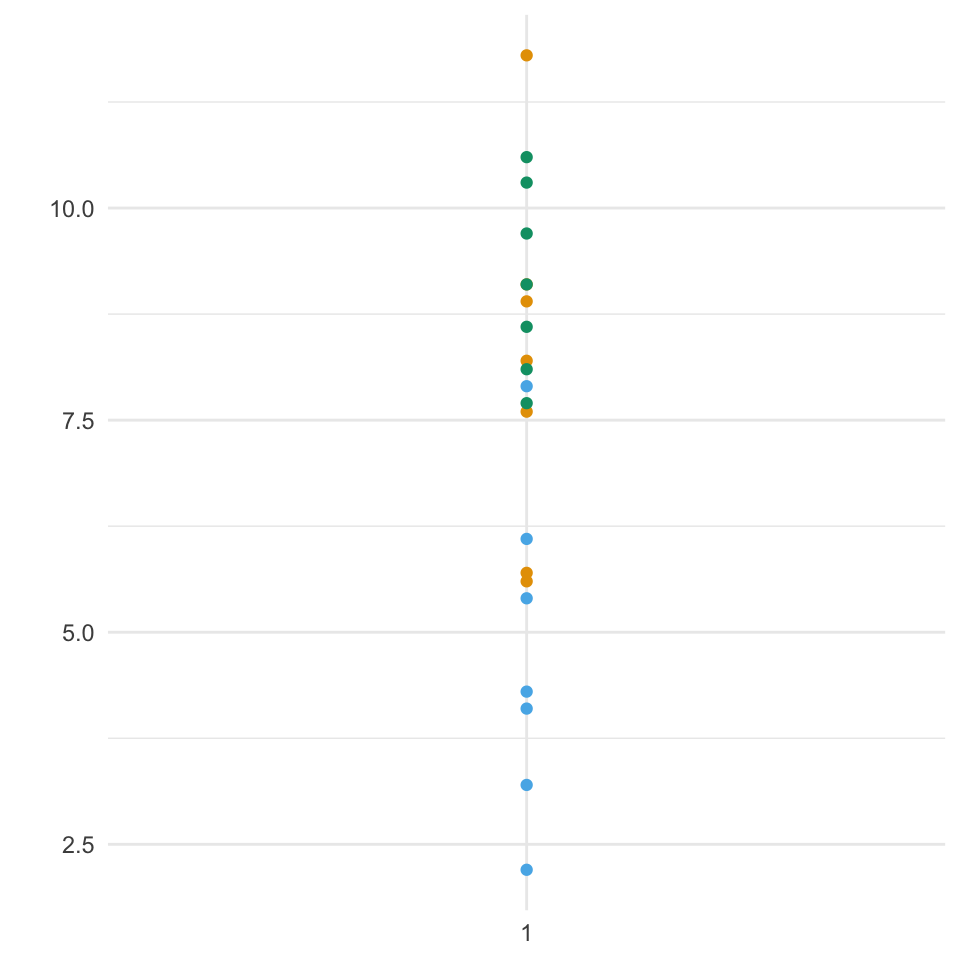
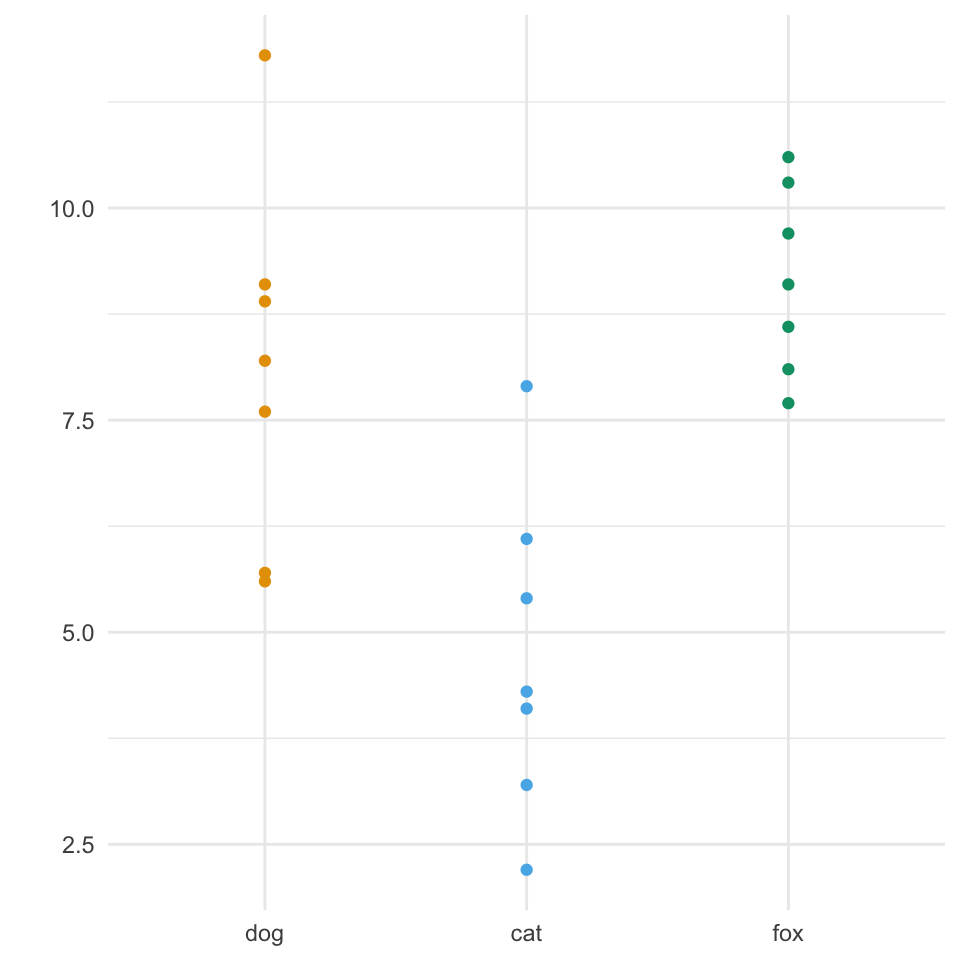
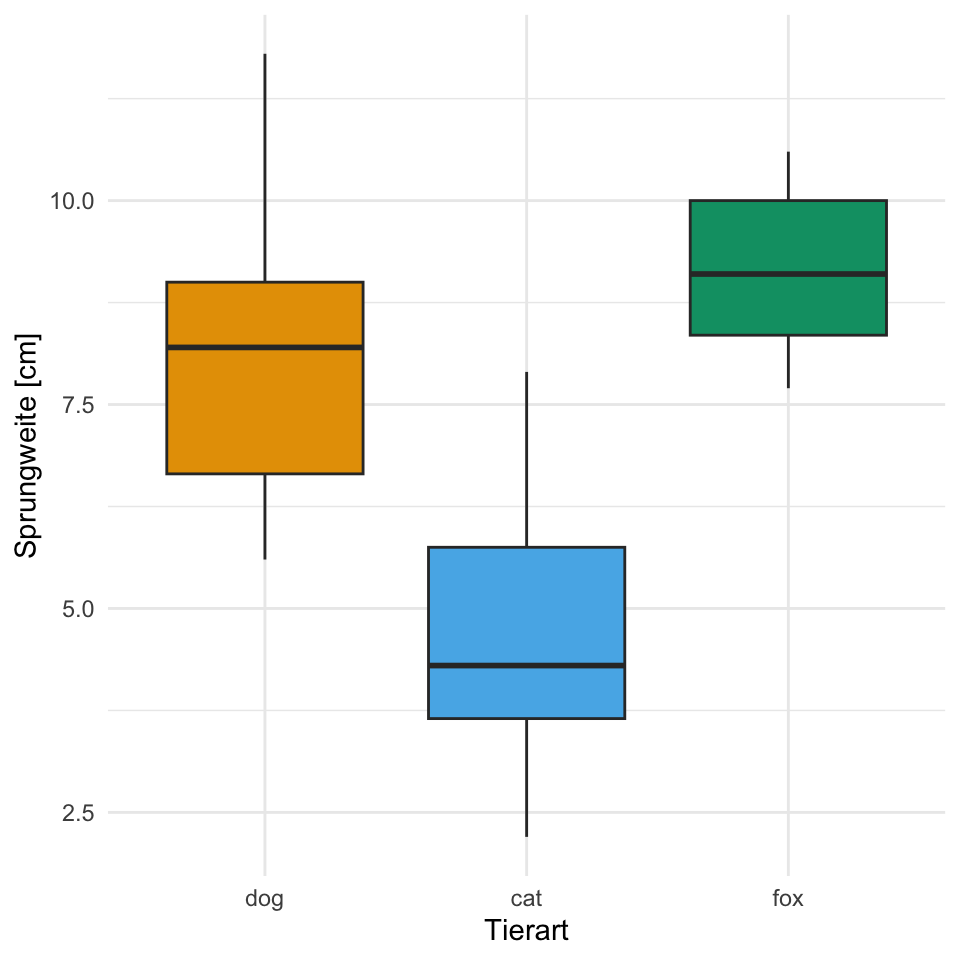
Wir tun jetzt für einen Moment so, als gebe es den Faktor animal nicht in den Daten und schauen uns die Verteilung der einzelnen Beobachtungen in Abbildung 30.1 (a) einmal an. Wir sehen das sich die Beobachtungen von ca. 2.2cm bis 11 cm streuen. Woher kommt nun diese Streuung bzw. Varianz? Was ist die Quelle der Varianz? In Abbildung 30.1 (b) haben wir die Punkte einmal nach dem Faktor animal eingefärbt. Wir sehen, dass die blauen Beobachtungen eher weitere Sprunglängen haben als die grünen Beobachtungen. Wir gruppieren die Beobachtungen in Abbildung 30.1 (c) nach dem Faktor animal und sehen, dass ein Teil der Varianz der Daten von dem Faktor animal ausgelöst wird.
animal betrachtet.
animal eingefärbt.
animal eingefärbt und gruppiert.
animal dargestellt.
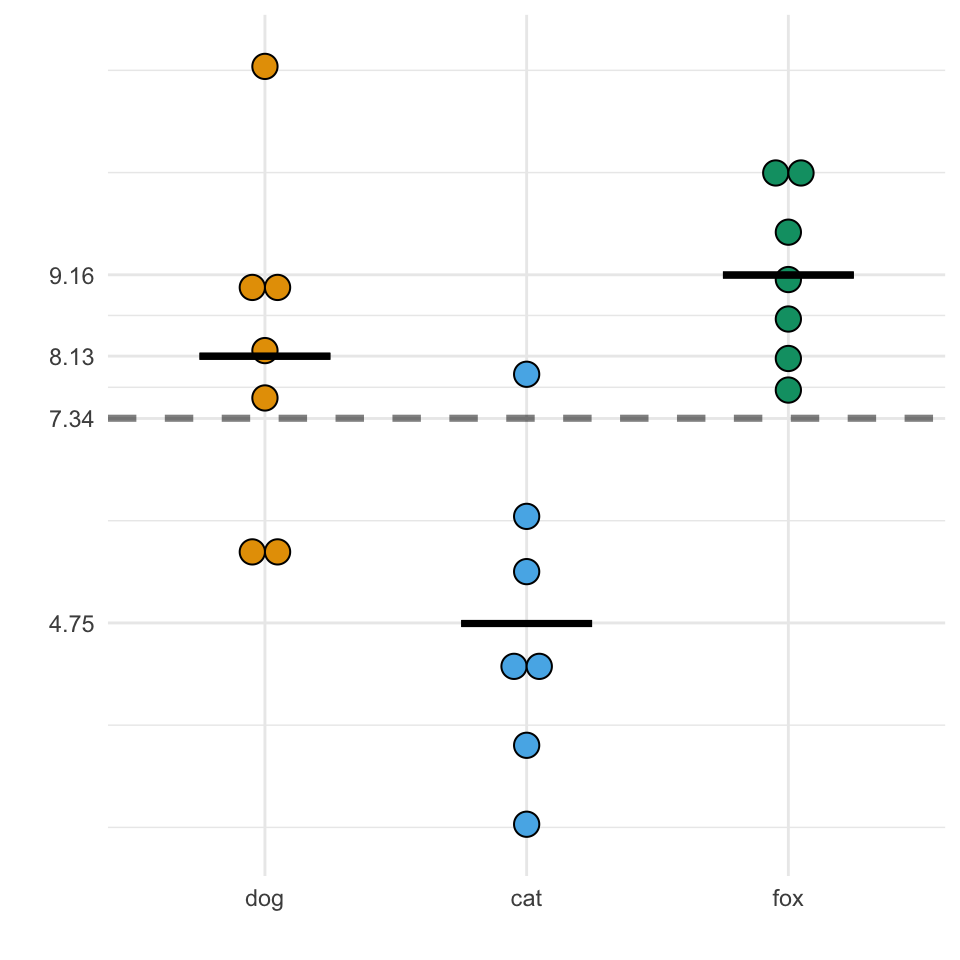
Gehen wir einen Schritt weiter und zeichnen einmal das globale Mittel in die Abbildung 30.2 (a) von \(\bar{y}_{..} = 7.34\) und lassen die Beobachtungen gruppiert nach dem Faktor animal. Wir sehen, dass die Level des Faktors animal um das globale Mittel streuen. Was ja auch bei einem Mittelwert zu erwarten ist. Wir können jetzt in Abbildung 30.2 (b) die lokalen Mittel für die einzelnen Level dog, catund fox ergänzen. Und abschließend in Abbildung 30.2 (c) die Abweichungen \(\\beta_i\) zwischen dem globalen Mittel \(\bar{y}_{..} = 7.34\) und den einzelnen lokalen Mittel berechnen. Die Summe der Abweichungen \(\\beta_i\) ist \(0.79 + (-2.6) + 1.81 \approx 0\). Das ist auch zu erwarten, den das globale Mittel muss ja per Definition als Mittelwert gleich großen Abstand “nach oben” wie “nach unten” haben.

animal gruppiert und das globale Mittel \(\bar{y}_{..} = 7.34\) ergänzt.
animal gruppiert und die lokalen Mittel \(\bar{y}_{i.}\) für jedes Level ergänzt.
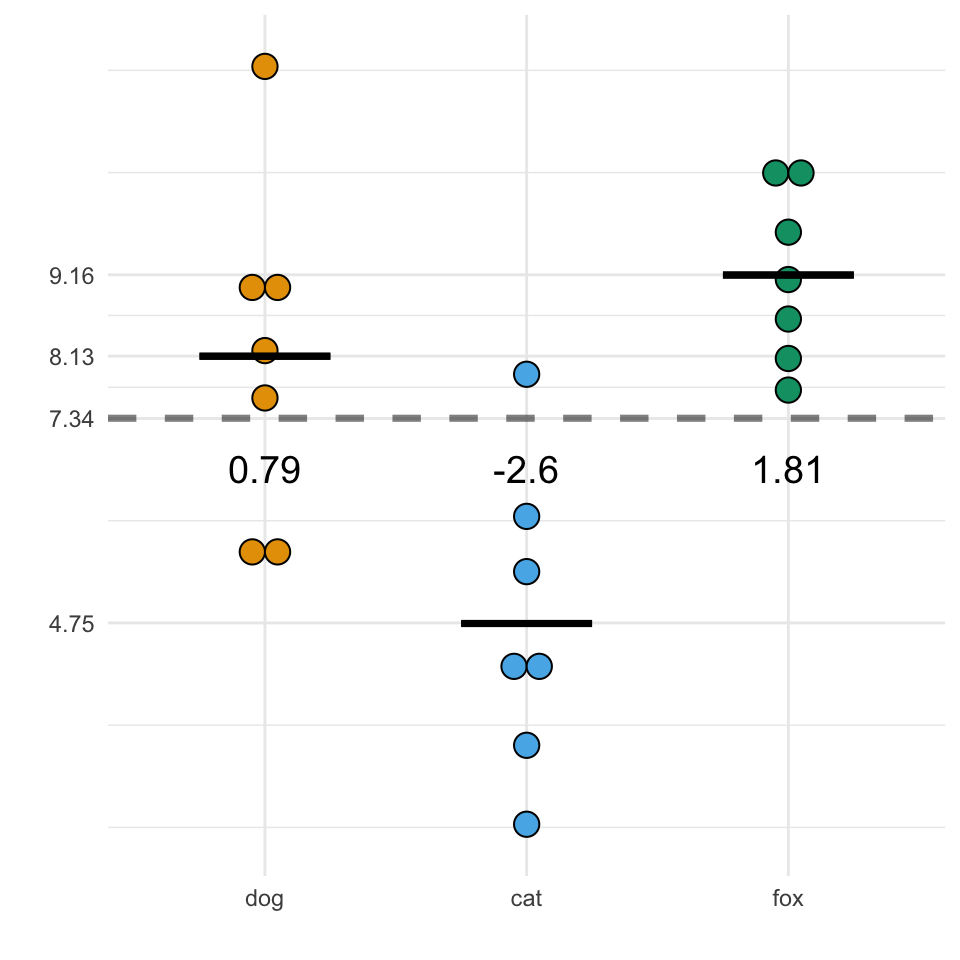
animal gruppiert und die Abweichungen \(\beta_i\) ergänzt.
animal.
Wir tragen die Werte der lokalen Mittelwerte \(\bar{y}_{i.}\) und deren Abweichungen \(\beta_i\) vom globalen Mittelwert \(\bar{y}_{..} = 7.34\) noch in die Tabelle 30.3 ein. Wir sehen in diesem Beispiel warum das Wide Format besser zum Verstehen der ANOVA ist, weil wir ja die lokalen Mittelwerte und die Abweichungen per Hand berechnen. Da wir in der Anwendung aber nie die ANOVA per Hand rechnen, liegen unsere Daten immer in R als Long-Format vor. Es handelt sich hier nur um die Veranschaulichung des Konzepts der ANOVA.
fac1_tbl für die jeweils \(j=7\) Beobachtungen für den Faktor animal. Wir ergänzen die lokalen Mittlwerte \(\bar{y}_{i.}\) und deren Abweichungen \(\beta_i\) vom globalen Mittelwert \(\bar{y}_{..} = 7.34\).
| j | dog | cat | fox |
|---|---|---|---|
| 1 | 5.7 | 3.2 | 7.7 |
| 2 | 8.9 | 2.2 | 8.1 |
| 3 | 11.8 | 5.4 | 9.1 |
| 4 | 8.2 | 4.1 | 9.7 |
| 5 | 5.6 | 4.3 | 10.6 |
| 6 | 9.1 | 7.9 | 8.6 |
| 7 | 7.6 | 6.1 | 10.3 |
| \(\bar{y}_{i.}\) | \(8.13\) | \(4.74\) | \(9.16\) |
| \(\beta_i\) | \(-2.6\) | \(0.79\) | \(1.81\) |
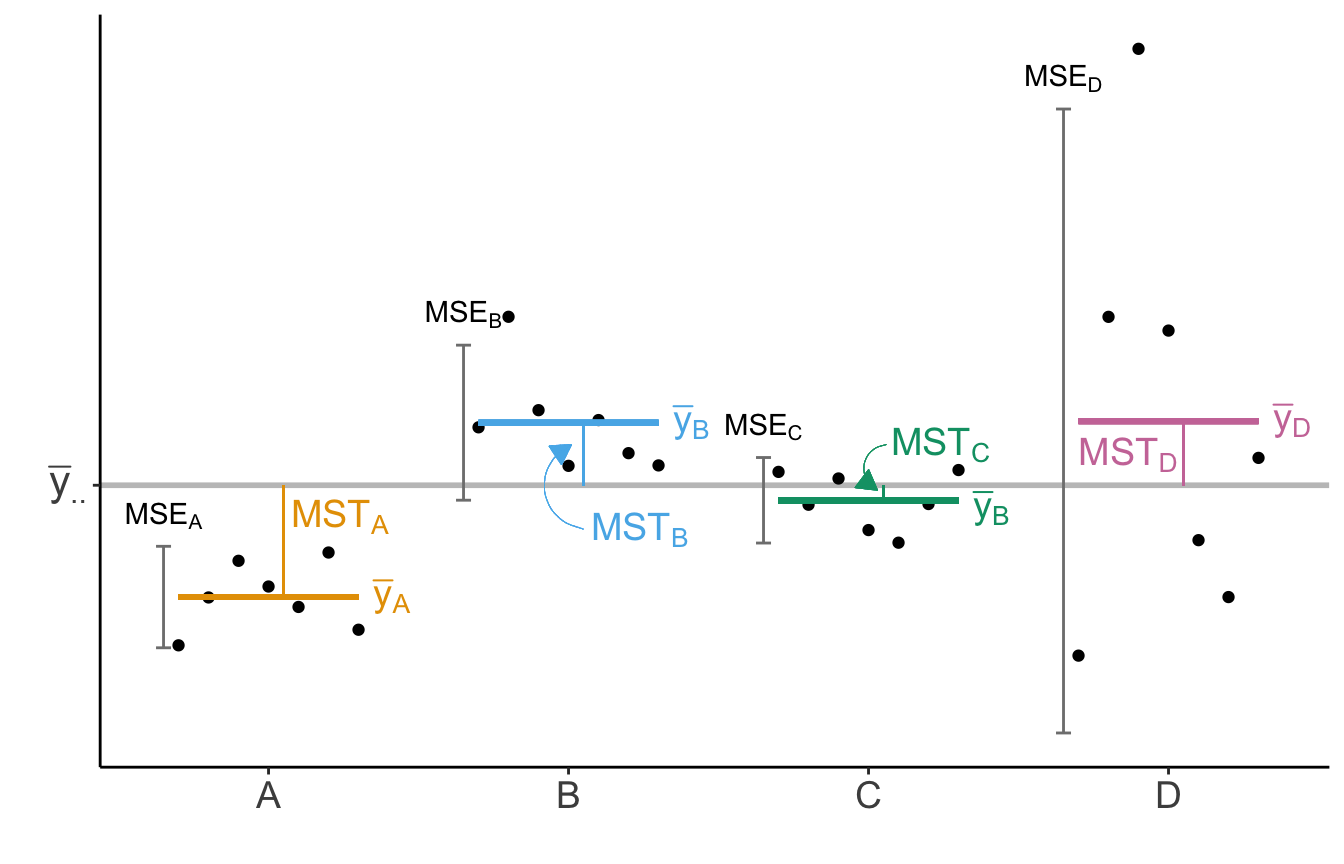
Wie kriegen wir nun die ANOVA rechnerisch auf die Straße? Schauen wir uns dazu einmal die Abbildung 30.3 an. Auf der linken Seiten sehen wir vier Gruppen, die keinen Effekt haben. Die Gruppen liegen alle auf der gleichen Höhe. Es ist mit keinem Unterschied zwischen den Gruppen zu rechnen. Alle Gruppenmittel liegen auf dem globalen Mittel. Die Abweichungen der einzelnen Gruppenmittel zum globalen Mittel ist damit gleich null. Auf der rechten Seite sehen wir vier Gruppen mit einem Effekt. Die Gruppen unterscheiden sich in ihren Gruppenmitteln. Dadurch unterscheide sich aber auch die Gruppenmittel von dem globalen Mittel.
Wir können daher wie in Tabelle 30.4 geschrieben die Funktionsweise der ANOVA zusammenfassen. Wir vergleichen die Mittelwerte indem wir die Varianzen nutzen.
| All level means are equal. | = | The differences between level means and the total mean are small. |
Nun kommen wir zum eigentlichen Schwenk und warum eigentlich die ANOVA meist etwas verwirrt. Wir wollen eine Aussage über die Mittelwerte machen. Die Nullhypothese lautet, dass alle Mittelwerte gleich sind. Wie wir in Tabelle 30.4 sagen, heißt alle Mittelwerte gleich auch, dass die Abweichungen von den Gruppenmitteln zum globalen Mittel klein ist.
Wie weit die Gruppenmittel von dem globalen Mittel weg sind, dazu nutzt die ANOVA die Varianz. Die ANOVA vergleicht somit
Wir berechnen also wie die Beobachtungen jeweils um das globale Mittel streuen (\(SS_{total}\)), die einzelnen Beobachtungen um die einzelnen Gruppenmittel \(SS_{error}\) und die Streuung der Gruppenmittel um das globale Mittel (\(SS_{animal}\)). Wir nennen die Streuung Abstandquadrate (eng. sum of squares) und damit sind die Sum of Square \((SS)\) nichts anderes als die Varianz. Die Tabelle 30.5 zeigt die Berechnung des Anteils jeder einzelnen Beobachtung an den jeweiligen Sum of Squares.
| animal (x) | jump_length (y) | \(\boldsymbol{\bar{y}_{i.}}\) | SS\(_{\boldsymbol{animal}}\) | SS\(_{\boldsymbol{error}}\) | SS\(_{\boldsymbol{total}}\) |
|---|---|---|---|---|---|
| dog | \(5.7\) | \(8.13\) | \((8.13 - 7.34)^2 = 0.62\) | \((5.7 - 8.13)^2 = 5.90\) | \((5.7 - 7.34)^2 = 2.69\) |
| dog | \(8.9\) | \(8.13\) | \((8.13 - 7.34)^2 = 0.62\) | \((8.9 - 8.13)^2 = 0.59\) | \((8.9 - 7.34)^2 = 2.43\) |
| dog | \(11.8\) | \(8.13\) | \((8.13 - 7.34)^2 = 0.62\) | \((11.8 - 8.13)^2 = 13.47\) | \((11.8 - 7.34)^2 = 19.89\) |
| dog | \(8.2\) | \(8.13\) | \((8.13 - 7.34)^2 = 0.62\) | \((8.2 - 8.13)^2 = 0.00\) | \((8.2 - 7.34)^2 = 0.74\) |
| dog | \(5.6\) | \(8.13\) | \((8.13 - 7.34)^2 = 0.62\) | \((5.6 - 8.13)^2 = 6.40\) | \((5.6 - 7.34)^2 = 3.03\) |
| dog | \(9.1\) | \(8.13\) | \((8.13 - 7.34)^2 = 0.62\) | \((9.1 - 8.13)^2 = 0.94\) | \((9.1 - 7.34)^2 = 3.10\) |
| dog | \(7.6\) | \(8.13\) | \((8.13 - 7.34)^2 = 0.62\) | \((7.6 - 8.13)^2 = 0.28\) | \((7.6 - 7.34)^2 = 0.07\) |
| cat | \(3.2\) | \(4.74\) | \((4.74 - 7.34)^2 = 6.76\) | \((3.2 - 4.74)^2 = 2.37\) | \((3.2 - 7.34)^2 = 17.14\) |
| cat | \(2.2\) | \(4.74\) | \((4.74 - 7.34)^2 = 6.76\) | \((2.2 - 4.74)^2 = 6.45\) | \((2.2 - 7.34)^2 = 26.42\) |
| cat | \(5.4\) | \(4.74\) | \((4.74 - 7.34)^2 = 6.76\) | \((5.4 - 4.74)^2 = 0.44\) | \((5.4 - 7.34)^2 = 3.76\) |
| cat | \(4.1\) | \(4.74\) | \((4.74 - 7.34)^2 = 6.76\) | \((4.1 - 4.74)^2 = 0.41\) | \((4.1 - 7.34)^2 = 10.50\) |
| cat | \(4.3\) | \(4.74\) | \((4.74 - 7.34)^2 = 6.76\) | \((4.3 - 4.74)^2 = 0.19\) | \((4.3 - 7.34)^2 = 9.24\) |
| cat | \(7.9\) | \(4.74\) | \((4.74 - 7.34)^2 = 6.76\) | \((7.9 - 4.74)^2 = 9.99\) | \((7.9 - 7.34)^2 = 0.31\) |
| cat | \(6.1\) | \(4.74\) | \((4.74 - 7.34)^2 = 6.76\) | \((6.1 - 4.74)^2 = 1.85\) | \((6.1 - 7.34)^2 = 1.54\) |
| fox | \(7.7\) | \(9.16\) | \((9.16 - 7.34)^2 = 3.31\) | \((7.7 - 9.16)^2 = 2.13\) | \((7.7 - 7.34)^2 = 0.13\) |
| fox | \(8.1\) | \(9.16\) | \((9.16 - 7.34)^2 = 3.31\) | \((8.1 - 9.16)^2 = 1.12\) | \((8.1 - 7.34)^2 = 0.58\) |
| fox | \(9.1\) | \(9.16\) | \((9.16 - 7.34)^2 = 3.31\) | \((9.1 - 9.16)^2 = 0.00\) | \((9.1 - 7.34)^2 = 3.10\) |
| fox | \(9.7\) | \(9.16\) | \((9.16 - 7.34)^2 = 3.31\) | \((9.7 - 9.16)^2 = 0.29\) | \((9.7 - 7.34)^2 = 5.57\) |
| fox | \(10.6\) | \(9.16\) | \((9.16 - 7.34)^2 = 3.31\) | \((10.6 - 9.16)^2 = 2.07\) | \((10.6 - 7.34)^2 = 10.63\) |
| fox | \(8.6\) | \(9.16\) | \((9.16 - 7.34)^2 = 3.31\) | \((8.6 - 9.16)^2 = 0.31\) | \((8.6 - 7.34)^2 = 1.59\) |
| fox | \(10.3\) | \(9.16\) | \((9.16 - 7.34)^2 = 3.31\) | \((10.3 - 9.16)^2 = 1.30\) | \((10.3 - 7.34)^2 = 8.76\) |
| \(74.68\) | \(56.53\) | \(131.21\) |
Die ANOVA wird deshalb auch Varianzzerlegung genannt, da die ANOVA versucht den Abstand der Beobachtungen auf die Variablen im Modell zu zerlegen. Also wie viel der Streuung von den Beobachtungen kann von dem Faktor animal erklärt werden? Genau der Abstand von den Gruppenmitteln zu dem globalen Mittelwert.
Du kannst dir das ungefähr als eine Reise von globalen Mittelwert zu der einzelnen Beobachtung vorstellen. Nehmen wir als Beispiel die kleinste Sprungweite eines Katzenflohs von 2.2 cm und visualisieren wir uns die Reise wie in Abbildung 30.4 zu sehen. Wie kommen wir jetzt numerisch vom globalen Mittel mit \(7.34\) zu der Beobachtung? Wir können zum einen den direkten Abstand mit \(2.2 - 7.34\) gleich \(-5.14\) cm berechnen. Das wäre der total Abstand. Wie sieht es nun aus, wenn wir das Gruppenmittel mit beachten? In dem Fall gehen wir vom globalen Mittel zum Gruppenmittel cat mit \(\bar{y}_{cat} - \bar{y}_{..} = 4.74 -7.34\) gleich \(\beta_{cat} = -2.6\) cm. Jetzt sind wir aber noch nicht bei der Beobachtung. Wir haben noch einen Rest von \(y_{cat,2} - \bar{y}_{cat} = 2.2 - 4.74\) gleich \(\epsilon_{cat, 2} = -2.54\) cm, die wir noch zurücklegen müssen. Das heißt, wir können einen Teil der Strecke mit dem Gruppenmittelwert erklären. Oder anders herum, wir können die Strecke vom globalen Mittelwert zu der Beobachtung in einen Teil für das Gruppenmittel und einen unerklärten Rest zerlegen.

Wir rechnen also eine ganze Menge an Abständen und quadrieren dann diese Abstände zu den Sum of Squares. Oder eben der Varianz. Dann fragen wir uns, ob der Faktor in unserem Modell einen Teil der Abstände erklären kann. Wir bauen uns dafür eine ANOVA Tabelle. Tabelle 30.6 zeigt eine theoretische, einfaktorielle ANOVA Tabelle. Wir berechnen zuerst die Abstände als \(SS\). Nun ist es aber so, dass wenn wir in einer Gruppe viele Level und/oder Beobachtungen haben, wir auch größere Sum of Squares bekommen. Wir müssen also die Sum of Squares in mittlere Abweichungsquadrate (eng. mean squares) mitteln. Abschließend können wir die F Statistik berechnen, indem wir die \(MS\) des Faktors durch die \(MS\) des Fehlers teilen. Das Verhältnis von erklärter Varianz vom Faktor zu dem unerklärten Rest.
| Varianzquelle | df | Sum of squares | Mean squares | F\(_{\boldsymbol{D}}\) |
|---|---|---|---|---|
| animal | \(k-1\) | \(SS_{animal} = \sum_{i=1}^{k}n_i(\bar{y}_{i.} - \bar{y}_{..})^2\) | \(MS_{animal} = \cfrac{SS_{animal}}{k-1}\) | \(F_{D} = \cfrac{MS_{animal}}{MS_{error}}\) |
| error | \(n-k\) | \(SS_{error} = \sum_{i=1}^{k}\sum_{j=1}^{n_i}(y_{ij} - \bar{y}_{i.})^2\) | \(MS_{error} = \cfrac{SS_{error}}{N-k}\) | |
| total | \(n-1\) | \(SS_{total} = \sum_{i=1}^{k}\sum_{j=1}^{n_i}(y_{ij} - \bar{y}_{..})^2\) |
Wir füllen jetzt die Tabelle 30.7 einmal mit den Werten aus. Nachdem wir das getan haben oder aber die Tabelle in R ausgegeben bekommen haben, können wir die Zahlen interpretieren.
| Varianzquelle | df | Sum of squares | Mean squares | F\(_{\boldsymbol{D}}\) |
|---|---|---|---|---|
| animal | \(3-1\) | \(SS_{animal} = 74.68\) | \(MS_{animal} = \cfrac{74.68}{3-1} = 37.34\) | \(F_{D} = \cfrac{37.34}{3.14} = 11.89\) |
| error | \(21-3\) | \(SS_{error} = 56.53\) | \(MS_{error} = \cfrac{56.53}{18} = 3.14\) | |
| total | \(21-1\) | \(SS_{total} = 131.21\) |
Zu erst ist die berechnete F Statistik \(F_{D}\) von Interesse. Wir haben hier eine \(F_{D}\) von 11.89. Wir vergleichen wieder die berechnete F Statistik mit einem kritischen Wert. Der kritische F Wert \(F_{\alpha = 5\%}\) lautet für die einfaktorielle ANOVA in diesem konkreten Beispiel mit \(F_{\alpha = 5\%} = 3.55\). Die Entscheidungsregel nach der F Teststatistik lautet, die \(H_0\) abzulehnen, wenn \(F_{D} > F_{\alpha = 5\%}\).
Wir können also die Nullhypothese \(H_0\) in unserem Beispiel ablehnen. Es liegt ein signifikanter Unterschied zwischen den Tiergruppen vor. Mindestens ein Mittelwertsunterschied in den Sprungweiten liegt vor.
Bei der Entscheidung mit der berechneten Teststatistik \(F_{D}\) gilt, wenn \(F_{D} \geq F_{\alpha = 5\%}\) wird die Nullhypothese (H\(_0\)) abgelehnt.
Achtung – Wir nutzen die Entscheidung mit der Teststatistik nur und ausschließlich in der Klausur. In der praktischen Anwendung hat die Betrachtung der berechneten Teststatistik keine Verwendung mehr. Wir nutzen in der praktischen Anwendung den \(p\)-Wert.
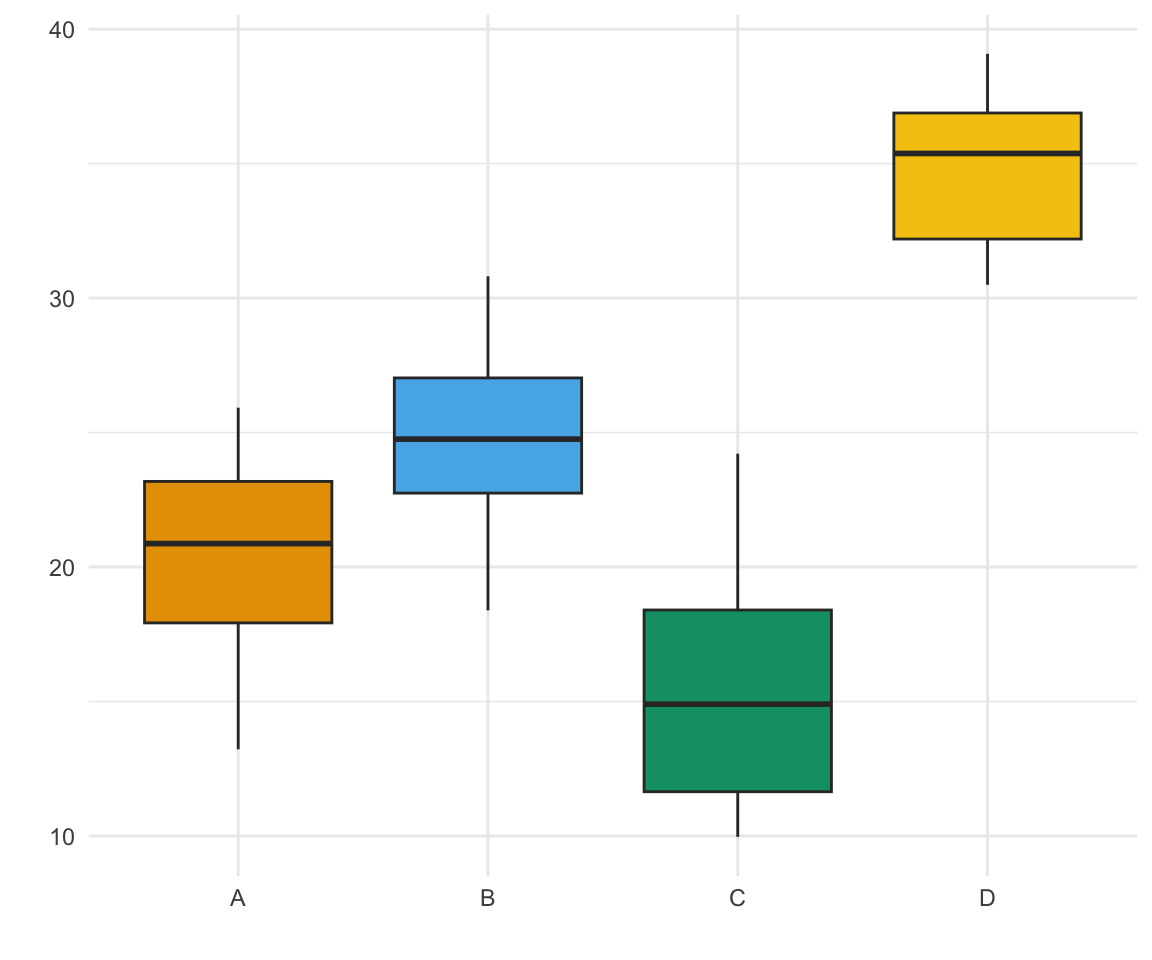
Abschließend noch ein Wort zu der Annahme an eine ANOVA. Wir wollen ja für eine ANOVA ein normalverteiltes Outcome \(y\) und die gleichen Varianzen über alle Gruppen. Wir wollen Varianzhomogenität vorliegen haben. In Abbildung 30.5 siehst du vier Behandlungsgruppen sowie deren lokale Mittel. Die Gruppe D hat eine sehr viel größere Varianz. Auch ist fraglich, ob die Gruppe D einer Normalverteilung folgt. Dadurch passieren zwei Dinge. Erstens ist der lokale Mittelwert von der Gruppe D viel näher am globalen Mittel als er eigentlich wäre, dadurch wird die Summe aus \(MS_{treatment}\) kleiner. Zweitens sind die Beobachtungen sehr weit um das lokale Mittel gestreut, dadurch wird die Summe aus \(MS_{error}\) viel größer. Wir erhalten dadurch eine sehr viel kleinere F Statistik. Im Prinzip vergleichst du mit einer ANOVA ein Set an gleich aussehenden Normalverteilungen. Wenn alles schief und krumm ist, dann ist es vermutlich sogar besser, als wenn wir eine total verkorkste Gruppenverteilung haben, wie hier in Beispiel D.
Wir können das einmal numerisch mit einem kritischen Wert für \(F_{\alpha = 5\%} = 3.55\) durchspielen. Nehmen wir folgende Summe für \(MST\) der Behandlungen aus der Abbildung 30.5 mit den einzelnen \(MST\) einmal wie folgt an. Wir nehmen an das \(MST_A\) gleich 10, \(MST_B\) gleich 20, \(MST_C\) gleich 8 und \(MST_D\) gleich 7 ist. Dann können wir durch das Summieren das \(MST\) berechnen.
\[ MST = 10 + 20 + 8 + 7 = 45 \]
Wenn wir jetzt die Summe für \(MSE\) berechnen, wird diese Summe sehr große, da die Gruppe D eine sehr große Varianz mit einbringt.
\[ MSE = 5 + 6 + 4 + 20 = 35 \]
Das führt am Ende dazu, dass wir eine sehr kleine F Statistik erhalten. Auch wenn sich vielleicht Gruppe B von Gruppe C unterscheidet, können wir den Unterschied wegen der großen Varianz aus Gruppe D nicht nachweisen.
\[ F = \cfrac{MST}{MSE} = \cfrac{45}{35} = 1.28 \leq 3.55 \]
Du siehst hier wie wichtig es ist, ich die Daten einmal zu visualisieren um zu sehen vorher mögliche Probleme herrühren können. Auf der anderen Seite können wir die ANOVA auf ein Recht breites Spektrum an Daten anwenden, solange wir wissen, das die Verteilungen in etwa für jede Gruppe gleich aussehen. Wir müssen nur mit dem \(\eta^2\) aufpassen, wenn wir zu schiefe Verteilungen haben. Dann gibt uns \(\eta^2\) keine valide Aussage mehr über den Anteil der erklärten Varianz.
Wir rechnen keine ANOVA per Hand sondern nutzen R. Dazu müssen wir als erstes das Modell definieren. Das ist im Falle der einfaktoriellen ANOVA relativ einfach. Wir haben unseren Datensatz fac1_tbl mit einer kontinuierlichen Variable jump_lemgth als \(y\) vorliegen sowie einen Faktor animal mit mehr als zwei Leveln als \(x\). Wir definieren das Modell in R in der Form jump_length ~ animal. Um das Modell zu rechnen nutzen wir die Funktion lm() - die Abkürzung für linear model. Danach pipen wir die Ausgabe vom lm() direkt in die Funktion anova(). Die Funktion anova() berechnet uns dann die eigentliche einfaktorielle ANOVA. Wir speichern die Ausgabe der ANOVA in fit_1. Schauen wir uns die ANOVA Ausgabe einmal an.
fit_1 <- lm(jump_length ~ animal, data = fac1_tbl) |>
anova()
fit_1Analysis of Variance Table
Response: jump_length
Df Sum Sq Mean Sq F value Pr(>F)
animal 3 148.16 49.388 4.0522 0.01831 *
Residuals 24 292.51 12.188
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Wir erhalten die Information was wir gerechnet haben, eine Varianzanalyse. Darunter steht, was das \(y\) war nämlich die jump_length. Wir erhalten eine Zeile für den Faktor animal und damit die \(SS_{animal}\) und eine Zeile für den Fehler und damit den \(SS_{error}\). In R heißen die \(SS_{error}\) dann Residuals. Die Zeile für die \(SS_{total}\) fehlt.
Neben der berechneten F Statistik \(F_{D}\) von \(11.89\) erhalten wir auch den p-Wert mit \(0.005\). Wir ignorieren die F Statistik, da wir in der Anwendung nur den p-Wert berücksichtigen. Die Entscheidung gegen die Nulhypothese lautet, dass wenn der p-Wert kleiner ist als das Signifkanzniveau \(\alpha\) von 5% wir die Nullhypothese ablehnen.
Wir haben hier ein signifikantes Ergebnis vorliegen. Mindestens ein Gruppenmittelerstunterschied ist signifikant. Abbildung 30.6 zeigt nochmal die Daten fac1_tbl als Boxplot. Wir überprüfen visuell, ob das Ergebnis der ANOVA stimmen kann. Ja, die Boxplots und das Ergebnis der ANOVA stimmen überein. Die Boxplots liegen nicht alle auf einer Ebene, so dass hier auch ein signifikanter Unterschied zu erwarten war.
Abschließend können wir noch die Funktion eta_squared() aus dem R Paket {effectsize} nutzen um einen Effektschätzer für die einfaktorielle ANOVA zu berechnen. Wir können mit \(\eta^2\) abschätzen, welchen Anteil der Faktor animal an der gesamten Varianz erklärt.
fit_1 |> eta_squared()For one-way between subjects designs, partial eta squared is equivalent
to eta squared. Returning eta squared.# Effect Size for ANOVA
Parameter | Eta2 | 95% CI
-------------------------------
animal | 0.34 | [0.04, 1.00]
- One-sided CIs: upper bound fixed at [1.00].Das \(\eta^2\) können wir auch einfach händisch berechnen.
\[ \eta^2 = \cfrac{SS_{animal}}{SS_{total}} = \cfrac{74.68}{131.21} = 0.57 = 57\% \]
Wir haben nun die Information, das 57% der Varianz der Beobachtungen durch den Faktor animal rklärt wird. Je nach Anwendungsgebiet kann die Relevanz sehr stark variieren. Im Bereich der Züchtung mögen erklärte Varianzen von unter 10% noch sehr relevant sein. Im Bereich des Feldexperiments erwarten wir schon höhere Werte für \(\eta^2\). Immerhin sollte ja unsere Behandlung maßgeblich für die z.B. größeren oder kleineren Pflanzen gesorgt haben.
Die zweifaktorielle ANOVA ist eine wunderbare Methode um herauszufinden, ob zwei Faktoren einen Einfluss auf ein normalverteiltes \(y\) haben. Die Stärke der zweifaktoriellen ANOVA ist hierbei, dass die ANOVA beide Effekte der Faktoren auf das \(y\) simultan modelliert. Darüber hinaus können wir auch noch einen Interaktionsterm mit in das Modell aufnehmen um zu schauen, ob die beiden Faktoren untereinander auch interagieren. Somit haben wir mit der zweifaktoriellen ANOVA die Auswertungsmehode für ein randomiziertes Blockdesign vorliegen.
Die zweifaktorielle ANOVA verlangt ein normalverteiltes \(y\) sowie Varianzhomogenität jeweils separat über beide Behandlungsfaktor \(x_1\) und \(x_2\). Daher alle Level von \(x_1\) sollen die gleiche Varianz haben. Ebenso sollen alle Level von \(x_2\) die gleiche Varianz haben. Unsere Annahme an die Daten \(D\) ist, dass das dein \(y\) normalverteilt ist und das die Level vom \(x_1\) und \(x_2\) jeweils für sich homogen in den Varianzen sind.
Wir wollen uns nun einen etwas komplexes Modell anschauen mit einem etwas komplizierteren Datensatz flea_dog_cat_fox_site.csv. Wir brauchen hierfür ein normalverteiltes \(y\) und sowie zwei Faktoren. Das macht auch soweit Sinn, denn wir wollen ja auch eine zweifaktorielle ANOVA rechnen.
Im Folgenden selektieren mit der Funktion select() die beiden Spalten jump_length als \(y\) und die Spalte animal sowie die Spalte site als \(x\). Danach müssen wir noch die Variable animal sowie die Variable site in einen Faktor mit der Funktion as_factor() umwandeln.
fac2_tbl <- read_csv2("data/flea_dog_cat_fox_site.csv") |>
select(animal, site, jump_length) |>
mutate(animal = as_factor(animal),
site = as_factor(site))Wir erhalten das Objekt fac2_tbl mit dem Datensatz in Tabelle 30.8 nochmal dargestellt.
jump_length und einem Faktor animal mit drei Leveln sowie dem Faktor site mit vier Leveln.
| animal | site | jump_length |
|---|---|---|
| cat | city | 12.04 |
| cat | city | 11.98 |
| cat | city | 16.10 |
| cat | city | 13.42 |
| cat | city | 12.37 |
| cat | city | 16.36 |
| cat | city | 14.91 |
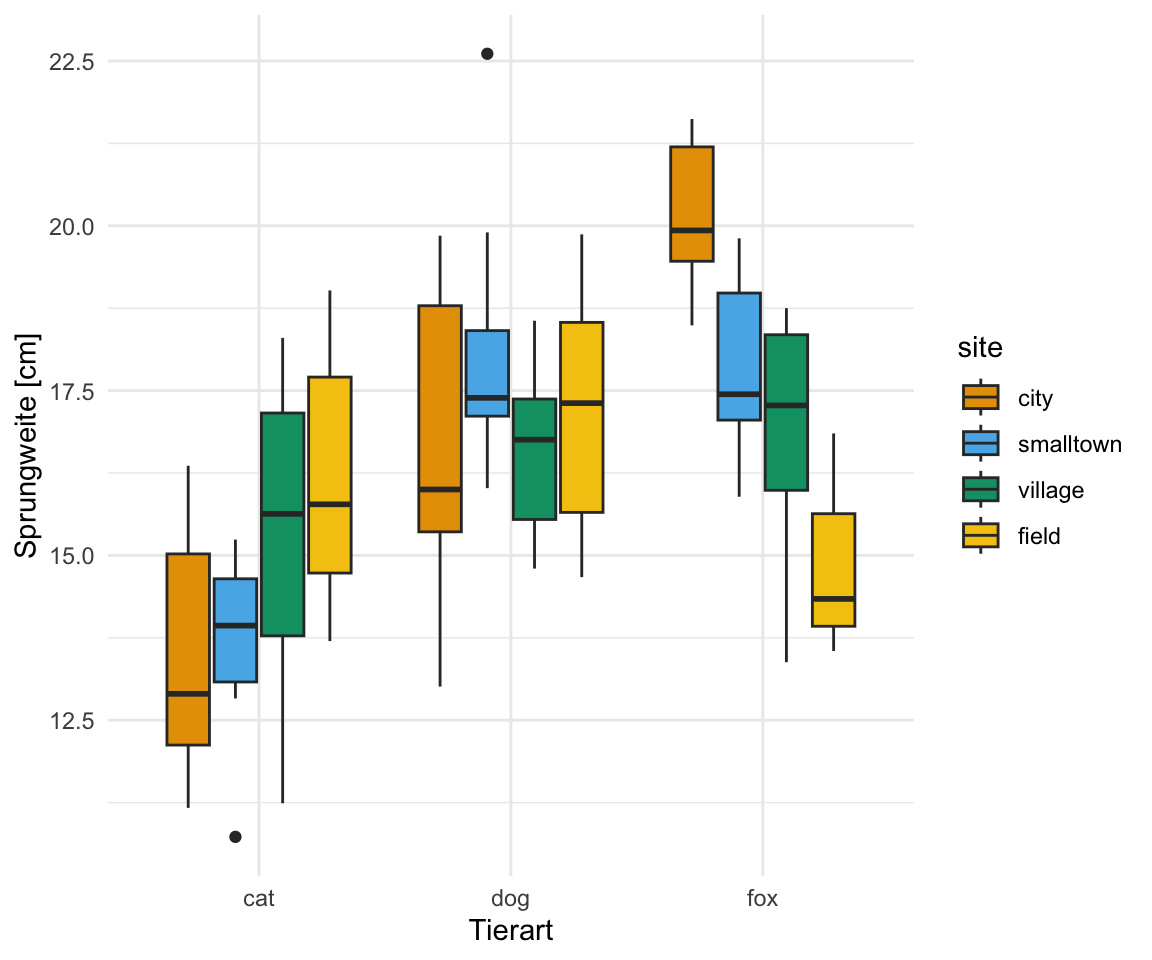
Die Beispieldaten sind in Abbildung 30.7 abgebildet. Wir sehen auf der x-Achse den Faktor animal mit den drei Leveln dog, cat und fox. Jeder dieser Faktorlevel hat nochmal einen Faktor in sich. Dieser Faktor lautet site und stellt dar, wo die Flöhe gesammelt wurden. Die vier Level des Faktors site sind city, smalltown, village und field.
Wir bauen dann mit den beiden Variablen bzw. Faktoren animal und site aus dem Objekt fac2_tbl folgendes Modell für die zweifaktorielle ANOVA:
\[ jump\_length \sim animal + site \]
Bevor wir jetzt das Modell verwenden, müssen wir uns nochmal überlegen, welchen Schluß wir eigentlich über die Nullhypothese machen. Wir immer können wir nur die Nullhypothese ablehnen. Daher überlegen wir uns im Folgenden wie die Nullhypothese in der zweifaktoriellen ANOVA aussieht. Dann bilden wir anhand der Nullhypothese noch die Alternativehypothese.
Wir haben für jeden Faktor der zweifaktoriellen ANOVA ein Hypothesenpaar. Im Folgenden sehen wir die jeweiligen Hypothesenpaare. Einmal für animal, als Haupteffekt. Wir nennen einen Faktor den Hauptfaktor, weil wir an diesem Faktor am meisten interessiert sind. Wenn wir später einen Posthoc Test durchführen würden, dann würden wir diesen Faktor nehmen. Wir sind primär an dem Unterschied der Sprungweiten in [cm] in Gruppen Hund, Katze und Fuchs interessiert.
\[ \begin{aligned} H_0: &\; \bar{y}_{cat} = \bar{y}_{dog} = \bar{y}_{fox}\\ H_A: &\; \bar{y}_{cat} \ne \bar{y}_{dog}\\ \phantom{H_A:} &\; \bar{y}_{cat} \ne \bar{y}_{fox}\\ \phantom{H_A:} &\; \bar{y}_{dog} \ne \bar{y}_{fox}\\ \phantom{H_A:} &\; \mbox{für mindestens ein Paar} \end{aligned} \]
Einmal für site, als Nebeneffekt oder Blockeffekt oder Clustereffekt. Meist eine Variable, die wir auch erhoben haben und vermutlich auch einen Effekt auf das \(y\) haben wird. Oder aber wir haben durch das exprimentelle Design noch eine Aufteilungsvariable wie Block vorliegen. In unserem Beispiel ist es site oder der Ort, wo wir die Hunde-, Katzen, und Fuchsflöhe gefunden haben.
\[ \begin{aligned} H_0: &\; \bar{y}_{city} = \bar{y}_{smalltown} = \bar{y}_{village} = \bar{y}_{field}\\ H_A: &\; \bar{y}_{city} \ne \bar{y}_{smalltown}\\ \phantom{H_A:} &\; \bar{y}_{city} \ne \bar{y}_{village}\\ \phantom{H_A:} &\; \bar{y}_{city} \ne \bar{y}_{field}\\ \phantom{H_A:} &\; \bar{y}_{smalltown} \ne \bar{y}_{village}\\ \phantom{H_A:} &\; \bar{y}_{smalltown} \ne \bar{y}_{field}\\ \phantom{H_A:} &\; \bar{y}_{village} \ne \bar{y}_{field}\\ \phantom{H_A:} &\; \mbox{für mindestens ein Paar} \end{aligned} \]
Einmal für die Interaktion animal:site - die eigentliche Stärke der zweifaktoriellen ANOVA. Wir können uns anschauen, ob die beiden Faktoren miteinander interagieren. Das heißt, ob eine Interaktion zwischen dem Faktor animal und dem Faktor site vorliegt.
\[ \begin{aligned} H_0: &\; \mbox{keine Interaktion}\\ H_A: &\; \mbox{eine Interaktion zwischen animal und site} \end{aligned} \]
Wir haben also jetzt die verschiedenen Hypothesenpaare definiert und schauen uns jetzt die ANOVA in R einmal in der Anwendung an.
Bei der einfaktoriellen ANOVA haben wir die Berechnungen der Sum of squares nochmal nachvollzogen. Im Falle der zweifaktoriellen ANOVA verzichten wir darauf. Das Prinzip ist das gleiche. Wir haben nur mehr Mitelwerte und mehr Abweichungen von diesen Mittelwerten, da wir ja nicht nur einen Faktor animal vorliegen haben sondern auch noch den Faktor site. Da wir aber die ANOVA nur Anwenden und dazu R nutzen, müssen wir jetzt nicht per Hand die zweifaktorielle ANOVA rechnen. Du musst aber die R Ausgabe der ANOVA verstehen. Und diese Ausgabe schauen wir uns jetzt einmal ohne und dann mit Interaktionsterm an.
Wir wollen nun einmal die zweifaktorielle ANOVA ohne Interaktionsterm rechnen die in Tabelle 30.9 dargestellt ist. Die \(SS\) und \(MS\) für die zweifaktorielle ANOVA berechnen wir nicht selber sondern nutzen die Funktion anova() in R.
| Varianzquelle | df | Sum of squares | Mean squares | F\(_{\boldsymbol{D}}\) |
|---|---|---|---|---|
| animal | \(a-1\) | \(SS_{animal}\) | \(MS_{animal}\) | \(F_{D} = \cfrac{MS_{animal}}{MS_{error}}\) |
| site | \(b-1\) | \(SS_{site}\) | \(MS_{site}\) | \(F_{D} = \cfrac{MS_{site}}{MS_{error}}\) |
| error | \(n-(a-1)(b-1)\) | \(SS_{error}\) | \(MS_{error}\) | |
| total | \(n-1\) | \(SS_{total}\) |
Im Folgenden sehen wir nochmal das Modell ohne Interaktionsterm. Wir nutzen die Schreibweise in R für eine Modellformel.
\[ jump\_length \sim animal + site \]
Wir bauen nun mit der obigen Formel ein lineares Modell mit der Funktion lm() in R. Danach pipen wir das Modell in die Funktion anova() wie auch in der einfaktoriellen Variante der ANOVA. Die Funktion bleibt die Gleiche, was sich ändert ist das Modell in der Funktion lm().
fit_2 <- lm(jump_length ~ animal + site, data = fac2_tbl) |>
anova()
fit_2Analysis of Variance Table
Response: jump_length
Df Sum Sq Mean Sq F value Pr(>F)
animal 2 180.03 90.017 19.8808 3.92e-08 ***
site 3 9.13 3.042 0.6718 0.571
Residuals 114 516.17 4.528
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Wir erhalten wiederum die ANOVA Ergebnistabelle. Anstatt nur die Zeile animal für den Effekt des Faktors animal sehen wir jetzt auch noch die Zeile site für den Effekt des Faktors site. Zuerst ist weiterhin der Faktor animal signifikant, da der \(p\)-Wert mit \(0.000000039196\) kleiner ist als das Signifikanzniveau \(\alpha\) von 5%. Wir können von mindestens einem Gurppenunterschied im Faktor animal ausgehen. Im Weiteren ist der Faktor site nicht signifikant. Es scheint keinen Unterschied zwischend den einzelnen Orten und der Sprunglänge von den Hunde-, Katzen- und Fuchsflöhen zu geben.
Neben der Standausgabe von R können wir auch die tidy Variante uns ausgeben lassen. In dem Fall sieht die Ausgabe etwas mehr aufgeräumt aus.
fit_2 |> tidy()# A tibble: 3 × 6
term df sumsq meansq statistic p.value
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 animal 2 180. 90.0 19.9 0.0000000392
2 site 3 9.13 3.04 0.672 0.571
3 Residuals 114 516. 4.53 NA NA Abschließend können wir uns übr \(\eta^2\) auch die erklärten Anteile der Varianz wiedergeben lassen.
fit_2 |> eta_squared()# Effect Size for ANOVA (Type I)
Parameter | Eta2 (partial) | 95% CI
-----------------------------------------
animal | 0.26 | [0.15, 1.00]
site | 0.02 | [0.00, 1.00]
- One-sided CIs: upper bound fixed at [1.00].Wir sehen, dass nur ein kleiner Teil der Varianz von dem Faktor animal erklärt wird, nämlich 26%. Für den Faktor site haben wir nur einen Anteil von 2% der erklärten Varianz. Somit hat die site weder einen signifikanten Einflluss auf die Sprungweite von Flöhen noch ist dieser Einfluss als relevant zu betrachten.
Abschließend können wir die Werte in der Tabelle 30.10 ergänzen. Die Frage ist inwieweit diese Tabelle in der Form von Interesse ist. Meist wird geschaut, ob die Faktoren signifikant sind oder nicht. Abschließend eventuell noch die \(\eta^2\) Werte berichtet. Hier musst du schauen, was in deinem Kontext der Forschung oder Abschlussarbeit erwartet wird.
| Varianzquelle | df | Sum of squares | Mean squares | F\(_{\boldsymbol{D}}\) |
|---|---|---|---|---|
| animal | \(3-1\) | \(SS_{animal} = 180.03\) | \(MS_{animal} = 90.02\) | \(F_{D} = \cfrac{90.02}{4.53} = 19.88\) |
| site | \(4-1\) | \(SS_{site} = 9.13\) | \(MS_{site} = 3.04\) | \(F_{D} = \cfrac{3.04}{4.53} = 0.67\) |
| error | \(120-(3-1)(4-1)\) | \(SS_{error} = 516.17\) | \(MS_{error} = 4.53\) | |
| total | \(120-1\) | \(SS_{total} = 705.33\) |
Die eigentlich Stärke der zweifaktoriellen ANOVA ist die Nutzung des Interaktionsterm. Also die Berücksichtigung der Interaktion zwischen den beiden Faktoren in der ANOVA. Wir wollen nun noch einmal die zweifaktorielle ANOVA mit Interaktionsterm rechnen, die in Tabelle 30.11 dargestellt ist. Die \(SS\) und \(MS\) für die zweifaktorielle ANOVA berechnen wir nicht selber sondern nutzen wie immer die Funktion anova() in R.
| Varianzquelle | df | Sum of squares | Mean squares | F\(_{\boldsymbol{D}}\) |
|---|---|---|---|---|
| animal | \(a-1\) | \(SS_{animal}\) | \(MS_{animal}\) | \(F_{D} = \cfrac{MS_{animal}}{MS_{error}}\) |
| site | \(b-1\) | \(SS_{site}\) | \(MS_{site}\) | \(F_{D} = \cfrac{MS_{site}}{MS_{error}}\) |
| animal \(\times\) site | \((a-1)(b-1)\) | \(SS_{animal \times site}\) | \(MS_{animal \times site}\) | \(F_{D} = \cfrac{MS_{animal \times site}}{MS_{error}}\) |
| error | \(n-ab\) | \(SS_{error}\) | \(MS_{error}\) | |
| total | \(n-1\) | \(SS_{total}\) |
Im Folgenden sehen wir nochmal das Modell mit Interaktionsterm. Wir nutzen die Schreibweise in R für eine Modellformel. Einen Interaktionsterm bilden wir durch das : in R ab. Wir können theoretisch auch noch weitere Interaktionsterme bilden, also auch x:y:z. Ich würde aber davon abraten, da diese Interaktionsterme schwer zu interpretieren sind.
\[ jump\_length \sim animal + site + animal:site \]
Wir bauen nun mit der obigen Formel ein lineares Modell mit der Funktion lm() in R. Es wieder das gleich wie schon zuvor. Danach pipen wir das Modell in die Funktion anova() wie auch in der einfaktoriellen Variante der ANOVA. Die Funktion bleibt die Gleiche, was sich ändert ist das Modell in der Funktion lm(). Auch die Interaktion müssen wir nicht extra in der ANOVA Funktion angeben. Alles wird im Modell des lm() abgebildet.
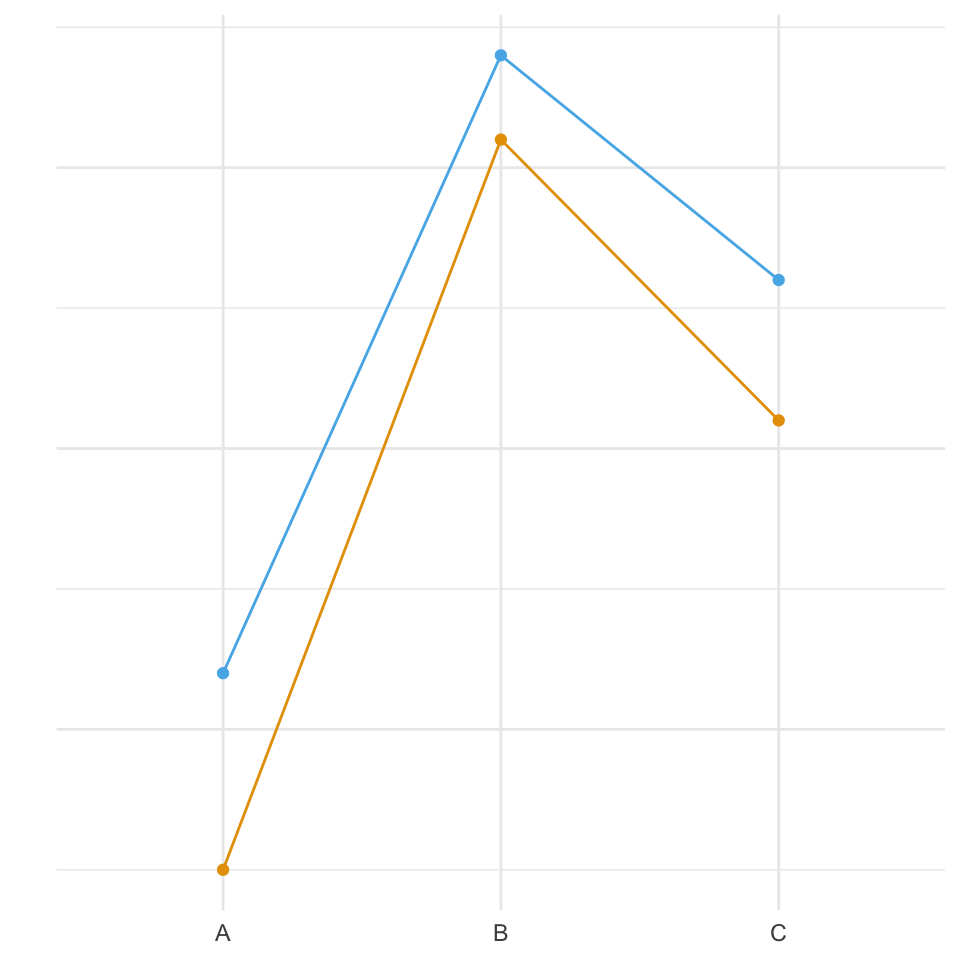
Die visuelle Regel zur Überprüfung der Interaktion lautet nun wie folgt. Abbildung 30.8 zeigt die entsprechende Vislualisierung. Wir haben keine Interaktion vorliegen, wenn die Geraden parallel zueinander laufen und die Abstände bei bei jedem Faktorlevel gleich sind. Wir schauen uns im Prinzip die erste Faktorstufe auf der x-Achse an. Wir sehen den Abstand von der roten zu blauen Linie sowie das die blaue Gerade über der roten Gerade liegt. Dieses Muster erwarten wir jetzt auch an dem Faktorlevel B und C. Eine leichte bis mittlere Interaktion liegt vor, wenn sich die Abstände von dem zweiten Faktor über die Faktorstufen des ersten Faktors ändern. Eine starke Interaktion liegt vor, wenn sich die Geraden schneiden.
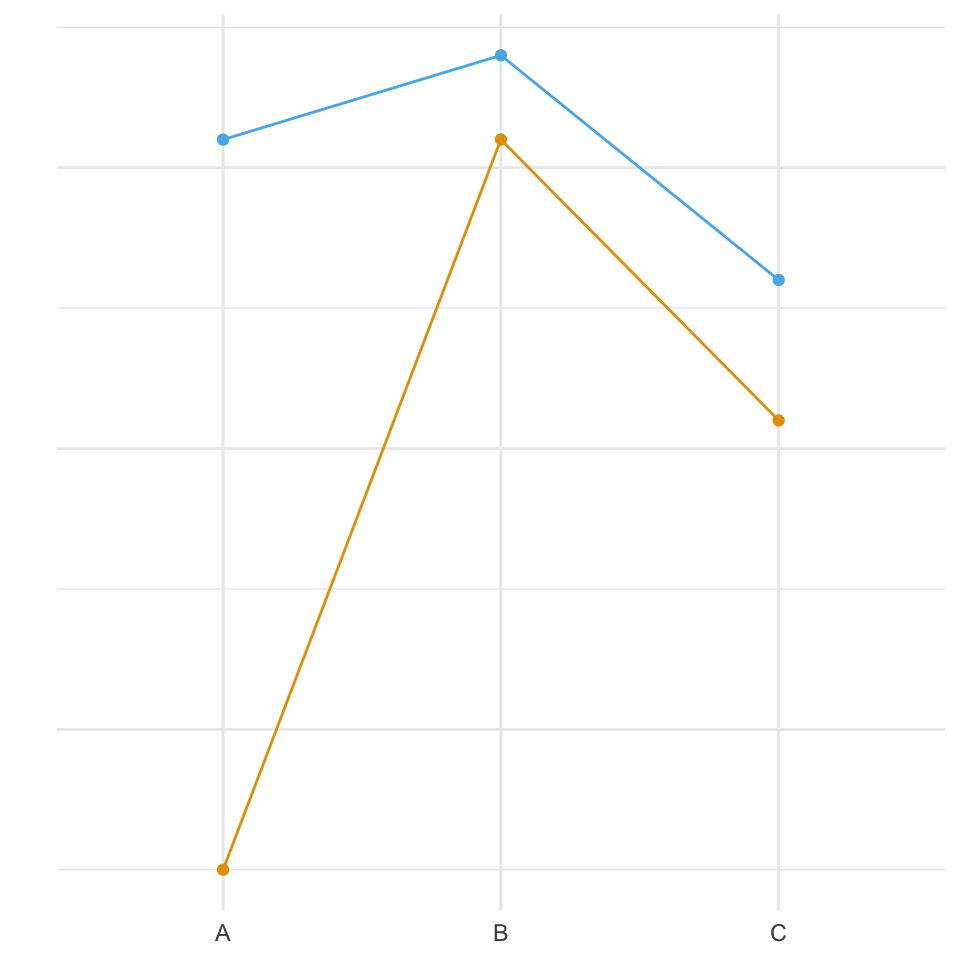
In der Abbildung 30.9 sehen wir den Interaktionsplot für unser Beispiel. Auf der y-Achse ist die Sprunglänge abgebildet und auf der x-Achse der Faktor animal. Die einzelnen Farben stellen die Level des Faktor site dar.
ggplot(fac2_tbl, aes(x = animal, y = jump_length,
color = site, group = site)) +
stat_summary(fun = mean, geom = "point") +
stat_summary(fun = mean, geom = "line") +
theme_minimal() +
scale_color_okabeito()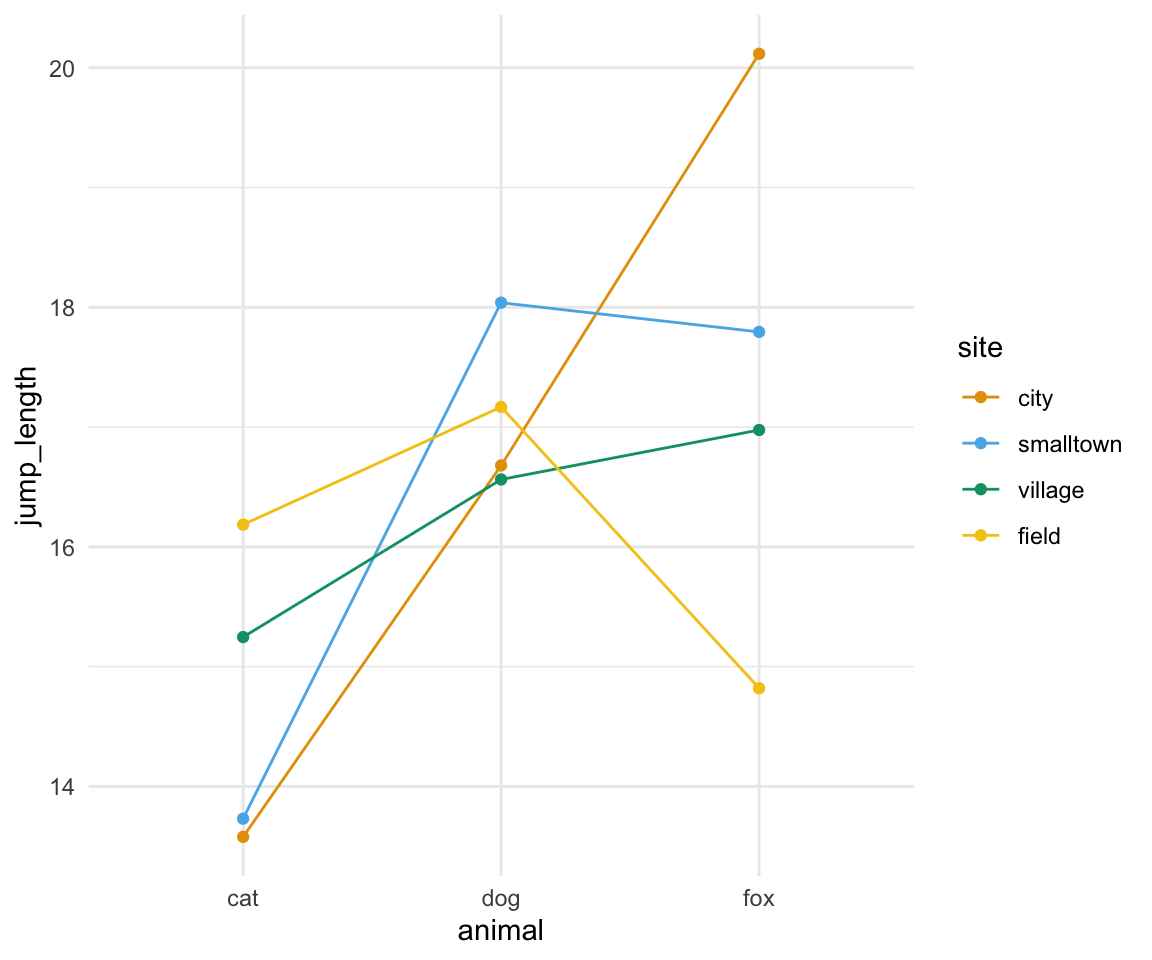
Wenn sich die Geraden in einem Interaktionsplot schneiden, haben wir eine Interaktion zwischen den beiden Faktoren vorliegen. Wir schauen zur visuellen Überprüfung auf den Faktor animal und das erste level cat. Wir sehen die Ordnung des zweiten Faktors site mit field, village, smalltown und city. Diese Ordnung und die Abstände sind bei zweiten Faktorlevel dog schon nicht mehr gegeben. Die Geraden schneiden sich. Auch liegt bei dem Level fox eine andere Ordnung vor. Daher sehen wir hier eine starke Interaktion zwischen den beiden Faktoren animal und site. Du kannst mehr über Geraden sowie lineare Modelle und deren Eigenschaften im Kapitel 41 erfahren.
Wir nehmen jetzt auf jeden Fall den Interaktionsterm animal:site mit in unser Modell und schauen uns einmal das Ergebnis der ANOVA an. Das lineare Modell der ANOVA wird erneut über die Funktion lm() berechnet und anschließend in die Funktion anova() gepipt.
fit_3 <- lm(jump_length ~ animal + site + animal:site, data = fac2_tbl) |>
anova()
fit_3Analysis of Variance Table
Response: jump_length
Df Sum Sq Mean Sq F value Pr(>F)
animal 2 180.03 90.017 30.2807 3.63e-11 ***
site 3 9.13 3.042 1.0233 0.3854
animal:site 6 195.11 32.519 10.9391 1.71e-09 ***
Residuals 108 321.05 2.973
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Die Ergebnistabelle der ANOVA wiederholt sich. Wir sehen, dass der Faktor animal signifikant ist, da der p-Wert mit \(0.000000000036\) kleiner ist als das Signifikanzniveau \(\alpha\) von 5%. Wir können daher die Nullhypothese ablehnen. Mindestens ein Mittelwertsvergleich unterschiedet sich zwischen den Levels des Faktors animal. Im Weiteren sehen wir, dass der Faktor site nicht signifkant ist, da der p-Wert mit \(0.39\) größer ist als das Signifikanzniveau \(\alpha\) von 5%. Wir können daher die Nullhypothese nicht ablehnen. Abschließend finden wir die Interaktion zwischen dem Faktor animalund site las signifikant vor. Wenn wir eine signifikante Interaktion vorliegen haben, dann müssen wir den Faktor animal getrennt für jedes Levels des Faktors site auswerten. Wir können keine Aussage über die Sprungweite von Hunde-, Katzen- und Fuchsflöhen unabhängig von der Herkunft site der Flöhe machen.
Wir können wie immer die etwas aufgeräumte Variante der ANOVA Ausgabe mit der Funktion tidy() uns ausgeben lassen.
fit_3 |> tidy()# A tibble: 4 × 6
term df sumsq meansq statistic p.value
<chr> <int> <dbl> <dbl> <dbl> <dbl>
1 animal 2 180. 90.0 30.3 3.63e-11
2 site 3 9.13 3.04 1.02 3.85e- 1
3 animal:site 6 195. 32.5 10.9 1.71e- 9
4 Residuals 108 321. 2.97 NA NA Im Folgenden können wir noch die \(\eta^2\) für die ANOVA als Effektschätzer berechnen lassen.
fit_3 |> eta_squared()# Effect Size for ANOVA (Type I)
Parameter | Eta2 (partial) | 95% CI
-------------------------------------------
animal | 0.36 | [0.24, 1.00]
site | 0.03 | [0.00, 1.00]
animal:site | 0.38 | [0.24, 1.00]
- One-sided CIs: upper bound fixed at [1.00].Wir sehen, dass nur ein kleiner Teil der Varianz von dem Faktor animal erklärt wird, nämlich 36%. Für den Faktor site haben wir nur einen Anteil von 3% der erklärten Varianz. Die Interaktion zwischen animal und site erklärt 38% der beobachteten Varianz udn ist somit auch vom Effekt her nicht zu ignorieren. Somit hat die site weder einen signifikanten Einflluss auf die Sprungweite von Flöhen noch ist dieser Einfluss als relevant zu betrachten.
Abschließend können wir die Werte in der Tabelle 30.12 ergänzen. Die Frage ist inwieweit diese Tabelle in der Form von Interesse ist. Meist wird geschaut, ob die Faktoren signifikant sind oder nicht. Abschließend eventuell noch die \(\eta^2\) Werte berichtet. Hier musst du schauen, was in deinem Kontext der Forschung oder Abschlussarbeit erwartet wird.
| Varianzquelle | df | Sum of squares | Mean squares | F\(_{\boldsymbol{D}}\) |
|---|---|---|---|---|
| animal | \(3-1\) | \(SS_{animal} = 180.03\) | \(MS_{animal} = 90.02\) | \(F_{D} = \cfrac{90.02}{2.97} = 30.28\) |
| site | \(4-1\) | \(SS_{site} = 9.13\) | \(MS_{site} = 3.04\) | \(F_{D} = \cfrac{3.04}{2.97} = 1.02\) |
| animal \(\times\) site | \((3-1)(4-1)\) | \(SS_{animal \times site} = 195.12\) | \(MS_{animal \times site} = 32.52\) | \(F_{D} = \cfrac{32.52}{2.97} = 10.94\) |
| error | \(120 - (3 \cdot 4)\) | \(SS_{error} = 321.06\) | \(MS_{error} = 2.97\) | |
| total | \(120-1\) | \(SS_{total} = 705.34\) |
Wenn wir eine zweifaktorielle ANOVA rechnen, dann können wir verschiedene Typen von ANOVAs rechnen. Dabei unterscheiden wir zwischen den Typen I, II und III. In dem folgenden Kasten gehe ich einmal auf die drei Typen ein. Wichtig ist, dass wir nur zwischen den drei Typen unterscheiden müssen, wenn wir ein unbalanciertes Design vorliegen haben. Ein unbalanciertes Design haben wir vorliegen, wenn wir in den einzelnen Behandlungsgrupen nicht die gleiche Anzahl an Beobachtungen vorliegen haben. Aber auch hier kommt es dann auf eine Beobachtung Unterschied wieder nicht so an.
Nochmal ganz wichtig, die Ergebnisse der ANOVA-Typen unterscheiden sich vor allem bei unbalancierten Datensätzen. Bei balancierten Datensätzen liefern alle drei Typen in der Regel ähnliche Ergebnisse. Wenn du aber nicht die gleichen Anzahlen an Beobachtungen pro Gruppe hast, dann gilt Folgendes:
Wir können die verschiedenen ANOVA Typen dann mit dem R Paket {car} rechnen. Das ist relativ einfach, die Funktion lauetet dann nur Anova() mit einem großen A am Anfang. Du ersetzt also einfach die Funktion anova() durch die Funktion Anova(), wenn du ein unbalanciertes Design vorliegen hast. Ich würde dir per default die ANOVA Type III empfehlen, wenn du auch einen Interaktionsterm mit in deinem Modell hast. Dann bist du auf der sicheren Seite.
# ANOVA Type I
fit |> anova()
# ANOVA Type II
fit |> Anova(type = "II")
# ANOVA Type III
fit |> Anova(type = "III")Einen tieferen Einblick gibt es natürlich wie immer auch unter Anova – Type I/II/III SS explained.
Nach einer berechneten ANOVA können wir zwei Fälle vorliegen haben.
Wenn du in deinem Experiment keine signifikanten Ergebnisse findest, ist das nicht schlimm. Du kannst deine Daten immer noch mit der explorativen Datenanalyse auswerten wie in Kapitel 17 beschrieben. ƒƒ